 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
TERA: Self-Supervised Learning of Transformer Encoder Representation for Speech
Jul 12, 2020
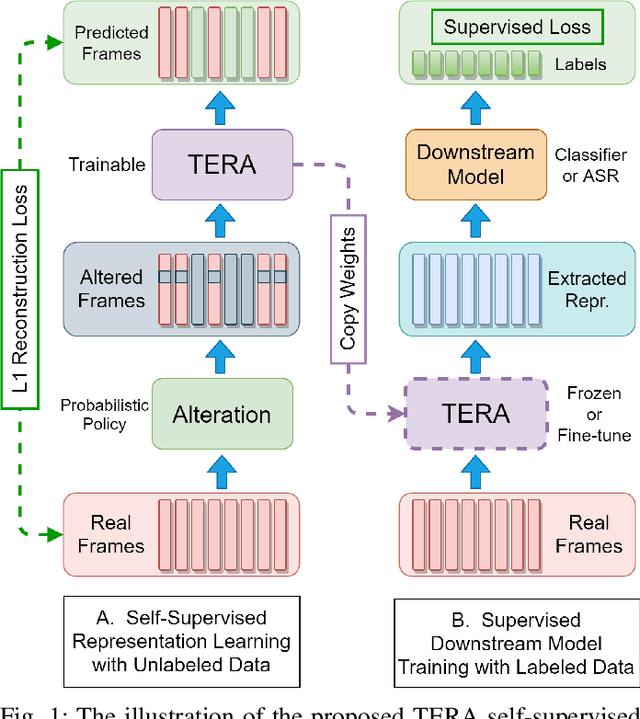
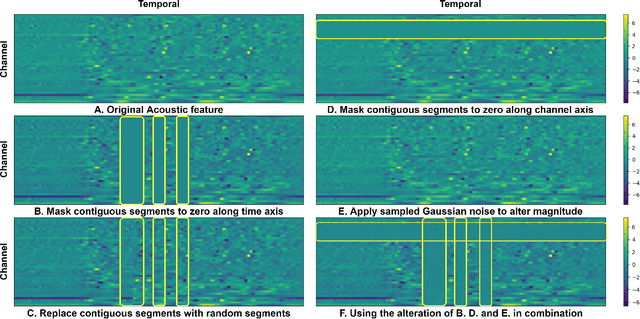
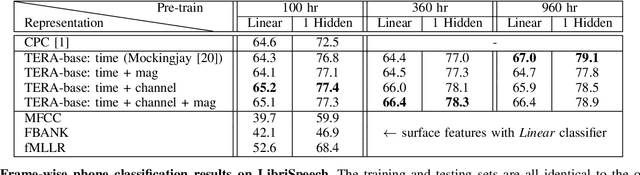
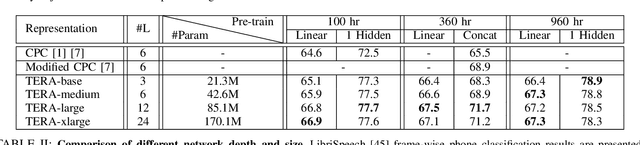
We introduce a self-supervised speech pre-training method called TERA, which stands for Transformer Encoder Representations from Alteration. Recent approaches often learn through the formulation of a single auxiliary task like contrastive prediction, autoregressive prediction, or masked reconstruction. Unlike previous approaches, we use a multi-target auxiliary task to pre-train Transformer Encoders on a large amount of unlabeled speech. The model learns through the reconstruction of acoustic frames from its altered counterpart, where we use a stochastic policy to alter along three dimensions: temporal, channel, and magnitude. TERA can be used to extract speech representations or fine-tune with downstream models. We evaluate TERA on several downstream tasks, including phoneme classification, speaker recognition, and speech recognition. TERA achieved strong performance on these tasks by improving upon surface features and outperforming previous methods. In our experiments, we show that through alteration along different dimensions, the model learns to encode distinct aspects of speech. We explore different knowledge transfer methods to incorporate the pre-trained model with downstream models. Furthermore, we show that the proposed method can be easily transferred to another dataset not used in pre-training.
