 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Phase Aware Speech Enhancement using Realisation of Complex-valued LSTM
Oct 27, 2020
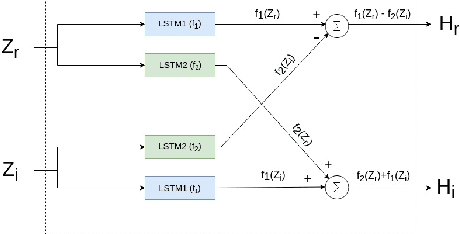

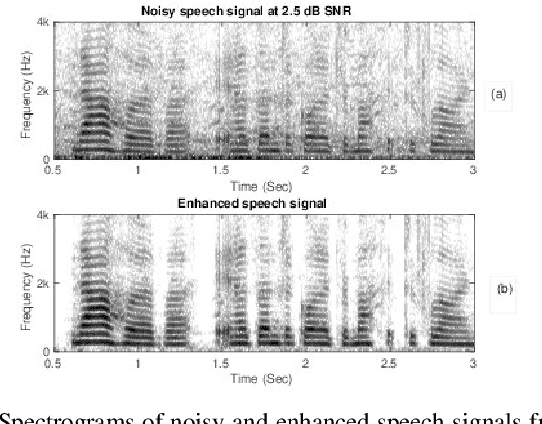
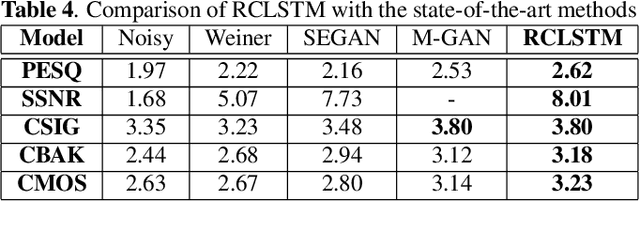
Most of the deep learning based speech enhancement (SE) methods rely on estimating the magnitude spectrum of the clean speech signal from the observed noisy speech signal, either by magnitude spectral masking or regression. These methods reuse the noisy phase while synthesizing the time-domain waveform from the estimated magnitude spectrum. However, there have been recent works highlighting the importance of phase in SE. There was an attempt to estimate the complex ratio mask taking phase into account using complex-valued feed-forward neural network (FFNN). But FFNNs cannot capture the sequential information essential for phase estimation. In this work, we propose a realisation of complex-valued long short-term memory (RCLSTM) network to estimate the complex ratio mask (CRM) using sequential information along time. The proposed RCLSTM is designed to process the complex-valued sequences using complex arithmetic, and hence it preserves the dependencies between the real and imaginary parts of CRM and thereby the phase. The proposed method is evaluated on the noisy speech mixtures formed from the Voice-Bank corpus and DEMAND database. When compared to real value based masking methods, the proposed RCLSTM improves over them in several objective measures including perceptual evaluation of speech quality (PESQ), in which it improves by over 4.3%
Generalized RNN beamformer for target speech separation
Jan 04, 2021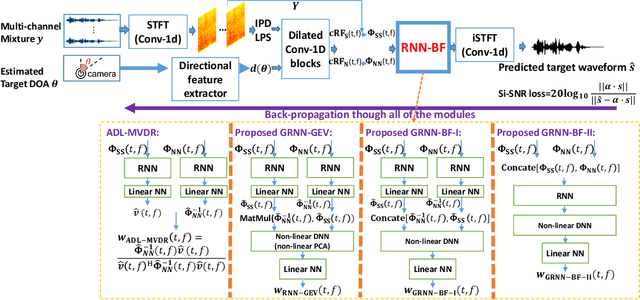
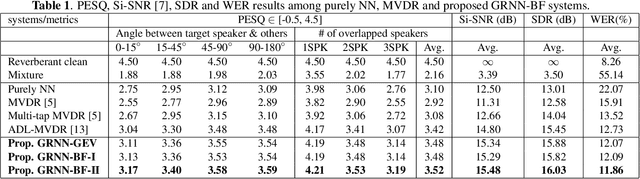
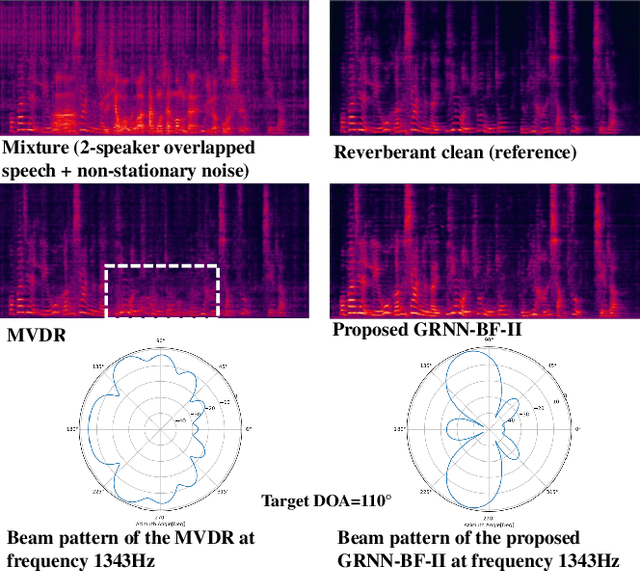
