 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Masked Autoencoders that Listen
Jul 13, 2022
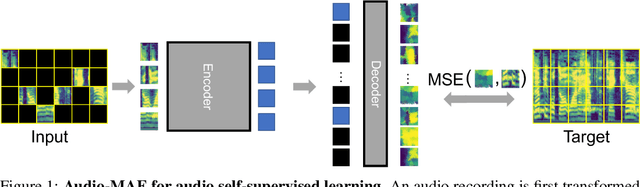
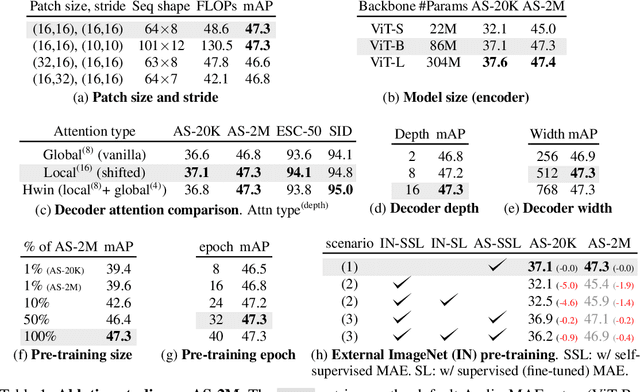

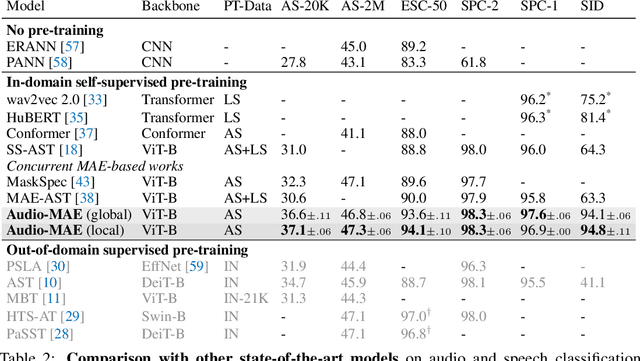
This paper studies a simple extension of image-based Masked Autoencoders (MAE) to self-supervised representation learning from audio spectrograms. Following the Transformer encoder-decoder design in MAE, our Audio-MAE first encodes audio spectrogram patches with a high masking ratio, feeding only the non-masked tokens through encoder layers. The decoder then re-orders and decodes the encoded context padded with mask tokens, in order to reconstruct the input spectrogram. We find it beneficial to incorporate local window attention in the decoder, as audio spectrograms are highly correlated in local time and frequency bands. We then fine-tune the encoder with a lower masking ratio on target datasets. Empirically, Audio-MAE sets new state-of-the-art performance on six audio and speech classification tasks, outperforming other recent models that use external supervised pre-training. The code and models will be at https://github.com/facebookresearch/AudioMAE.
