 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Open Range Pitch Tracking for Carrier Frequency Difference Estimation from HF Transmitted Speech
Mar 03, 2021
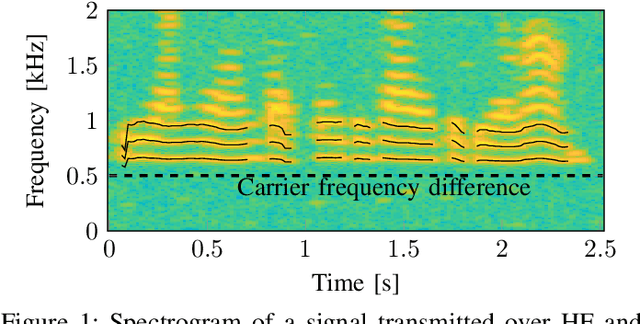
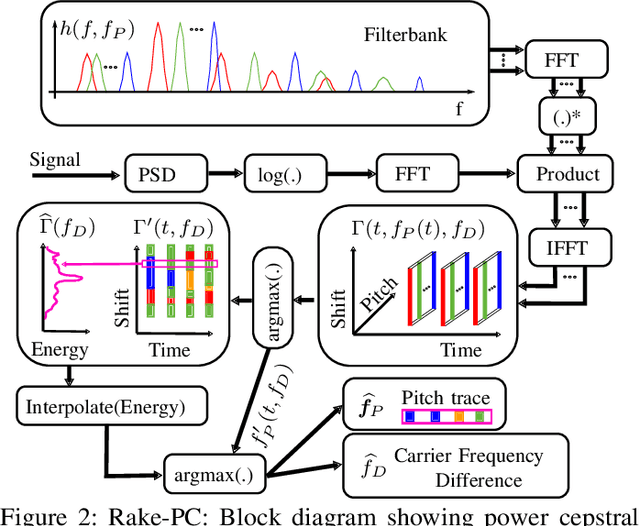
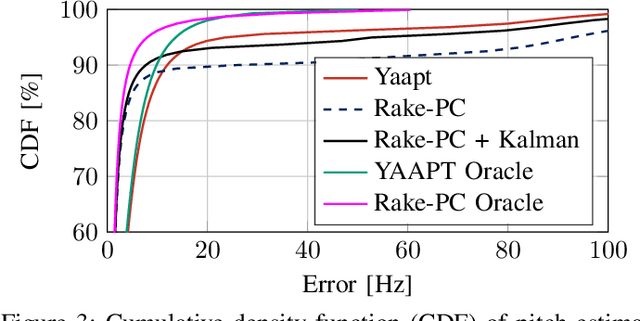
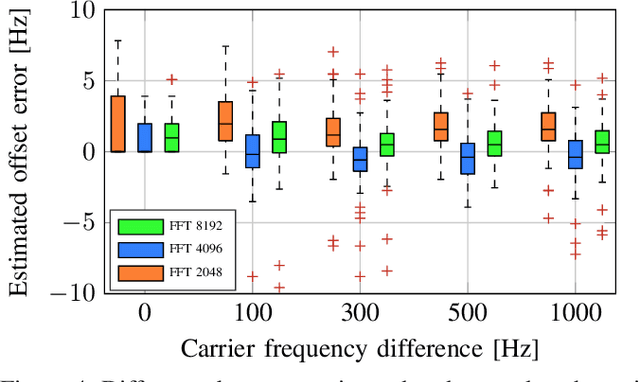
In this paper we investigate the task of detecting carrier frequency differences from demodulated single sideband signals by examining the pitch contours of the received baseband speech signal in the short-time spectral domain. From the detected pitch frequency trajectory and its harmonics a carrier frequency difference, which is caused by demodulating the radio signal with the wrong carrier frequency, can be deduced. A computationally efficient realization in the power cepstral domain is presented. The core component, i.e., the pitch tracking algorithm, is shown to perform comparably to a state of the art algorithm. The full carrier frequency difference estimation system is tested on recordings of real transmissions over HF links. A comparison with an existing approach shows improved estimation accuracy, both on short and longer speech utterances
Mixtures of Deep Neural Experts for Automated Speech Scoring
Jun 23, 2021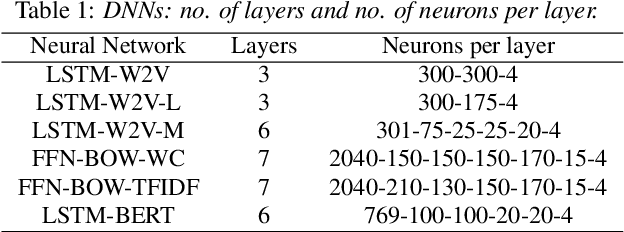
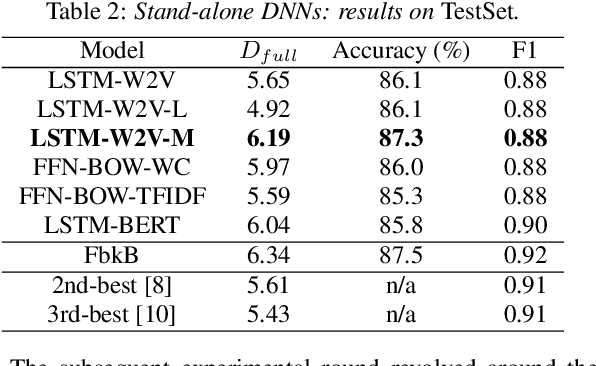
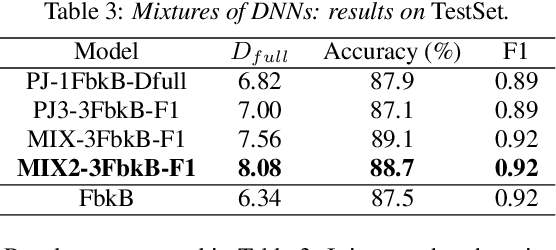
The paper copes with the task of automatic assessment of second language proficiency from the language learners' spoken responses to test prompts. The task has significant relevance to the field of computer assisted language learning. The approach presented in the paper relies on two separate modules: (1) an automatic speech recognition system that yields text transcripts of the spoken interactions involved, and (2) a multiple classifier system based on deep learners that ranks the transcripts into proficiency classes. Different deep neural network architectures (both feed-forward and recurrent) are specialized over diverse representations of the texts in terms of: a reference grammar, the outcome of probabilistic language models, several word embeddings, and two bag-of-word models. Combination of the individual classifiers is realized either via a probabilistic pseudo-joint model, or via a neural mixture of experts. Using the data of the third Spoken CALL Shared Task challenge, the highest values to date were obtained in terms of three popular evaluation metrics.
