 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Spanish and English Phoneme Recognition by Training on Simulated Classroom Audio Recordings of Collaborative Learning Environments
Feb 21, 2022



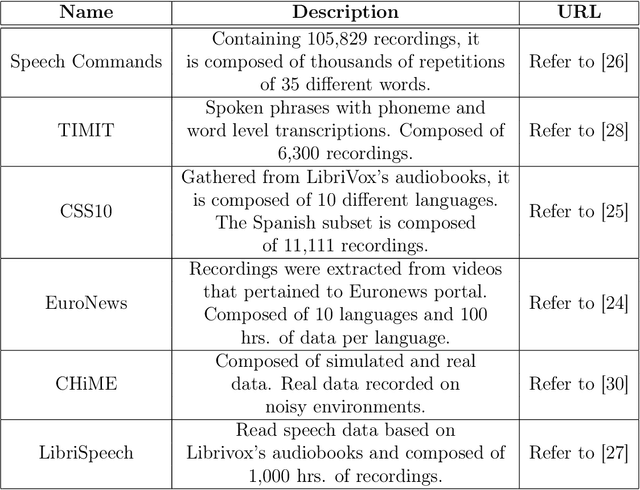
Audio recordings of collaborative learning environments contain a constant presence of cross-talk and background noise. Dynamic speech recognition between Spanish and English is required in these environments. To eliminate the standard requirement of large-scale ground truth, the thesis develops a simulated dataset by transforming audio transcriptions into phonemes and using 3D speaker geometry and data augmentation to generate an acoustic simulation of Spanish and English speech. The thesis develops a low-complexity neural network for recognizing Spanish and English phonemes (available at github.com/muelitas/keywordRec). When trained on 41 English phonemes, 0.099 PER is achieved on Speech Commands. When trained on 36 Spanish phonemes and tested on real recordings of collaborative learning environments, a 0.7208 LER is achieved. Slightly better than Google's Speech-to-text 0.7272 LER, which used anywhere from 15 to 1,635 times more parameters and trained on 300 to 27,500 hours of real data as opposed to 13 hours of simulated audios.
Consistent Transcription and Translation of Speech
Aug 28, 2020

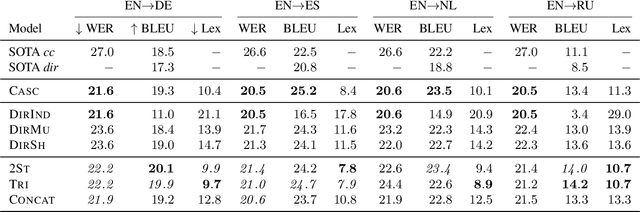
The conventional paradigm in speech translation starts with a speech recognition step to generate transcripts, followed by a translation step with the automatic transcripts as input. To address various shortcomings of this paradigm, recent work explores end-to-end trainable direct models that translate without transcribing. However, transcripts can be an indispensable output in practical applications, which often display transcripts alongside the translations to users. We make this common requirement explicit and explore the task of jointly transcribing and translating speech. While high accuracy of transcript and translation are crucial, even highly accurate systems can suffer from inconsistencies between both outputs that degrade the user experience. We introduce a methodology to evaluate consistency and compare several modeling approaches, including the traditional cascaded approach and end-to-end models. We find that direct models are poorly suited to the joint transcription/translation task, but that end-to-end models that feature a coupled inference procedure are able to achieve strong consistency. We further introduce simple techniques for directly optimizing for consistency, and analyze the resulting trade-offs between consistency, transcription accuracy, and translation accuracy.
