 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Meta-Transfer Learning for Code-Switched Speech Recognition
Apr 29, 2020
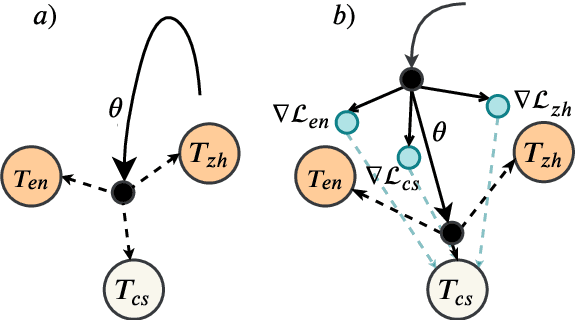
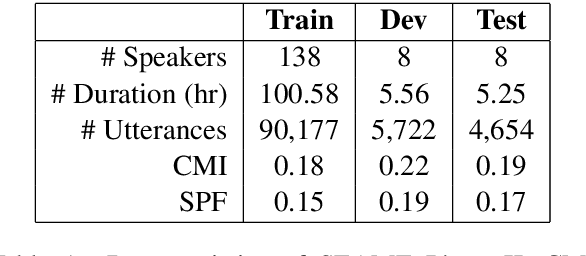
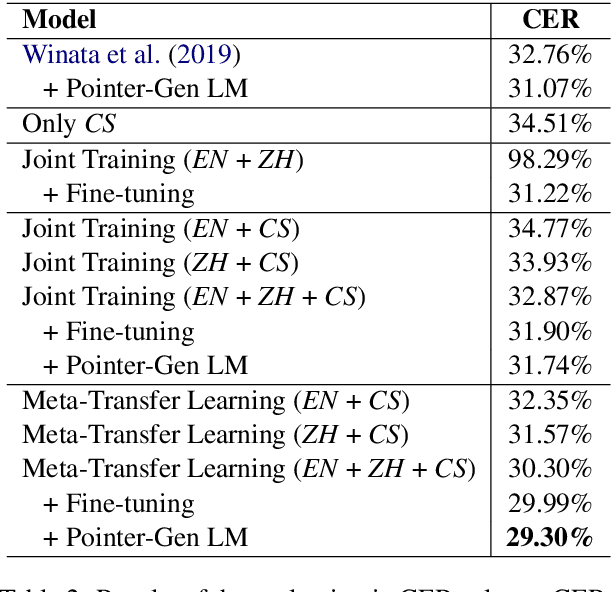
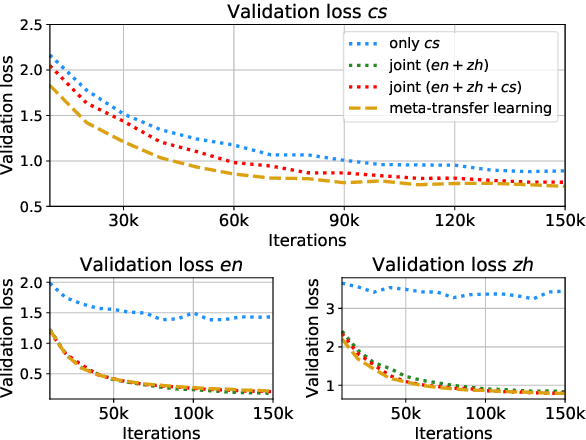
An increasing number of people in the world today speak a mixed-language as a result of being multilingual. However, building a speech recognition system for code-switching remains difficult due to the availability of limited resources and the expense and significant effort required to collect mixed-language data. We therefore propose a new learning method, meta-transfer learning, to transfer learn on a code-switched speech recognition system in a low-resource setting by judiciously extracting information from high-resource monolingual datasets. Our model learns to recognize individual languages, and transfer them so as to better recognize mixed-language speech by conditioning the optimization on the code-switching data. Based on experimental results, our model outperforms existing baselines on speech recognition and language modeling tasks, and is faster to converge.
