 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Training Neural Speech Recognition Systems with Synthetic Speech Augmentation
Nov 02, 2018
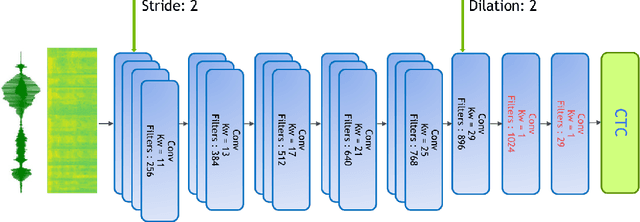
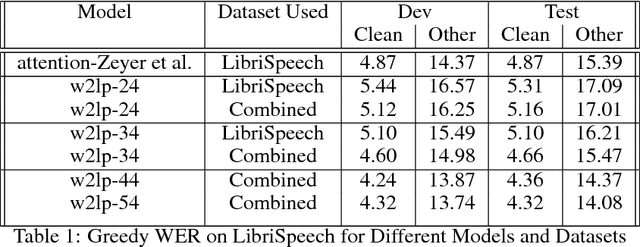
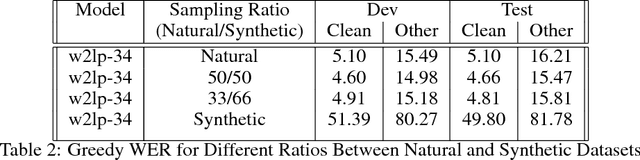
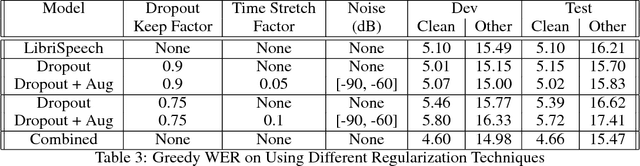
Building an accurate automatic speech recognition (ASR) system requires a large dataset that contains many hours of labeled speech samples produced by a diverse set of speakers. The lack of such open free datasets is one of the main issues preventing advancements in ASR research. To address this problem, we propose to augment a natural speech dataset with synthetic speech. We train very large end-to-end neural speech recognition models using the LibriSpeech dataset augmented with synthetic speech. These new models achieve state of the art Word Error Rate (WER) for character-level based models without an external language model.
End-to-End Dereverberation, Beamforming, and Speech Recognition with Improved Numerical Stability and Advanced Frontend
Feb 23, 2021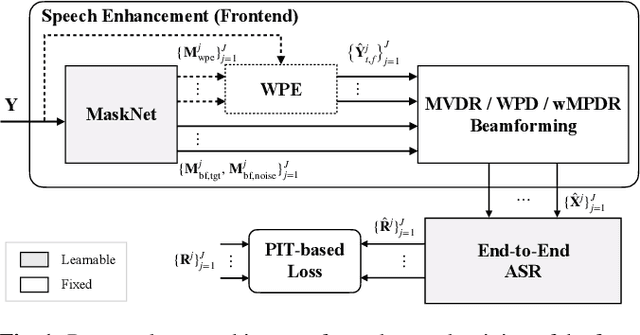
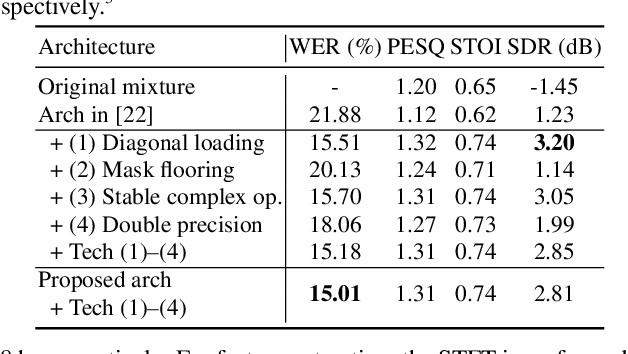
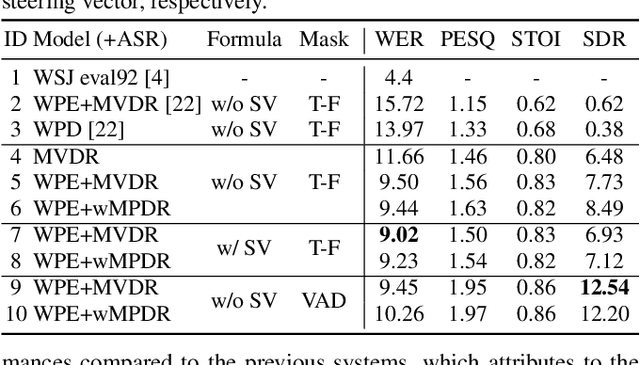
Recently, the end-to-end approach has been successfully applied to multi-speaker speech separation and recognition in both single-channel and multichannel conditions. However, severe performance degradation is still observed in the reverberant and noisy scenarios, and there is still a large performance gap between anechoic and reverberant conditions. In this work, we focus on the multichannel multi-speaker reverberant condition, and propose to extend our previous framework for end-to-end dereverberation, beamforming, and speech recognition with improved numerical stability and advanced frontend subnetworks including voice activity detection like masks. The techniques significantly stabilize the end-to-end training process. The experiments on the spatialized wsj1-2mix corpus show that the proposed system achieves about 35% WER relative reduction compared to our conventional multi-channel E2E ASR system, and also obtains decent speech dereverberation and separation performance (SDR=12.5 dB) in the reverberant multi-speaker condition while trained only with the ASR criterion.
