 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
Jun 19, 2021
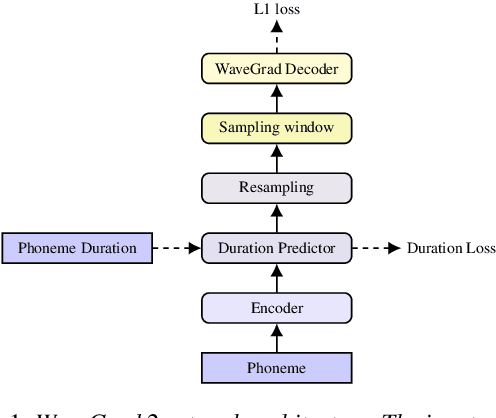
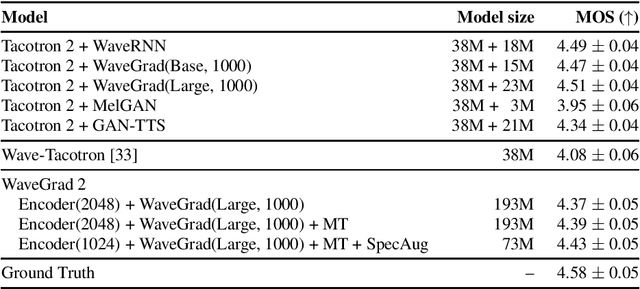
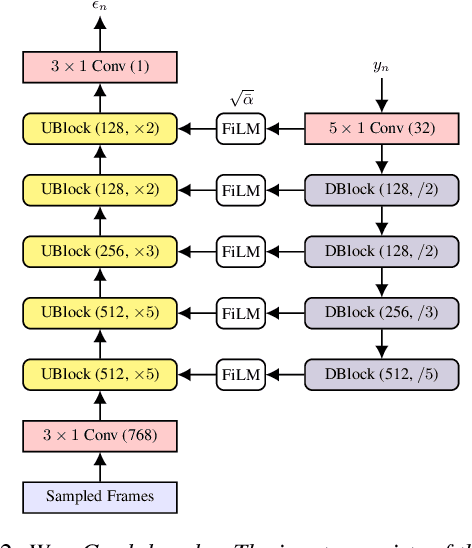

This paper introduces WaveGrad 2, a non-autoregressive generative model for text-to-speech synthesis. WaveGrad 2 is trained to estimate the gradient of the log conditional density of the waveform given a phoneme sequence. The model takes an input phoneme sequence, and through an iterative refinement process, generates an audio waveform. This contrasts to the original WaveGrad vocoder which conditions on mel-spectrogram features, generated by a separate model. The iterative refinement process starts from Gaussian noise, and through a series of refinement steps (e.g., 50 steps), progressively recovers the audio sequence. WaveGrad 2 offers a natural way to trade-off between inference speed and sample quality, through adjusting the number of refinement steps. Experiments show that the model can generate high fidelity audio, approaching the performance of a state-of-the-art neural TTS system. We also report various ablation studies over different model configurations. Audio samples are available at https://wavegrad.github.io/v2.
Detecting Adversarial Examples in Batches -- a geometrical approach
Jun 17, 2022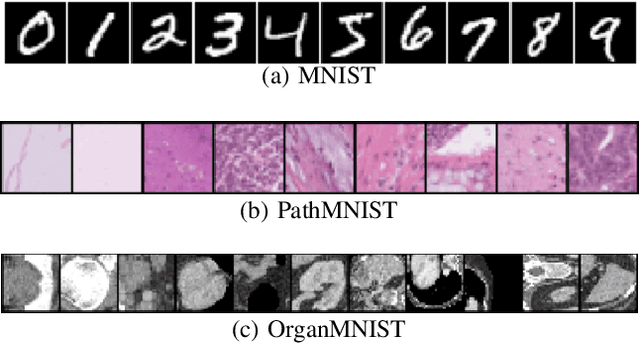

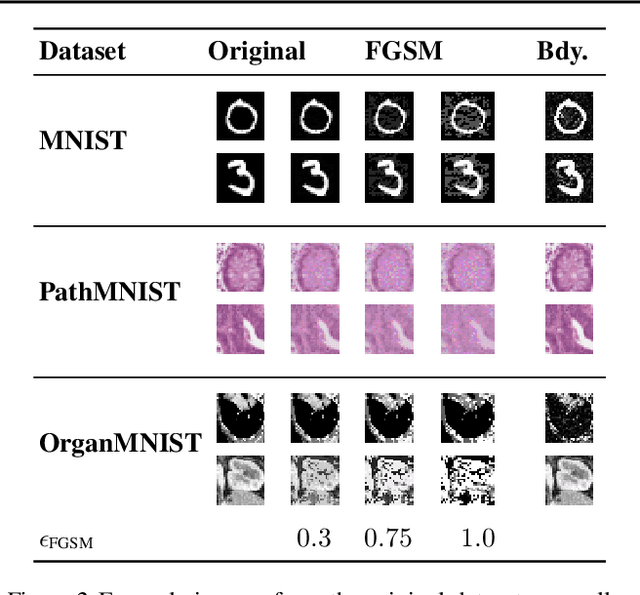

Many deep learning methods have successfully solved complex tasks in computer vision and speech recognition applications. Nonetheless, the robustness of these models has been found to be vulnerable to perturbed inputs or adversarial examples, which are imperceptible to the human eye, but lead the model to erroneous output decisions. In this study, we adapt and introduce two geometric metrics, density and coverage, and evaluate their use in detecting adversarial samples in batches of unseen data. We empirically study these metrics