 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A RAG-based Question Answering System Proposal for Understanding Islam: MufassirQAS LLM
Feb 01, 2024
Challenges exist in learning and understanding religions, such as the complexity and depth of religious doctrines and teachings. Chatbots as question-answering systems can help in solving these challenges. LLM chatbots use NLP techniques to establish connections between topics and accurately respond to complex questions. These capabilities make it perfect for enlightenment on religion as a question-answering chatbot. However, LLMs also tend to generate false information, known as hallucination. Also, the chatbots' responses can include content that insults personal religious beliefs, interfaith conflicts, and controversial or sensitive topics. It must avoid such cases without promoting hate speech or offending certain groups of people or their beliefs. This study uses a vector database-based Retrieval Augmented Generation (RAG) approach to enhance the accuracy and transparency of LLMs. Our question-answering system is called "MufassirQAS". We created a database consisting of several open-access books that include Turkish context. These books contain Turkish translations and interpretations of Islam. This database is utilized to answer religion-related questions and ensure our answers are trustworthy. The relevant part of the dataset, which LLM also uses, is presented along with the answer. We have put careful effort into creating system prompts that give instructions to prevent harmful, offensive, or disrespectful responses to respect people's values and provide reliable results. The system answers and shares additional information, such as the page number from the respective book and the articles referenced for obtaining the information. MufassirQAS and ChatGPT are also tested with sensitive questions. We got better performance with our system. Study and enhancements are still in progress. Results and future works are given.
ToPro: Token-Level Prompt Decomposition for Cross-Lingual Sequence Labeling Tasks
Jan 29, 2024Prompt-based methods have been successfully applied to multilingual pretrained language models for zero-shot cross-lingual understanding. However, most previous studies primarily focused on sentence-level classification tasks, and only a few considered token-level labeling tasks such as Named Entity Recognition (NER) and Part-of-Speech (POS) tagging. In this paper, we propose Token-Level Prompt Decomposition (ToPro), which facilitates the prompt-based method for token-level sequence labeling tasks. The ToPro method decomposes an input sentence into single tokens and applies one prompt template to each token. Our experiments on multilingual NER and POS tagging datasets demonstrate that ToPro-based fine-tuning outperforms Vanilla fine-tuning and Prompt-Tuning in zero-shot cross-lingual transfer, especially for languages that are typologically different from the source language English. Our method also attains state-of-the-art performance when employed with the mT5 model. Besides, our exploratory study in multilingual large language models shows that ToPro performs much better than the current in-context learning method. Overall, the performance improvements show that ToPro could potentially serve as a novel and simple benchmarking method for sequence labeling tasks.
Cascaded Cross-Modal Transformer for Audio-Textual Classification
Jan 15, 2024Speech classification tasks often require powerful language understanding models to grasp useful features, which becomes problematic when limited training data is available. To attain superior classification performance, we propose to harness the inherent value of multimodal representations by transcribing speech using automatic speech recognition (ASR) models and translating the transcripts into different languages via pretrained translation models. We thus obtain an audio-textual (multimodal) representation for each data sample. Subsequently, we combine language-specific Bidirectional Encoder Representations from Transformers (BERT) with Wav2Vec2.0 audio features via a novel cascaded cross-modal transformer (CCMT). Our model is based on two cascaded transformer blocks. The first one combines text-specific features from distinct languages, while the second one combines acoustic features with multilingual features previously learned by the first transformer block. We employed our system in the Requests Sub-Challenge of the ACM Multimedia 2023 Computational Paralinguistics Challenge. CCMT was declared the winning solution, obtaining an unweighted average recall (UAR) of 65.41% and 85.87% for complaint and request detection, respectively. Moreover, we applied our framework on the Speech Commands v2 and HarperValleyBank dialog data sets, surpassing previous studies reporting results on these benchmarks. Our code is freely available for download at: https://github.com/ristea/ccmt.
