 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
The Phonetic Footprint of Parkinson's Disease
Dec 21, 2021

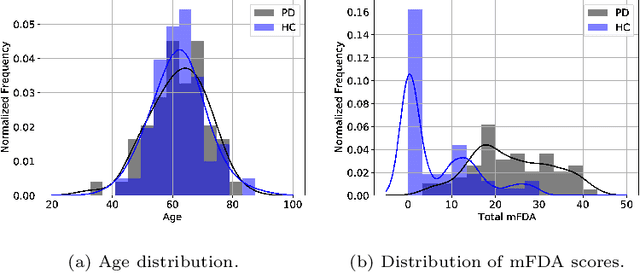
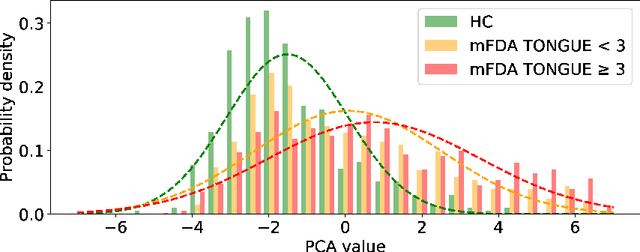
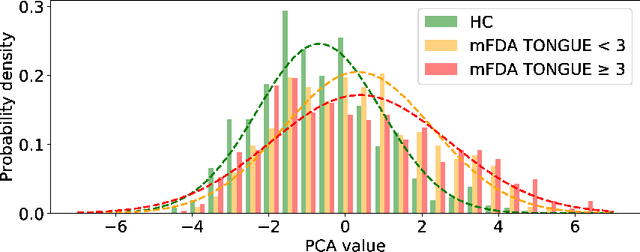
As one of the most prevalent neurodegenerative disorders, Parkinson's disease (PD) has a significant impact on the fine motor skills of patients. The complex interplay of different articulators during speech production and realization of required muscle tension become increasingly difficult, thus leading to a dysarthric speech. Characteristic patterns such as vowel instability, slurred pronunciation and slow speech can often be observed in the affected individuals and were analyzed in previous studies to determine the presence and progression of PD. In this work, we used a phonetic recognizer trained exclusively on healthy speech data to investigate how PD affected the phonetic footprint of patients. We rediscovered numerous patterns that had been described in previous contributions although our system had never seen any pathological speech previously. Furthermore, we could show that intermediate activations from the neural network could serve as feature vectors encoding information related to the disease state of individuals. We were also able to directly correlate the expert-rated intelligibility of a speaker with the mean confidence of phonetic predictions. Our results support the assumption that pathological data is not necessarily required to train systems that are capable of analyzing PD speech.
* https://www.sciencedirect.com/science/article/abs/pii/S0885230821001169
AraCOVID19-MFH: Arabic COVID-19 Multi-label Fake News and Hate Speech Detection Dataset