using MNIST and two real-world biomedical datasets from MedMNIST, subjected to two different adversarial attacks. Our experiments show promising results for both metrics to detect adversarial examples. We believe that his work can lay the ground for further study on these metrics' use in deployed machine learning systems to monitor for possible attacks by adversarial examples or related pathologies such as dataset shift.
Confidence Estimation for Attention-based Sequence-to-sequence Models for Speech Recognition
Oct 23, 2020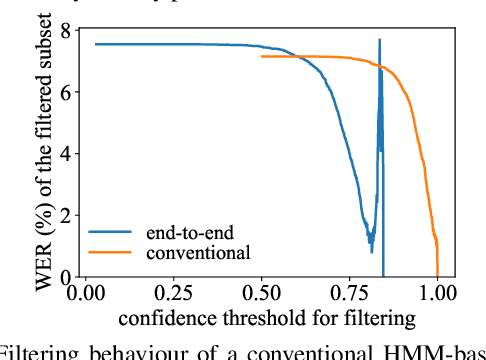
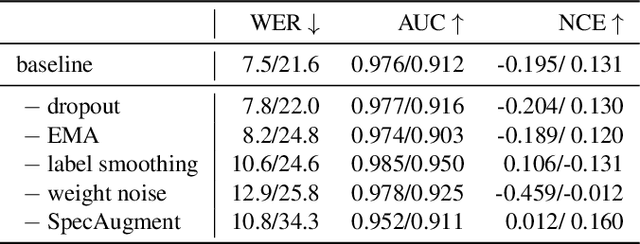
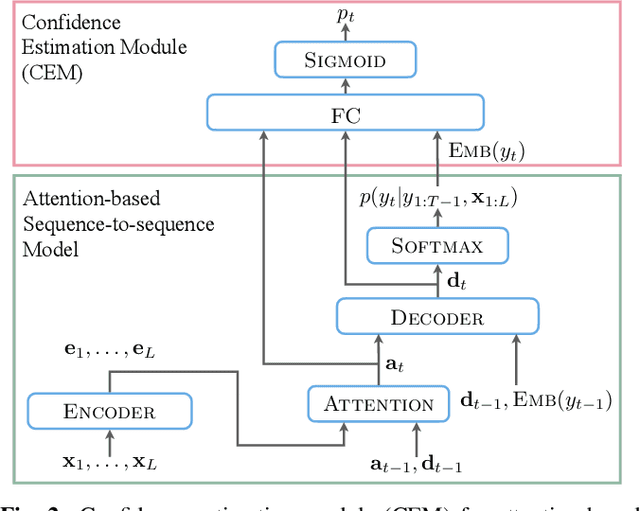
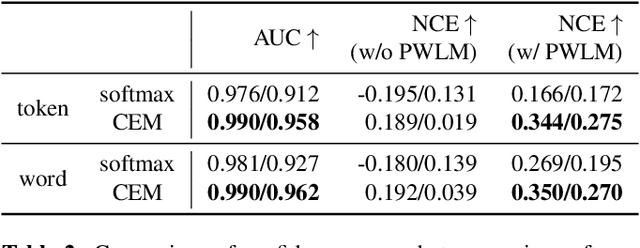
For various speech-related tasks, confidence scores from a speech recogniser are a useful measure to assess the quality of transcriptions. In traditional hidden Markov model-based automatic speech recognition (ASR) systems, confidence scores can be reliably obtained from word posteriors in decoding lattices. However, for an ASR system with an auto-regressive decoder, such as an attention-based sequence-to-sequence model, computing word posteriors is difficult. An obvious alternative is to use the decoder softmax probability as the model confidence. In this paper, we first examine how some commonly used regularisation methods influence the softmax-based confidence scores and study the overconfident behaviour of end-to-end models. Then we propose a lightweight and effective approach named confidence estimation module (CEM) on top of an existing end-to-end ASR model. Experiments on LibriSpeech show that CEM can mitigate the overconfidence problem and can produce more reliable confidence scores with and without shallow fusion of a language model. Further analysis shows that CEM generalises well to speech from a moderately mismatched domain and can potentially improve downstream tasks such as semi-supervised learning.
