 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Location, Location: Enhancing the Evaluation of Text-to-Speech Synthesis Using the Rapid Prosody Transcription Paradigm
Jul 06, 2021
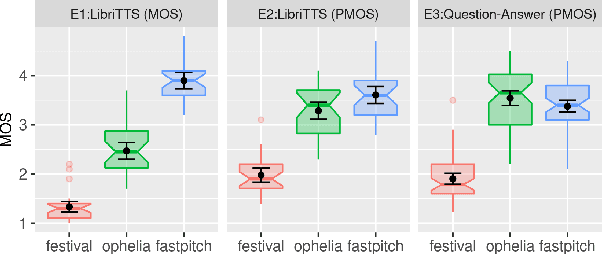
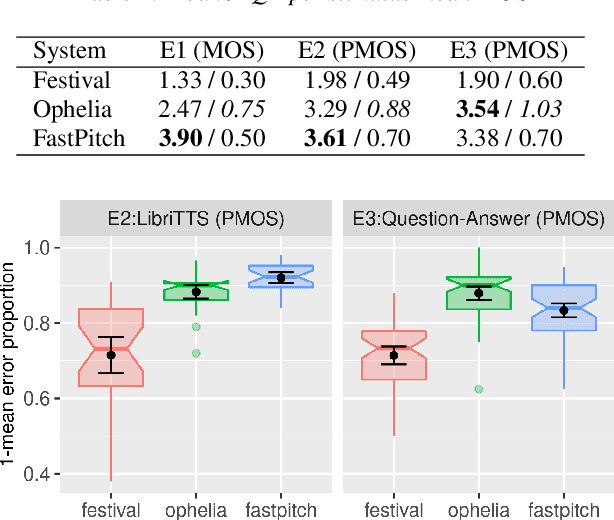
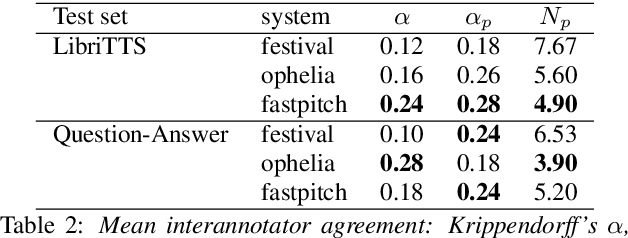
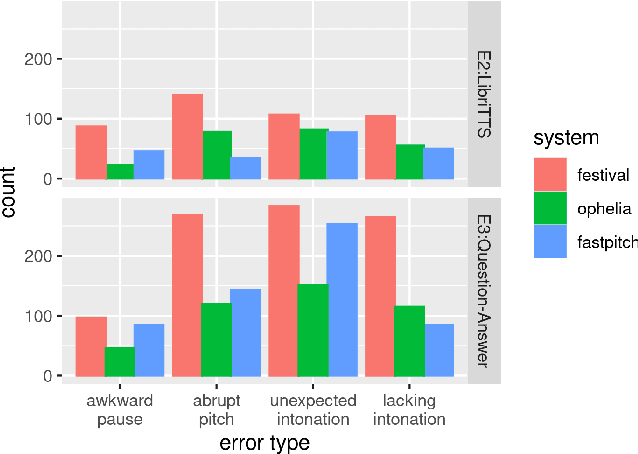
Text-to-Speech synthesis systems are generally evaluated using Mean Opinion Score (MOS) tests, where listeners score samples of synthetic speech on a Likert scale. A major drawback of MOS tests is that they only offer a general measure of overall quality-i.e., the naturalness of an utterance-and so cannot tell us where exactly synthesis errors occur. This can make evaluation of the appropriateness of prosodic variation within utterances inconclusive. To address this, we propose a novel evaluation method based on the Rapid Prosody Transcription paradigm. This allows listeners to mark the locations of errors in an utterance in real-time, providing a probabilistic representation of the perceptual errors that occur in the synthetic signal. We conduct experiments that confirm that the fine-grained evaluation can be mapped to system rankings of standard MOS tests, but the error marking gives a much more comprehensive assessment of synthesized prosody. In particular, for standard audiobook test set samples, we see that error marks consistently cluster around words at major prosodic boundaries indicated by punctuation. However, for question-answer based stimuli, where we control information structure, we see differences emerge in the ability of neural TTS systems to generate context-appropriate prosodic prominence.
