 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Prosody Learning Mechanism for Speech Synthesis System Without Text Length Limit
Aug 13, 2020
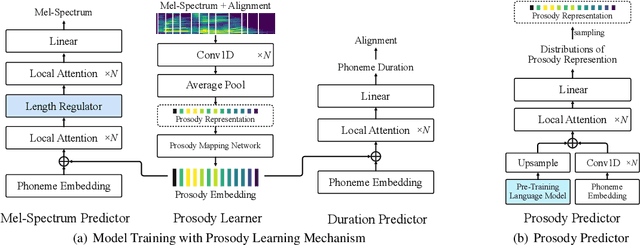
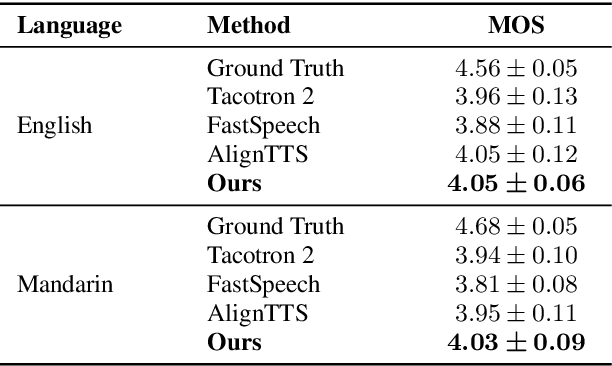


Recent neural speech synthesis systems have gradually focused on the control of prosody to improve the quality of synthesized speech, but they rarely consider the variability of prosody and the correlation between prosody and semantics together. In this paper, a prosody learning mechanism is proposed to model the prosody of speech based on TTS system, where the prosody information of speech is extracted from the melspectrum by a prosody learner and combined with the phoneme sequence to reconstruct the mel-spectrum. Meanwhile, the sematic features of text from the pre-trained language model is introduced to improve the prosody prediction results. In addition, a novel self-attention structure, named as local attention, is proposed to lift this restriction of input text length, where the relative position information of the sequence is modeled by the relative position matrices so that the position encodings is no longer needed. Experiments on English and Mandarin show that speech with more satisfactory prosody has obtained in our model. Especially in Mandarin synthesis, our proposed model outperforms baseline model with a MOS gap of 0.08, and the overall naturalness of the synthesized speech has been significantly improved.
CPrune: Compiler-Informed Model Pruning for Efficient Target-Aware DNN Execution
Jul 04, 2022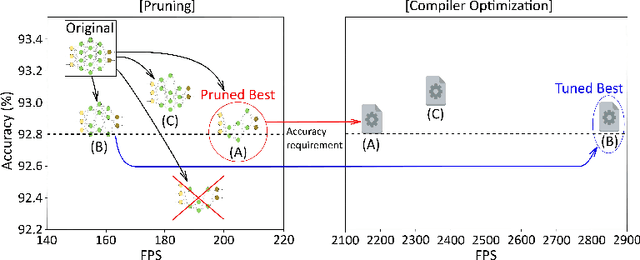
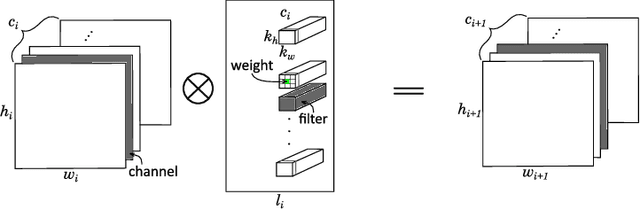
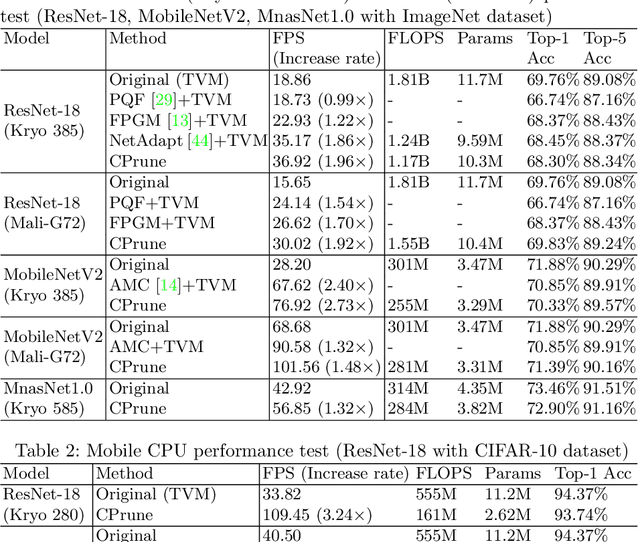
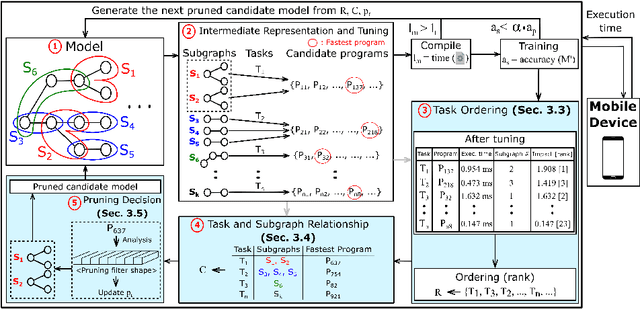
Mobile devices run deep learning models for various purposes, such as image classification and speech recognition. Due to the resource constraints of mobile devices, researchers have focused on either making a lightweight deep neural network (DNN) model using model pruning or generating an efficient code using compiler optimization. Surprisingly, we found that the straightforward integration between