 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speech prosody and remote experiments: a technical report
Jun 21, 2021
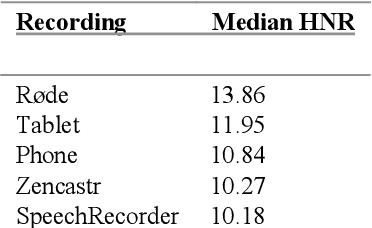

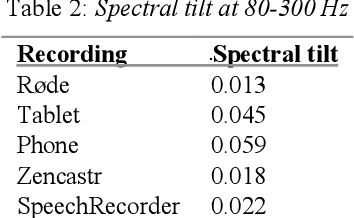
The aim of this paper is twofold. First, we present a review of different recording options for gathering prosodic data in the event that fieldwork is impracticable (e.g. due to pandemics). Under this light, we mimic a long-distance reading task experiment using different software and hardware synchronously. In order to evaluate the employed methodologies, we extract noise levels and frequency manipulation of the recordings. Subsequently, we examine the impact of the different recordings onto linguistic variables, such as the pitch curves and values. We also include a discussion on experimental practicalities. After balancing these factors, we decree an online platform, Zencastr, as the most affordable and practical for acoustic data collection. Secondly, we want to open up a debate on the most optimal remote methodology that researchers on speech prosody can deploy.
Combining Unsupervised and Text Augmented Semi-Supervised Learning for Low Resourced Autoregressive Speech Recognition
Oct 29, 2021
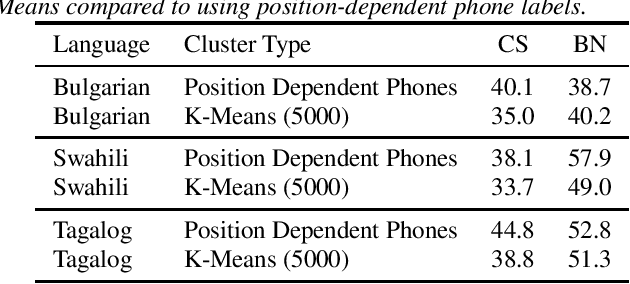
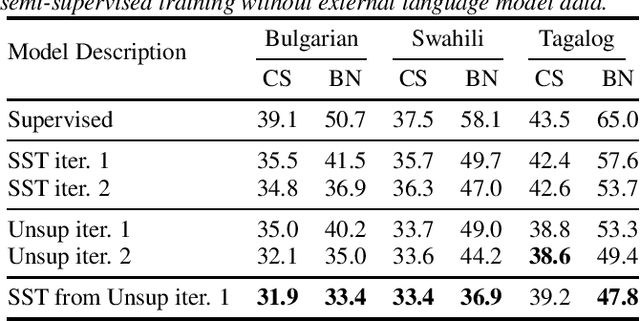
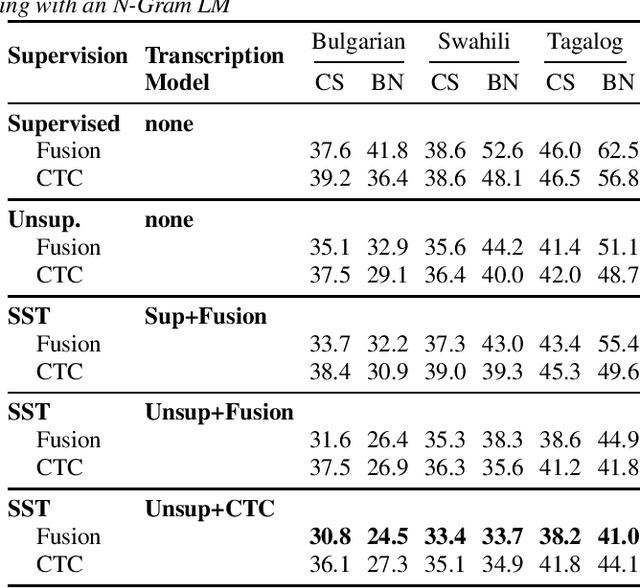
Recent advances in unsupervised representation learning have demonstrated the impact of pretraining on large amounts of read speech. We adapt these techniques for domain adaptation in low-resource -- both in terms of data and compute -- conversational and broadcast domains. Moving beyond CTC, we pretrain state-of-the-art Conformer models in an unsupervised manner. While the unsupervised approach outperforms traditional semi-supervised training, the techniques are complementary. Combining the techniques is a 5% absolute improvement in WER, averaged over all conditions, compared to semi-supervised training alone. Additional text data is incorporated through external language models. By using CTC-based decoding, we are better able to take advantage of the additional text data. When used as a transcription model, it allows the Conformer model to better incorporate the knowledge from the language model through semi-supervised training than shallow fusion. Final performance is an additional 2% better absolute when using CTC-based decoding for semi-supervised training compared to shallow fusion.
