 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
KoSpeech: Open-Source Toolkit for End-to-End Korean Speech Recognition
Sep 26, 2020
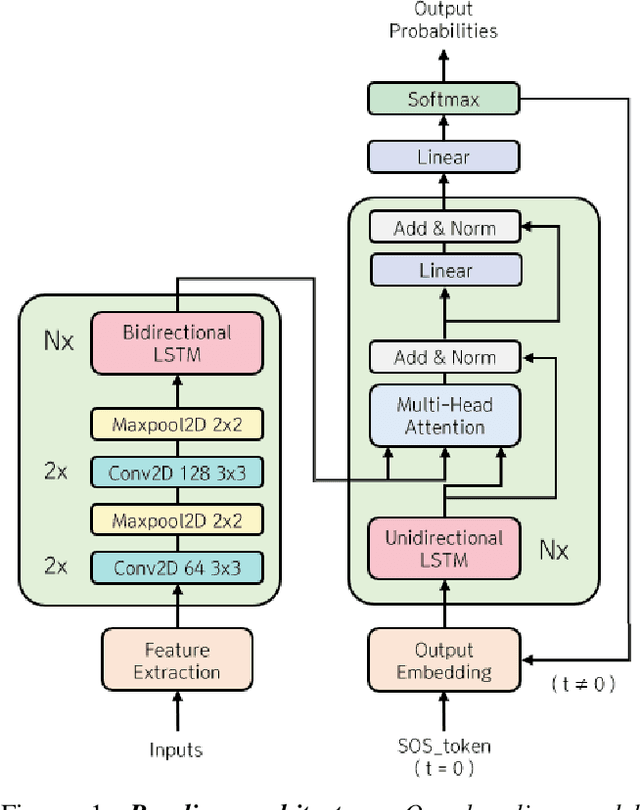


We present KoSpeech, an open-source software, which is modular and extensible end-to-end Korean automatic speech recognition (ASR) toolkit based on the deep learning library PyTorch. Several automatic speech recognition open-source toolkits have been released, but all of them deal with non-Korean languages, such as English (e.g. ESPnet, Espresso). Although AI Hub opened 1,000 hours of Korean speech corpus known as KsponSpeech, there is no established preprocessing method and baseline model to compare model performances. Therefore, we propose preprocessing methods for KsponSpeech corpus and a baseline model for benchmarks. Our baseline model is based on Listen, Attend and Spell (LAS) architecture and ables to customize various training hyperparameters conveniently. By KoSpeech, we hope this could be a guideline for those who research Korean speech recognition. Our baseline model achieved 10.31% character error rate (CER) at KsponSpeech corpus only with the acoustic model. Our source code is available here.
Time-Frequency Localization Using Deep Convolutional Maxout Neural Network in Persian Speech Recognition
Aug 09, 2021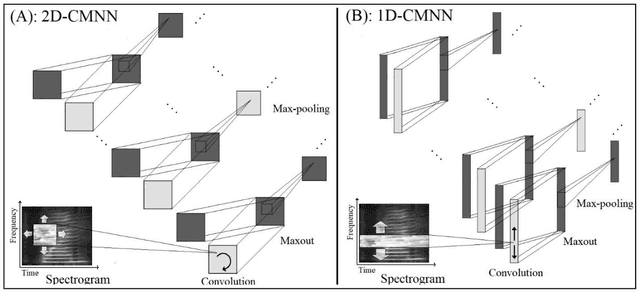
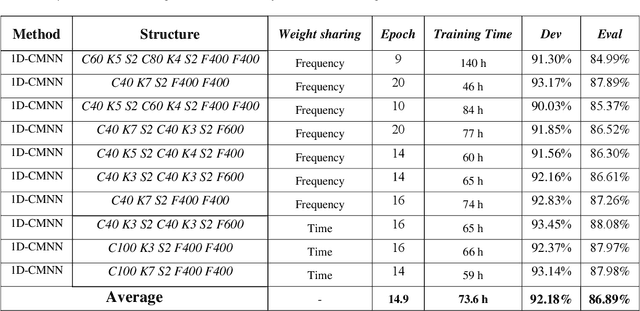
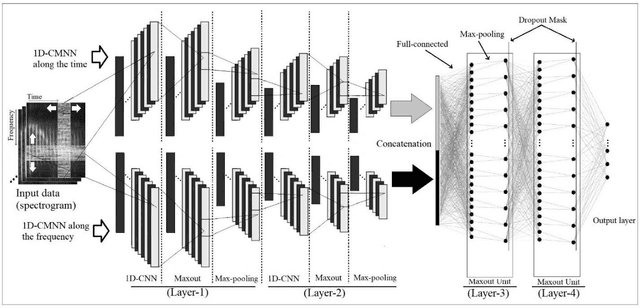
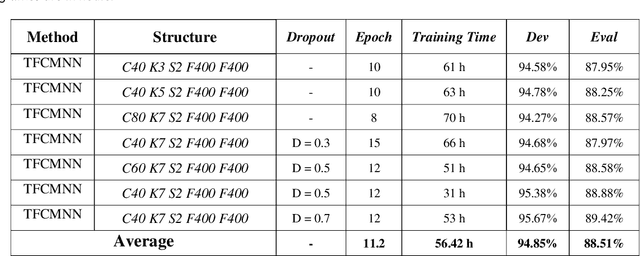
In this paper, a CNN-based structure for time-frequency localization of audio signal information in the ASR acoustic model is proposed for Persian speech recognition. Research has shown that the receptive fields' time-frequency flexibility in some mammals' auditory neurons system improves recognition performance. Biosystems have inspired many artificial systems because of their high efficiency and performance, so time-frequency localization has been used extensively to improve system performance. In the last few years, much work has been done to localize time-frequency information in ASR systems, which has used the spatial immutability properties of methods such as TDNN, CNN and LSTM-RNN. However, most of these models have large parameter volumes and are challenging to