 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
C3-DINO: Joint Contrastive and Non-contrastive Self-Supervised Learning for Speaker Verification
Aug 15, 2022
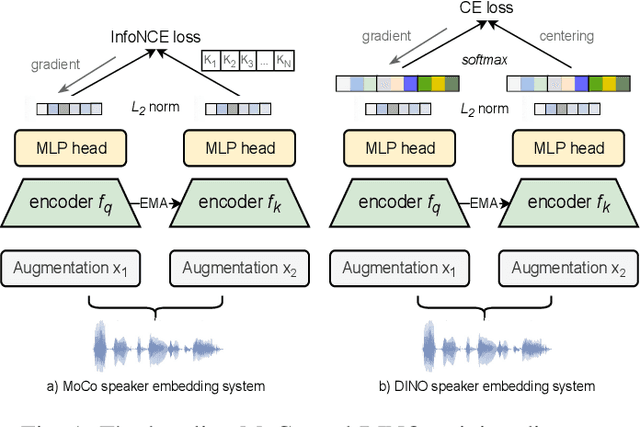
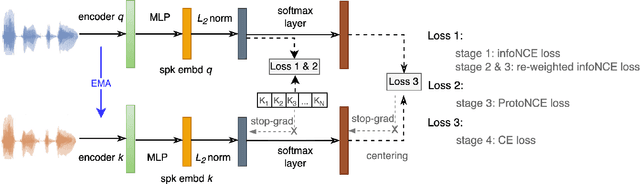
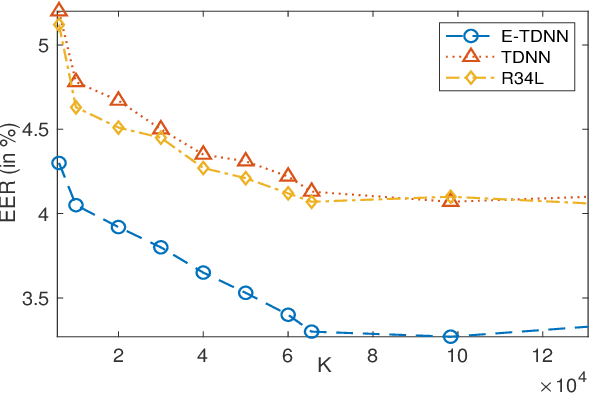
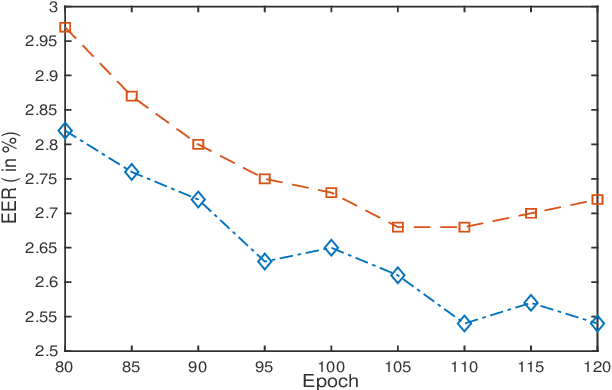
Self-supervised learning (SSL) has drawn an increased attention in the field of speech processing. Recent studies have demonstrated that contrastive learning is able to learn discriminative speaker embeddings in a self-supervised manner. However, base contrastive self-supervised learning (CSSL) assumes that the pairs generated from a view of anchor instance and any view of other instances are all negative, which introduces many false negative pairs in constructing the loss function. The problem is referred as $class$-$collision$, which remains as one major issue that impedes the CSSL based speaker verification (SV) systems from achieving better performances. In the meanwhile, studies reveal that negative sample free SSL frameworks perform well in learning speaker or image representations. In this study, we investigate SSL techniques that lead to an improved SV performance. We first analyse the impact of false negative pairs in the CSSL systems. Then, a multi-stage Class-Collision Correction (C3) method is proposed, which leads to the state-of-the-art CSSL based speaker embedding system. On the basis of the pretrained CSSL model, we further propose to employ a negative sample free SSL objective (i.e., DINO) to fine-tune the speaker embedding network. The resulting speaker embedding system (C3-DINO) achieves 2.5% EER with a simple Cosine Distance Scoring method on Voxceleb1 test set, which outperforms the previous SOTA SSL system (4.86%) by a significant +45% relative improvement. With speaker clustering and pseudo labeling on Voxceleb2 training set, a LDA/CDS back-end applying on the C3-DINO speaker embeddings is able to further push the EER to 2.2%. Comprehensive experimental investigations of the Voxceleb benchmarks and our internal dataset demonstrate the effectiveness of our proposed methods, and the performance gap between the SSL SV and the supervised counterpart narrows further.