model compression and compiler auto-tuning often does not produce the most efficient model for a target device. We propose CPrune, a compiler-informed model pruning for efficient target-aware DNN execution to support an application with a required target accuracy. CPrune makes a lightweight DNN model through informed pruning based on the structural information of subgraphs built during the compiler tuning process. Our experimental results show that CPrune increases the DNN execution speed up to 2.73x compared to the state-of-the-art TVM auto-tune while satisfying the accuracy requirement.
Thutmose Tagger: Single-pass neural model for Inverse Text Normalization
Jul 29, 2022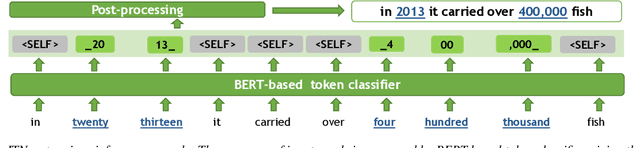
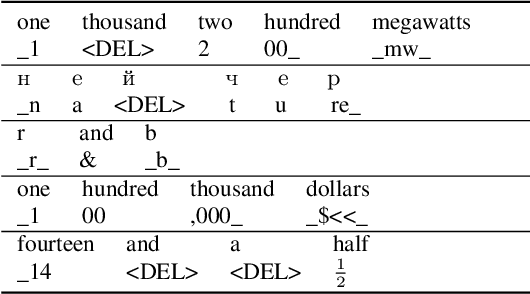

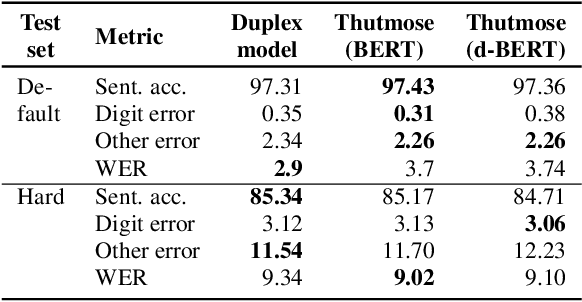
Inverse text normalization (ITN) is an essential post-processing step in automatic speech recognition (ASR). It converts numbers, dates, abbreviations, and other semiotic classes from the spoken form generated by ASR to their written forms. One can consider ITN as a Machine Translation task and use neural sequence-to-sequence models to solve it. Unfortunately, such neural models are prone to hallucinations that could lead to unacceptable errors. To mitigate this issue, we propose a single-pass token classifier model that regards ITN as a tagging task. The model assigns a replacement fragment to every input token or marks it for deletion or copying without changes. We present a dataset preparation method based on the granular alignment of ITN examples. The proposed model is less prone to hallucination errors. The model is trained on the Google Text Normalization dataset and achieves state-of-the-art sentence accuracy on both English and Russian test sets. One-to-one correspondence between tags and input words improves the interpretability of the model's predictions, simplifies debugging, and allows for post-processing corrections. The model is simpler than sequence-to-sequence models and easier to optimize in production settings. The model and the code to prepare the dataset is published as part of NeMo project.
