 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
"Are you okay, honey?": Recognizing Emotions among Couples Managing Diabetes in Daily Life using Multimodal Real-World Smartwatch Data
Aug 22, 2022
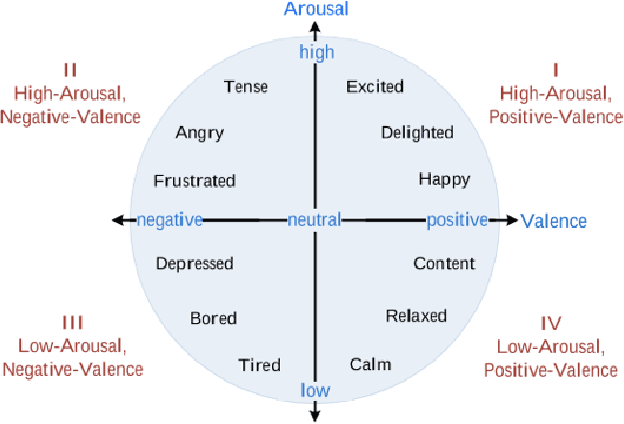
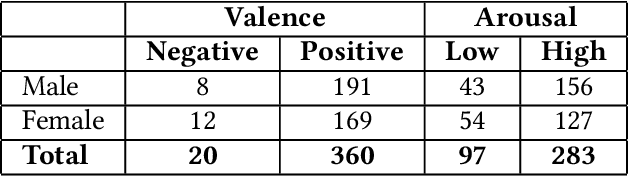
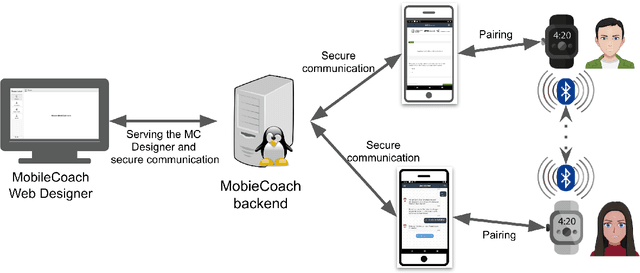
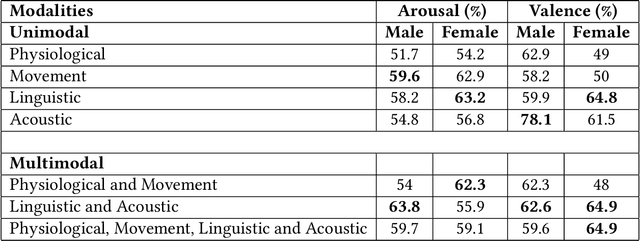
Couples generally manage chronic diseases together and the management takes an emotional toll on both patients and their romantic partners. Consequently, recognizing the emotions of each partner in daily life could provide an insight into their emotional well-being in chronic disease management. Currently, the process of assessing each partner's emotions is manual, time-intensive, and costly. Despite the existence of works on emotion recognition among couples, none of these works have used data collected from couples' interactions in daily life. In this work, we collected 85 hours (1,021 5-minute samples) of real-world multimodal smartwatch sensor data (speech, heart rate, accelerometer, and gyroscope) and self-reported emotion data (n=612) from 26 partners (13 couples) managing diabetes mellitus type 2 in daily life. We extracted physiological, movement, acoustic, and linguistic features, and trained machine learning models (support vector machine and random forest) to recognize each partner's self-reported emotions (valence and arousal). Our results from the best models (balanced accuracies of 63.8% and 78.1% for arousal and valence respectively) are better than chance and our prior work that also used data from German-speaking, Swiss-based couples, albeit, in the lab. This work contributes toward building automated emotion recognition systems that would eventually enable partners to monitor their emotions in daily life and enable the delivery of interventions to improve their emotional well-being.
