 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
MCMChaos: Improvising Rap Music with MCMC Methods and Chaos Theory
Jan 15, 2024
A novel freestyle rap software, MCMChaos 0.0.1, based on rap music transcriptions created in previous research is presented. The software has three different versions, each making use of different mathematical simulation methods: collapsed gibbs sampler and lorenz attractor simulation. As far as we know, these simulation methods have never been used in rap music generation before. The software implements Python Text-to-Speech processing (pyttxs) to convert text wrangled from the MCFlow corpus into English speech. In each version, values simulated from each respective mathematical model alter the rate of speech, volume, and (in the multiple voice case) the voice of the text-to-speech engine on a line-by-line basis. The user of the software is presented with a real-time graphical user interface (GUI) which instantaneously changes the initial values read into the mathematical simulation methods. Future research might attempt to allow for more user control and autonomy.
Single-channel speech enhancement using learnable loss mixup
Dec 20, 2023Generalization remains a major problem in supervised learning of single-channel speech enhancement. In this work, we propose learnable loss mixup (LLM), a simple and effortless training diagram, to improve the generalization of deep learning-based speech enhancement models. Loss mixup, of which learnable loss mixup is a special variant, optimizes a mixture of the loss functions of random sample pairs to train a model on virtual training data constructed from these pairs of samples. In learnable loss mixup, by conditioning on the mixed data, the loss functions are mixed using a non-linear mixing function automatically learned via neural parameterization. Our experimental results on the VCTK benchmark show that learnable loss mixup achieves 3.26 PESQ, outperforming the state-of-the-art.
DSNet: Disentangled Siamese Network with Neutral Calibration for Speech Emotion Recognition
Dec 25, 2023One persistent challenge in deep learning based speech emotion recognition (SER) is the unconscious encoding of emotion-irrelevant factors (e.g., speaker or phonetic variability), which limits the generalization of SER in practical use. In this paper, we propose DSNet, a Disentangled Siamese Network with neutral calibration, to meet the demand for a more robust and explainable SER model. Specifically, we introduce an orthogonal feature disentanglement module to explicitly project the high-level representation into two distinct subspaces. Later, we propose a novel neutral calibration mechanism to encourage one subspace to capture sufficient emotion-irrelevant information. In this way, the other one can better isolate and emphasize the emotion-relevant information within speech signals. Experimental results on two popular benchmark datasets demonstrate the superiority of DSNet over various state-of-the-art methods for speaker-independent SER.
Performance Assessment of ChatGPT vs Bard in Detecting Alzheimer's Dementia
Jan 30, 2024Large language models (LLMs) find increasing applications in many fields. Here, three LLM chatbots (ChatGPT-3.5, ChatGPT-4 and Bard) are assessed - in their current form, as publicly available - for their ability to recognize Alzheimer's Dementia (AD) and Cognitively Normal (CN) individuals using textual input derived from spontaneous speech recordings. Zero-shot learning approach is used at two levels of independent queries, with the second query (chain-of-thought prompting) eliciting more detailed than the first. Each LLM chatbot's performance is evaluated on the prediction generated in terms of accuracy, sensitivity, specificity, precision and F1 score. LLM chatbots generated three-class outcome ("AD", "CN", or "Unsure"). When positively identifying AD, Bard produced highest true-positives (89% recall) and highest F1 score (71%), but tended to misidentify CN as AD, with high confidence (low "Unsure" rates); for positively identifying CN, GPT-4 resulted in the highest true-negatives at 56% and highest F1 score (62%), adopting a diplomatic stance (moderate "Unsure" rates). Overall, three LLM chatbots identify AD vs CN surpassing chance-levels but do not currently satisfy clinical application.
Multi-CMGAN+/+: Leveraging Multi-Objective Speech Quality Metric Prediction for Speech Enhancement
Dec 14, 2023Neural network based approaches to speech enhancement have shown to be particularly powerful, being able to leverage a data-driven approach to result in a significant performance gain versus other approaches. Such approaches are reliant on artificially created labelled training data such that the neural model can be trained using intrusive loss functions which compare the output of the model with clean reference speech. Performance of such systems when enhancing real-world audio often suffers relative to their performance on simulated test data. In this work, a non-intrusive multi-metric prediction approach is introduced, wherein a model trained on artificial labelled data using inference of an adversarially trained metric prediction neural network. The proposed approach shows improved performance versus state-of-the-art systems on the recent CHiME-7 challenge \ac{UDASE} task evaluation sets.
An Integration of Pre-Trained Speech and Language Models for End-to-End Speech Recognition
Dec 06, 2023Advances in machine learning have made it possible to perform various text and speech processing tasks, including automatic speech recognition (ASR), in an end-to-end (E2E) manner. Since typical E2E approaches require large amounts of training data and resources, leveraging pre-trained foundation models instead of training from scratch is gaining attention. Although there have been attempts to use pre-trained speech and language models in ASR, most of them are limited to using either. This paper explores the potential of integrating a pre-trained speech representation model with a large language model (LLM) for E2E ASR. The proposed model enables E2E ASR by generating text tokens in an autoregressive manner via speech representations as speech prompts, taking advantage of the vast knowledge provided by the LLM. Furthermore, the proposed model can incorporate remarkable developments for LLM utilization, such as inference optimization and parameter-efficient domain adaptation. Experimental results show that the proposed model achieves performance comparable to modern E2E ASR models.
