 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speech to Text Adaptation: Towards an Efficient Cross-Modal Distillation
May 17, 2020
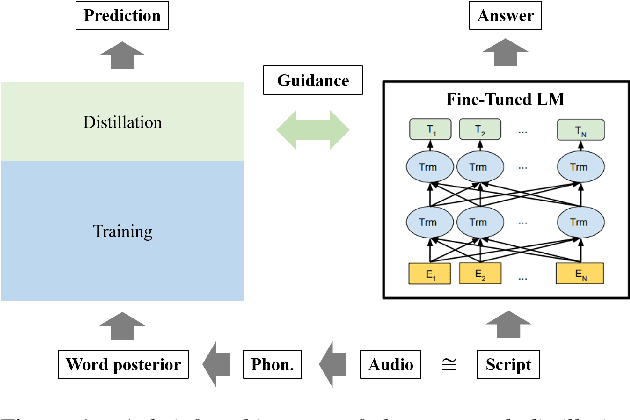
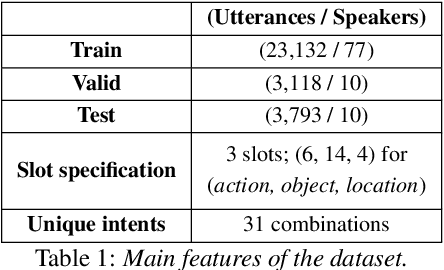
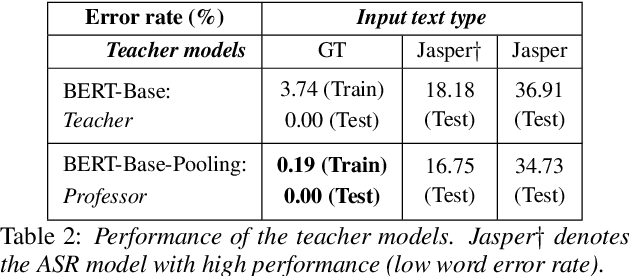
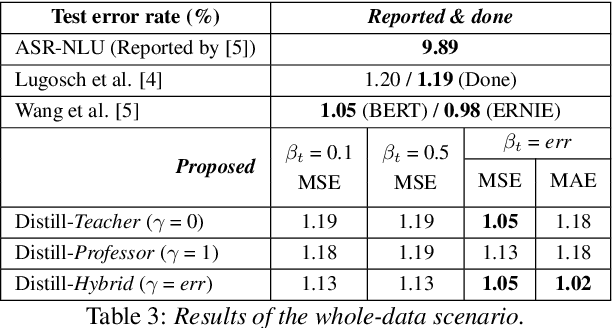
Speech is one of the most effective means of communication and is full of information that helps the transmission of utterer's thoughts. However, mainly due to the cumbersome processing of acoustic features, phoneme or word posterior probability has frequently been discarded in understanding the natural language. Thus, some recent spoken language understanding (SLU) modules have utilized an end-to-end structure that preserves the uncertainty information. This further reduces the propagation of speech recognition error and guarantees computational efficiency. We claim that in this process, the speech comprehension can benefit from the inference of massive pre-trained language models (LMs). We transfer the knowledge from a concrete Transformer-based text LM to an SLU module which can face a data shortage, based on recent cross-modal distillation methodologies. We demonstrate the validity of our proposal upon the performance on the Fluent Speech Command dataset. Thereby, we experimentally verify our hypothesis that the knowledge could be shared from the top layer of the LM to a fully speech-based module, in which the abstracted speech is expected to meet the semantic representation.