The Phonetic Footprint of Parkinson's Disease
Dec 21, 2021
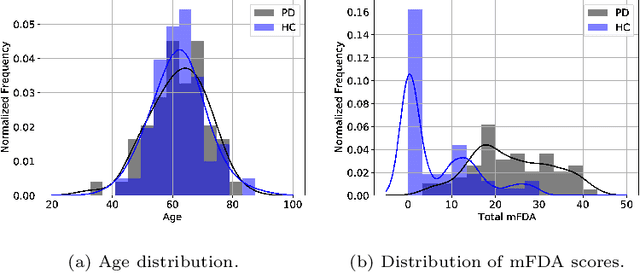
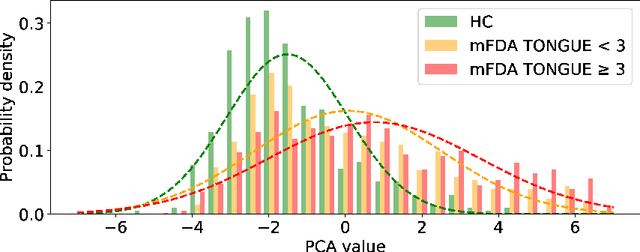
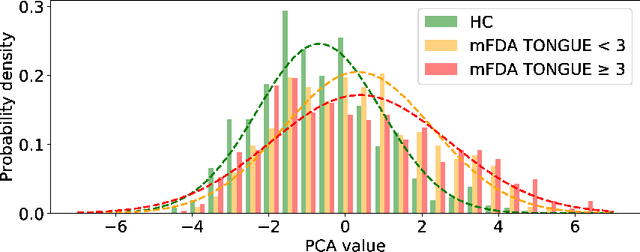
As one of the most prevalent neurodegenerative disorders, Parkinson's disease (PD) has a significant impact on the fine motor skills of patients. The complex interplay of different articulators during speech production and realization of required muscle tension become increasingly difficult, thus leading to a dysarthric speech. Characteristic patterns such as vowel instability, slurred pronunciation and slow speech can often be observed in the affected individuals and were analyzed in previous studies to determine the presence and progression of PD. In this work, we used a phonetic recognizer trained exclusively on healthy speech data to investigate how PD affected the phonetic footprint of patients. We rediscovered numerous patterns that had been described in previous contributions although our system had never seen any pathological speech previously. Furthermore, we could show that intermediate activations from the neural network could serve as feature vectors encoding information related to the disease state of individuals. We were also able to directly correlate the expert-rated intelligibility of a speaker with the mean confidence of phonetic predictions. Our results support the assumption that pathological data is not necessarily required to train systems that are capable of analyzing PD speech.
