 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Exploring Retraining-Free Speech Recognition for Intra-sentential Code-Switching
Aug 27, 2021

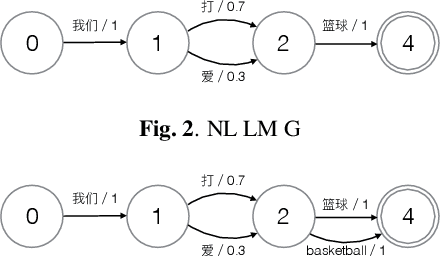
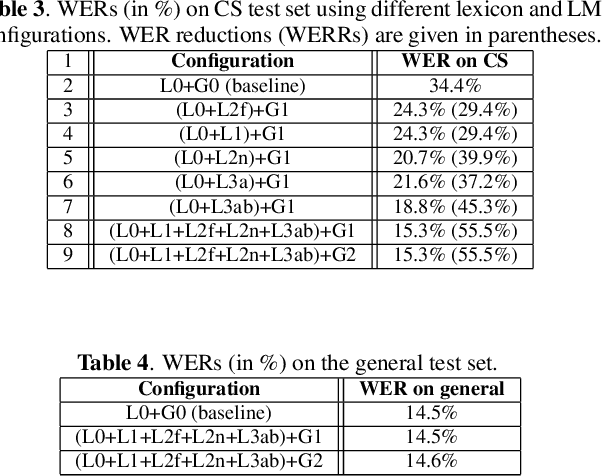
In this paper, we present our initial efforts for building a code-switching (CS) speech recognition system leveraging existing acoustic models (AMs) and language models (LMs), i.e., no training required, and specifically targeting intra-sentential switching. To achieve such an ambitious goal, new mechanisms for foreign pronunciation generation and language model (LM) enrichment have been devised. Specifically, we have designed an automatic approach to obtain high quality pronunciation of foreign language (FL) words in the native language (NL) phoneme set using existing acoustic phone decoders and an LSTM-based grapheme-to-phoneme (G2P) model. Improved accented pronunciations have thus been obtained by learning foreign pronunciations directly from data. Furthermore, a code-switching LM was deployed by converting the original NL LM into a CS LM using translated word pairs and borrowing statistics for the NL LM. Experimental evidence clearly demonstrates that our approach better deals with accented foreign pronunciations than techniques based on human labeling. Moreover, our best system achieves a 55.5% relative word error rate reduction from 34.4%, obtained with a conventional monolingual ASR system, to 15.3% on an intra-sentential CS task without harming the monolingual recognition accuracy.
Transformer-based end-to-end speech recognition with residual Gaussian-based self-attention
Mar 29, 2021Self-attention (SA), which encodes vector sequences according to their pairwise similarity, is widely used in speech recognition due to its strong context modeling ability. However, when applied to long sequence data, its accuracy is reduced. This is caused by the fact that its weighted average operator may lead to the dispersion of the attention distribution, which results in the relationship between adjacent signals ignored. To address this issue, in this paper, we introduce relative-position-awareness self-attention (RPSA). It not only maintains the global-range dependency modeling ability of self-attention, but also improves the localness modeling ability. Because the local window length of the original RPSA is fixed and sensitive to different test data, here we propose Gaussian-based self-attention (GSA) whose window length is learnable and adaptive to the test data automatically. We further generalize GSA to a new residual Gaussian self-attention (resGSA) for the performance improvement. We apply RPSA, GSA, and resGSA to Transformer-based speech recognition respectively. Experimental results on the AISHELL-1 Mandarin speech recognition corpus demonstrate the effectiveness of the proposed methods. For example, the resGSA-Transformer achieves a character error rate (CER) of 5.86% on the test set, which is relative 7.8% lower than that of the SA-Transformer. Although the performance of the proposed resGSA-Transformer is only slightly better than that of the RPSA-Transformer, it does not have to tune the window length manually.