Continuous Speech Recognition using EEG and Video
Dec 23, 2019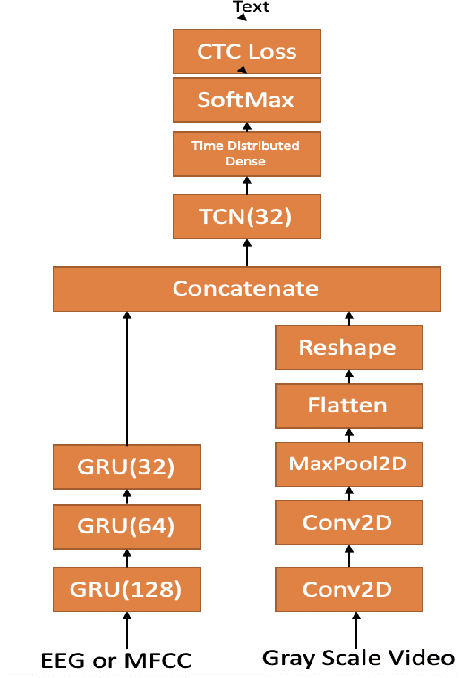
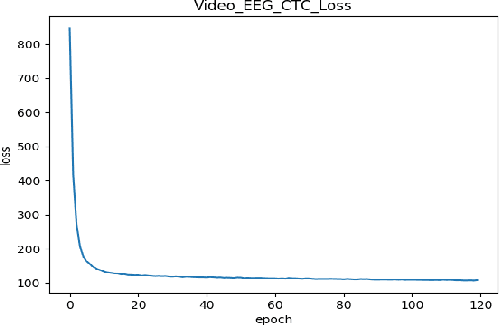
In this paper we investigate whether electroencephalography (EEG) features can be used to improve the performance of continuous visual speech recognition systems. We implemented a connectionist temporal classification (CTC) based end-to-end automatic speech recognition (ASR) model for performing recognition. Our results demonstrate that EEG features are helpful in enhancing the performance of continuous visual speech recognition systems.
Learning Decoupling Features Through Orthogonality Regularization
Mar 31, 2022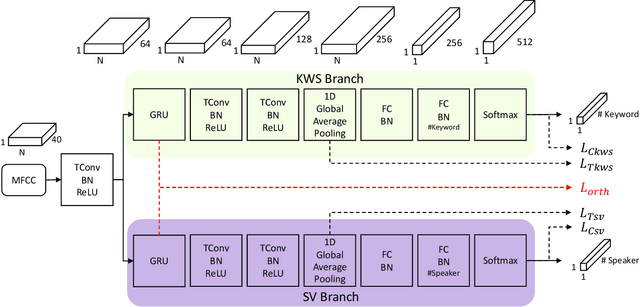
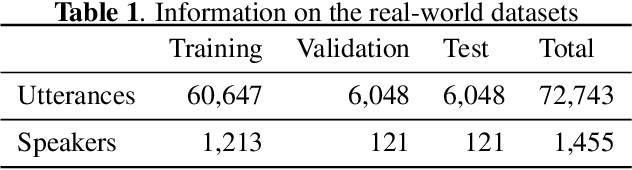
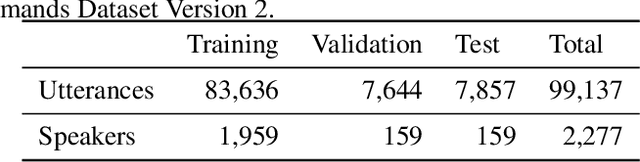
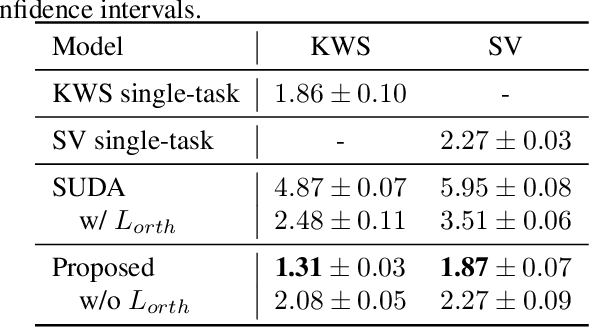
Keyword spotting (KWS) and speaker verification (SV) are two important tasks in speech applications. Research shows that the state-of-art KWS and SV models are trained independently using different datasets since they expect to learn distinctive acoustic features. However, humans can distinguish language content and the speaker identity simultaneously. Motivated by this, we believe it is important to explore a method that can effectively extract common features while decoupling task-specific features. Bearing this in mind, a two-branch deep network (KWS branch and SV branch) with the same network structure is developed and a novel decoupling feature