 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
TL;DW? Summarizing Instructional Videos with Task Relevance & Cross-Modal Saliency
Aug 14, 2022

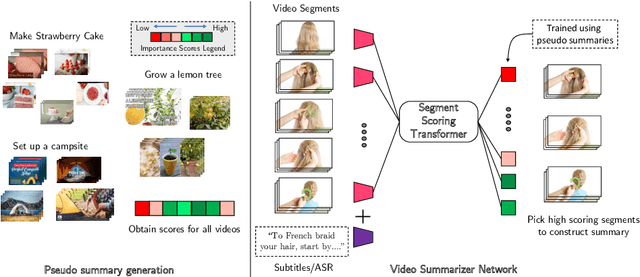
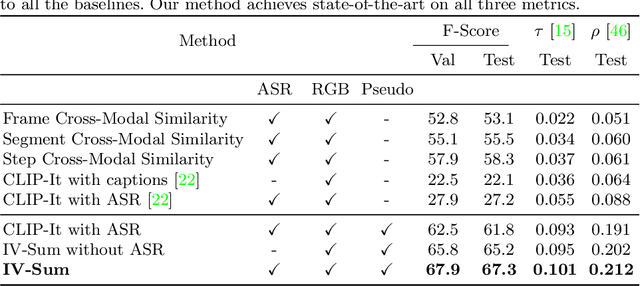
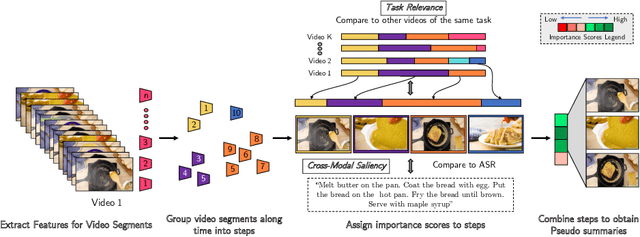
YouTube users looking for instructions for a specific task may spend a long time browsing content trying to find the right video that matches their needs. Creating a visual summary (abridged version of a video) provides viewers with a quick overview and massively reduces search time. In this work, we focus on summarizing instructional videos, an under-explored area of video summarization. In comparison to generic videos, instructional videos can be parsed into semantically meaningful segments that correspond to important steps of the demonstrated task. Existing video summarization datasets rely on manual frame-level annotations, making them subjective and limited in size. To overcome this, we first automatically generate pseudo summaries for a corpus of instructional videos by exploiting two key assumptions: (i) relevant steps are likely to appear in multiple videos of the same task (Task Relevance), and (ii) they are more likely to be described by the demonstrator verbally (Cross-Modal Saliency). We propose an instructional video summarization network that combines a context-aware temporal video encoder and a segment scoring transformer. Using pseudo summaries as weak supervision, our network constructs a visual summary for an instructional video given only video and transcribed speech. To evaluate our model, we collect a high-quality test set, WikiHow Summaries, by scraping WikiHow articles that contain video demonstrations and visual depictions of steps allowing us to obtain the ground-truth summaries. We outperform several baselines and a state-of-the-art video summarization model on this new benchmark.