Multi-Task Learning with Sentiment, Emotion, and Target Detection to Recognize Hate Speech and Offensive Language
Sep 21, 2021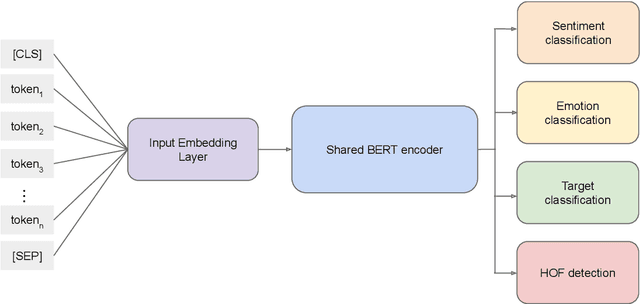
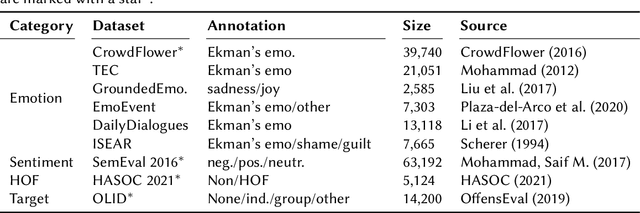
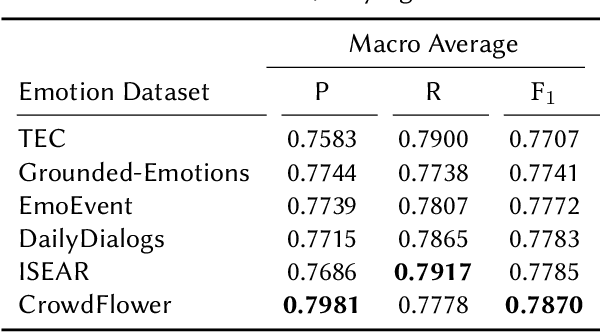
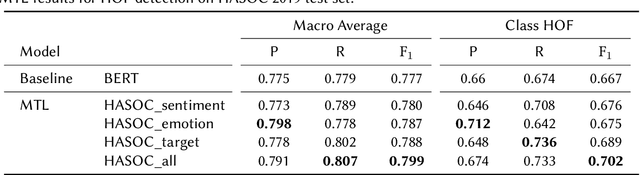
The recognition of hate speech and offensive language (HOF) is commonly formulated as a classification task to decide if a text contains HOF. We investigate whether HOF detection can profit by taking into account the relationships between HOF and similar concepts: (a) HOF is related to sentiment analysis because hate speech is typically a negative statement and expresses a negative opinion; (b) it is related to emotion analysis, as expressed hate points to the author experiencing (or pretending to experience) anger while the addressees experience (or are intended to experience) fear. (c) Finally, one constituting element of HOF is the mention of a targeted person or group. On this basis, we hypothesize that HOF detection shows improvements when being modeled jointly with these concepts, in a multi-task learning setup. We base our experiments on existing data sets for each of these concepts (sentiment, emotion, target of HOF) and evaluate our models as a participant (as team IMS-SINAI) in the HASOC FIRE 2021 English Subtask 1A. Based on model-selection experiments in which we consider multiple available resources and submissions to the shared task, we find that the combination of the CrowdFlower emotion corpus, the SemEval 2016 Sentiment Corpus, and the OffensEval 2019 target detection data leads to an F1 =.79 in a multi-head multi-task learning model based on BERT, in comparison to .7895 of plain BERT. On the HASOC 2019 test data, this result is more substantial with an increase by 2pp in F1 and a considerable increase in recall. Across both data sets (2019, 2021), the recall is particularly increased for the class of HOF (6pp for the 2019 data and 3pp for the 2021 data), showing that MTL with emotion, sentiment, and target identification is an appropriate approach for early warning systems that might be deployed in social media platforms.