Attention-Guided Adaptation for Code-Switching Speech Recognition
Dec 14, 2023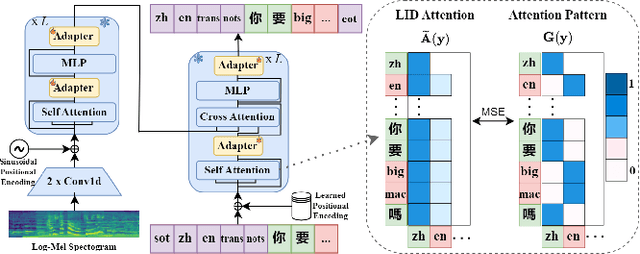
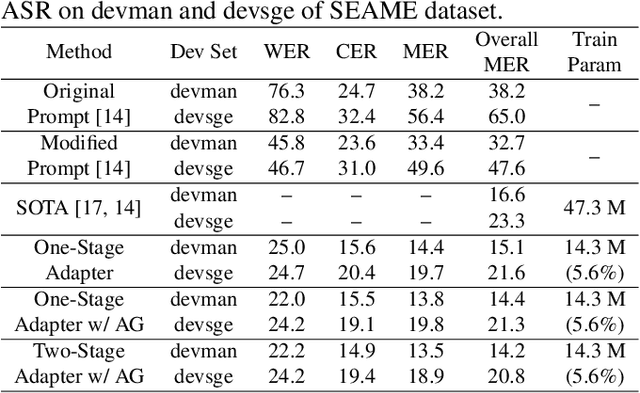
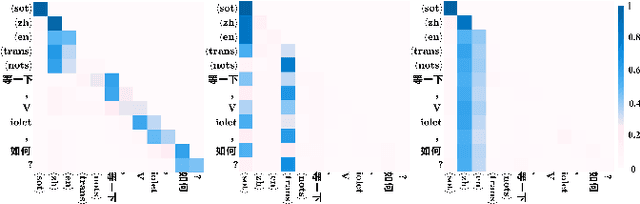
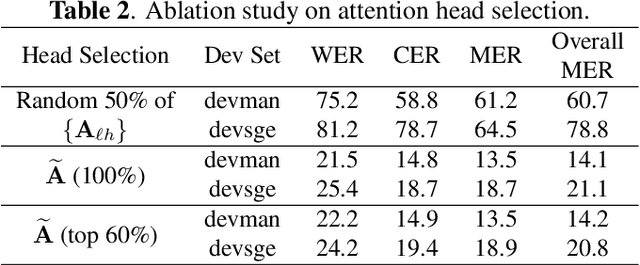
The prevalence of the powerful multilingual models, such as Whisper, has significantly advanced the researches on speech recognition. However, these models often struggle with handling the code-switching setting, which is essential in multilingual speech recognition. Recent studies have attempted to address this setting by separating the modules for different languages to ensure distinct latent representations for languages. Some other methods considered the switching mechanism based on language identification. In this study, a new attention-guided adaptation is proposed to conduct parameter-efficient learning for bilingual ASR. This method selects those attention heads in a model which closely express language identities and then guided those heads to be correctly attended with their corresponding languages. The experiments on the Mandarin-English code-switching speech corpus show that the proposed approach achieves a 14.2% mixed error rate, surpassing state-of-the-art method, where only 5.6% additional parameters over Whisper are trained.
cantnlp@LT-EDI-2024: Automatic Detection of Anti-LGBTQ+ Hate Speech in Under-resourced Languages
Jan 28, 2024This paper describes our homophobia/transphobia in social media comments detection system developed as part of the shared task at LT-EDI-2024. We took a transformer-based approach to develop our multiclass classification model for ten language conditions (English, Spanish, Gujarati, Hindi, Kannada, Malayalam, Marathi, Tamil, Tulu, and Telugu). We introduced synthetic and organic instances of script-switched language data during domain adaptation to mirror the linguistic realities of social media language as seen in the labelled training data. Our system ranked second for Gujarati and Telugu with varying levels of performance for other language conditions. The results suggest incorporating elements of paralinguistic behaviour such as script-switching may improve the performance of language detection systems especially in the cases of under-resourced languages conditions.