AsNER -- Annotated Dataset and Baseline for Assamese Named Entity recognition
Jul 07, 2022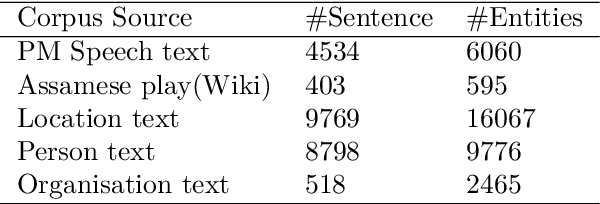
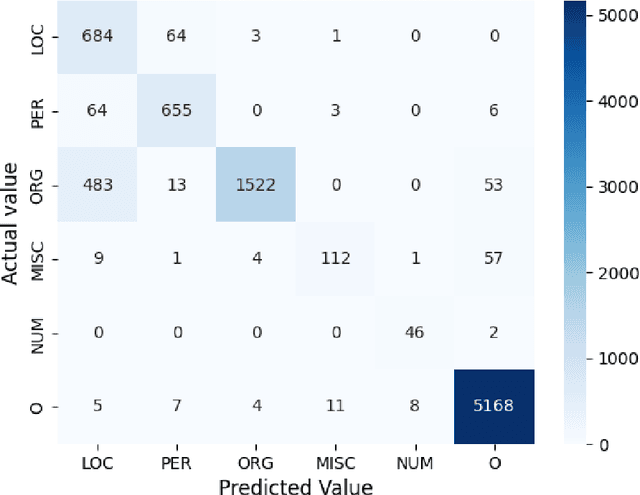
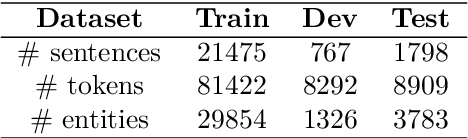
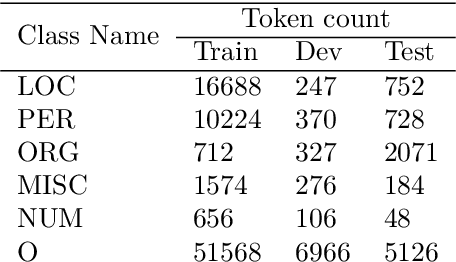
We present the AsNER, a named entity annotation dataset for low resource Assamese language with a baseline Assamese NER model. The dataset contains about 99k tokens comprised of text from the speech of the Prime Minister of India and Assamese play. It also contains person names, location names and addresses. The proposed NER dataset is likely to be a significant resource for deep neural based Assamese language processing. We benchmark the dataset by training NER models and evaluating using state-of-the-art architectures for supervised named entity recognition (NER) such as Fasttext, BERT, XLM-R, FLAIR, MuRIL etc. We implement several baseline approaches with state-of-the-art sequence tagging Bi-LSTM-CRF architecture. The highest F1-score among all baselines achieves an accuracy of 80.69% when using MuRIL as a word embedding method. The annotated dataset and the top performing model are made publicly available.
* Published at LREC 2022
Multi-Modal Detection of Alzheimer's Disease from Speech and Text
Nov 30, 2020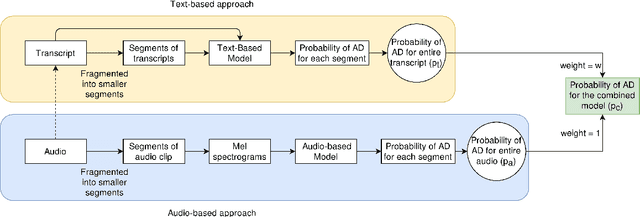
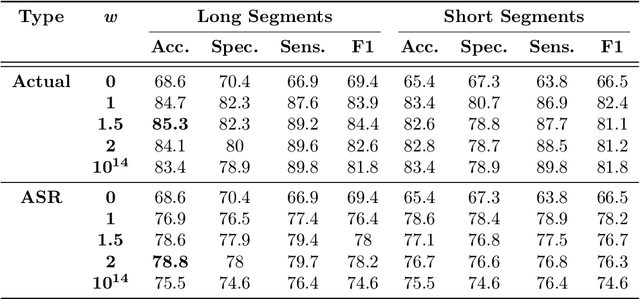
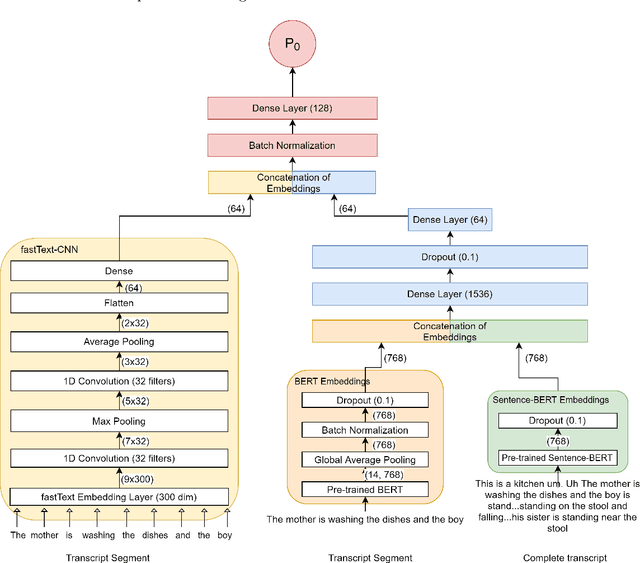
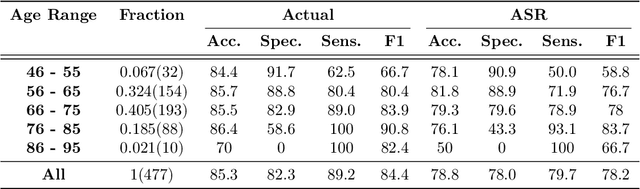
Reliable detection of the prodromal stages of Alzheimer's disease (AD) remains difficult even today because, unlike other neurocognitive impairments, there is no definitive diagnosis of AD in vivo. In this context, existing research has shown that patients often develop language impairment even in mild AD conditions. We