SLNSpeech: solving extended speech separation problem by the help of sign language
Jul 21, 2020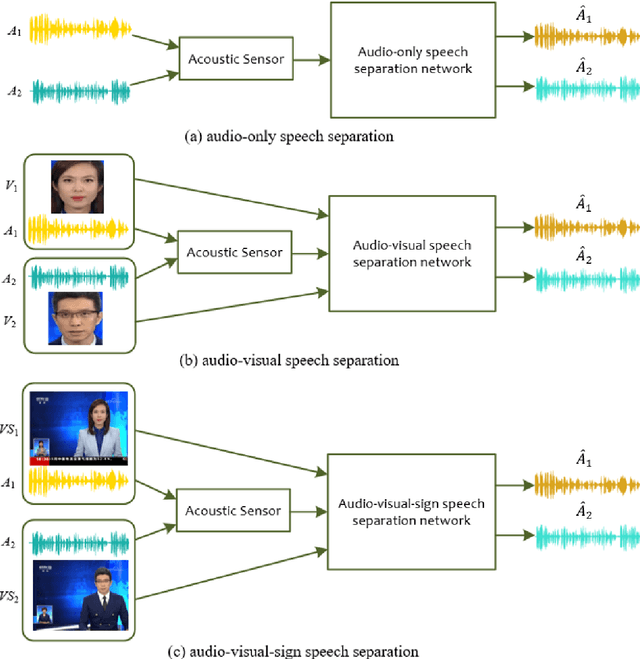


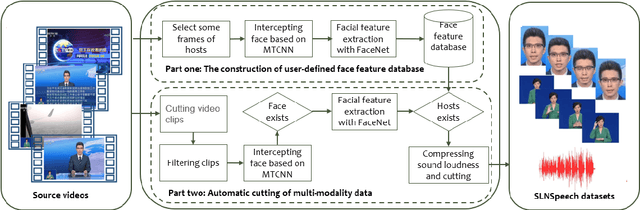
A speech separation task can be roughly divided into audio-only separation and audio-visual separation. In order to make speech separation technology applied in the real scenario of the disabled, this paper presents an extended speech separation problem which refers in particular to sign language assisted speech separation. However, most existing datasets for speech separation are audios and videos which contain audio and/or visual modalities. To address the extended speech separation problem, we introduce a large-scale dataset named Sign Language News Speech (SLNSpeech) dataset in which three modalities of audio, visual, and sign language are coexisted. Then, we design a general deep learning network for the self-supervised learning of three modalities, particularly, using sign language embeddings together with audio or audio-visual information for better solving the speech separation task. Specifically, we use 3D residual convolutional network to extract sign language features and use pretrained VGGNet model to exact visual features. After that, an improved U-Net with skip connections in feature extraction stage is applied for learning the embeddings among the mixed spectrogram transformed from source audios, the sign language features and visual features. Experiments results show that, besides visual modality, sign language modality can also be used alone to supervise speech separation task. Moreover, we also show the effectiveness of sign language assisted speech separation when the visual modality is disturbed. Source code will be released in http://cheertt.top/homepage/
Vietnamese Capitalization and Punctuation Recovery Models
Jul 04, 2022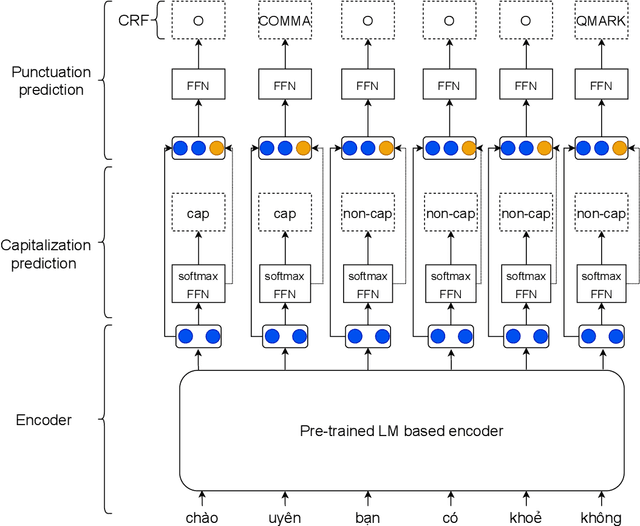
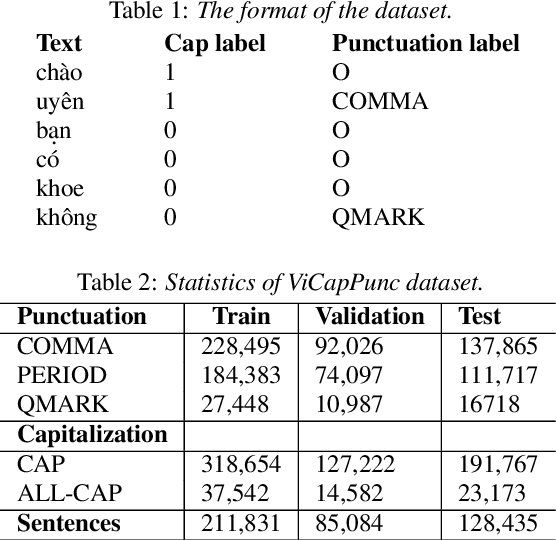
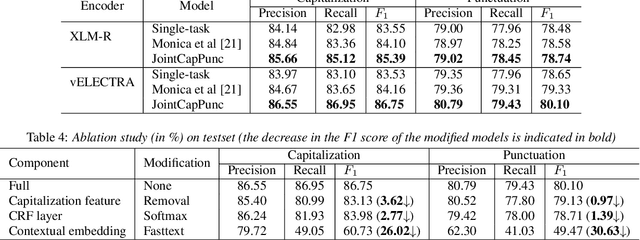
