 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Gaze-enhanced Crossmodal Embeddings for Emotion Recognition
Apr 30, 2022

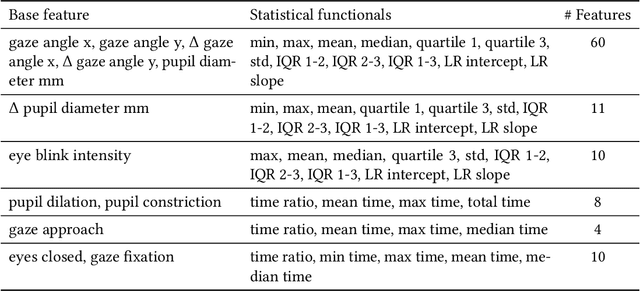

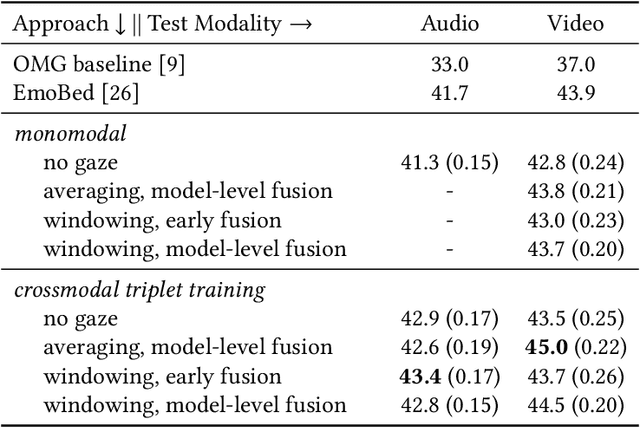
Emotional expressions are inherently multimodal -- integrating facial behavior, speech, and gaze -- but their automatic recognition is often limited to a single modality, e.g. speech during a phone call. While previous work proposed crossmodal emotion embeddings to improve monomodal recognition performance, despite its importance, an explicit representation of gaze was not included. We propose a new approach to emotion recognition that incorporates an explicit representation of gaze in a crossmodal emotion embedding framework. We show that our method outperforms the previous state of the art for both audio-only and video-only emotion classification on the popular One-Minute Gradual Emotion Recognition dataset. Furthermore, we report extensive ablation experiments and provide detailed insights into the performance of different state-of-the-art gaze representations and integration strategies. Our results not only underline the importance of gaze for emotion recognition but also demonstrate a practical and highly effective approach to leveraging gaze information for this task.
End-to-End Spectro-Temporal Graph Attention Networks for Speaker Verification Anti-Spoofing and Speech Deepfake Detection
Jul 27, 2021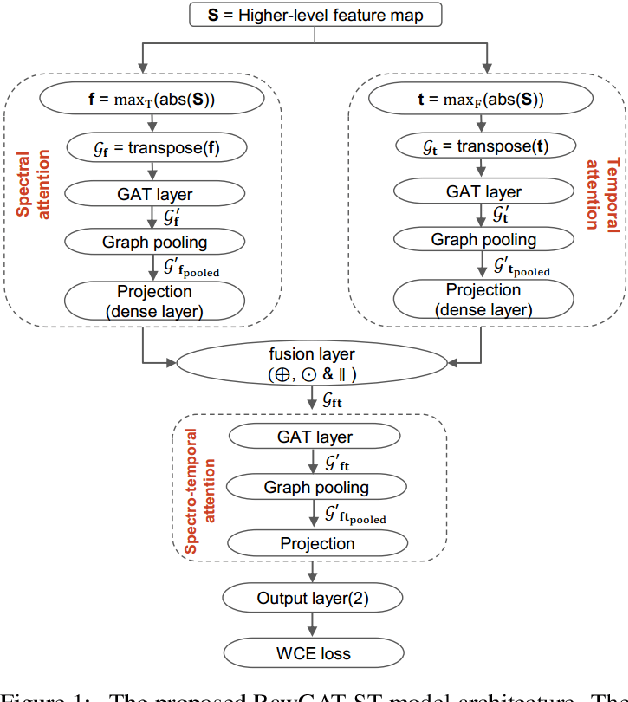
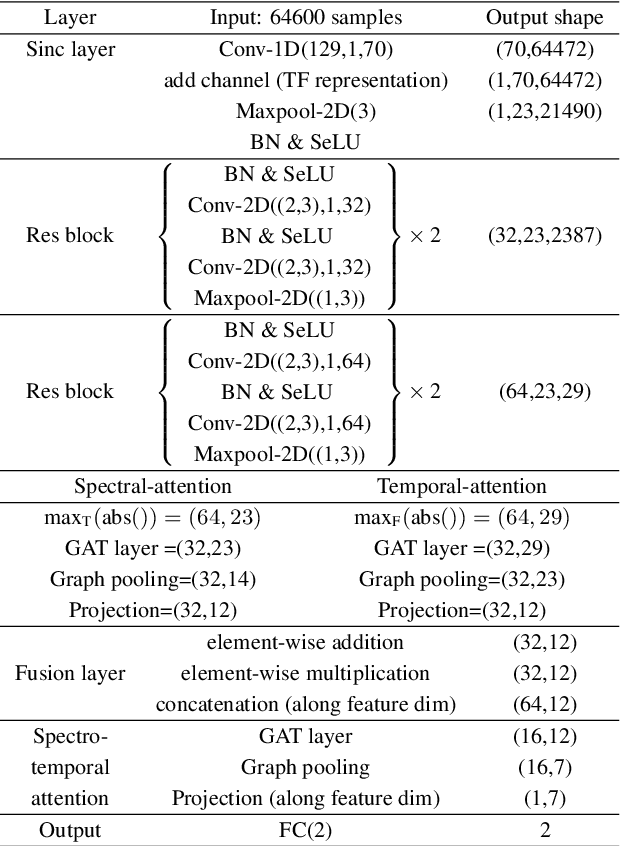
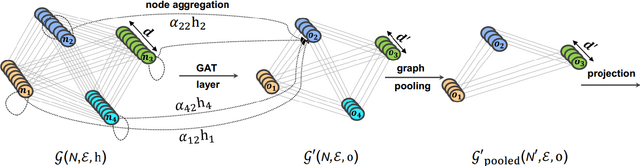

Artefacts that serve to distinguish bona fide speech from spoofed or deepfake speech are known to reside in specific subbands and temporal segments. Various approaches can be used to capture and model such artefacts, however, none works well across a spectrum of diverse spoofing attacks. Reliable detection then often