propose a multimodal deep learning method that utilizes speech and the corresponding transcript simultaneously to detect AD. For audio signals, the proposed audio-based network, a convolutional neural network (CNN) based model, predicts the diagnosis for multiple speech segments, which are combined for the final prediction. Similarly, we use contextual embedding extracted from BERT concatenated with a CNN-generated embedding for classifying the transcript. The individual predictions of the two models are then combined to make the final classification. We also perform experiments to analyze the model performance when Automated Speech Recognition (ASR) system generated transcripts are used instead of manual transcription in the text-based model. The proposed method achieves 85.3% 10-fold cross-validation accuracy when trained and evaluated on the Dementiabank Pitt corpus.
Training Neural Speech Recognition Systems with Synthetic Speech Augmentation
Nov 02, 2018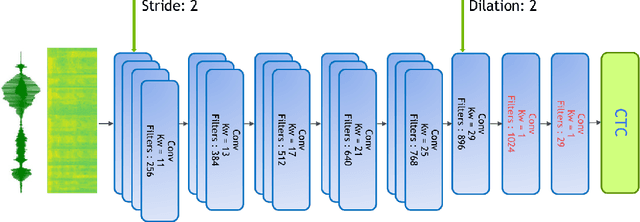
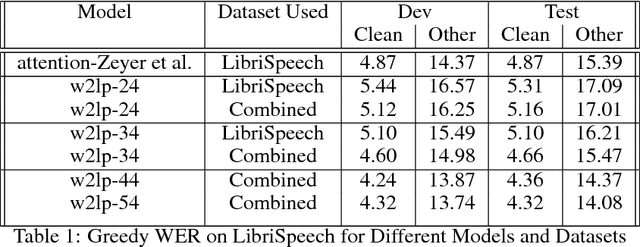
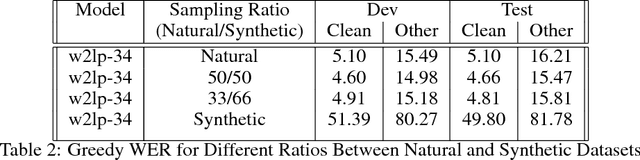
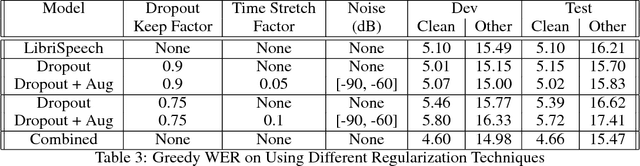
Building an accurate automatic speech recognition (ASR) system requires a large dataset that contains many hours of labeled speech samples produced by a diverse set of speakers. The lack of such open free datasets is one of the main issues preventing advancements in ASR research. To address this problem, we propose to augment a natural speech dataset with synthetic speech. We train very large end-to-end neural speech recognition models using the LibriSpeech dataset augmented with synthetic speech. These new models achieve state of the art Word Error Rate (WER) for character-level based models without an external language model.