Despite the rise of recent performant methods in Automatic Speech Recognition (ASR), such methods do not ensure proper casing and punctuation for their outputs. This problem has a significant impact on the comprehension of both Natural Language Processing (NLP) algorithms and human to process. Capitalization and punctuation restoration is imperative in pre-processing pipelines for raw textual inputs. For low resource languages like Vietnamese, public datasets for this task are scarce. In this paper, we contribute a public dataset for capitalization and punctuation recovery for Vietnamese; and propose a joint model for both tasks named JointCapPunc. Experimental results on the Vietnamese dataset show the effectiveness of our joint model compare to single model and previous joint learning model. We publicly release our dataset and the implementation of our model at https://github.com/anhtunguyen98/JointCapPunc
Speaker-Independent Speech-Driven Visual Speech Synthesis using Domain-Adapted Acoustic Models
May 15, 2019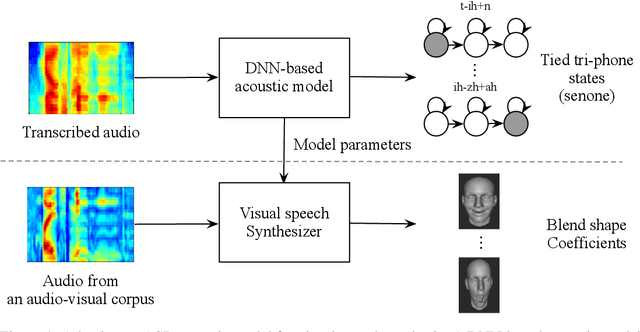

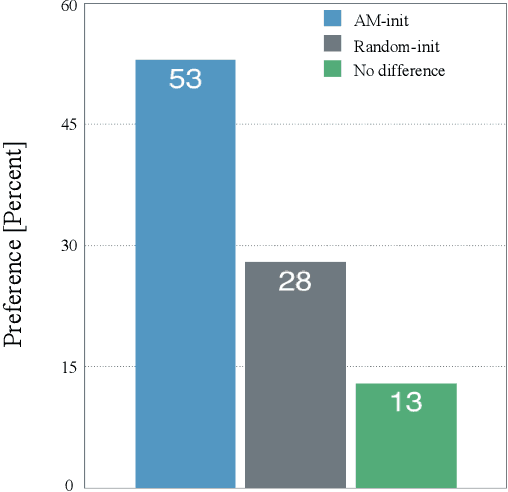
Speech-driven visual speech synthesis involves mapping features extracted from acoustic speech to the corresponding lip animation controls for a face model. This mapping can take many forms, but a powerful approach is to use deep neural networks (DNNs). However, a limitation is the lack of synchronized audio, video, and depth data required to reliably train the DNNs, especially for speaker-independent models. In this paper, we investigate adapting an automatic speech recognition (ASR) acoustic model (AM) for the visual speech synthesis problem. We train the AM on ten thousand hours of audio-only data. The AM is then adapted to the visual speech synthesis domain using ninety hours of synchronized audio-visual speech. Using a subjective assessment test, we compared the performance of the AM-initialized DNN to one with a random initialization. The results show that viewers significantly prefer animations generated from the AM-initialized DNN than the ones generated using the randomly initialized model. We conclude that visual speech synthesis can significantly benefit from the powerful representation of speech in the ASR acoustic models.
