 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
dictNN: A Dictionary-Enhanced CNN Approach for Classifying Hate Speech on Twitter
Mar 16, 2021
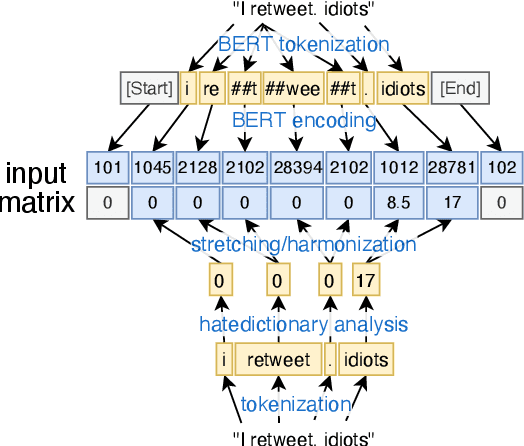
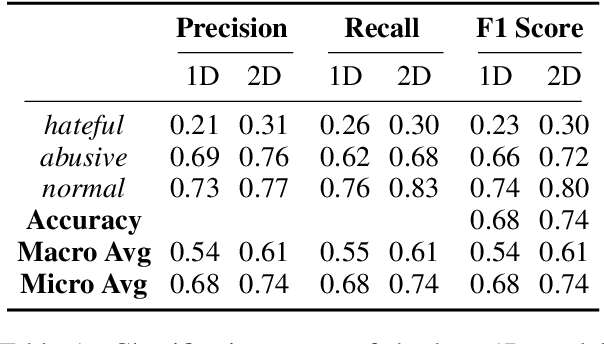

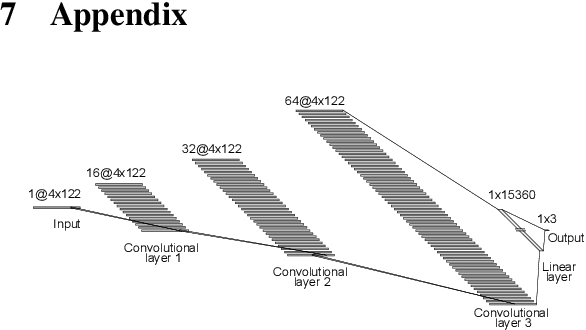
Hate speech on social media is a growing concern, and automated methods have so far been sub-par at reliably detecting it. A major challenge lies in the potentially evasive nature of hate speech due to the ambiguity and fast evolution of natural language. To tackle this, we introduce a vectorisation based on a crowd-sourced and continuously updated dictionary of hate words and propose fusing this approach with standard word embedding in order to improve the classification performance of a CNN model. To train and test our model we use a merge of two established datasets (110,748 tweets in total). By adding the dictionary-enhanced input, we are able to increase the CNN model's predictive power and increase the F1 macro score by seven percentage points.
Voice Reconstruction from Silent Speech with a Sequence-to-Sequence Model
Jul 31, 2021
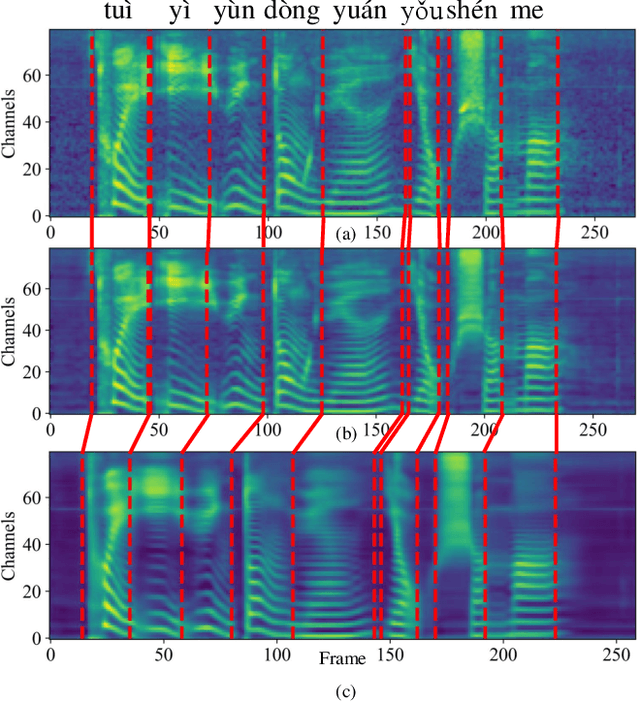
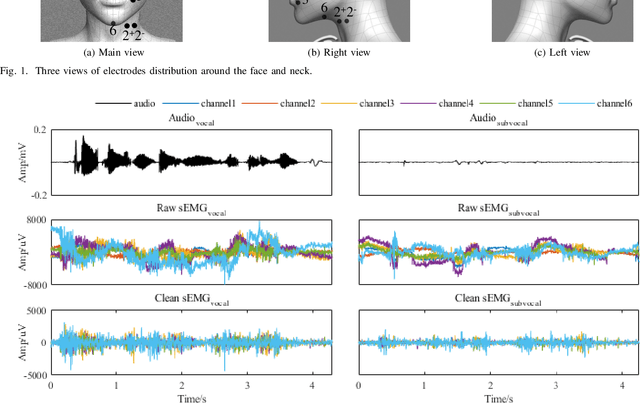
Silent Speech Decoding (SSD) based on Surface electromyography (sEMG) has become a prevalent task in recent years. Though revolutions have been proposed to decode sEMG to audio successfully, some problems still remain. In this paper, we propose an optimized sequence-to-sequence (Seq2Seq) approach to synthesize voice from subvocal sEMG. Both subvocal and vocal sEMG are collected and preprocessed to provide data information. Then, we extract durations from the alignment between subvocal and vocal signals to regulate the subvocal sEMG following audio length. Besides, we use phoneme classification and vocal sEMG reconstruction modules to improve the model performance. Finally, experiments on a Mandarin speaker dataset, which consists of 6.49 hours of data, demonstrate that the proposed model improves the mapping accuracy and voice quality of reconstructed voice.