Super-Human Performance in Online Low-latency Recognition of Conversational Speech
Oct 22, 2020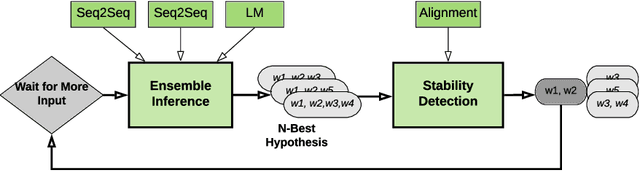
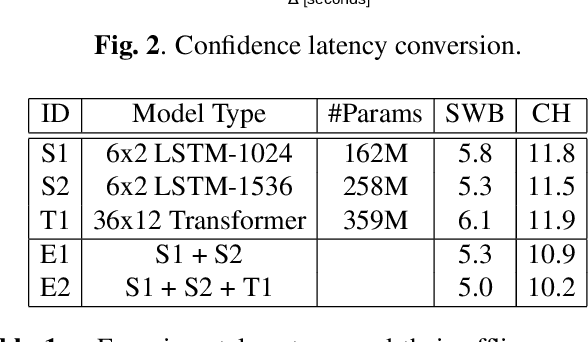
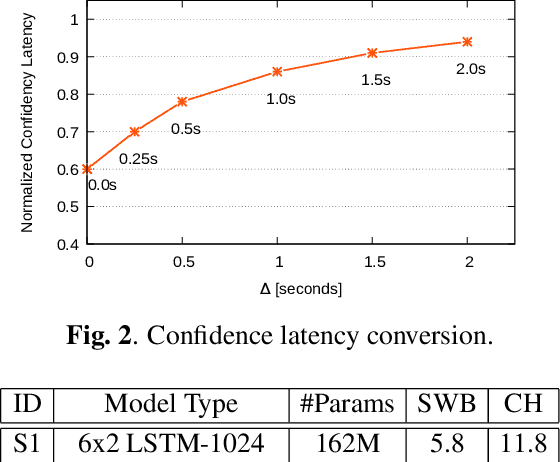
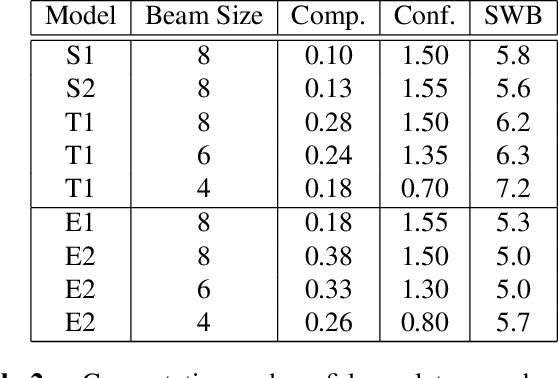
Achieving super-human performance in recognizing human speech has been a goal for several decades, as researchers have worked on increasingly challenging tasks. In the 1990's it was discovered, that conversational speech between two humans turns out to be considerably more difficult than read speech as hesitations, disfluencies, false starts and sloppy articulation complicate acoustic processing and require robust handling of acoustic, lexical and language context, jointly. Early attempts with statistical models could only reach error rates over 50% and far from human performance (WER of around 5.5%). Neural hybrid models and recent attention-based encoder-decoder models have considerably improved performance as such contexts can now be learned in an integral fashion. However, processing such contexts requires an entire utterance presentation and thus introduces unwanted delays before a recognition result can be output. In this paper, we address performance as well as latency. We present results for a system that can achieve super-human performance (at a WER of 5.0%, over the Switchboard conversational benchmark) at a word based latency of only 1 second behind a speaker's speech. The system uses multiple attention-based encoder-decoder networks integrated within a novel low latency incremental inference approach.