Calibrate and Refine! A Novel and Agile Framework for ASR-error Robust Intent Detection
May 23, 2022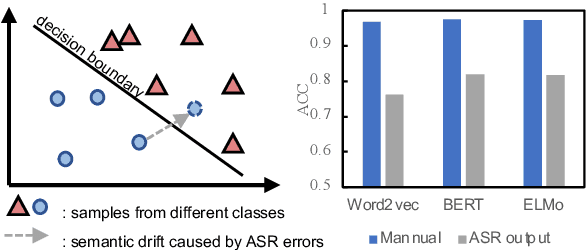
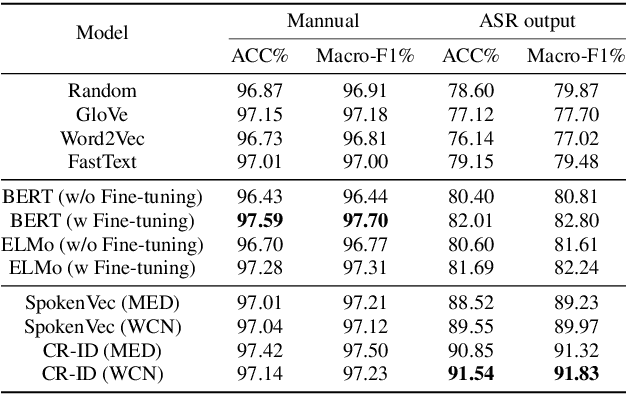
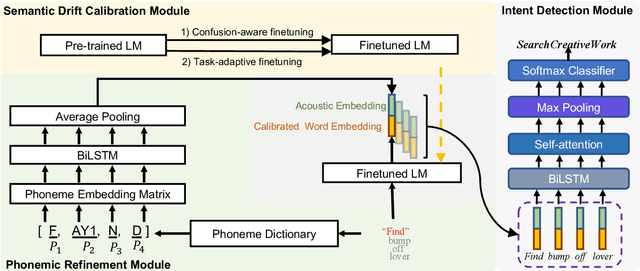
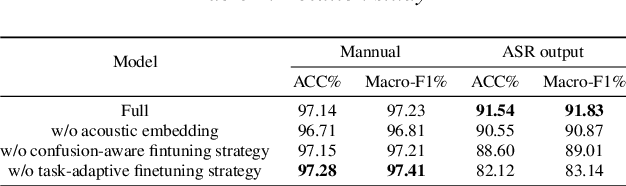
The past ten years have witnessed the rapid development of text-based intent detection, whose benchmark performances have already been taken to a remarkable level by deep learning techniques. However, automatic speech recognition (ASR) errors are inevitable in real-world applications due to the environment noise, unique speech patterns and etc, leading to sharp performance drop in state-of-the-art text-based intent detection models. Essentially, this phenomenon is caused by the semantic drift brought by ASR errors and most existing works tend to focus on designing new model structures to reduce its impact, which is at the expense of versatility and flexibility. Different from previous one-piece model, in this paper, we propose a novel and agile framework called CR-ID for ASR error robust intent detection with two plug-and-play modules, namely semantic drift calibration module (SDCM) and phonemic refinement module (PRM), which are both model-agnostic and thus could be easily integrated to any existing intent detection models without modifying their structures. Experimental results on SNIPS dataset show that, our proposed CR-ID framework achieves competitive performance and outperform all the baseline methods on ASR outputs, which verifies that CR-ID can effectively alleviate the semantic drift caused by ASR errors.