train. In the structure we have designed, called Time-Frequency Convolutional Maxout Neural Network (TFCMNN), two parallel blocks consisting of 1D-CMNN each have weight sharing in one dimension, are applied simultaneously but independently to the feature vectors. Then their output is concatenated and applied to a fully connected Maxout network for classification. To improve the performance of this structure, we have used newly developed methods and models such as the maxout, Dropout, and weight normalization. Two experimental sets were designed and implemented on the Persian FARSDAT speech data set to evaluate the performance of this model compared to conventional 1D-CMNN models. According to the experimental results, the average recognition score of TFCMNN models is about 1.6% higher than the average of conventional models. In addition, the average training time of the TFCMNN models is about 17 hours lower than the average training time of traditional models. As a result, as mentioned in other references, time-frequency localization in ASR systems increases system accuracy and speeds up the model training process.
Relative Positional Encoding for Speech Recognition and Direct Translation
May 20, 2020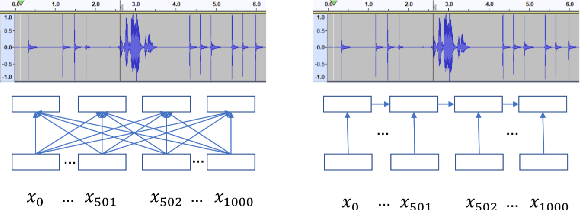
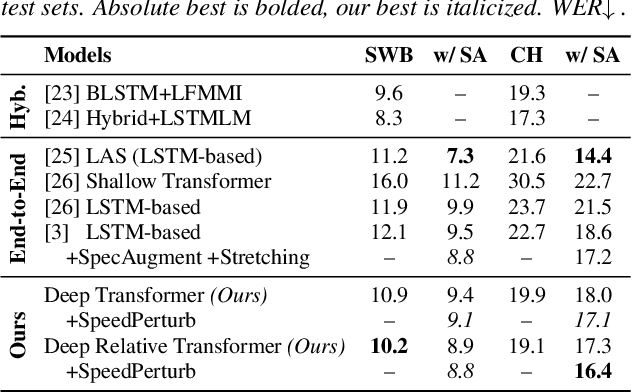


Transformer models are powerful sequence-to-sequence architectures that are capable of directly mapping speech inputs to transcriptions or translations. However, the mechanism for modeling positions in this model was tailored for text modeling, and thus is less ideal for acoustic inputs. In this work, we adapt the relative position encoding scheme to the Speech Transformer, where the key addition is relative distance between input states in the self-attention network. As a result, the network can better adapt to the variable distributions present in speech data. Our experiments show that our resulting model achieves the best recognition result on the Switchboard benchmark in the non-augmentation condition, and the best published result in the MuST-C speech translation benchmark. We also show that this model is able to better utilize synthetic data than the Transformer, and adapts better to variable sentence segmentation quality for speech translation.