You Are What You Tweet: Profiling Users by Past Tweets to Improve Hate Speech Detection
Dec 16, 2020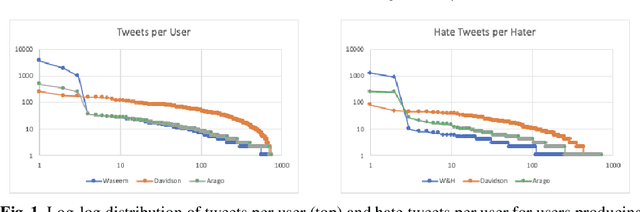
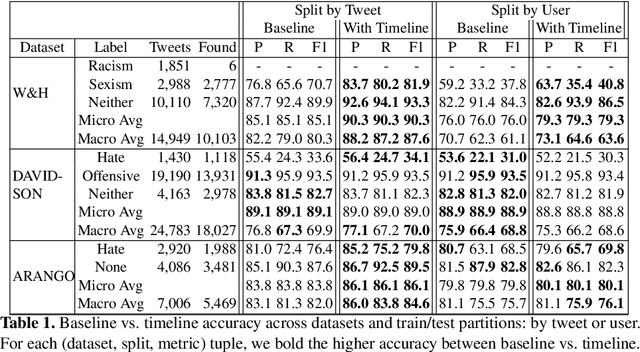
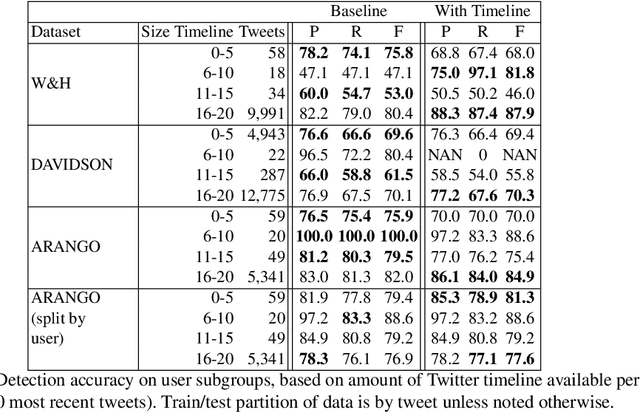
Hate speech detection research has predominantly focused on purely content-based methods, without exploiting any additional context. We briefly critique pros and cons of this task formulation. We then investigate profiling users by their past utterances as an informative prior to better predict whether new utterances constitute hate speech. To evaluate this, we augment three Twitter hate speech datasets with additional timeline data, then embed this additional context into a strong baseline model. Promising results suggest merit for further investigation, though analysis is complicated by differences in annotation schemes and processes, as well as Twitter API limitations and data sharing policies.
Call-sign recognition and understanding for noisy air-traffic transcripts using surveillance information
Apr 13, 2022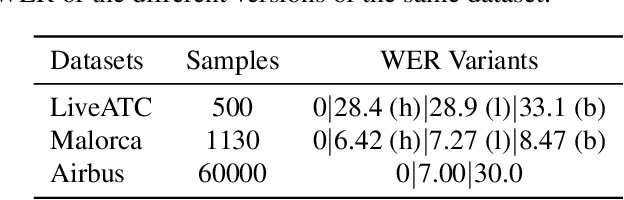

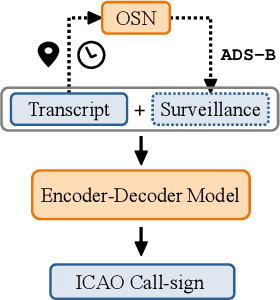
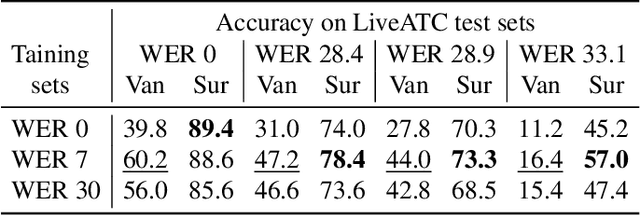
Air traffic control (ATC) relies on communication via speech between pilot and air-traffic controller (ATCO). The call-sign, as unique identifier for each flight, is used to address a specific pilot by the ATCO. Extracting the call-sign from the communication is a challenge because of the noisy ATC voice channel and the additional noise introduced by the receiver. A low signal-to-noise ratio (SNR) in the speech leads to high word error rate (WER) transcripts. We propose a new call-sign recognition and understanding (CRU) system that addresses this issue. The recognizer is trained to identify call-signs in noisy ATC transcripts and convert them into the standard International Civil Aviation Organization (ICAO) format. By incorporating surveillance information, we can multiply the call-sign accuracy (CSA) up to a factor of four. The introduced data augmentation adds additional performance on high WER transcripts and allows the adaptation of the model to unseen airspaces.