Improving the Training Recipe for a Robust Conformer-based Hybrid Model
Jun 26, 2022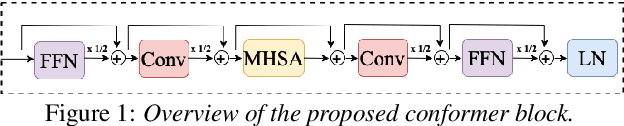
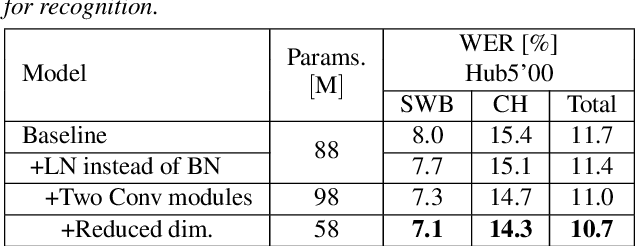
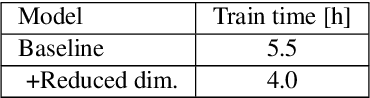
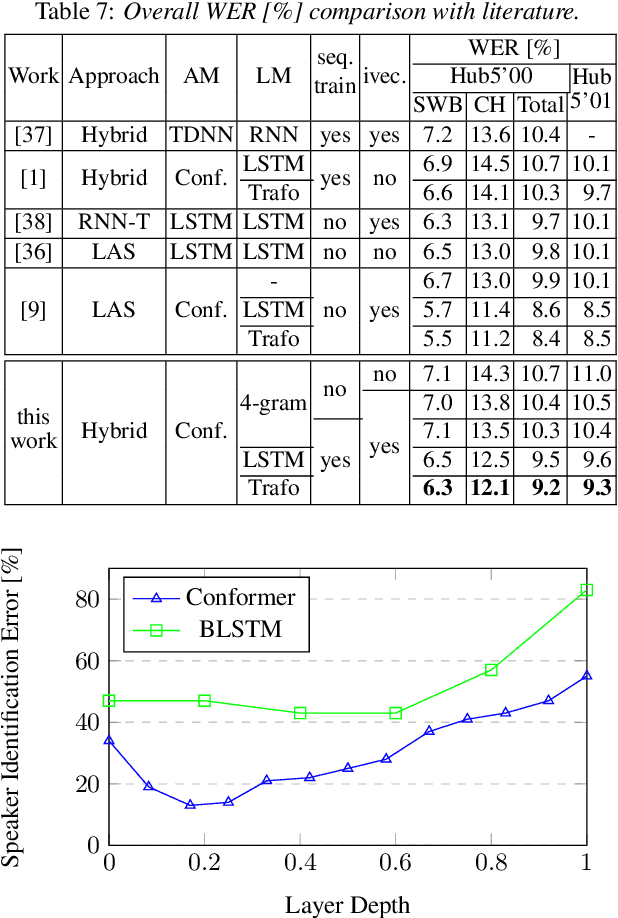
Speaker adaptation is important to build robust automatic speech recognition (ASR) systems. In this work, we investigate various methods for speaker adaptive training (SAT) based on feature-space approaches for a conformer-based acoustic model (AM) on the Switchboard 300h dataset. We propose a method, called Weighted-Simple-Add, which adds weighted speaker information vectors to the input of the multi-head self-attention module of the conformer AM. Using this method for SAT, we achieve 3.5% and 4.5% relative improvement in terms of WER on the CallHome part of Hub5'00 and Hub5'01 respectively. Moreover, we build on top of our previous work where we proposed a novel and competitive training recipe for a conformer-based hybrid AM. We extend and improve this recipe where we achieve 11% relative improvement in terms of word-error-rate (WER) on Switchboard 300h Hub5'00 dataset. We also make this recipe efficient by reducing the total number of parameters by 34% relative.
