 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
On Robustness to Missing Video for Audiovisual Speech Recognition
Dec 19, 2023
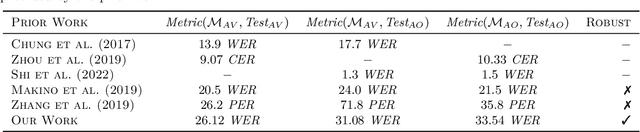
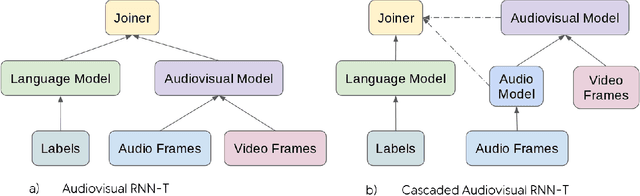
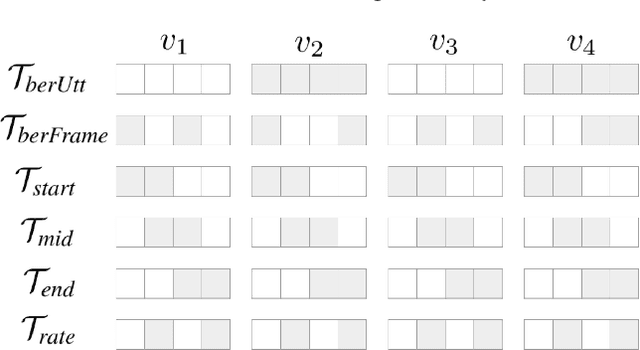
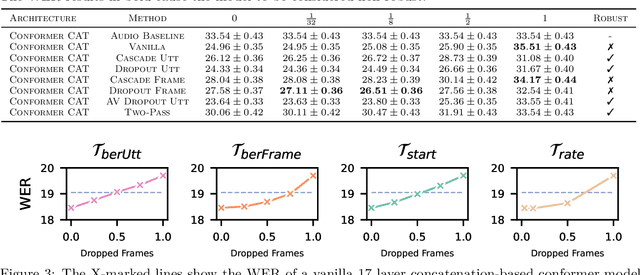
It has been shown that learning audiovisual features can lead to improved speech recognition performance over audio-only features, especially for noisy speech. However, in many common applications, the visual features are partially or entirely missing, e.g.~the speaker might move off screen. Multi-modal models need to be robust: missing video frames should not degrade the performance of an audiovisual model to be worse than that of a single-modality audio-only model. While there have been many attempts at building robust models, there is little consensus on how robustness should be evaluated. To address this, we introduce a framework that allows claims about robustness to be evaluated in a precise and testable way. We also conduct a systematic empirical study of the robustness of common audiovisual speech recognition architectures on a range of acoustic noise conditions and test suites. Finally, we show that an architecture-agnostic solution based on cascades can consistently achieve robustness to missing video, even in settings where existing techniques for robustness like dropout fall short.
An Integration of Pre-Trained Speech and Language Models for End-to-End Speech Recognition
Dec 06, 2023Advances in machine learning have made it possible to perform various text and speech processing tasks, including automatic speech recognition (ASR), in an end-to-end (E2E) manner. Since typical E2E approaches require large amounts of training data and resources, leveraging pre-trained foundation models instead of training from scratch is gaining attention. Although there have been attempts to use pre-trained speech and language models in ASR, most of them are limited to using either. This paper explores the potential of integrating a pre-trained speech representation model with a large language model (LLM) for E2E ASR. The proposed model enables E2E ASR by generating text tokens in an autoregressive manner via speech representations as speech prompts, taking advantage of the vast knowledge provided by the LLM. Furthermore, the proposed model can incorporate remarkable developments for LLM utilization, such as inference optimization and parameter-efficient domain adaptation. Experimental results show that the proposed model achieves performance comparable to modern E2E ASR models.
On Speaker Attribution with SURT
Jan 28, 2024The Streaming Unmixing and Recognition Transducer (SURT) has recently become a popular framework for continuous, streaming, multi-talker speech recognition (ASR). With advances in architecture, objectives, and mixture simulation methods, it was demonstrated that SURT can be an efficient streaming method for speaker-agnostic transcription of real meetings. In this work, we push this framework further by proposing methods to perform speaker-attributed transcription with SURT, for both short mixtures and long recordings. We achieve this by adding an auxiliary speaker branch to SURT, and synchronizing its label prediction with ASR token prediction through HAT-style blank factorization. In order to ensure consistency in relative speaker labels across different utterance groups in a recording, we propose "speaker prefixing" -- appending each chunk with high-confidence frames of speakers identified in previous chunks, to establish the relative order. We perform extensive ablation experiments on synthetic LibriSpeech mixtures to validate our design choices, and demonstrate the efficacy of our final model on the AMI corpus.
