 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Three-Module Modeling For End-to-End Spoken Language Understanding Using Pre-trained DNN-HMM-Based Acoustic-Phonetic Model
Apr 07, 2022
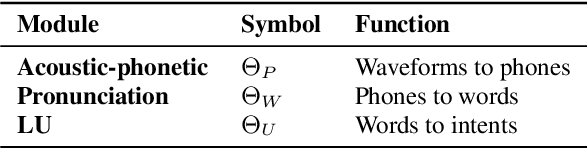
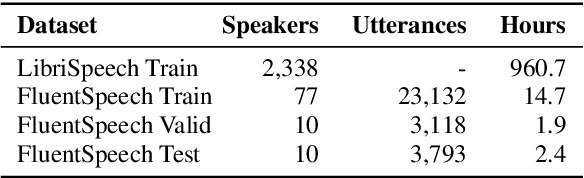
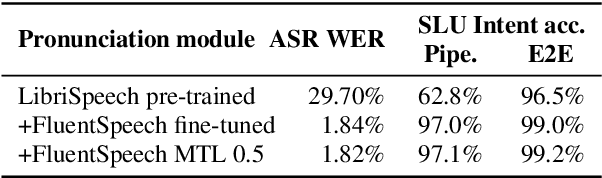

In spoken language understanding (SLU), what the user says is converted to his/her intent. Recent work on end-to-end SLU has shown that accuracy can be improved via pre-training approaches. We revisit ideas presented by Lugosch et al. using speech pre-training and three-module modeling; however, to ease construction of the end-to-end SLU model, we use as our phoneme module an open-source acoustic-phonetic model from a DNN-HMM hybrid automatic speech recognition (ASR) system instead of training one from scratch. Hence we fine-tune on speech only for the word module, and we apply multi-target learning (MTL) on the word and intent modules to jointly optimize SLU performance. MTL yields a relative reduction of 40% in intent-classification error rates (from 1.0% to 0.6%). Note that our three-module model is a streaming method. The final outcome of the proposed three-module modeling approach yields an intent accuracy of 99.4% on FluentSpeech, an intent error rate reduction of 50% compared to that of Lugosch et al. Although we focus on real-time streaming methods, we also list non-streaming methods for comparison.
Arabic Code-Switching Speech Recognition using Monolingual Data
Jul 04, 2021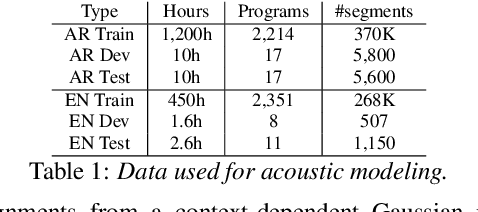
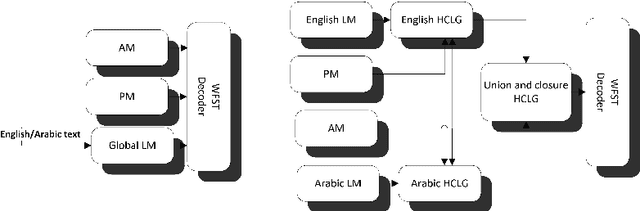
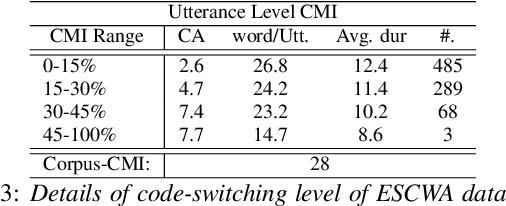
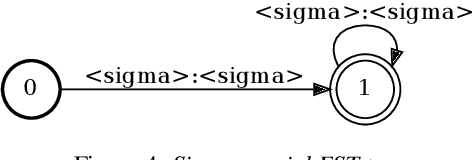
Code-switching in automatic speech recognition (ASR) is an important challenge due to globalization. Recent research in multilingual ASR shows potential improvement over monolingual systems. We study key issues related to multilingual modeling for ASR through a series of large-scale ASR experiments. Our innovative framework deploys a multi-graph approach in the weighted finite state transducers (WFST) framework. We compare our WFST decoding strategies with a transformer sequence to sequence system trained on the same data. Given a code-switching scenario between Arabic and English languages, our results show that the WFST decoding approaches were more suitable for the intersentential code-switching datasets. In addition, the transformer system performed better for intrasentential code-switching task. With this study, we release an artificially generated development and test sets, along with ecological code-switching test set, to benchmark the ASR performance.