Relative Positional Encoding for Speech Recognition and Direct Translation
May 20, 2020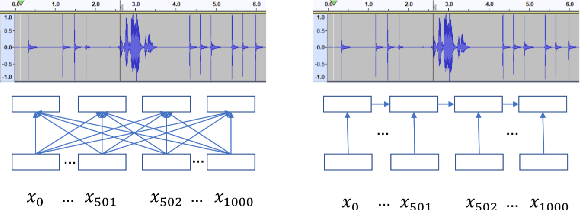
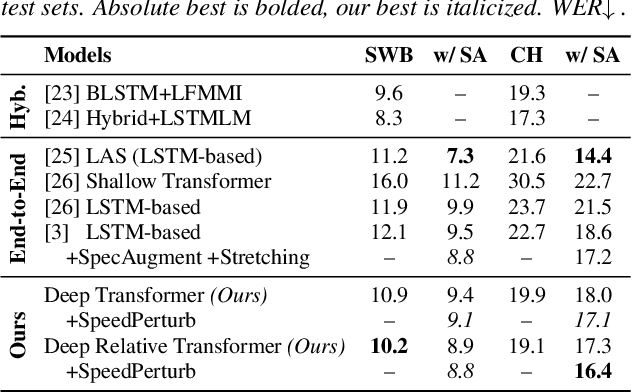


Transformer models are powerful sequence-to-sequence architectures that are capable of directly mapping speech inputs to transcriptions or translations. However, the mechanism for modeling positions in this model was tailored for text modeling, and thus is less ideal for acoustic inputs. In this work, we adapt the relative position encoding scheme to the Speech Transformer, where the key addition is relative distance between input states in the self-attention network. As a result, the network can better adapt to the variable distributions present in speech data. Our experiments show that our resulting model achieves the best recognition result on the Switchboard benchmark in the non-augmentation condition, and the best published result in the MuST-C speech translation benchmark. We also show that this model is able to better utilize synthetic data than the Transformer, and adapts better to variable sentence segmentation quality for speech translation.
