 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
AdaVITS: Tiny VITS for Low Computing Resource Speaker Adaptation
Jun 01, 2022
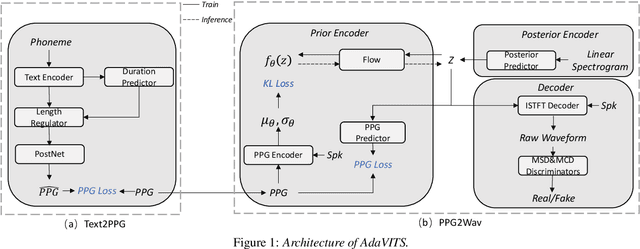

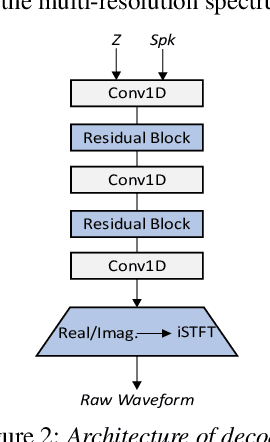
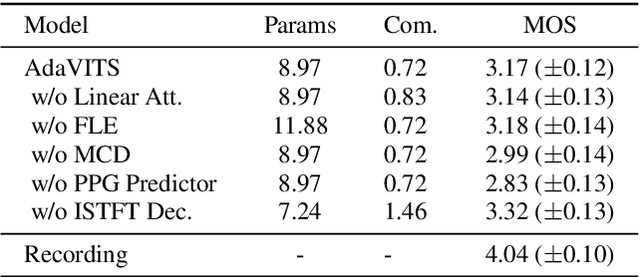
Speaker adaptation in text-to-speech synthesis (TTS) is to finetune a pre-trained TTS model to adapt to new target speakers with limited data. While much effort has been conducted towards this task, seldom work has been performed for low computational resource scenarios due to the challenges raised by the requirement of the lightweight model and less computational complexity. In this paper, a tiny VITS-based TTS model, named AdaVITS, for low computing resource speaker adaptation is proposed. To effectively reduce parameters and computational complexity of VITS, an iSTFT-based wave construction decoder is proposed to replace the upsampling-based decoder which is resource-consuming in the original VITS. Besides, NanoFlow is introduced to share the density estimate across flow blocks to reduce the parameters of the prior encoder. Furthermore, to reduce the computational complexity of the textual encoder, scaled-dot attention is replaced with linear attention. To deal with the instability caused by the simplified model, instead of using the original text encoder, phonetic posteriorgram (PPG) is utilized as linguistic feature via a text-to-PPG module, which is then used as input for the encoder. Experiment shows that AdaVITS can generate stable and natural speech in speaker adaptation with 8.97M model parameters and 0.72GFlops computational complexity.
The Development of a Labelled te reo Māori-English Bilingual Database for Language Technology
Aug 21, 2022


Te reo M\=aori (referred to as M\=aori), New Zealand's indigenous language, is under-resourced in language technology. M\=aori speakers are bilingual, where M\=aori is code-switched with English. Unfortunately, there are minimal resources available for M\=aori language technology, language detection and code-switch detection between M\=aori-English pair. Both English and M\=aori use Roman-derived orthography making rule-based systems for detecting language and code-switching restrictive. Most M\=aori language detection is done manually by language experts. This research builds a M\=aori-English bilingual database of 66,016,807 words with word-level language annotation. The New Zealand Parliament Hansard debates reports were used to build the database. The language labels are assigned using language-specific rules and expert manual annotations. Words with the same spelling, but different meanings, exist for M\=aori and English. These words could not be categorised as M\=aori or English based on word-level language rules. Hence, manual annotations were necessary. An analysis reporting the various aspects of the database such as metadata, year-wise analysis, frequently occurring words, sentence length and N-grams is also reported. The database developed here is a valuable tool for future language and speech technology development for Aotearoa New Zealand. The methodology followed to label the database can also be followed by other low-resourced language pairs.