A Unified Framework for Speech Separation
Dec 17, 2019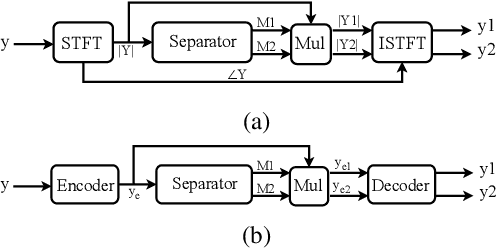
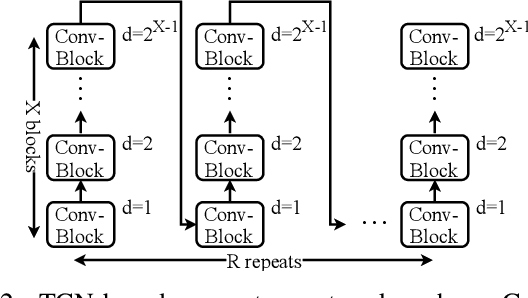
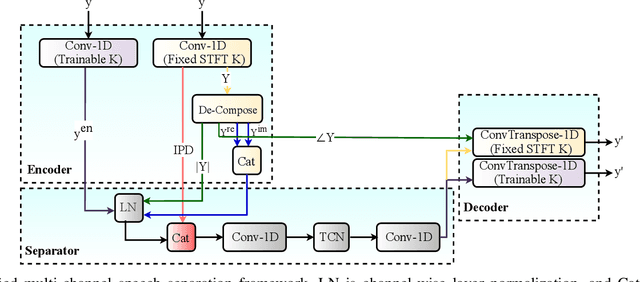
Speech separation refers to extracting each individual speech source in a given mixed signal. Recent advancements in speech separation and ongoing research in this area, have made these approaches as promising techniques for pre-processing of naturalistic audio streams. After incorporating deep learning techniques into speech separation, performance on these systems is improving faster. The initial solutions introduced for deep learning based speech separation analyzed the speech signals into time-frequency domain with STFT; and then encoded mixed signals were fed into a deep neural network based separator. Most recently, new methods are introduced to separate waveform of the mixed signal directly without analyzing them using STFT. Here, we introduce a unified framework to include both spectrogram and waveform separations into a single structure, while being only different in the kernel function used to encode and decode the data; where, both can achieve competitive performance. This new framework provides flexibility; in addition, depending on the characteristics of the data, or limitations of the memory and latency can set the hyper-parameters to flow in a pipeline of the framework which fits the task properly. We extend single-channel speech separation into multi-channel framework with end-to-end training of the network while optimizing the speech separation criterion (i.e., Si-SNR) directly. We emphasize on how tied kernel functions for calculating spatial features, encoder, and decoder in multi-channel framework can be effective. We simulate spatialized reverberate data for both WSJ0 and LibriSpeech corpora here, and while these two sets of data are different in the matter of size and duration, the effect of capturing shorter and longer dependencies of previous/+future samples are studied in detail. We report SDR, Si-SNR and PESQ to evaluate the performance of developed solutions.