WOLONet: Wave Outlooker for Efficient and High Fidelity Speech Synthesis
Jun 20, 2022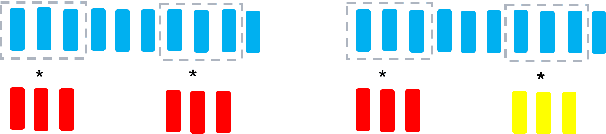
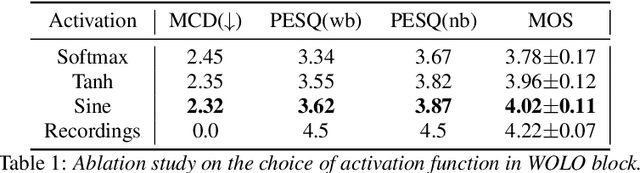
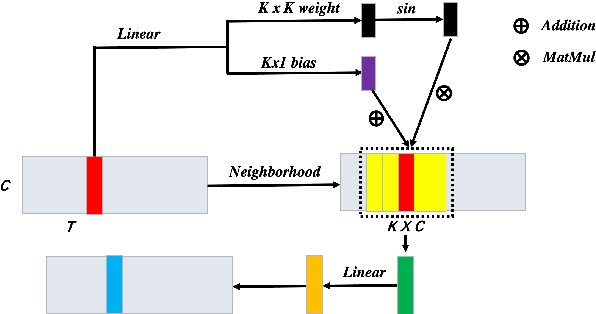
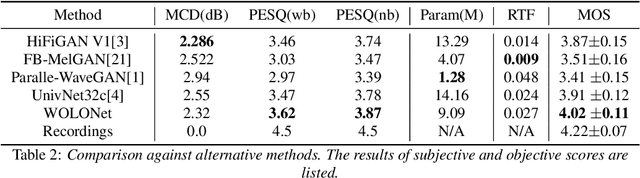
Recently, GAN-based neural vocoders such as Parallel WaveGAN, MelGAN, HiFiGAN, and UnivNet have become popular due to their lightweight and parallel structure, resulting in a real-time synthesized waveform with high fidelity, even on a CPU. HiFiGAN and UnivNet are two SOTA vocoders. Despite their high quality, there is still room for improvement. In this paper, motivated by the structure of Vision Outlooker from computer vision, we adopt a similar idea and propose an effective and lightweight neural vocoder called WOLONet. In this network, we develop a novel lightweight block that uses a location-variable, channel-independent, and depthwise dynamic convolutional kernel with sinusoidally activated dynamic kernel weights. To demonstrate the effectiveness and generalizability of our method, we perform an ablation study to verify our novel design and make a subjective and objective comparison with typical GAN-based vocoders. The results show that our WOLONet achieves the best generation quality while requiring fewer parameters than the two neural SOTA vocoders, HiFiGAN and UnivNet.
