 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Neural Emotion Director: Speech-preserving semantic control of facial expressions in "in-the-wild" videos
Dec 01, 2021
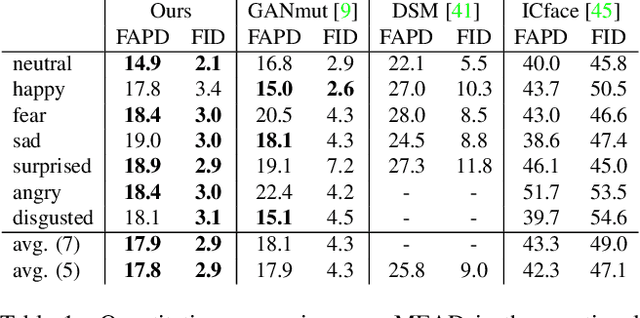
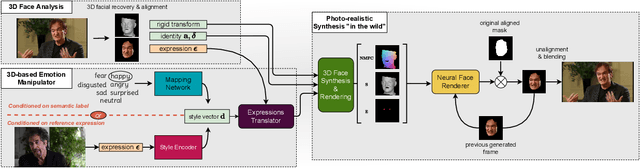


In this paper, we introduce a novel deep learning method for photo-realistic manipulation of the emotional state of actors in "in-the-wild" videos. The proposed method is based on a parametric 3D face representation of the actor in the input scene that offers a reliable disentanglement of the facial identity from the head pose and facial expressions. It then uses a novel deep domain translation framework that alters the facial expressions in a consistent and plausible manner, taking into account their dynamics. Finally, the altered facial expressions are used to photo-realistically manipulate the facial region in the input scene based on an especially-designed neural face renderer. To the best of our knowledge, our method is the first to be capable of controlling the actor's facial expressions by even using as a sole input the semantic labels of the manipulated emotions, while at the same time preserving the speech-related lip movements. We conduct extensive qualitative and quantitative evaluations and comparisons, which demonstrate the effectiveness of our approach and the especially promising results that we obtain. Our method opens a plethora of new possibilities for useful applications of neural rendering technologies, ranging from movie post-production and video games to photo-realistic affective avatars.
Alzheimer's Dementia Recognition through Spontaneous Speech: The ADReSS Challenge
Apr 14, 2020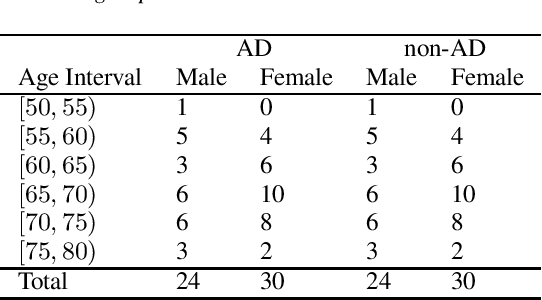
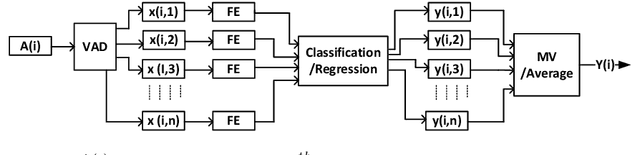
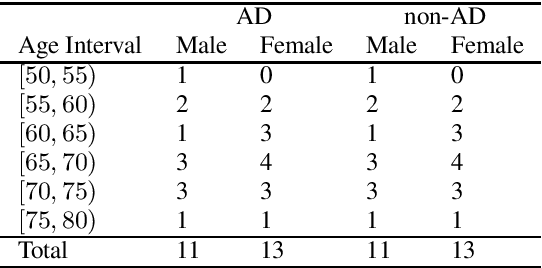

The ADReSS Challenge at INTERSPEECH 2020 defines a shared task through which different approaches to the automated recognition of Alzheimer's dementia based on spontaneous speech can be compared. ADReSS provides researchers with a benchmark speech dataset which has been acoustically pre-processed and balanced in terms of age and gender, defining two cognitive assessment tasks, namely: the Alzheimer's speech classification task and the neuropsychological score regression task. In the Alzheimer's speech classification task, ADReSS challenge participants create models for classifying speech as dementia or healthy control speech. In the the neuropsychological score regression task, participants create models to predict mini-mental state examination scores. This paper describes the ADReSS Challenge in detail and presents a baseline for both tasks, including a feature extraction procedure and results for a classification and a regression model. ADReSS aims to provide the speech and language Alzheimer's research community with a platform for comprehensive methodological comparisons. This will contribute to addressing the lack of standardisation that currently affects the field and shed light on avenues for future research and clinical applicability.