Cross-Modal Transfer Learning for Multilingual Speech-to-Text Translation
Oct 24, 2020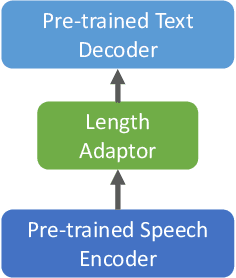
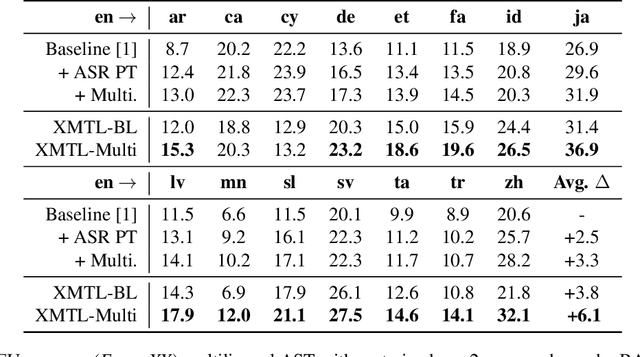
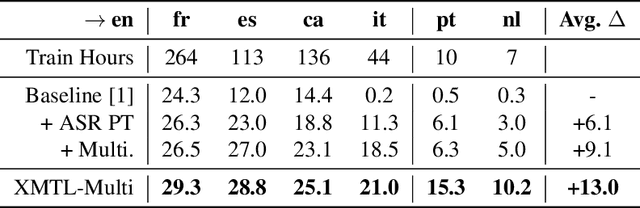

We propose an effective approach to utilize pretrained speech and text models to perform speech-to-text translation (ST). Our recipe to achieve cross-modal and cross-lingual transfer learning (XMTL) is simple and generalizable: using an adaptor module to bridge the modules pretrained in different modalities, and an efficient finetuning step which leverages the knowledge from pretrained modules yet making it work on a drastically different downstream task. With this approach, we built a multilingual speech-to-text translation model with pretrained audio encoder (wav2vec) and multilingual text decoder (mBART), which achieves new state-of-the-art on CoVoST 2 ST benchmark [1] for English into 15 languages as well as 6 Romance languages into English with on average +2.8 BLEU and +3.9 BLEU, respectively. On low-resource languages (with less than 10 hours training data), our approach significantly improves the quality of speech-to-text translation with +9.0 BLEU on Portuguese-English and +5.2 BLEU on Dutch-English.
Open Terminology Management and Sharing Toolkit for Federation of Terminology Databases
Jul 14, 2022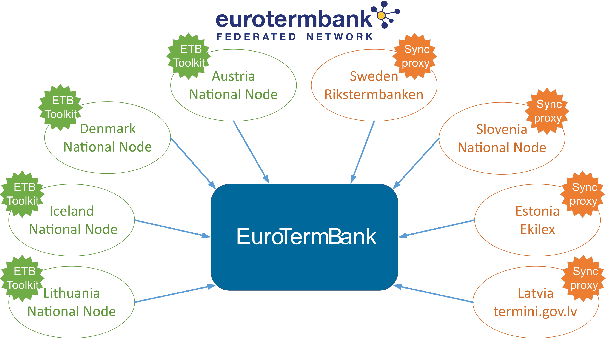
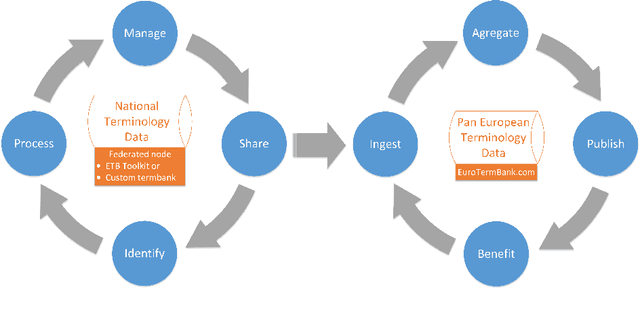
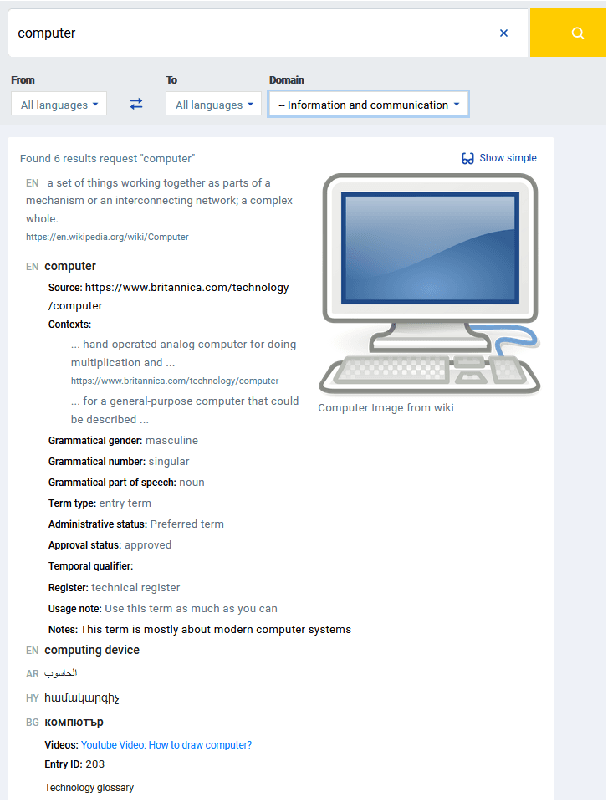
Consolidated access to current and reliable terms from different subject fields and languages is necessary for content creators and translators. Terminology is also needed in AI applications such as machine translation, speech recognition, information extraction, and other natural language processing tools. In this work, we facilitate standards-based sharing and management of terminology resources by providing an open terminology management solution - the EuroTermBank Toolkit. It