depends upon the fusion of multiple detection systems, each tuned to detect different forms of attack. In this paper we show that better performance can be achieved when the fusion is performed within the model itself and when the representation is learned automatically from raw waveform inputs. The principal contribution is a spectro-temporal graph attention network (GAT) which learns the relationship between cues spanning different sub-bands and temporal intervals. Using a model-level graph fusion of spectral (S) and temporal (T) sub-graphs and a graph pooling strategy to improve discrimination, the proposed RawGAT-ST model achieves an equal error rate of 1.06 % for the ASVspoof 2019 logical access database. This is one of the best results reported to date and is reproducible using an open source implementation.
Masked Autoencoders that Listen
Jul 13, 2022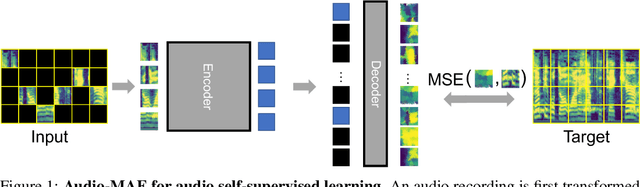

This paper studies a simple extension of image-based Masked Autoencoders (MAE) to self-supervised representation learning from audio spectrograms. Following the Transformer encoder-decoder design in MAE, our Audio-MAE first encodes audio spectrogram patches with a high masking ratio, feeding only the non-masked tokens through encoder layers. The decoder then re-orders and decodes the encoded context padded with mask tokens, in order to reconstruct the input spectrogram. We find it beneficial to incorporate local window attention in the decoder, as audio spectrograms are highly correlated in local time and frequency bands. We then fine-tune the encoder with a lower masking ratio on target datasets. Empirically, Audio-MAE sets new state-of-the-art performance on six audio and speech classification tasks, outperforming other recent models that use external supervised pre-training. The code and models will be at https://github.com/facebookresearch/AudioMAE.