Summary On The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Grand Challenge
Feb 08, 2022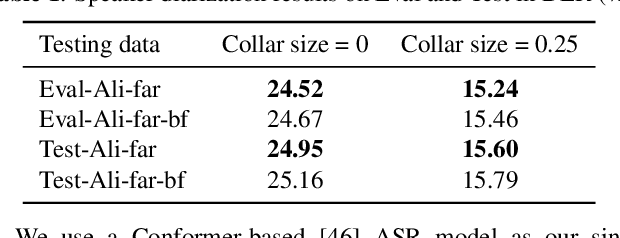
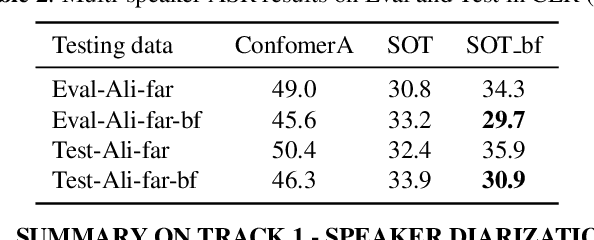
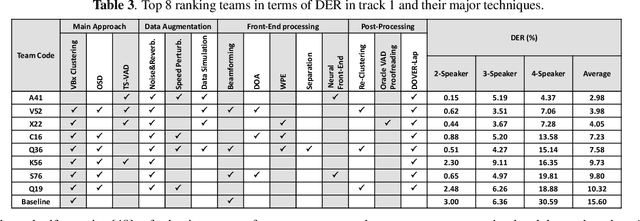
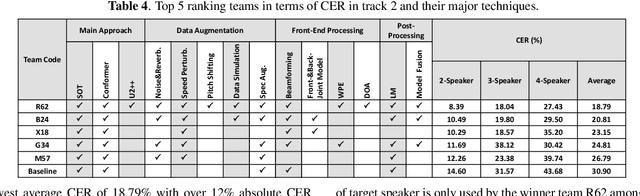
The ICASSP 2022 Multi-channel Multi-party Meeting Transcription Grand Challenge (M2MeT) focuses on one of the most valuable and the most challenging scenarios of speech technologies. The M2MeT challenge has particularly set up two tracks, speaker diarization (track 1) and multi-speaker automatic speech recognition (ASR) (track 2). Along with the challenge, we released 120 hours of real-recorded Mandarin meeting speech data with manual annotation, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. We briefly describe the released dataset, track setups, baselines and summarize the challenge results and major techniques used in the submissions.