Beam-Guided TasNet: An Iterative Speech Separation Framework with Multi-Channel Output
Feb 20, 2021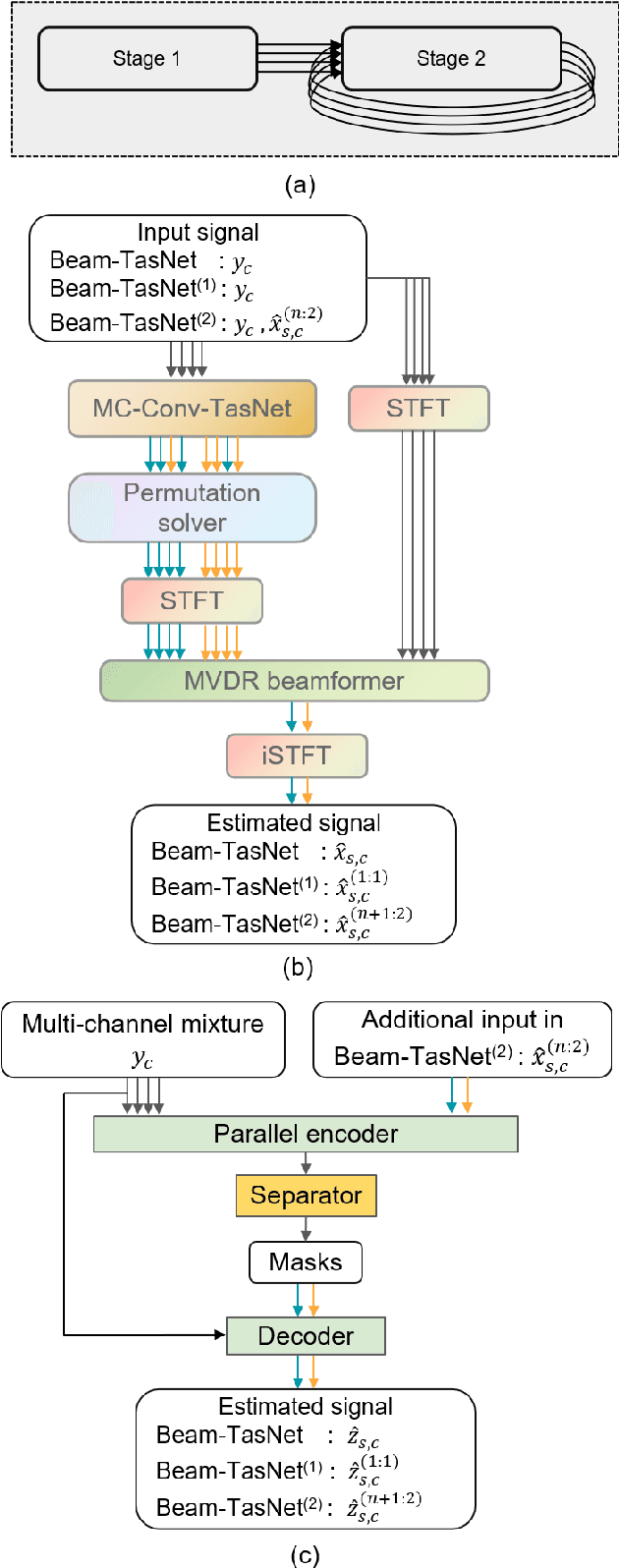
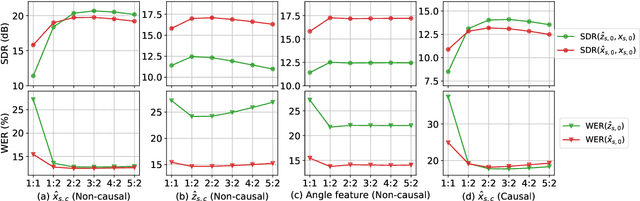
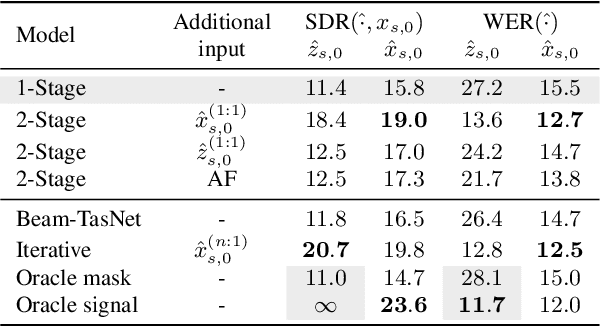
Time-domain audio separation network (TasNet) has achieved remarkable performance in blind source separation (BSS). Classic multi-channel speech processing framework employs signal estimation and beamforming. For example, Beam-TasNet links multi-channel convolutional TasNet (MC-Conv-TasNet) with minimum variance distortionless response (MVDR) beamforming, which leverages the strong modelling ability of data-driven MC-Conv-TasNet and boosts the performance of beamforming with an accurate estimation of speech statistics. Such integration can be viewed as a directed acyclic graph by accepting multi-channel input and generating multi-source output. In this letter, we design a "multi-channel input, multi-channel multi-source output" (MIMMO) speech separation system entitled "Beam-Guided TasNet", where MC-Conv-TasNet and MVDR can interact and promote each other more compactly under a directed cyclic flow. Specifically, the first stage uses Beam-TasNet to generate estimated single-speaker signals, which favours the separation in the second stage. The proposed framework facilitates iterative signal refinement with the guide of beamforming and seeks to reach the upper bound of the MVDR-based methods. Experimental results on the spatialized WSJ0-2MIX demonstrate that the Beam-Guided TasNet has achieved an SDR of 20.7 dB, which exceeded the baseline Beam-TasNet by 4.2 dB under the same model size and narrowed the gap with the oracle signal-based MVDR to 2.9 dB.