* https://www.sciencedirect.com/science/article/abs/pii/S0885230821001169
Finnish Parliament ASR corpus - Analysis, benchmarks and statistics
Mar 28, 2022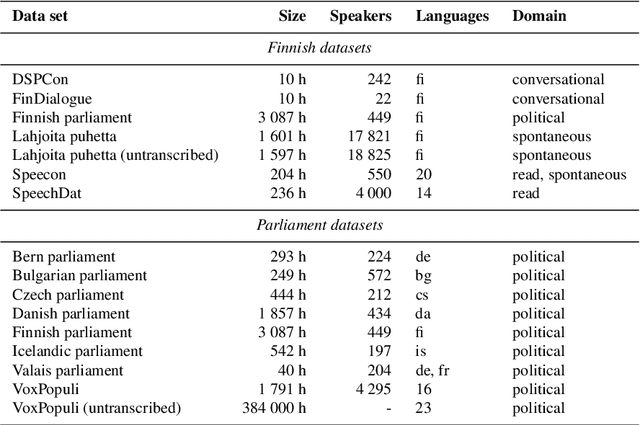
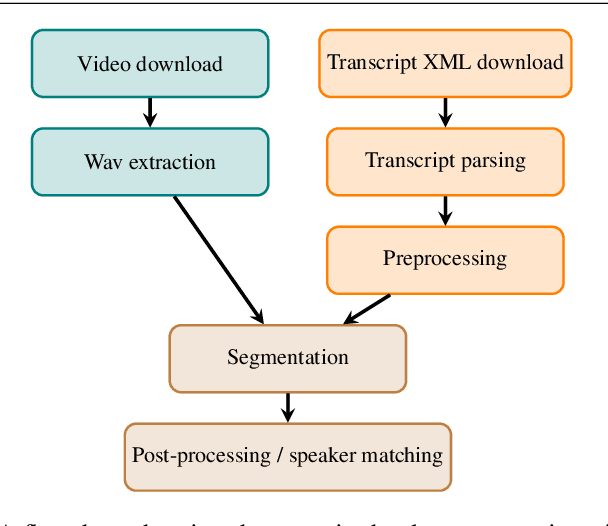

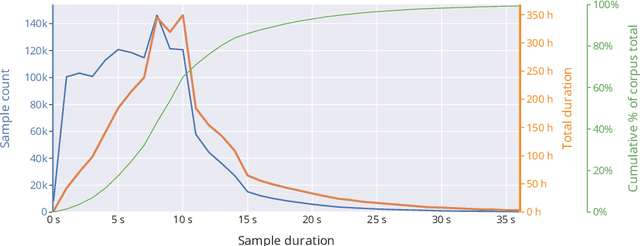
Public sources like parliament meeting recordings and transcripts provide ever-growing material for the training and evaluation of automatic speech recognition (ASR) systems. In this paper, we publish and analyse the Finnish parliament ASR corpus, the largest publicly available collection of manually transcribed speech data for Finnish with over 3000 hours of speech and 449 speakers for which it provides rich demographic metadata. This corpus builds on earlier initial work, and as a result the corpus has a natural split into two training subsets from two periods of time. Similarly, there are two official, corrected test sets covering different times, setting an ASR task with longitudinal distribution-shift characteristics. An official development set is also provided. We develop a complete Kaldi-based data preparation pipeline, and hidden Markov model (HMM), hybrid deep neural network (HMM-DNN) and attention-based encoder-decoder (AED) ASR recipes. We set benchmarks on the official test sets, as well as multiple other recently used test sets. Both temporal corpus subsets are already large, and we observe that beyond their scale, ASR performance on the official test sets plateaus, whereas other domains benefit from added data. The HMM-DNN and AED approaches are compared in a carefully matched equal data setting, with the HMM-DNN system consistently performing better. Finally, the variation of the ASR accuracy is compared between the speaker categories available in the parliament metadata to detect potential biases based on factors such as gender, age, and education.
Improving Dysarthric Speech Intelligibility Using Cycle-consistent Adversarial Training
Jan 10, 2020
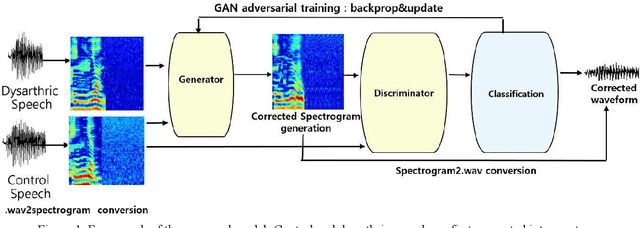
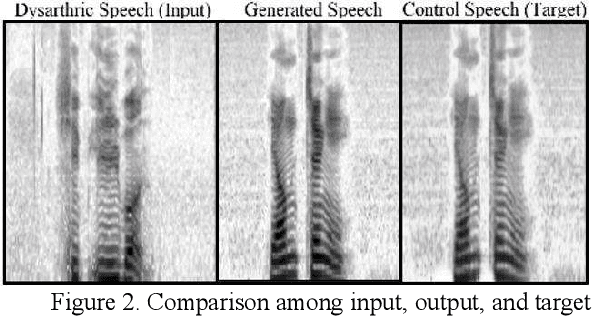
Dysarthria is a motor speech impairment affecting millions of people. Dysarthric speech can be far less intelligible than those of non-dysarthric speakers, causing significant communication difficulties. The goal of our work is to develop a model for dysarthric to healthy speech conversion using Cycle-consistent GAN. Using 18,700 dysarthric and 8,610 healthy control Korean utterances that were recorded for the purpose of automatic recognition of voice keyboard in a previous study, the generator is trained to transform dysarthric to healthy speech in the spectral domain, which is then converted back to speech. Objective evaluation using automatic speech recognition of the generated utterance on a held-out test set shows that the recognition performance is improved compared with the original dysarthic speech after performing adversarial training, as the absolute WER has been lowered by 33.4%. It demonstrates that the proposed GAN-based conversion method is useful for improving dysarthric speech intelligibility.