Style Transfer of Audio Effects with Differentiable Signal Processing
Jul 18, 2022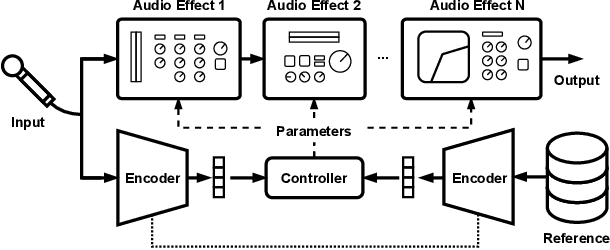
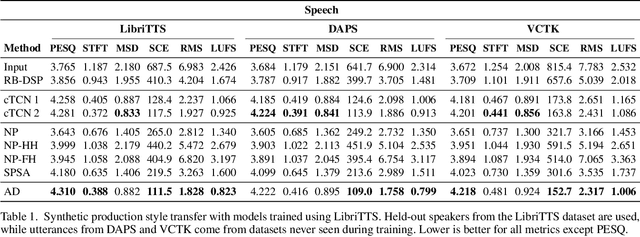
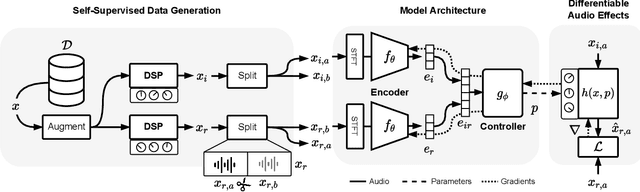
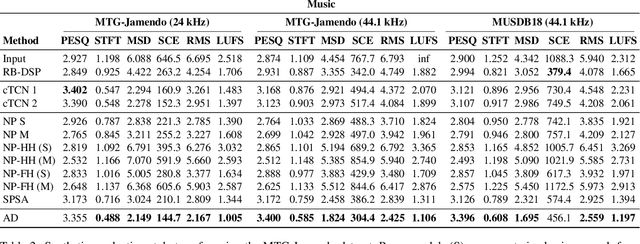
We present a framework that can impose the audio effects and production style from one recording to another by example with the goal of simplifying the audio production process. We train a deep neural network to analyze an input recording and a style reference recording, and predict the control parameters of audio effects used to render the output. In contrast to past work, we integrate audio effects as differentiable operators in our framework, perform backpropagation through audio effects, and optimize end-to-end using an audio-domain loss. We use a self-supervised training strategy enabling automatic control of audio effects without the use of any labeled or paired training data. We survey a range of existing and new approaches for differentiable signal processing, showing how each can be integrated into our framework while discussing their trade-offs. We evaluate our approach on both speech and music tasks, demonstrating that our approach generalizes both to unseen recordings and even to sample rates different than those seen during training. Our approach produces convincing production style transfer results with the ability to transform input recordings to produced recordings, yielding audio effect control parameters that enable interpretability and user interaction.