A non-causal FFTNet architecture for speech enhancement
Jun 08, 2020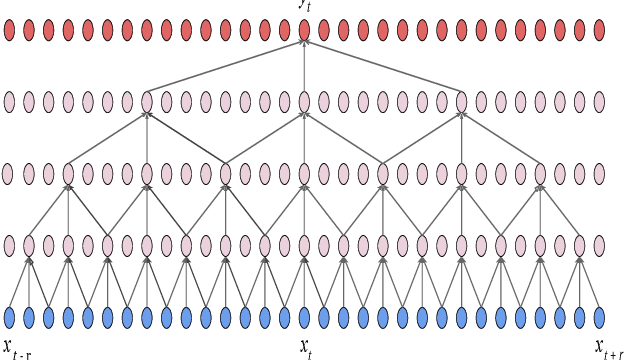
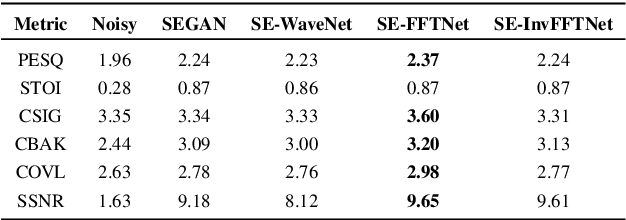
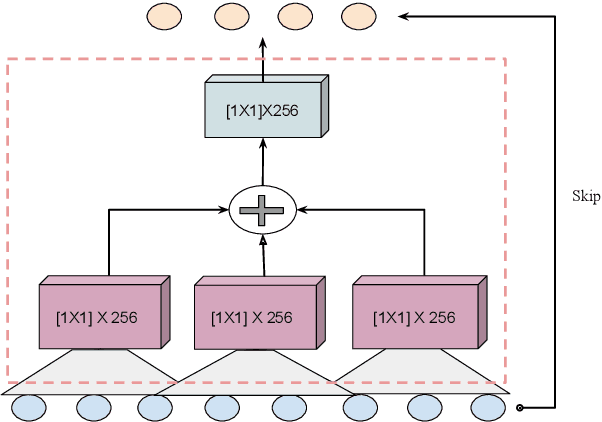

In this paper, we suggest a new parallel, non-causal and shallow waveform domain architecture for speech enhancement based on FFTNet, a neural network for generating high quality audio waveform. In contrast to other waveform based approaches like WaveNet, FFTNet uses an initial wide dilation pattern. Such an architecture better represents the long term correlated structure of speech in the time domain, where noise is usually highly non-correlated, and therefore it is suitable for waveform domain based speech enhancement. To further strengthen this feature of FFTNet, we suggest a non-causal FFTNet architecture, where the present sample in each layer is estimated from the past and future samples of the previous layer. By suggesting a shallow network and applying non-causality within certain limits, the suggested FFTNet for speech enhancement (SE-FFTNet) uses much fewer parameters compared to other neural network based approaches for speech enhancement like WaveNet and SEGAN. Specifically, the suggested network has considerably reduced model parameters: 32% fewer compared to WaveNet and 87% fewer compared to SEGAN. Finally, based on subjective and objective metrics, SE-FFTNet outperforms WaveNet in terms of enhanced signal quality, while it provides equally good performance as SEGAN. A Tensorflow implementation of the architecture is provided at 1 .
Exploring Retraining-Free Speech Recognition for Intra-sentential Code-Switching
Aug 27, 2021
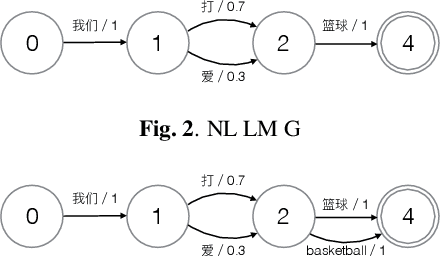
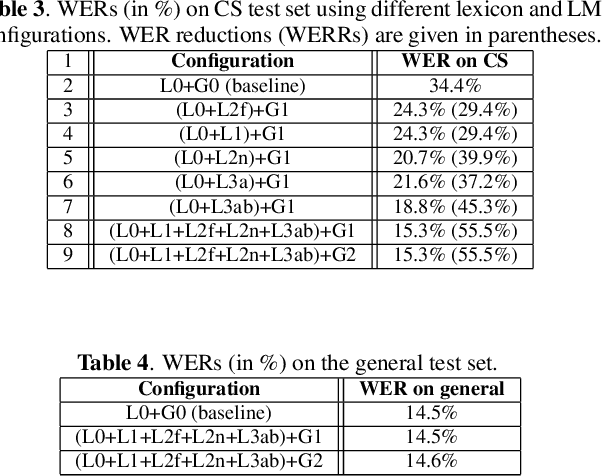
In this paper, we present our initial efforts for building a code-switching (CS) speech recognition system leveraging existing acoustic models (AMs) and language models (LMs), i.e., no training required, and specifically targeting intra-sentential switching. To achieve such an ambitious goal, new mechanisms for foreign pronunciation generation and language model (LM) enrichment have been devised. Specifically, we have designed an automatic approach to obtain high quality pronunciation of foreign language (FL) words in the native language (NL) phoneme set using existing acoustic phone decoders and an LSTM-based grapheme-to-phoneme (G2P) model. Improved accented pronunciations have thus been obtained by learning foreign pronunciations directly from data. Furthermore, a code-switching LM was deployed by converting the original NL LM into a CS LM using translated word pairs and borrowing statistics for the NL LM. Experimental evidence clearly demonstrates that our approach better deals with accented foreign pronunciations than techniques based on human labeling. Moreover, our best system achieves a 55.5% relative word error rate reduction from 34.4%, obtained with a conventional monolingual ASR system, to 15.3% on an intra-sentential CS task without harming the monolingual recognition accuracy.