allows organisations to manage and search their terms, create term collections, and share them within and outside the organisation by participating in the network of federated databases. The data curated in the federated databases are automatically shared with EuroTermBank, the largest multilingual terminology resource in Europe, allowing translators and language service providers as well as researchers and students to access terminology resources in their most current version.
Consistent Transcription and Translation of Speech
Aug 28, 2020
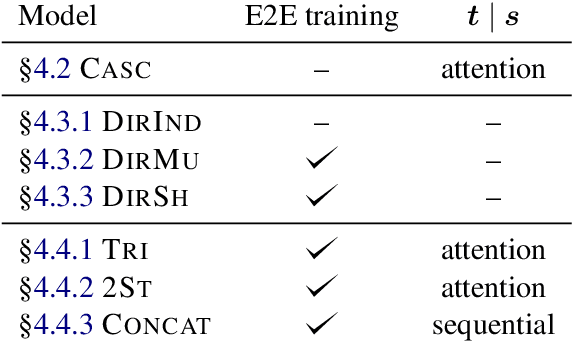

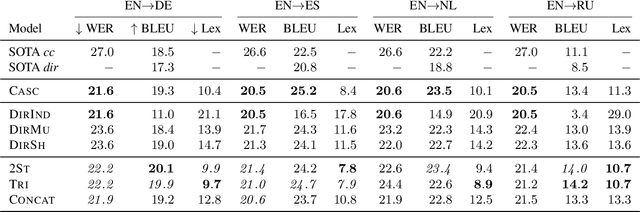
The conventional paradigm in speech translation starts with a speech recognition step to generate transcripts, followed by a translation step with the automatic transcripts as input. To address various shortcomings of this paradigm, recent work explores end-to-end trainable direct models that translate without transcribing. However, transcripts can be an indispensable output in practical applications, which often display transcripts alongside the translations to users. We make this common requirement explicit and explore the task of jointly transcribing and translating speech. While high accuracy of transcript and translation are crucial, even highly accurate systems can suffer from inconsistencies between both outputs that degrade the user experience. We introduce a methodology to evaluate consistency and compare several modeling approaches, including the traditional cascaded approach and end-to-end models. We find that direct models are poorly suited to the joint transcription/translation task, but that end-to-end models that feature a coupled inference procedure are able to achieve strong consistency. We further introduce simple techniques for directly optimizing for consistency, and analyze the resulting trade-offs between consistency, transcription accuracy, and translation accuracy.