Self-Attention Channel Combinator Frontend for End-to-End Multichannel Far-field Speech Recognition
Sep 10, 2021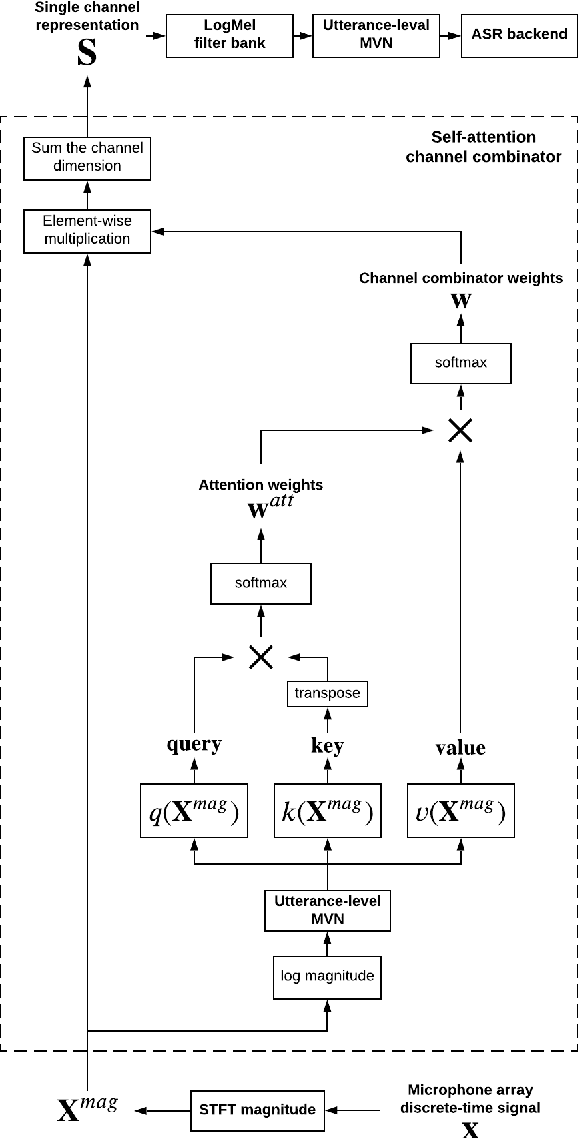
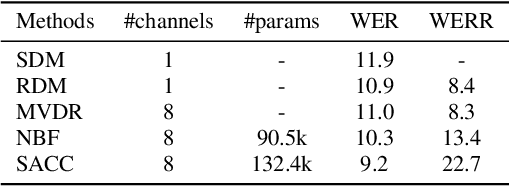
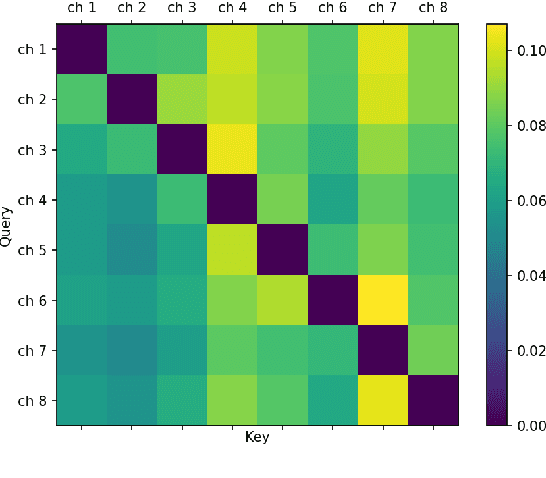
When a sufficiently large far-field training data is presented, jointly optimizing a multichannel frontend and an end-to-end (E2E) Automatic Speech Recognition (ASR) backend shows promising results. Recent literature has shown traditional beamformer designs, such as MVDR (Minimum Variance Distortionless Response) or fixed beamformers can be successfully integrated as the frontend into an E2E ASR system with learnable parameters. In this work, we propose the self-attention channel combinator (SACC) ASR frontend, which leverages the self-attention mechanism to combine multichannel audio signals in the magnitude spectral domain. Experiments conducted on a multichannel playback test data shows that the SACC achieved a 9.3% WERR compared to a state-of-the-art fixed beamformer-based frontend, both jointly optimized with a ContextNet-based ASR backend. We also demonstrate the connection between the SACC and the traditional beamformers, and analyze the intermediate outputs of the SACC.