Multimodal Speech Recognition with Unstructured Audio Masking
Oct 16, 2020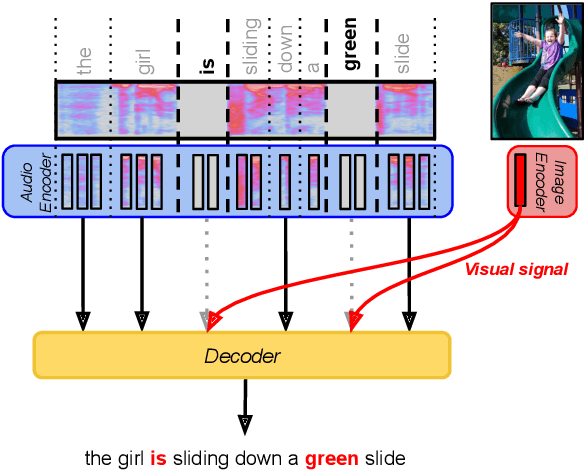
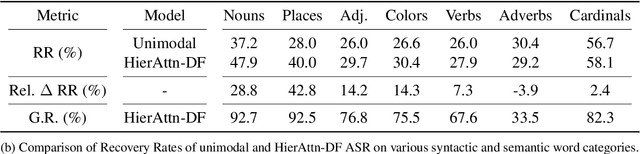
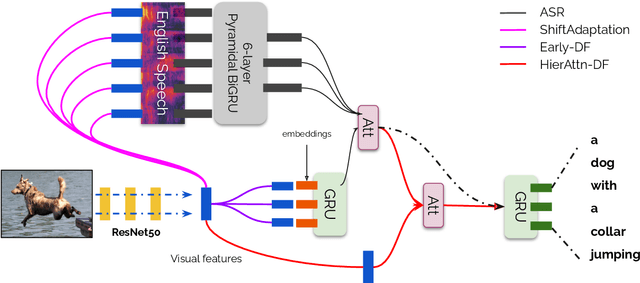
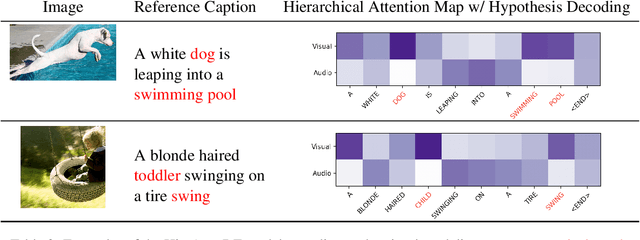
Visual context has been shown to be useful for automatic speech recognition (ASR) systems when the speech signal is noisy or corrupted. Previous work, however, has only demonstrated the utility of visual context in an unrealistic setting, where a fixed set of words are systematically masked in the audio. In this paper, we simulate a more realistic masking scenario during model training, called RandWordMask, where the masking can occur for any word segment. Our experiments on the Flickr 8K Audio Captions Corpus show that multimodal ASR can generalize to recover different types of masked words in this unstructured masking setting. Moreover, our analysis shows that our models are capable of attending to the visual signal when the audio signal is corrupted. These results show that multimodal ASR systems can leverage the visual signal in more generalized noisy scenarios.
Improving Reverberant Speech Separation with Multi-stage Training and Curriculum Learning
Jul 19, 2021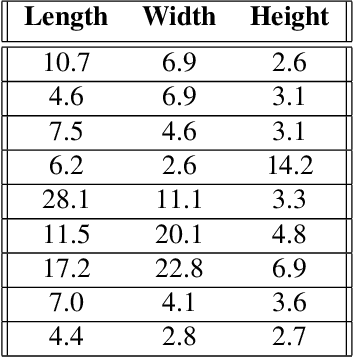
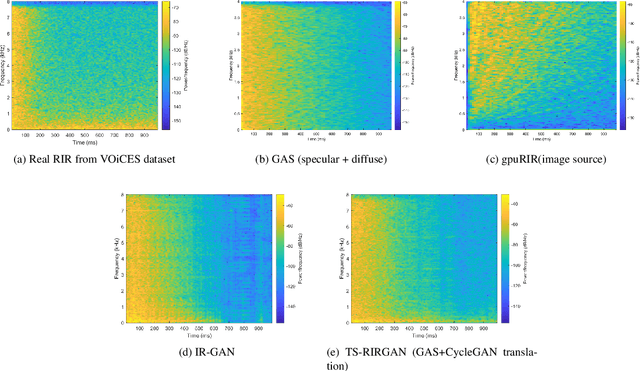
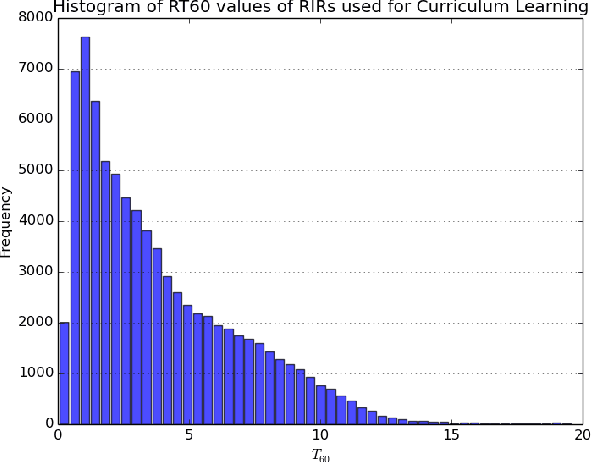
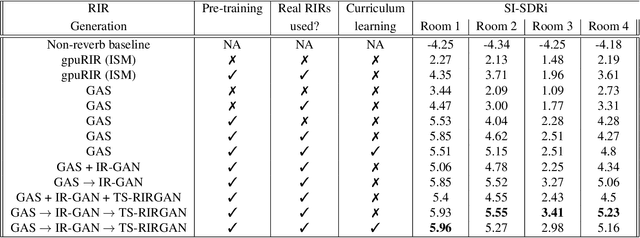
We present a novel approach that improves the performance of reverberant speech separation. Our approach is based on an accurate geometric acoustic simulator (GAS) which generates realistic room impulse responses (RIRs) by modeling both specular and diffuse reflections. We