Controllable Data Generation by Deep Learning: A Review
Jul 25, 2022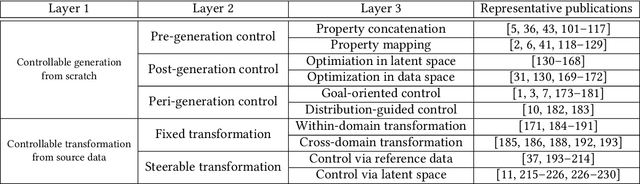
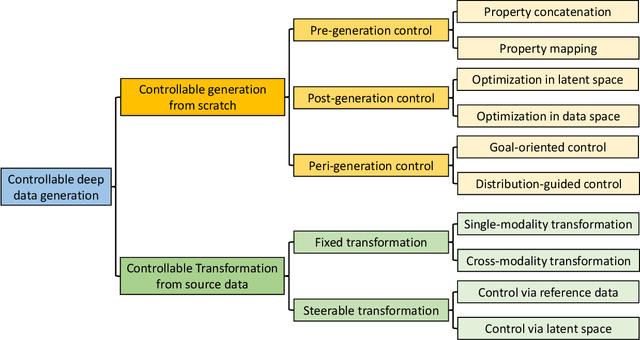
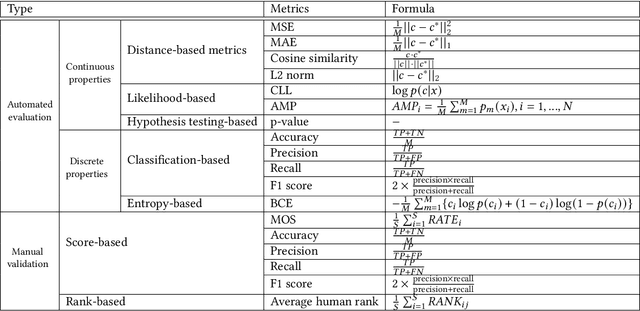
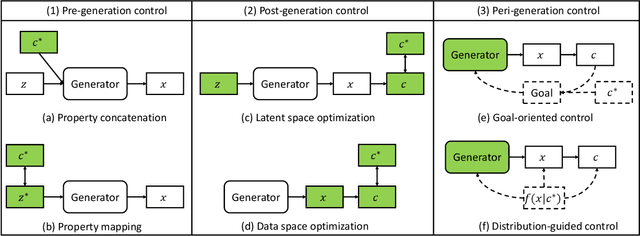
Designing and generating new data under targeted properties has been attracting various critical applications such as molecule design, image editing and speech synthesis. Traditional hand-crafted approaches heavily rely on expertise experience and intensive human efforts, yet still suffer from the insufficiency of scientific knowledge and low throughput to support effective and efficient data generation. Recently, the advancement of deep learning induces expressive methods that can learn the underlying representation and properties of data. Such capability provides new opportunities in figuring out the mutual relationship between the structural patterns and functional properties of the data and leveraging such relationship to generate structural data given the desired properties. This article provides a systematic review of this promising research area, commonly known as controllable deep data generation. Firstly, the potential challenges are raised and preliminaries are provided. Then the controllable deep data generation is formally defined, a taxonomy on various techniques is proposed and the evaluation metrics in this specific domain are summarized. After that, exciting applications of controllable deep data generation are introduced and existing works are experimentally analyzed and compared. Finally, the promising future directions of controllable deep data generation are highlighted and five potential challenges are identified.