GraphPB: Graphical Representations of Prosody Boundary in Speech Synthesis
Dec 03, 2020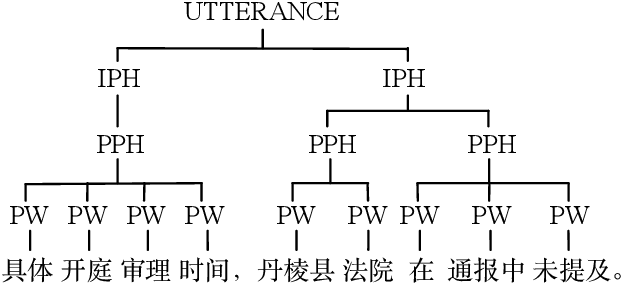

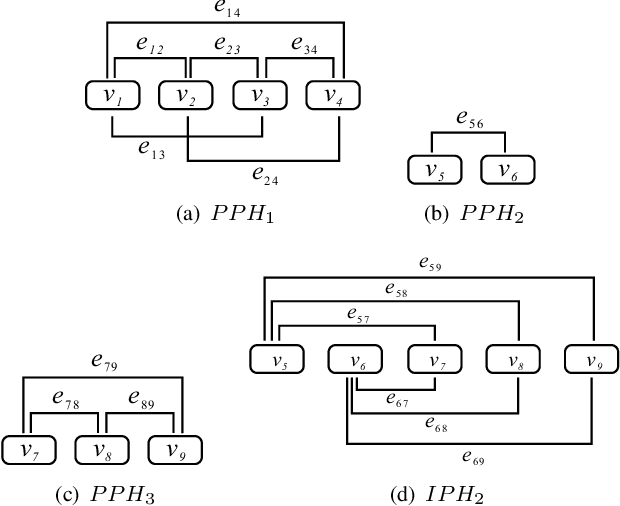

This paper introduces a graphical representation approach of prosody boundary (GraphPB) in the task of Chinese speech synthesis, intending to parse the semantic and syntactic relationship of input sequences in a graphical domain for improving the prosody performance. The nodes of the graph embedding are formed by prosodic words, and the edges are formed by the other prosodic boundaries, namely prosodic phrase boundary (PPH) and intonation phrase boundary (IPH). Different Graph Neural Networks (GNN) like Gated Graph Neural Network (GGNN) and Graph Long Short-term Memory (G-LSTM) are utilised as graph encoders to exploit the graphical prosody boundary information. Graph-to-sequence model is proposed and formed by a graph encoder and an attentional decoder. Two techniques are proposed to embed sequential information into the graph-to-sequence text-to-speech model. The experimental results show that this proposed approach can encode the phonetic and prosody rhythm of an utterance. The mean opinion score (MOS) of these GNN models shows comparative results with the state-of-the-art sequence-to-sequence models with better performance in the aspect of prosody. This provides an alternative approach for prosody modelling in end-to-end speech synthesis.
Robust Speaker Recognition with Transformers Using wav2vec 2.0
Mar 28, 2022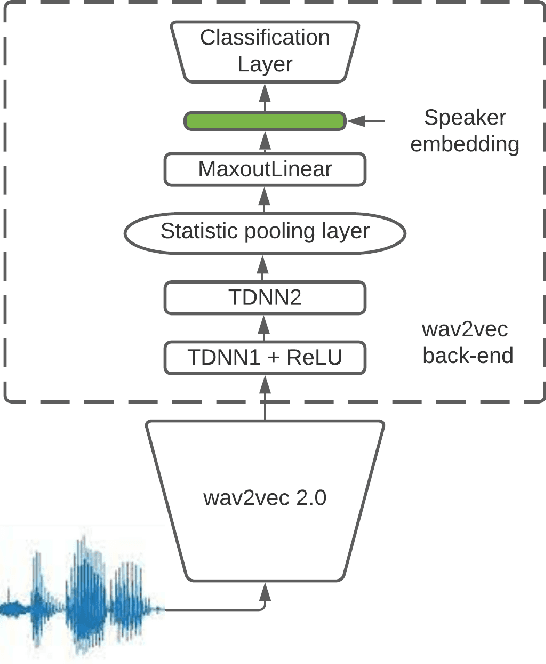
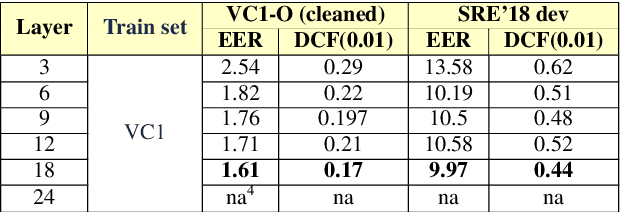
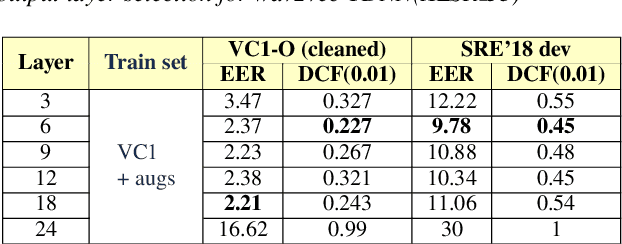
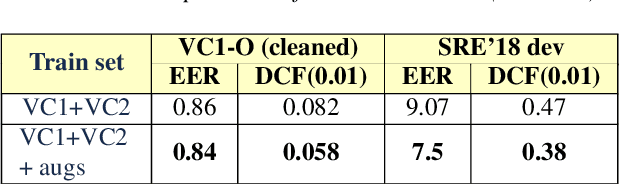
Recent advances in unsupervised speech representation learning discover new approaches and provide new state-of-the-art for diverse types of speech processing tasks. This paper presents an investigation of using wav2vec 2.0 deep speech representations for the speaker recognition task. The proposed fine-tuning procedure of wav2vec 2.0 with simple TDNN and statistic pooling back-end using additive angular margin loss allows to obtain deep speaker embedding extractor that is well-generalized across different domains. It is concluded that Contrastive Predictive Coding pretraining scheme efficiently utilizes the power of unlabeled data, and thus opens the door to powerful transformer-based speaker recognition systems. The experimental results obtained in this study demonstrate that fine-tuning can