Large-vocabulary Audio-visual Speech Recognition in Noisy Environments
Sep 10, 2021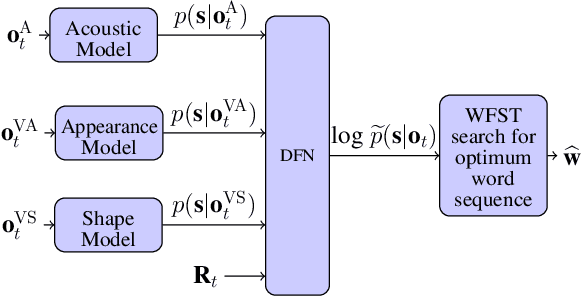
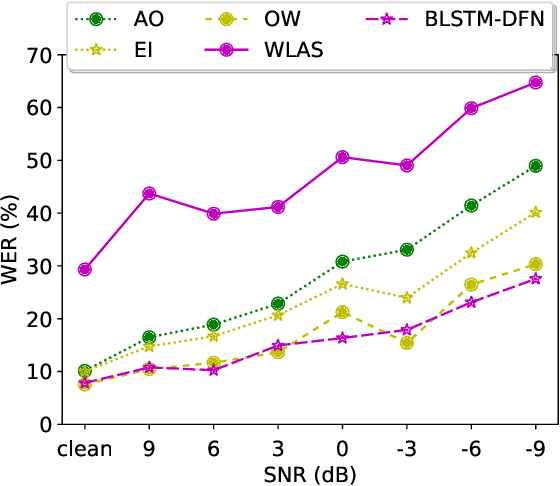

Audio-visual speech recognition (AVSR) can effectively and significantly improve the recognition rates of small-vocabulary systems, compared to their audio-only counterparts. For large-vocabulary systems, however, there are still many difficulties, such as unsatisfactory video recognition accuracies, that make it hard to improve over audio-only baselines. In this paper, we specifically consider such scenarios, focusing on the large-vocabulary task of the LRS2 database, where audio-only performance is far superior to video-only accuracies, making this an interesting and challenging setup for multi-modal integration. To address the inherent difficulties, we propose a new fusion strategy: a recurrent integration network is trained to fuse the state posteriors of multiple single-modality models, guided by a set of model-based and signal-based stream reliability measures. During decoding, this network is used for stream integration within a hybrid recognizer, where it can thus cope with the time-variant reliability and information content of its multiple feature inputs. We compare the results with end-to-end AVSR systems as well as with competitive hybrid baseline models, finding that the new fusion strategy shows superior results, on average even outperforming oracle dynamic stream weighting, which has so far marked the -- realistically unachievable -- upper bound for standard stream weighting. Even though the pure lipreading performance is low, audio-visual integration is helpful under all -- clean, noisy, and reverberant -- conditions. On average, the new system achieves a relative word error rate reduction of 42.18\% compared to the audio-only model, pointing at a high effectiveness of the proposed integration approach.