Streaming non-autoregressive model for any-to-many voice conversion
Jun 15, 2022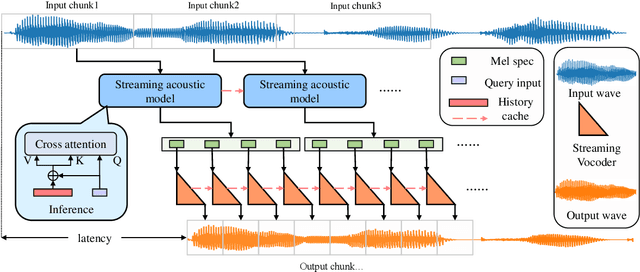
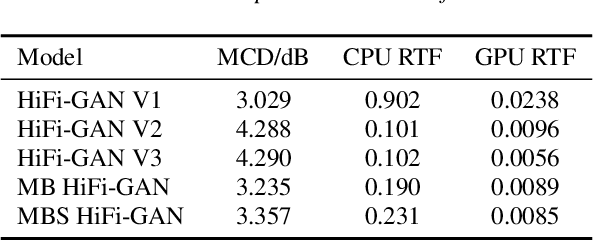
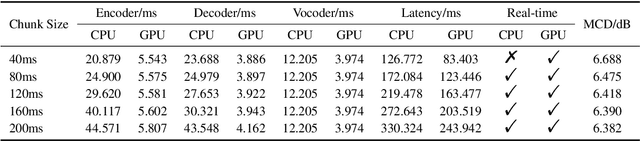
Voice conversion models have developed for decades, and current mainstream research focuses on non-streaming voice conversion. However, streaming voice conversion is more suitable for practical application scenarios than non-streaming voice conversion. In this paper, we propose a streaming any-to-many voice conversion based on fully non-autoregressive model, which includes a streaming transformer based acoustic model and a streaming vocoder. Streaming transformer based acoustic model is composed of a pre-trained encoder from streaming end-to-end based automatic speech recognition model and a decoder modified on FastSpeech blocks. Streaming vocoder is designed for streaming task with pseudo quadrature mirror filter bank and causal convolution. Experimental results show that the proposed method achieves significant performance both in latency and conversion quality and can be real-time on CPU and GPU.