be done on relatively small sets and a clean version of data. Using data augmentation during fine-tuning provides additional performance gains in speaker verification. In this study speaker recognition systems were analyzed on a wide range of well-known verification protocols: VoxCeleb1 cleaned test set, NIST SRE 18 development set, NIST SRE 2016 and NIST SRE 2019 evaluation set, VOiCES evaluation set, NIST 2021 SRE, and CTS challenges sets.
TinySpeech: Attention Condensers for Deep Speech Recognition Neural Networks on Edge Devices
Aug 16, 2020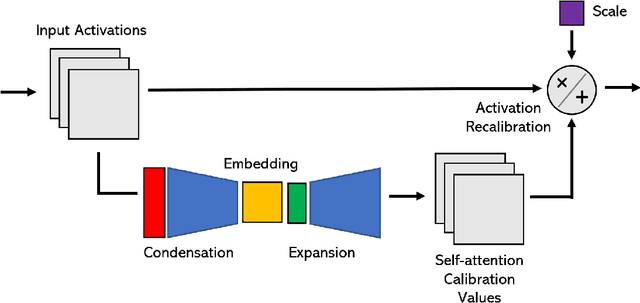

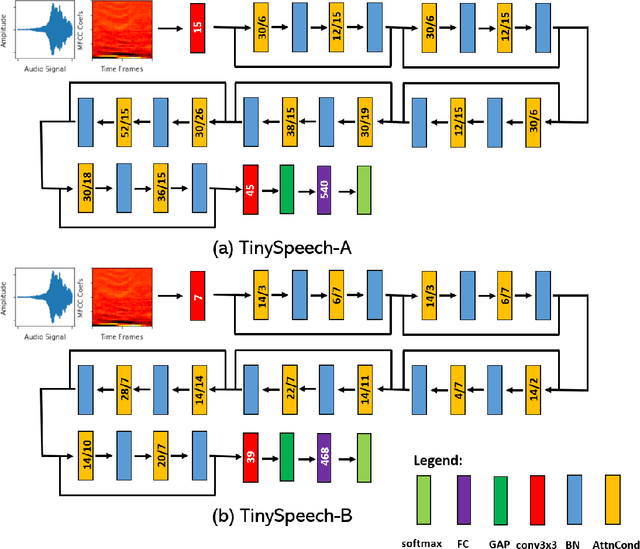
Advances in deep learning have led to state-of-the-art performance across a multitude of speech recognition tasks. Nevertheless, the widespread deployment of deep neural networks for on-device speech recognition remains a challenge, particularly in edge scenarios where the memory and computing resources are highly constrained (e.g., low-power embedded devices) or where the memory and computing budget dedicated to speech recognition is low (e.g., mobile devices performing numerous tasks besides speech recognition). In this study, we introduce the concept of attention condensers for building low-footprint, highly-efficient deep neural networks for on-device speech recognition on the edge. More specifically, an attention condenser is a self-attention mechanism that learns and produces a condensed embedding characterizing joint local and cross-channel activation relationships, and performs selective attention accordingly. To illustrate its efficacy, we introduce TinySpeech, low-precision deep neural networks comprising largely of attention condensers tailored for on-device speech recognition using a machine-driven design exploration strategy. Experimental results on the Google Speech Commands benchmark dataset for limited-vocabulary speech recognition showed that TinySpeech networks achieved significantly lower architectural complexity (as much as $207\times$ fewer parameters) and lower computational complexity (as much as $21\times$ fewer multiply-add operations) when compared to previous deep neural networks in research literature. These results not only demonstrate the efficacy of attention condensers for building highly efficient deep neural networks for on-device speech recognition, but also illuminate its potential for accelerating deep learning on the edge and empowering a wide range of TinyML applications.