Unsupervised Word Segmentation using K Nearest Neighbors
Apr 27, 2022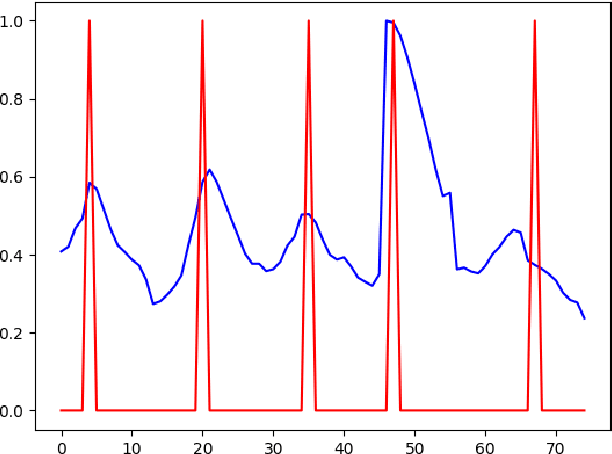
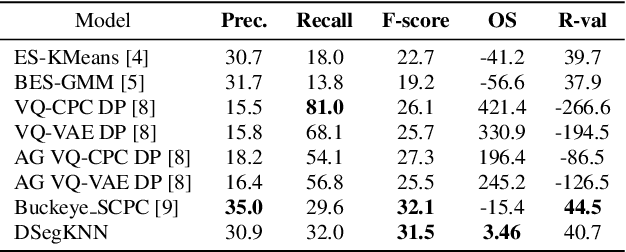
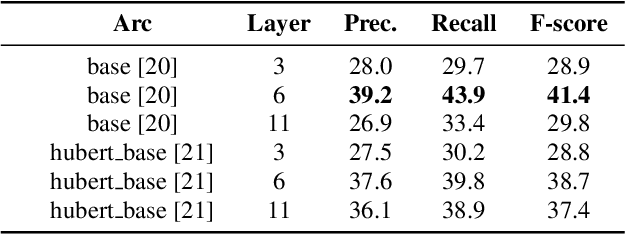
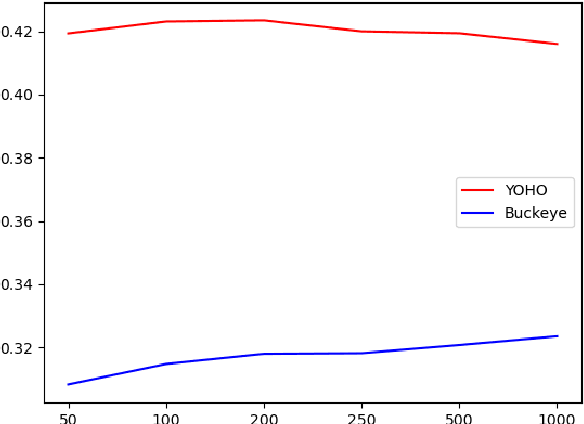
In this paper, we propose an unsupervised kNN-based approach for word segmentation in speech utterances. Our method relies on self-supervised pre-trained speech representations, and compares each audio segment of a given utterance to its K nearest neighbors within the training set. Our main assumption is that a segment containing more than one word would occur less often than a segment containing a single word. Our method does not require phoneme discovery and is able to operate directly on pre-trained audio representations. This is in contrast to current methods that use a two-stage approach; first detecting the phonemes in the utterance and then detecting word-boundaries according to statistics calculated on phoneme patterns. Experiments on two datasets demonstrate improved results over previous single-stage methods and competitive results on state-of-the-art two-stage methods.