End-to-End Learning of Speech 2D Feature-Trajectory for Prosthetic Hands
Sep 22, 2020



Speech is one of the most common forms of communication in humans. Speech commands are essential parts of multimodal controlling of prosthetic hands. In the past decades, researchers used automatic speech recognition systems for controlling prosthetic hands by using speech commands. Automatic speech recognition systems learn how to map human speech to text. Then, they used natural language processing or a look-up table to map the estimated text to a trajectory. However, the performance of conventional speech-controlled prosthetic hands is still unsatisfactory. Recent advancements in general-purpose graphics processing units (GPGPUs) enable intelligent devices to run deep neural networks in real-time. Thus, architectures of intelligent systems have rapidly transformed from the paradigm of composite subsystems optimization to the paradigm of end-to-end optimization. In this paper, we propose an end-to-end convolutional neural network (CNN) that maps speech 2D features directly to trajectories for prosthetic hands. The proposed convolutional neural network is lightweight, and thus it runs in real-time in an embedded GPGPU. The proposed method can use any type of speech 2D feature that has local correlations in each dimension such as spectrogram, MFCC, or PNCC. We omit the speech to text step in controlling the prosthetic hand in this paper. The network is written in Python with Keras library that has a TensorFlow backend. We optimized the CNN for NVIDIA Jetson TX2 developer kit. Our experiment on this CNN demonstrates a root-mean-square error of 0.119 and 20ms running time to produce trajectory outputs corresponding to the voice input data. To achieve a lower error in real-time, we can optimize a similar CNN for a more powerful embedded GPGPU such as NVIDIA AGX Xavier.
STEPs-RL: Speech-Text Entanglement for Phonetically Sound Representation Learning
Nov 23, 2020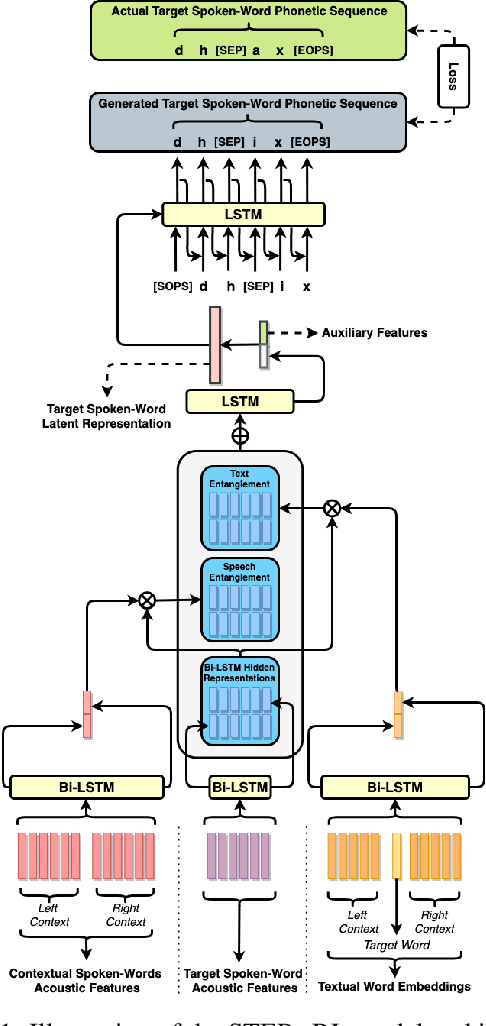
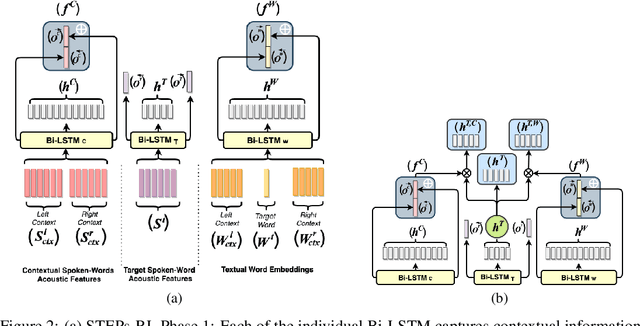

In this paper, we present a novel multi-modal deep neural network architecture that uses speech and text entanglement for learning phonetically sound spoken-word representations. STEPs-RL is trained in a supervised manner to predict the phonetic sequence of a target spoken-word using its contextual spoken word's speech and text, such that the model encodes its meaningful latent representations. Unlike existing work, we have used text along with speech for auditory representation learning to capture semantical and syntactical information along with the acoustic and temporal information. The latent representations produced by our model were not only able to predict the target phonetic sequences with an accuracy of 89.47% but were also able to achieve competitive results to textual word representation models, Word2Vec & FastText (trained on textual transcripts), when evaluated on four widely used word similarity benchmark datasets. In addition, investigation of the generated vector space also demonstrated the capability of the proposed model to capture the phonetic structure of the spoken-words. To the best of our knowledge, none of the existing works use speech and text entanglement for learning spoken-word representation, which makes this work first of its kind.