Recently we proposed an all-deep-learning minimum variance distortionless response (ADL-MVDR) method where the unstable matrix inverse and principal component analysis (PCA) operations in the MVDR were replaced by recurrent neural networks (RNNs). However, it is not clear whether the success of the ADL-MVDR is owed to the calculated covariance matrices or following the MVDR formula. In this work, we demonstrate the importance of the calculated covariance matrices and propose three types of generalized RNN beamformers (GRNN-BFs) where the beamforming solution is beyond the MVDR and optimal. The GRNN-BFs could predict the frame-wise beamforming weights by leveraging on the temporal modeling capability of RNNs. The proposed GRNN-BF method obtains better performance than the state-of-the-art ADL-MVDR and the traditional mask-based MVDR methods in terms of speech quality (PESQ), speech-to-noise ratio (SNR), and word error rate (WER).
ATCSpeechNet: A multilingual end-to-end speech recognition framework for air traffic control systems
Feb 17, 2021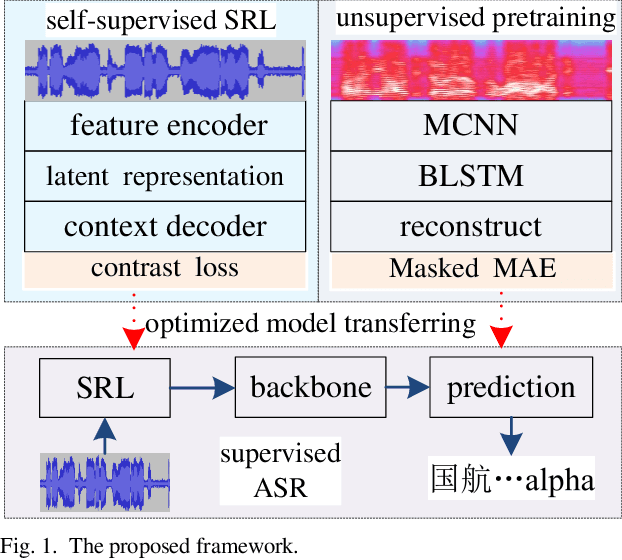
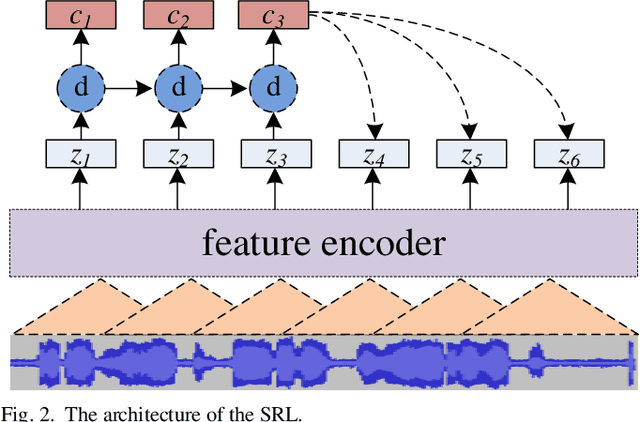
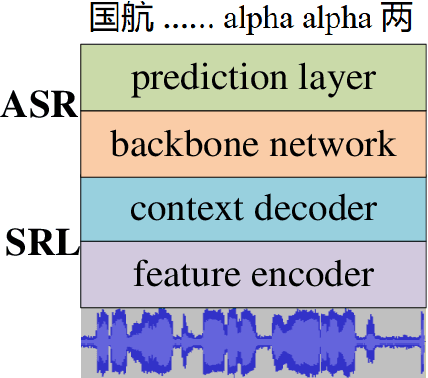
In this paper, a multilingual end-to-end framework, called as ATCSpeechNet, is proposed to tackle the issue of translating communication speech into human-readable text in air traffic control (ATC) systems. In the proposed framework, we focus on integrating the multilingual automatic speech recognition (ASR) into one model, in which an end-to-end paradigm is developed to convert speech waveform into text directly, without any feature engineering or lexicon. In order to make up for the deficiency of the handcrafted feature engineering caused by ATC challenges, a speech representation learning (SRL) network is proposed to capture robust and discriminative speech representations from the raw wave. The self-supervised training strategy is adopted to optimize the SRL network from unlabeled data, and further to predict the speech features, i.e., wave-to-feature. An end-to-end architecture is improved to complete the ASR task, in which a grapheme-based modeling unit is applied to address the multilingual ASR issue. Facing the