Attention-based Neural Beamforming Layers for Multi-channel Speech Recognition
May 14, 2021

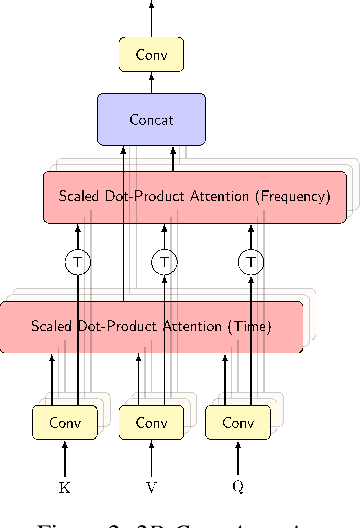

Attention-based beamformers have recently been shown to be effective for multi-channel speech recognition. However, they are less capable at capturing local information. In this work, we propose a 2D Conv-Attention module which combines convolution neural networks with attention for beamforming. We apply self- and cross-attention to explicitly model the correlations within and between the input channels. The end-to-end 2D Conv-Attention model is compared with a multi-head self-attention and superdirective-based neural beamformers. We train and evaluate on an in-house multi-channel dataset. The results show a relative improvement of 3.8% in WER by the proposed model over the baseline neural beamformer.
Punctuation Restoration in Spanish Customer Support Transcripts using Transfer Learning
May 27, 2022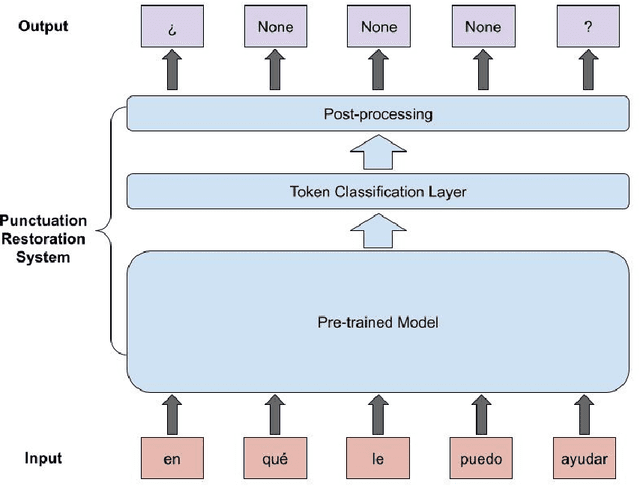
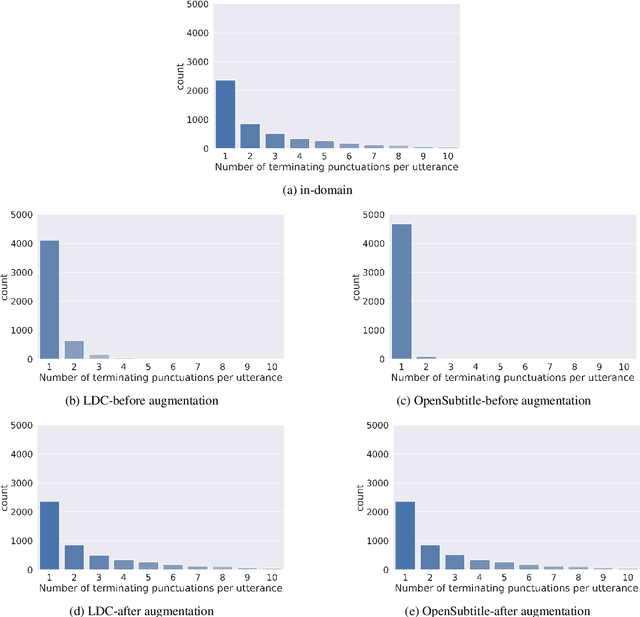

Automatic Speech Recognition (ASR) systems typically produce unpunctuated transcripts that have poor readability. In addition, building a punctuation restoration system is challenging for low-resource languages, especially for domain-specific applications. In this paper, we propose a Spanish punctuation restoration system designed for a real-time customer support transcription service. To address the data sparsity of Spanish transcripts in the customer support domain, we introduce two transfer-learning-based strategies: 1) domain adaptation using out-of-domain Spanish text data; 2) cross-lingual transfer learning leveraging in-domain English transcript data. Our experiment results show that these strategies improve the accuracy of the Spanish punctuation restoration system.