Sequence-to-Sequence Learning via Attention Transfer for Incremental Speech Recognition
Nov 04, 2020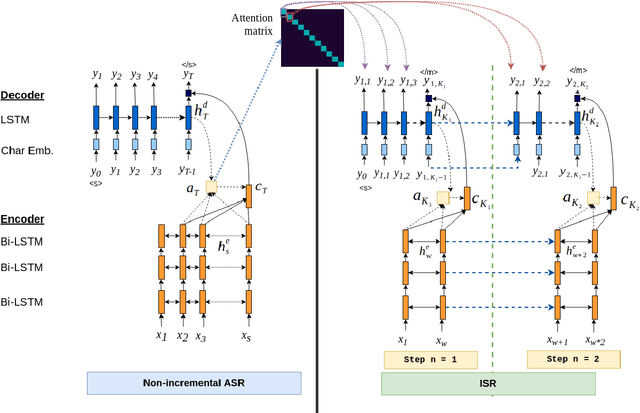
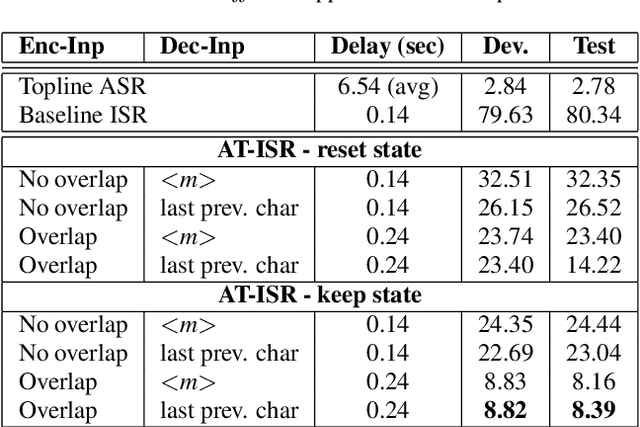
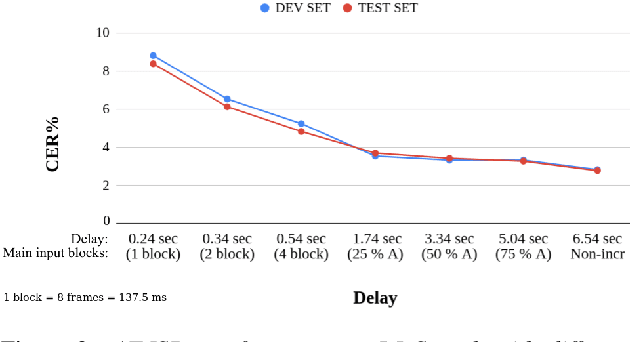
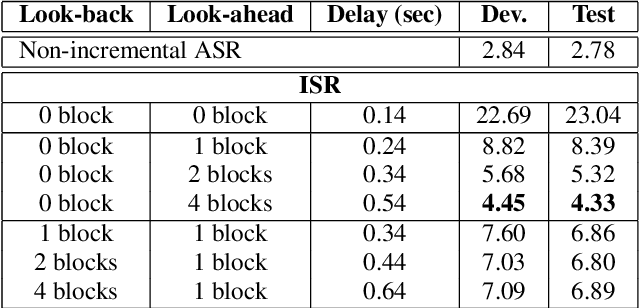
Attention-based sequence-to-sequence automatic speech recognition (ASR) requires a significant delay to recognize long utterances because the output is generated after receiving entire input sequences. Although several studies recently proposed sequence mechanisms for incremental speech recognition (ISR), using different frameworks and learning algorithms is more complicated than the standard ASR model. One main reason is because the model needs to decide the incremental steps and learn the transcription that aligns with the current short speech segment. In this work, we investigate whether it is possible to employ the original architecture of attention-based ASR for ISR tasks by treating a full-utterance ASR as the teacher model and the ISR as the student model. We design an alternative student network that, instead of using a thinner or a shallower model, keeps the original architecture of the teacher model but with shorter sequences (few encoder and decoder states). Using attention transfer, the student network learns to mimic the same alignment between the current input short speech segments and the transcription. Our experiments show that by delaying the starting time of recognition process with about 1.7 sec, we can achieve comparable performance to one that needs to wait until the end.