problem of small transcribed samples in the ATC domain, an unsupervised approach with mask prediction is applied to pre-train the backbone network of the ASR model on unlabeled data by a feature-to-feature process. Finally, by integrating the SRL with ASR, an end-to-end multilingual ASR framework is formulated in a supervised manner, which is able to translate the raw wave into text in one model, i.e., wave-to-text. Experimental results on the ATCSpeech corpus demonstrate that the proposed approach achieves a high performance with a very small labeled corpus and less resource consumption, only 4.20% label error rate on the 58-hour transcribed corpus. Compared to the baseline model, the proposed approach obtains over 100% relative performance improvement which can be further enhanced with the increasing of the size of the transcribed samples.
Unsupervised Speech Decomposition via Triple Information Bottleneck
Apr 29, 2020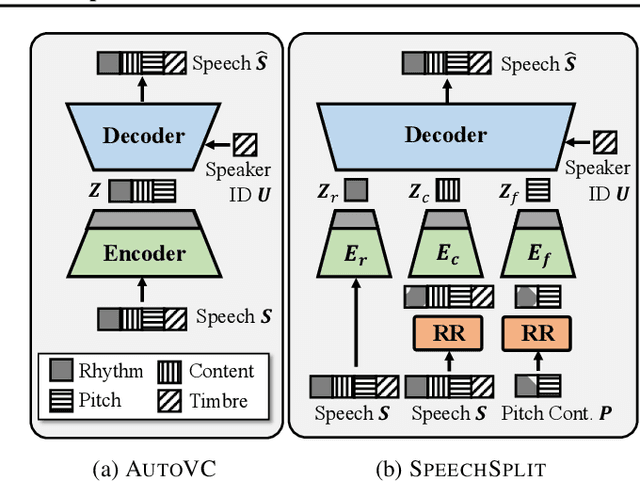
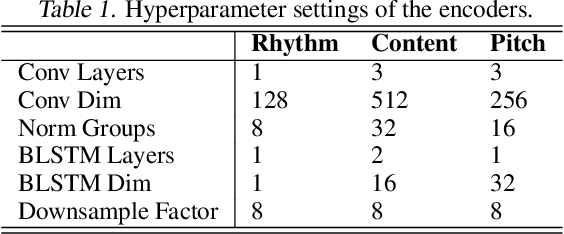

Speech information can be roughly decomposed into four components: language content, timbre, pitch, and rhythm. Obtaining disentangled representations of these components is useful in many speech analysis and generation applications. Recently, state-of-the-art voice conversion systems have led to speech representations that can disentangle speaker-dependent and independent information. However, these systems can only disentangle timbre, while information about pitch, rhythm and content is still mixed together. Further disentangling the remaining speech components is an under-determined problem in the absence of explicit annotations for each component, which are difficult and expensive to obtain. In this paper, we propose SpeechSplit, which can blindly decompose speech into its four components by introducing three carefully designed information bottlenecks. SpeechSplit is among the first algorithms that can separately perform style transfer on timbre, pitch and rhythm without text labels.