Deep Variational Generative Models for Audio-visual Speech Separation
Aug 17, 2020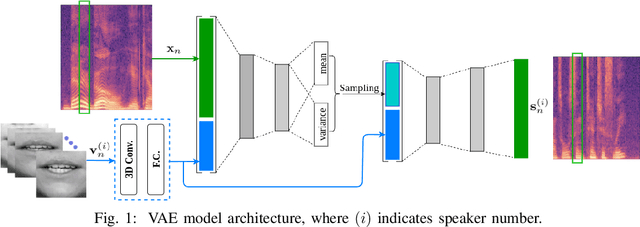
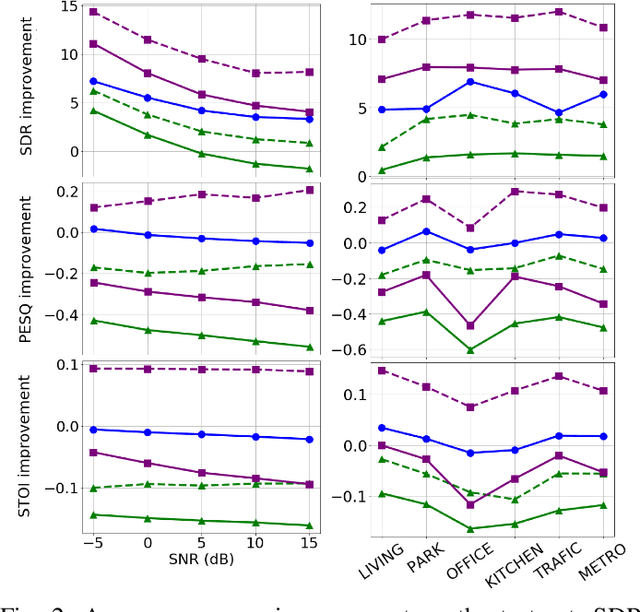
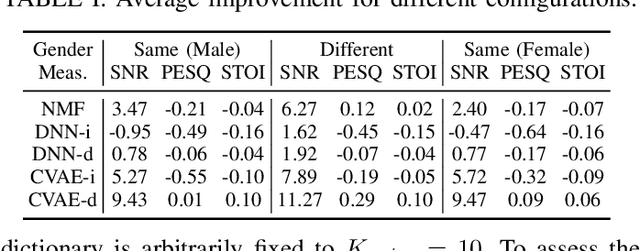
In this paper, we are interested in audio-visual speech separation given a single-channel audio recording as well as visual information (lips movements) associated with each speaker. We propose an unsupervised technique based on audio-visual generative modeling of clean speech. More specifically, during training, a latent variable generative model is learned from clean speech spectrograms using a variational auto-encoder (VAE). To better utilize the visual information, the posteriors of the latent variables are inferred from mixed speech (instead of clean speech) as well as the visual data. The visual modality also serves as a prior for latent variables, through a visual network. At test time, the learned generative model (both for speaker-independent and speaker-dependent scenarios) is combined with an unsupervised non-negative matrix factorization (NMF) variance model for background noise. All the latent variables and noise parameters are then estimated by a Monte Carlo expectation-maximization algorithm. Our experiments show that the proposed unsupervised VAE-based method yields better separation performance than NMF-based approaches as well as a supervised deep learning-based technique.