TeCANet: Temporal-Contextual Attention Network for Environment-Aware Speech Dereverberation
Mar 31, 2021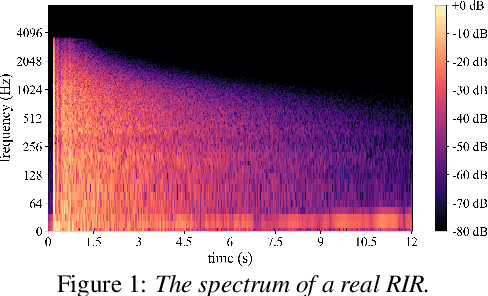
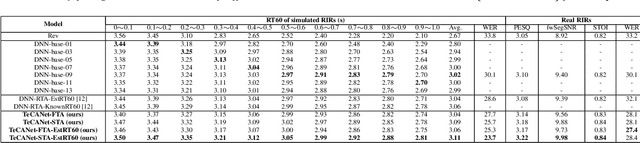
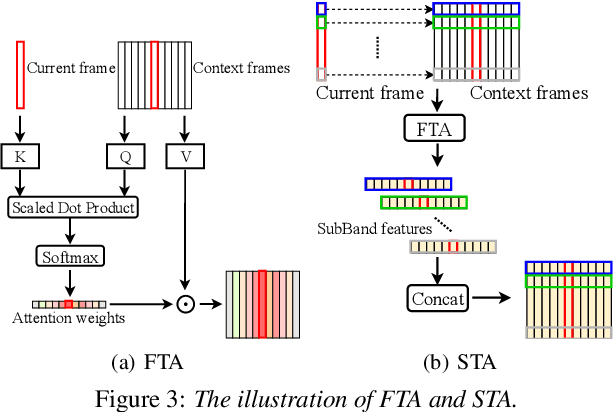
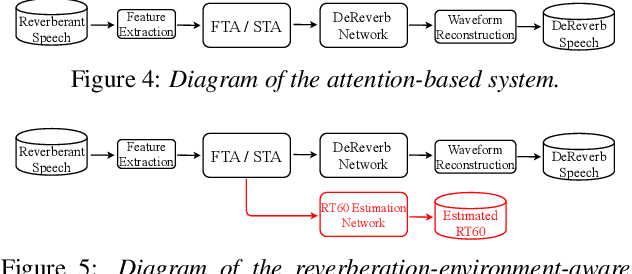
In this paper, we exploit the effective way to leverage contextual information to improve the speech dereverberation performance in real-world reverberant environments. We propose a temporal-contextual attention approach on the deep neural network (DNN) for environment-aware speech dereverberation, which can adaptively attend to the contextual information. More specifically, a FullBand based Temporal Attention approach (FTA) is proposed, which models the correlations between the fullband information of the context frames. In addition, considering the difference between the attenuation of high frequency bands and low frequency bands (high frequency bands attenuate faster than low frequency bands) in the room impulse response (RIR), we also propose a SubBand based Temporal Attention approach (STA). In order to guide the network to be more aware of the reverberant environments, we jointly optimize the dereverberation network and the reverberation time (RT60) estimator in a multi-task manner. Our experimental results indicate that the proposed method outperforms our previously proposed reverberation-time-aware DNN and the learned attention weights are fully physical consistent. We also report a preliminary yet promising dereverberation and recognition experiment on real test data.
Multi-Task Learning with Sentiment, Emotion, and Target Detection to Recognize Hate Speech and Offensive Language
Sep 21, 2021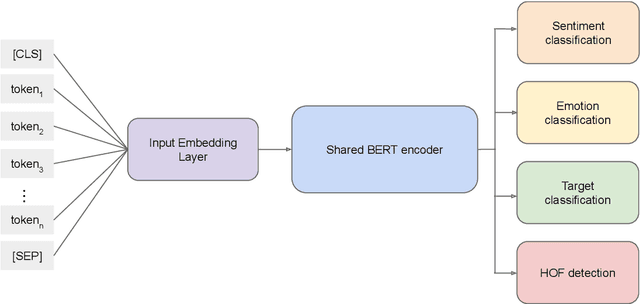
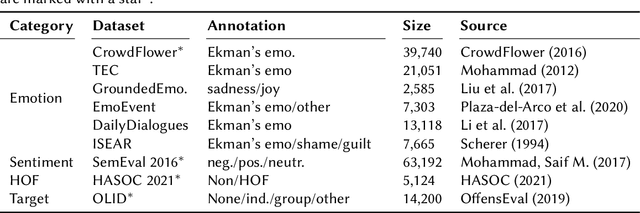
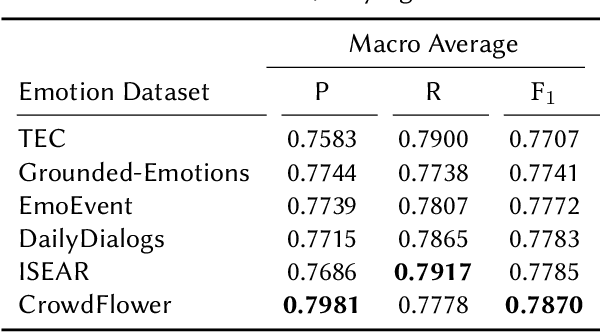
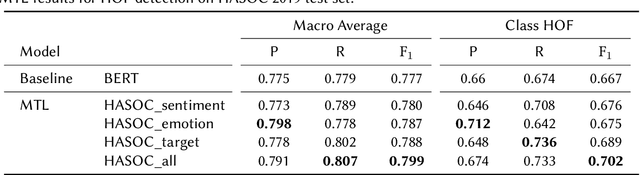
The recognition of hate speech and offensive language (HOF) is commonly formulated as a classification task to decide if a text contains HOF. We investigate whether HOF detection can profit by taking into account the relationships between HOF and similar concepts: (a) HOF is related to sentiment analysis because hate speech is typically a negative statement and expresses a negative opinion; (b) it is related to emotion analysis, as expressed hate points to the author experiencing (or pretending to experience) anger while the addressees experience (or are intended to