Streaming non-autoregressive model for any-to-many voice conversion
Jun 15, 2022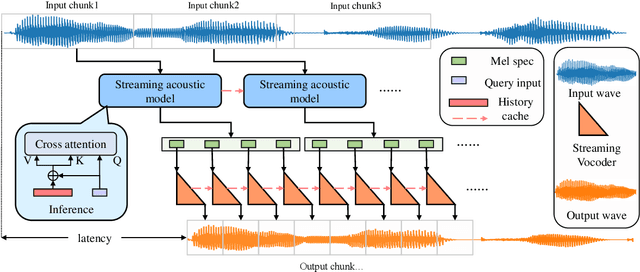
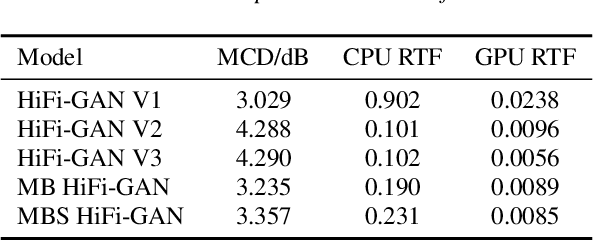
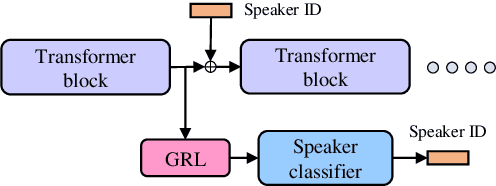
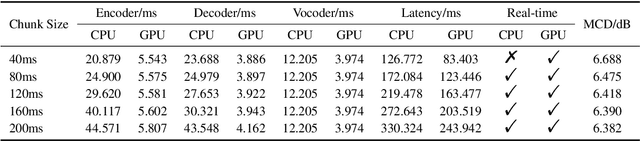
Voice conversion models have developed for decades, and current mainstream research focuses on non-streaming voice conversion. However, streaming voice conversion is more suitable for practical application scenarios than non-streaming voice conversion. In this paper, we propose a streaming any-to-many voice conversion based on fully non-autoregressive model, which includes a streaming transformer based acoustic model and a streaming vocoder. Streaming transformer based acoustic model is composed of a pre-trained encoder from streaming end-to-end based automatic speech recognition model and a decoder modified on FastSpeech blocks. Streaming vocoder is designed for streaming task with pseudo quadrature mirror filter bank and causal convolution. Experimental results show that the proposed method achieves significant performance both in latency and conversion quality and can be real-time on CPU and GPU.
The VoicePrivacy 2020 Challenge Evaluation Plan
May 14, 2022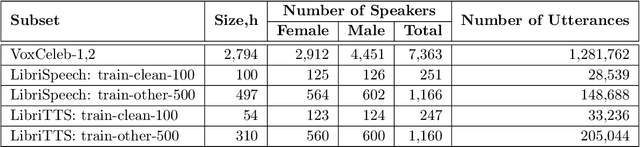
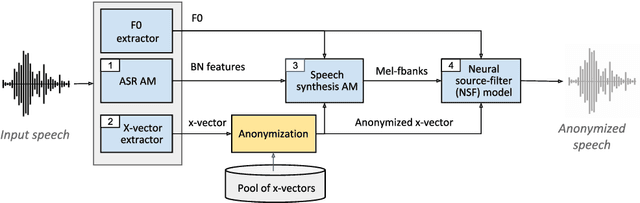
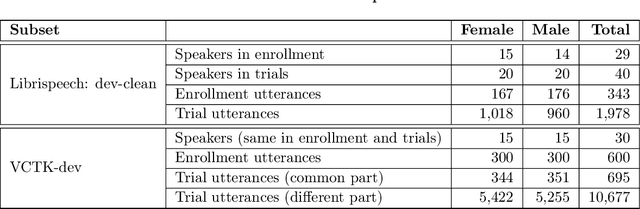
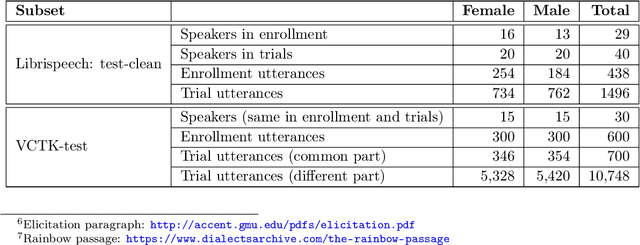
The VoicePrivacy Challenge aims to promote the development of privacy preservation tools for speech technology by gathering a new community to define the tasks of interest and the evaluation methodology, and benchmarking solutions through a series of challenges. In this document, we formulate the voice anonymization task selected for the VoicePrivacy 2020 Challenge and describe the datasets used for system development and evaluation. We also present the attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and report objective evaluation results.