The Geometry of Multilingual Language Model Representations
May 22, 2022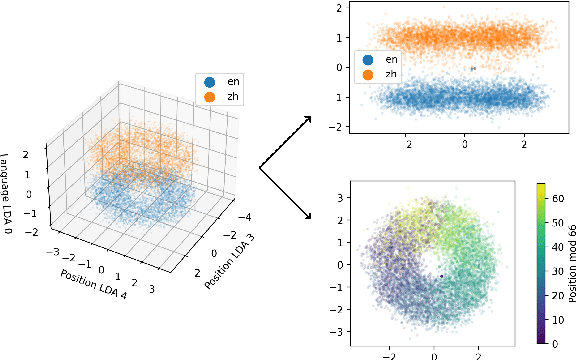
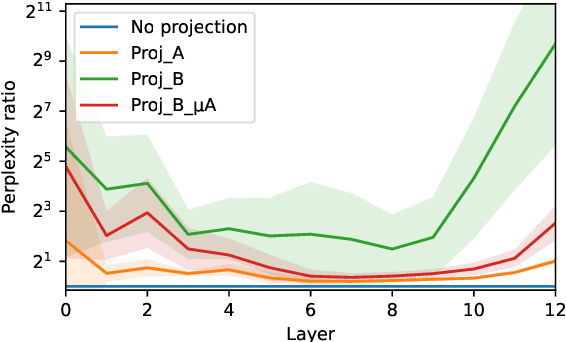
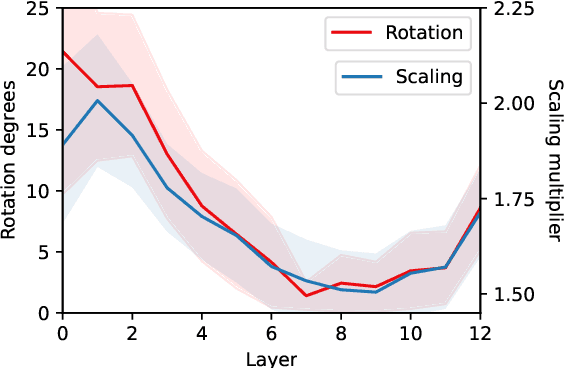
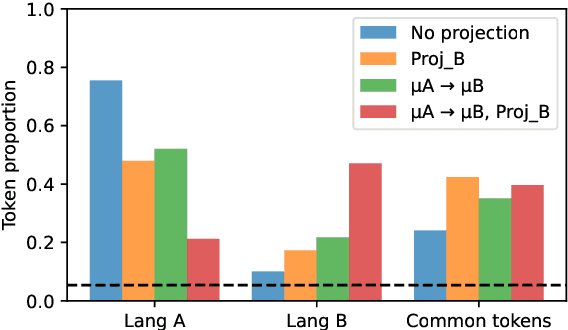
We assess how multilingual language models maintain a shared multilingual representation space while still encoding language-sensitive information in each language. Using XLM-R as a case study, we show that languages occupy similar linear subspaces after mean-centering, evaluated based on causal effects on language modeling performance and direct comparisons between subspaces for 88 languages. The subspace means differ along language-sensitive axes that are relatively stable throughout middle layers, and these axes encode information such as token vocabularies. Shifting representations by language means is sufficient to induce token predictions in different languages. However, we also identify stable language-neutral axes that encode information such as token positions and part-of-speech. We visualize representations projected onto language-sensitive and language-neutral axes, identifying language family and part-of-speech clusters, along with spirals, toruses, and curves representing token position information. These results demonstrate that multilingual language models encode information along orthogonal language-sensitive and language-neutral axes, allowing the models to extract a variety of features for downstream tasks and cross-lingual transfer learning.
Perceptimatic: A human speech perception benchmark for unsupervised subword modelling
Oct 12, 2020
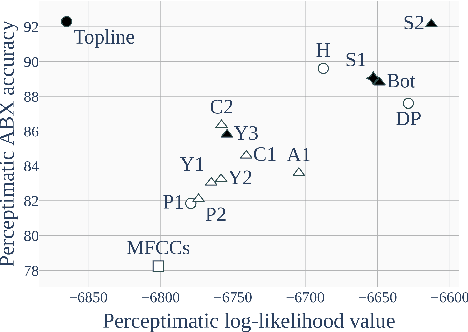
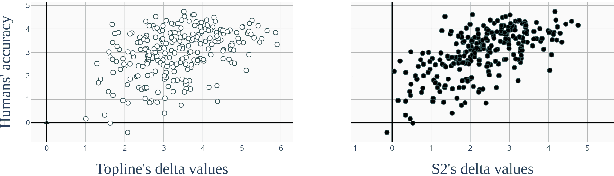
In this paper, we present a data set and methods to compare speech processing models and human behaviour on a phone discrimination task. We provide Perceptimatic, an open data set which consists of French and English speech stimuli, as well as the results of 91 English- and 93 French-speaking listeners. The stimuli test a wide range of French and English contrasts, and are extracted directly from corpora of natural running read speech, used for the 2017 Zero Resource Speech Challenge. We provide a method to compare humans' perceptual space with models' representational space, and we apply it to models previously submitted to the Challenge. We show that, unlike unsupervised models and supervised multilingual models, a standard supervised monolingual HMM-GMM phone recognition system, while good at discriminating phones, yields a representational space very different from that of human native listeners.