also propose three training methods - pre-training, multi-stage training and curriculum learning that significantly improve separation quality in the presence of reverberation. We also demonstrate that mixing the synthetic RIRs with a small number of real RIRs during training enhances separation performance. We evaluate our approach on reverberant mixtures generated from real, recorded data (in several different room configurations) from the VOiCES dataset. Our novel approach (curriculum learning+pre-training+multi-stage training) results in a significant relative improvement over prior techniques based on image source method (ISM).
A Light-weight contextual spelling correction model for customizing transducer-based speech recognition systems
Aug 17, 2021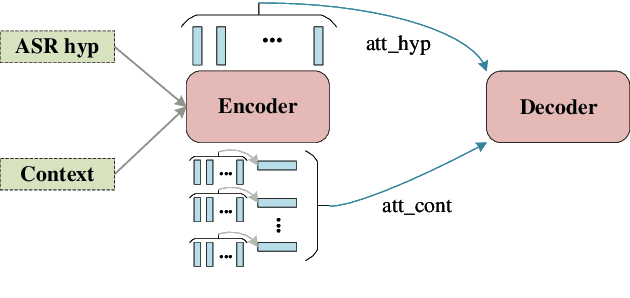


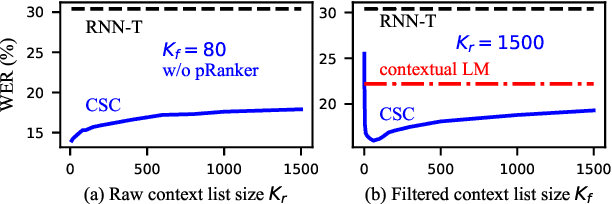
It's challenging to customize transducer-based automatic speech recognition (ASR) system with context information which is dynamic and unavailable during model training. In this work, we introduce a light-weight contextual spelling correction model to correct context-related recognition errors in transducer-based ASR systems. We incorporate the context information into the spelling correction model with a shared context encoder and use a filtering algorithm to handle large-size context lists. Experiments show that the model improves baseline ASR model performance with about 50% relative word error rate reduction, which also significantly outperforms the baseline method such as contextual LM biasing. The model also shows excellent performance for out-of-vocabulary terms not seen during training.