May 07, 2021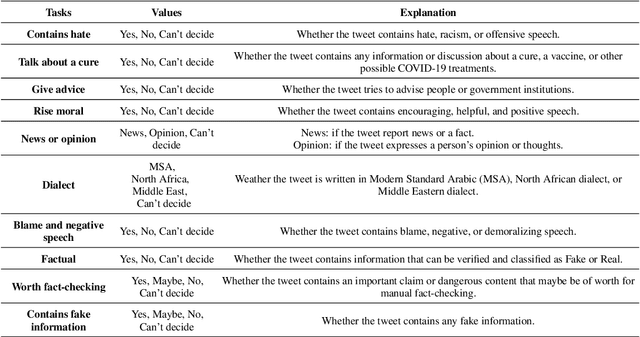
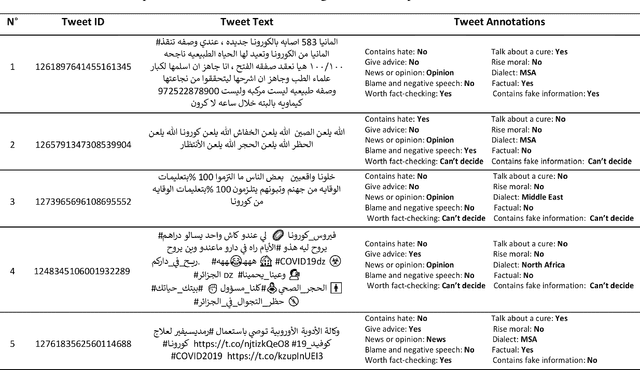

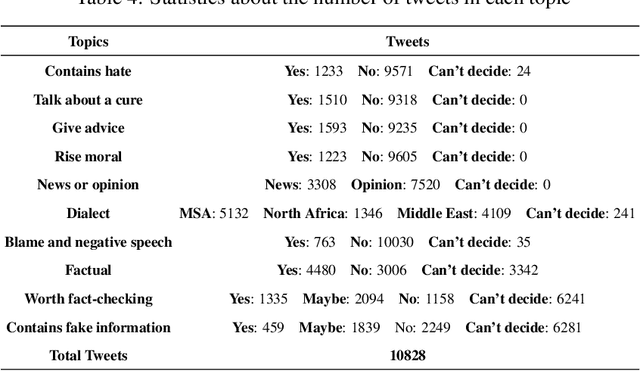
Along with the COVID-19 pandemic, an "infodemic" of false and misleading information has emerged and has complicated the COVID-19 response efforts. Social networking sites such as Facebook and Twitter have contributed largely to the spread of rumors, conspiracy theories, hate, xenophobia, racism, and prejudice. To combat the spread of fake news, researchers around the world have and are still making considerable efforts to build and share COVID-19 related research articles, models, and datasets. This paper releases "AraCOVID19-MFH" a manually annotated multi-label Arabic COVID-19 fake news and hate speech detection dataset. Our dataset contains 10,828 Arabic tweets annotated with 10 different labels. The labels have been designed to consider some aspects relevant to the fact-checking task, such as the tweet's check worthiness, positivity/negativity, and factuality. To confirm our annotated dataset's practical utility, we used it to train and evaluate several classification models and reported the obtained results. Though the dataset is mainly designed for fake news detection, it can also be used for hate speech detection, opinion/news classification, dialect identification, and many other tasks.
Open Range Pitch Tracking for Carrier Frequency Difference Estimation from HF Transmitted Speech
Mar 03, 2021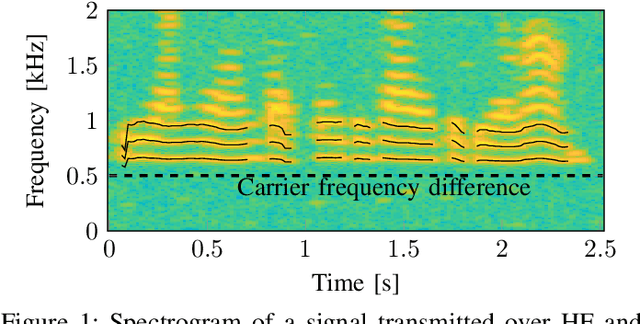
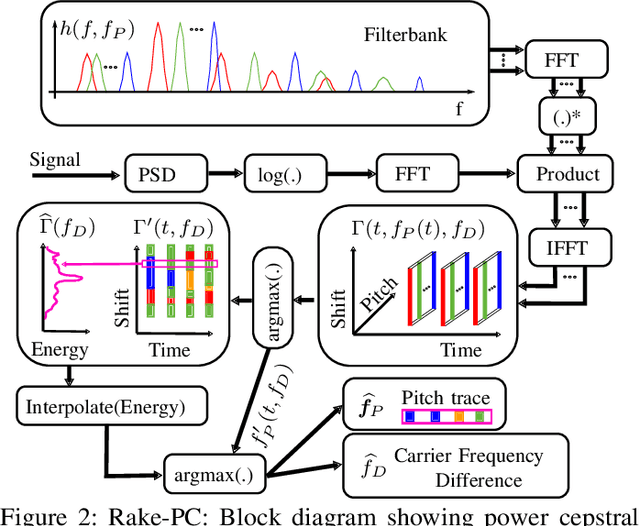
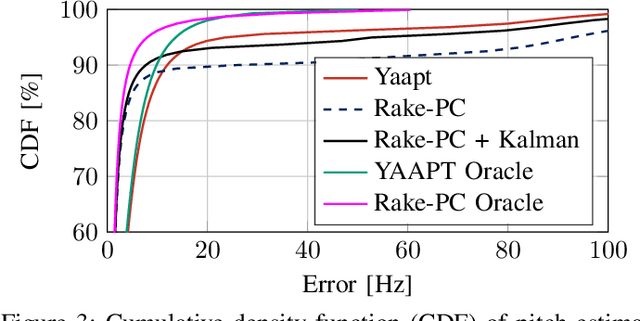
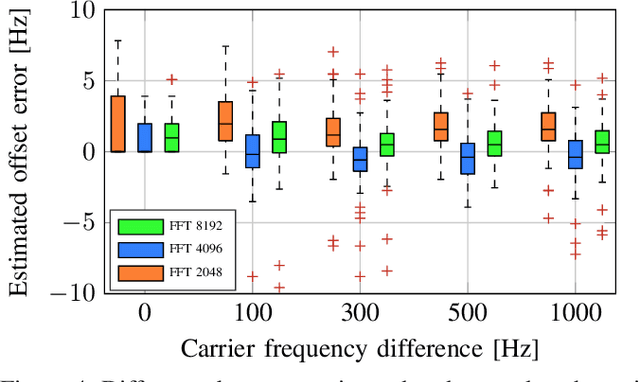