Text-to-Speech Synthesis Techniques for MIDI-to-Audio Synthesis
Apr 28, 2021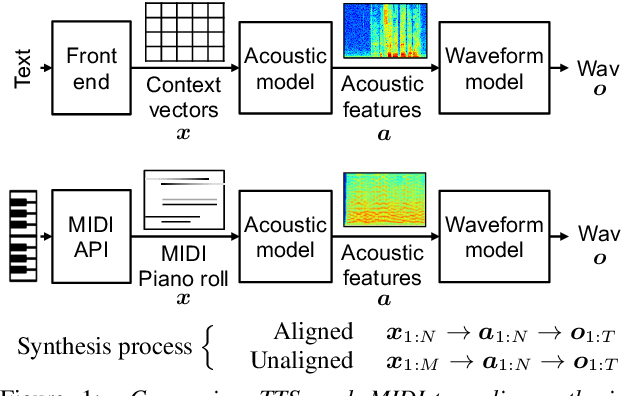
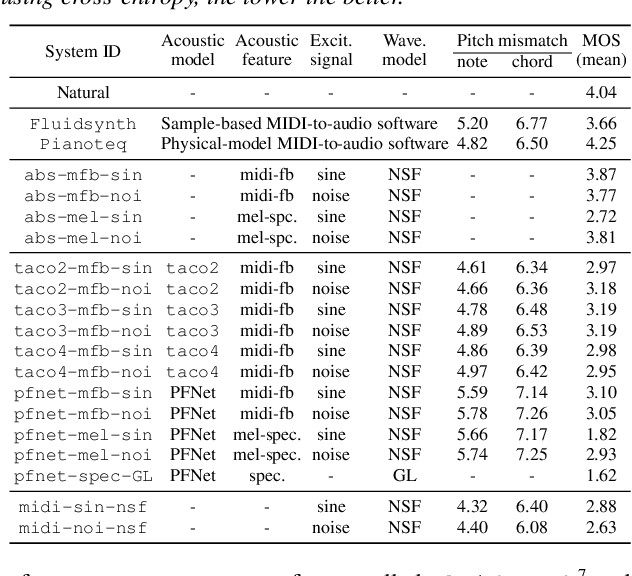
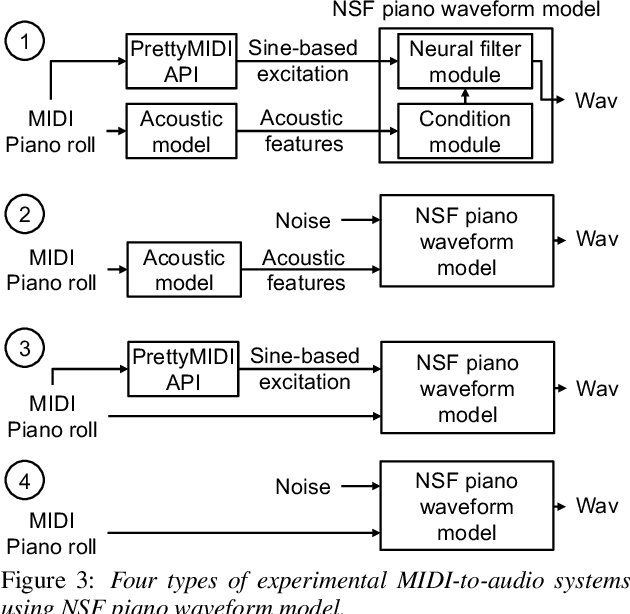
Speech synthesis and music audio generation from symbolic input differ in many aspects but share some similarities. In this study, we investigate how text-to-speech synthesis techniques can be used for piano MIDI-to-audio synthesis tasks. Our investigation includes Tacotron and neural source-filter waveform models as the basic components, with which we build MIDI-to-audio synthesis systems in similar ways to TTS frameworks. We also include reference systems using conventional sound modeling techniques such as sample-based and physical-modeling-based methods. The subjective experimental results demonstrate that the investigated TTS components can be applied to piano MIDI-to-audio synthesis with minor modifications. The results also reveal the performance bottleneck -- while the waveform model can synthesize high quality piano sound given natural acoustic features, the conversion from MIDI to acoustic features is challenging. The full MIDI-to-audio synthesis system is still inferior to the sample-based or physical-modeling-based approaches, but we encourage TTS researchers to test their TTS models for this new task and improve the performance.