An exhaustive variable selection study for linear models of soundscape emotions: rankings and Gibbs analysis
Jul 26, 2022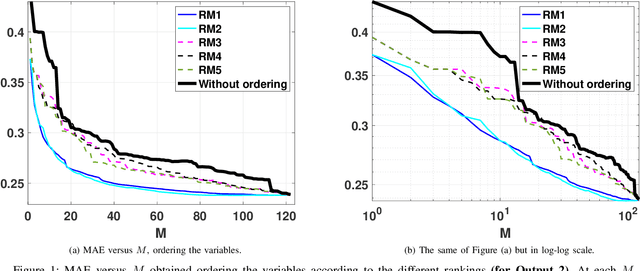
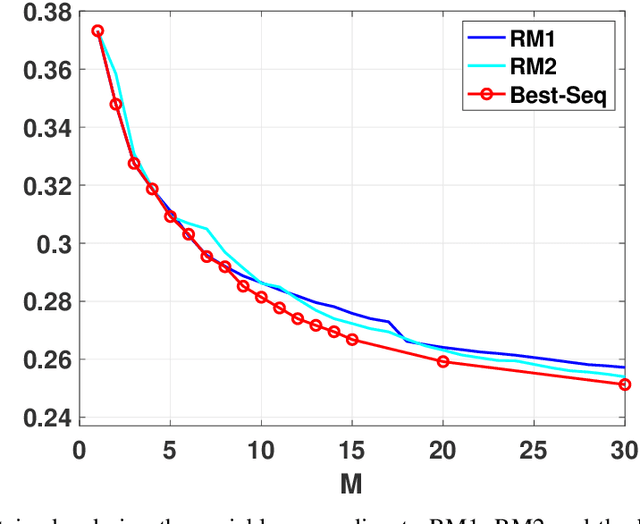
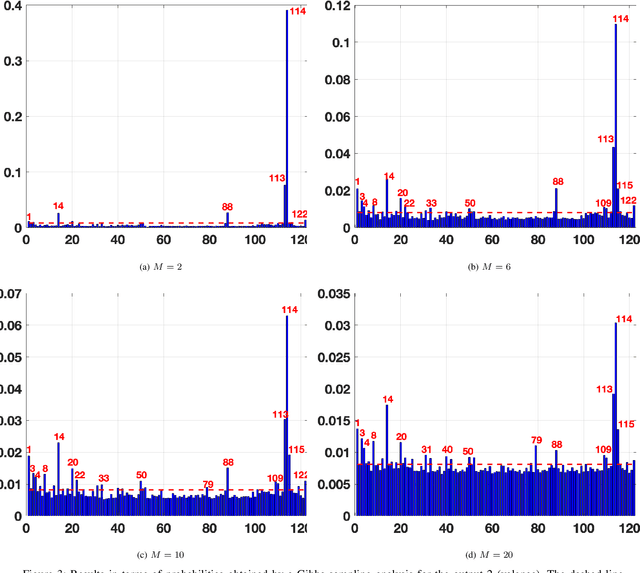

In the last decade, soundscapes have become one of the most active topics in Acoustics, providing a holistic approach to the acoustic environment, which involves human perception and context. Soundscapes-elicited emotions are central and substantially subtle and unnoticed (compared to speech or music). Currently, soundscape emotion recognition is a very active topic in the literature. We provide an exhaustive variable selection study (i.e., a selection of the soundscapes indicators) to a well-known dataset (emo-soundscapes). We consider linear soundscape emotion models for two soundscapes descriptors: arousal and valence. Several ranking schemes and procedures for selecting the number of variables are applied. We have also performed an alternating optimization scheme for obtaining the best sequences keeping fixed a certain number of features. Furthermore, we have designed a novel technique based on Gibbs sampling, which provides a more complete and clear view of the relevance of each variable. Finally, we have also compared our results with the analysis obtained by the classical methods based on p-values. As a result of our study, we suggest two simple and parsimonious linear models of only 7 and 16 variables (within the 122 possible features) for the two outputs (arousal and valence), respectively. The suggested linear models provide very good and competitive performance, with $R^2>0.86$ and $R^2>0.63$ (values obtained after a cross-validation procedure), respectively.