Listen with Intent: Improving Speech Recognition with Audio-to-Intent Front-End
May 14, 2021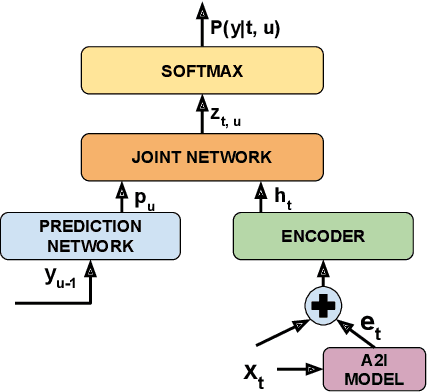
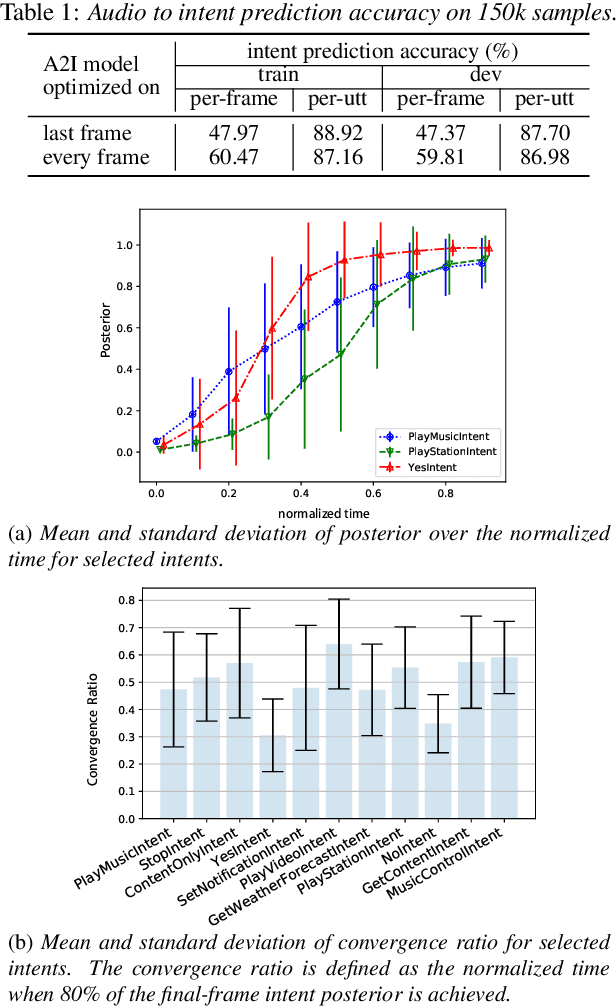
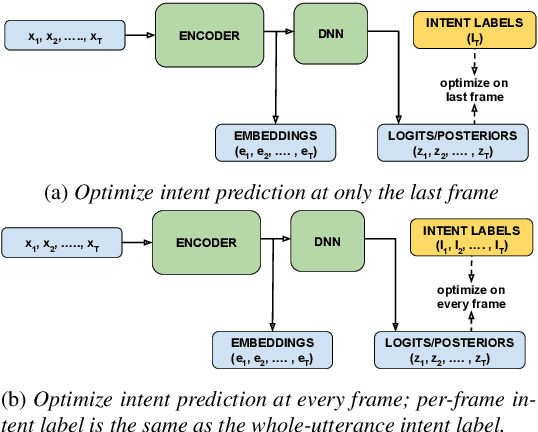
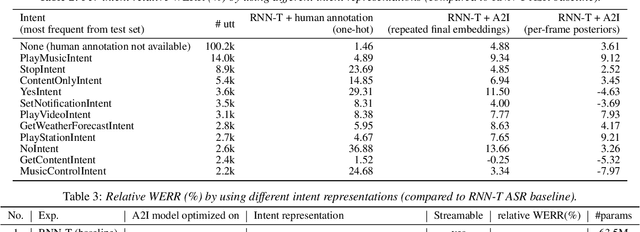
Comprehending the overall intent of an utterance helps a listener recognize the individual words spoken. Inspired by this fact, we perform a novel study of the impact of explicitly incorporating intent representations as additional information to improve a recurrent neural network-transducer (RNN-T) based automatic speech recognition (ASR) system. An audio-to-intent (A2I) model encodes the intent of the utterance in the form of embeddings or posteriors, and these are used as auxiliary inputs for RNN-T training and inference. Experimenting with a 50k-hour far-field English speech corpus, this study shows that when running the system in non-streaming mode, where intent representation is extracted from the entire utterance and then used to bias streaming RNN-T search from the start, it provides a 5.56% relative word error rate reduction (WERR). On the other hand, a streaming system using per-frame intent posteriors as extra inputs for the RNN-T ASR system yields a 3.33% relative WERR. A further detailed analysis of the streaming system indicates that our proposed method brings especially good gain on media-playing related intents (e.g. 9.12% relative WERR on PlayMusicIntent).