In this paper we investigate the task of detecting carrier frequency differences from demodulated single sideband signals by examining the pitch contours of the received baseband speech signal in the short-time spectral domain. From the detected pitch frequency trajectory and its harmonics a carrier frequency difference, which is caused by demodulating the radio signal with the wrong carrier frequency, can be deduced. A computationally efficient realization in the power cepstral domain is presented. The core component, i.e., the pitch tracking algorithm, is shown to perform comparably to a state of the art algorithm. The full carrier frequency difference estimation system is tested on recordings of real transmissions over HF links. A comparison with an existing approach shows improved estimation accuracy, both on short and longer speech utterances
R-MelNet: Reduced Mel-Spectral Modeling for Neural TTS
Jun 30, 2022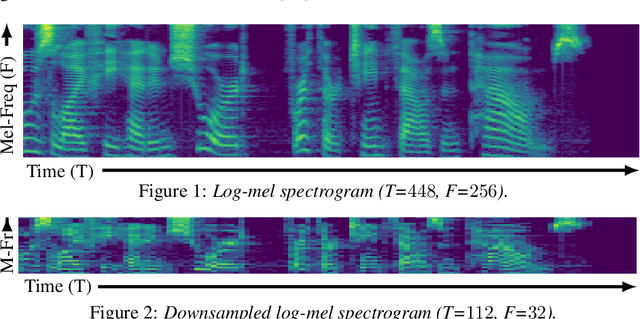
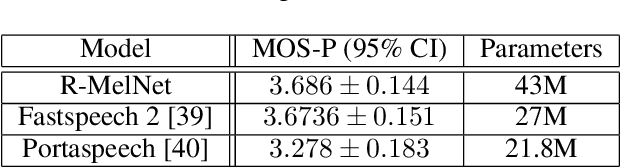
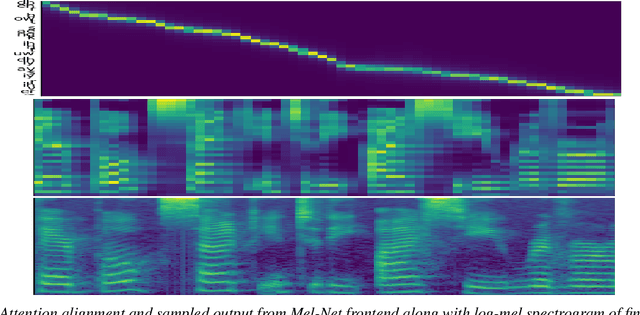

This paper introduces R-MelNet, a two-part autoregressive architecture with a frontend based on the first tier of MelNet and a backend WaveRNN-style audio decoder for neural text-to-speech synthesis. Taking as input a mixed sequence of characters and phonemes, with an optional audio priming sequence, this model produces low-resolution mel-spectral features which are interpolated and used by a WaveRNN decoder to produce an audio waveform. Coupled with half precision training, R-MelNet uses under 11 gigabytes of GPU memory on a single commodity GPU (NVIDIA 2080Ti). We detail a number of critical implementation details for stable half precision training, including an approximate, numerically stable mixture of logistics attention. Using a stochastic, multi-sample per step inference scheme, the resulting model generates highly varied audio, while enabling text and audio based controls to modify output waveforms. Qualitative and quantitative evaluations of an R-MelNet system trained on a single speaker TTS dataset demonstrate the effectiveness of our approach.