Gender Representation in Open Source Speech Resources
Mar 18, 2020
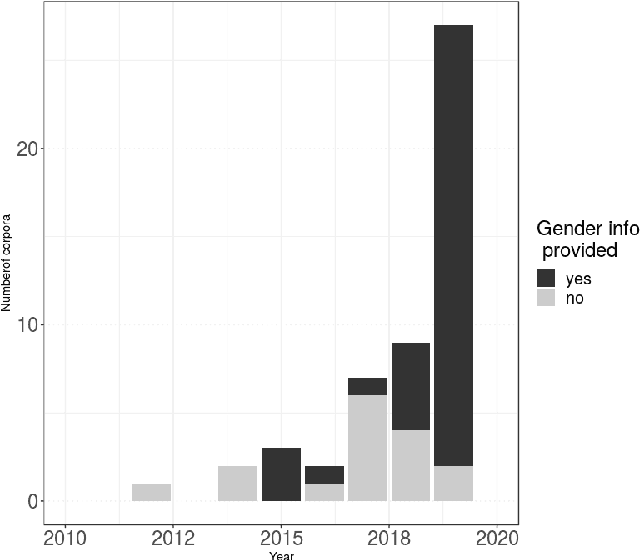

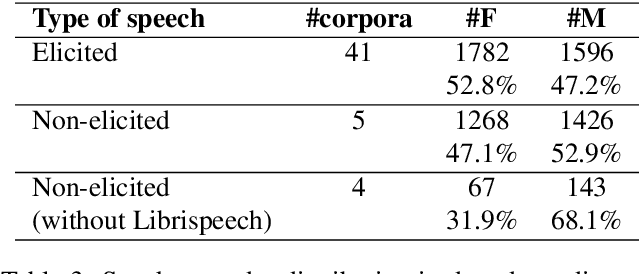
With the rise of artificial intelligence (AI) and the growing use of deep-learning architectures, the question of ethics, transparency and fairness of AI systems has become a central concern within the research community. We address transparency and fairness in spoken language systems by proposing a study about gender representation in speech resources available through the Open Speech and Language Resource platform. We show that finding gender information in open source corpora is not straightforward and that gender balance depends on other corpus characteristics (elicited/non elicited speech, low/high resource language, speech task targeted). The paper ends with recommendations about metadata and gender information for researchers in order to assure better transparency of the speech systems built using such corpora.
Time-Frequency Localization Using Deep Convolutional Maxout Neural Network in Persian Speech Recognition
Sep 06, 2021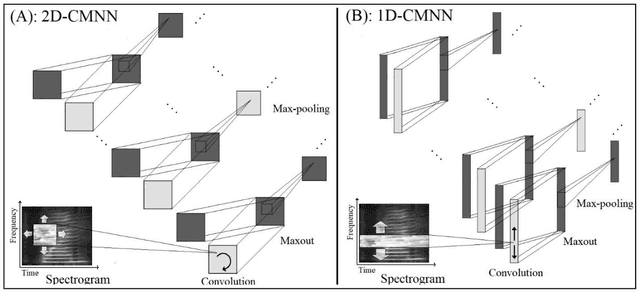
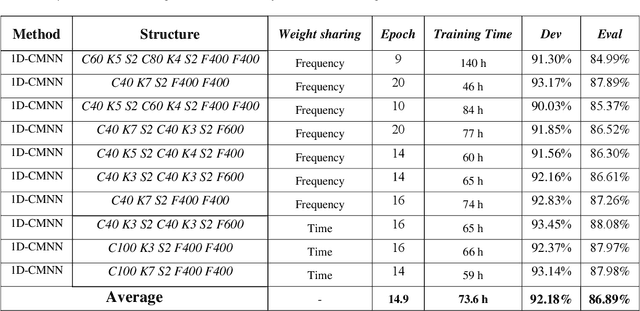
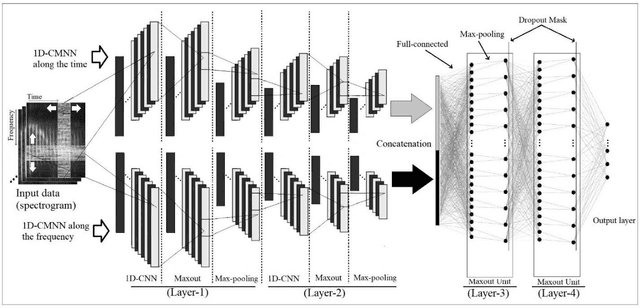
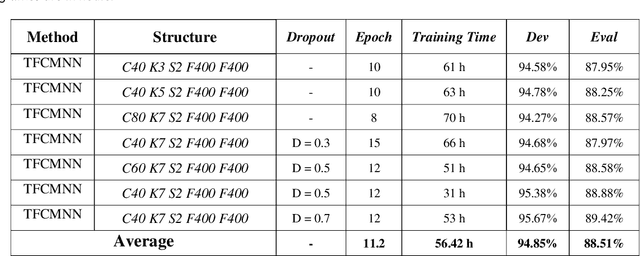