Joint prediction of truecasing and punctuation for conversational speech in low-resource scenarios
Sep 13, 2021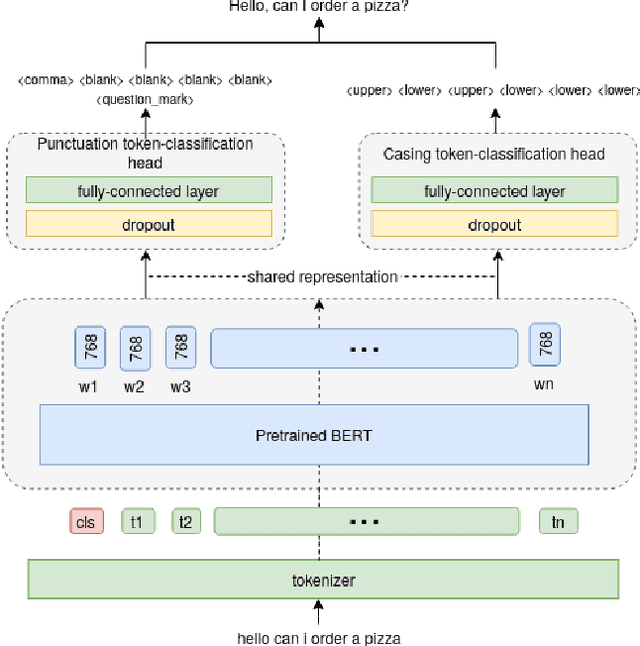
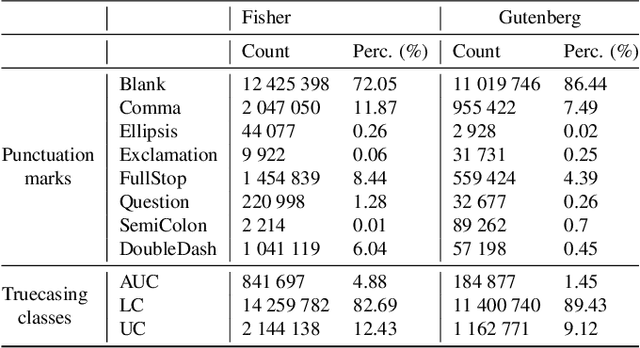
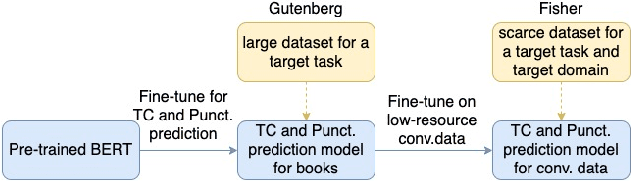
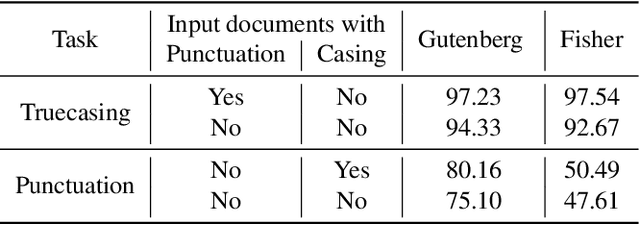
Capitalization and punctuation are important cues for comprehending written texts and conversational transcripts. Yet, many ASR systems do not produce punctuated and case-formatted speech transcripts. We propose to use a multi-task system that can exploit the relations between casing and punctuation to improve their prediction performance. Whereas text data for predicting punctuation and truecasing is seemingly abundant, we argue that written text resources are inadequate as training data for conversational models. We quantify the mismatch between written and conversational text domains by comparing the joint distributions of punctuation and word cases, and by testing our model cross-domain. Further, we show that by training the model in the written text domain and then transfer learning to conversations, we can achieve reasonable performance with less data.