Complex Spectral Mapping With Attention Based Convolution Recrrent Neural Network for Speech Enhancement
Apr 12, 2021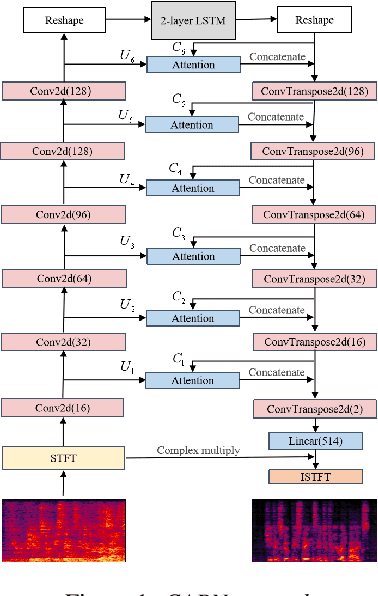
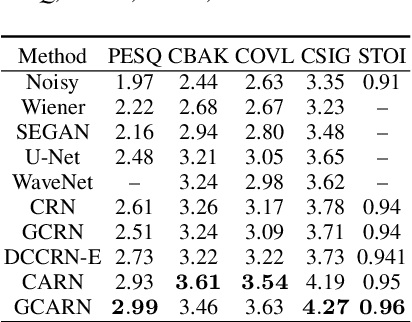
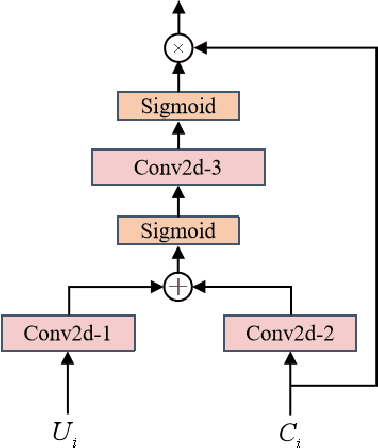
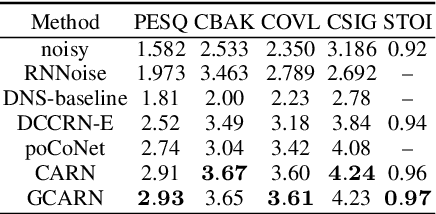
Speech enhancement has benefited from the success of deep learning in terms of intelligibility and perceptual quality. Conventional time-frequency (TF) domain methods focus on predicting TF-masks or speech spectrum,via a naive convolution neural network or recurrent neural network.Some recent studies were based on Complex spectral Mapping convolution recurrent neural network (CRN) . These models skiped directly from encoder layers' output and decoder layers' input ,which maybe thoughtless. We proposed an attention mechanism based skip connection between encoder and decoder layers,namely Complex Spectral Mapping With Attention Based Convolution Recurrent Neural Network (CARN).Compared with CRN model,the proposed CARN model improved more than 10% relatively at several metrics such as PESQ,CBAK,COVL,CSIG and son,and outperformed the place 1st model in both real time and non-real time track of the DNS Challenge 2020 at these metrics.