Speech Recognition using EEG signals recorded using dry electrodes
Aug 13, 2020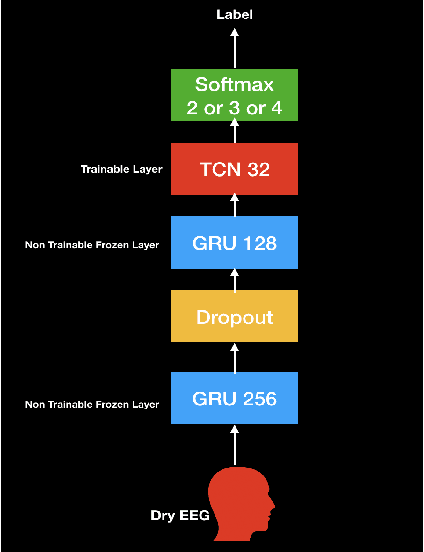
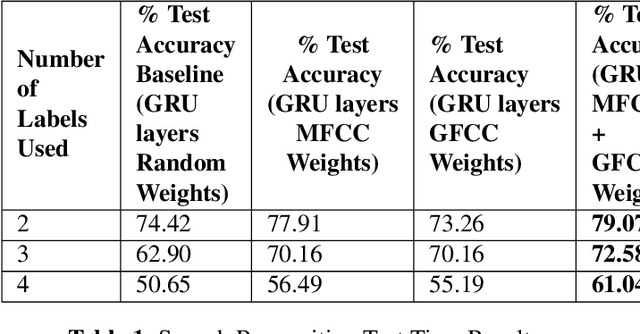
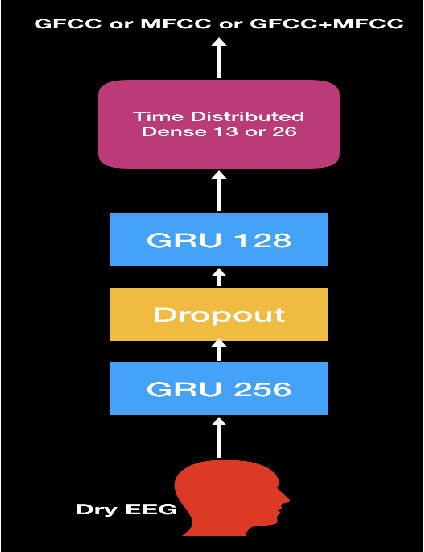
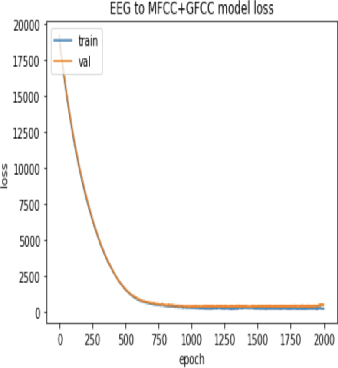
In this paper, we demonstrate speech recognition using electroencephalography (EEG) signals obtained using dry electrodes on a limited English vocabulary consisting of three vowels and one word using a deep learning model. We demonstrate a test accuracy of 79.07 percent on a subset vocabulary consisting of two English vowels. Our results demonstrate the feasibility of using EEG signals recorded using dry electrodes for performing the task of speech recognition.
Integrating Text Inputs For Training and Adapting RNN Transducer ASR Models
Feb 26, 2022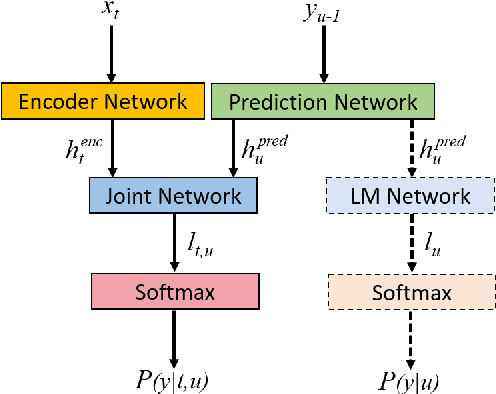
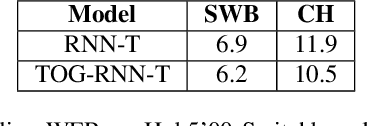
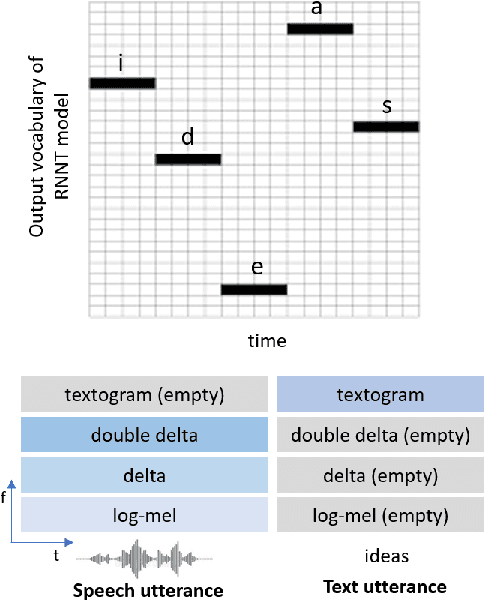
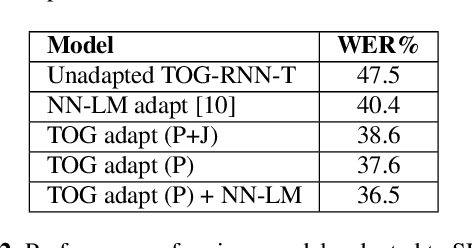
Compared to hybrid automatic speech recognition (ASR) systems that use a modular architecture in which each component can be independently adapted to a new domain, recent end-to-end (E2E) ASR system are harder to customize due to their all-neural monolithic construction. In this paper, we propose a novel text representation and training framework for E2E ASR models. With this approach, we show that a trained RNN Transducer (RNN-T) model's internal LM component can be effectively adapted with text-only data. An RNN-T model trained using both speech and text inputs improves over a baseline model trained on just speech with close to 13% word error