Relaxed Attention: A Simple Method to Boost Performance of End-to-End Automatic Speech Recognition
Jul 02, 2021
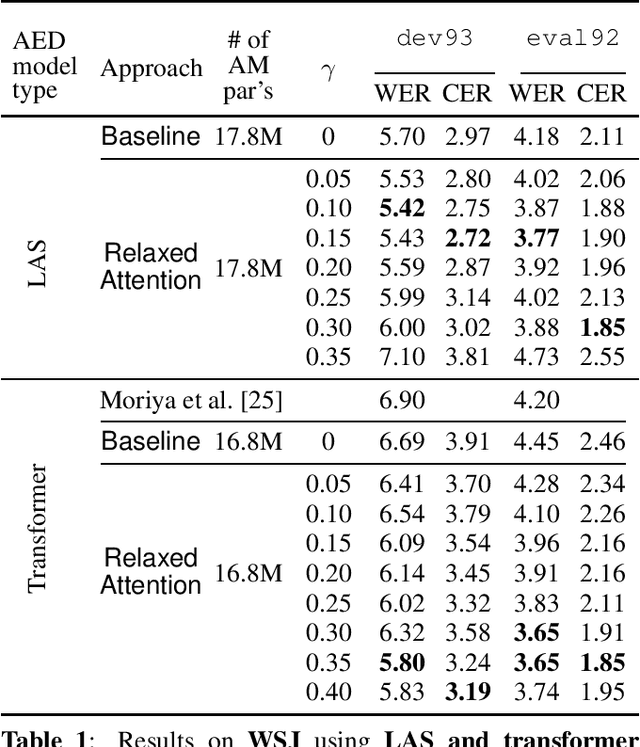
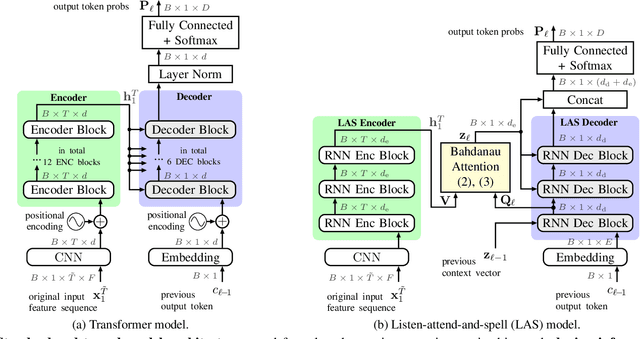
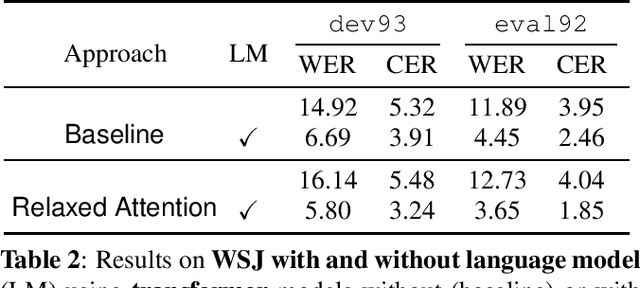
Recently, attention-based encoder-decoder (AED) models have shown high performance for end-to-end automatic speech recognition (ASR) across several tasks. Addressing overconfidence in such models, in this paper we introduce the concept of relaxed attention, which is a simple gradual injection of a uniform distribution to the encoder-decoder attention weights during training that is easily implemented with two lines of code. We investigate the effect of relaxed attention across different AED model architectures and two prominent ASR tasks, Wall Street Journal (WSJ) and Librispeech. We found that transformers trained with relaxed attention outperform the standard baseline models consistently during decoding with external language models. On WSJ, we set a new benchmark for transformer-based end-to-end speech recognition with a word error rate of 3.65%, outperforming state of the art (4.20%) by 13.1% relative, while introducing only a single hyperparameter. Upon acceptance, models will be published on github.