L3Cube-MahaNLP: Marathi Natural Language Processing Datasets, Models, and Library
May 31, 2022Despite being the third most popular language in India, the Marathi language lacks useful NLP resources. Moreover, popular NLP libraries do not have support for the Marathi language. With L3Cube-MahaNLP, we aim to build resources and a library for Marathi natural language processing. We present datasets and transformer models for supervised tasks like sentiment analysis, named entity recognition, and hate speech detection. We have also published a monolingual Marathi corpus for unsupervised language modeling tasks. Overall we present MahaCorpus, MahaSent, MahaNER, and MahaHate datasets and their corresponding MahaBERT models fine-tuned on these datasets. We aim to move ahead of benchmark datasets and prepare useful resources for Marathi. The resources are available at https://github.com/l3cube-pune/MarathiNLP.
SAQAM: Spatial Audio Quality Assessment Metric
Jun 24, 2022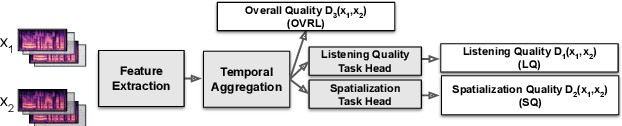

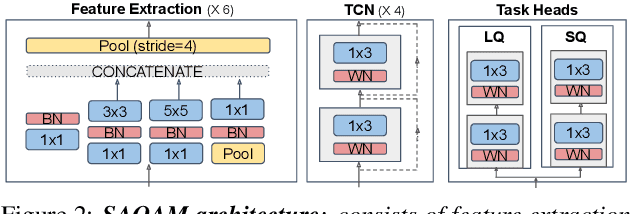

Audio quality assessment is critical for assessing the perceptual realism of sounds. However, the time and expense of obtaining ''gold standard'' human judgments limit the availability of such data. For AR&VR, good perceived sound quality and localizability of sources are among the key elements to ensure complete immersion of the user. Our work introduces SAQAM which uses a multi-task learning framework to assess listening quality (LQ) and spatialization quality (SQ) between any given pair of binaural signals without using any subjective data. We model LQ by training on a simulated dataset of triplet human judgments, and SQ by utilizing activation-level distances from networks trained for direction of arrival (DOA) estimation. We show that SAQAM correlates well with human responses across four diverse datasets. Since it is a deep network, the metric is differentiable, making it suitable as a loss function for other tasks. For example, simply replacing an existing loss with our metric yields improvement in a speech-enhancement network.
Utterance-by-utterance overlap-aware neural diarization with Graph-PIT
Jul 28, 2022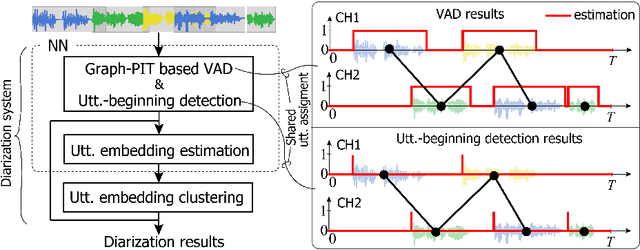
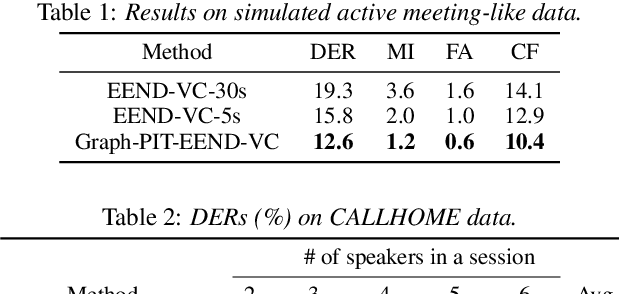
Recent speaker diarization studies showed that integration of end-to-end neural diarization (EEND) and clustering-based diarization is a promising approach for achieving state-of-the-art performance on various tasks. Such an approach first divides an observed signal into fixed-length segments, then performs {\it segment-level} local diarization based on an EEND module, and merges the segment-level results via clustering to form a final global diarization result. The segmentation is done to limit the number of speakers in each segment since the current EEND cannot handle a large number of speakers. In this paper, we argue that such an approach involving the segmentation has several issues; for example, it inevitably faces a dilemma that larger segment sizes increase both the context available for enhancing the performance and the number of speakers for the local EEND module to handle. To resolve such a problem, this paper proposes a novel framework that performs diarization without segmentation. However, it can still handle challenging data containing many speakers and a significant amount of overlapping speech. The proposed method can take an entire meeting for inference and perform {\it utterance-by-utterance} diarization that clusters utterance activities in terms of speakers. To this end, we leverage a neural network training scheme called Graph-PIT proposed recently for neural source separation. Experiments with simulated active-meeting-like data and CALLHOME data show the superiority of the proposed approach over the conventional methods.