Paralinguistics-Enhanced Large Language Modeling of Spoken Dialogue
Jan 17, 2024Large Language Models (LLMs) have demonstrated superior abilities in tasks such as chatting, reasoning, and question-answering. However, standard LLMs may ignore crucial paralinguistic information, such as sentiment, emotion, and speaking style, which are essential for achieving natural, human-like spoken conversation, especially when such information is conveyed by acoustic cues. We therefore propose Paralinguistics-enhanced Generative Pretrained Transformer (ParalinGPT), an LLM that utilizes text and speech modalities to better model the linguistic content and paralinguistic attributes of spoken dialogue. The model takes the conversational context of text, speech embeddings, and paralinguistic attributes as input prompts within a serialized multitasking multimodal framework. Specifically, our framework serializes tasks in the order of current paralinguistic attribute prediction, response paralinguistic attribute prediction, and response text generation with autoregressive conditioning. We utilize the Switchboard-1 corpus, including its sentiment labels as the paralinguistic attribute, as our spoken dialogue dataset. Experimental results indicate the proposed serialized multitasking method outperforms typical sequence classification techniques on current and response sentiment classification. Furthermore, leveraging conversational context and speech embeddings significantly improves both response text generation and sentiment prediction. Our proposed framework achieves relative improvements of 6.7%, 12.0%, and 3.5% in current sentiment accuracy, response sentiment accuracy, and response text BLEU score, respectively.
Acoustic models of Brazilian Portuguese Speech based on Neural Transformers
Dec 14, 2023An acoustic model, trained on a significant amount of unlabeled data, consists of a self-supervised learned speech representation useful for solving downstream tasks, perhaps after a fine-tuning of the model in the respective downstream task. In this work, we build an acoustic model of Brazilian Portuguese Speech through a Transformer neural network. This model was pretrained on more than $800$ hours of Brazilian Portuguese Speech, using a combination of pretraining techniques. Using a labeled dataset collected for the detection of respiratory insufficiency in Brazilian Portuguese speakers, we fine-tune the pretrained Transformer neural