A Proactive and Dual Prevention Mechanism against Illegal Song Covers empowered by Singing Voice Conversion
Jan 30, 2024Singing voice conversion (SVC) automates song covers by converting one singer's singing voice into another target singer's singing voice with the original lyrics and melody. However, it raises serious concerns about copyright and civil right infringements to multiple entities. This work proposes SongBsAb, the first proactive approach to mitigate unauthorized SVC-based illegal song covers. SongBsAb introduces human-imperceptible perturbations to singing voices before releasing them, so that when they are used, the generation process of SVC will be interfered, resulting in unexpected singing voices. SongBsAb features a dual prevention effect by causing both (singer) identity disruption and lyric disruption, namely, the SVC-covered singing voice neither imitates the target singer nor preserves the original lyrics. To improve the imperceptibility of perturbations, we refine a psychoacoustic model-based loss with the backing track as an additional masker, a unique accompanying element for singing voices compared to ordinary speech voices. To enhance the transferability, we propose to utilize a frame-level interaction reduction-based loss. We demonstrate the prevention effectiveness, utility, and robustness of SongBsAb on three SVC models and two datasets using both objective and human study-based subjective metrics. Our work fosters an emerging research direction for mitigating illegal automated song covers.
Seq2seq for Automatic Paraphasia Detection in Aphasic Speech
Dec 16, 2023Paraphasias are speech errors that are often characteristic of aphasia and they represent an important signal in assessing disease severity and subtype. Traditionally, clinicians manually identify paraphasias by transcribing and analyzing speech-language samples, which can be a time-consuming and burdensome process. Identifying paraphasias automatically can greatly help clinicians with the transcription process and ultimately facilitate more efficient and consistent aphasia assessment. Previous research has demonstrated the feasibility of automatic paraphasia detection by training an automatic speech recognition (ASR) model to extract transcripts and then training a separate paraphasia detection model on a set of hand-engineered features. In this paper, we propose a novel, sequence-to-sequence (seq2seq) model that is trained end-to-end (E2E) to perform both ASR and paraphasia detection tasks. We show that the proposed model outperforms the previous state-of-the-art approach for both word-level and utterance-level paraphasia detection tasks and provide additional follow-up evaluations to further understand the proposed model behavior.
Stimulus-Informed Generalized Canonical Correlation Analysis for Group Analysis of Neural Responses
Jan 31, 2024Various new brain-computer interface technologies or neuroscience applications require decoding stimulus-following neural responses to natural stimuli such as speech and video from, e.g., electroencephalography (EEG) signals. In this context, generalized canonical correlation analysis (GCCA) is often used as a group analysis technique, which allows the extraction of correlated signal components from the neural activity of multiple subjects attending to the same stimulus. GCCA can be used to improve the signal-to-noise ratio of the stimulus-following neural responses relative to all other irrelevant (non-)neural activity, or to quantify the correlated neural activity across multiple subjects in a group-wise coherence metric. However, the traditional GCCA technique is stimulus-unaware: no information about the stimulus is used to estimate the correlated components from the neural data of several subjects. Therefore, the GCCA technique might fail to extract relevant correlated signal components in practical situations where the amount of information is limited, for example, because of a limited amount of training data or group size. This motivates a new stimulus-informed GCCA (SI-GCCA) framework that allows taking the stimulus into account to extract the correlated components. We show that SI-GCCA outperforms GCCA in various practical settings, for both auditory and visual stimuli. Moreover, we showcase how SI-GCCA can be used to steer the estimation of the components towards the stimulus. As such, SI-GCCA substantially improves upon GCCA for various purposes, ranging from preprocessing to quantifying attention.