* published in IEEE-ACM Transactions on Audio, Speech and Language Processing
Personalized Keyword Spotting through Multi-task Learning
Jun 28, 2022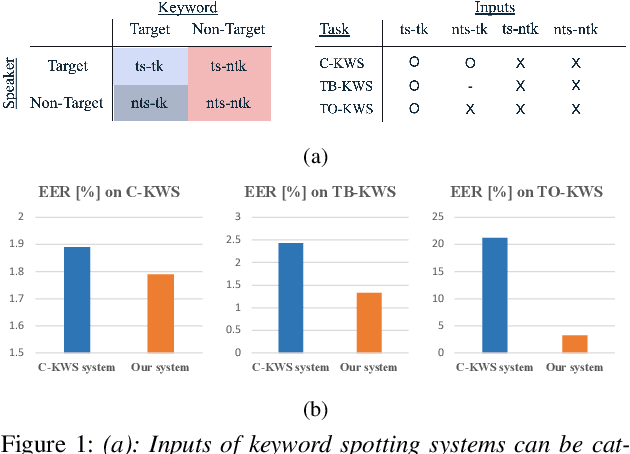
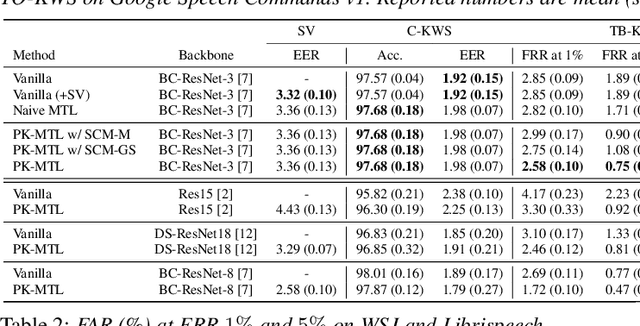
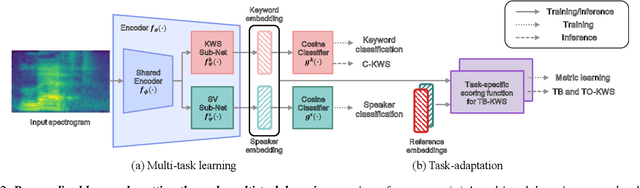
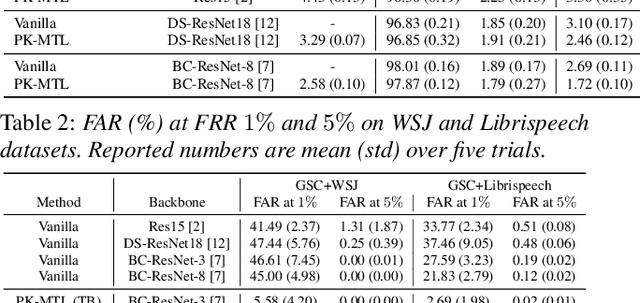
Keyword spotting (KWS) plays an essential role in enabling speech-based user interaction on smart devices, and conventional KWS (C-KWS) approaches have concentrated on detecting user-agnostic pre-defined keywords. However, in practice, most user interactions come from target users enrolled in the device which motivates to construct personalized keyword spotting. We design two personalized KWS tasks; (1) Target user Biased KWS (TB-KWS) and (2) Target user Only KWS (TO-KWS). To solve the tasks, we propose personalized keyword spotting through multi-task learning (PK-MTL) that consists of multi-task learning and task-adaptation. First, we introduce applying multi-task learning on keyword spotting and speaker verification to leverage user information to the keyword spotting system. Next, we design task-specific scoring functions to adapt to the personalized KWS tasks thoroughly. We evaluate our framework on conventional and personalized scenarios, and the results show that PK-MTL can dramatically reduce the false alarm rate, especially in various practical scenarios.