network on the following tasks: respiratory insufficiency detection, gender recognition and age group classification. We compare the performance of pretrained Transformers on these tasks with that of Transformers without previous pretraining, noting a significant improvement. In particular, the performance of respiratory insufficiency detection obtains the best reported results so far, indicating this kind of acoustic model as a promising tool for speech-as-biomarker approach. Moreover, the performance of gender recognition is comparable to the state of the art models in English.
Decoding Envelope and Frequency-Following EEG Responses to Continuous Speech Using Deep Neural Networks
Dec 15, 2023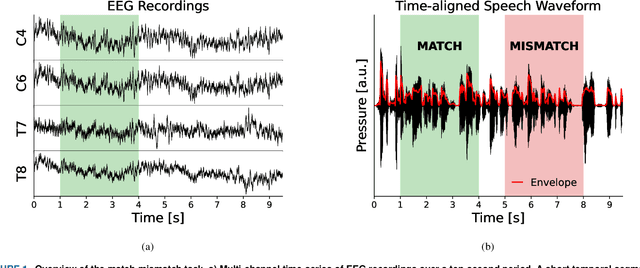
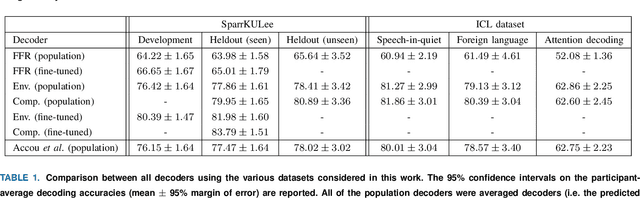
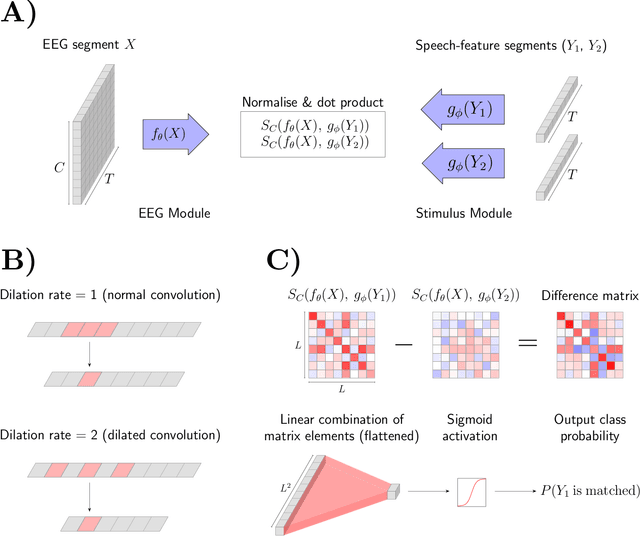
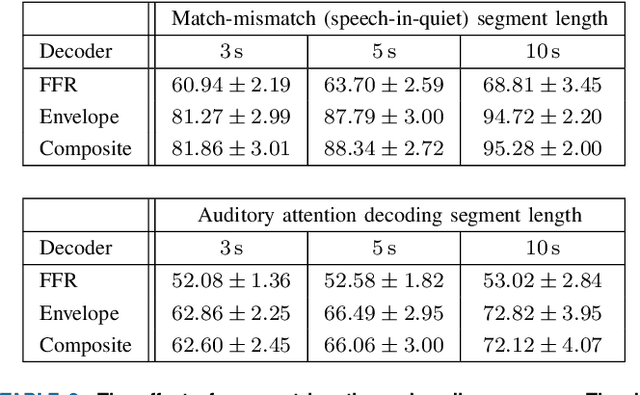
The electroencephalogram (EEG) offers a non-invasive means by which a listener's auditory system may be monitored during continuous speech perception. Reliable auditory-EEG decoders could facilitate the objective diagnosis of hearing disorders, or find applications in cognitively-steered hearing aids. Previously, we developed decoders for the ICASSP Auditory EEG Signal Processing Grand Challenge (SPGC). These decoders aimed to solve the match-mismatch task: given a short temporal segment of EEG recordings, and two candidate speech segments, the task is to identify which of the two speech segments is temporally aligned, or matched, with the EEG segment. The decoders made use of cortical responses to the speech envelope, as well as speech-related frequency-following responses, to relate the EEG recordings to the speech stimuli. Here we comprehensively document the methods by which the decoders were developed. We extend our previous analysis by exploring the association between speaker characteristics (pitch and sex) and classification accuracy, and provide a full statistical analysis of the final performance of the decoders as evaluated on a heldout portion of the dataset. Finally, the generalisation capabilities of the decoders are characterised, by evaluating them using an entirely different dataset which contains EEG recorded under a variety of speech-listening conditions. The results show that the match-mismatch decoders achieve accurate and robust classification accuracies, and they can even serve as auditory attention decoders without additional training.