An Overview of Recent Work in Media Forensics: Methods and Threats
Apr 26, 2022


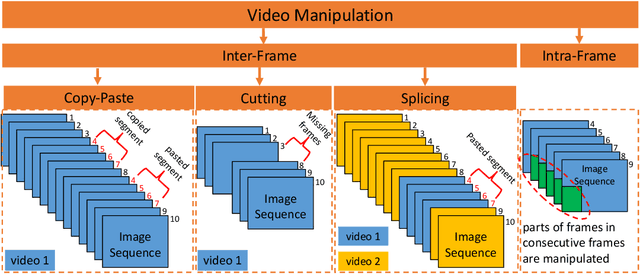
In this paper, we review recent work in media forensics for digital images, video, audio (specifically speech), and documents. For each data modality, we discuss synthesis and manipulation techniques that can be used to create and modify digital media. We then review technological advancements for detecting and quantifying such manipulations. Finally, we consider open issues and suggest directions for future research.
Fast End-to-End Speech Recognition via Non-Autoregressive Models and Cross-Modal Knowledge Transferring from BERT
Feb 15, 2021
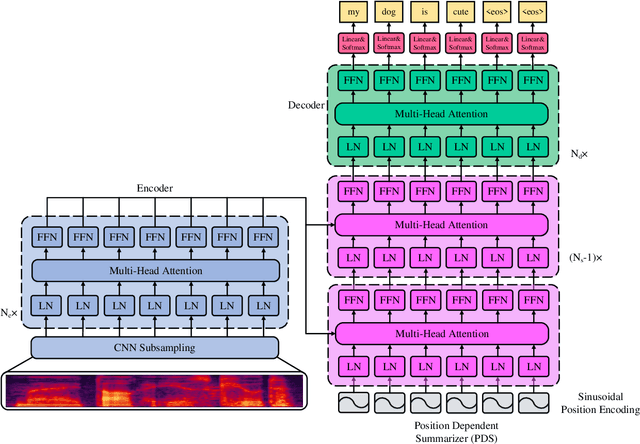
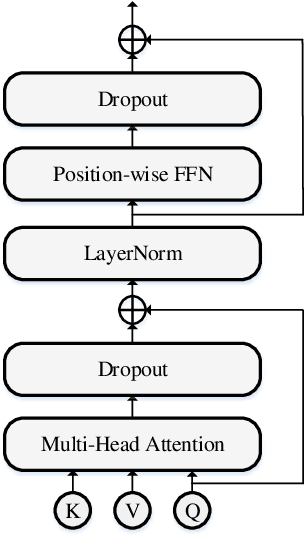
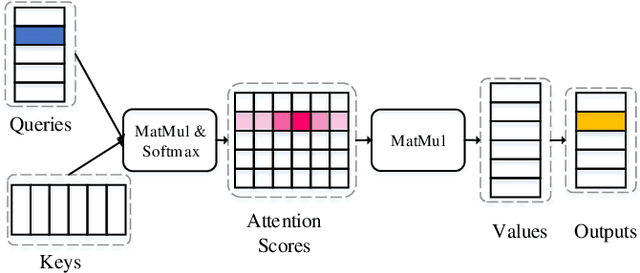
Attention-based encoder-decoder (AED) models have achieved promising performance in speech recognition. However, because the decoder predicts text tokens (such as characters or words) in an autoregressive manner, it is difficult for an AED model to predict all tokens in parallel. This makes the inference speed relatively slow. We believe that because the encoder already captures the whole speech utterance, which has the token-level relationship implicitly, we can predict a token without explicitly autoregressive language modeling. When the prediction of a token does not rely on other tokens, the parallel prediction of all tokens in the sequence is realizable. Based on this idea, we propose a non-autoregressive speech recognition model called LASO (Listen Attentively, and Spell Once). The model consists of an encoder, a decoder, and a position dependent summarizer (PDS). The three modules are based on basic attention blocks. The encoder extracts high-level representations from the speech. The PDS uses positional encodings corresponding to tokens to convert the acoustic representations into token-level representations. The decoder further captures token-level relationships with the self-attention mechanism. At last, the probability distribution on the vocabulary is computed for each token position. Therefore, speech recognition is re-formulated as a position-wise classification problem. Further, we propose a cross-modal transfer learning method to refine semantics from a large-scale pre-trained language model BERT for improving the performance.