Composing General Audio Representation by Fusing Multilayer Features of a Pre-trained Model
May 17, 2022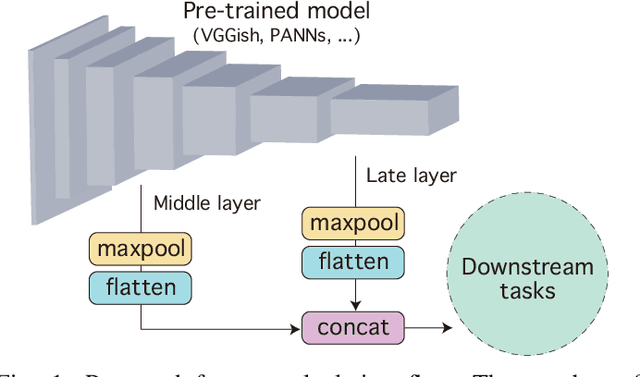
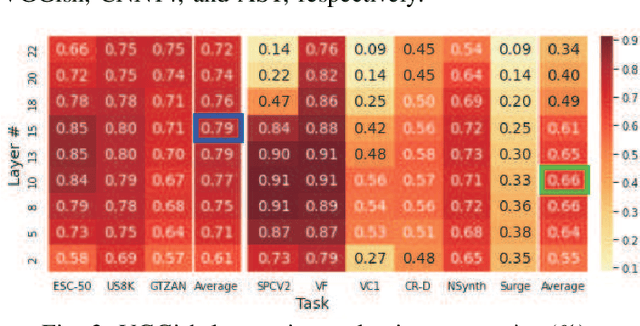

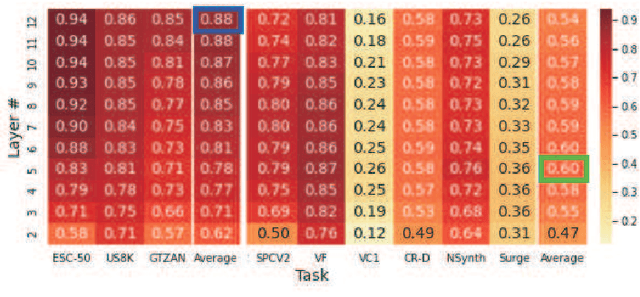
Many application studies rely on audio DNN models pre-trained on a large-scale dataset as essential feature extractors, and they extract features from the last layers. In this study, we focus on our finding that the middle layer features of existing supervised pre-trained models are more effective than the late layer features for some tasks. We propose a simple approach to compose features effective for general-purpose applications, consisting of two steps: (1) calculating feature vectors along the time frame from middle/late layer outputs, and (2) fusing them. This approach improves the utility of frequency and channel information in downstream processes, and combines the effectiveness of middle and late layer features for different tasks. As a result, the feature vectors become effective for general purposes. In the experiments using VGGish, PANNs' CNN14, and AST on nine downstream tasks, we first show that each layer output of these models serves different tasks. Then, we demonstrate that the proposed approach significantly improves their performance and brings it to a level comparable to that of the state-of-the-art. In particular, the performance of the non-semantic speech (NOSS) tasks greatly improves, especially on Speech commands V2 with VGGish of +77.1 (14.3% to 91.4%).