Gender Representation in Open Source Speech Resources
Mar 18, 2020
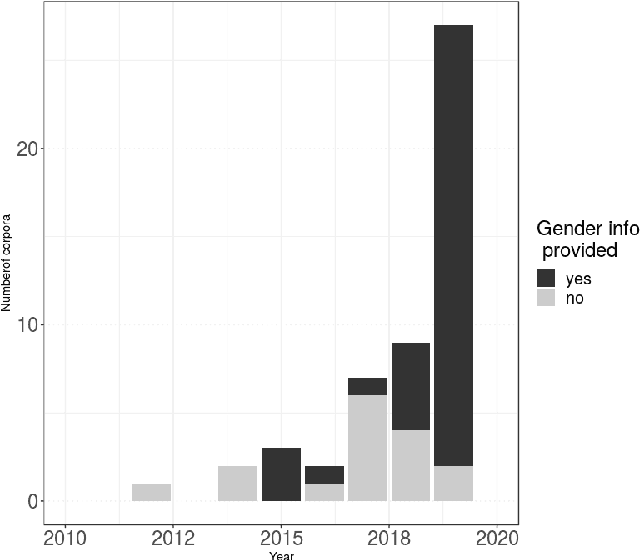

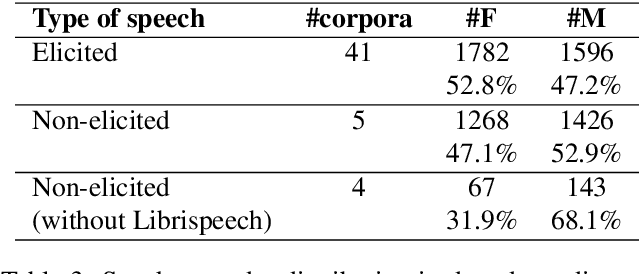
With the rise of artificial intelligence (AI) and the growing use of deep-learning architectures, the question of ethics, transparency and fairness of AI systems has become a central concern within the research community. We address transparency and fairness in spoken language systems by proposing a study about gender representation in speech resources available through the Open Speech and Language Resource platform. We show that finding gender information in open source corpora is not straightforward and that gender balance depends on other corpus characteristics (elicited/non elicited speech, low/high resource language, speech task targeted). The paper ends with recommendations about metadata and gender information for researchers in order to assure better transparency of the speech systems built using such corpora.
Arabic Code-Switching Speech Recognition using Monolingual Data
Jul 04, 2021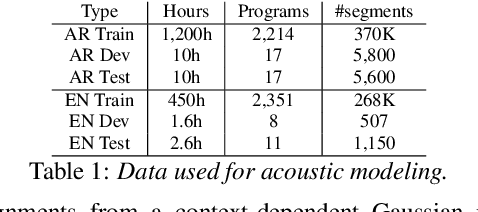
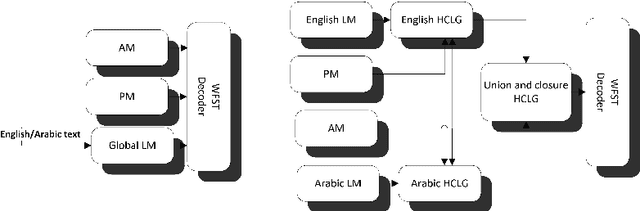
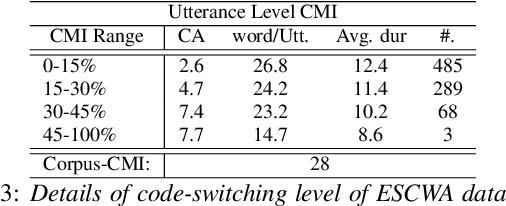
Code-switching in automatic speech recognition (ASR) is an important challenge due to globalization. Recent research in multilingual ASR shows potential improvement over monolingual systems. We study key issues related to multilingual modeling for ASR through a series of large-scale ASR experiments. Our innovative framework deploys a multi-graph approach in the weighted finite state transducers (WFST) framework. We compare our WFST decoding strategies with a transformer sequence to sequence system trained on the same data. Given a code-switching scenario between Arabic and English languages, our results show that the WFST decoding approaches were more suitable for the intersentential code-switching datasets. In addition, the transformer system performed better for intrasentential code-switching task. With this study, we release an artificially generated development and test sets, along with ecological code-switching test set, to benchmark the ASR performance.