Three-Module Modeling For End-to-End Spoken Language Understanding Using Pre-trained DNN-HMM-Based Acoustic-Phonetic Model
Apr 07, 2022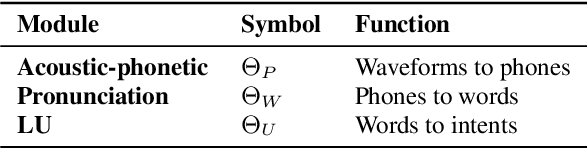
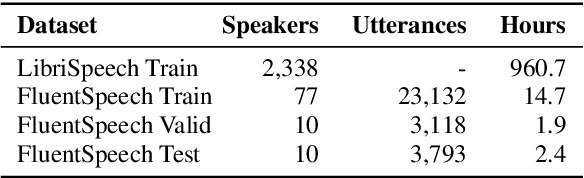
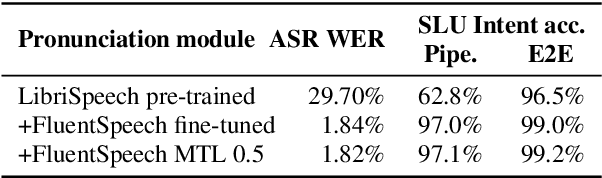

In spoken language understanding (SLU), what the user says is converted to his/her intent. Recent work on end-to-end SLU has shown that accuracy can be improved via pre-training approaches. We revisit ideas presented by Lugosch et al. using speech pre-training and three-module modeling; however, to ease construction of the end-to-end SLU model, we use as our phoneme module an open-source acoustic-phonetic model from a DNN-HMM hybrid automatic speech recognition (ASR) system instead of training one from scratch. Hence we fine-tune on speech only for the word module, and we apply multi-target learning (MTL) on the word and intent modules to jointly optimize SLU performance. MTL yields a relative reduction of 40% in intent-classification error rates (from 1.0% to 0.6%). Note that our three-module model is a streaming method. The final outcome of the proposed three-module modeling approach yields an intent accuracy of 99.4% on FluentSpeech, an intent error rate reduction of 50% compared to that of Lugosch et al. Although we focus on real-time streaming methods, we also list non-streaming methods for comparison.
Unsupervised Word Segmentation using K Nearest Neighbors
Apr 27, 2022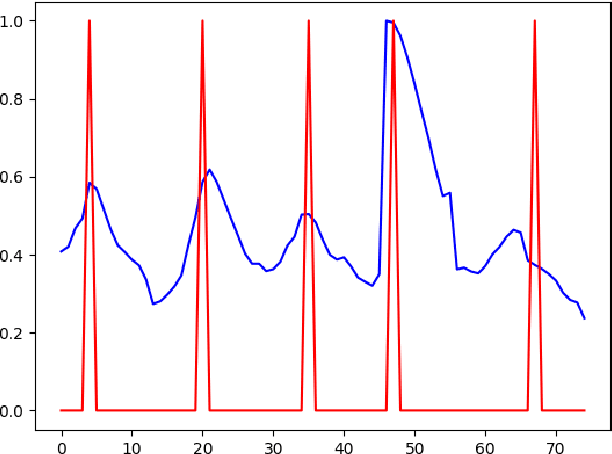
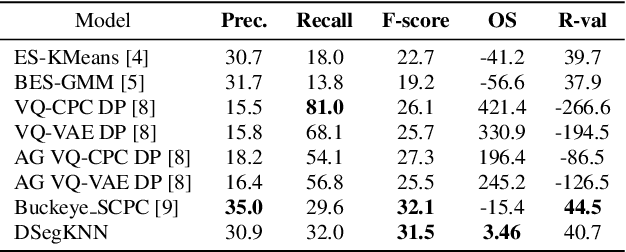
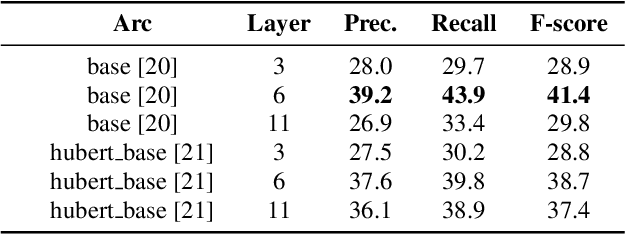