Source and Target Bidirectional Knowledge Distillation for End-to-end Speech Translation
Apr 13, 2021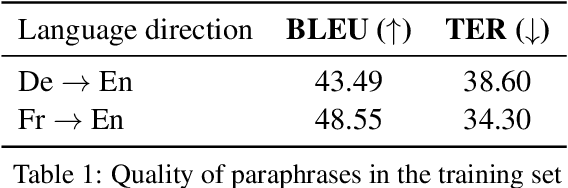
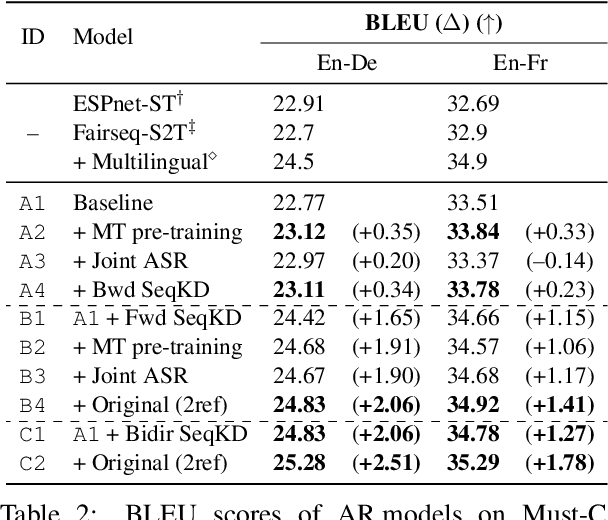
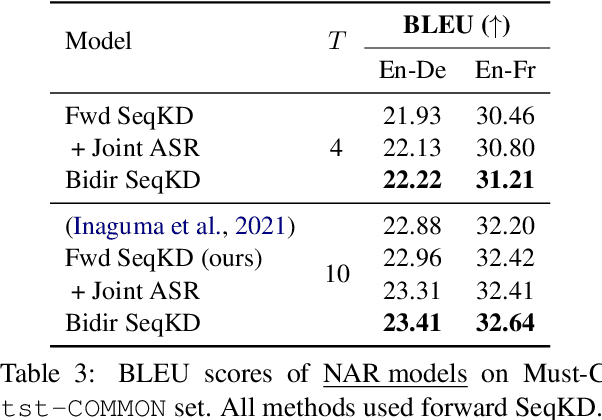
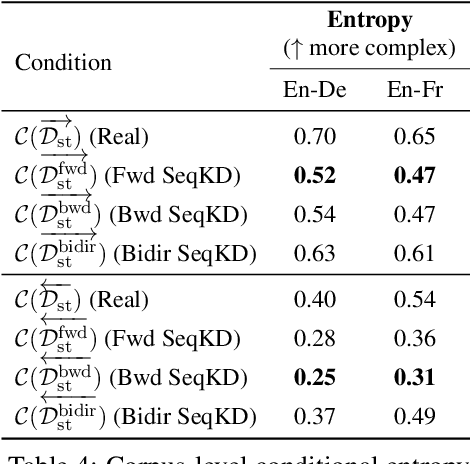
A conventional approach to improving the performance of end-to-end speech translation (E2E-ST) models is to leverage the source transcription via pre-training and joint training with automatic speech recognition (ASR) and neural machine translation (NMT) tasks. However, since the input modalities are different, it is difficult to leverage source language text successfully. In this work, we focus on sequence-level knowledge distillation (SeqKD) from external text-based NMT models. To leverage the full potential of the source language information, we propose backward SeqKD, SeqKD from a target-to-source backward NMT model. To this end, we train a bilingual E2E-ST model to predict paraphrased transcriptions as an auxiliary task with a single decoder. The paraphrases are generated from the translations in bitext via back-translation. We further propose bidirectional SeqKD in which SeqKD from both forward and backward NMT models is combined. Experimental evaluations on both autoregressive and non-autoregressive models show that SeqKD in each direction consistently improves the translation performance, and the effectiveness is complementary regardless of the model capacity.