Towards Understanding and Mitigating Audio Adversarial Examples for Speaker Recognition
Jun 07, 2022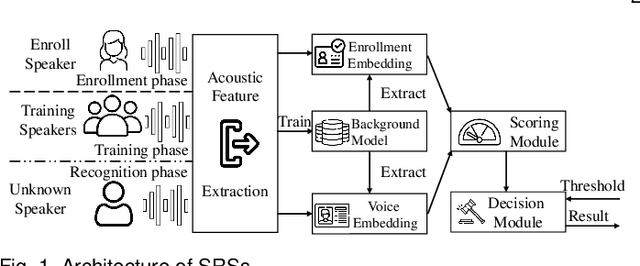
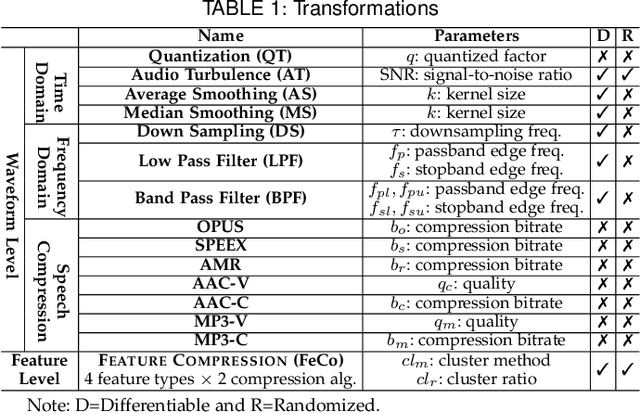
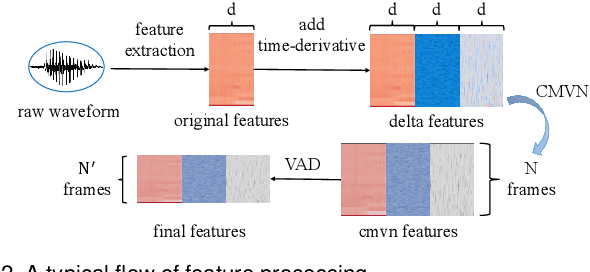
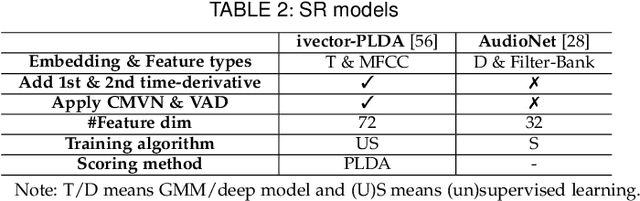
Speaker recognition systems (SRSs) have recently been shown to be vulnerable to adversarial attacks, raising significant security concerns. In this work, we systematically investigate transformation and adversarial training based defenses for securing SRSs. According to the characteristic of SRSs, we present 22 diverse transformations and thoroughly evaluate them using 7 recent promising adversarial attacks (4 white-box and 3 black-box) on speaker recognition. With careful regard for best practices in defense evaluations, we analyze the strength of transformations to withstand adaptive attacks. We also evaluate and understand their effectiveness against adaptive attacks when combined with adversarial training. Our study provides lots of useful insights and findings, many of them are new or inconsistent with the conclusions in the image and speech recognition domains, e.g., variable and constant bit rate speech compressions have different performance, and some non-differentiable transformations remain effective against current promising evasion techniques which often work well in the image domain. We demonstrate that the proposed novel feature-level transformation combined with adversarial training is rather effective compared to the sole adversarial training in a complete white-box setting, e.g., increasing the accuracy by 13.62% and attack cost by two orders of magnitude, while other transformations do not necessarily improve the overall defense capability. This work sheds further light on the research directions in this field. We also release our evaluation platform SPEAKERGUARD to foster further research.