A Model Compression Method with Matrix Product Operators for Speech Enhancement
Oct 10, 2020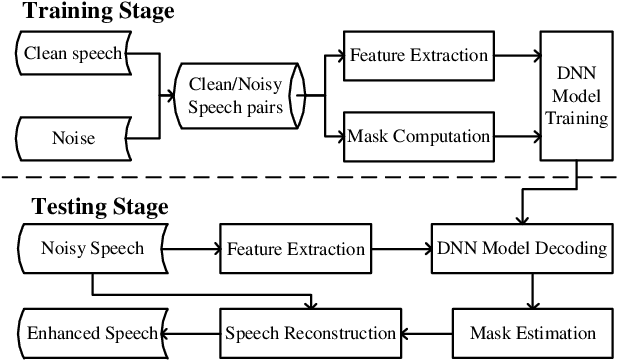

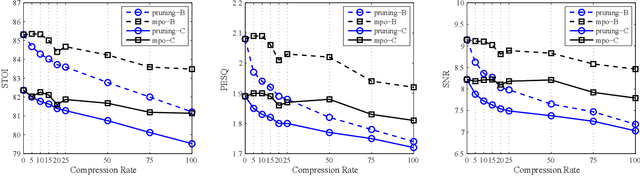
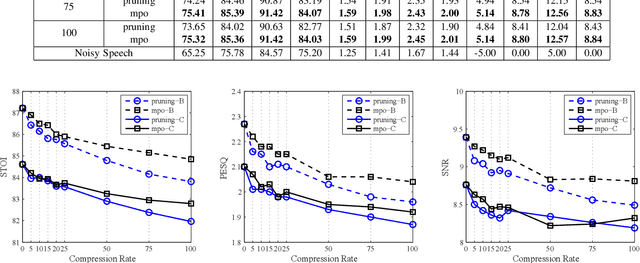
The deep neural network (DNN) based speech enhancement approaches have achieved promising performance. However, the number of parameters involved in these methods is usually enormous for the real applications of speech enhancement on the device with the limited resources. This seriously restricts the applications. To deal with this issue, model compression techniques are being widely studied. In this paper, we propose a model compression method based on matrix product operators (MPO) to substantially reduce the number of parameters in DNN models for speech enhancement. In this method, the weight matrices in the linear transformations of neural network model are replaced by the MPO decomposition format before training. In experiment, this process is applied to the causal neural network models, such as the feedforward multilayer perceptron (MLP) and long short-term memory (LSTM) models. Both MLP and LSTM models with/without compression are then utilized to estimate the ideal ratio mask for monaural speech enhancement. The experimental results show that our proposed MPO-based method outperforms the widely-used pruning method for speech enhancement under various compression rates, and further improvement can be achieved with respect to low compression rates. Our proposal provides an effective model compression method for speech enhancement, especially in cloud-free application.