Discretization and Re-synthesis: an alternative method to solve the Cocktail Party Problem
Dec 17, 2021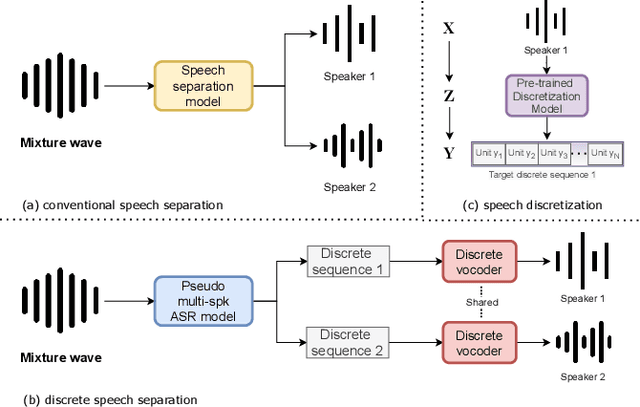

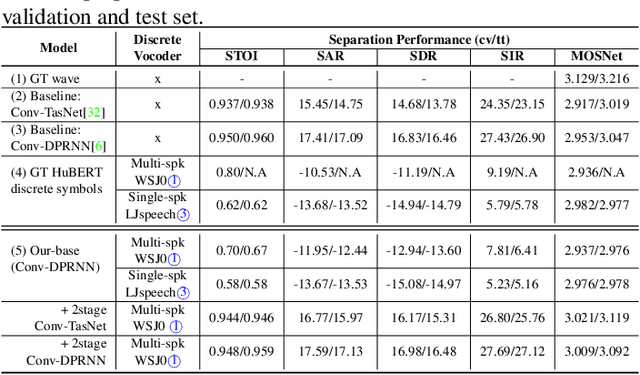
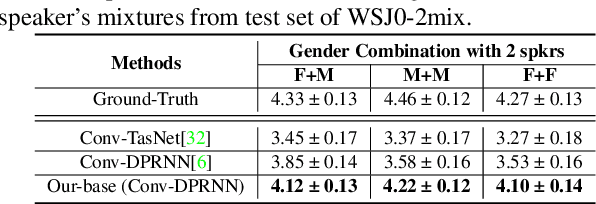
Deep learning based models have significantly improved the performance of speech separation with input mixtures like the cocktail party. Prominent methods (e.g., frequency-domain and time-domain speech separation) usually build regression models to predict the ground-truth speech from the mixture, using the masking-based design and the signal-level loss criterion (e.g., MSE or SI-SNR). This study demonstrates, for the first time, that the synthesis-based approach can also perform well on this problem, with great flexibility and strong potential. Specifically, we propose a novel speech separation/enhancement model based on the recognition of discrete symbols, and convert the paradigm of the speech separation/enhancement related tasks from regression to classification. By utilizing the synthesis model with the input of discrete symbols, after the prediction of discrete symbol sequence, each target speech could be re-synthesized. Evaluation results based on the WSJ0-2mix and VCTK-noisy corpora in various settings show that our proposed method can steadily synthesize the separated speech with high speech quality and without any interference, which is difficult to avoid in regression-based methods. In addition, with negligible loss of listening quality, the speaker conversion of enhanced/separated speech could be easily realized through our method.