Controllable neural text-to-speech synthesis using intuitive prosodic features
Sep 14, 2020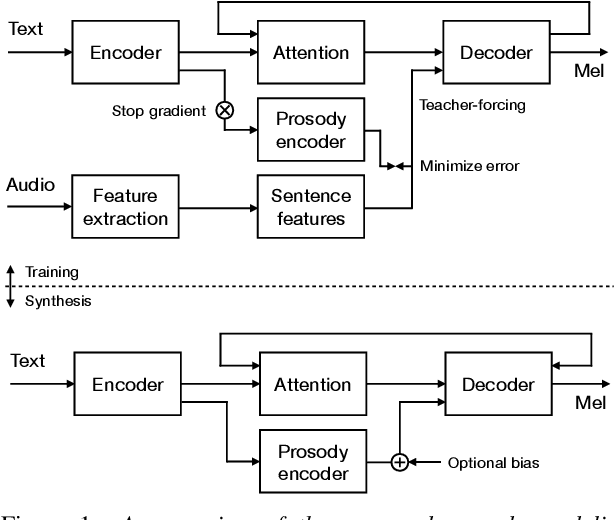
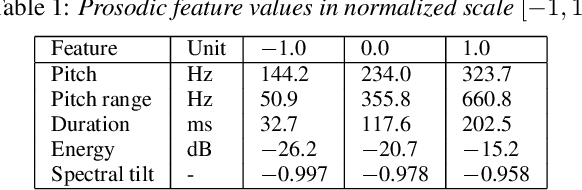
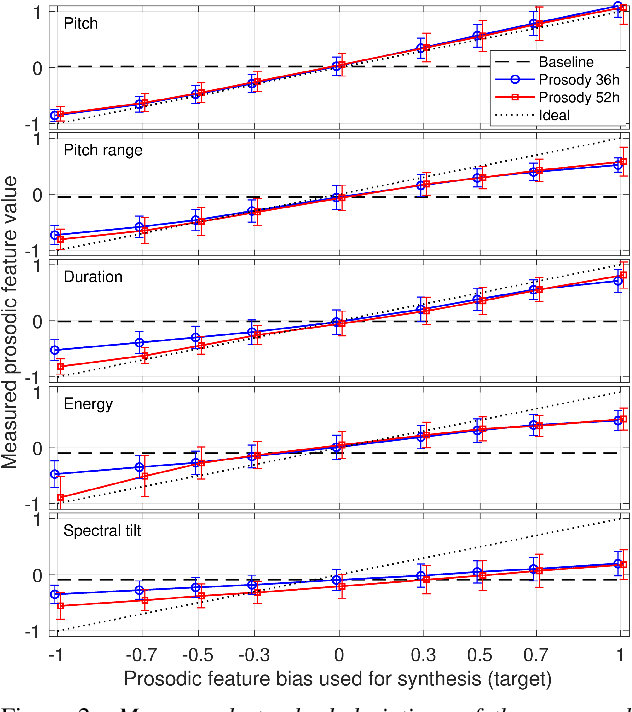
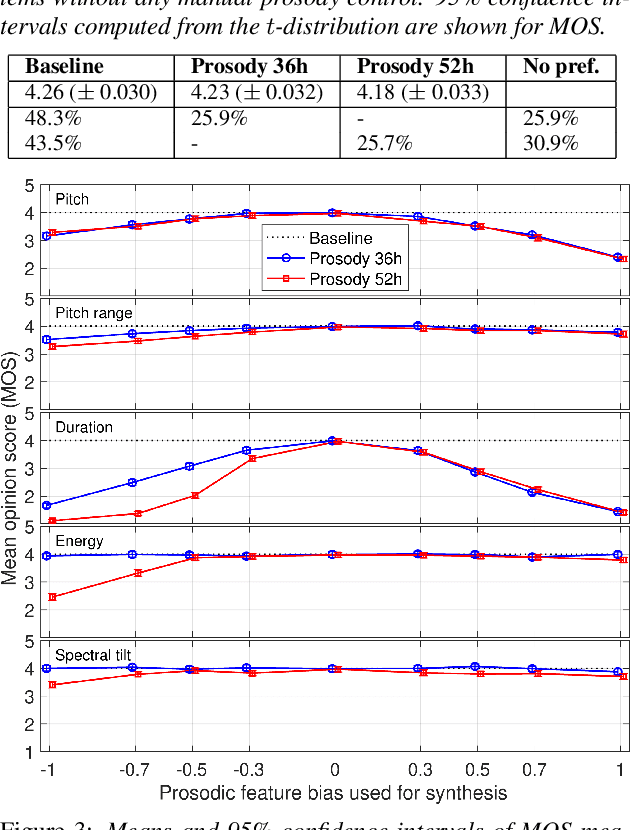
Modern neural text-to-speech (TTS) synthesis can generate speech that is indistinguishable from natural speech. However, the prosody of generated utterances often represents the average prosodic style of the database instead of having wide prosodic variation. Moreover, the generated prosody is solely defined by the input text, which does not allow for different styles for the same sentence. In this work, we train a sequence-to-sequence neural network conditioned on acoustic speech features to learn a latent prosody space with intuitive and meaningful dimensions. Experiments show that a model conditioned on sentence-wise pitch, pitch range, phone duration, energy, and spectral tilt can effectively control each prosodic dimension and generate a wide variety of speaking styles, while maintaining similar mean opinion score (4.23) to our Tacotron baseline (4.26).