TERA: Self-Supervised Learning of Transformer Encoder Representation for Speech
Jul 12, 2020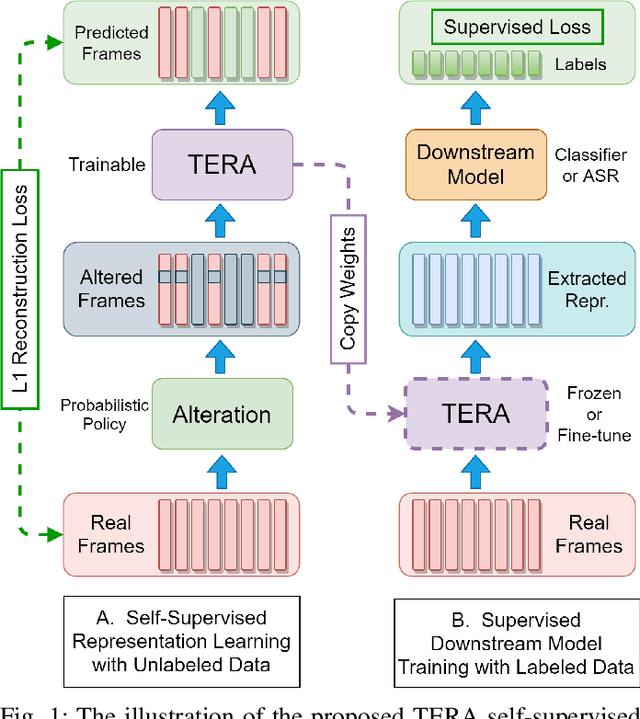
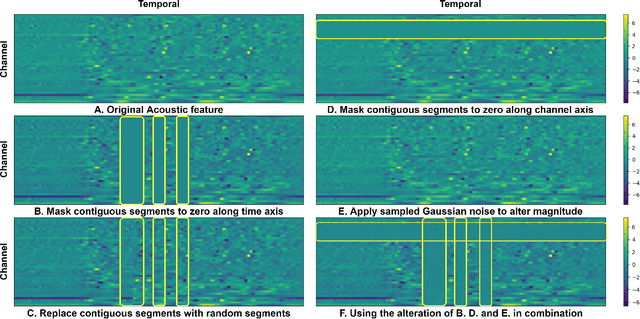
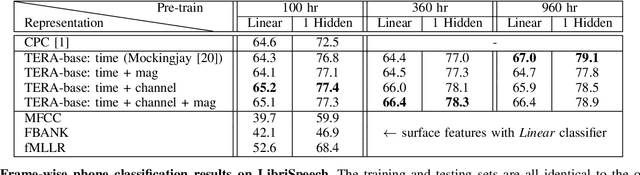
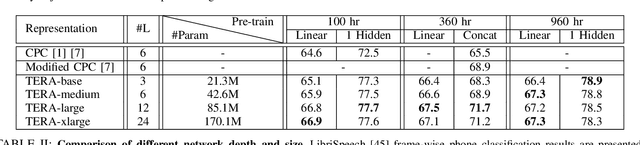
We introduce a self-supervised speech pre-training method called TERA, which stands for Transformer Encoder Representations from Alteration. Recent approaches often learn through the formulation of a single auxiliary task like contrastive prediction, autoregressive prediction, or masked reconstruction. Unlike previous approaches, we use a multi-target auxiliary task to pre-train Transformer Encoders on a large amount of unlabeled speech. The model learns through the reconstruction of acoustic frames from its altered counterpart, where we use a stochastic policy to alter along three dimensions: temporal, channel, and magnitude. TERA can be used to extract speech representations or fine-tune with downstream models. We evaluate TERA on several downstream tasks, including phoneme classification, speaker recognition, and speech recognition. TERA achieved strong performance on these tasks by improving upon surface features and outperforming previous methods. In our experiments, we show that through alteration along different dimensions, the model learns to encode distinct aspects of speech. We explore different knowledge transfer methods to incorporate the pre-trained model with downstream models. Furthermore, we show that the proposed method can be easily transferred to another dataset not used in pre-training.