Multimodal Attention Merging for Improved Speech Recognition and Audio Event Classification
Dec 22, 2023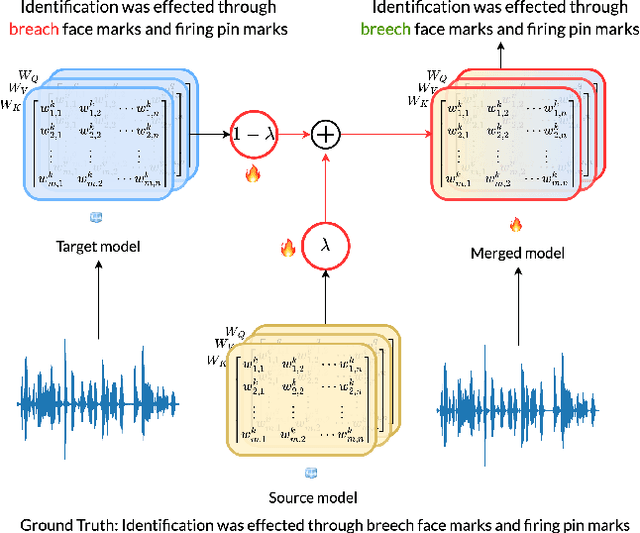
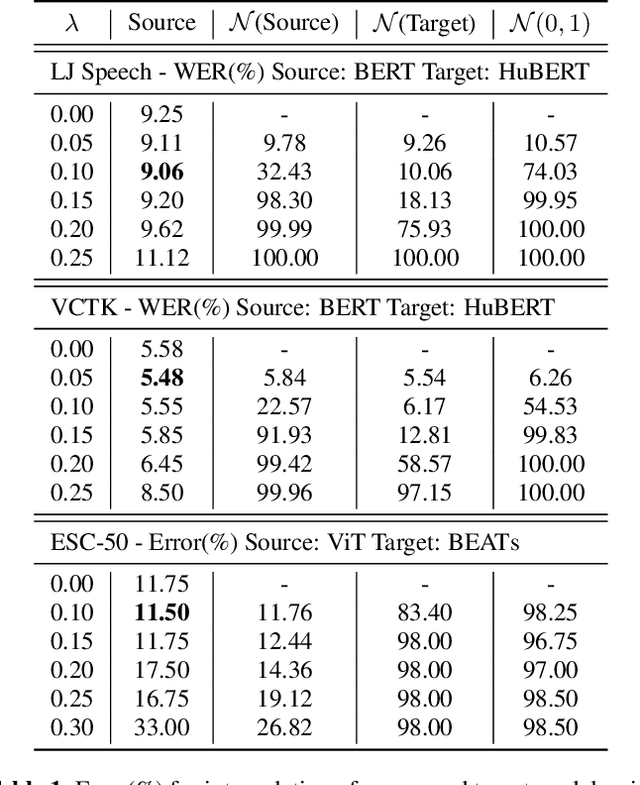
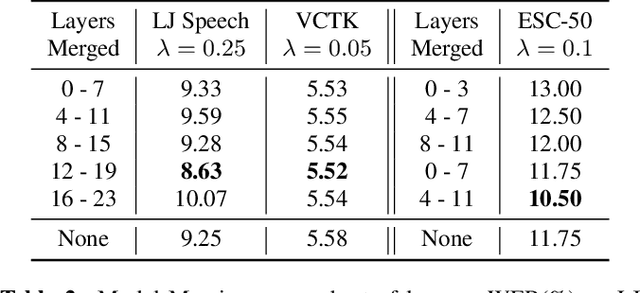
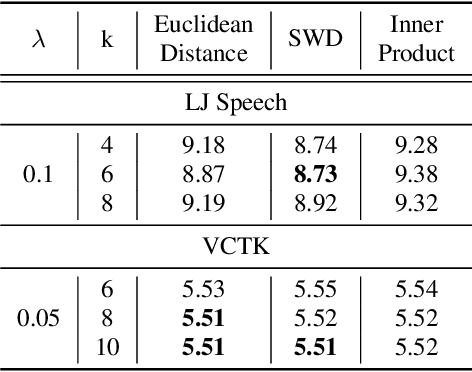
Training large foundation models using self-supervised objectives on unlabeled data, followed by fine-tuning on downstream tasks, has emerged as a standard procedure. Unfortunately, the efficacy of this approach is often constrained by both limited fine-tuning compute and scarcity in labeled downstream data. We introduce Multimodal Attention Merging (MAM), an attempt that facilitates direct knowledge transfer from attention matrices of models rooted in high resource modalities, text and images, to those in resource-constrained domains, speech and audio, employing a zero-shot paradigm. MAM reduces the relative Word Error Rate (WER) of an Automatic Speech Recognition (ASR) model by up to 6.70%, and relative classification error of an Audio Event Classification (AEC) model by 10.63%. In cases where some data/compute is available, we present Learnable-MAM, a data-driven approach to merging attention matrices, resulting in a further 2.90% relative reduction in WER for ASR and 18.42% relative reduction in AEC compared to fine-tuning.
Large Language Models for Multi-Modal Human-Robot Interaction
Jan 26, 2024This paper presents an innovative large language model (LLM)-based robotic system for enhancing multi-modal human-robot interaction (HRI). Traditional HRI systems relied on complex designs for intent estimation, reasoning, and behavior generation, which were resource-intensive. In contrast, our system empowers researchers and practitioners to regulate robot behavior through three key aspects: providing high-level linguistic guidance, creating "atomics" for actions and expressions the robot can use, and offering a set of examples. Implemented on a physical robot, it demonstrates proficiency in adapting to multi-modal inputs and determining the appropriate manner of action to assist humans with its arms, following researchers' defined guidelines. Simultaneously, it coordinates the robot's lid, neck, and ear movements with speech output to produce dynamic, multi-modal expressions. This showcases the system's potential to revolutionize HRI by shifting from conventional, manual state-and-flow design methods to an intuitive, guidance-based, and example-driven approach.