The MSXF TTS System for ICASSP 2022 ADD Challenge
Jan 27, 2022
This paper presents our MSXF TTS system for Task 3.1 of the Audio Deep Synthesis Detection (ADD) Challenge 2022. We use an end to end text to speech system, and add a constraint loss to the system when training stage. The end to end TTS system is VITS, and the pre-training self-supervised model is wav2vec 2.0. And we also explore the influence of the speech speed and volume in spoofing. The faster speech means the less the silence part in audio, the easier to fool the detector. We also find the smaller the volume, the better spoofing ability, though we normalize volume for submission. Our team is identified as C2, and we got the fourth place in the challenge.
Continuous Speech Recognition using EEG and Video
Dec 24, 2019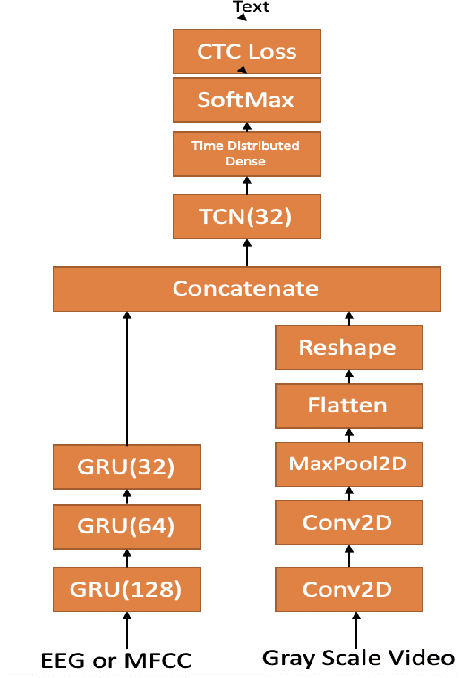
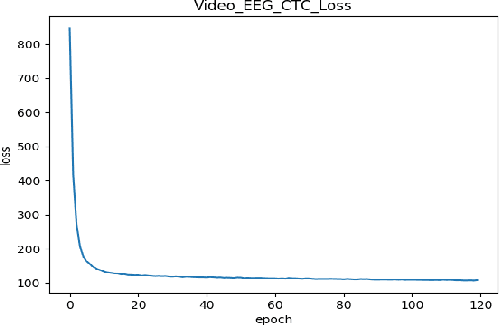
In this paper we investigate whether electroencephalography (EEG) features can be used to improve the performance of continuous visual speech recognition systems. We implemented a connectionist temporal classification (CTC) based end-to-end automatic speech recognition (ASR) model for performing recognition. Our results demonstrate that EEG features are helpful in enhancing the performance of continuous visual speech recognition systems.
Does Speech enhancement of publicly available data help build robust Speech Recognition Systems?