Speech-to-Singing Conversion based on Boundary Equilibrium GAN
May 30, 2020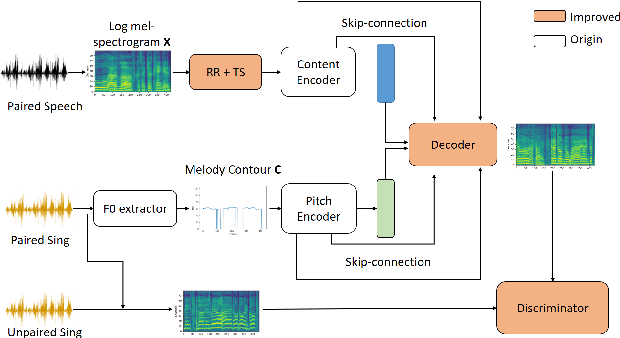
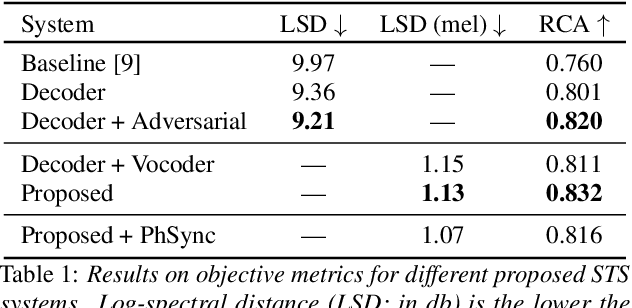
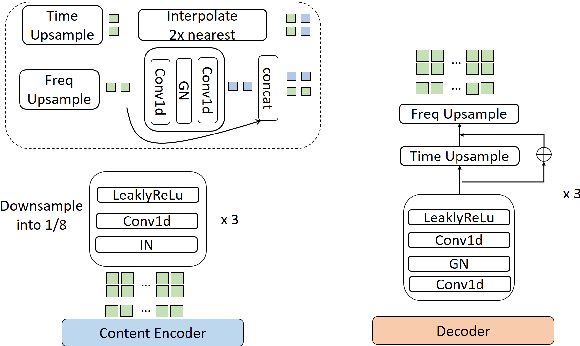
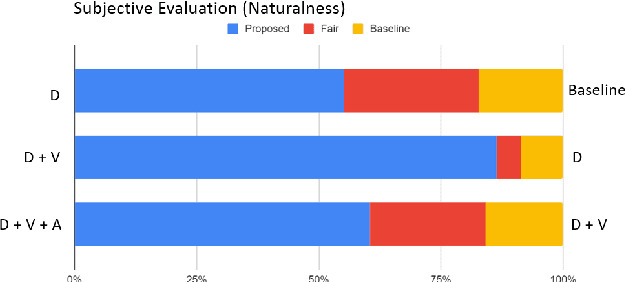
This paper investigates the use of generative adversarial network (GAN)-based models for converting the spectrogram of a speech signal into that of a singing one, without reference to the phoneme sequence underlying the speech. This is achieved by viewing speech-to-singing conversion as a style transfer problem. Specifically, given a speech input, and optionally the F0 contour of the target singing, the proposed model generates as the output a singing signal with a progressive-growing encoder/decoder architecture and boundary equilibrium GAN loss functions. Our quantitative and qualitative analysis show that the proposed model generates singing voices with much higher naturalness than an existing non adversarially-trained baseline. For reproducibility, the code will be publicly available at a GitHub repository upon paper publication.
Meta-Transfer Learning for Code-Switched Speech Recognition
Apr 29, 2020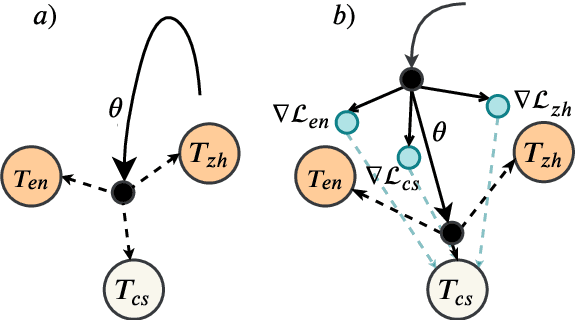
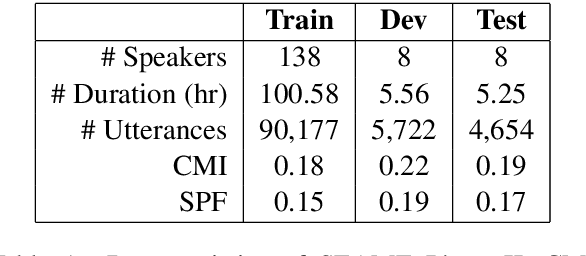
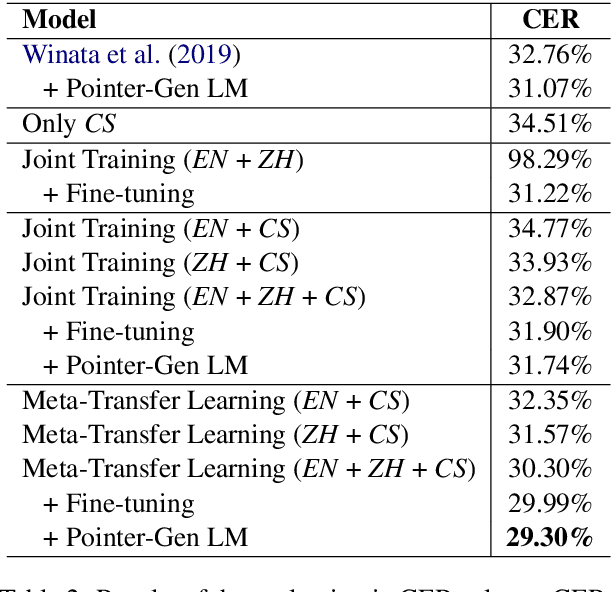
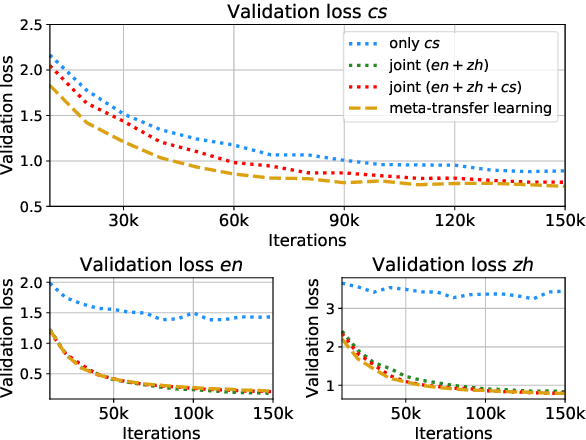
An increasing number of people in the world today speak a mixed-language as a result of being multilingual. However, building a speech recognition system for code-switching remains difficult due to the availability of limited resources and the expense and significant effort required to collect mixed-language data. We therefore propose a new learning method, meta-transfer learning, to transfer learn on a code-switched speech recognition system in a low-resource setting by judiciously extracting information from high-resource monolingual