Dereverberation using joint estimation of dry speech signal and acoustic system
Jul 24, 2020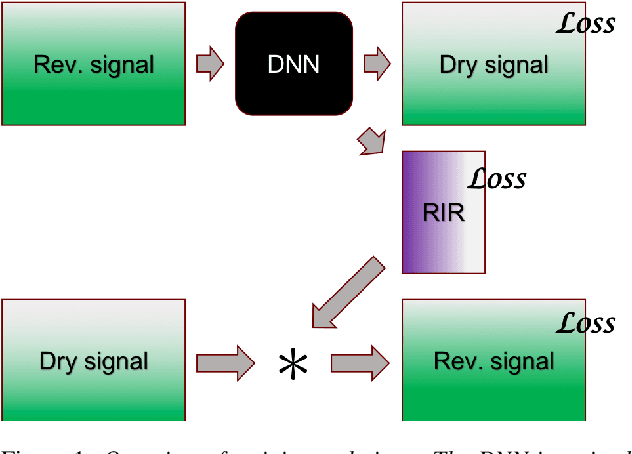
The purpose of speech dereverberation is to remove quality-degrading effects of a time-invariant impulse response filter from the signal. In this report, we describe an approach to speech dereverberation that involves joint estimation of the dry speech signal and of the room impulse response. We explore deep learning models that apply to each task separately, and how these can be combined in a joint model with shared parameters.
Improving the Naturalness of Simulated Conversations for End-to-End Neural Diarization
Apr 24, 2022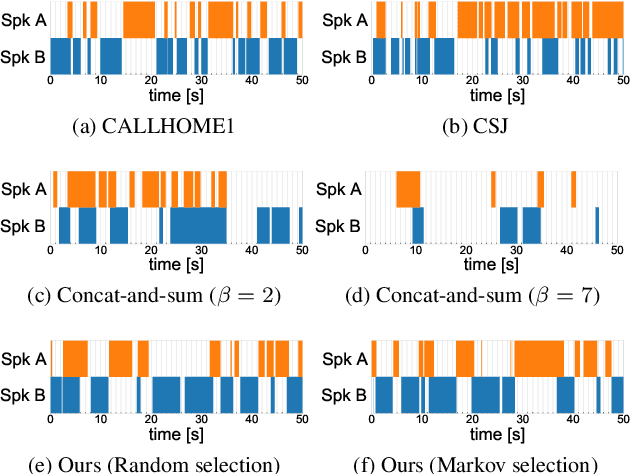
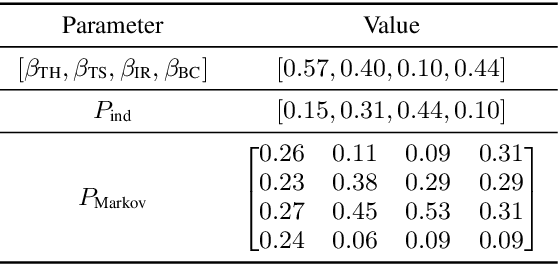
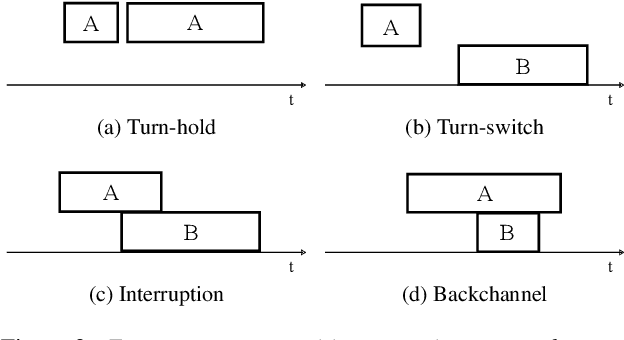
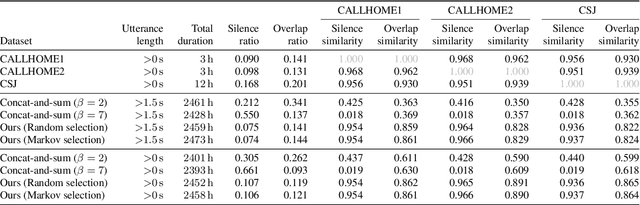
This paper investigates a method for simulating natural conversation in the model training of end-to-end neural diarization (EEND). Due to the lack of any annotated real conversational dataset, EEND is usually pretrained on a large-scale simulated conversational dataset first and then adapted to the target real dataset. Simulated datasets play an essential role in the training of EEND, but as yet there has been insufficient investigation into an optimal simulation method. We thus propose a method to simulate natural conversational speech. In contrast to conventional methods, which simply combine the speech of multiple speakers, our method takes turn-taking into account. We define four types of speaker transition and sequentially arrange them to simulate natural conversations. The dataset simulated using our method was found to be statistically similar to the real dataset in terms of the silence and overlap ratios. The experimental results on two-speaker diarization using the CALLHOME and CSJ datasets showed that the simulated dataset contributes to improving the performance of EEND.