More for Less: Non-Intrusive Speech Quality Assessment with Limited Annotations
Aug 19, 2021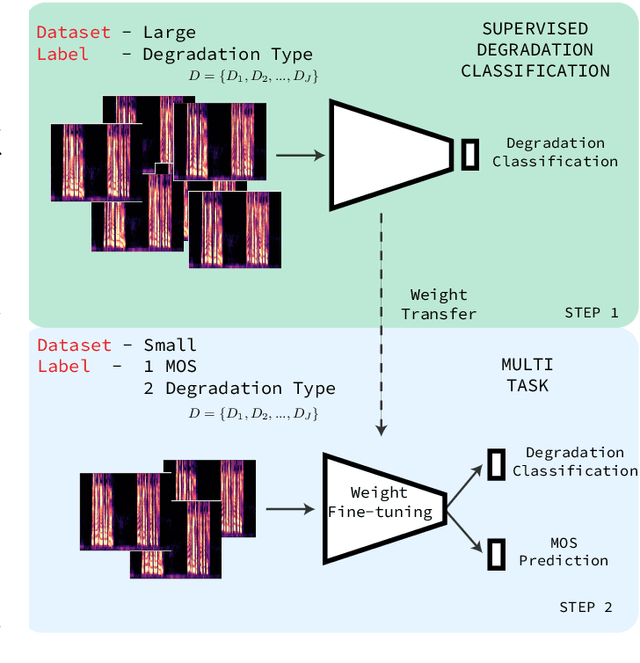
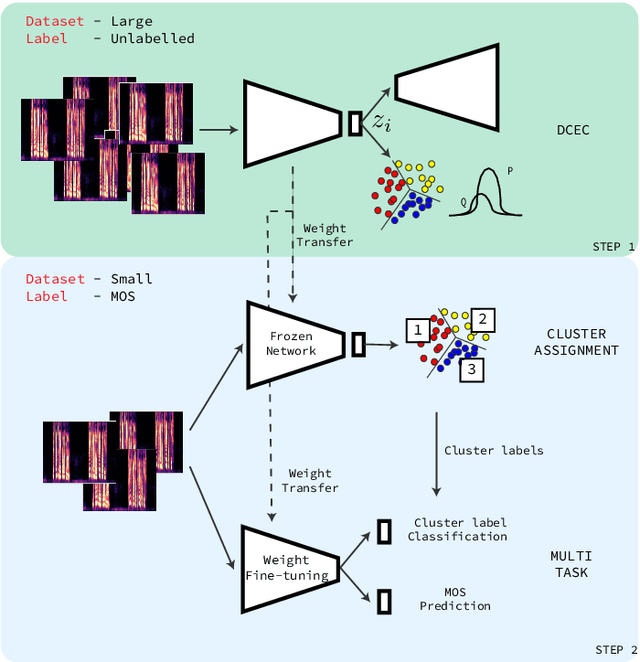
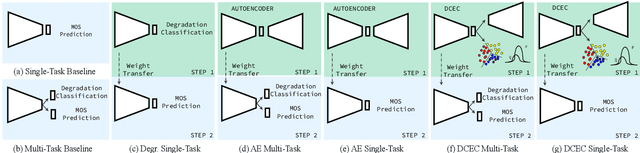
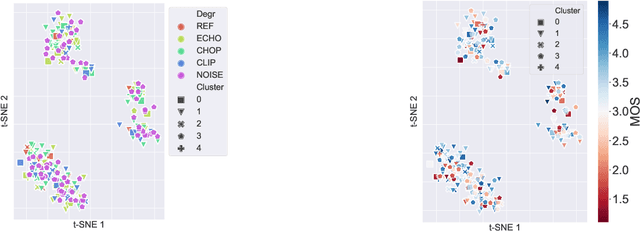
Non-intrusive speech quality assessment is a crucial operation in multimedia applications. The scarcity of annotated data and the lack of a reference signal represent some of the main challenges for designing efficient quality assessment metrics. In this paper, we propose two multi-task models to tackle the problems above. In the first model, we first learn a feature representation with a degradation classifier on a large dataset. Then we perform MOS prediction and degradation classification simultaneously on a small dataset annotated with MOS. In the second approach, the initial stage consists of learning features with a deep clustering-based unsupervised feature representation on the large dataset. Next, we perform MOS prediction and cluster label classification simultaneously on a small dataset. The results show that the deep clustering-based model outperforms the degradation classifier-based model and the 3 baselines (autoencoder features, P.563, and SRMRnorm) on TCD-VoIP. This paper indicates that multi-task learning combined with feature representations from unlabelled data is a promising approach to deal with the lack of large MOS annotated datasets.
Stuttering Speech Disfluency Prediction using Explainable Attribution Vectors of Facial Muscle Movements