Overlap-aware End-to-End Supervised Hierarchical Graph Clustering for Speaker Diarization
Jan 23, 2024Speaker diarization, the task of segmenting an audio recording based on speaker identity, constitutes an important speech pre-processing step for several downstream applications. The conventional approach to diarization involves multiple steps of embedding extraction and clustering, which are often optimized in an isolated fashion. While end-to-end diarization systems attempt to learn a single model for the task, they are often cumbersome to train and require large supervised datasets. In this paper, we propose an end-to-end supervised hierarchical clustering algorithm based on graph neural networks (GNN), called End-to-end Supervised HierARchical Clustering (E-SHARC). The E-SHARC approach uses front-end mel-filterbank features as input and jointly learns an embedding extractor and the GNN clustering module, performing representation learning, metric learning, and clustering with end-to-end optimization. Further, with additional inputs from an external overlap detector, the E-SHARC approach is capable of predicting the speakers in the overlapping speech regions. The experimental evaluation on several benchmark datasets like AMI, VoxConverse and DISPLACE, illustrates that the proposed E-SHARC framework improves significantly over the state-of-art diarization systems.
On Robustness to Missing Video for Audiovisual Speech Recognition
Dec 19, 2023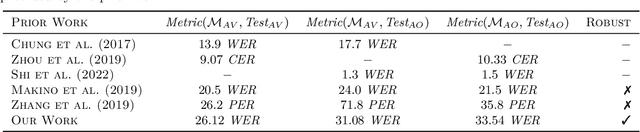
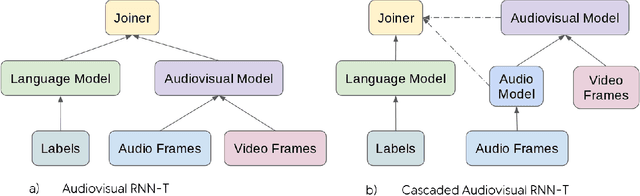
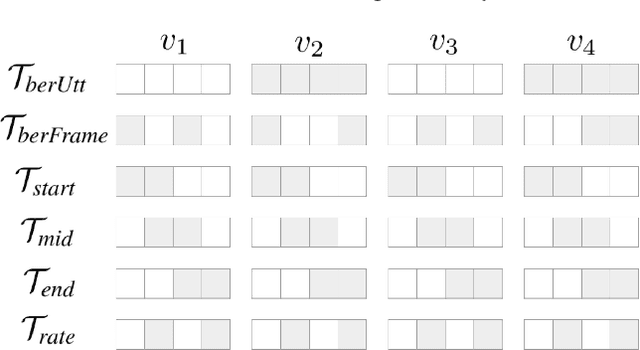
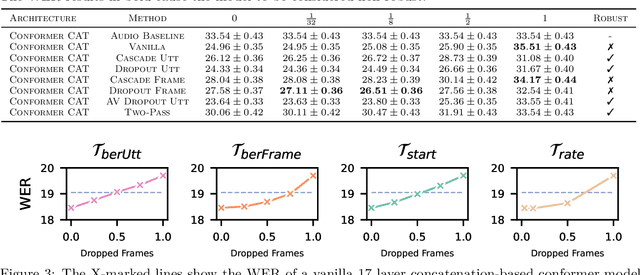
It has been shown that learning audiovisual features can lead to improved speech recognition performance over audio-only features, especially for noisy speech. However, in many common applications, the visual features are partially or entirely missing, e.g.~the speaker might move off screen. Multi-modal models need to be robust: missing video frames should not degrade the performance of an audiovisual model to be worse than that of a single-modality audio-only model. While there have been many attempts at building robust models, there is little consensus on how robustness should be evaluated. To address this, we introduce a framework that allows claims about robustness to be evaluated in a precise and testable way. We also conduct a systematic empirical study of the robustness of common audiovisual speech recognition architectures on a range of acoustic noise conditions and test suites. Finally, we show that an architecture-agnostic solution based on cascades can consistently achieve robustness to missing video, even in settings where existing techniques for robustness like dropout fall short.
Embedding-based search in JetBrains IDEs
Jan 26, 2024Most modern Integrated Development Environments (IDEs) and code editors have a feature to search across available functionality and items in an open project. In JetBrains IDEs, this feature is called Search Everywhere: it allows users to search for files, actions, classes, symbols, settings, and anything from VCS history from a single entry point. However, it works with the candidates obtained by algorithms that don't account for semantics, e.g., synonyms, complex word permutations, part of the speech modifications, and typos. In this work, we describe the machine learning approach we implemented to improve the discoverability of search items. We also share the obstacles encountered during this process and how we overcame them.
A RAG-based Question Answering System Proposal for Understanding Islam: MufassirQAS LLM
Jan 31, 2024There exist challenges in learning and understanding religions as the presence of complexity and depth of religious doctrines and teachings. Chatbots as question-answering systems can help in solving these challenges. LLM chatbots use NLP techniques to establish connections between topics and accurately respond to complex questions. These capabilities make it perfect to be used in enlightenment on religion as a question answering chatbot. However, LLMs also have a tendency to generate false information, known as hallucination. The responses of the chatbots can include content that insults personal religious beliefs, interfaith conflicts, and controversial or sensitive topics. It needs to avoid such cases without promoting hate speech or offending certain groups of people or their beliefs. This study uses a vector database-based Retrieval Augmented Generation (RAG) approach to enhance the accuracy and transparency of LLMs. Our question-answering system is called as "MufassirQAS". We created a vector database with several open-access books that include Turkish context. These are Turkish translations, and interpretations on Islam. We worked on creating system prompts with care, ensuring they provide instructions that prevent harmful, offensive, or disrespectful responses. We also tested the MufassirQAS and ChatGPT with sensitive questions. We got better performance with our system. Study and enhancements are still in progress. Results and future works are given.