A non-causal FFTNet architecture for speech enhancement
Jun 08, 2020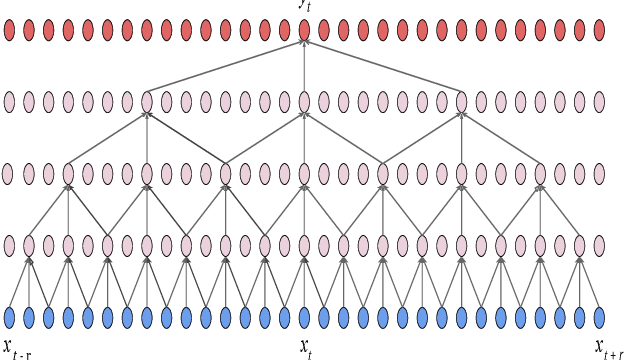
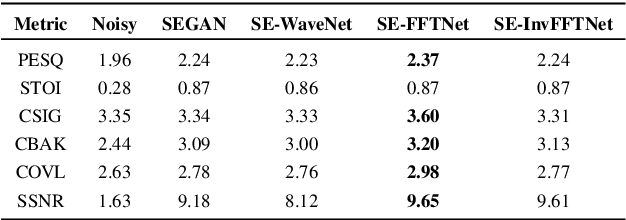
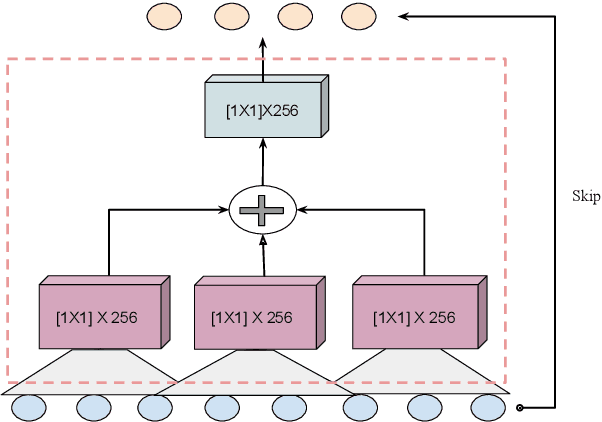

In this paper, we suggest a new parallel, non-causal and shallow waveform domain architecture for speech enhancement based on FFTNet, a neural network for generating high quality audio waveform. In contrast to other waveform based approaches like WaveNet, FFTNet uses an initial wide dilation pattern. Such an architecture better represents the long term correlated structure of speech in the time domain, where noise is usually highly non-correlated, and therefore it is suitable for waveform domain based speech enhancement. To further strengthen this feature of FFTNet, we suggest a non-causal FFTNet architecture, where the present sample in each layer is estimated from the past and future samples of the previous layer. By suggesting a shallow network and applying non-causality within certain limits, the suggested FFTNet for speech enhancement (SE-FFTNet) uses much fewer parameters compared to other neural network based approaches for speech enhancement like WaveNet and SEGAN. Specifically, the suggested network has considerably reduced model parameters: 32% fewer compared to WaveNet and 87% fewer compared to SEGAN. Finally, based on subjective and objective metrics, SE-FFTNet outperforms WaveNet in terms of enhanced signal quality, while it provides equally good performance as SEGAN. A Tensorflow implementation of the architecture is provided at 1 .