Intermediate-layer output Regularization for Attention-based Speech Recognition with Shared Decoder
Jul 09, 2022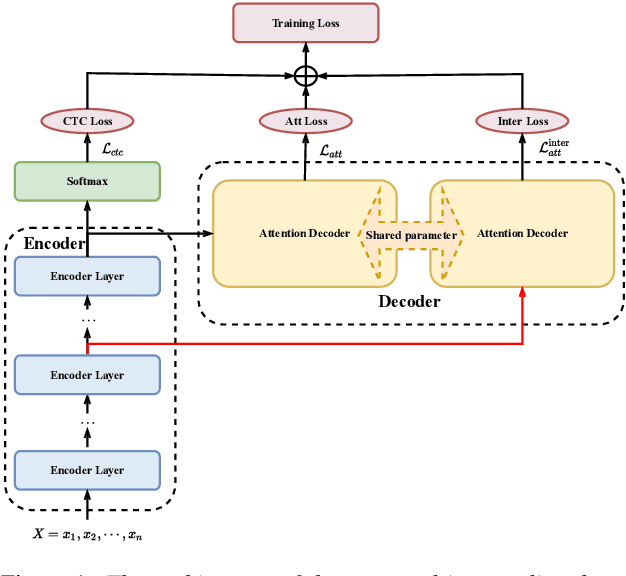
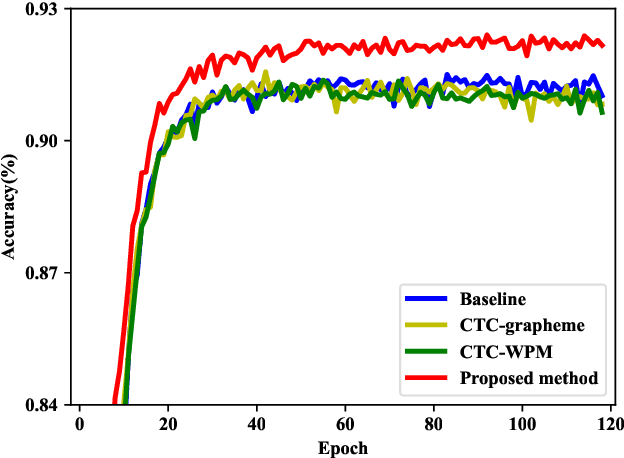
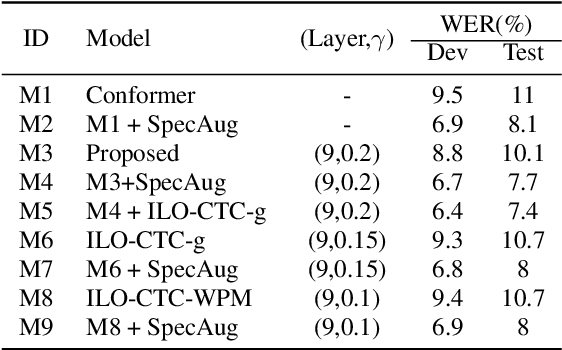
Intermediate layer output (ILO) regularization by means of multitask training on encoder side has been shown to be an effective approach to yielding improved results on a wide range of end-to-end ASR frameworks. In this paper, we propose a novel method to do ILO regularized training differently. Instead of using conventional multitask methods that entail more training overhead, we directly make the intermediate layer output as input to the decoder, that is, our decoder not only accepts the output of the final encoder layer as input, it also takes the output of the encoder ILO as input during training. With the proposed method, as both encoder and decoder are simultaneously "regularized", the network is more sufficiently trained, consistently leading to improved results, over the ILO-based CTC method, as well as over the original attention-based modeling method without the proposed method employed.
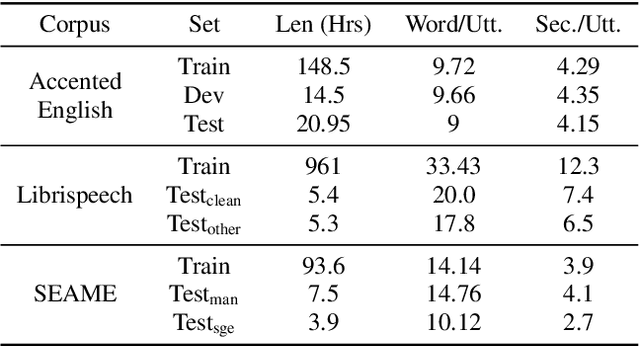
Semantic Data Augmentation for End-to-End Mandarin Speech Recognition
Apr 26, 2021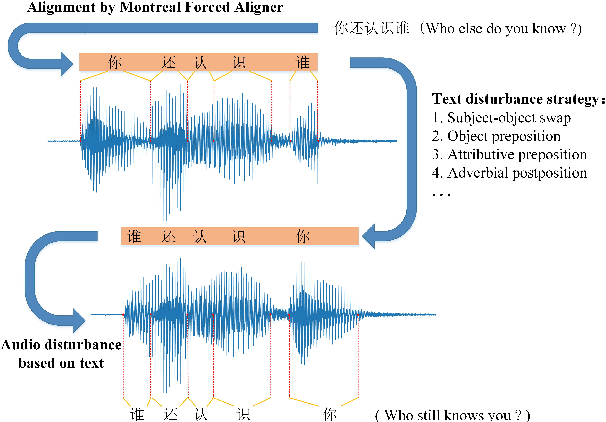


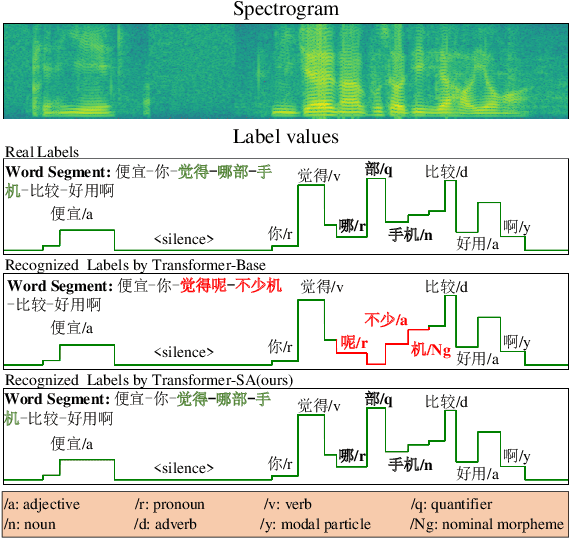
End-to-end models have gradually become the preferred option for automatic speech recognition (ASR) applications. During the training of end-to-end ASR, data augmentation is a quite effective technique for regularizing the neural networks. This paper proposes a novel data augmentation technique based on semantic transposition of the transcriptions