Transfer learning from High-Resource to Low-Resource Language Improves Speech Affect Recognition Classification Accuracy
Mar 04, 2021

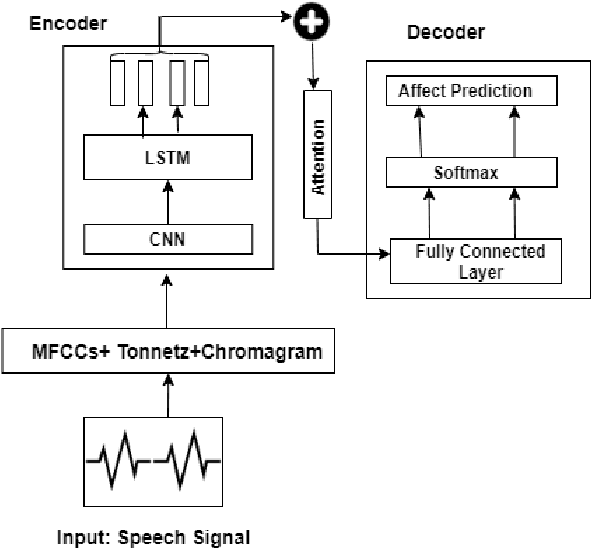
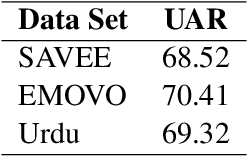
Speech Affect Recognition is a problem of extracting emotional affects from audio data. Low resource languages corpora are rear and affect recognition is a difficult task in cross-corpus settings. We present an approach in which the model is trained on high resource language and fine-tune to recognize affects in low resource language. We train the model in same corpus setting on SAVEE, EMOVO, Urdu, and IEMOCAP by achieving baseline accuracy of 60.45, 68.05, 80.34, and 56.58 percent respectively. For capturing the diversity of affects in languages cross-corpus evaluations are discussed in detail. We find that accuracy improves by adding the domain target data into the training data. Finally, we show that performance is improved for low resource language speech affect recognition by achieving the UAR OF 69.32 and 68.2 for Urdu and Italian speech affects.
TinySpeech: Attention Condensers for Deep Speech Recognition Neural Networks on Edge Devices
Aug 23, 2020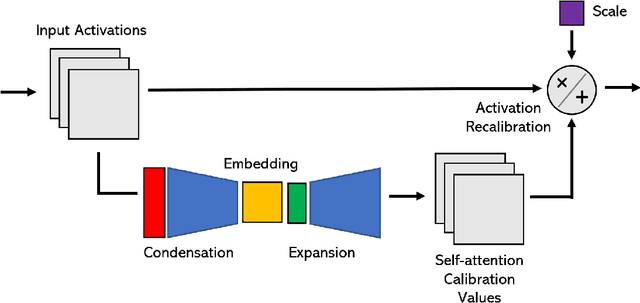

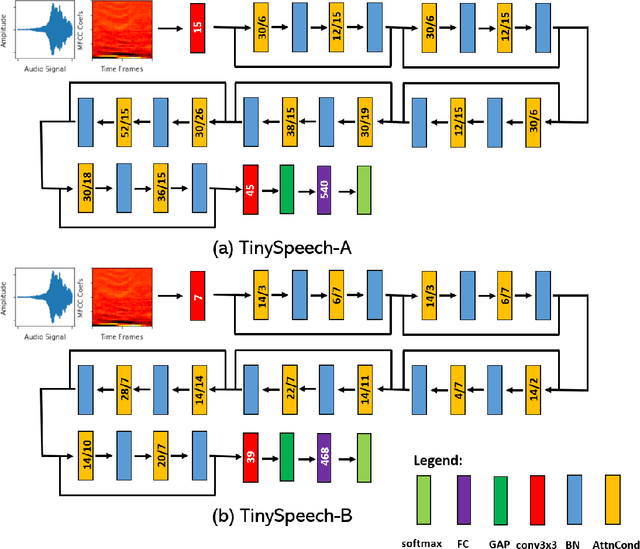
Advances in deep learning have led to state-of-the-art performance across a multitude of speech recognition tasks. Nevertheless, the widespread deployment of deep neural networks for on-device speech recognition remains a challenge, particularly in edge scenarios where the memory and computing resources are highly constrained (e.g., low-power embedded devices) or where the memory and computing budget dedicated to speech recognition is low (e.g., mobile devices performing numerous tasks besides speech recognition). In this study, we introduce the concept of attention condensers for building low-footprint, highly-efficient deep neural networks for on-device speech recognition on the