CPrune: Compiler-Informed Model Pruning for Efficient Target-Aware DNN Execution
Jul 04, 2022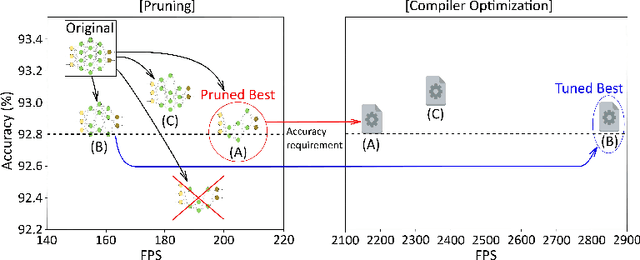
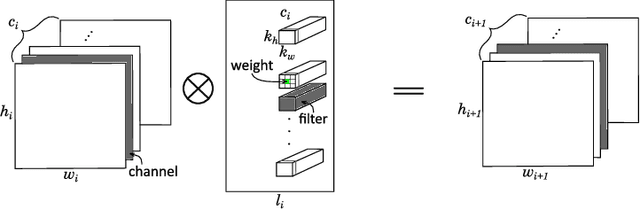
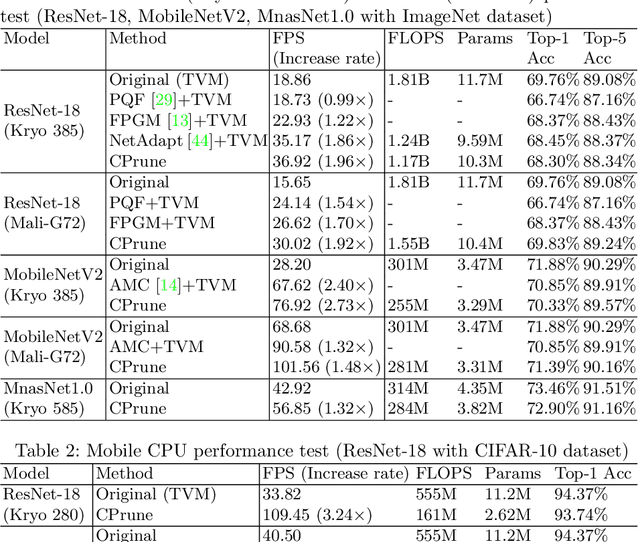
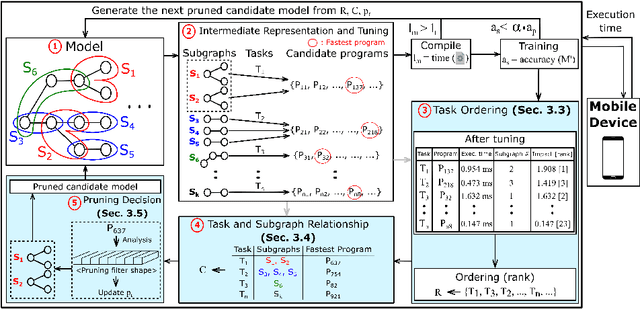
Mobile devices run deep learning models for various purposes, such as image classification and speech recognition. Due to the resource constraints of mobile devices, researchers have focused on either making a lightweight deep neural network (DNN) model using model pruning or generating an efficient code using compiler optimization. Surprisingly, we found that the straightforward integration between model compression and compiler auto-tuning often does not produce the most efficient model for a target device. We propose CPrune, a compiler-informed model pruning for efficient target-aware DNN execution to support an application with a required target accuracy. CPrune makes a lightweight DNN model through informed pruning based on the structural information of subgraphs built during the compiler tuning process. Our experimental results show that CPrune increases the DNN execution speed up to 2.73x compared to the state-of-the-art TVM auto-tune while satisfying the accuracy requirement.