via syntax rules for end-to-end Mandarin ASR. Specifically, we first segment the transcriptions based on part-of-speech tags. Then transposition strategies, such as placing the object in front of the subject or swapping the subject and the object, are applied on the segmented sentences. Finally, the acoustic features corresponding to the transposed transcription are reassembled based on the audio-to-text forced-alignment produced by a pre-trained ASR system. The combination of original data and augmented one is used for training a new ASR system. The experiments are conducted on the Transformer[2] and Conformer[3] based ASR. The results show that the proposed method can give consistent performance gain to the system. Augmentation related issues, such as comparison of different strategies and ratios for data combination are also investigated.
Correlation based Multi-phasal models for improved imagined speech EEG recognition
Nov 04, 2020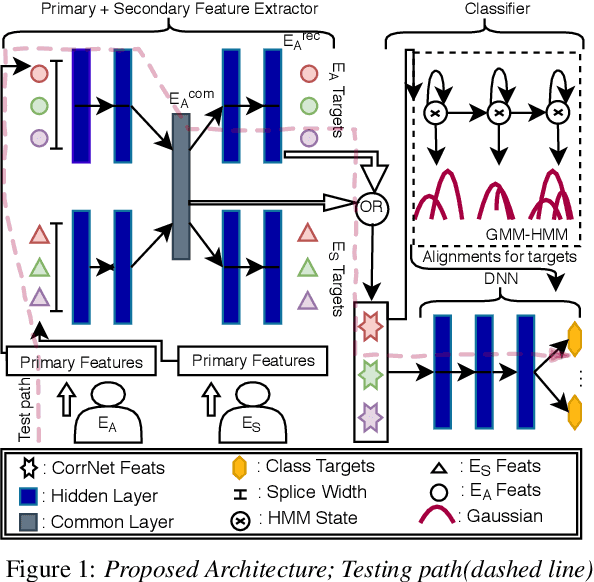
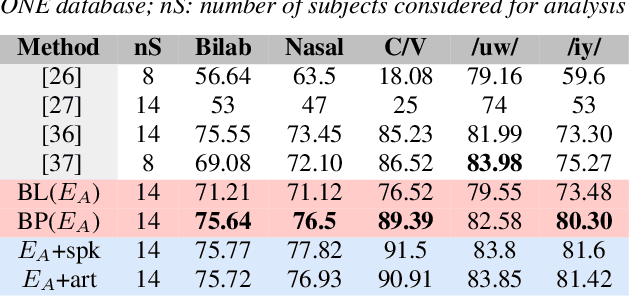
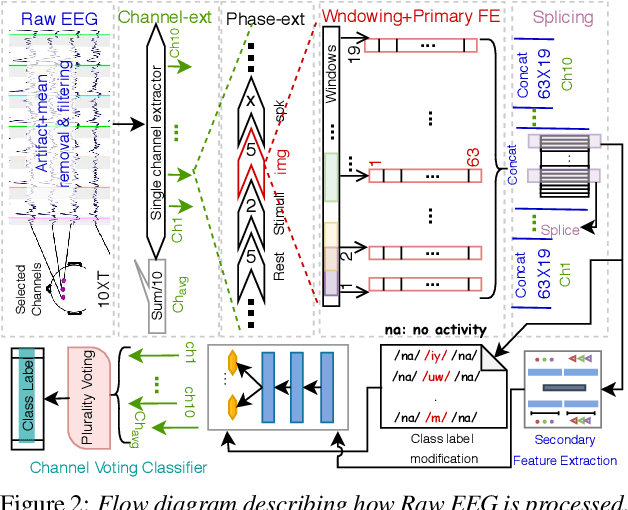
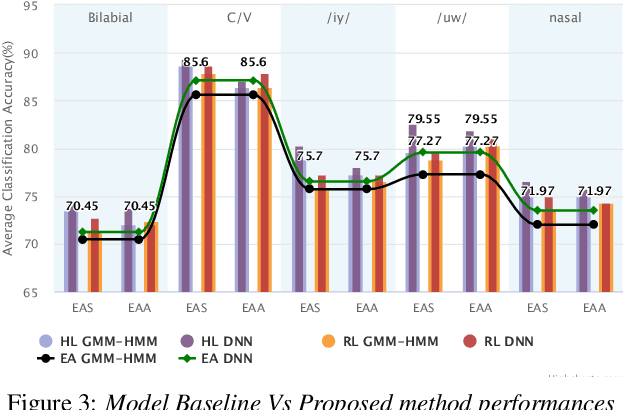
Translation of imagined speech electroencephalogram(EEG) into human understandable commands greatly facilitates the design of naturalistic brain computer interfaces. To achieve improved imagined speech unit classification, this work aims to profit from the parallel information contained in multi-phasal EEG data recorded while speaking, imagining and performing articulatory movements corresponding to specific speech units. A bi-phase common representation learning module using neural networks is designed to model the correlation and reproducibility between an analysis phase and