More for Less: Non-Intrusive Speech Quality Assessment with Limited Annotations
Aug 19, 2021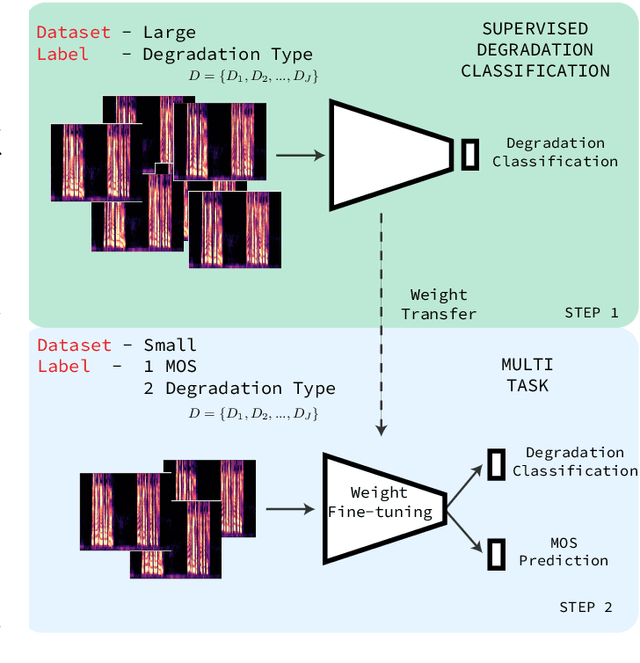
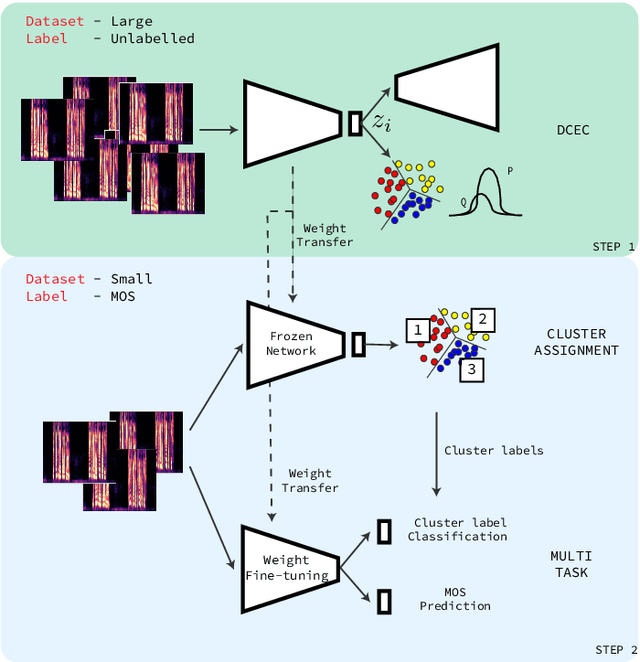
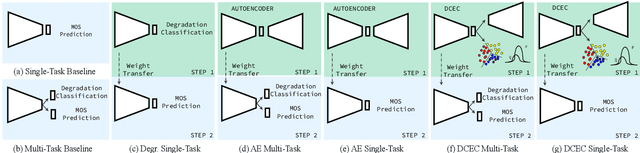
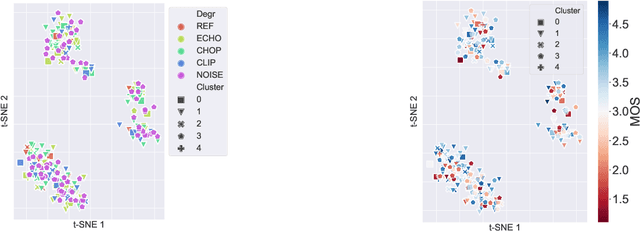
Non-intrusive speech quality assessment is a crucial operation in multimedia applications. The scarcity of annotated data and the lack of a reference signal represent some of the main challenges for designing efficient quality assessment metrics. In this paper, we propose two multi-task models to tackle the problems above. In the first model, we first learn a feature representation with a degradation classifier on a large dataset. Then we perform MOS prediction and degradation classification simultaneously on a small dataset annotated with MOS. In the second approach, the initial stage consists of learning features with a deep clustering-based unsupervised feature representation on the large dataset. Next, we perform MOS prediction and cluster label classification simultaneously on a small dataset. The results show that the deep clustering-based model outperforms the degradation classifier-based model and the 3 baselines (autoencoder features, P.563, and SRMRnorm) on TCD-VoIP. This paper indicates that multi-task learning combined with feature representations from unlabelled data is a promising approach to deal with the lack of large MOS annotated datasets.