Oct 02, 2020


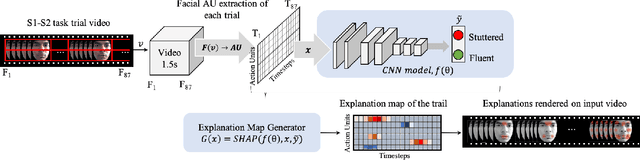
Speech disorders such as stuttering disrupt the normal fluency of speech by involuntary repetitions, prolongations and blocking of sounds and syllables. In addition to these disruptions to speech fluency, most adults who stutter (AWS) also experience numerous observable secondary behaviors before, during, and after a stuttering moment, often involving the facial muscles. Recent studies have explored automatic detection of stuttering using Artificial Intelligence (AI) based algorithm from respiratory rate, audio, etc. during speech utterance. However, most methods require controlled environments and/or invasive wearable sensors, and are unable explain why a decision (fluent vs stuttered) was made. We hypothesize that pre-speech facial activity in AWS, which can be captured non-invasively, contains enough information to accurately classify the upcoming utterance as either fluent or stuttered. Towards this end, this paper proposes a novel explainable AI (XAI) assisted convolutional neural network (CNN) classifier to predict near future stuttering by learning temporal facial muscle movement patterns of AWS and explains the important facial muscles and actions involved. Statistical analyses reveal significantly high prevalence of cheek muscles (p<0.005) and lip muscles (p<0.005) to predict stuttering and shows a behavior conducive of arousal and anticipation to speak. The temporal study of these upper and lower facial muscles may facilitate early detection of stuttering, promote automated assessment of stuttering and have application in behavioral therapies by providing automatic non-invasive feedback in realtime.