Oct 29, 2019
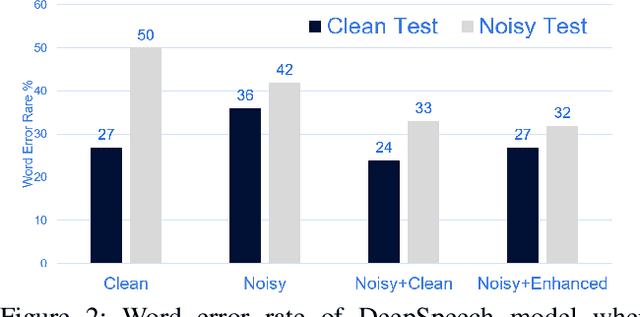
Automatic speech recognition (ASR) systems play a key role in many commercial products including voice assistants. Typically, they require large amounts of clean speech data for training which gives an undue advantage to large organizations which have tons of private data. In this paper, we have first curated a fairly big dataset using publicly available data sources. Thereafter, we tried to investigate if we can use publicly available noisy data to train robust ASR systems. We have used speech enhancement to clean the noisy data first and then used it together with its cleaned version to train ASR systems. We have found that using speech enhancement gives 9.5\% better word error rate than training on just noisy data and 9\% better than training on just clean data. It's performance is also comparable to the ideal case scenario when trained on noisy and its clean version.
Recent improvements of ASR models in the face of adversarial attacks
Apr 04, 2022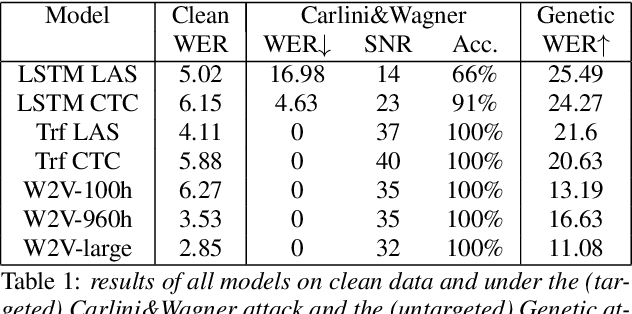
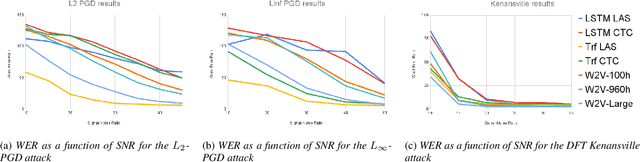
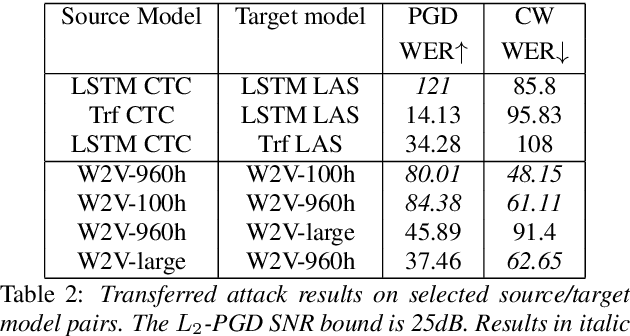
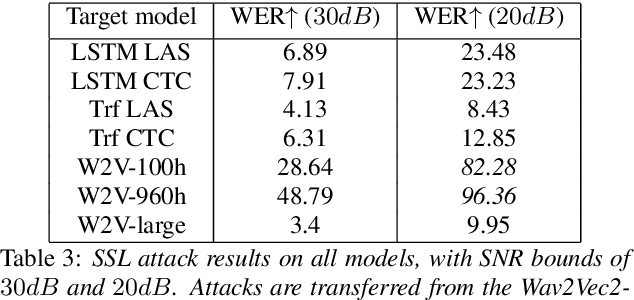
Like many other tasks involving neural networks, Speech Recognition models are vulnerable to adversarial attacks. However recent research has pointed out differences between attacks and defenses on ASR models compared to image models. Improving the robustness of ASR models requires a paradigm shift from evaluating attacks on one or a few models to a systemic approach in evaluation. We lay the ground for such research by evaluating on various architectures a representative set of adversarial attacks: targeted and untargeted, optimization and speech processing-based, white-box, black-box and targeted attacks. Our results show that the relative strengths of different attack algorithms vary considerably when changing the model architecture, and that the results of some attacks are not to be blindly trusted. They also indicate that training choices such as self-supervised pretraining can significantly impact robustness by enabling transferable perturbations. We release our source code as a package that should help future research in evaluating their attacks and defenses.