Dictionary Attacks on Speaker Verification
Apr 24, 2022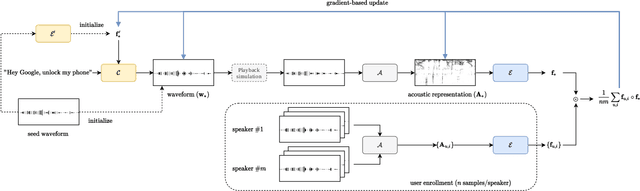
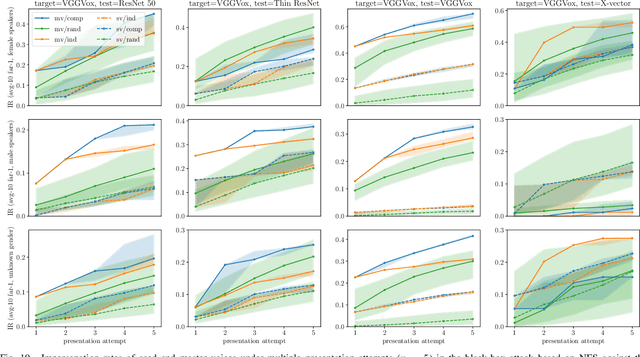

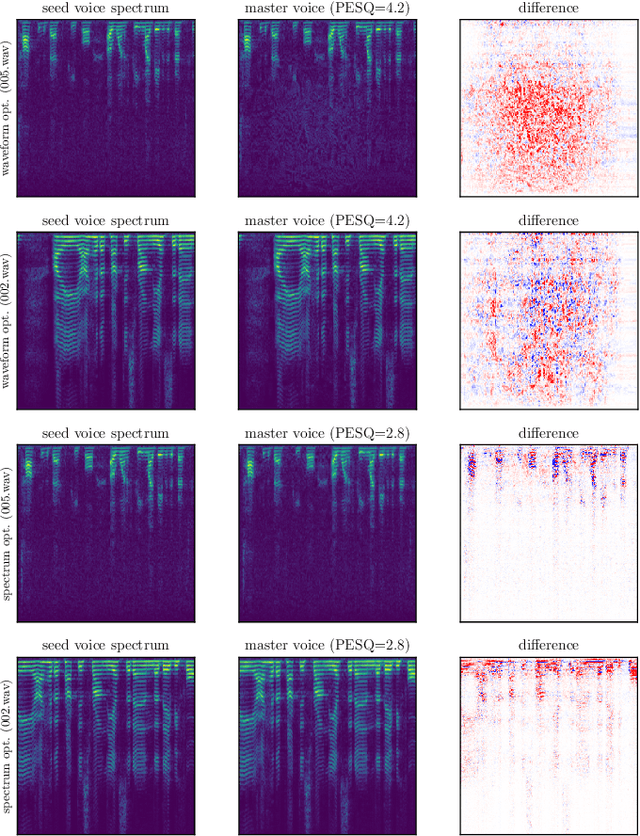
In this paper, we propose dictionary attacks against speaker verification - a novel attack vector that aims to match a large fraction of speaker population by chance. We introduce a generic formulation of the attack that can be used with various speech representations and threat models. The attacker uses adversarial optimization to maximize raw similarity of speaker embeddings between a seed speech sample and a proxy population. The resulting master voice successfully matches a non-trivial fraction of people in an unknown population. Adversarial waveforms obtained with our approach can match on average 69% of females and 38% of males enrolled in the target system at a strict decision threshold calibrated to yield false alarm rate of 1%. By using the attack with a black-box voice cloning system, we obtain master voices that are effective in the most challenging conditions and transferable between speaker encoders. We also show that, combined with multiple attempts, this attack opens even more to serious issues on the security of these systems.
A practical introduction to the Rational Speech Act modeling framework
May 20, 2021Recent advances in computational cognitive science (i.e., simulation-based probabilistic programs) have paved the way for significant progress in formal, implementable models of pragmatics. Rather than describing a pragmatic reasoning process in prose, these models formalize and implement one, deriving both qualitative and quantitative predictions of human behavior -- predictions that consistently prove correct, demonstrating the viability and value of the framework. The current paper provides a practical introduction to and critical assessment of the Bayesian Rational Speech Act modeling framework, unpacking theoretical foundations, exploring technological innovations, and drawing connections to issues beyond current applications.