rate (WER) reduction on the Switchboard and CallHome test sets of the NIST Hub5 2000 evaluation. The usefulness of the proposed approach is further demonstrated by customizing this general purpose RNN-T model to three separate datasets. We observe 20-45% relative word error rate (WER) reduction in these settings with this novel LM style customization technique using only unpaired text data from the new domains.
Lost in Interpreting: Speech Translation from Source or Interpreter?
Jun 17, 2021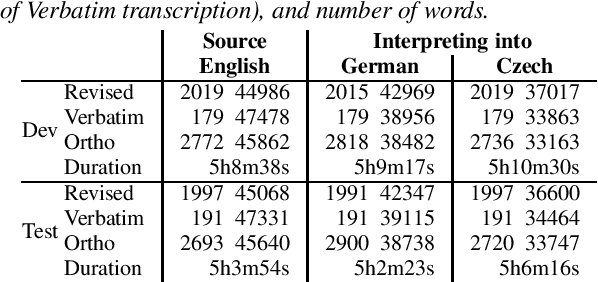
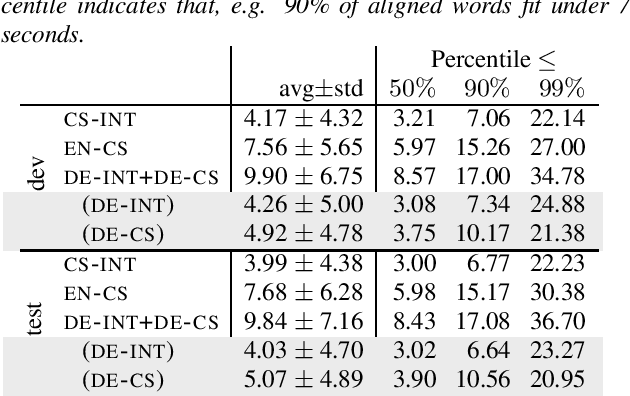

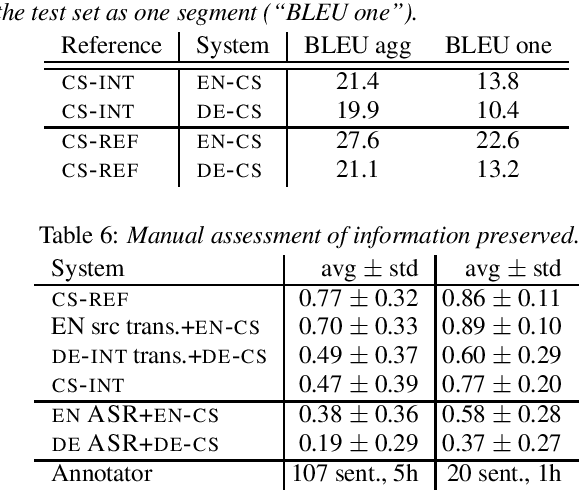
Interpreters facilitate multi-lingual meetings but the affordable set of languages is often smaller than what is needed. Automatic simultaneous speech translation can extend the set of provided languages. We investigate if such an automatic system should rather follow the original speaker, or an interpreter to achieve better translation quality at the cost of increased delay. To answer the question, we release Europarl Simultaneous Interpreting Corpus (ESIC), 10 hours of recordings and transcripts of European Parliament speeches in English, with simultaneous interpreting into Czech and German. We evaluate quality and latency of speaker-based and interpreter-based spoken translation systems from English to Czech. We study the differences in implicit simplification and summarization of the human interpreter compared to a machine translation system trained to shorten the output to some extent. Finally, we perform human evaluation to measure information loss of each of these approaches.