Mondegreen: A Post-Processing Solution to Speech Recognition Error Correction for Voice Search Queries
May 20, 2021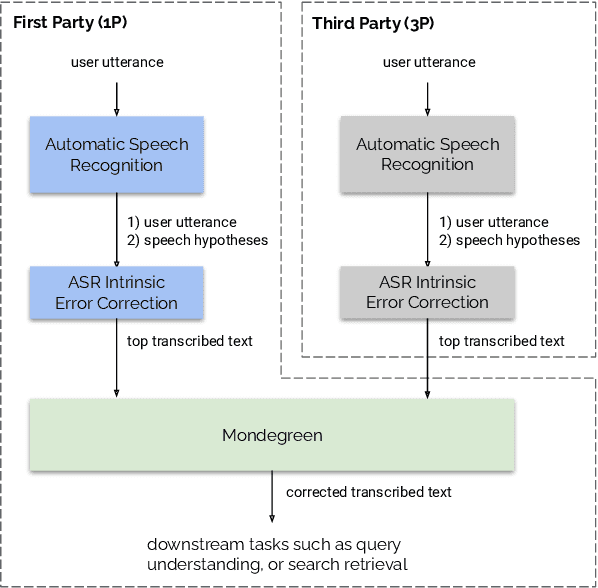
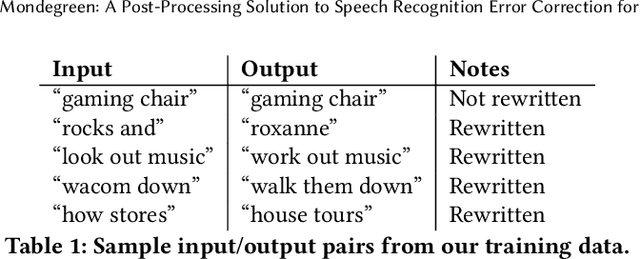
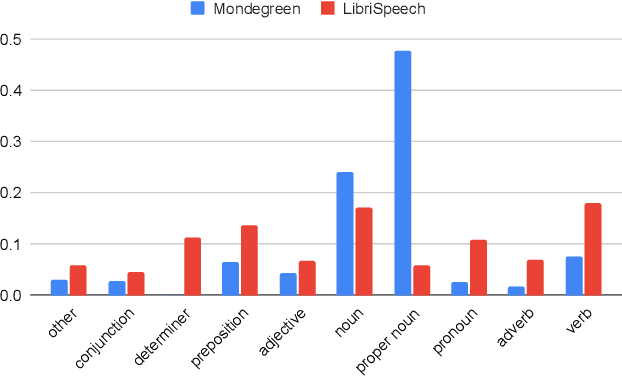
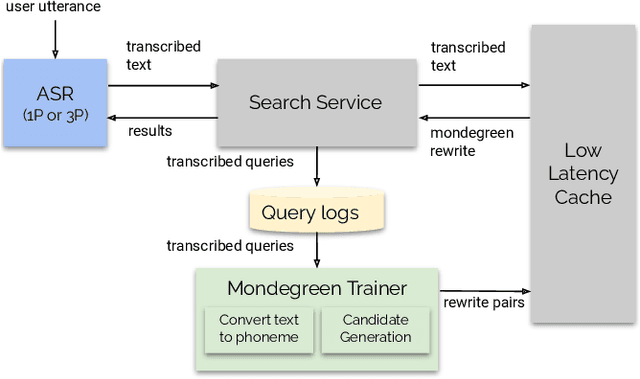
As more and more online search queries come from voice, automatic speech recognition becomes a key component to deliver relevant search results. Errors introduced by automatic speech recognition (ASR) lead to irrelevant search results returned to the user, thus causing user dissatisfaction. In this paper, we introduce an approach, Mondegreen, to correct voice queries in text space without depending on audio signals, which may not always be available due to system constraints or privacy or bandwidth (for example, some ASR systems run on-device) considerations. We focus on voice queries transcribed via several proprietary commercial ASR systems. These queries come from users making internet, or online service search queries. We first present an analysis showing how different the language distribution coming from user voice queries is from that in traditional text corpora used to train off-the-shelf ASR systems. We then demonstrate that Mondegreen can achieve significant improvements in increased user interaction by correcting user voice queries in one of the largest search systems in Google. Finally, we see Mondegreen as complementing existing highly-optimized production ASR systems, which may not be frequently retrained and thus lag behind due to vocabulary drifts.