Dialogue Enhancement and Listening Effort in Broadcast Audio: A Multimodal Evaluation
Aug 03, 2022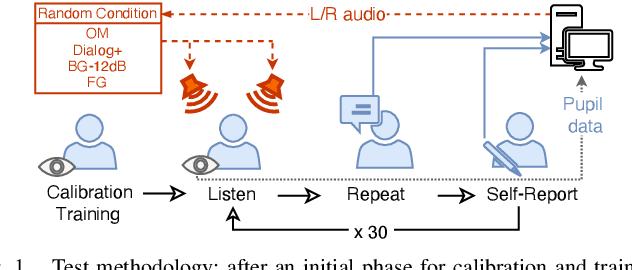
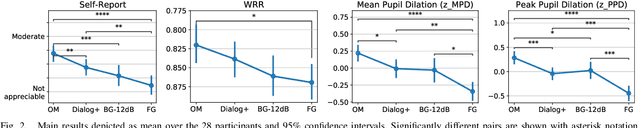
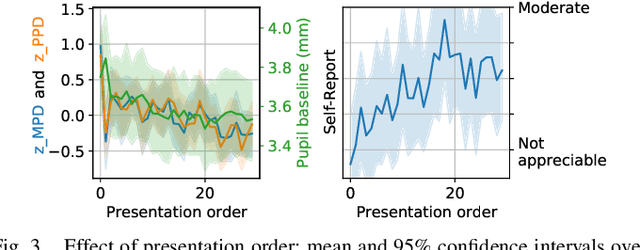
Dialogue enhancement (DE) plays a vital role in broadcasting, enabling the personalization of the relative level between foreground speech and background music and effects. DE has been shown to improve the quality of experience, intelligibility, and self-reported listening effort (LE). A physiological indicator of LE known from audiology studies is pupil size. The relation between pupil size and LE is typically studied using artificial sentences and background noises not encountered in broadcast content. This work evaluates the effect of DE on LE in a multimodal manner that includes pupil size (tracked by a VR headset) and real-world audio excerpts from TV. Under ideal listening conditions, 28 normal-hearing participants listened to 30 audio excerpts presented in random order and processed by conditions varying the relative level between foreground and background audio. One of these conditions employed a recently proposed source separation system to attenuate the background given the original mixture as the sole input. After listening to each excerpt, subjects were asked to repeat the heard sentence and self-report the LE. Mean pupil dilation and peak pupil dilation were analyzed and compared with the self-report and the word recall rate. The multimodal evaluation shows a consistent trend of decreasing LE along with decreasing background level. DE, also when enabled by source separation, significantly reduces the pupil size as well as the self-reported LE. This highlights the benefit of personalization functionalities at the user's end.
Characterizing Speech Adversarial Examples Using Self-Attention U-Net Enhancement
Mar 31, 2020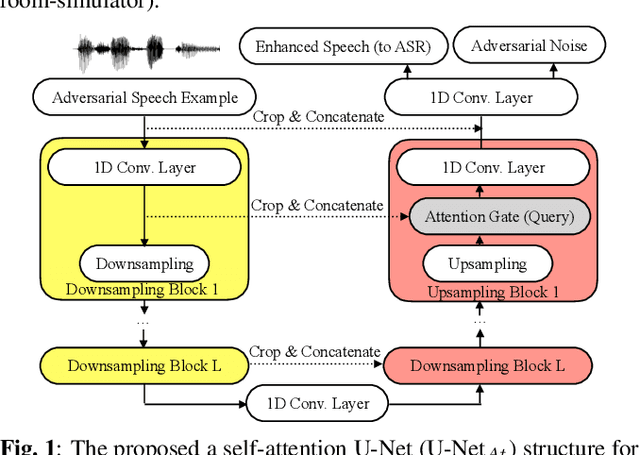
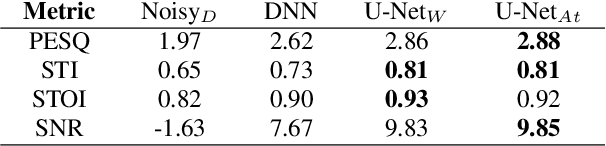
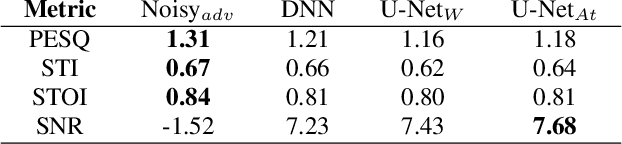
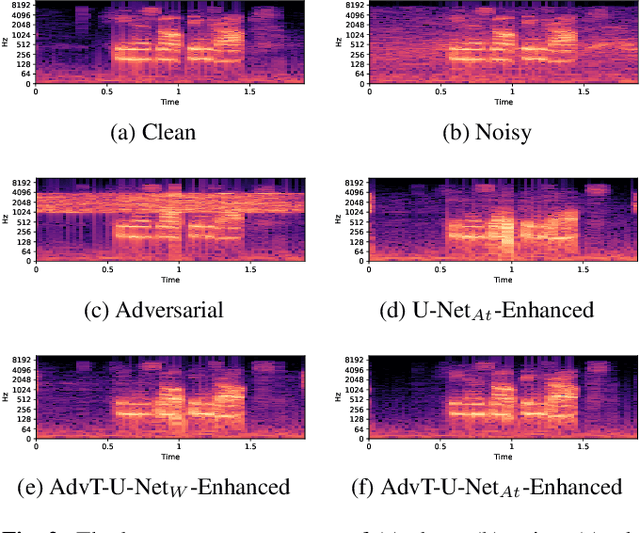