Data augmentation for learning predictive models on EEG: a systematic comparison
Jun 29, 2022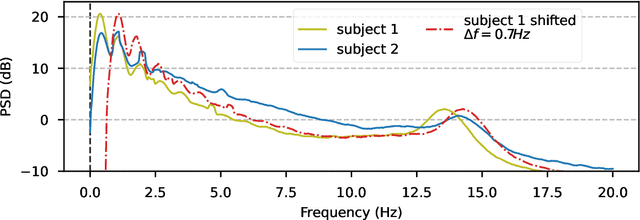

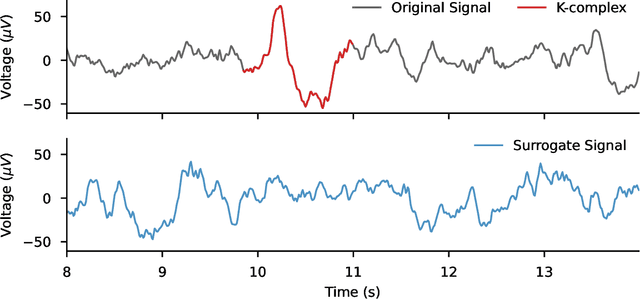

The use of deep learning for electroencephalography (EEG) classification tasks has been rapidly growing in the last years, yet its application has been limited by the relatively small size of EEG datasets. Data augmentation, which consists in artificially increasing the size of the dataset during training, has been a key ingredient to obtain state-of-the-art performances across applications such as computer vision or speech. While a few augmentation transformations for EEG data have been proposed in the literature, their positive impact on performance across tasks remains elusive. In this work, we propose a unified and exhaustive analysis of the main existing EEG augmentations, which are compared in a common experimental setting. Our results highlight the best data augmentations to consider for sleep stage classification and motor imagery brain computer interfaces, showing predictive power improvements greater than 10% in some cases.
Hidden bawls, whispers, and yelps: can text be made to sound more than just its words?
Feb 22, 2022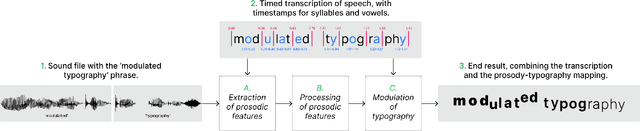
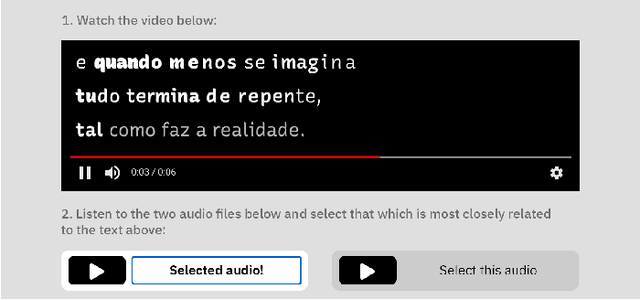
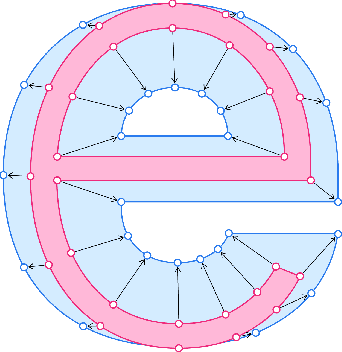

Whether a word was bawled, whispered, or yelped, captions will typically represent it in the same way. If they are your only way to access what is being said, subjective nuances expressed in the voice will be lost. Since so much of communication is carried by these nuances, we posit that if captions are to be used as an accurate representation of speech, embedding visual representations of paralinguistic qualities into captions could help readers use them to better understand speech beyond its mere textual content. This paper presents a model for processing vocal prosody (its loudness, pitch, and duration) and mapping it into visual dimensions of typography (respectively, font-weight, baseline shift, and letter-spacing), creating a visual representation of these lost vocal subtleties that can be embedded directly into the typographical form of text. An evaluation was carried out where participants were exposed to this speech-modulated typography and asked to match it to its originating audio, presented between similar alternatives. Participants (n=117) were able to correctly identify the original audios with an average accuracy of 65%, with no significant difference when showing them modulations as animated or static text. Additionally, participants' comments showed their mental models of speech-modulated typography varied widely.