edge. More specifically, an attention condenser is a self-attention mechanism that learns and produces a condensed embedding characterizing joint local and cross-channel activation relationships, and performs selective attention accordingly. To illustrate its efficacy, we introduce TinySpeech, low-precision deep neural networks comprising largely of attention condensers tailored for on-device speech recognition using a machine-driven design exploration strategy. Experimental results on the Google Speech Commands benchmark dataset for limited-vocabulary speech recognition showed that TinySpeech networks achieved significantly lower architectural complexity (as much as $207\times$ fewer parameters) and lower computational complexity (as much as $21\times$ fewer multiply-add operations) when compared to previous deep neural networks in research literature. These results not only demonstrate the efficacy of attention condensers for building highly efficient deep neural networks for on-device speech recognition, but also illuminate its potential for accelerating deep learning on the edge and empowering a wide range of TinyML applications.
Adaptation Algorithms for Speech Recognition: An Overview
Aug 14, 2020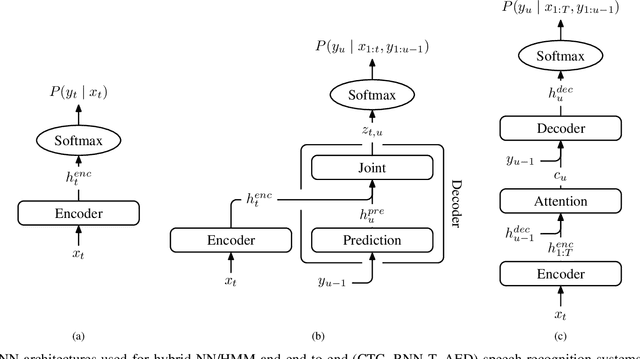
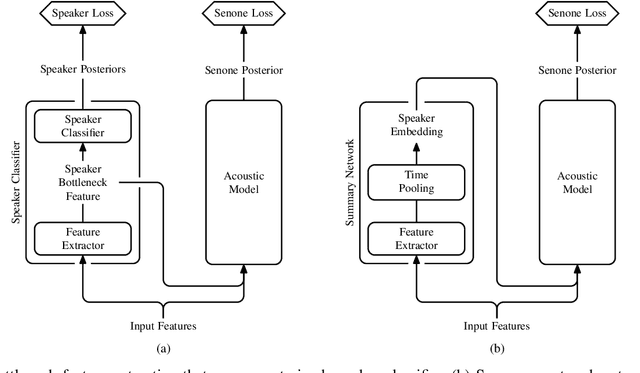
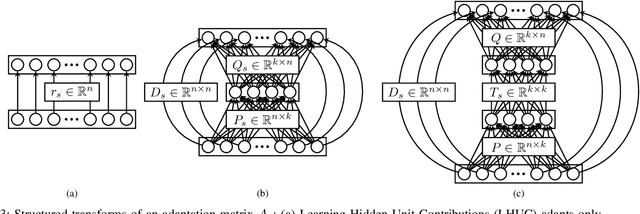
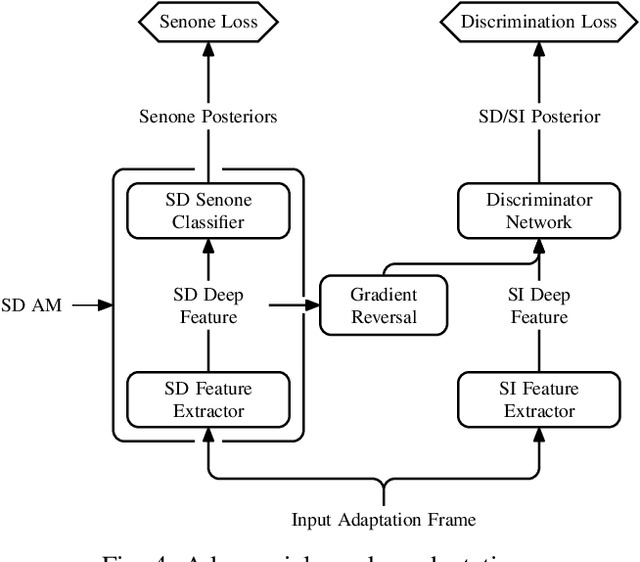
We present a structured overview of adaptation algorithms for neural network-based speech recognition, considering both hybrid hidden Markov model / neural network systems and end-to-end neural network systems, with a focus on speaker adaptation, domain adaptation, and accent adaptation. The overview characterizes adaptation algorithms as based on embeddings, model parameter adaptation, or data augmentation. We present a meta-analysis of the performance of speech recognition adaptation algorithms, based on relative error rate reductions as reported in the literature.