Constrained Variational Autoencoder for improving EEG based Speech Recognition Systems
Jun 01, 2020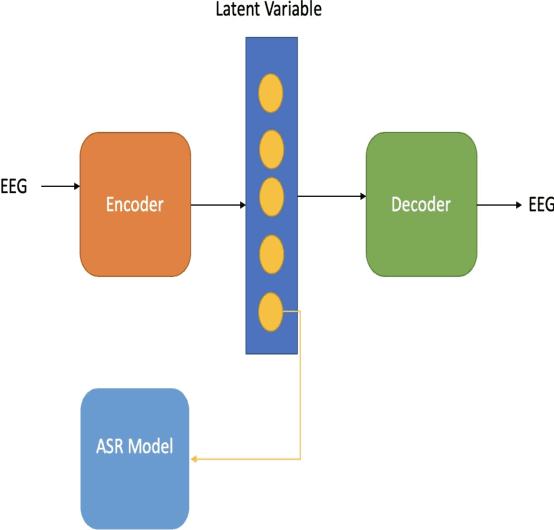

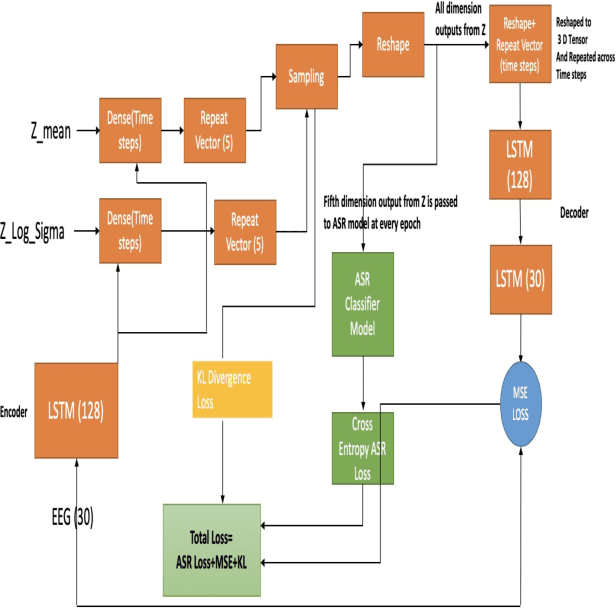
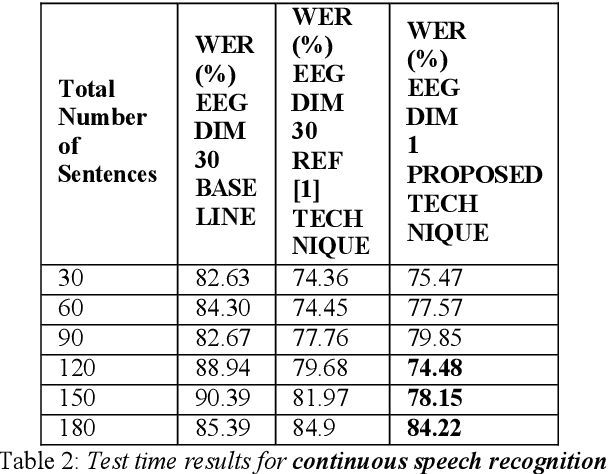
In this paper we introduce a recurrent neural network (RNN) based variational autoencoder (VAE) model with a new constrained loss function that can generate more meaningful electroencephalography (EEG) features from raw EEG features to improve the performance of EEG based speech recognition systems. We demonstrate that both continuous and isolated speech recognition systems trained and tested using EEG features generated from raw EEG features using our VAE model results in improved performance and we demonstrate our results for a limited English vocabulary consisting of 30 unique sentences for continuous speech recognition and for an English vocabulary consisting of 2 unique sentences for isolated speech recognition. We compare our method with another recently introduced method described by authors in [1] to improve the performance of EEG based continuous speech recognition systems and we demonstrate that our method outperforms their method as vocabulary size increases when trained and tested using the same data set. Even though we demonstrate results only for automatic speech recognition (ASR) experiments in this paper, the proposed VAE model with constrained loss function can be extended to a variety of other EEG based brain computer interface (BCI) applications.