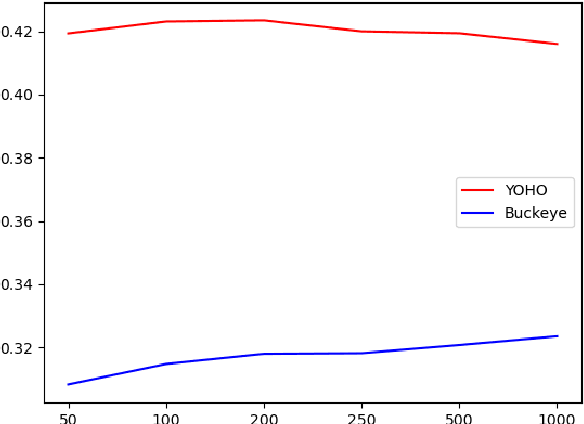
In this paper, we propose an unsupervised kNN-based approach for word segmentation in speech utterances. Our method relies on self-supervised pre-trained speech representations, and compares each audio segment of a given utterance to its K nearest neighbors within the training set. Our main assumption is that a segment containing more than one word would occur less often than a segment containing a single word. Our method does not require phoneme discovery and is able to operate directly on pre-trained audio representations. This is in contrast to current methods that use a two-stage approach; first detecting the phonemes in the utterance and then detecting word-boundaries according to statistics calculated on phoneme patterns. Experiments on two datasets demonstrate improved results over previous single-stage methods and competitive results on state-of-the-art two-stage methods.
A Large-scale Dataset for Hate Speech Detection on Vietnamese Social Media Texts
Apr 05, 2021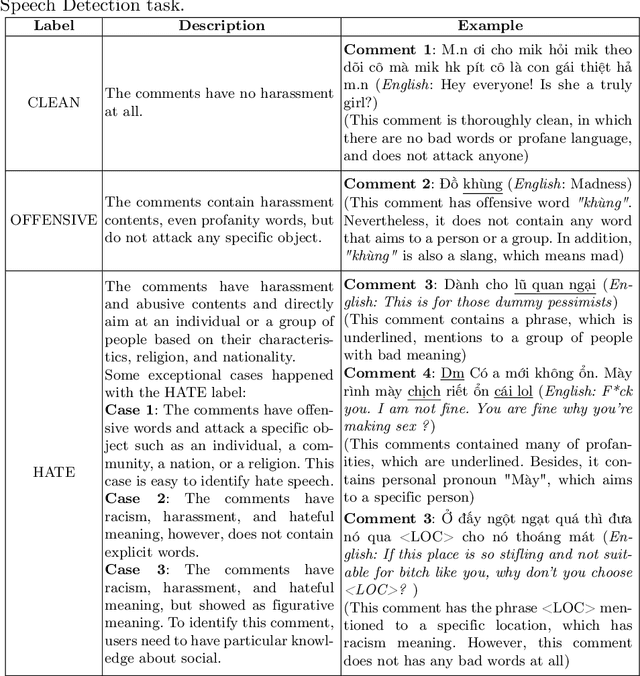
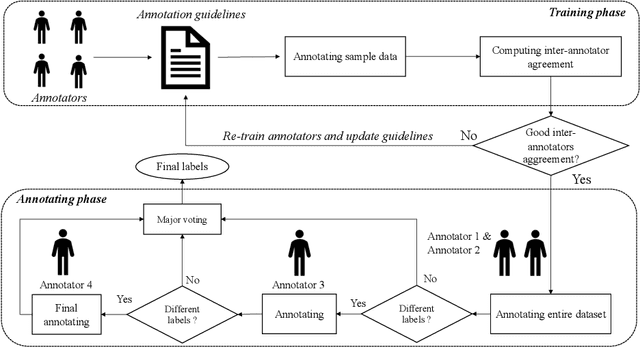
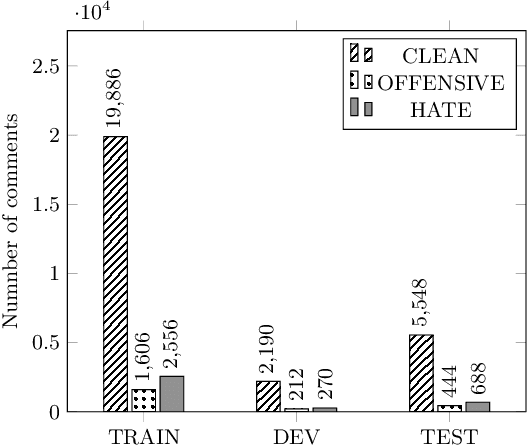

In recent years, Vietnam witnesses the mass development of social network users on different social platforms such as Facebook, Youtube, Instagram, and Tiktok. On social medias, hate speech has become a critical problem for social network users. To solve this problem, we introduce the ViHSD - a human-annotated dataset for automatically detecting hate speech on the social network. This dataset contains over 30,000 