DenseShift: Towards Accurate and Transferable Low-Bit Shift Network
Aug 20, 2022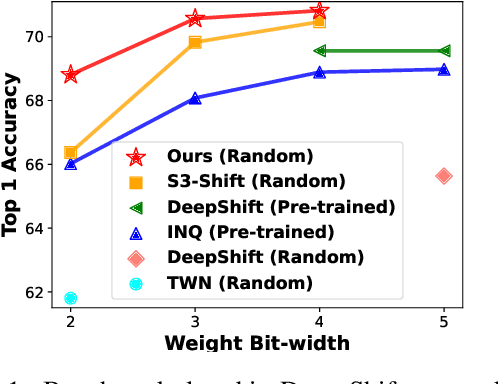
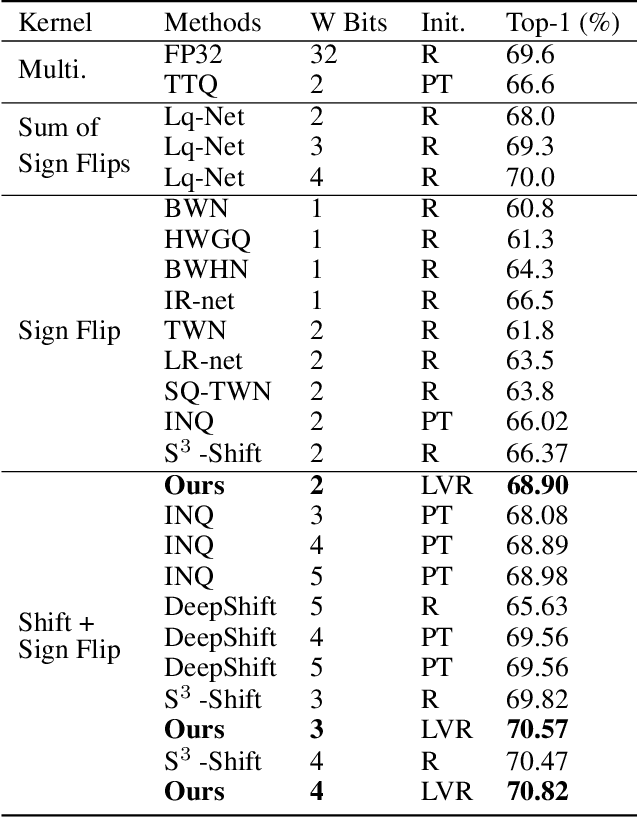
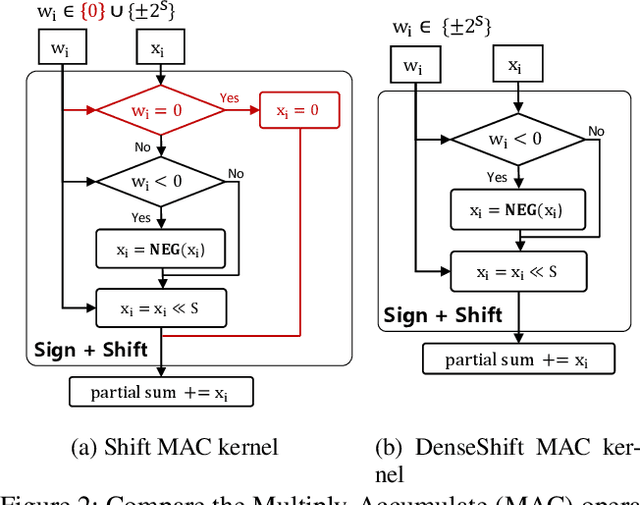
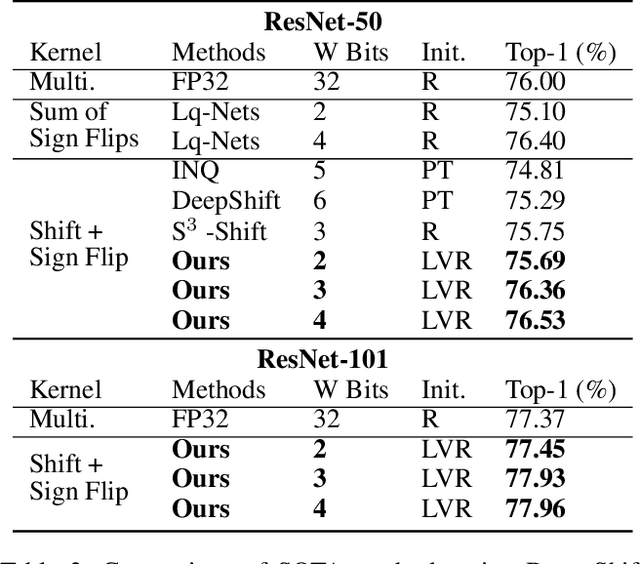
Deploying deep neural networks on low-resource edge devices is challenging due to their ever-increasing resource requirements. Recent investigations propose multiplication-free neural networks to reduce computation and memory consumption. Shift neural network is one of the most effective tools towards these reductions. However, existing low-bit shift networks are not as accurate as their full precision counterparts and cannot efficiently transfer to a wide range of tasks due to their inherent design flaws. We propose DenseShift network that exploits the following novel designs. First, we demonstrate that the zero-weight values in low-bit shift networks are neither useful to the model capacity nor simplify the model inference. Therefore, we propose to use a zero-free shifting mechanism to simplify inference while increasing the model capacity. Second, we design a new metric to measure the weight freezing issue in training low-bit shift networks, and propose a sign-scale decomposition to improve the training efficiency. Third, we propose the low-variance random initialization strategy to improve the model's performance in transfer learning scenarios. We run extensive experiments on various computer vision and speech tasks. The experimental results show that DenseShift network significantly outperforms existing low-bit multiplication-free networks and can achieve competitive performance to the full-precision counterpart. It also exhibits strong transfer learning performance with no drop in accuracy.