experience) fear. (c) Finally, one constituting element of HOF is the mention of a targeted person or group. On this basis, we hypothesize that HOF detection shows improvements when being modeled jointly with these concepts, in a multi-task learning setup. We base our experiments on existing data sets for each of these concepts (sentiment, emotion, target of HOF) and evaluate our models as a participant (as team IMS-SINAI) in the HASOC FIRE 2021 English Subtask 1A. Based on model-selection experiments in which we consider multiple available resources and submissions to the shared task, we find that the combination of the CrowdFlower emotion corpus, the SemEval 2016 Sentiment Corpus, and the OffensEval 2019 target detection data leads to an F1 =.79 in a multi-head multi-task learning model based on BERT, in comparison to .7895 of plain BERT. On the HASOC 2019 test data, this result is more substantial with an increase by 2pp in F1 and a considerable increase in recall. Across both data sets (2019, 2021), the recall is particularly increased for the class of HOF (6pp for the 2019 data and 3pp for the 2021 data), showing that MTL with emotion, sentiment, and target identification is an appropriate approach for early warning systems that might be deployed in social media platforms.
Improving speech recognition models with small samples for air traffic control systems
Feb 16, 2021
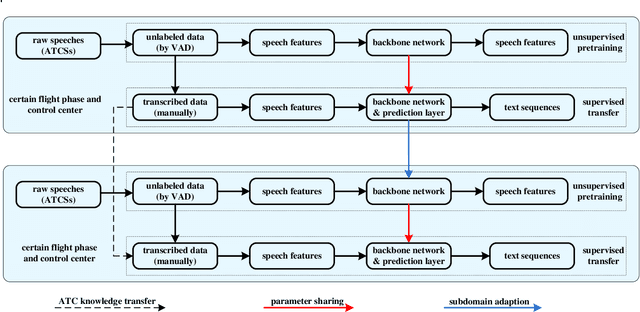
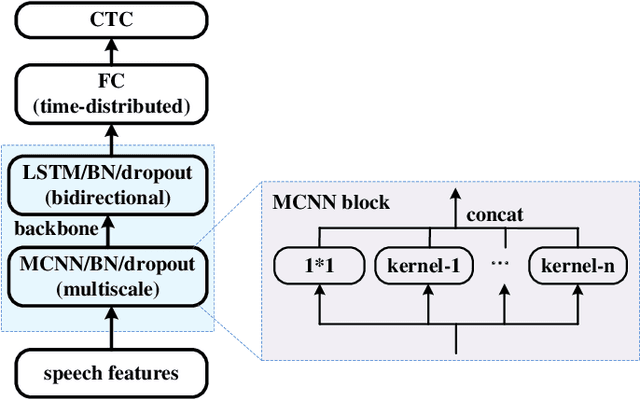
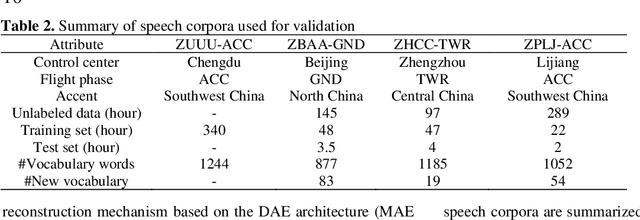
In the domain of air traffic control (ATC) systems, efforts to train a practical automatic speech recognition (ASR) model always faces the problem of small training samples since the collection and annotation of speech samples are expert- and domain-dependent task. In this work, a novel training approach based on pretraining and transfer learning is proposed to address this issue, and an improved end-to-end deep learning model is developed to address the specific challenges of ASR in the ATC domain. An unsupervised pretraining strategy is first proposed to learn speech representations from unlabeled samples for a certain dataset. Specifically, a masking strategy is applied to improve the diversity of the sample without losing their general patterns. Subsequently, transfer learning is applied to fine-tune a pretrained or other optimized baseline models to finally achieves the supervised ASR task. By virtue of the common terminology