Monaural Speech Enhancement with Complex Convolutional Block Attention Module and Joint Time Frequency Losses
Feb 03, 2021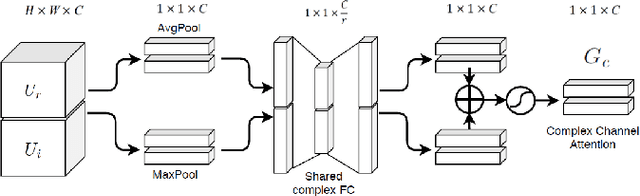
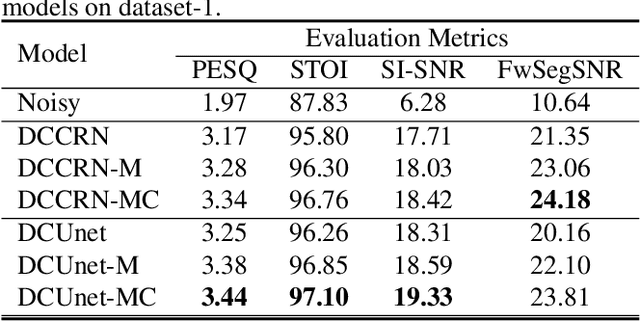
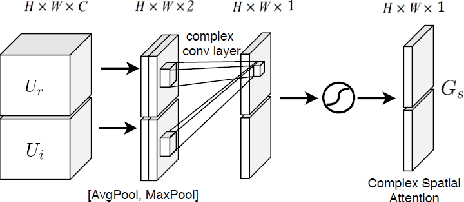
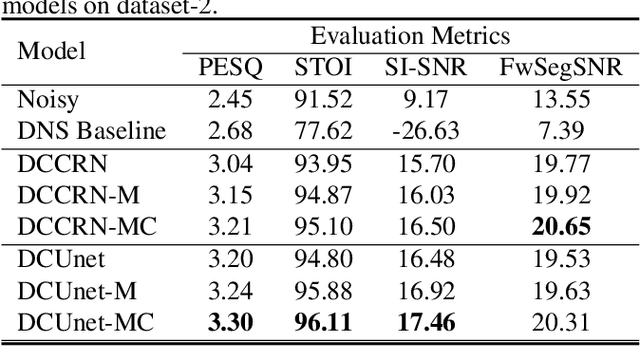
Deep complex U-Net structure and convolutional recurrent network (CRN) structure achieve state-of-the-art performance for monaural speech enhancement. Both deep complex U-Net and CRN are encoder and decoder structures with skip connections, which heavily rely on the representation power of the complex-valued convolutional layers. In this paper, we propose a complex convolutional block attention module (CCBAM) to boost the representation power of the complex-valued convolutional layers by constructing more informative features. The CCBAM is a lightweight and general module which can be easily integrated into any complex-valued convolutional layers. We integrate CCBAM with the deep complex U-Net and CRN to enhance their performance for speech enhancement. We further propose a mixed loss function to jointly optimize the complex models in both time-frequency (TF) domain and time domain. By integrating CCBAM and the mixed loss, we form a new end-to-end (E2E) complex speech enhancement framework. Ablation experiments and objective evaluations show the superior performance of the proposed approaches.
Multi-rate attention architecture for fast streamable Text-to-speech spectrum modeling
Apr 01, 2021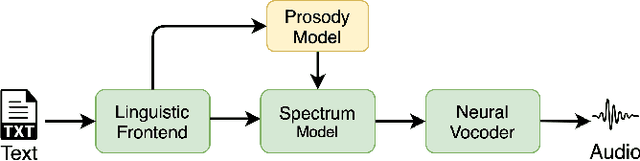
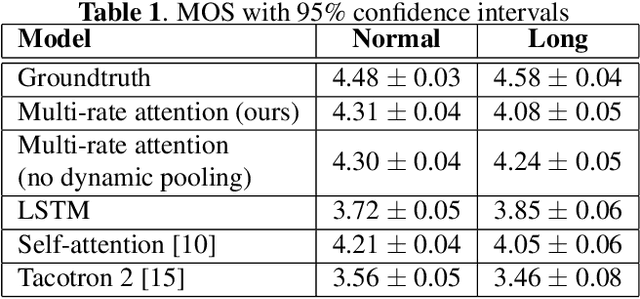
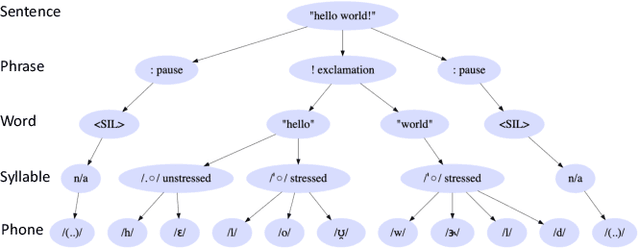
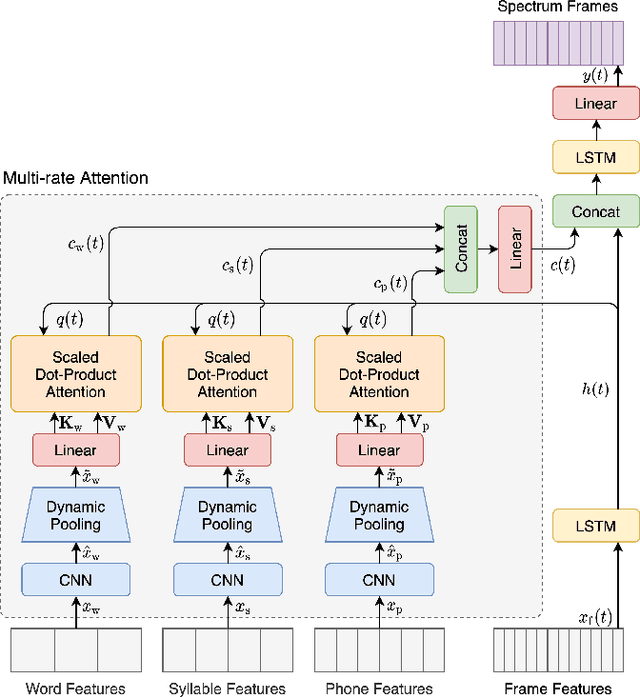
Typical high quality text-to-speech (TTS) systems today use a two-stage architecture, with a spectrum model stage that generates spectral frames and a vocoder stage that generates the actual audio. High-quality spectrum models usually incorporate the encoder-decoder architecture with self-attention or bi-directional long short-term (BLSTM) units. While these models can produce high quality speech, they often incur O($L$) increase in both latency and real-time factor (RTF) with