Multi-rate attention architecture for fast streamable Text-to-speech spectrum modeling
Apr 01, 2021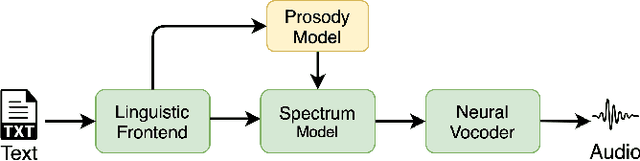
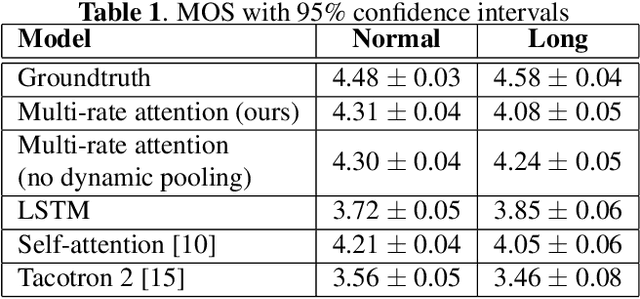
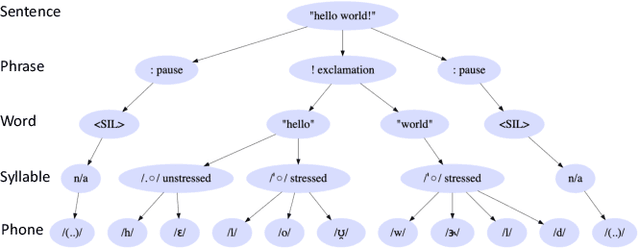
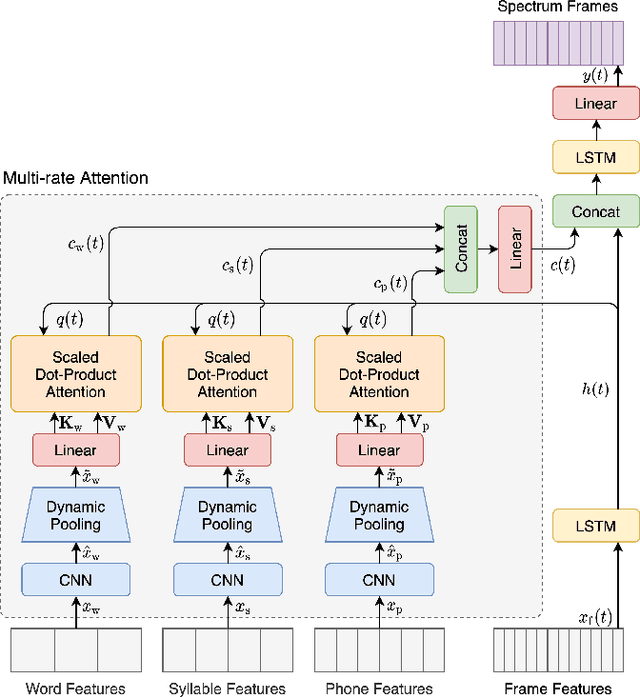
Typical high quality text-to-speech (TTS) systems today use a two-stage architecture, with a spectrum model stage that generates spectral frames and a vocoder stage that generates the actual audio. High-quality spectrum models usually incorporate the encoder-decoder architecture with self-attention or bi-directional long short-term (BLSTM) units. While these models can produce high quality speech, they often incur O($L$) increase in both latency and real-time factor (RTF) with respect to input length $L$. In other words, longer inputs leads to longer delay and slower synthesis speed, limiting its use in real-time applications. In this paper, we propose a multi-rate attention architecture that breaks the latency and RTF bottlenecks by computing a compact representation during encoding and recurrently generating the attention vector in a streaming manner during decoding. The proposed architecture achieves high audio quality (MOS of 4.31 compared to groundtruth 4.48), low latency, and low RTF at the same time. Meanwhile, both latency and RTF of the proposed system stay constant regardless of input lengths, making it ideal for real-time applications.