Using Affect as a Communication Modality to Improve Human-Robot Communication in Robot-Assisted Search and Rescue Scenarios
Aug 20, 2022
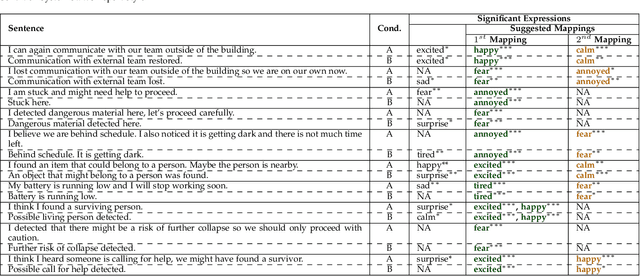

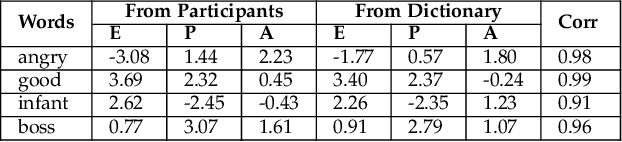
Emotions can provide a natural communication modality to complement the existing multi-modal capabilities of social robots, such as text and speech, in many domains. We conducted three online studies with 112, 223, and 151 participants to investigate the benefits of using emotions as a communication modality for Search And Rescue (SAR) robots. In the first experiment, we investigated the feasibility of conveying information related to SAR situations through robots' emotions, resulting in mappings from SAR situations to emotions. The second study used Affect Control Theory as an alternative method for deriving such mappings. This method is more flexible, e.g. allows for such mappings to be adjusted for different emotion sets and different robots. In the third experiment, we created affective expressions for an appearance-constrained outdoor field research robot using LEDs as an expressive channel. Using these affective expressions in a variety of simulated SAR situations, we evaluated the effect of these expressions on participants' (adopting the role of rescue workers) situational awareness. Our results and proposed methodologies provide (a) insights on how emotions could help conveying messages in the context of SAR, and (b) evidence on the effectiveness of adding emotions as a communication modality in a (simulated) SAR communication context.
Maximum Phase Modeling for Sparse Linear Prediction of Speech
Jun 07, 2020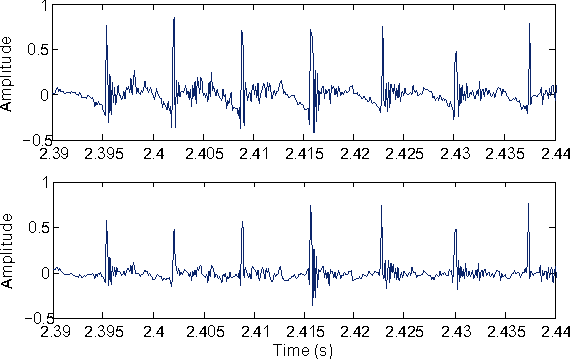
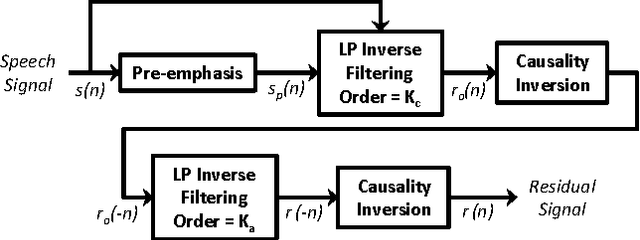
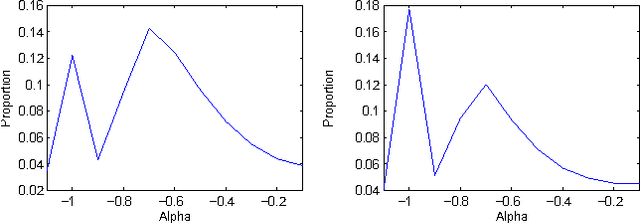
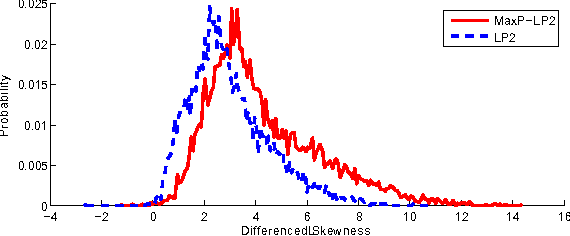