learning method is proposed to push up the performance of KWS and SV simultaneously where speaker-invariant keyword representations and keyword-invariant speaker representations are expected respectively. Experiments are conducted on Google Speech Commands Dataset (GSCD). The results demonstrate that the orthogonality regularization helps the network to achieve SOTA EER of 1.31% and 1.87% on KWS and SV, respectively.
Continuous ErrP detections during multimodal human-robot interaction
Jul 25, 2022
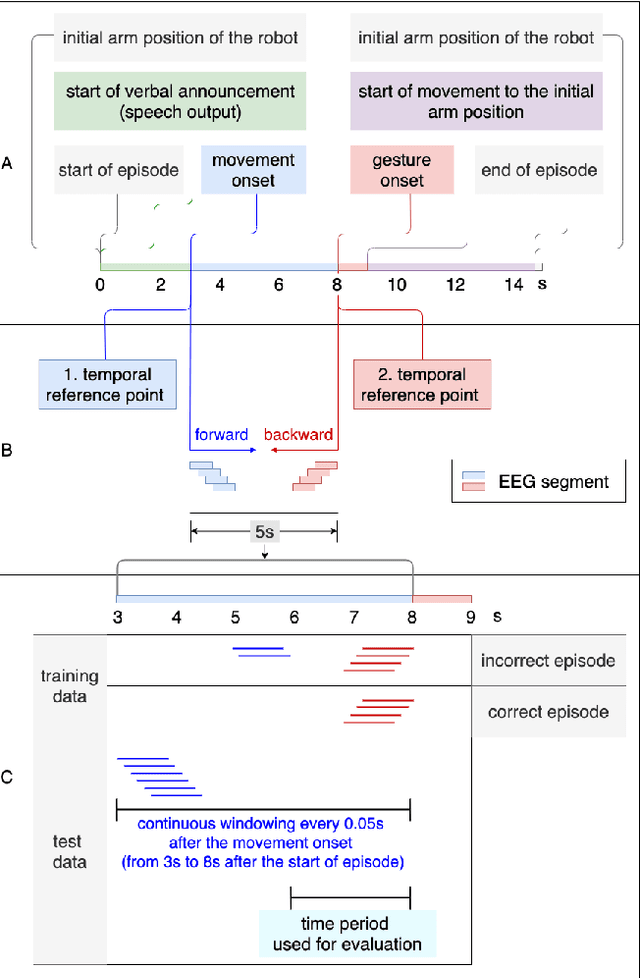
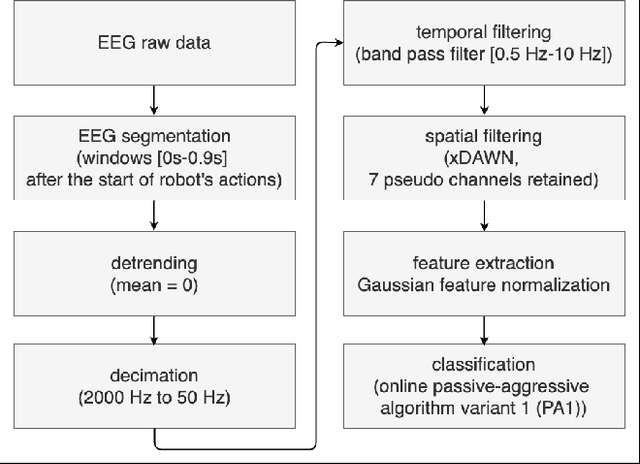
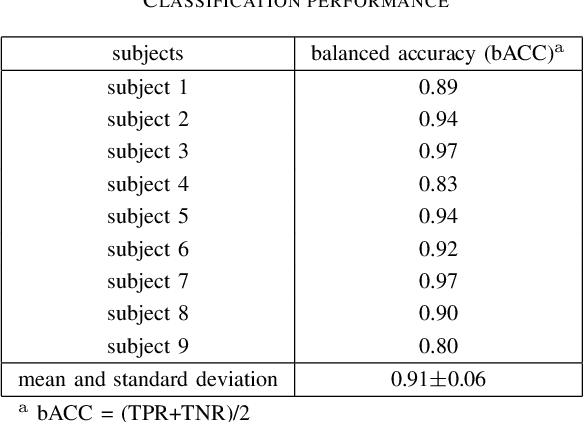
Human-in-the-loop approaches are of great importance for robot applications. In the presented study, we implemented a multimodal human-robot interaction (HRI) scenario, in which a simulated robot communicates with its human partner through speech and gestures. The robot announces its intention verbally and selects the appropriate action using pointing gestures. The human partner, in turn, evaluates whether the robot's verbal announcement (intention) matches the action (pointing gesture) chosen by the robot. For cases where the verbal announcement of the robot does not match the corresponding action choice of the robot, we expect error-related potentials (ErrPs) in the human electroencephalogram (EEG). These intrinsic evaluations of robot actions by humans, evident in the EEG, were recorded in real time, continuously segmented online and classified