Bias-Aware Loss for Training Image and Speech Quality Prediction Models from Multiple Datasets
Apr 20, 2021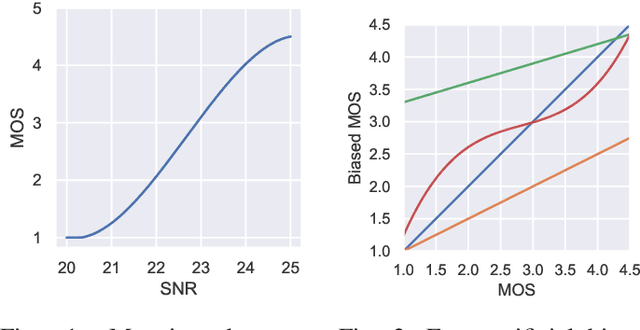
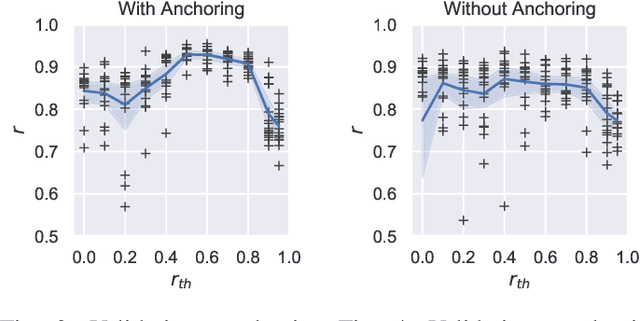
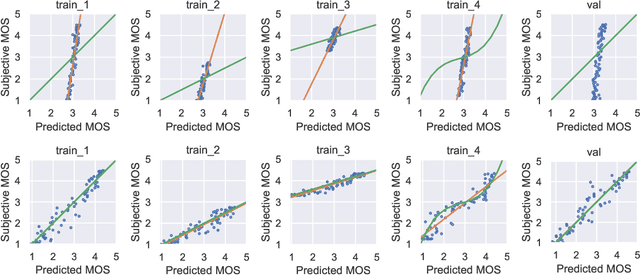
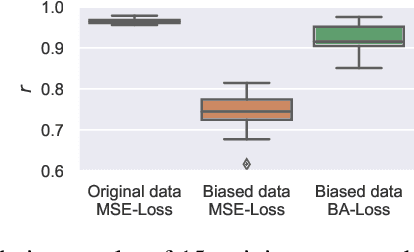
The ground truth used for training image, video, or speech quality prediction models is based on the Mean Opinion Scores (MOS) obtained from subjective experiments. Usually, it is necessary to conduct multiple experiments, mostly with different test participants, to obtain enough data to train quality models based on machine learning. Each of these experiments is subject to an experiment-specific bias, where the rating of the same file may be substantially different in two experiments (e.g. depending on the overall quality distribution). These different ratings for the same distortion levels confuse neural networks during training and lead to lower performance. To overcome this problem, we propose a bias-aware loss function that estimates each dataset's biases during training with a linear function and considers it while optimising the network weights. We prove the efficiency of the proposed method by training and validating quality prediction models on synthetic and subjective image and speech quality datasets.