datasets. Our model learns to recognize individual languages, and transfer them so as to better recognize mixed-language speech by conditioning the optimization on the code-switching data. Based on experimental results, our model outperforms existing baselines on speech recognition and language modeling tasks, and is faster to converge.
Deep Time Delay Neural Network for Speech Enhancement with Full Data Learning
Nov 11, 2020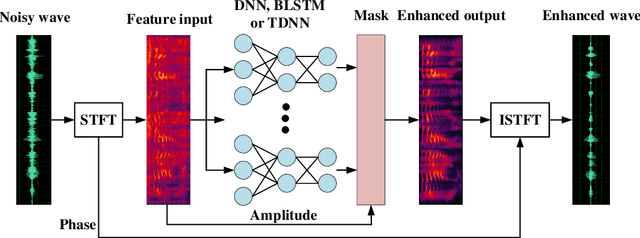
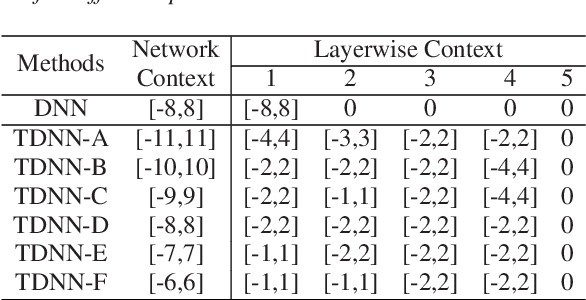
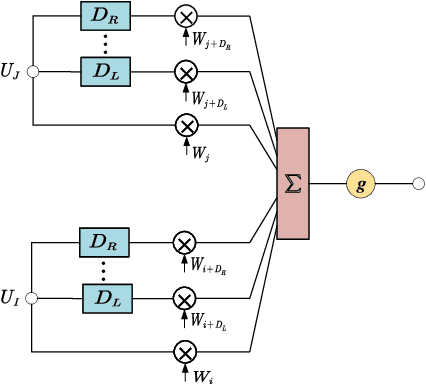
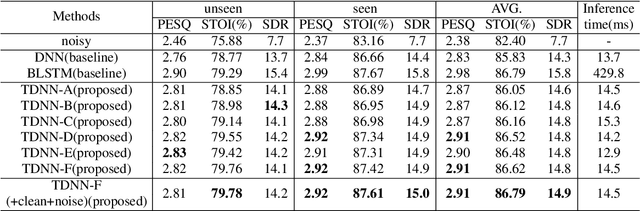
Recurrent neural networks (RNNs) have shown significant improvements in recent years for speech enhancement. However, the model complexity and inference time cost of RNNs are much higher than deep feed-forward neural networks (DNNs). Therefore, these limit the applications of speech enhancement. This paper proposes a deep time delay neural network (TDNN) for speech enhancement with full data learning. The TDNN has excellent potential for capturing long range temporal contexts, which utilizes a modular and incremental design. Besides, the TDNN preserves the feed-forward structure so that its inference cost is comparable to standard DNN. To make full use of the training data, we propose a full data learning method for speech enhancement. More specifically, we not only use the noisy-to-clean (input-to-target) to train the enhanced model, but also the clean-to-clean and noise-to-silence data. Therefore, all of the training data can be used to train the enhanced model. Our experiments are conducted on TIMIT dataset. Experimental results show that our proposed method could achieve a better performance than DNN and comparable even better performance than BLSTM. Meanwhile, compared with the BLSTM, the proposed method drastically reduce the inference time.