asynchronously. For feature selection, we propose an approach that allows the combinations of forward and backward sliding windows to train a classifier. We achieved an average classification performance of 91% across 9 subjects. As expected, we also observed a relatively high variability between the subjects. In the future, the proposed feature selection approach will be extended to allow for customization of feature selection. To this end, the best combinations of forward and backward sliding windows will be automatically selected to account for inter-subject variability in classification performance. In addition, we plan to use the intrinsic human error evaluation evident in the error case by the ErrP in interactive reinforcement learning to improve multimodal human-robot interaction.
Data-driven Attention and Data-independent DCT based Global Context Modeling for Text-independent Speaker Recognition
Aug 04, 2022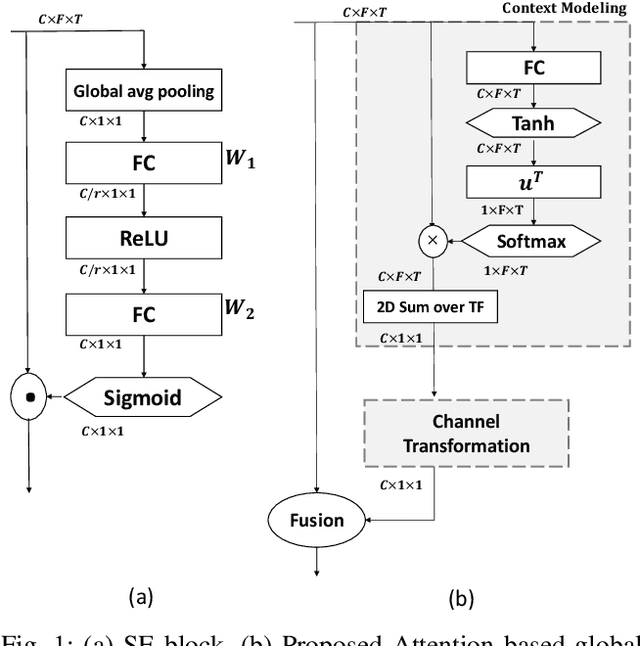
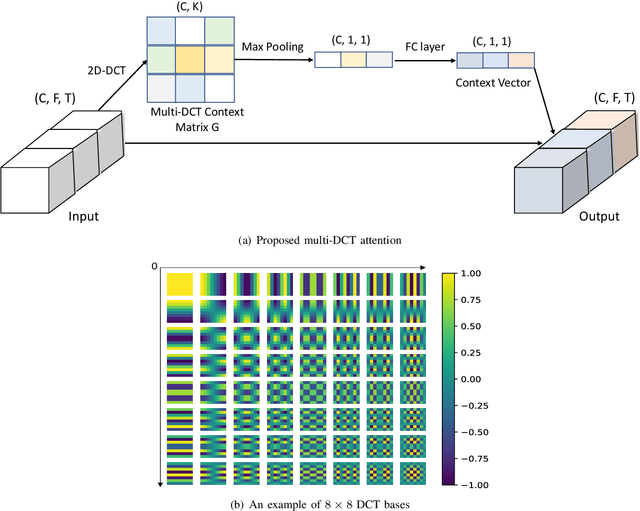
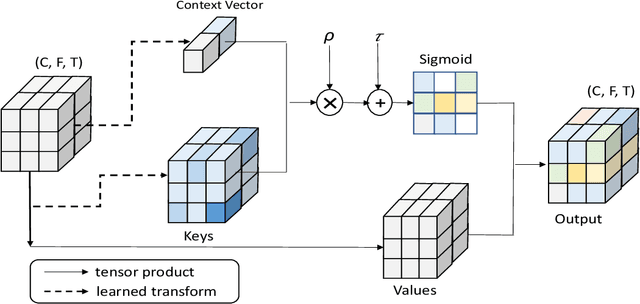
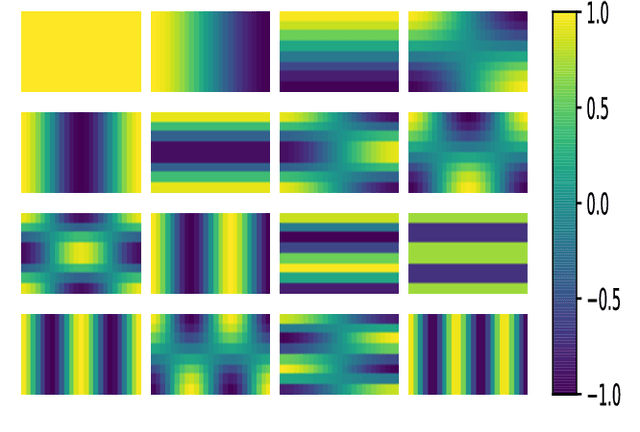
Learning an effective speaker representation is crucial for achieving reliable performance in speaker verification tasks. Speech signals are high-dimensional, long, and variable-length sequences that entail a complex hierarchical structure. Signals may contain diverse information at each time-frequency (TF) location. For example, it may be more beneficial to focus on high-energy parts for phoneme classes such as fricatives. The standard convolutional layer that operates on neighboring local regions cannot capture the complex TF global context information. In this study, a general global time-frequency context modeling framework is proposed to leverage the context information specifically for speaker representation modeling. First, a data-driven attention-based context model is introduced to capture the long-range and non-local relationship across different time-frequency locations. Second, a data-independent 2D-DCT based context model is proposed to improve model interpretability. A multi-DCT attention mechanism is presented to improve modeling power with alternate DCT base forms. Finally, the global context information is used to recalibrate salient time-frequency locations by computing the similarity between the global context and local features. The proposed lightweight blocks can be easily incorporated into a speaker model with little additional computational costs and effectively improves the speaker verification performance compared to the standard ResNet model and Squeeze\&Excitation block by a large margin. Detailed ablation studies are also performed to analyze various factors that may impact performance of the proposed individual modules. Results from experiments show that the proposed global context modeling framework can efficiently improve the learned speaker representations by achieving channel-wise and time-frequency feature recalibration.