used in the ATC domain, the transfer learning task can be regarded as a sub-domain adaption task, in which the transferred model is optimized using a joint corpus consisting of baseline samples and new transcribed samples from the target dataset. This joint corpus construction strategy enriches the size and diversity of the training samples, which is important for addressing the issue of the small transcribed corpus. In addition, speed perturbation is applied to augment the new transcribed samples to further improve the quality of the speech corpus. Three real ATC datasets are used to validate the proposed ASR model and training strategies. The experimental results demonstrate that the ASR performance is significantly improved on all three datasets, with an absolute character error rate only one-third of that achieved through the supervised training. The applicability of the proposed strategies to other ASR approaches is also validated.
Text-Guided Synthesis of Artistic Images with Retrieval-Augmented Diffusion Models
Jul 26, 2022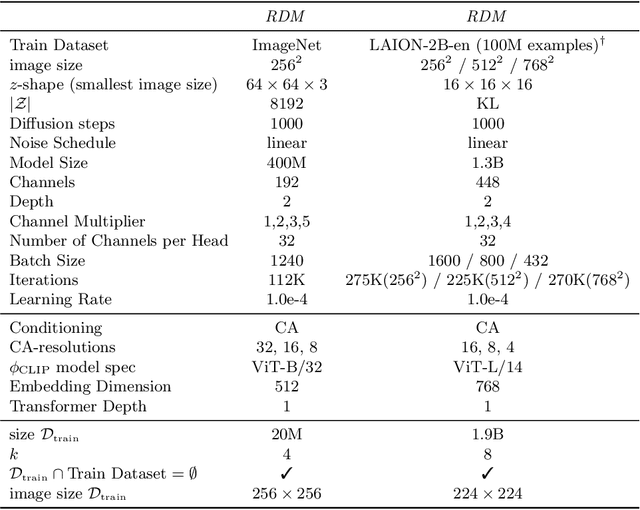
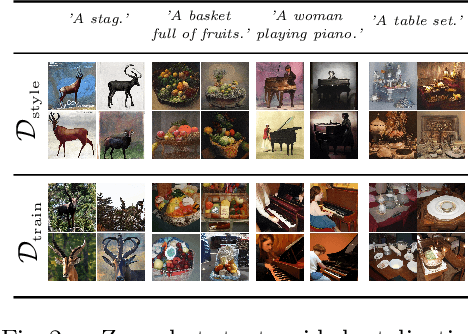

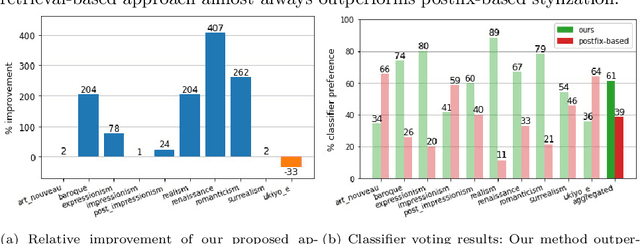
Novel architectures have recently improved generative image synthesis leading to excellent visual quality in various tasks. Of particular note is the field of ``AI-Art'', which has seen unprecedented growth with the emergence of powerful multimodal models such as CLIP. By combining speech and image synthesis models, so-called ``prompt-engineering'' has become established, in which carefully selected and composed sentences are used to achieve a certain visual style in the synthesized image. In this note, we present an alternative approach based on retrieval-augmented diffusion models (RDMs). In RDMs, a set of nearest neighbors is retrieved from an external database during training for each training instance, and the diffusion model is conditioned on these informative samples. During inference (sampling), we replace the retrieval database with a more specialized database that contains, for example, only images of a particular visual style. This provides a novel way to prompt a general trained model after training and thereby specify a particular visual style. As shown by our experiments, this approach is superior to specifying the visual style within the text prompt. We open-source code and model weights at https://github.com/CompVis/latent-diffusion .