Finnish Parliament ASR corpus - Analysis, benchmarks and statistics
Mar 28, 2022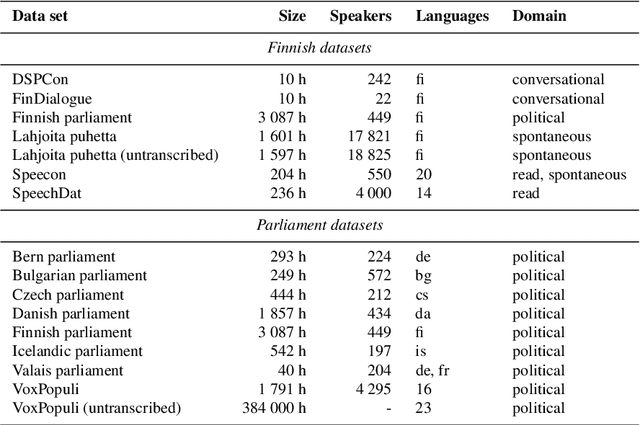
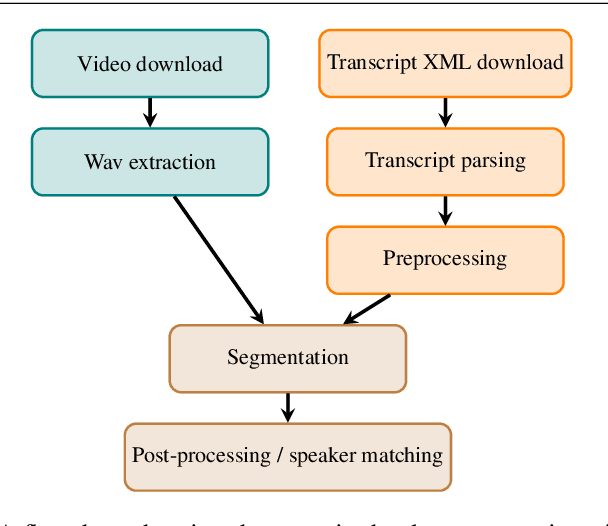

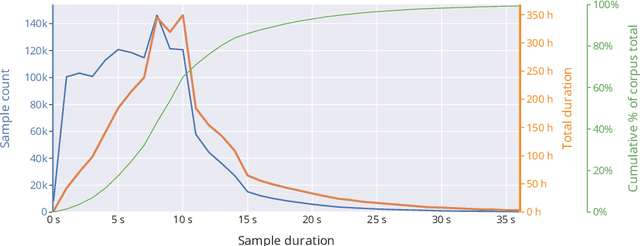
Public sources like parliament meeting recordings and transcripts provide ever-growing material for the training and evaluation of automatic speech recognition (ASR) systems. In this paper, we publish and analyse the Finnish parliament ASR corpus, the largest publicly available collection of manually transcribed speech data for Finnish with over 3000 hours of speech and 449 speakers for which it provides rich demographic metadata. This corpus builds on earlier initial work, and as a result the corpus has a natural split into two training subsets from two periods of time. Similarly, there are two official, corrected test sets covering different times, setting an ASR task with longitudinal distribution-shift characteristics. An official development set is also provided. We develop a complete Kaldi-based data preparation pipeline, and hidden Markov model (HMM), hybrid deep neural network (HMM-DNN) and attention-based encoder-decoder (AED) ASR recipes. We set benchmarks on the official test sets, as well as multiple other recently used test sets. Both temporal corpus subsets are already large, and we observe that beyond their scale, ASR performance on the official test sets plateaus, whereas other domains benefit from added data. The HMM-DNN and AED approaches are compared in a carefully matched equal data setting, with the HMM-DNN system consistently performing better. Finally, the variation of the ASR accuracy is compared between the speaker categories available in the parliament metadata to detect potential biases based on factors such as gender, age, and education.