Vietnamese Capitalization and Punctuation Recovery Models
Jul 04, 2022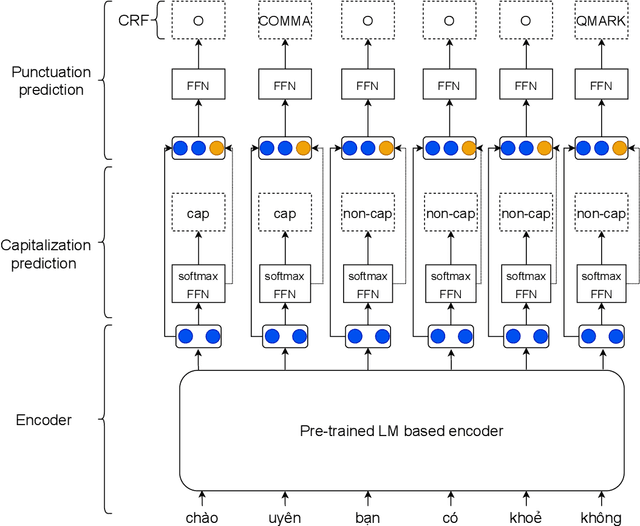
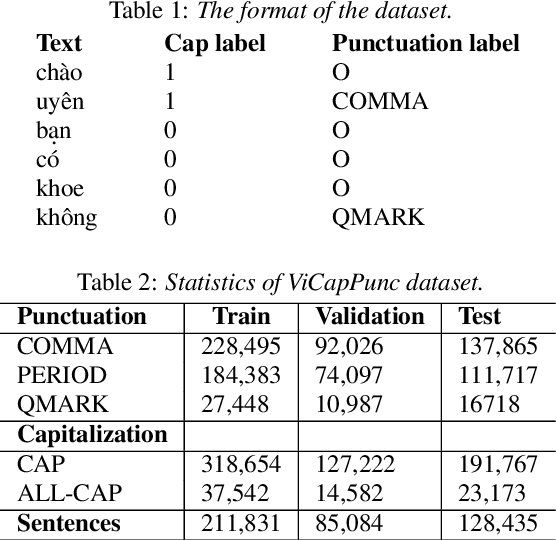
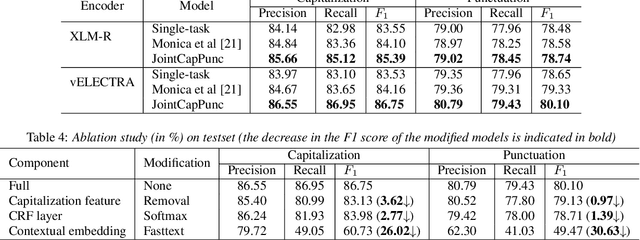
Despite the rise of recent performant methods in Automatic Speech Recognition (ASR), such methods do not ensure proper casing and punctuation for their outputs. This problem has a significant impact on the comprehension of both Natural Language Processing (NLP) algorithms and human to process. Capitalization and punctuation restoration is imperative in pre-processing pipelines for raw textual inputs. For low resource languages like Vietnamese, public datasets for this task are scarce. In this paper, we contribute a public dataset for capitalization and punctuation recovery for Vietnamese; and propose a joint model for both tasks named JointCapPunc. Experimental results on the Vietnamese dataset show the effectiveness of our joint model compare to single model and previous joint learning model. We publicly release our dataset and the implementation of our model at https://github.com/anhtunguyen98/JointCapPunc