a support phase. The trained Correlation Network is then employed to extract discriminative features of the analysis phase. These features are further classified into five binary phonological categories using machine learning models such as Gaussian mixture based hidden Markov model and deep neural networks. The proposed approach further handles the non-availability of multi-phasal data during decoding. Topographic visualizations along with result-based inferences suggest that the multi-phasal correlation modelling approach proposed in the paper enhances imagined-speech EEG recognition performance.
BERT, can HE predict contrastive focus? Predicting and controlling prominence in neural TTS using a language model
Jul 04, 2022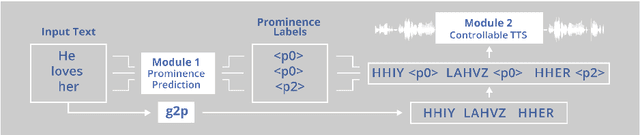

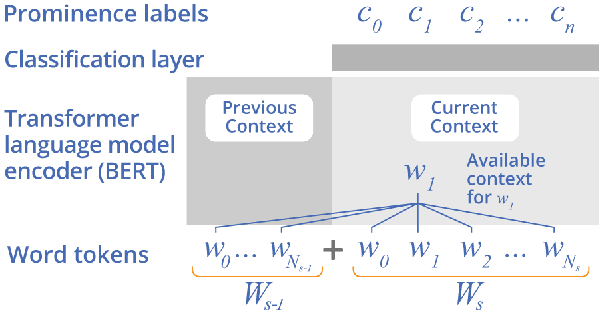
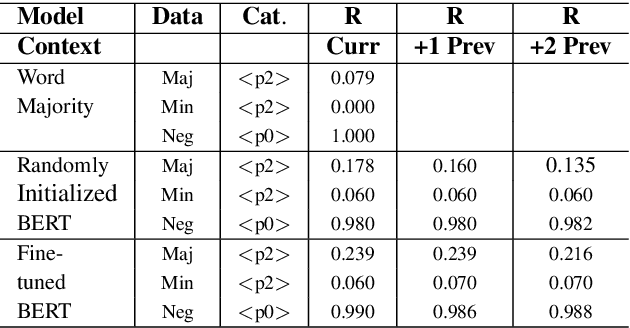
Several recent studies have tested the use of transformer language model representations to infer prosodic features for text-to-speech synthesis (TTS). While these studies have explored prosody in general, in this work, we look specifically at the prediction of contrastive focus on personal pronouns. This is a particularly challenging task as it often requires semantic, discursive and/or pragmatic knowledge to predict correctly. We collect a corpus of utterances containing contrastive focus and we evaluate the accuracy of a BERT model, finetuned to predict quantized acoustic prominence features, on these samples. We also investigate how past utterances can provide relevant information for this prediction. Furthermore, we evaluate the controllability of pronoun prominence in a TTS model conditioned on acoustic prominence features.