In this paper, a CNN-based structure for time-frequency localization of information in the ASR acoustic model is proposed for Persian speech recognition. Research has shown that the receptive fields' spectrotemporal plasticity of some neurons in mammals' primary auditory cortex and midbrain makes localization facilities that improve recognition performance. As biosystems have inspired many man-maid systems because of their high efficiency and performance, in the last few years, much work has been done to localize time-frequency information in ASR systems, which has used the spatial or temporal immutability properties of methods such as TDNN, CNN, and LSTM-RNN. However, most of these models have large parameter volumes and are challenging to train. We have presented a structure called Time-Frequency Convolutional Maxout Neural Network (TFCMNN) in which two parallel time-domain and frequency-domain 1D-CMNN are used. These two blocks are applied simultaneously but independently to the spectrogram, and then their output is concatenated and applied jointly to a fully connected Maxout network for classification. To improve the performance of this structure, we have used newly developed methods and models such as Dropout, maxout, and weight normalization. Two sets of experiments were designed and implemented on the Persian FARSDAT speech dataset to evaluate the performance of this model compared to conventional 1D-CMNN models. According to the experimental results, the average recognition score of TFCMNN models is about 1.6% higher than the average of conventional models. In addition, the average training time of the TFCMNN models is about 17 hours lower than the average training time of traditional models. Therefore, as proven in other sources, we can say that time-frequency localization in ASR systems increases system accuracy and speeds up the training process.
WAVPROMPT: Towards Few-Shot Spoken Language Understanding with Frozen Language Models
Mar 29, 2022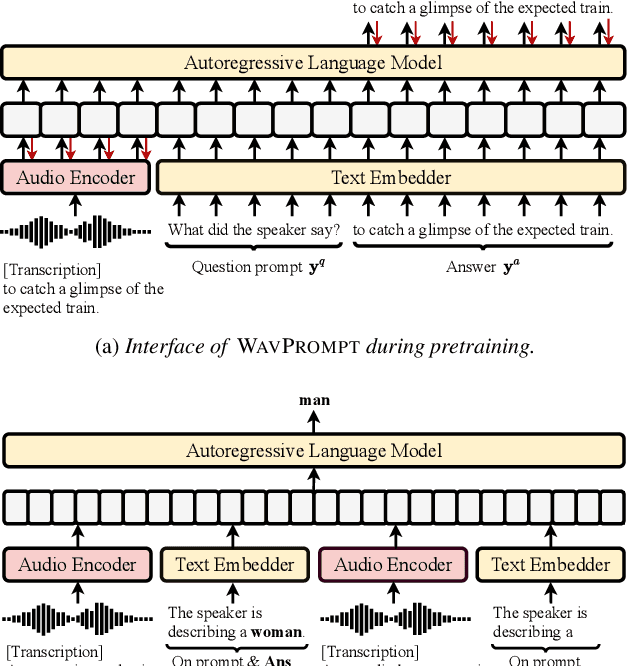
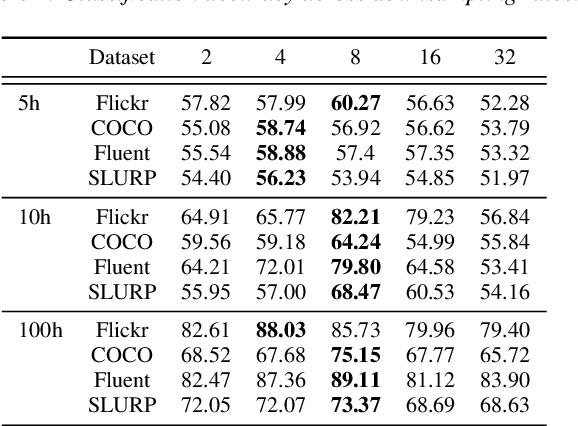

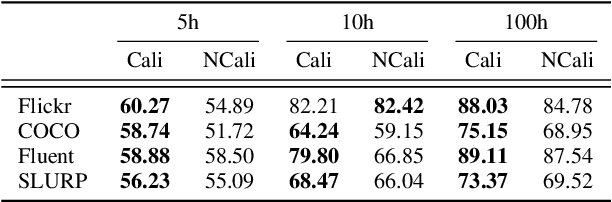
Large-scale auto-regressive language models pretrained on massive text have demonstrated their impressive ability to perform new natural language tasks with only a few text examples, without the need for fine-tuning. Recent studies further show that such a few-shot learning ability can be extended to the text-image setting by training an encoder to encode the images into embeddings functioning like the text embeddings of the language model. Interested in exploring the possibility of transferring the few-shot learning ability to the audio-text setting, we propose a novel speech understanding framework, WavPrompt, where we finetune a wav2vec model to generate a sequence of audio embeddings understood by the language model. We show that WavPrompt is a few-shot learner that can perform speech understanding tasks better than a naive text