Cyclic Defense GAN Against Speech Adversarial Attacks
Mar 26, 2021
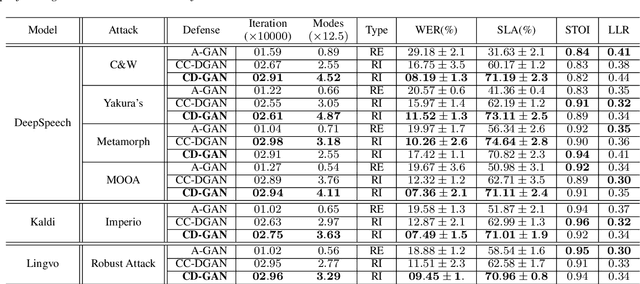
This paper proposes a new defense approach for counteracting with state-of-the-art white and black-box adversarial attack algorithms. Our approach fits in the category of implicit reactive defense algorithms since it does not directly manipulate the potentially malicious input signals. Instead, it reconstructs a similar signal with a synthesized spectrogram using a cyclic generative adversarial network. This cyclic framework helps to yield a stable generative model. Finally, we feed the reconstructed signal into the speech-to-text model for transcription. The conducted experiments on targeted and non-targeted adversarial attacks developed for attacking DeepSpeech, Kaldi, and Lingvo models demonstrate the proposed defense's effectiveness in adverse scenarios.
VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition
Sep 09, 2020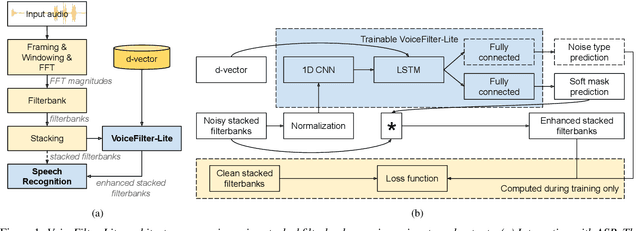

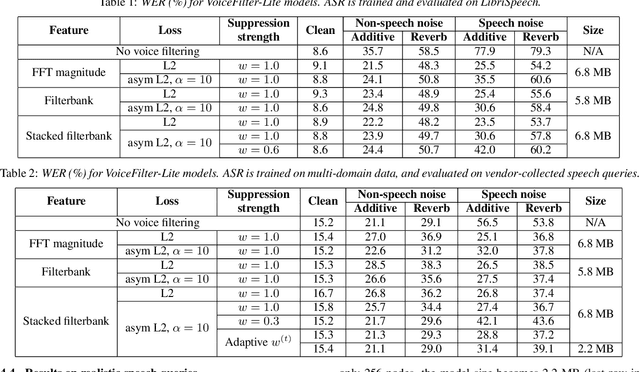
We introduce VoiceFilter-Lite, a single-channel source separation model that runs on the device to preserve only the speech signals from a target user, as part of a streaming speech recognition system. Delivering such a model presents numerous challenges: It should improve the performance when the input signal consists of overlapped speech, and must not hurt the speech recognition performance under all other acoustic conditions. Besides, this model must be tiny, fast, and perform inference in a streaming fashion, in order to have minimal impact on CPU, memory, battery and latency. We propose novel techniques to meet these multi-faceted requirements, including using a new asymmetric loss, and adopting adaptive runtime suppression strength. We also show that such a model can be quantized as a 8-bit integer model and run in realtime.