Continuous Silent Speech Recognition using EEG
Feb 29, 2020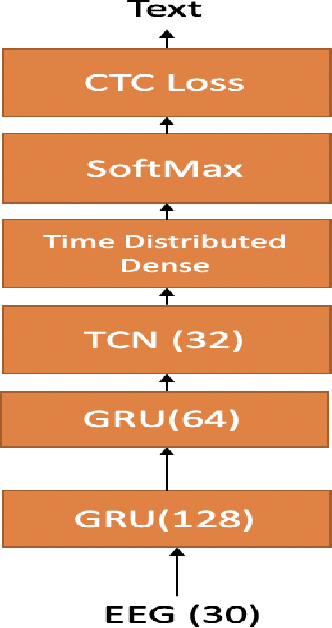
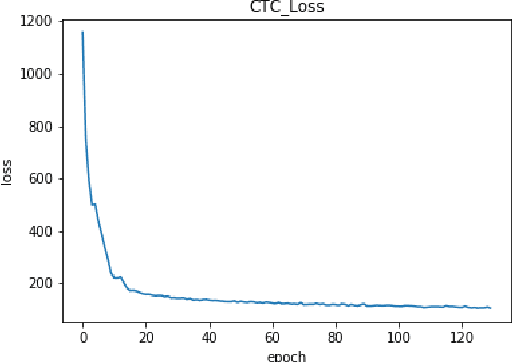
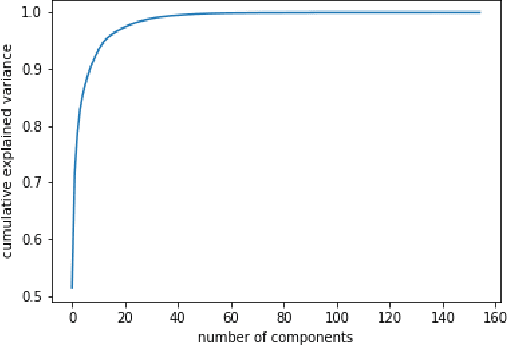
In this paper we explore continuous silent speech recognition using electroencephalography (EEG) signals. We implemented a connectionist temporal classification (CTC) automatic speech recognition (ASR) model to translate EEG signals recorded in parallel while subjects were reading English sentences in their mind without producing any voice to text. Our results demonstrate the feasibility of using EEG signals for performing continuous silent speech recognition. We demonstrate our results for a limited English vocabulary consisting of 30 unique sentences.
Tree-constrained Pointer Generator for End-to-end Contextual Speech Recognition
Sep 17, 2021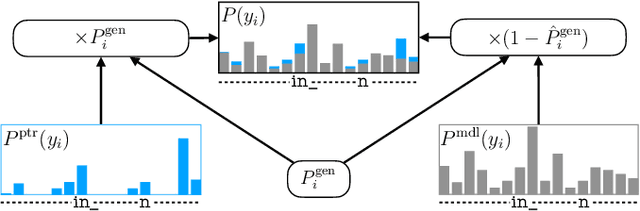

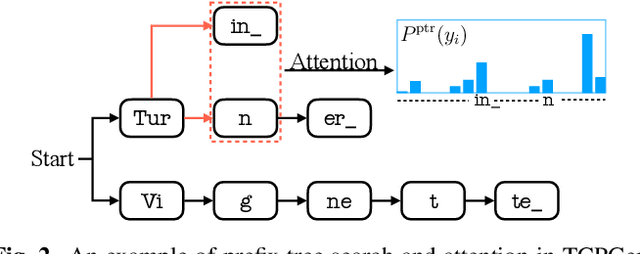
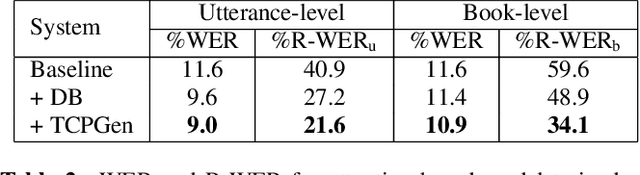
Contextual knowledge is important for real-world automatic speech recognition (ASR) applications. In this paper, a novel tree-constrained pointer generator (TCPGen) component is proposed that incorporates such knowledge as a list of biasing words into both attention-based encoder-decoder and transducer end-to-end ASR models in a neural-symbolic way. TCPGen structures the biasing words into an efficient prefix tree to serve as its symbolic input and creates a neural shortcut between the tree and the final ASR output distribution to facilitate recognising biasing words during decoding. Systems were trained and evaluated on the Librispeech corpus where biasing words were extracted at the scales of an utterance, a chapter, or a book to simulate different application scenarios. Experimental results showed that TCPGen consistently improved word error rates (WERs) compared to the baselines, and in particular, achieved significant WER reductions on the biasing words. TCPGen is highly efficient: it can handle 5,000 biasing words and distractors and only add a small overhead to memory use and computation cost.