baseline. We conduct detailed ablation studies on different components and hyperparameters to empirically identify the best model configuration. In addition, we conduct a non-speech understanding experiment to show WavPrompt can extract more information than just the transcriptions.
Controllable neural text-to-speech synthesis using intuitive prosodic features
Sep 14, 2020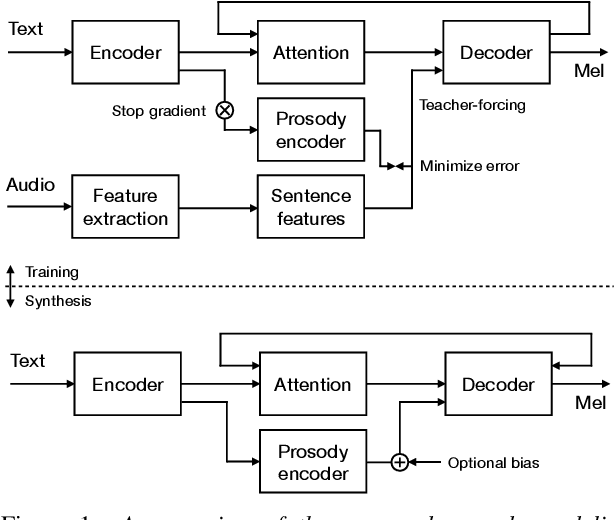
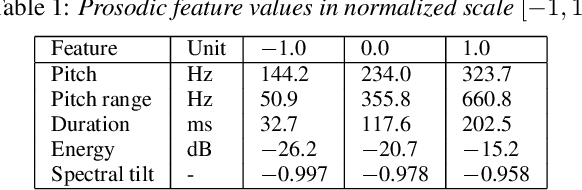
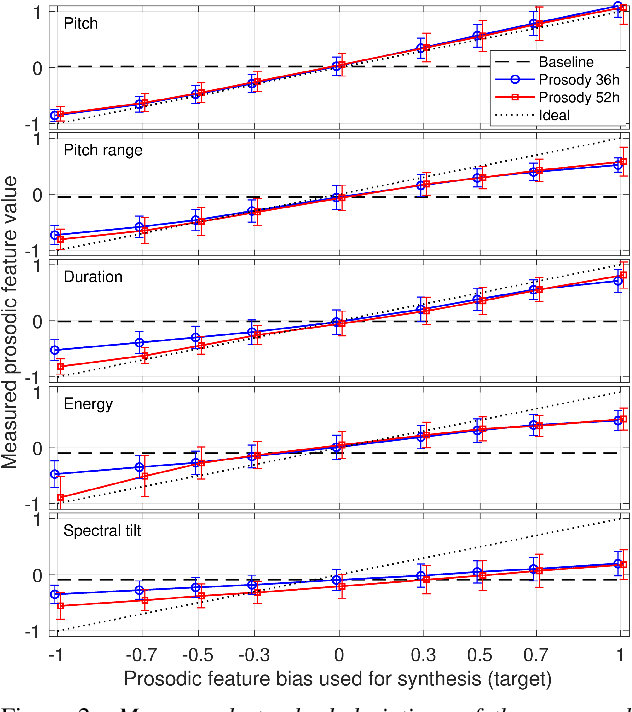
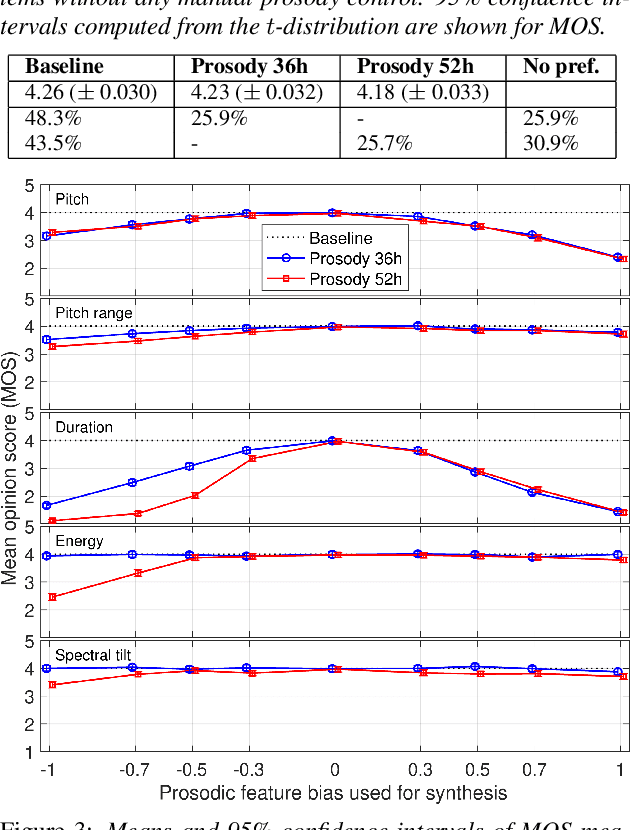
Modern neural text-to-speech (TTS) synthesis can generate speech that is indistinguishable from natural speech. However, the prosody of generated utterances often represents the average prosodic style of the database instead of having wide prosodic variation. Moreover, the generated prosody is solely defined by the input text, which does not allow for different styles for the same sentence. In this work, we train a sequence-to-sequence neural network conditioned on acoustic speech features to learn a latent prosody space with intuitive and meaningful dimensions. Experiments show that a model conditioned on sentence-wise pitch, pitch range, phone duration, energy, and spectral tilt can effectively control each prosodic dimension and generate a wide variety of speaking styles, while maintaining similar mean opinion score (4.23) to our Tacotron baseline (4.26).