Sparse Mixture of Local Experts for Efficient Speech Enhancement
May 16, 2020
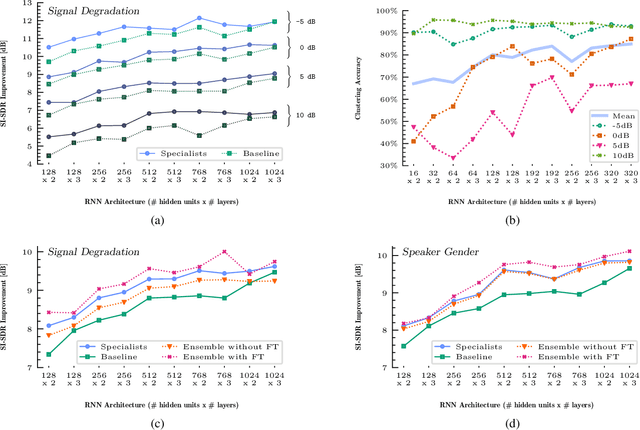
In this paper, we investigate a deep learning approach for speech denoising through an efficient ensemble of specialist neural networks. By splitting up the speech denoising task into non-overlapping subproblems and introducing a classifier, we are able to improve denoising performance while also reducing computational complexity. More specifically, the proposed model incorporates a gating network which assigns noisy speech signals to an appropriate specialist network based on either speech degradation level or speaker gender. In our experiments, a baseline recurrent network is compared against an ensemble of similarly-designed smaller recurrent networks regulated by the auxiliary gating network. Using stochastically generated batches from a large noisy speech corpus, the proposed model learns to estimate a time-frequency masking matrix based on the magnitude spectrogram of an input mixture signal. Both baseline and specialist networks are trained to estimate the ideal ratio mask, while the gating network is trained to perform subproblem classification. Our findings demonstrate that a fine-tuned ensemble network is able to exceed the speech denoising capabilities of a generalist network, doing so with fewer model parameters.
Automatic Analysis of the Emotional Content of Speech in Daylong Child-Centered Recordings from a Neonatal Intensive Care Unit
Jun 14, 2021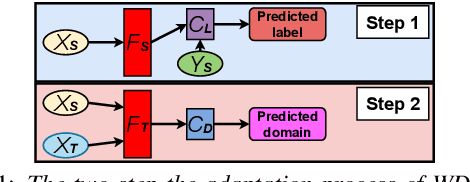
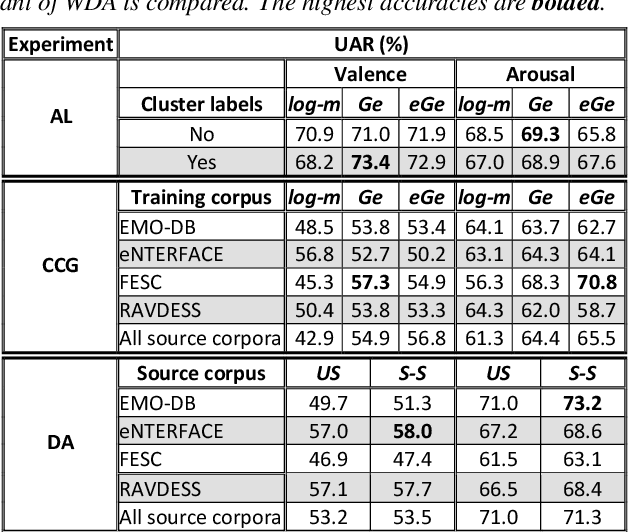
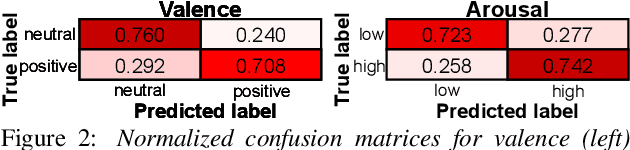
Researchers have recently started to study how the emotional speech heard by young infants can affect their developmental outcomes. As a part of this research, hundreds of hours of daylong recordings from preterm infants' audio environments were collected from two hospitals in Finland and Estonia in the context of so-called APPLE study. In order to analyze the emotional content of speech in such a massive dataset, an automatic speech emotion recognition (SER) system is required. However, there are no emotion labels or existing indomain SER systems to be used for this purpose. In this paper, we introduce this initially unannotated large-scale real-world audio dataset and describe the development of a functional SER system for the Finnish subset of the data. We explore the effectiveness of alternative state-of-the-art techniques to deploy a SER system to a new domain, comparing cross-corpus generalization, WGAN-based domain adaptation, and active learning in the task. As a result, we show that the best-performing models are able to achieve a classification performance of 73.4% unweighted average recall (UAR) and 73.2% UAR for a binary classification for valence and arousal, respectively. The results also show that active learning achieves the most consistent performance compared to the two alternatives.
VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition
Sep 09, 2020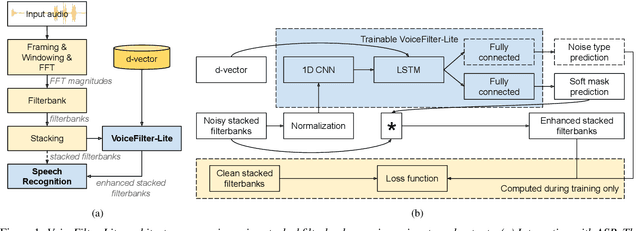

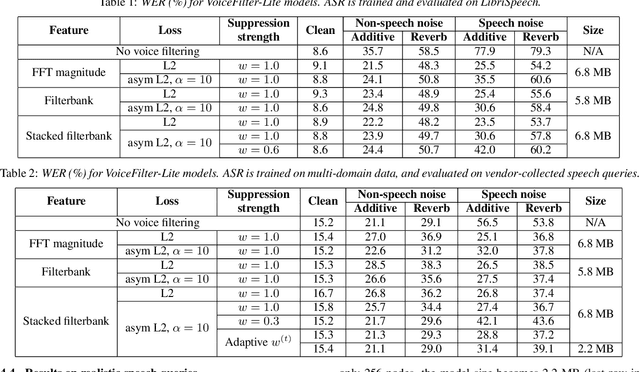
We introduce VoiceFilter-Lite, a single-channel source separation model that runs on the device to preserve only the speech signals from a target user, as part of a streaming speech recognition system. Delivering such a model presents numerous challenges: It should improve the performance when the input signal consists of overlapped speech, and must not hurt the speech recognition performance under all other acoustic conditions. Besides, this model must be tiny, fast, and perform inference in a streaming fashion, in order to have minimal impact on CPU, memory, battery and latency. We propose novel techniques to meet these multi-faceted requirements, including using a new asymmetric loss, and adopting adaptive runtime suppression strength. We also show that such a model can be quantized as a 8-bit integer model and run in realtime.
ASCEND: A Spontaneous Chinese-English Dataset for Code-switching in Multi-turn Conversation
Dec 17, 2021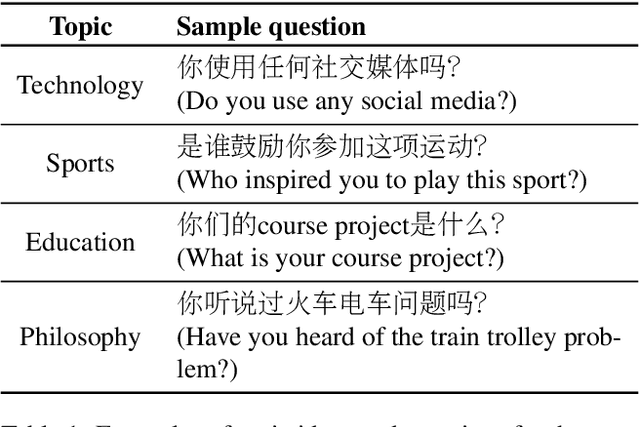

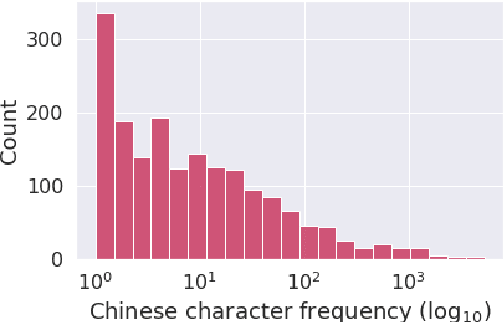
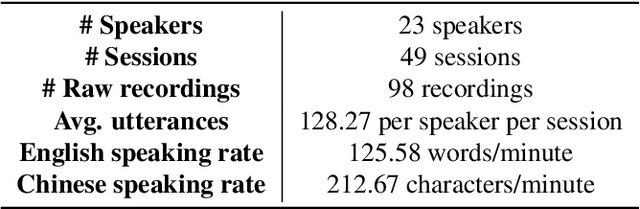
Code-switching is a speech phenomenon when a speaker switches language during a conversation. Despite the spontaneous nature of code-switching in conversational spoken language, most existing works collect code-switching data through read speech instead of spontaneous speech. ASCEND (A Spontaneous Chinese-English Dataset) introduces a high-quality resource of spontaneous multi-turn conversational dialogue Chinese-English code-switching corpus collected in Hong Kong. We report ASCEND's design and procedure of collecting the speech data, including the annotations in this work. ASCEND includes 23 bilinguals that are fluent in both Chinese and English and consists of 10.62 hours clean speech corpus.