Learning Robust and Multilingual Speech Representations
Jan 29, 2020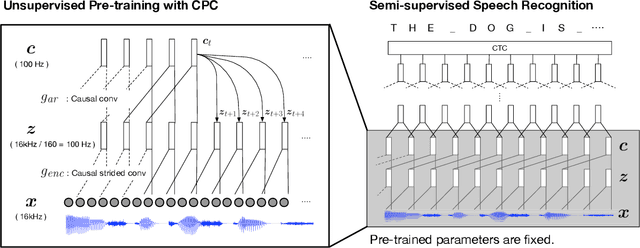
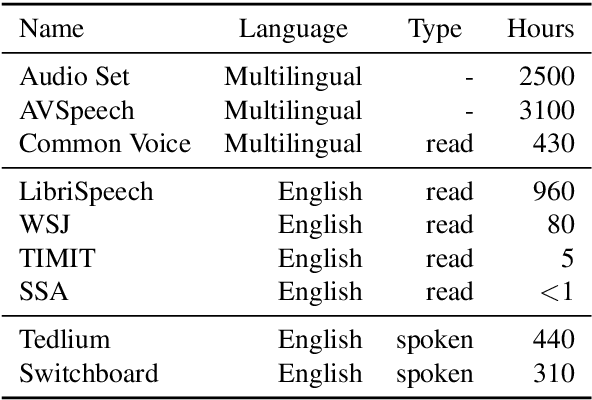
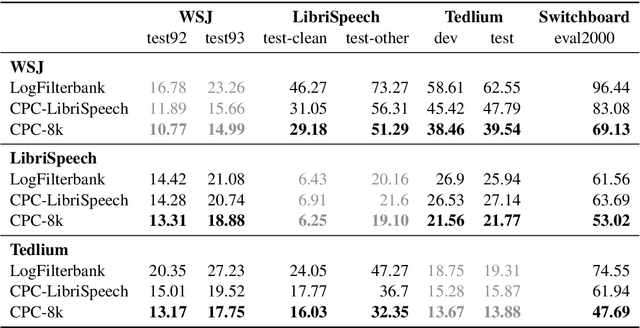
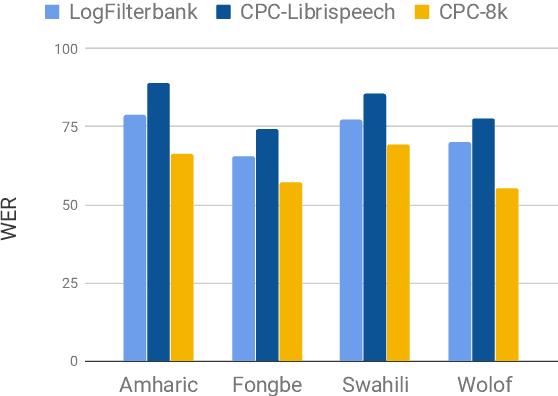
Unsupervised speech representation learning has shown remarkable success at finding representations that correlate with phonetic structures and improve downstream speech recognition performance. However, most research has been focused on evaluating the representations in terms of their ability to improve the performance of speech recognition systems on read English (e.g. Wall Street Journal and LibriSpeech). This evaluation methodology overlooks two important desiderata that speech representations should have: robustness to domain shifts and transferability to other languages. In this paper we learn representations from up to 8000 hours of diverse and noisy speech data and evaluate the representations by looking at their robustness to domain shifts and their ability to improve recognition performance in many languages. We find that our representations confer significant robustness advantages to the resulting recognition systems: we see significant improvements in out-of-domain transfer relative to baseline feature sets and the features likewise provide improvements in 25 phonetically diverse languages including tonal languages and low-resource languages.