ClovaCall: Korean Goal-Oriented Dialog Speech Corpus for Automatic Speech Recognition of Contact Centers
Apr 20, 2020
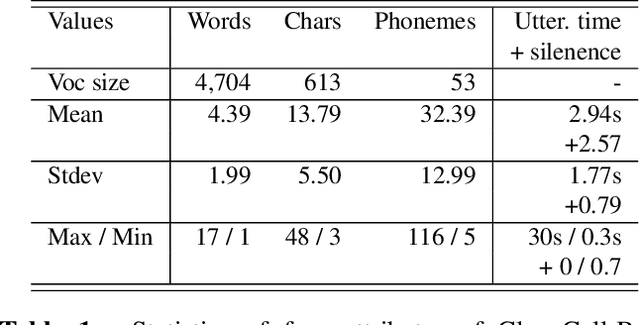
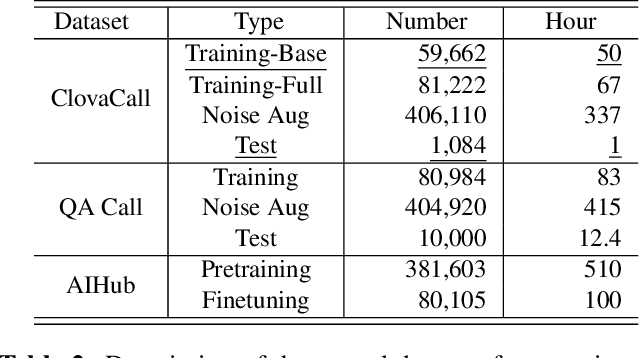
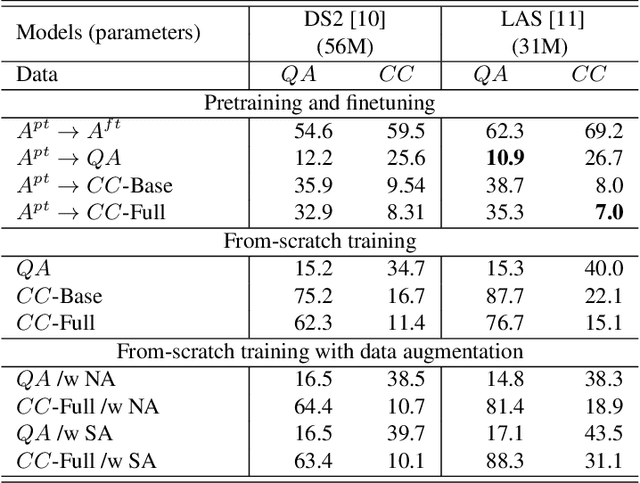
Automatic speech recognition (ASR) via call is essential for various applications, including AI for contact center (AICC) services. Despite the advancement of ASR, however, most publicly available speech corpora such as Switchboard are old-fashioned. Also, most existing call corpora are in English and mainly focus on open-domain dialog or general scenarios such as audiobooks. Here we introduce a new large-scale Korean call-based speech corpus under a goal-oriented dialog scenario from more than 11,000 people, i.e., ClovaCall corpus. ClovaCall includes approximately 60,000 pairs of a short sentence and its corresponding spoken utterance in a restaurant reservation domain. We validate the effectiveness of our dataset with intensive experiments using two standard ASR models. Furthermore, we release our ClovaCall dataset and baseline source codes to be available via https://github.com/ClovaAI/ClovaCall.