TinySpeech: Attention Condensers for Deep Speech Recognition Neural Networks on Edge Devices
Aug 23, 2020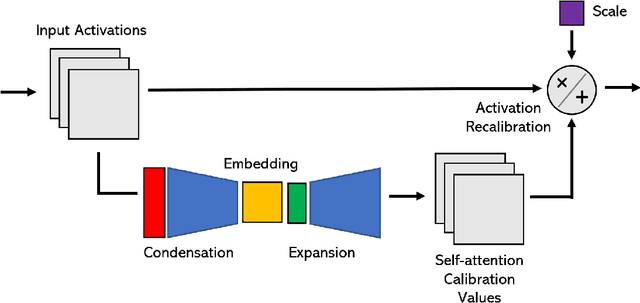

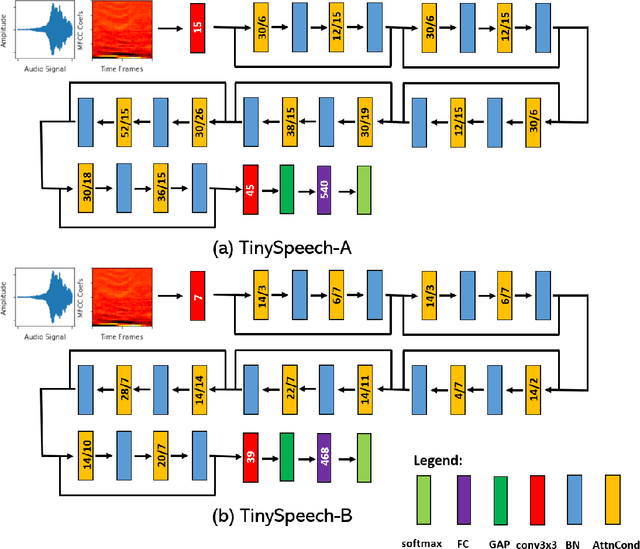
Advances in deep learning have led to state-of-the-art performance across a multitude of speech recognition tasks. Nevertheless, the widespread deployment of deep neural networks for on-device speech recognition remains a challenge, particularly in edge scenarios where the memory and computing resources are highly constrained (e.g., low-power embedded devices) or where the memory and computing budget dedicated to speech recognition is low (e.g., mobile devices performing numerous tasks besides speech recognition). In this study, we introduce the concept of attention condensers for building low-footprint, highly-efficient deep neural networks for on-device speech recognition on the edge. More specifically, an attention condenser is a self-attention mechanism that learns and produces a condensed embedding characterizing joint local and cross-channel activation relationships, and performs selective attention accordingly. To illustrate its efficacy, we introduce TinySpeech, low-precision deep neural networks comprising largely of attention condensers tailored for on-device speech recognition using a machine-driven design exploration strategy. Experimental results on the Google Speech Commands benchmark dataset for limited-vocabulary speech recognition showed that TinySpeech networks achieved significantly lower architectural complexity (as much as $207\times$ fewer parameters) and lower computational complexity (as much as $21\times$ fewer multiply-add operations) when compared to previous deep neural networks in research literature. These results not only demonstrate the efficacy of attention condensers for building highly efficient deep neural networks for on-device speech recognition, but also illuminate its potential for accelerating deep learning on the edge and empowering a wide range of TinyML applications.