Monaural Speech Enhancement with Complex Convolutional Block Attention Module and Joint Time Frequency Losses
Feb 03, 2021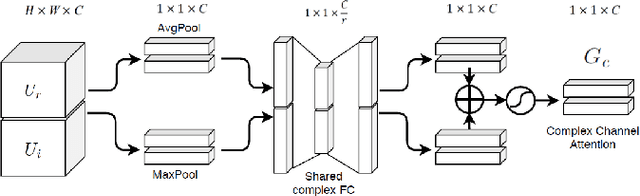
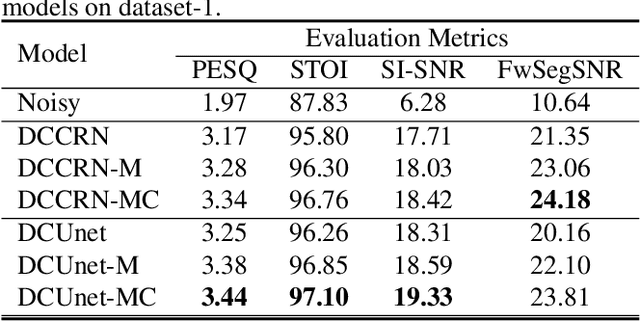
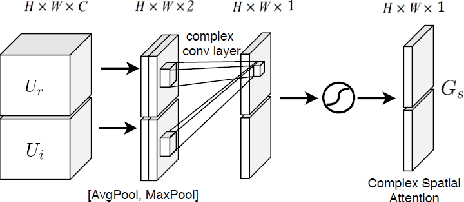
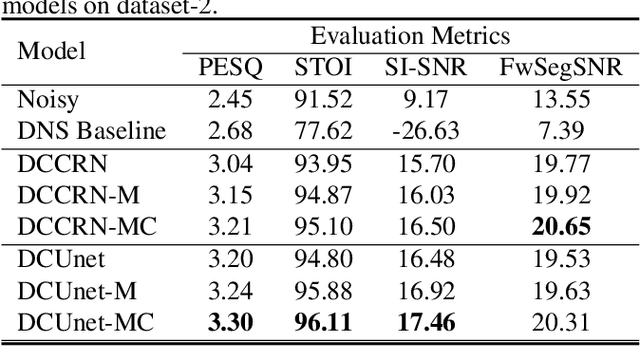
Deep complex U-Net structure and convolutional recurrent network (CRN) structure achieve state-of-the-art performance for monaural speech enhancement. Both deep complex U-Net and CRN are encoder and decoder structures with skip connections, which heavily rely on the representation power of the complex-valued convolutional layers. In this paper, we propose a complex convolutional block attention module (CCBAM) to boost the representation power of the complex-valued convolutional layers by constructing more informative features. The CCBAM is a lightweight and general module which can be easily integrated into any complex-valued convolutional layers. We integrate CCBAM with the deep complex U-Net and CRN to enhance their performance for speech enhancement. We further propose a mixed loss function to jointly optimize the complex models in both time-frequency (TF) domain and time domain. By integrating CCBAM and the mixed loss, we form a new end-to-end (E2E) complex speech enhancement framework. Ablation experiments and objective evaluations show the superior performance of the proposed approaches.