Endpoint Detection for Streaming End-to-End Multi-talker ASR
Jan 24, 2022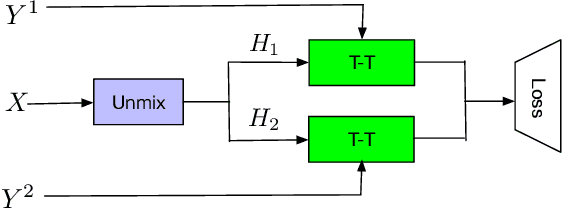
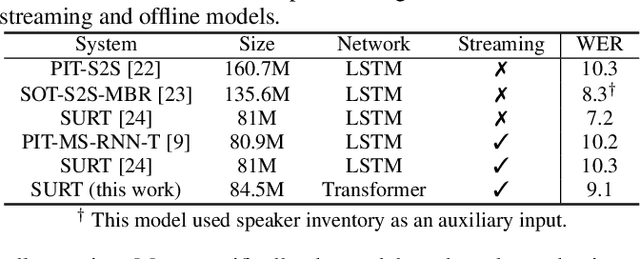
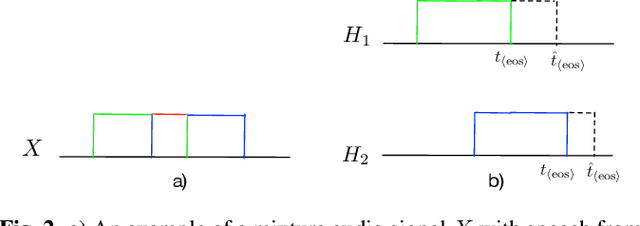
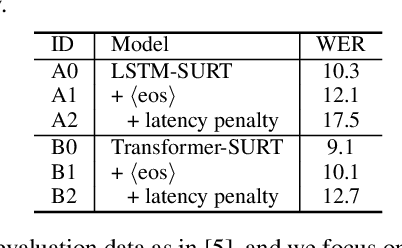
Streaming end-to-end multi-talker speech recognition aims at transcribing the overlapped speech from conversations or meetings with an all-neural model in a streaming fashion, which is fundamentally different from a modular-based approach that usually cascades the speech separation and the speech recognition models trained independently. Previously, we proposed the Streaming Unmixing and Recognition Transducer (SURT) model based on recurrent neural network transducer (RNN-T) for this problem and presented promising results. However, for real applications, the speech recognition system is also required to determine the timestamp when a speaker finishes speaking for prompt system response. This problem, known as endpoint (EP) detection, has not been studied previously for multi-talker end-to-end models. In this work, we address the EP detection problem in the SURT framework by introducing an end-of-sentence token as an output unit, following the practice of single-talker end-to-end models. Furthermore, we also present a latency penalty approach that can significantly cut down the EP detection latency. Our experimental results based on the 2-speaker LibrispeechMix dataset show that the SURT model can achieve promising EP detection without significantly degradation of the recognition accuracy.