SAR-Net: A End-to-End Deep Speech Accent Recognition Network
Dec 08, 2020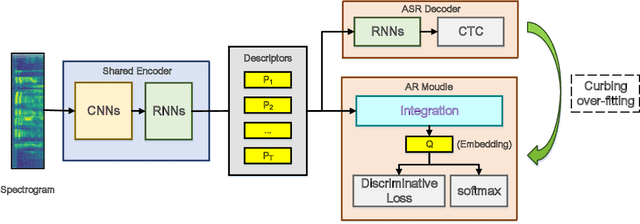
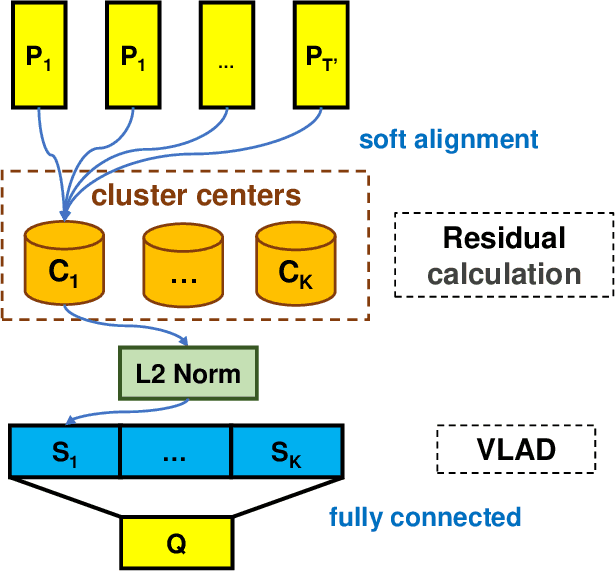
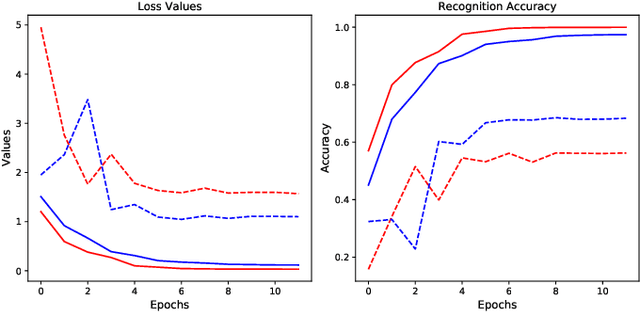
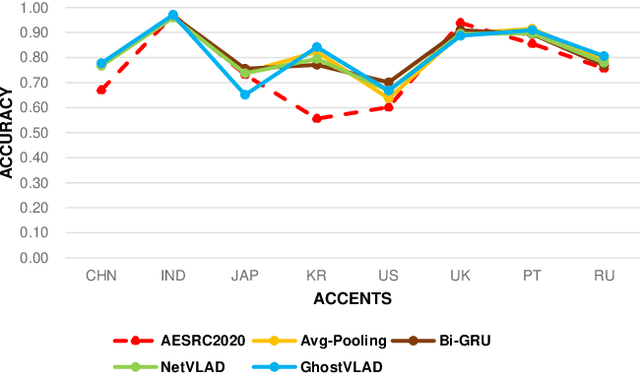
This paper proposes a end-to-end deep network to recognize kinds of accents under the same language, where we develop and transfer the deep architecture in speaker-recognition area to accent classification task for learning utterance-level accent representation. Compared with the individual-level feature in speaker-recognition, accent recognition throws a more challenging issue in acquiring compact group-level features for the speakers with the same accent, hence a good discriminative accent feature space is desired. Our deep framework adopts multitask-learning mechanism and mainly consists of three modules: a shared CNNs and RNNs based front-end encoder, a core accent recognition branch, and an auxiliary speech recognition branch, where we take speech spectrogram as input. More specifically, with the sequential descriptors learned from a shared encoder, the accent recognition branch first condenses all descriptors into an embedding vector, and then explores different discriminative loss functions which are popular in face recognition domain to enhance embedding discrimination. Additionally, due to the accent is a speaking-related timbre, adding speech recognition branch effectively curbs the over-fitting phenomenon in accent recognition during training. We show that our network without any data-augment preproccessings is significantly ahead of the baseline system on the accent classification track in the Accented English Speech Recognition Challenge 2020 (AESRC2020), where the state-of-the-art loss function Circle-Loss achieves the best discriminative optimization for accent representation.