Three-Module Modeling For End-to-End Spoken Language Understanding Using Pre-trained DNN-HMM-Based Acoustic-Phonetic Model
Apr 07, 2022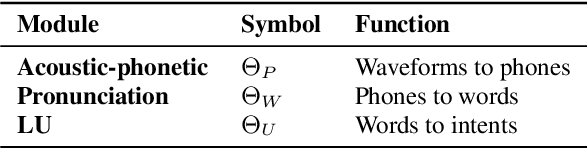
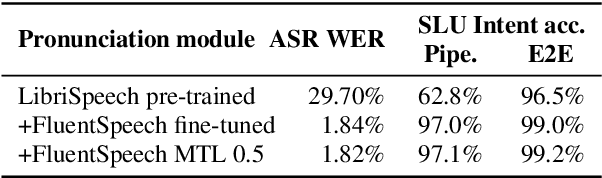

In spoken language understanding (SLU), what the user says is converted to his/her intent. Recent work on end-to-end SLU has shown that accuracy can be improved via pre-training approaches. We revisit ideas presented by Lugosch et al. using speech pre-training and three-module modeling; however, to ease construction of the end-to-end SLU model, we use as our phoneme module an open-source acoustic-phonetic model from a DNN-HMM hybrid automatic speech recognition (ASR) system instead of training one from scratch. Hence we fine-tune on speech only for the word module, and we apply multi-target learning (MTL) on the word and intent modules to jointly optimize SLU performance. MTL yields a relative reduction of 40% in intent-classification error rates (from 1.0% to 0.6%). Note that our three-module model is a streaming method. The final outcome of the proposed three-module modeling approach yields an intent accuracy of 99.4% on FluentSpeech, an intent error rate reduction of 50% compared to that of Lugosch et al. Although we focus on real-time streaming methods, we also list non-streaming methods for comparison.