Summary On The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Grand Challenge
Feb 08, 2022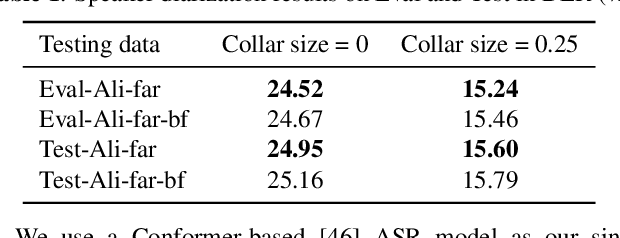
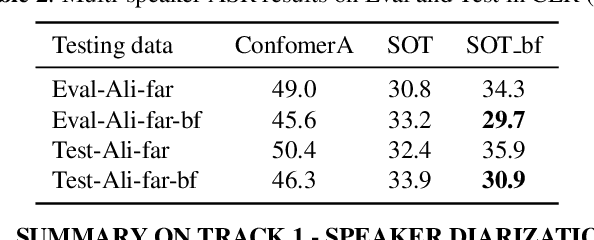
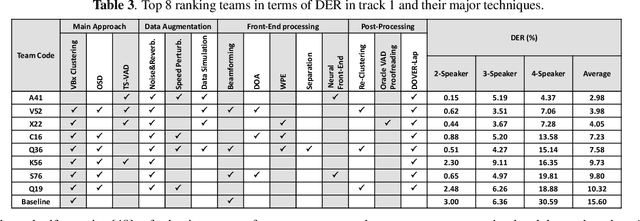
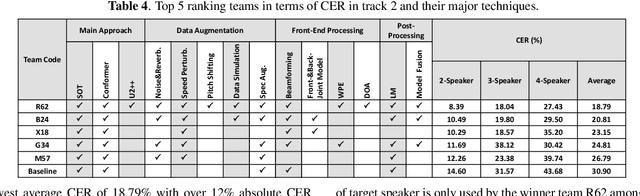
The ICASSP 2022 Multi-channel Multi-party Meeting Transcription Grand Challenge (M2MeT) focuses on one of the most valuable and the most challenging scenarios of speech technologies. The M2MeT challenge has particularly set up two tracks, speaker diarization (track 1) and multi-speaker automatic speech recognition (ASR) (track 2). Along with the challenge, we released 120 hours of real-recorded Mandarin meeting speech data with manual annotation, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. We briefly describe the released dataset, track setups, baselines and summarize the challenge results and major techniques used in the submissions.
Enhance Language Identification using Dual-mode Model with Knowledge Distillation
Mar 07, 2022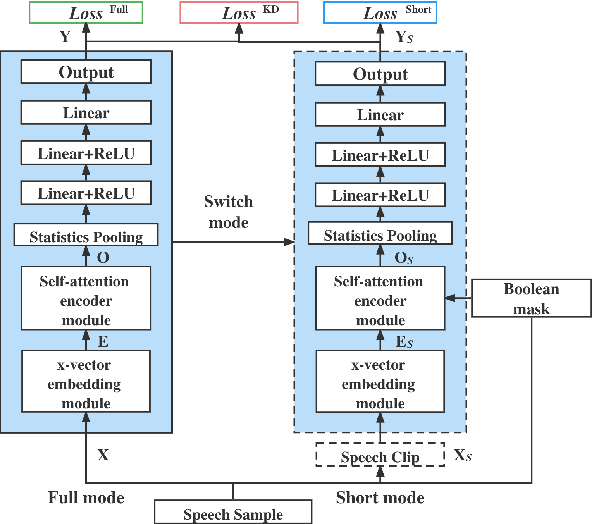
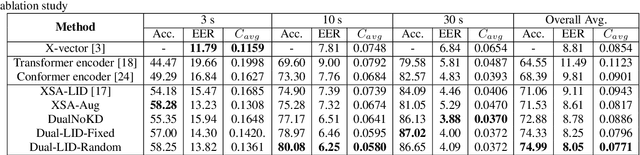

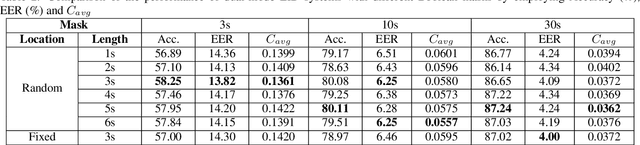
In this paper, we propose to employ a dual-mode framework on the x-vector self-attention (XSA-LID) model with knowledge distillation (KD) to enhance its language identification (LID) performance for both long and short utterances. The dual-mode XSA-LID model is trained by jointly optimizing both the full and short modes with their respective inputs being the full-length speech and its short clip extracted by a specific Boolean mask, and KD is applied to further boost the performance on short utterances. In addition, we investigate the impact of clip-wise linguistic variability and lexical integrity for LID by analyzing the variation of LID performance in terms of the lengths and positions of the mimicked speech clips. We evaluated our approach on the MLS14 data from the NIST 2017 LRE. With the 3~s random-location Boolean mask, our proposed method achieved 19.23%, 21.52% and 8.37% relative improvement in average cost compared with the XSA-LID model on 3s, 10s, and 30s speech, respectively.