StableFace: Analyzing and Improving Motion Stability for Talking Face Generation
Aug 29, 2022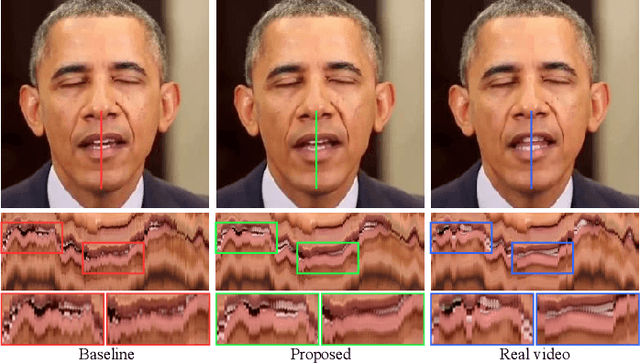
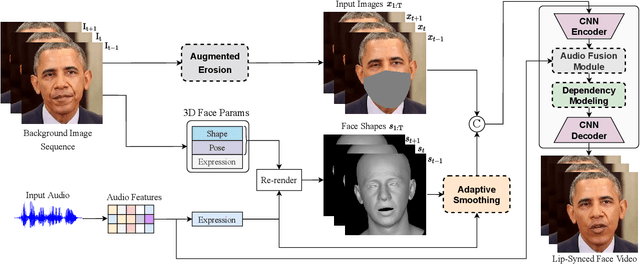
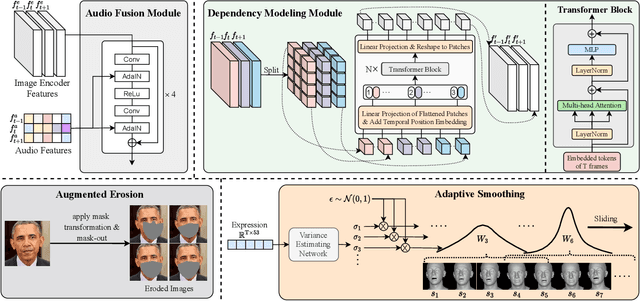

While previous speech-driven talking face generation methods have made significant progress in improving the visual quality and lip-sync quality of the synthesized videos, they pay less attention to lip motion jitters which greatly undermine the realness of talking face videos. What causes motion jitters, and how to mitigate the problem? In this paper, we conduct systematic analyses on the motion jittering problem based on a state-of-the-art pipeline that uses 3D face representations to bridge the input audio and output video, and improve the motion stability with a series of effective designs. We find that several issues can lead to jitters in synthesized talking face video: 1) jitters from the input 3D face representations; 2) training-inference mismatch; 3) lack of dependency modeling among video frames. Accordingly, we propose three effective solutions to address this issue: 1) we propose a gaussian-based adaptive smoothing module to smooth the 3D face representations to eliminate jitters in the input; 2) we add augmented erosions on the input data of the neural renderer in training to simulate the distortion in inference to reduce mismatch; 3) we develop an audio-fused transformer generator to model dependency among video frames. Besides, considering there is no off-the-shelf metric for measuring motion jitters in talking face video, we devise an objective metric (Motion Stability Index, MSI), to quantitatively measure the motion jitters by calculating the reciprocal of variance acceleration. Extensive experimental results show the superiority of our method on motion-stable face video generation, with better quality than previous systems.
VoiceMe: Personalized voice generation in TTS
Mar 29, 2022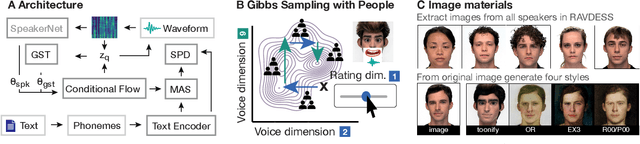
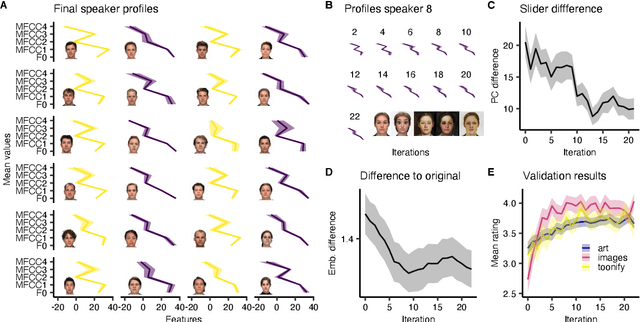
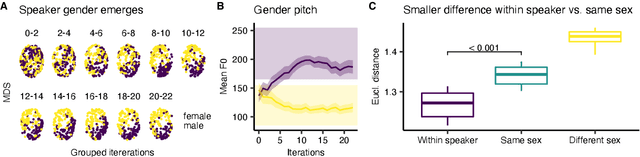
Novel text-to-speech systems can generate entirely new voices that were not seen during training. However, it remains a difficult task to efficiently create personalized voices from a high dimensional speaker space. In this work, we use speaker embeddings from a state-of-the-art speaker verification model (SpeakerNet) trained on thousands of speakers to condition a TTS model. We employ a human sampling paradigm to explore this speaker latent space. We show that users can create voices that fit well to photos of faces, art portraits, and cartoons. We recruit online participants to collectively manipulate the voice of a speaking face. We show that (1) a separate group of human raters confirms that the created voices match the faces, (2) speaker gender apparent from the face is well-recovered in the voice, and (3) people are consistently moving towards the real voice prototype for the given face. Our results demonstrate that this technology can be applied in a wide number of applications including character voice development in audiobooks and games, personalized speech assistants, and individual voices for people with speech impairment.