C3-DINO: Joint Contrastive and Non-contrastive Self-Supervised Learning for Speaker Verification
Aug 15, 2022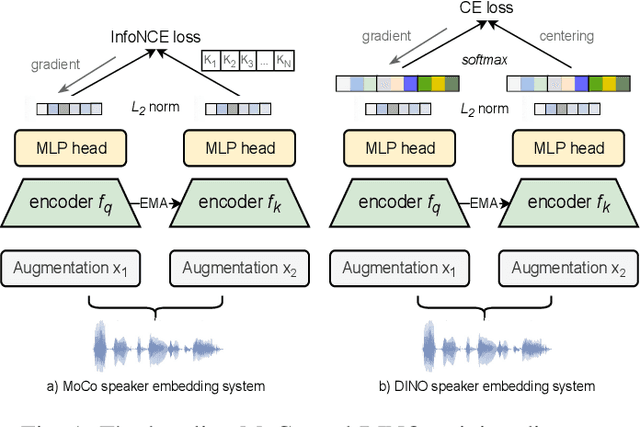
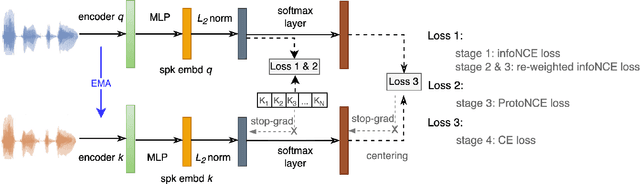
Self-supervised learning (SSL) has drawn an increased attention in the field of speech processing. Recent studies have demonstrated that contrastive learning is able to learn discriminative speaker embeddings in a self-supervised manner. However, base contrastive self-supervised learning (CSSL) assumes that the pairs generated from a view of anchor instance and any view of other instances are all negative, which introduces many false negative pairs in constructing the loss function. The problem is referred as $class$-$collision$, which remains as one major issue that impedes the CSSL based speaker verification (SV) systems from achieving better performances. In the meanwhile, studies reveal that negative sample free SSL frameworks perform well in learning speaker or image representations. In this study, we investigate SSL techniques that lead to an improved SV performance. We first analyse the impact of false negative pairs in the CSSL systems. Then, a multi-stage Class-Collision Correction (C3) method is proposed, which leads to the state-of-the-art CSSL based speaker embedding system. On the basis of the pretrained CSSL model, we further propose to employ a negative sample free SSL objective (i.e., DINO) to fine-tune the speaker embedding network. The resulting speaker embedding system (C3-DINO) achieves 2.5% EER with a simple Cosine Distance Scoring method on Voxceleb1 test set, which outperforms the previous SOTA SSL system (4.86%) by a significant +45% relative improvement. With speaker clustering and pseudo labeling on Voxceleb2 training set, a LDA/CDS back-end applying on the C3-DINO speaker embeddings is able to further push the EER to 2.2%. Comprehensive experimental investigations of the Voxceleb benchmarks and our internal dataset demonstrate the effectiveness of our proposed methods, and the performance gap between the SSL SV and the supervised counterpart narrows further.