Attention-based multi-task learning for speech-enhancement and speaker-identification in multi-speaker dialogue scenario
Jan 07, 2021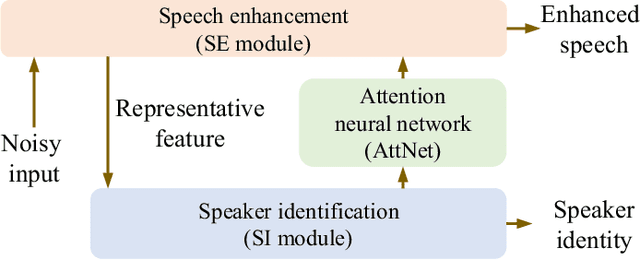
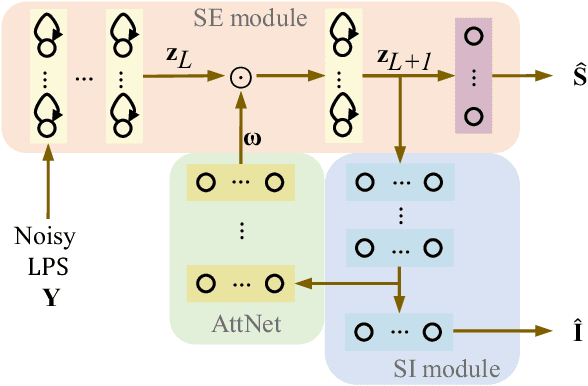
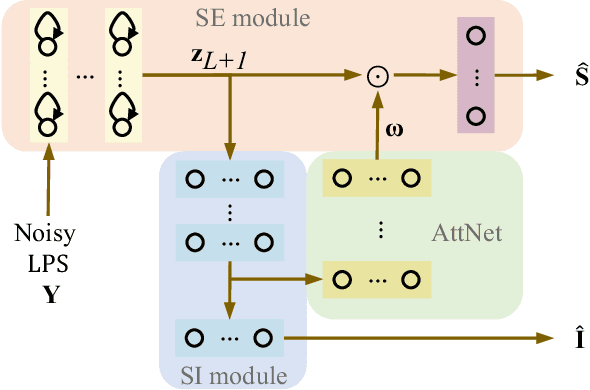
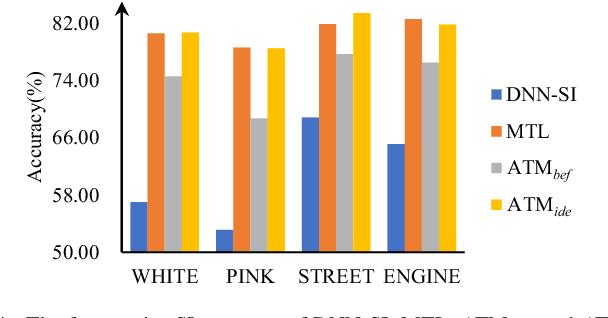
Multi-task learning (MTL) and the attention technique have been proven to effectively extract robust acoustic features for various speech-related applications in noisy environments. In this study, we integrated MTL and the attention-weighting mechanism and propose an attention-based MTL (ATM0 approach to realize a multi-model learning structure and to promote the speech enhancement (SE) and speaker identification (SI) systems simultaneously. There are three subsystems in the proposed ATM: SE, SI, and attention-Net (AttNet). In the proposed system, a long-short-term memory (LSTM) is used to perform SE, while a deep neural network (DNN) model is applied to construct SI and AttNet in ATM. The overall ATM system first extracts the representative features and then enhances the speech spectra in LSTM-SE and classifies speaker identity in DNN-SI. We conducted our experiment on Taiwan Mandarin hearing in noise test database. The evaluation results indicate that the proposed ATM system not only increases the quality and intelligibility of noisy speech input but also improves the accuracy of the SI system when compared to the conventional MTL approaches.