Improving Reverberant Speech Separation with Multi-stage Training and Curriculum Learning
Jul 19, 2021
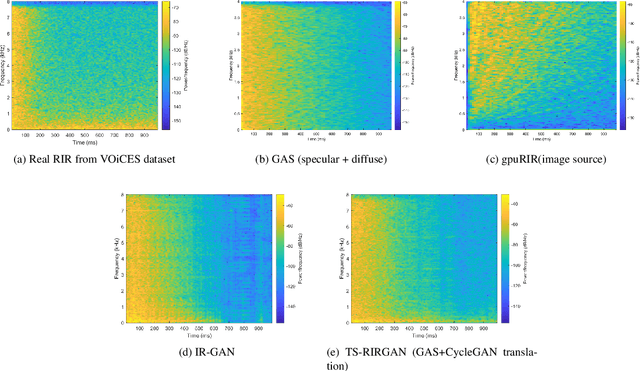
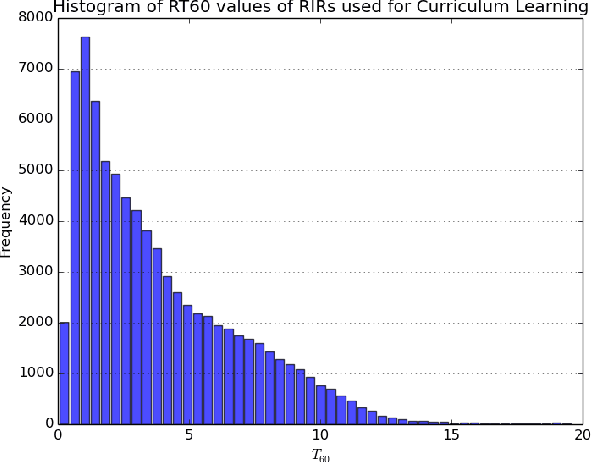
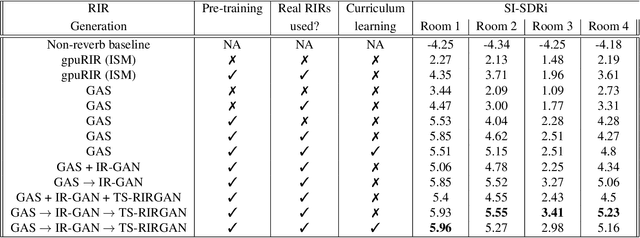
We present a novel approach that improves the performance of reverberant speech separation. Our approach is based on an accurate geometric acoustic simulator (GAS) which generates realistic room impulse responses (RIRs) by modeling both specular and diffuse reflections. We also propose three training methods - pre-training, multi-stage training and curriculum learning that significantly improve separation quality in the presence of reverberation. We also demonstrate that mixing the synthetic RIRs with a small number of real RIRs during training enhances separation performance. We evaluate our approach on reverberant mixtures generated from real, recorded data (in several different room configurations) from the VOiCES dataset. Our novel approach (curriculum learning+pre-training+multi-stage training) results in a significant relative improvement over prior techniques based on image source method (ISM).