On the Impact of Word Error Rate on Acoustic-Linguistic Speech Emotion Recognition: An Update for the Deep Learning Era
Apr 20, 2021
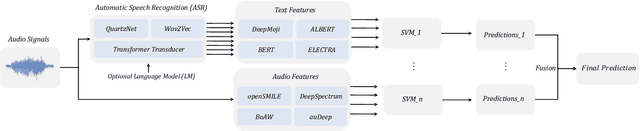
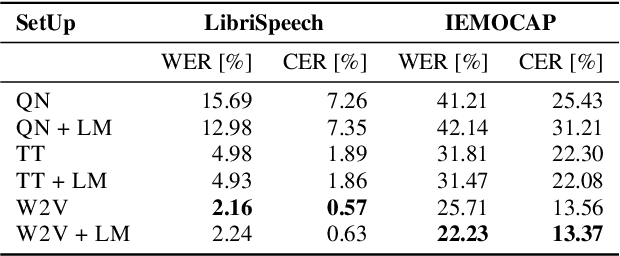

Text encodings from automatic speech recognition (ASR) transcripts and audio representations have shown promise in speech emotion recognition (SER) ever since. Yet, it is challenging to explain the effect of each information stream on the SER systems. Further, more clarification is required for analysing the impact of ASR's word error rate (WER) on linguistic emotion recognition per se and in the context of fusion with acoustic information exploitation in the age of deep ASR systems. In order to tackle the above issues, we create transcripts from the original speech by applying three modern ASR systems, including an end-to-end model trained with recurrent neural network-transducer loss, a model with connectionist temporal classification loss, and a wav2vec framework for self-supervised learning. Afterwards, we use pre-trained textual models to extract text representations from the ASR outputs and the gold standard. For extraction and learning of acoustic speech features, we utilise openSMILE, openXBoW, DeepSpectrum, and auDeep. Finally, we conduct decision-level fusion on both information streams -- acoustics and linguistics. Using the best development configuration, we achieve state-of-the-art unweighted average recall values of $73.6\,\%$ and $73.8\,\%$ on the speaker-independent development and test partitions of IEMOCAP, respectively.
Refining Automatic Speech Recognition System for older adults
Nov 17, 2020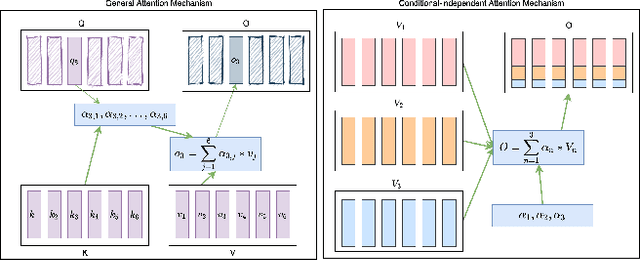
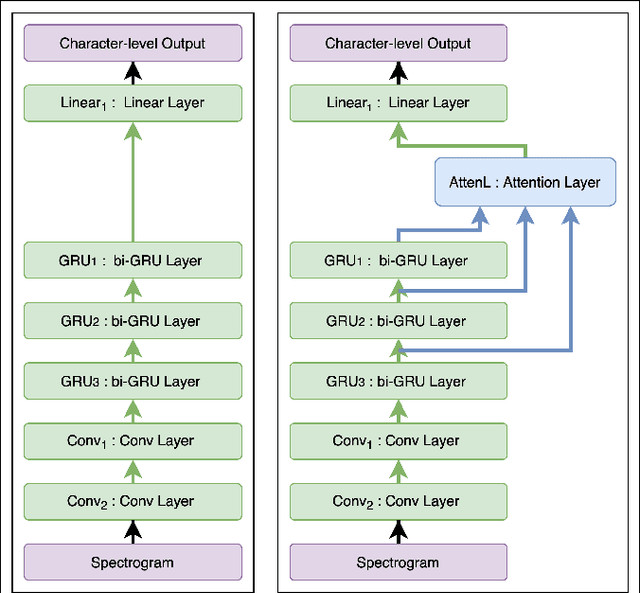
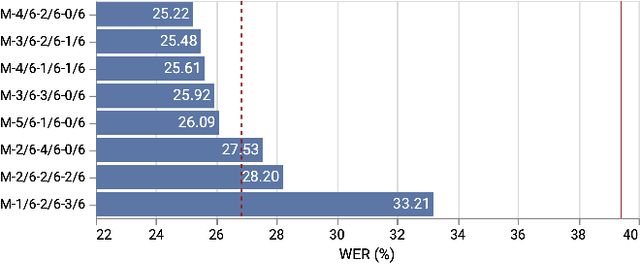
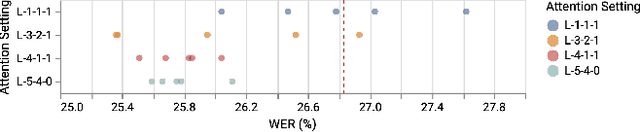