Part of speech and gramset tagging algorithms for unknown words based on morphological dictionaries of the Veps and Karelian languages
Mar 22, 2021
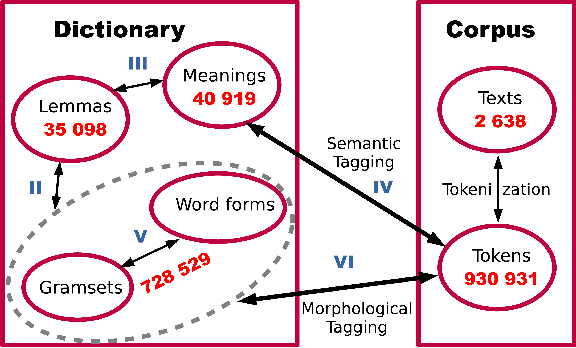

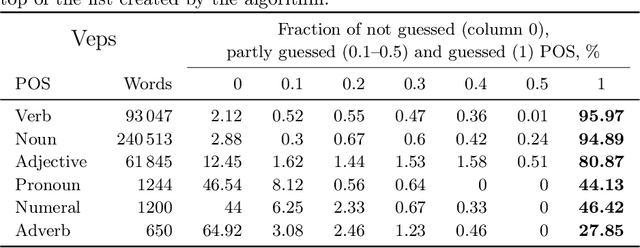
This research devoted to the low-resource Veps and Karelian languages. Algorithms for assigning part of speech tags to words and grammatical properties to words are presented in the article. These algorithms use our morphological dictionaries, where the lemma, part of speech and a set of grammatical features (gramset) are known for each word form. The algorithms are based on the analogy hypothesis that words with the same suffixes are likely to have the same inflectional models, the same part of speech and gramset. The accuracy of these algorithms were evaluated and compared. 313 thousand Vepsian and 66 thousand Karelian words were used to verify the accuracy of these algorithms. The special functions were designed to assess the quality of results of the developed algorithms. 92.4% of Vepsian words and 86.8% of Karelian words were assigned a correct part of speech by the developed algorithm. 95.3% of Vepsian words and 90.7% of Karelian words were assigned a correct gramset by our algorithm. Morphological and semantic tagging of texts, which are closely related and inseparable in our corpus processes, are described in the paper.