comments, each comment in the dataset has one of three labels: CLEAN, OFFENSIVE, or HATE. Besides, we introduce the data creation process for annotating and evaluating the quality of the dataset. Finally, we evaluated the dataset by deep learning models and transformer models.
WOLONet: Wave Outlooker for Efficient and High Fidelity Speech Synthesis
Jun 20, 2022
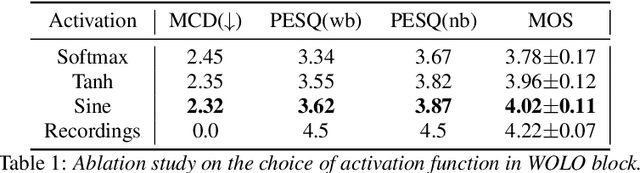
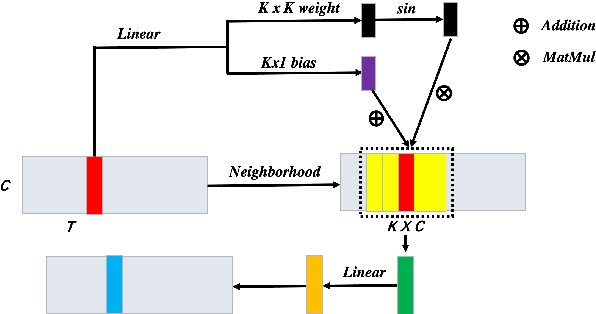
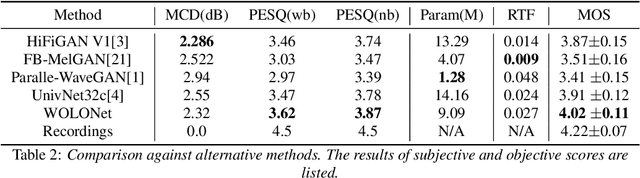
Recently, GAN-based neural vocoders such as Parallel WaveGAN, MelGAN, HiFiGAN, and UnivNet have become popular due to their lightweight and parallel structure, resulting in a real-time synthesized waveform with high fidelity, even on a CPU. HiFiGAN and UnivNet are two SOTA vocoders. Despite their high quality, there is still room for improvement. In this paper, motivated by the structure of Vision Outlooker from computer vision, we adopt a similar idea and propose an effective and lightweight neural vocoder called WOLONet. In this network, we develop a novel lightweight block that uses a location-variable, channel-independent, and depthwise dynamic convolutional kernel with sinusoidally activated dynamic kernel weights. To demonstrate the effectiveness and generalizability of our method, we perform an ablation study to verify our novel design and make a subjective and objective comparison with typical GAN-based vocoders. The results show that our WOLONet achieves the best generation quality while requiring fewer parameters than the two neural SOTA vocoders, HiFiGAN and UnivNet.