Efficient conformer: Progressive downsampling and grouped attention for automatic speech recognition
Sep 08, 2021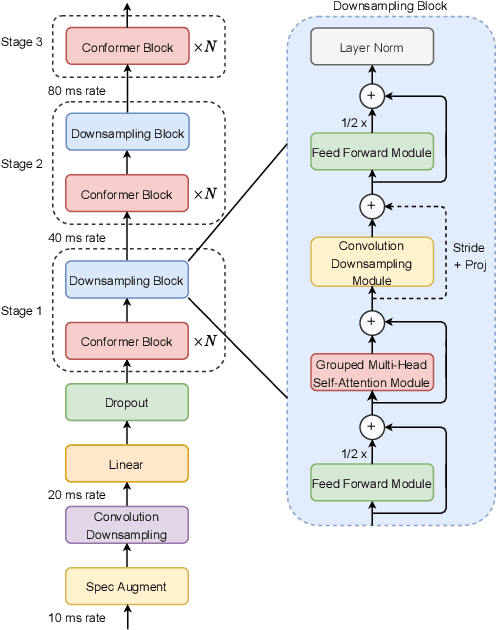
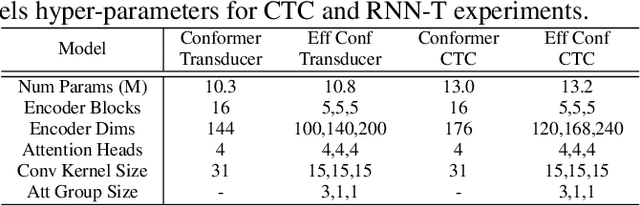

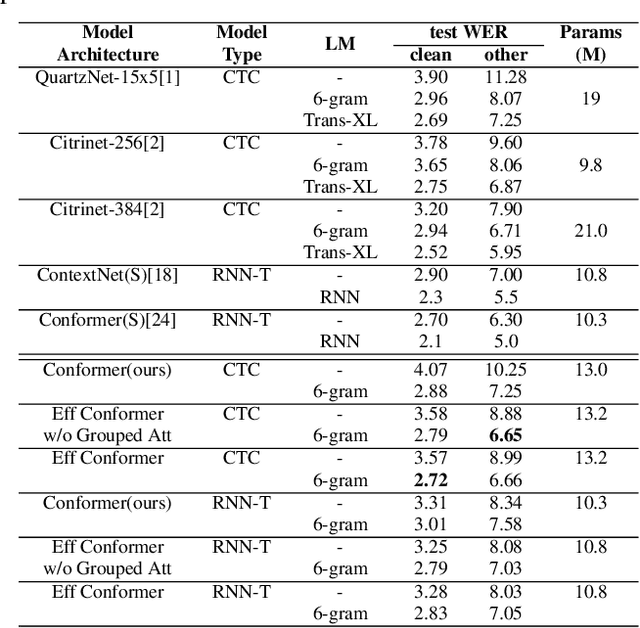
The recently proposed Conformer architecture has shown state-of-the-art performances in Automatic Speech Recognition by combining convolution with attention to model both local and global dependencies. In this paper, we study how to reduce the Conformer architecture complexity with a limited computing budget, leading to a more efficient architecture design that we call Efficient Conformer. We introduce progressive downsampling to the Conformer encoder and propose a novel attention mechanism named grouped attention, allowing us to reduce attention complexity from $O(n^{2}d)$ to $O(n^{2}d / g)$ for sequence length $n$, hidden dimension $d$ and group size parameter $g$. We also experiment the use of strided multi-head self-attention as a global downsampling operation. Our experiments are performed on the LibriSpeech dataset with CTC and RNN-Transducer losses. We show that within the same computing budget, the proposed architecture achieves better performances with faster training and decoding compared to the Conformer. Our 13M parameters CTC model achieves competitive WERs of 3.6%/9.0% without using a language model and 2.7%/6.7% with an external n-gram language model on the test-clean/test-other sets while being 29% faster than our CTC Conformer baseline at inference and 36% faster to train.
Improved Speech Emotion Recognition using Transfer Learning and Spectrogram Augmentation
Aug 08, 2021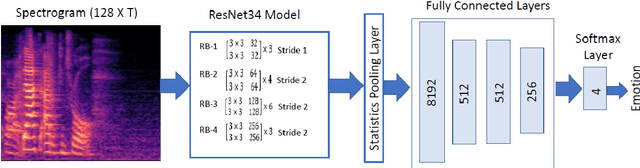
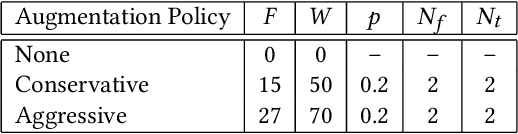
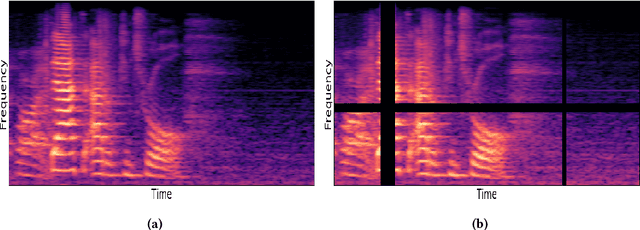
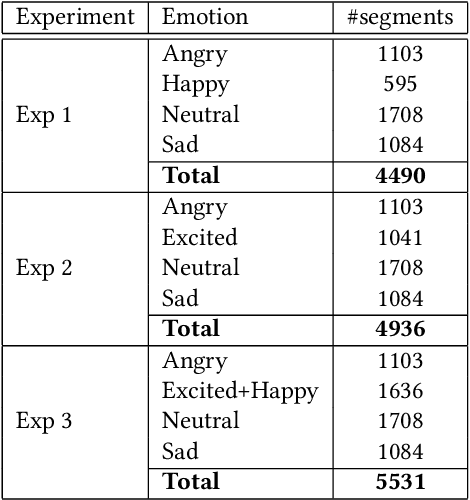
Automatic speech emotion recognition (SER) is a challenging task that plays a crucial role in natural human-computer interaction. One of the main challenges in SER is data scarcity, i.e., insufficient amounts of carefully labeled data to build and fully explore complex deep learning models for emotion classification. This paper