respect to input length $L$. In other words, longer inputs leads to longer delay and slower synthesis speed, limiting its use in real-time applications. In this paper, we propose a multi-rate attention architecture that breaks the latency and RTF bottlenecks by computing a compact representation during encoding and recurrently generating the attention vector in a streaming manner during decoding. The proposed architecture achieves high audio quality (MOS of 4.31 compared to groundtruth 4.48), low latency, and low RTF at the same time. Meanwhile, both latency and RTF of the proposed system stay constant regardless of input lengths, making it ideal for real-time applications.
Attention-based multi-task learning for speech-enhancement and speaker-identification in multi-speaker dialogue scenario
Jan 07, 2021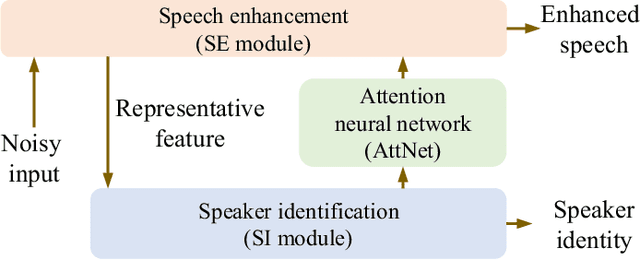
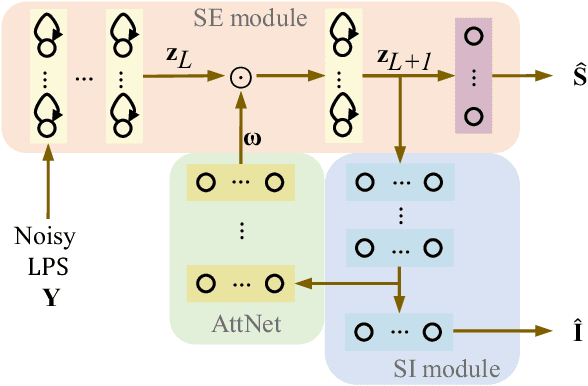
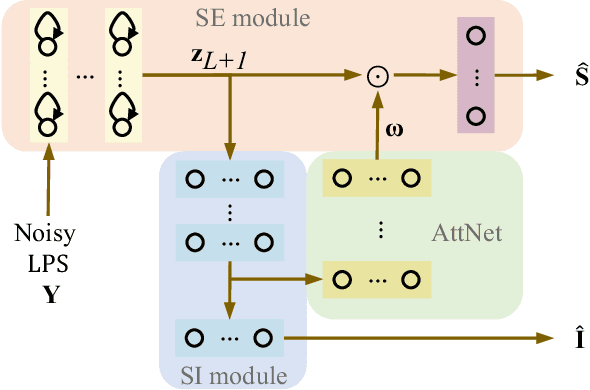
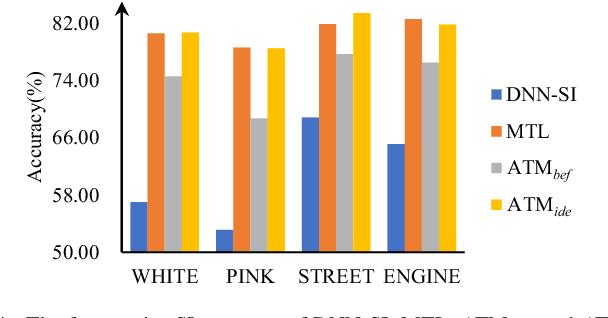
Multi-task learning (MTL) and the attention technique have been proven to effectively extract robust acoustic features for various speech-related applications in noisy environments. In this study, we integrated MTL and the attention-weighting mechanism and propose an attention-based MTL (ATM0 approach to realize a multi-model learning structure and to promote the speech enhancement (SE) and speaker identification (SI) systems simultaneously. There are three subsystems in the proposed ATM: SE, SI, and attention-Net (AttNet). In the proposed system, a long-short-term memory (LSTM) is used to perform SE, while a deep neural network (DNN) model is applied to construct SI and AttNet in ATM. The overall ATM system first extracts the representative features and then enhances the speech spectra in LSTM-SE and classifies speaker identity in DNN-SI. We conducted our experiment on Taiwan Mandarin hearing in noise test database. The evaluation results indicate that the proposed ATM system not only increases the quality and intelligibility of noisy speech input but also improves the accuracy of the SI system when compared to the conventional MTL approaches.