Multi-Task Learning with Sentiment, Emotion, and Target Detection to Recognize Hate Speech and Offensive Language
Oct 13, 2021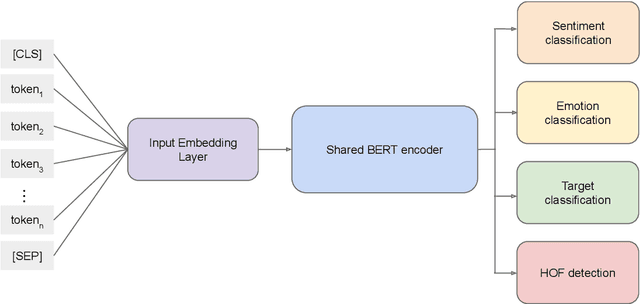
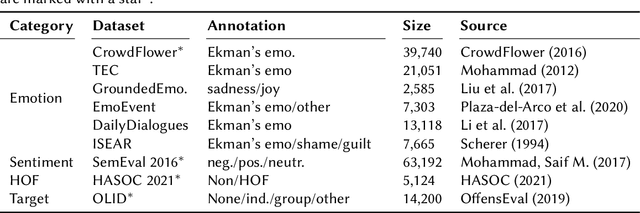
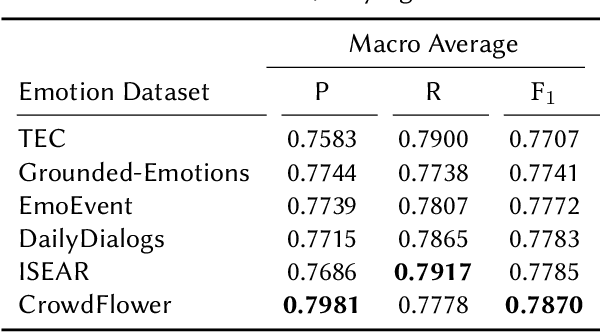
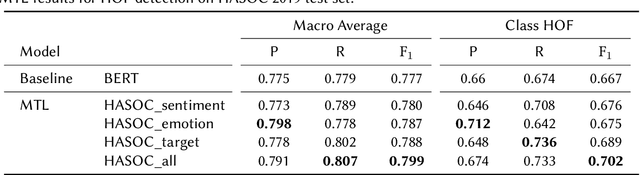
The recognition of hate speech and offensive language (HOF) is commonly formulated as a classification task to decide if a text contains HOF. We investigate whether HOF detection can profit by taking into account the relationships between HOF and similar concepts: (a) HOF is related to sentiment analysis because hate speech is typically a negative statement and expresses a negative opinion; (b) it is related to emotion analysis, as expressed hate points to the author experiencing (or pretending to experience) anger while the addressees experience (or are intended to experience) fear. (c) Finally, one constituting element of HOF is the mention of a targeted person or group. On this basis, we hypothesize that HOF detection shows improvements when being modeled jointly with these concepts, in a multi-task learning setup. We base our experiments on existing data sets for each of these concepts (sentiment, emotion, target of HOF) and evaluate our models as a participant (as team IMS-SINAI) in the HASOC FIRE 2021 English Subtask 1A. Based on model-selection experiments in which we consider multiple available resources and submissions to the shared task, we find that the combination of the CrowdFlower emotion corpus, the SemEval 2016 Sentiment Corpus, and the OffensEval 2019 target detection data leads to an F1 =.79 in a multi-head multi-task learning model based on BERT, in comparison to .7895 of plain BERT. On the HASOC 2019 test data, this result is more substantial with an increase by 2pp in F1 and a considerable increase in recall. Across both data sets (2019, 2021), the recall is particularly increased for the class of HOF (6pp for the 2019 data and 3pp for the 2021 data), showing that MTL with emotion, sentiment, and target identification is an appropriate approach for early warning systems that might be deployed in social media platforms.