Fusing Wav2vec2.0 and BERT into End-to-end Model for Low-resource Speech Recognition
Jan 17, 2021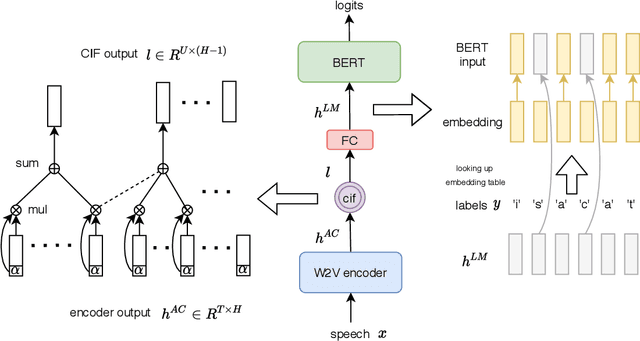
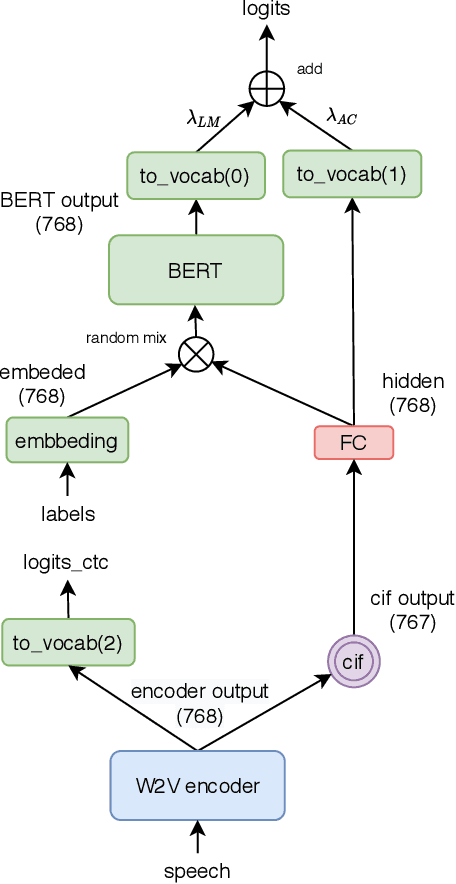
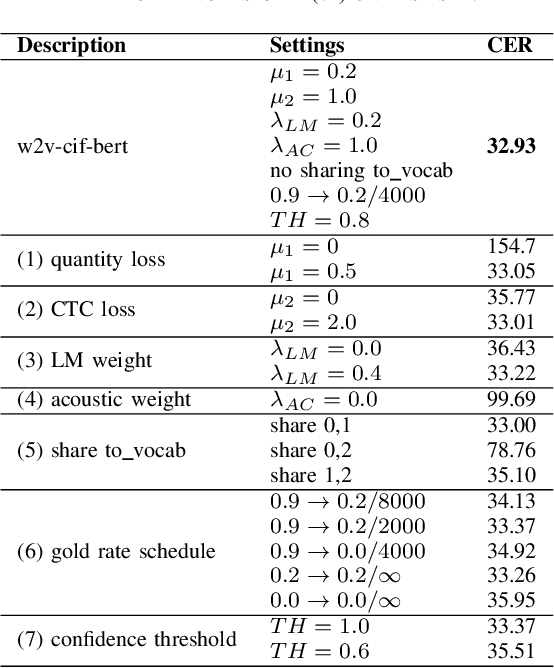
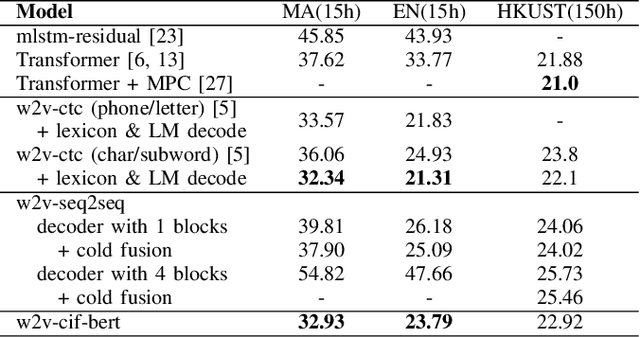
Self-supervised acoustic pre-training has achieved impressive results on low-resource speech recognition tasks. It indicates that the pretrain-and-finetune paradigm is a promising direction. In this work, we propose an end-to-end model for the low-resource speech recognition, which fuses a pre-trained audio encoder (wav2vec2.0) and a pre-trained text decoder (BERT). The two modules are connected by a linear attention mechanism without parameters. A fully connected layer is introduced for hidden mapping between speech and language modalities. Besides, we design an effective fine-tuning strategy to preserve and utilize the text context modeling ability of the pre-trained decoder. Armed with this strategy, our model exhibits distinct faster convergence and better performance. Our model achieves approaching recognition performance in CALLHOME corpus (15h) as the SOTA pipeline modeling.