Attention-based multi-task learning for speech-enhancement and speaker-identification in multi-speaker dialogue scenario
Jan 07, 2021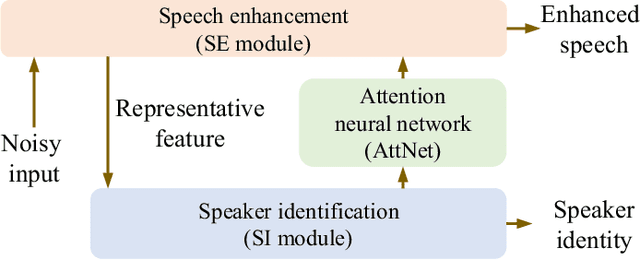
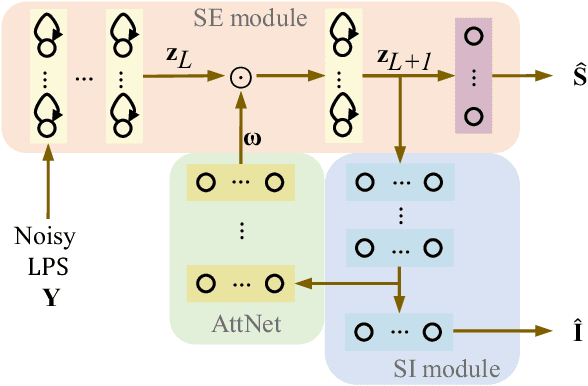
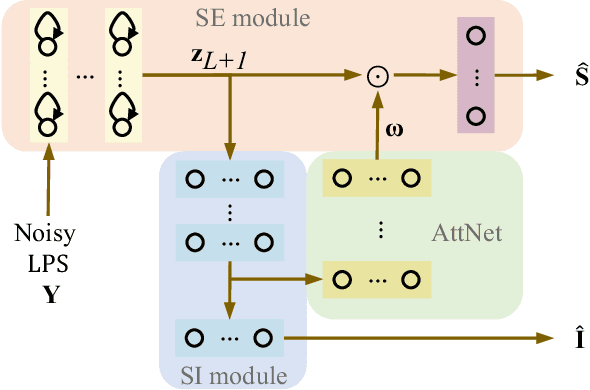
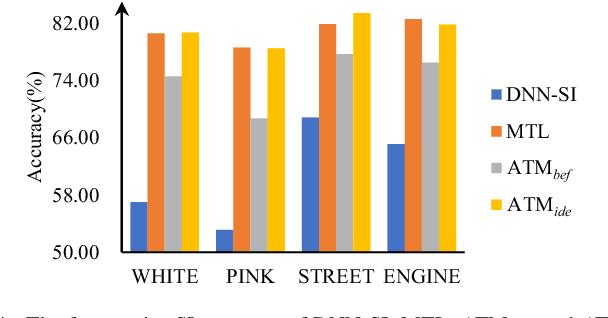
Multi-task learning (MTL) and the attention technique have been proven to effectively extract robust acoustic features for various speech-related applications in noisy environments. In this study, we integrated MTL and the attention-weighting mechanism and propose an attention-based MTL (ATM0 approach to realize a multi-model learning structure and to promote the speech enhancement (SE) and speaker identification (SI) systems simultaneously. There are three subsystems in the proposed ATM: SE, SI, and attention-Net (AttNet). In the proposed system, a long-short-term memory (LSTM) is used to perform SE, while a deep neural network (DNN) model is applied to construct SI and AttNet in ATM. The overall ATM system first extracts the representative features and then enhances the speech spectra in LSTM-SE and classifies speaker identity in DNN-SI. We conducted our experiment on Taiwan Mandarin hearing in noise test database. The evaluation results indicate that the proposed ATM system not only increases the quality and intelligibility of noisy speech input but also improves the accuracy of the SI system when compared to the conventional MTL approaches.