Recent studies have highlighted adversarial examples as ubiquitous threats to the deep neural network (DNN) based speech recognition systems. In this work, we present a U-Net based attention model, U-Net$_{At}$, to enhance adversarial speech signals. Specifically, we evaluate the model performance by interpretable speech recognition metrics and discuss the model performance by the augmented adversarial training. Our experiments show that our proposed U-Net$_{At}$ improves the perceptual evaluation of speech quality (PESQ) from 1.13 to 2.78, speech transmission index (STI) from 0.65 to 0.75, short-term objective intelligibility (STOI) from 0.83 to 0.96 on the task of speech enhancement with adversarial speech examples. We conduct experiments on the automatic speech recognition (ASR) task with adversarial audio attacks. We find that (i) temporal features learned by the attention network are capable of enhancing the robustness of DNN based ASR models; (ii) the generalization power of DNN based ASR model could be enhanced by applying adversarial training with an additive adversarial data augmentation. The ASR metric on word-error-rates (WERs) shows that there is an absolute 2.22 $\%$ decrease under gradient-based perturbation, and an absolute 2.03 $\%$ decrease, under evolutionary-optimized perturbation, which suggests that our enhancement models with adversarial training can further secure a resilient ASR system.
Is "moby dick" a Whale or a Bird? Named Entities and Terminology in Speech Translation
Sep 15, 2021
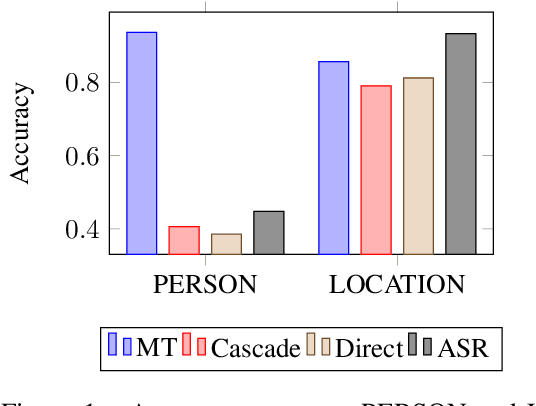

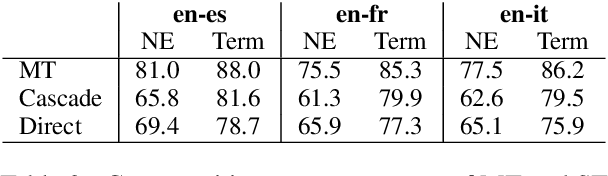
Automatic translation systems are known to struggle with rare words. Among these, named entities (NEs) and domain-specific terms are crucial, since errors in their translation can lead to severe meaning distortions. Despite their importance, previous speech translation (ST) studies have neglected them, also due to the dearth of publicly available resources tailored to their specific evaluation. To fill this gap, we i) present the first systematic analysis of the behavior of state-of-the-art ST systems in translating NEs and terminology, and ii) release NEuRoparl-ST, a novel benchmark built from European Parliament speeches annotated with NEs and terminology. Our experiments on the three language directions covered by our benchmark (en->es/fr/it) show that ST systems correctly translate 75-80% of terms and 65-70% of NEs, with very low performance (37-40%) on person names.