Source and Target Bidirectional Knowledge Distillation for End-to-end Speech Translation
Apr 13, 2021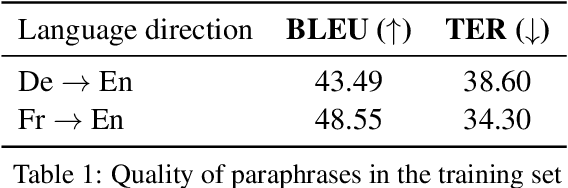
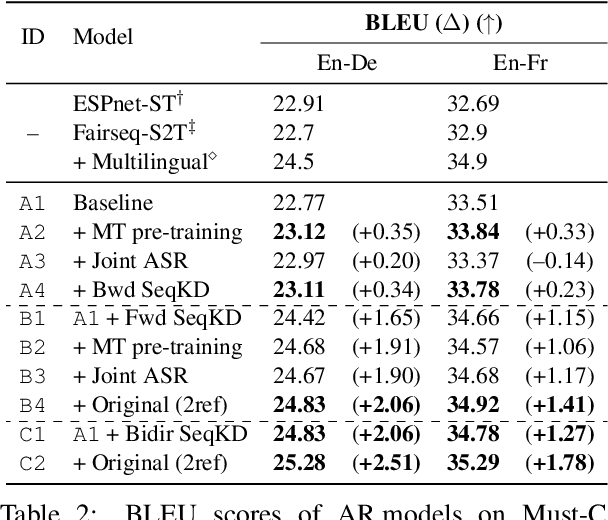
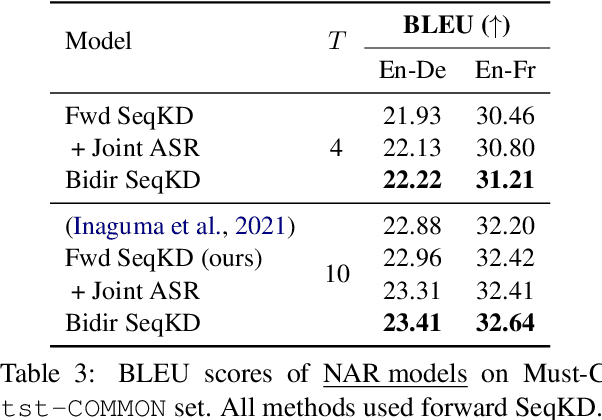
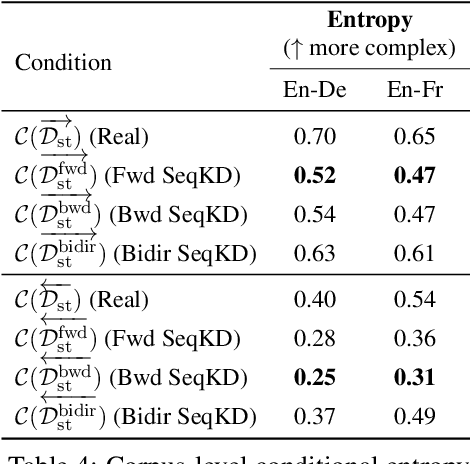
A conventional approach to improving the performance of end-to-end speech translation (E2E-ST) models is to leverage the source transcription via pre-training and joint training with automatic speech recognition (ASR) and neural machine translation (NMT) tasks. However, since the input modalities are different, it is difficult to leverage source language text successfully. In this work, we focus on sequence-level knowledge distillation (SeqKD) from external text-based NMT models. To leverage the full potential of the source language information, we propose backward SeqKD, SeqKD from a target-to-source backward NMT model. To this end, we train a bilingual E2E-ST model to predict paraphrased transcriptions as an auxiliary task with a single decoder. The paraphrases are generated from the translations in bitext via back-translation. We further propose bidirectional SeqKD in which SeqKD from both forward and backward NMT models is combined. Experimental evaluations on both autoregressive and non-autoregressive models show that SeqKD in each direction consistently improves the translation performance, and the effectiveness is complementary regardless of the model capacity.