NeRF-AD: Neural Radiance Field with Attention-based Disentanglement for Talking Face Synthesis
Jan 23, 2024Talking face synthesis driven by audio is one of the current research hotspots in the fields of multidimensional signal processing and multimedia. Neural Radiance Field (NeRF) has recently been brought to this research field in order to enhance the realism and 3D effect of the generated faces. However, most existing NeRF-based methods either burden NeRF with complex learning tasks while lacking methods for supervised multimodal feature fusion, or cannot precisely map audio to the facial region related to speech movements. These reasons ultimately result in existing methods generating inaccurate lip shapes. This paper moves a portion of NeRF learning tasks ahead and proposes a talking face synthesis method via NeRF with attention-based disentanglement (NeRF-AD). In particular, an Attention-based Disentanglement module is introduced to disentangle the face into Audio-face and Identity-face using speech-related facial action unit (AU) information. To precisely regulate how audio affects the talking face, we only fuse the Audio-face with audio feature. In addition, AU information is also utilized to supervise the fusion of these two modalities. Extensive qualitative and quantitative experiments demonstrate that our NeRF-AD outperforms state-of-the-art methods in generating realistic talking face videos, including image quality and lip synchronization. To view video results, please refer to https://xiaoxingliu02.github.io/NeRF-AD.
A RAG-based Question Answering System Proposal for Understanding Islam: MufassirQAS LLM
Feb 01, 2024Challenges exist in learning and understanding religions, such as the complexity and depth of religious doctrines and teachings. Chatbots as question-answering systems can help in solving these challenges. LLM chatbots use NLP techniques to establish connections between topics and accurately respond to complex questions. These capabilities make it perfect for enlightenment on religion as a question-answering chatbot. However, LLMs also tend to generate false information, known as hallucination. Also, the chatbots' responses can include content that insults personal religious beliefs, interfaith conflicts, and controversial or sensitive topics. It must avoid such cases without promoting hate speech or offending certain groups of people or their beliefs. This study uses a vector database-based Retrieval Augmented Generation (RAG) approach to enhance the accuracy and transparency of LLMs. Our question-answering system is called "MufassirQAS". We created a database consisting of several open-access books that include Turkish context. These books contain Turkish translations and interpretations of Islam. This database is utilized to answer religion-related questions and ensure our answers are trustworthy. The relevant part of the dataset, which LLM also uses, is presented along with the answer. We have put careful effort into creating system prompts that give instructions to prevent harmful, offensive, or disrespectful responses to respect people's values and provide reliable results. The system answers and shares additional information, such as the page number from the respective book and the articles referenced for obtaining the information. MufassirQAS and ChatGPT are also tested with sensitive questions. We got better performance with our system. Study and enhancements are still in progress. Results and future works are given.
ToPro: Token-Level Prompt Decomposition for Cross-Lingual Sequence Labeling Tasks
Jan 29, 2024Prompt-based methods have been successfully applied to multilingual pretrained language models for zero-shot cross-lingual understanding. However, most previous studies primarily focused on sentence-level classification tasks, and only a few considered token-level labeling tasks such as Named Entity Recognition (NER) and Part-of-Speech (POS) tagging. In this paper, we propose Token-Level Prompt Decomposition (ToPro), which facilitates the prompt-based method for token-level sequence labeling tasks. The ToPro method decomposes an input sentence into single tokens and applies one prompt template to each token. Our experiments on multilingual NER and POS tagging datasets demonstrate that ToPro-based fine-tuning outperforms Vanilla fine-tuning and Prompt-Tuning in zero-shot cross-lingual transfer, especially for languages that are typologically different from the source language English. Our method also attains state-of-the-art performance when employed with the mT5 model. Besides, our exploratory study in multilingual large language models shows that ToPro performs much better than the current in-context learning method. Overall, the performance improvements show that ToPro could potentially serve as a novel and simple benchmarking method for sequence labeling tasks.
Cascaded Cross-Modal Transformer for Audio-Textual Classification
Jan 15, 2024Speech classification tasks often require powerful language understanding models to grasp useful features, which becomes problematic when limited training data is available. To attain superior classification performance, we propose to harness the inherent value of multimodal representations by transcribing speech using automatic speech recognition (ASR) models and translating the transcripts into different languages via pretrained translation models. We thus obtain an audio-textual (multimodal) representation for each data sample. Subsequently, we combine language-specific Bidirectional Encoder Representations from Transformers (BERT) with Wav2Vec2.0 audio features via a novel cascaded cross-modal transformer (CCMT). Our model is based on two cascaded transformer blocks. The first one combines text-specific features from distinct languages, while the second one combines acoustic features with multilingual features previously learned by the first transformer block. We employed our system in the Requests Sub-Challenge of the ACM Multimedia 2023 Computational Paralinguistics Challenge. CCMT was declared the winning solution, obtaining an unweighted average recall (UAR) of 65.41% and 85.87% for complaint and request detection, respectively. Moreover, we applied our framework on the Speech Commands v2 and HarperValleyBank dialog data sets, surpassing previous studies reporting results on these benchmarks. Our code is freely available for download at: https://github.com/ristea/ccmt.