Building a high quality automatic speech recognition (ASR) system with limited training data has been a challenging task particularly for a narrow target population. Open-sourced ASR systems, trained on sufficient data from adults, are susceptible on seniors' speech due to acoustic mismatch between adults and seniors. With 12 hours of training data, we attempt to develop an ASR system for socially isolated seniors (80+ years old) with possible cognitive impairments. We experimentally identify that ASR for the adult population performs poorly on our target population and transfer learning (TL) can boost the system's performance. Standing on the fundamental idea of TL, tuning model parameters, we further improve the system by leveraging an attention mechanism to utilize the model's intermediate information. Our approach achieves 1.58% absolute improvements over the TL model.
Data augmentation for learning predictive models on EEG: a systematic comparison
Jun 29, 2022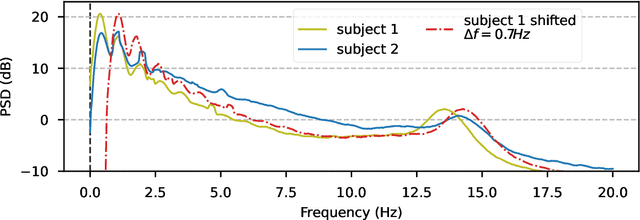

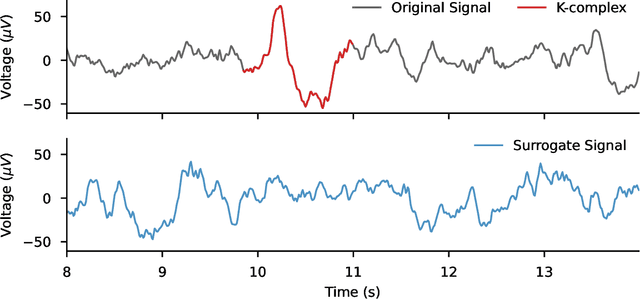

The use of deep learning for electroencephalography (EEG) classification tasks has been rapidly growing in the last years, yet its application has been limited by the relatively small size of EEG datasets. Data augmentation, which consists in artificially increasing the size of the dataset during training, has been a key ingredient to obtain state-of-the-art performances across applications such as computer vision or speech. While a few augmentation transformations for EEG data have been proposed in the literature, their positive impact on performance across tasks remains elusive. In this work, we propose a unified and exhaustive analysis of the main existing EEG augmentations, which are compared in a common experimental setting. Our results highlight the best data augmentations to consider for sleep stage classification and motor imagery brain computer interfaces, showing predictive power improvements greater than 10% in some cases.