MASRI-HEADSET: A Maltese Corpus for Speech Recognition
Aug 13, 2020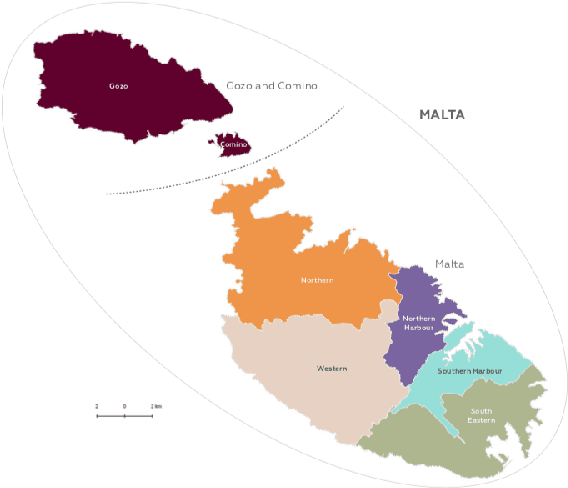
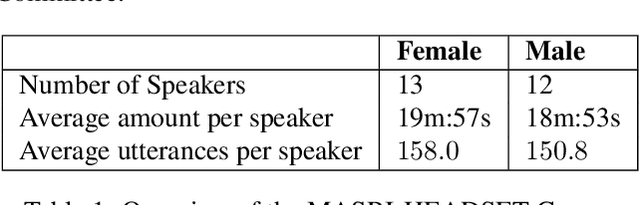
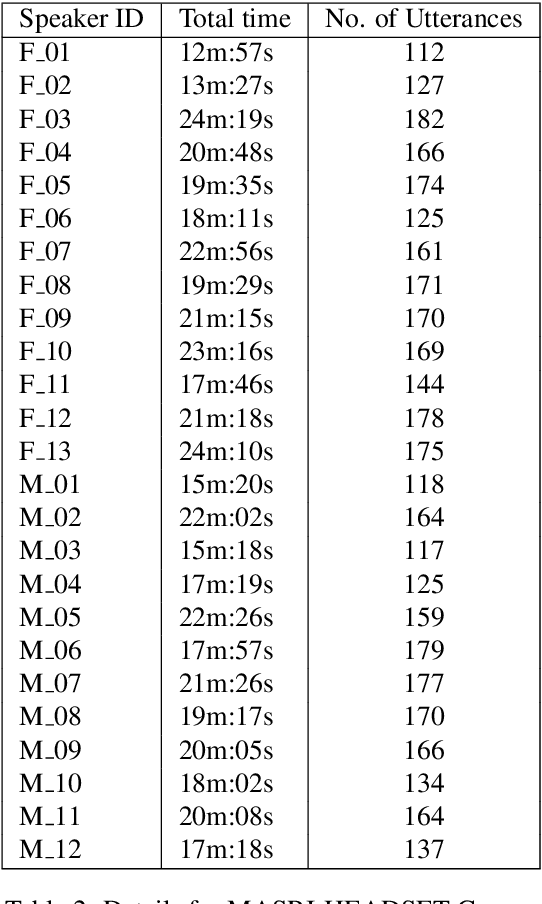
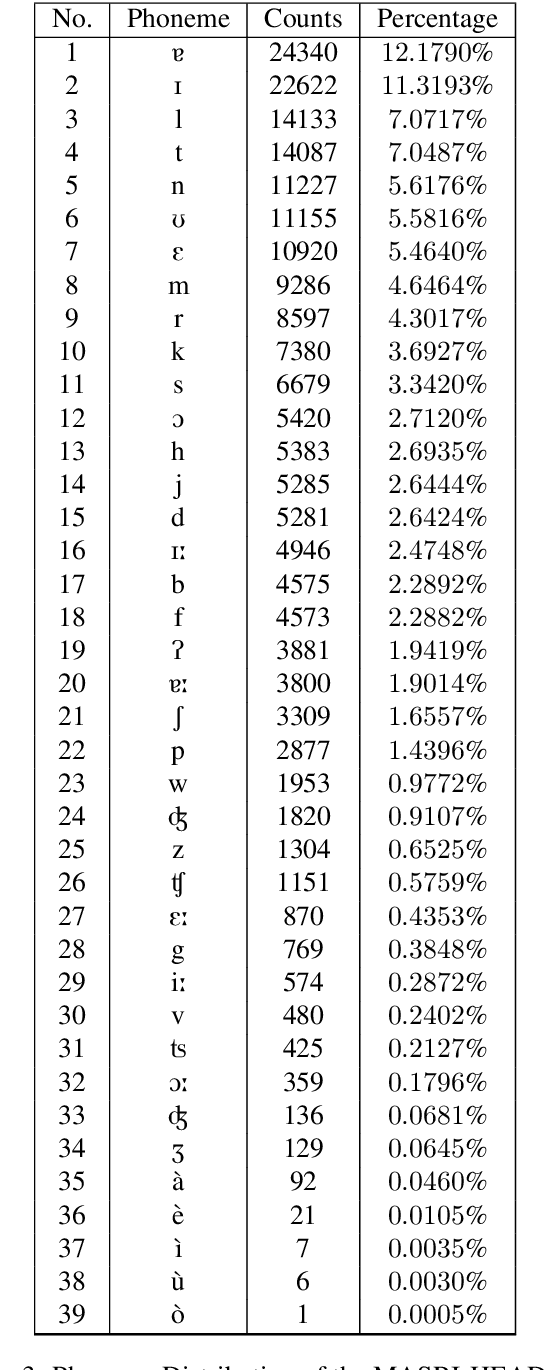
Maltese, the national language of Malta, is spoken by approximately 500,000 people. Speech processing for Maltese is still in its early stages of development. In this paper, we present the first spoken Maltese corpus designed purposely for Automatic Speech Recognition (ASR). The MASRI-HEADSET corpus was developed by the MASRI project at the University of Malta. It consists of 8 hours of speech paired with text, recorded by using short text snippets in a laboratory environment. The speakers were recruited from different geographical locations all over the Maltese islands, and were roughly evenly distributed by gender. This paper also presents some initial results achieved in baseline experiments for Maltese ASR using Sphinx and Kaldi. The MASRI-HEADSET Corpus is publicly available for research/academic purposes.
Consistent Transcription and Translation of Speech
Jul 24, 2020
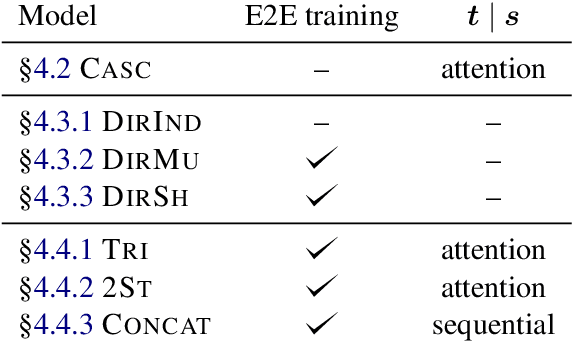

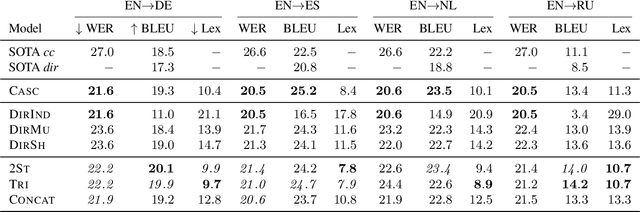
The conventional paradigm in speech translation starts with a speech recognition step to generate transcripts, followed by a translation step with the automatic transcripts as input. To address various shortcomings of this paradigm, recent work explores end-to-end trainable direct models that translate without transcribing. However, transcripts can be an indispensable output in practical applications, which often display transcripts alongside the translations to users. We make this common requirement explicit and explore the task of jointly transcribing and translating speech. While high accuracy of transcript and translation are crucial, even highly accurate systems can suffer from inconsistencies between both outputs that degrade the user experience. We introduce a methodology to evaluate consistency and compare several modeling approaches, including the traditional cascaded approach and end-to-end models. We find that direct models are poorly suited to the joint transcription/translation task, but that end-to-end models that feature a coupled inference procedure are able to achieve strong consistency. We further introduce simple techniques for directly optimizing for consistency, and analyze the resulting trade-offs between consistency, transcription accuracy, and translation accuracy.