DeepFry: Identifying Vocal Fry Using Deep Neural Networks
Mar 31, 2022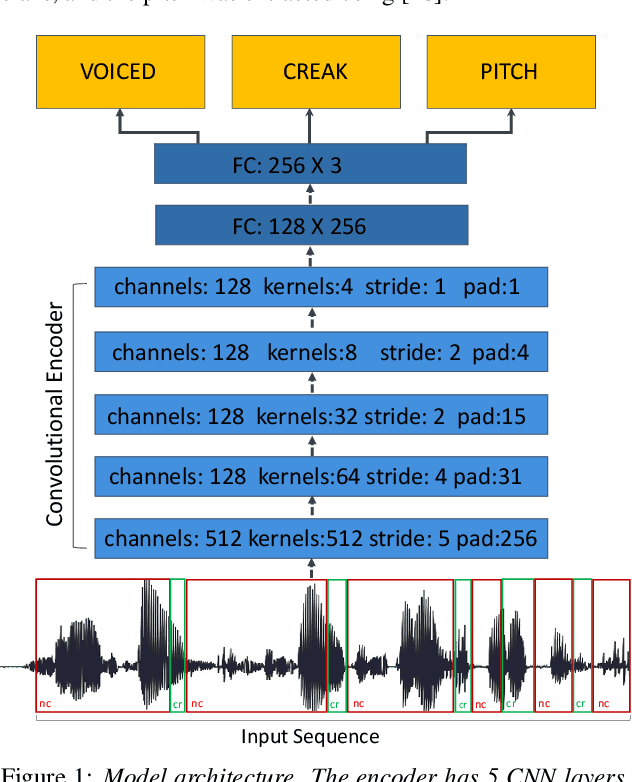
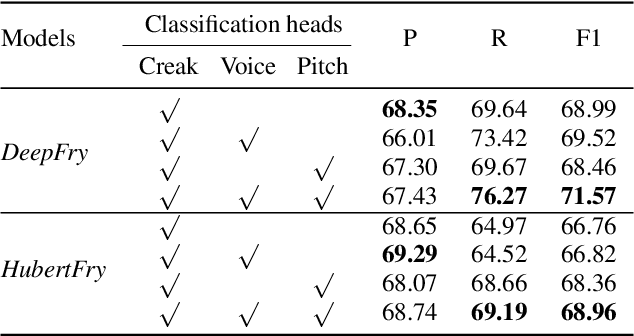

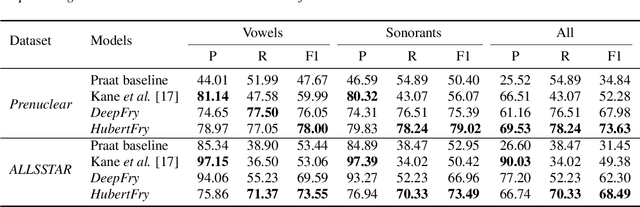
Vocal fry or creaky voice refers to a voice quality characterized by irregular glottal opening and low pitch. It occurs in diverse languages and is prevalent in American English, where it is used not only to mark phrase finality, but also sociolinguistic factors and affect. Due to its irregular periodicity, creaky voice challenges automatic speech processing and recognition systems, particularly for languages where creak is frequently used. This paper proposes a deep learning model to detect creaky voice in fluent speech. The model is composed of an encoder and a classifier trained together. The encoder takes the raw waveform and learns a representation using a convolutional neural network. The classifier is implemented as a multi-headed fully-connected network trained to detect creaky voice, voicing, and pitch, where the last two are used to refine creak prediction. The model is trained and tested on speech of American English speakers, annotated for creak by trained phoneticians. We evaluated the performance of our system using two encoders: one is tailored for the task, and the other is based on a state-of-the-art unsupervised representation. Results suggest our best-performing system has improved recall and F1 scores compared to previous methods on unseen data.