Speech-to-Singing Conversion based on Boundary Equilibrium GAN
May 28, 2020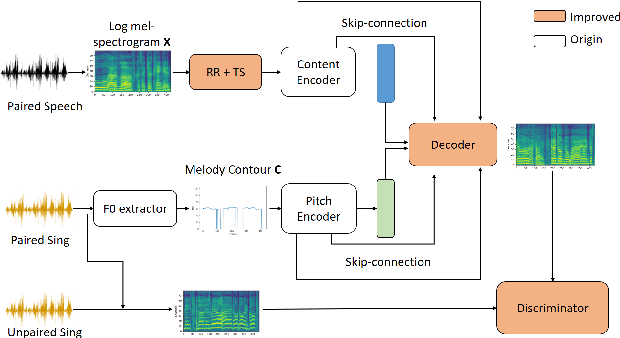
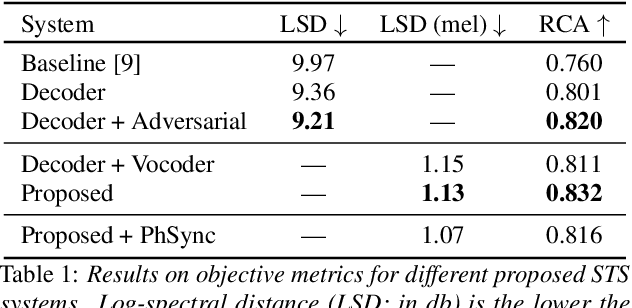
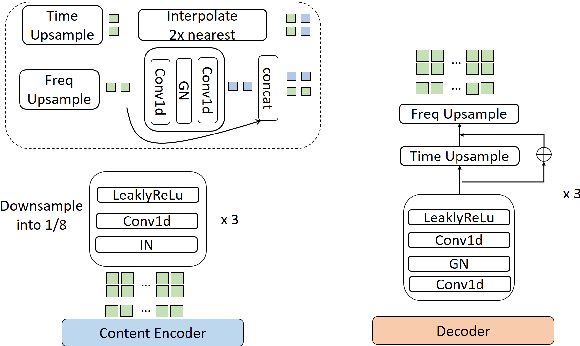
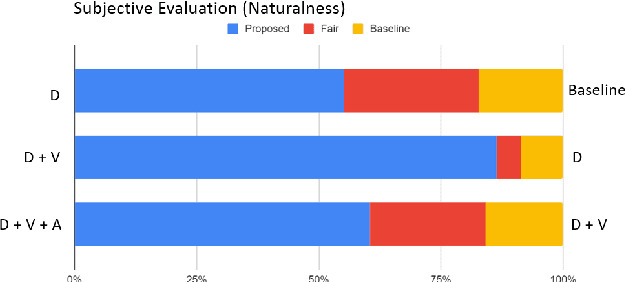
This paper investigates the use of generative adversarial network (GAN)-based models for converting the spectrogram of a speech signal into that of a singing one, without reference to the phoneme sequence underlying the speech. This is achieved by viewing speech-to-singing conversion as a style transfer problem. Specifically, given a speech input, and optionally the F0 contour of the target singing, the proposed model generates as the output a singing signal with a progressive-growing encoder/decoder architecture and boundary equilibrium GAN loss functions. Our quantitative and qualitative analysis show that the proposed model generates singing voices with much higher naturalness than an existing non adversarially-trained baseline. For reproducibility, the code will be publicly available at a GitHub repository upon paper publication.