Is "moby dick" a Whale or a Bird? Named Entities and Terminology in Speech Translation
Sep 15, 2021
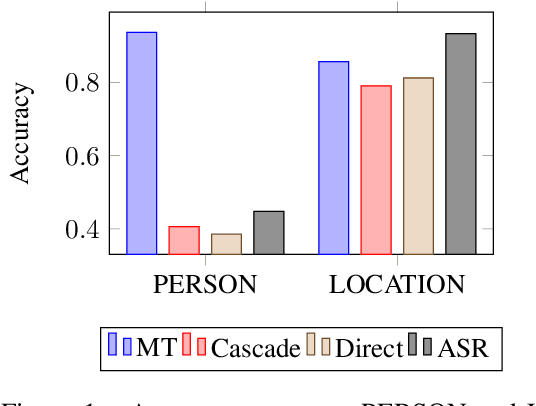

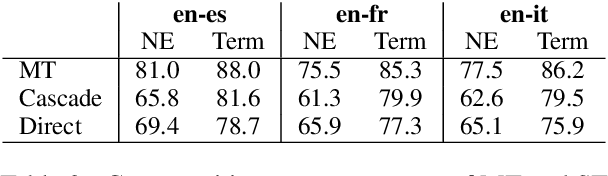
Automatic translation systems are known to struggle with rare words. Among these, named entities (NEs) and domain-specific terms are crucial, since errors in their translation can lead to severe meaning distortions. Despite their importance, previous speech translation (ST) studies have neglected them, also due to the dearth of publicly available resources tailored to their specific evaluation. To fill this gap, we i) present the first systematic analysis of the behavior of state-of-the-art ST systems in translating NEs and terminology, and ii) release NEuRoparl-ST, a novel benchmark built from European Parliament speeches annotated with NEs and terminology. Our experiments on the three language directions covered by our benchmark (en->es/fr/it) show that ST systems correctly translate 75-80% of terms and 65-70% of NEs, with very low performance (37-40%) on person names.
Bias-Aware Loss for Training Image and Speech Quality Prediction Models from Multiple Datasets
Apr 20, 2021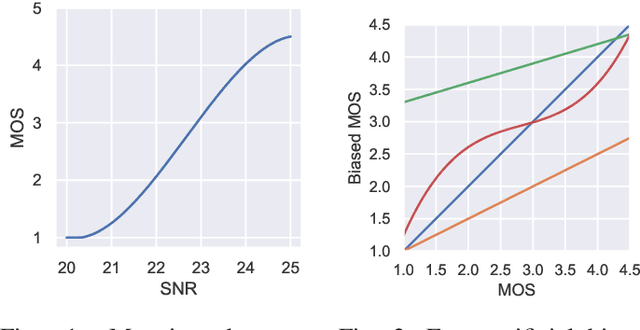
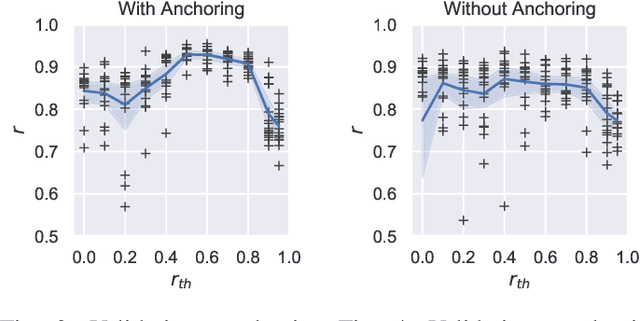
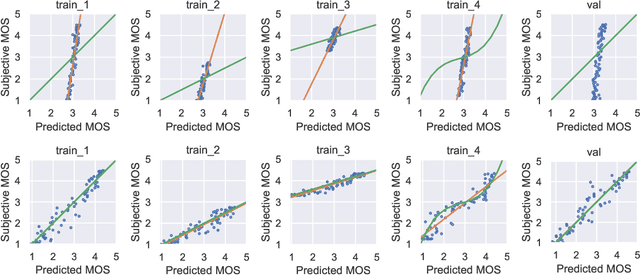
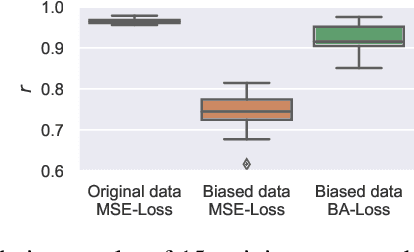