Language technology practitioners as language managers: arbitrating data bias and predictive bias in ASR
Feb 25, 2022Despite the fact that variation is a fundamental characteristic of natural language, automatic speech recognition systems perform systematically worse on non-standardised and marginalised language varieties. In this paper we use the lens of language policy to analyse how current practices in training and testing ASR systems in industry lead to the data bias giving rise to these systematic error differences. We believe that this is a useful perspective for speech and language technology practitioners to understand the origins and harms of algorithmic bias, and how they can mitigate it. We also propose a re-framing of language resources as (public) infrastructure which should not solely be designed for markets, but for, and with meaningful cooperation of, speech communities.
Cut Inner Layers: A Structured Pruning Strategy for Efficient U-Net GANs
Jun 29, 2022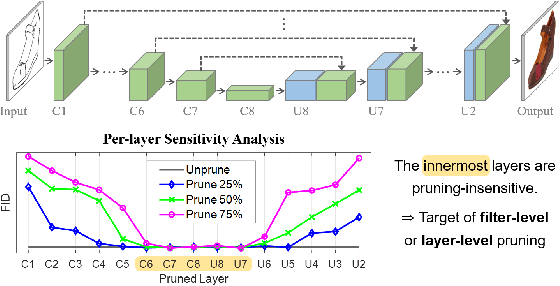
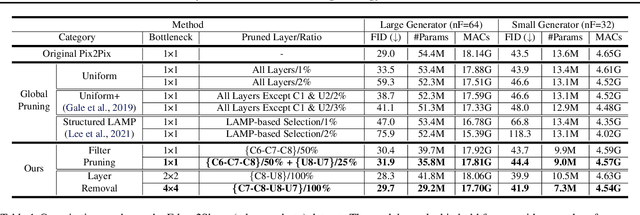
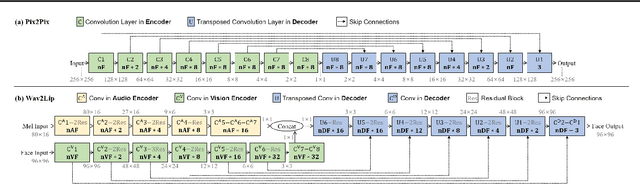
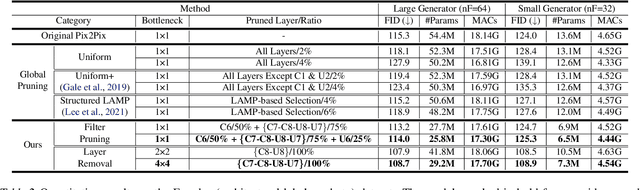
Pruning effectively compresses overparameterized models. Despite the success of pruning methods for discriminative models, applying them for generative models has been relatively rarely approached. This study conducts structured pruning on U-Net generators of conditional GANs. A per-layer sensitivity analysis confirms that many unnecessary filters exist in the innermost layers near the bottleneck and can be substantially pruned. Based on this observation, we prune these filters from multiple inner layers or suggest alternative architectures by completely eliminating the layers. We evaluate our approach with Pix2Pix for image-to-image translation and Wav2Lip for speech-driven talking face generation. Our method outperforms global pruning baselines, demonstrating the importance of properly considering where to prune for U-Net generators.