aims to address this challenge using a transfer learning strategy combined with spectrogram augmentation. Specifically, we propose a transfer learning approach that leverages a pre-trained residual network (ResNet) model including a statistics pooling layer from speaker recognition trained using large amounts of speaker-labeled data. The statistics pooling layer enables the model to efficiently process variable-length input, thereby eliminating the need for sequence truncation which is commonly used in SER systems. In addition, we adopt a spectrogram augmentation technique to generate additional training data samples by applying random time-frequency masks to log-mel spectrograms to mitigate overfitting and improve the generalization of emotion recognition models. We evaluate the effectiveness of our proposed approach on the interactive emotional dyadic motion capture (IEMOCAP) dataset. Experimental results indicate that the transfer learning and spectrogram augmentation approaches improve the SER performance, and when combined achieve state-of-the-art results.
TED: Triple Supervision Decouples End-to-end Speech-to-text Translation
Sep 21, 2020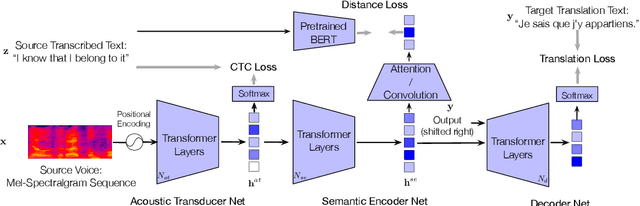
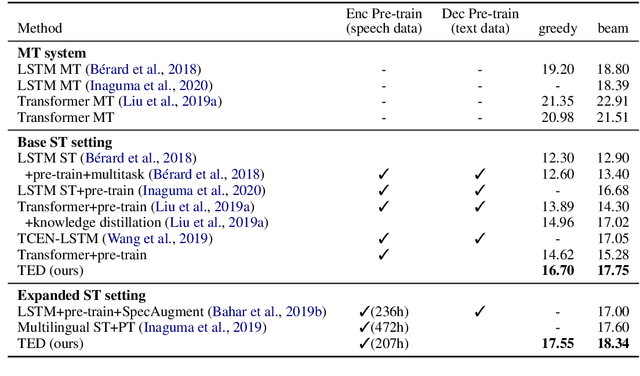
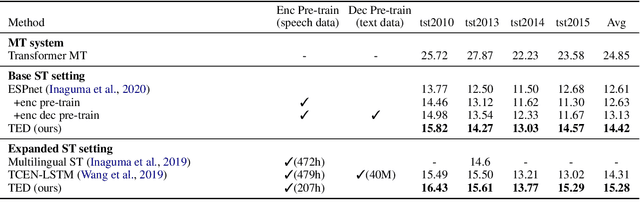
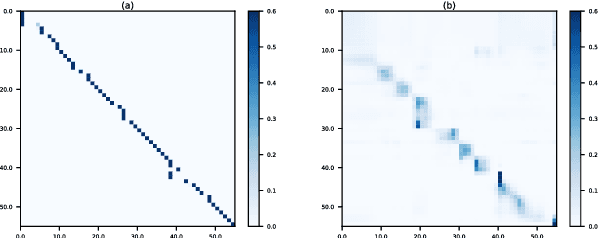
An end-to-end speech-to-text translation (ST) takes audio in a source language and outputs the text in a target language. Inspired by neuroscience, humans have perception systems and cognitive systems to process different information, we propose TED, \textbf{T}ransducer-\textbf{E}ncoder-\textbf{D}ecoder, a unified framework with triple supervision to decouple the end-to-end speech-to-text translation task. In addition to the target sentence translation loss, \method includes two auxiliary supervising signals to guide the acoustic transducer that extracts acoustic features from the input, and the semantic encoder to extract semantic features relevant to the source transcription text. Our method achieves state-of-the-art performance on both English-French and English-German speech translation benchmarks.