Interpretable Dysarthric Speaker Adaptation based on Optimal-Transport
Mar 14, 2022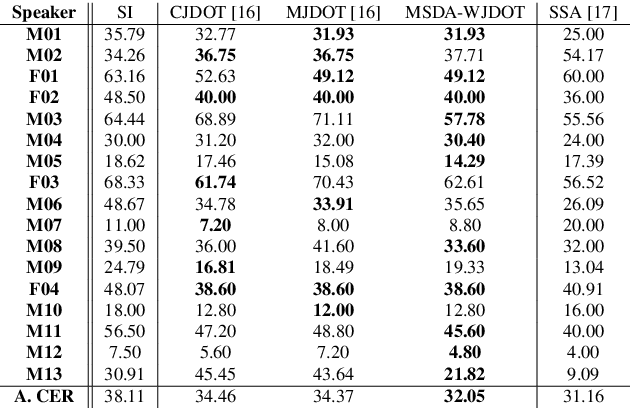
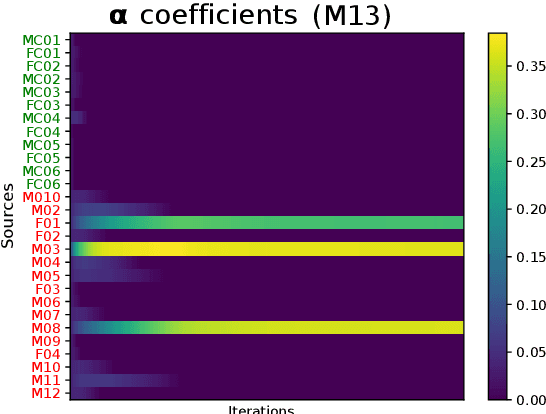
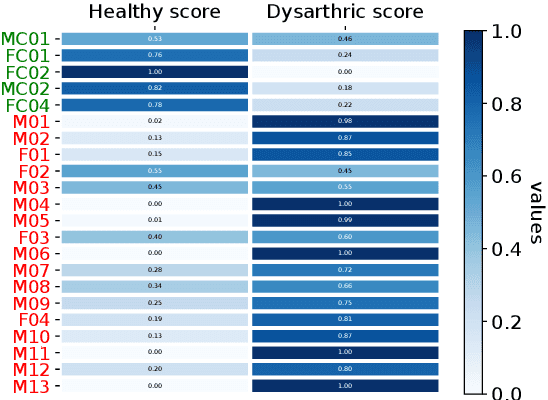
This work addresses the mismatch problem between the distribution of training data (source) and testing data (target), in the challenging context of dysarthric speech recognition. We focus on Speaker Adaptation (SA) in command speech recognition, where data from multiple sources (i.e., multiple speakers) are available. Specifically, we propose an unsupervised Multi-Source Domain Adaptation (MSDA) algorithm based on optimal-transport, called MSDA via Weighted Joint Optimal Transport (MSDA-WJDOT). We achieve a Command Error Rate relative reduction of 16% and 7% over the speaker-independent model and the best competitor method, respectively. The strength of the proposed approach is that, differently from any other existing SA method, it offers an interpretable model that can also be exploited, in this context, to diagnose dysarthria without any specific training. Indeed, it provides a closeness measure between the target and the source speakers, reflecting their similarity in terms of speech characteristics. Based on the similarity between the target speaker and the healthy/dysarthric source speakers, we then define the healthy/dysarthric score of the target speaker that we leverage to perform dysarthria detection. This approach does not require any additional training and achieves a 95% accuracy in the dysarthria diagnosis.
A Light-weight contextual spelling correction model for customizing transducer-based speech recognition systems
Aug 17, 2021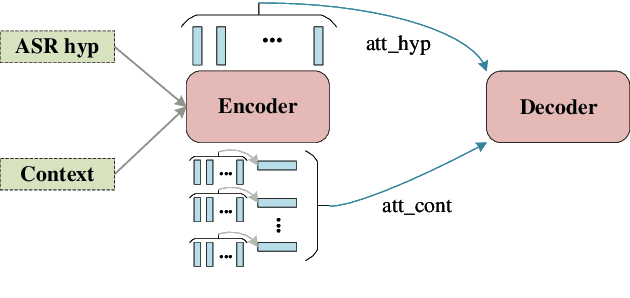


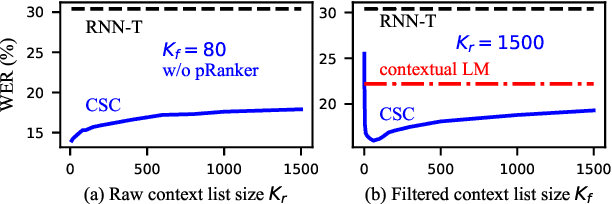
It's challenging to customize transducer-based automatic speech recognition (ASR) system with context information which is dynamic and unavailable during model training. In this work, we introduce a light-weight contextual spelling correction model to correct context-related recognition errors in transducer-based ASR systems. We incorporate the context information into the spelling correction model with a shared context encoder and use a filtering algorithm to handle large-size context lists. Experiments show that the model improves baseline ASR model performance with about 50% relative word error rate reduction, which also significantly outperforms the baseline method such as contextual LM biasing. The model also shows excellent performance for out-of-vocabulary terms not seen during training.