Integrating Text Inputs For Training and Adapting RNN Transducer ASR Models
Feb 26, 2022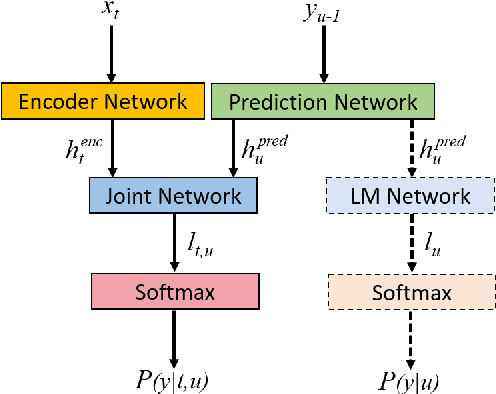
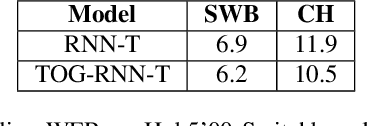
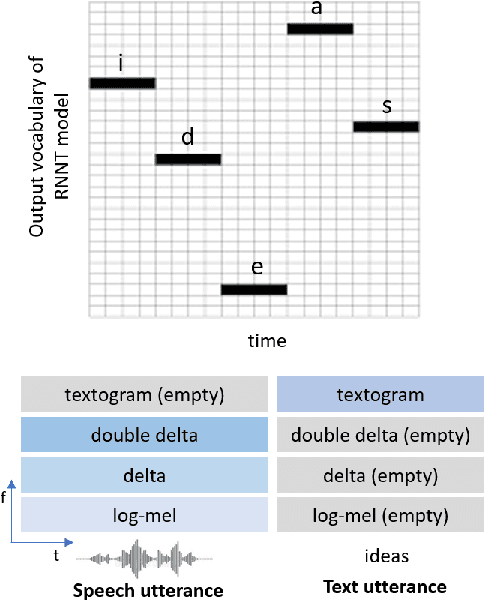
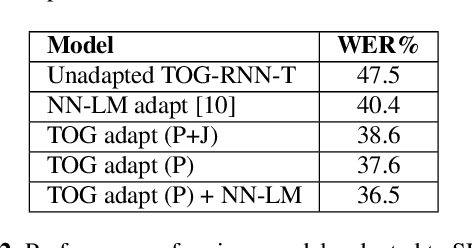
Compared to hybrid automatic speech recognition (ASR) systems that use a modular architecture in which each component can be independently adapted to a new domain, recent end-to-end (E2E) ASR system are harder to customize due to their all-neural monolithic construction. In this paper, we propose a novel text representation and training framework for E2E ASR models. With this approach, we show that a trained RNN Transducer (RNN-T) model's internal LM component can be effectively adapted with text-only data. An RNN-T model trained using both speech and text inputs improves over a baseline model trained on just speech with close to 13% word error rate (WER) reduction on the Switchboard and CallHome test sets of the NIST Hub5 2000 evaluation. The usefulness of the proposed approach is further demonstrated by customizing this general purpose RNN-T model to three separate datasets. We observe 20-45% relative word error rate (WER) reduction in these settings with this novel LM style customization technique using only unpaired text data from the new domains.