A comparison of Vietnamese Statistical Parametric Speech Synthesis Systems
May 26, 2020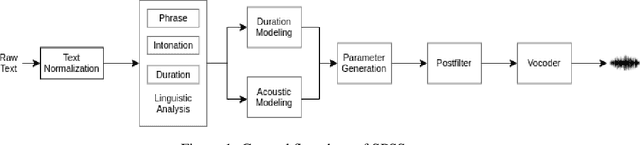
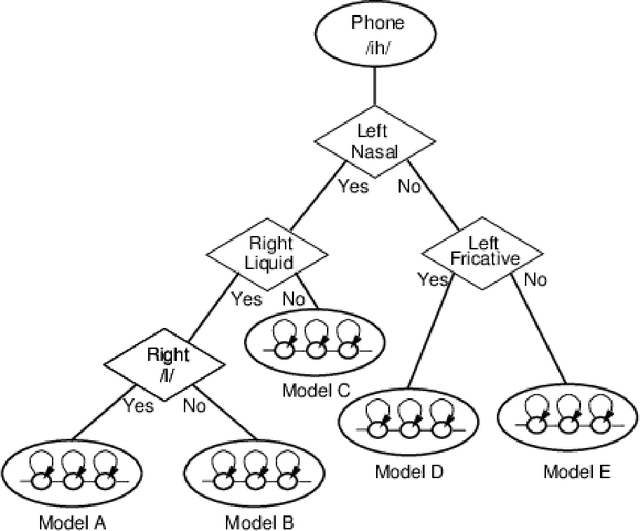
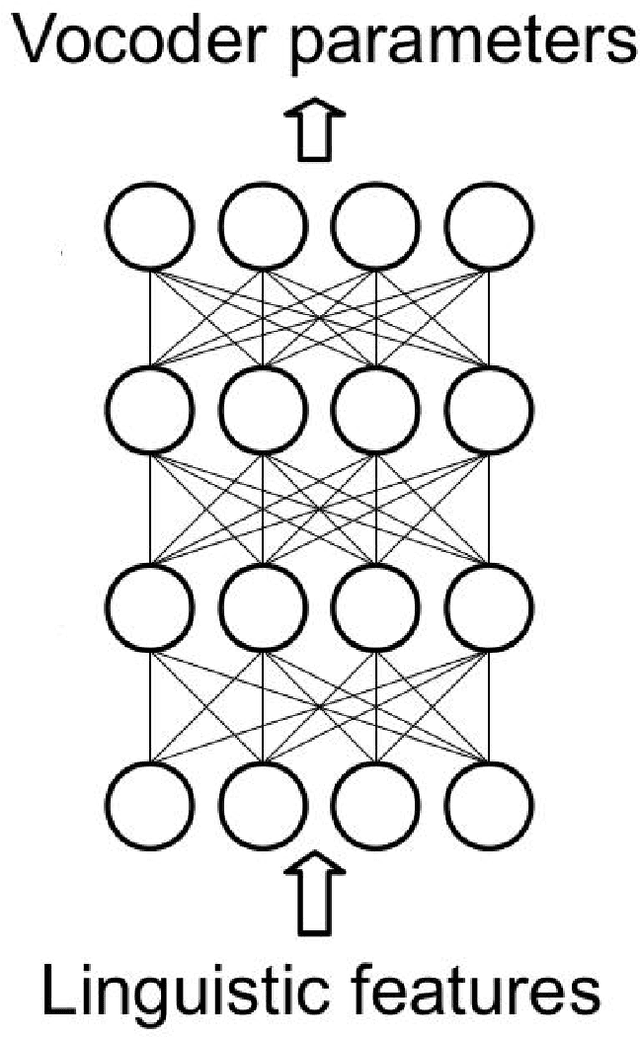
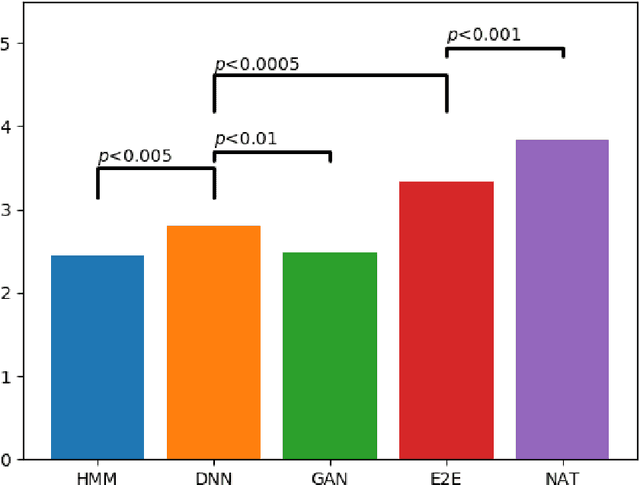
In recent years, statistical parametric speech synthesis (SPSS) systems have been widely utilized in many interactive speech-based systems (e.g.~Amazon's Alexa, Bose's headphones). To select a suitable SPSS system, both speech quality and performance efficiency (e.g.~decoding time) must be taken into account. In the paper, we compared four popular Vietnamese SPSS techniques using: 1) hidden Markov models (HMM), 2) deep neural networks (DNN), 3) generative adversarial networks (GAN), and 4) end-to-end (E2E) architectures, which consists of Tacontron~2 and WaveGlow vocoder in terms of speech quality and performance efficiency. We showed that the E2E systems accomplished the best quality, but required the power of GPU to achieve real-time performance. We also showed that the HMM-based system had inferior speech quality, but it was the most efficient system. Surprisingly, the E2E systems were more efficient than the DNN and GAN in inference on GPU. Surprisingly, the GAN-based system did not outperform the DNN in term of quality.