The ground truth used for training image, video, or speech quality prediction models is based on the Mean Opinion Scores (MOS) obtained from subjective experiments. Usually, it is necessary to conduct multiple experiments, mostly with different test participants, to obtain enough data to train quality models based on machine learning. Each of these experiments is subject to an experiment-specific bias, where the rating of the same file may be substantially different in two experiments (e.g. depending on the overall quality distribution). These different ratings for the same distortion levels confuse neural networks during training and lead to lower performance. To overcome this problem, we propose a bias-aware loss function that estimates each dataset's biases during training with a linear function and considers it while optimising the network weights. We prove the efficiency of the proposed method by training and validating quality prediction models on synthetic and subjective image and speech quality datasets.
Speech Recognition using EEG signals recorded using dry electrodes
Aug 13, 2020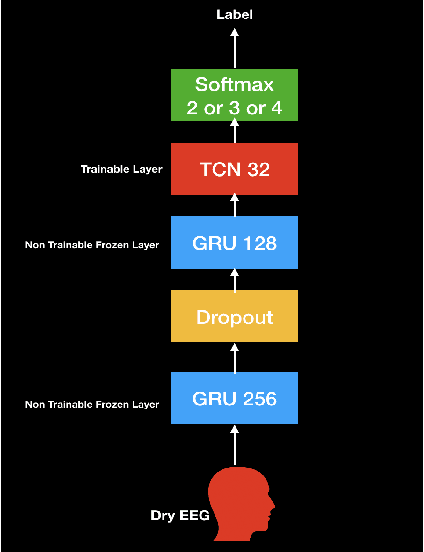
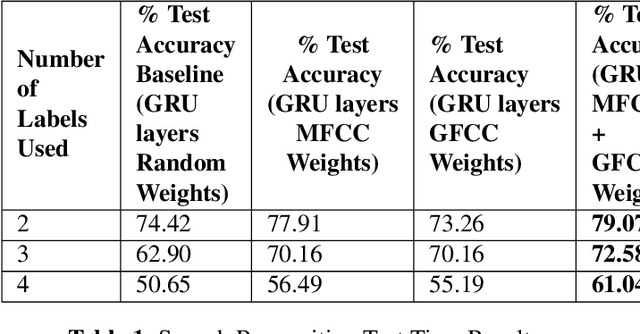
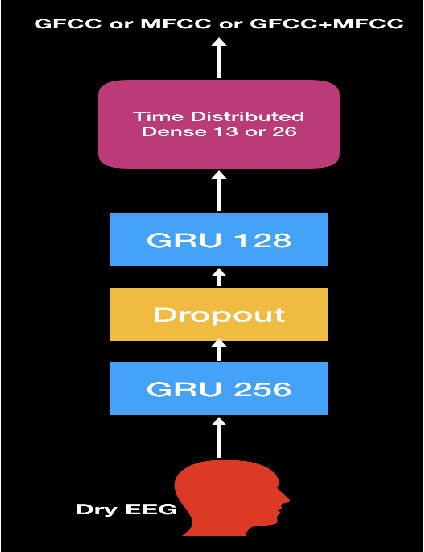
In this paper, we demonstrate speech recognition using electroencephalography (EEG) signals obtained using dry electrodes on a limited English vocabulary consisting of three vowels and one word using a deep learning model. We demonstrate a test accuracy of 79.07 percent on a subset vocabulary consisting of two English vowels. Our results demonstrate the feasibility of using EEG signals recorded using dry electrodes for performing the task of speech recognition.