Time-Frequency Localization Using Deep Convolutional Maxout Neural Network in Persian Speech Recognition
Sep 06, 2021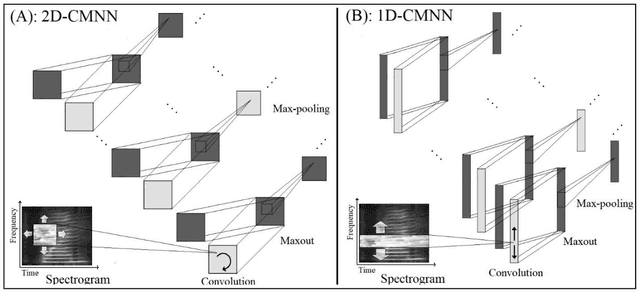
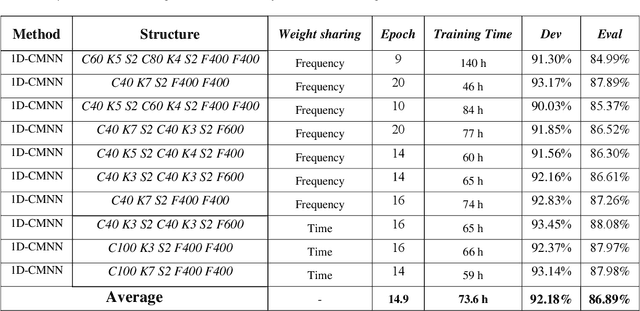
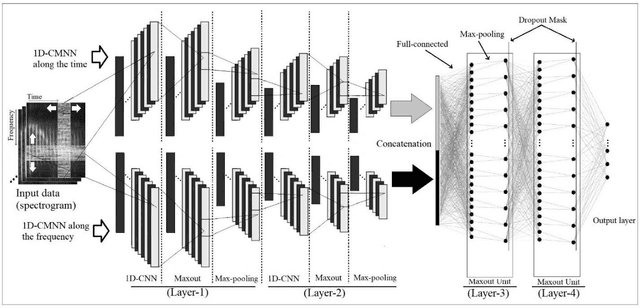
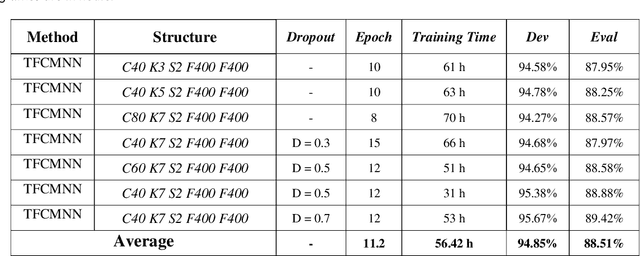
In this paper, a CNN-based structure for time-frequency localization of information in the ASR acoustic model is proposed for Persian speech recognition. Research has shown that the receptive fields' spectrotemporal plasticity of some neurons in mammals' primary auditory cortex and midbrain makes localization facilities that improve recognition performance. As biosystems have inspired many man-maid systems because of their high efficiency and performance, in the last few years, much work has been done to localize time-frequency information in ASR systems, which has used the spatial or temporal immutability properties of methods such as TDNN, CNN, and LSTM-RNN. However, most of these models have large parameter volumes and are challenging to train. We have presented a structure called Time-Frequency Convolutional Maxout Neural Network (TFCMNN) in which two parallel time-domain and frequency-domain 1D-CMNN are used. These two blocks are applied simultaneously but independently to the spectrogram, and then their output is concatenated and applied jointly to a fully connected Maxout network for classification. To improve the performance of this structure, we have used newly developed methods and models such as Dropout, maxout, and weight normalization. Two sets of experiments were designed and implemented on the Persian FARSDAT speech dataset to evaluate the performance of this model compared to conventional 1D-CMNN models. According to the experimental results, the average recognition score of TFCMNN models is about 1.6% higher than the average of conventional models. In addition, the average training time of the TFCMNN models is about 17 hours lower than the average training time of traditional models. Therefore, as proven in other sources, we can say that time-frequency localization in ASR systems increases system accuracy and speeds up the training process.
Bilingual by default: Voice Assistants and the role of code-switching in creating a bilingual user experience
Jun 20, 2022Conversational User Interfaces such as Voice Assistants are hugely popular. Yet they are designed to be monolingual by default, lacking support for, or sensitivity to, the bilingual dialogue experience. In this provocation paper, we highlight the language production challenges faced in VA interaction for bilingual users. We argue that, by facilitating phenomena seen in bilingual interaction, such as code-switching, we can foster a more inclusive and improved user experience for bilingual users. We also explore ways that this might be achieved, through the support of multiple language recognition as well as being sensitive to the preferences of code-switching in speech output.