Linear prediction (LP) is an ubiquitous analysis method in speech processing. Various studies have focused on sparse LP algorithms by introducing sparsity constraints into the LP framework. Sparse LP has been shown to be effective in several issues related to speech modeling and coding. However, all existing approaches assume the speech signal to be minimum-phase. Because speech is known to be mixed-phase, the resulting residual signal contains a persistent maximum-phase component. The aim of this paper is to propose a novel technique which incorporates a modeling of the maximum-phase contribution of speech, and can be applied to any filter representation. The proposed method is shown to significantly increase the sparsity of the LP residual signal and to be effective in two illustrative applications: speech polarity detection and excitation modeling.
WeNet: Production First and Production Ready End-to-End Speech Recognition Toolkit
Feb 02, 2021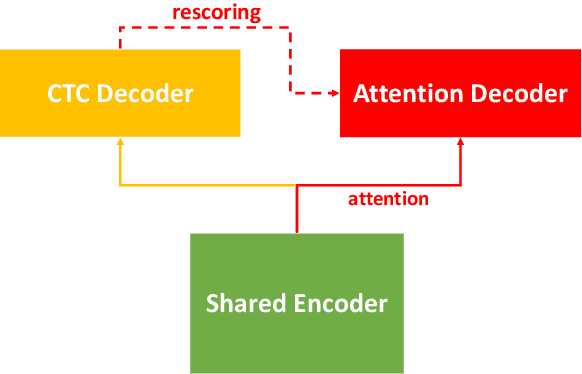
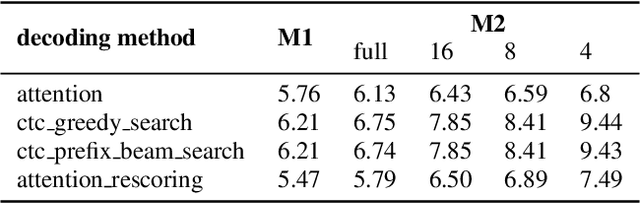
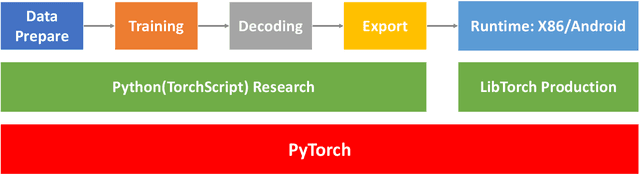
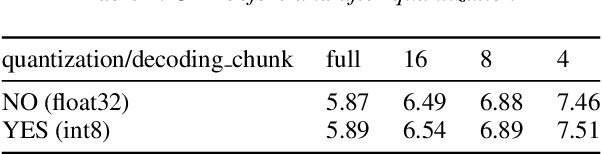
In this paper, we present a new open source, production first and production ready end-to-end (E2E) speech recognition toolkit named WeNet. The main motivation of WeNet is to close the gap between the research and the production of E2E speech recognition models. WeNet provides an efficient way to ship ASR applications in several real-world scenarios, which is the main difference and advantage to other open source E2E speech recognition toolkits. This paper introduces WeNet from three aspects, including model architecture, framework design and performance metrics. Our experiments on AISHELL-1 using WeNet, not only give a promising character error rate (CER) on a unified streaming and non-streaming two pass (U2) E2E model but also show reasonable RTF and latency, both of these aspects are favored for production adoption. The toolkit is publicly available at https://github.com/mobvoi/wenet.