Adaptation Algorithms for Speech Recognition: An Overview
Aug 14, 2020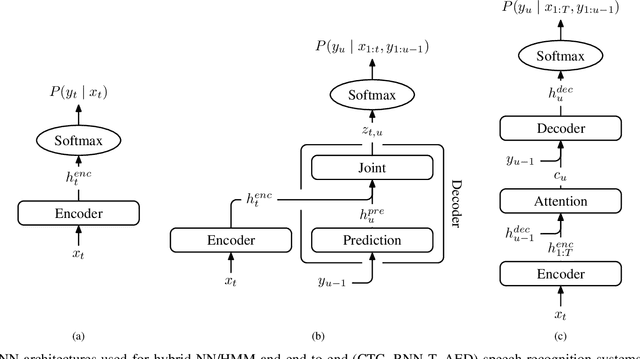
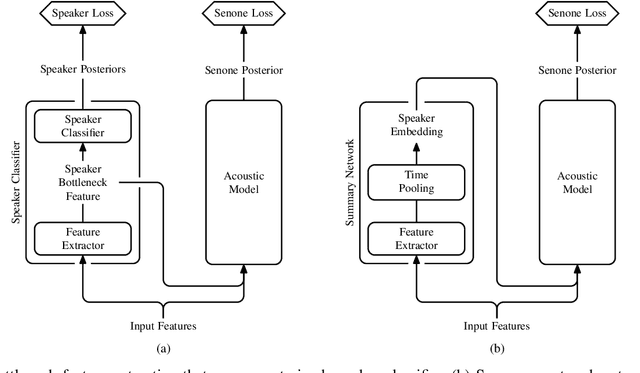
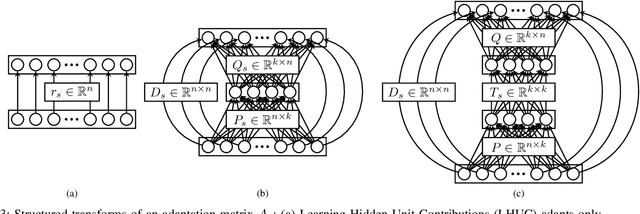
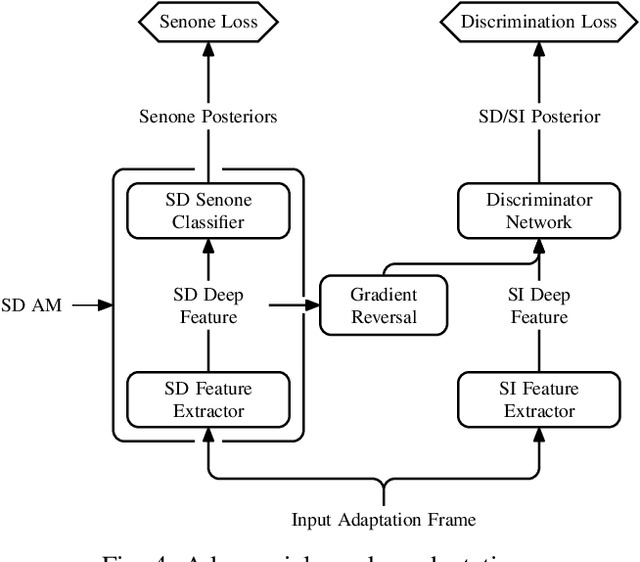
We present a structured overview of adaptation algorithms for neural network-based speech recognition, considering both hybrid hidden Markov model / neural network systems and end-to-end neural network systems, with a focus on speaker adaptation, domain adaptation, and accent adaptation. The overview characterizes adaptation algorithms as based on embeddings, model parameter adaptation, or data augmentation. We present a meta-analysis of the performance of speech recognition adaptation algorithms, based on relative error rate reductions as reported in the literature.