A comparison of Vietnamese Statistical Parametric Speech Synthesis Systems
May 26, 2020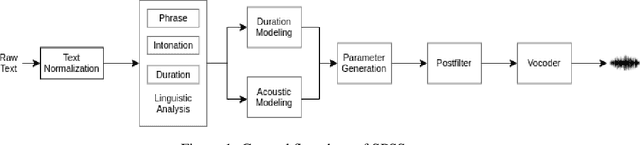
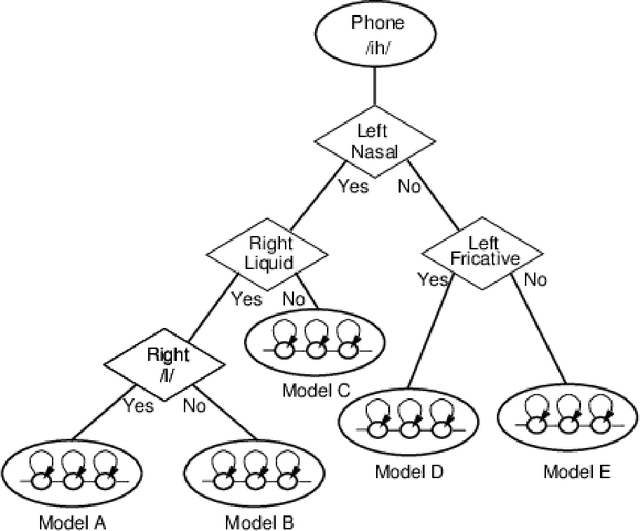
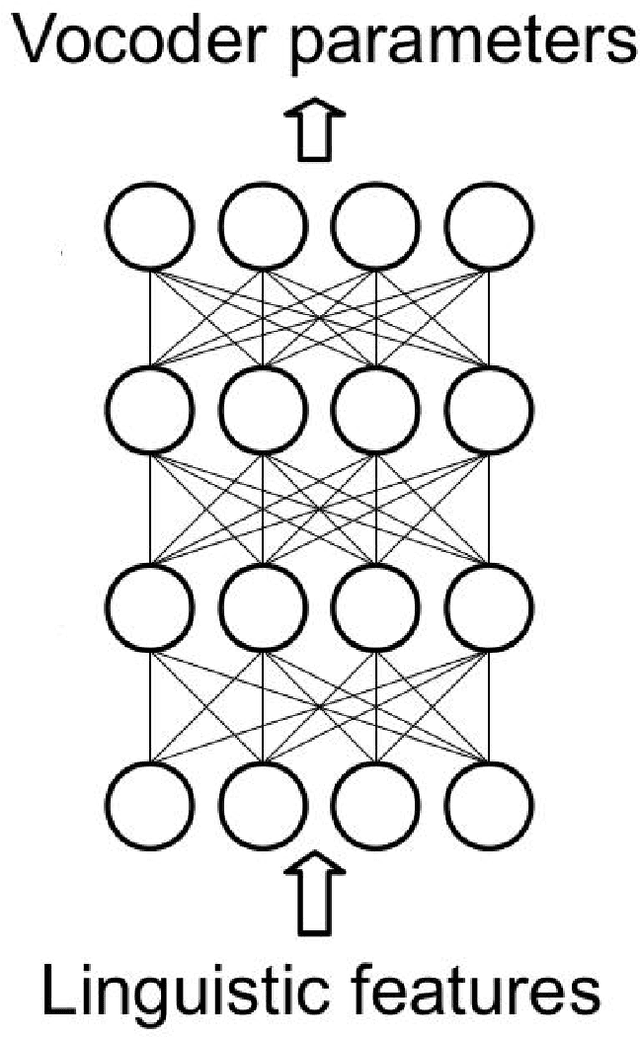
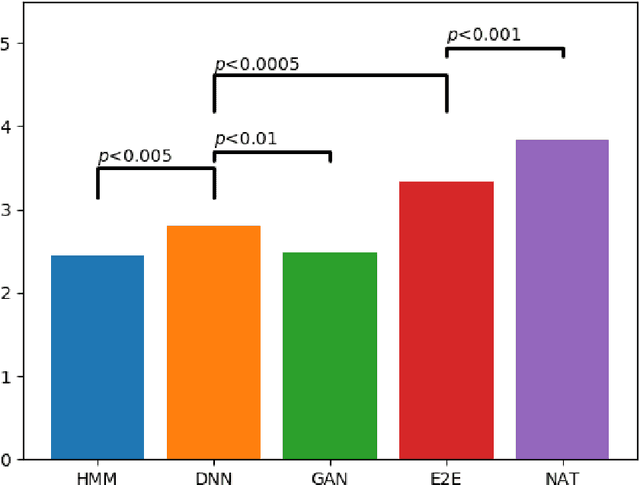
In recent years, statistical parametric speech synthesis (SPSS) systems have been widely utilized in many interactive speech-based systems (e.g.~Amazon's Alexa, Bose's headphones). To select a suitable SPSS system, both speech quality and performance efficiency (e.g.~decoding time) must be taken into account. In the paper, we compared four popular Vietnamese SPSS techniques using: 1) hidden Markov models (HMM), 2) deep neural networks (DNN), 3) generative adversarial networks (GAN), and 4) end-to-end (E2E) architectures, which consists of Tacontron~2 and WaveGlow vocoder in terms of speech quality and performance efficiency. We showed that the E2E systems accomplished the best quality, but required the power of GPU to achieve real-time performance. We also showed that the HMM-based system had inferior speech quality, but it was the most efficient system. Surprisingly, the E2E systems were more efficient than the DNN and GAN in inference on GPU. Surprisingly, the GAN-based system did not outperform the DNN in term of quality.
Thutmose Tagger: Single-pass neural model for Inverse Text Normalization
Jul 29, 2022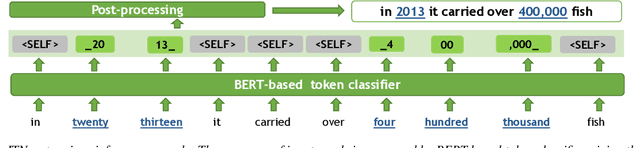
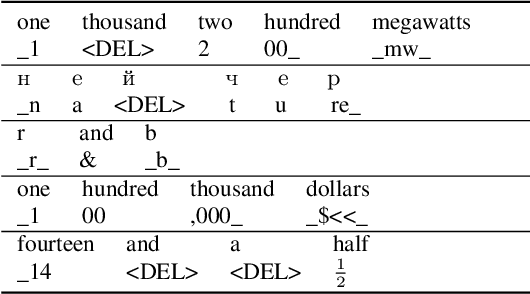

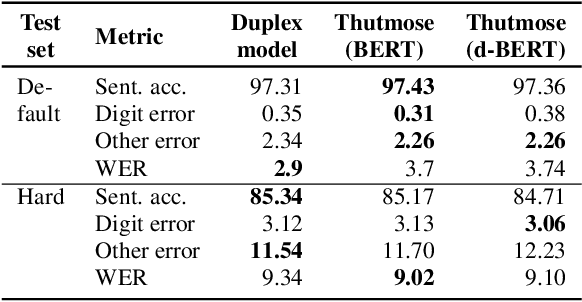
Inverse text normalization (ITN) is an essential post-processing step in automatic speech recognition (ASR). It converts numbers, dates, abbreviations, and other semiotic classes from the spoken form generated by ASR to their written forms. One can consider ITN as a Machine Translation task and use neural sequence-to-sequence models to solve it. Unfortunately, such neural models are prone to hallucinations that could lead to unacceptable errors. To mitigate this issue, we propose a single-pass token classifier model that regards ITN as a tagging task. The model assigns a replacement fragment to every input token or marks it for deletion or copying without changes. We present a dataset preparation method based on the granular alignment of ITN examples. The proposed model is less prone to hallucination errors. The model is trained on the Google Text Normalization dataset and achieves state-of-the-art sentence accuracy on both English and Russian test sets. One-to-one correspondence between tags and input words improves the interpretability of the model's predictions, simplifies debugging, and allows for post-processing corrections. The model is simpler than sequence-to-sequence models and easier to optimize in production settings. The model and the code to prepare the dataset is published as part of NeMo project.