* 11 pages, 6 figures, 7 tables
Conv-NILM-Net, a causal and multi-appliance model for energy source separation
Aug 03, 2022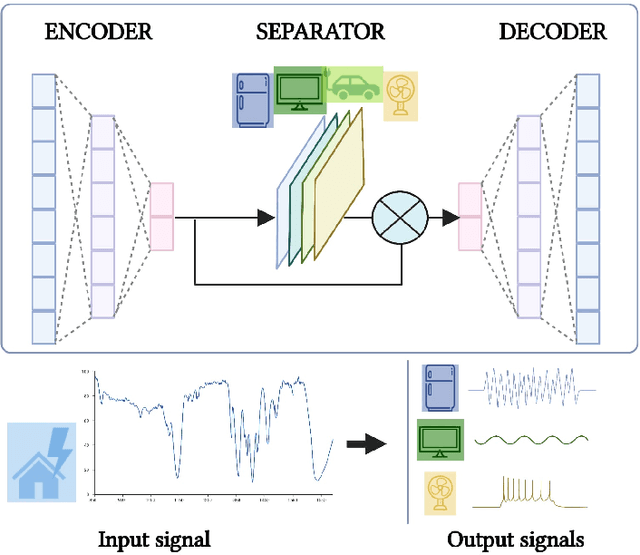

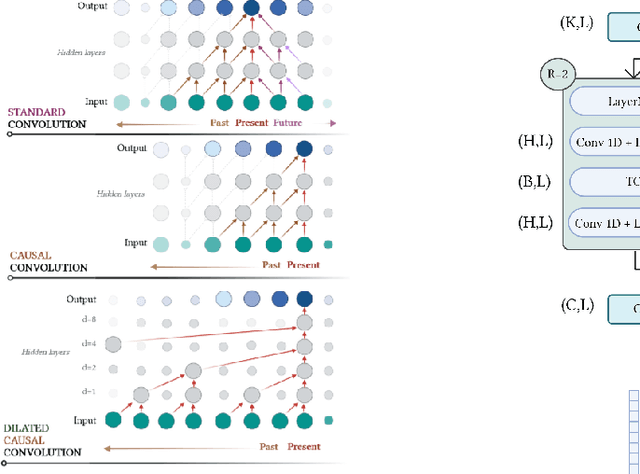
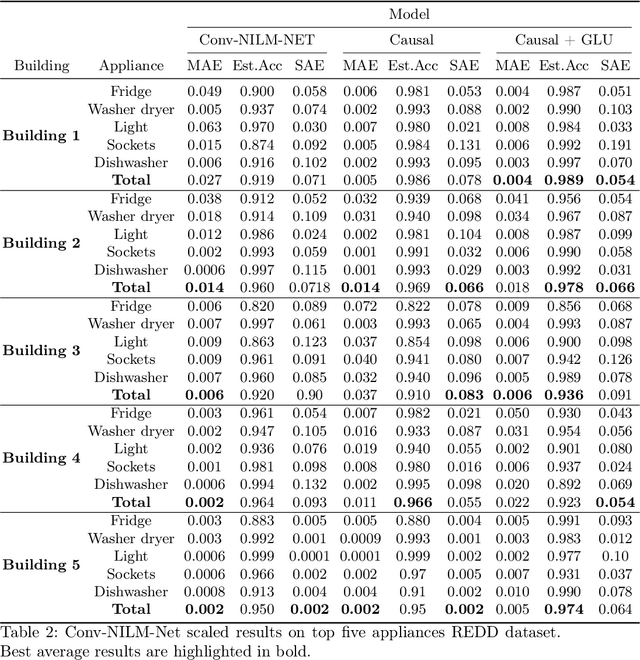
Non-Intrusive Load Monitoring (NILM) seeks to save energy by estimating individual appliance power usage from a single aggregate measurement. Deep neural networks have become increasingly popular in attempting to solve NILM problems. However most used models are used for Load Identification rather than online Source Separation. Among source separation models, most use a single-task learning approach in which a neural network is trained exclusively for each appliance. This strategy is computationally expensive and ignores the fact that multiple appliances can be active simultaneously and dependencies between them. The rest of models are not causal, which is important for real-time application. Inspired by Convtas-Net, a model for speech separation, we propose Conv-NILM-net, a fully convolutional framework for end-to-end NILM. Conv-NILM-net is a causal model for multi appliance source separation. Our model is tested on two real datasets REDD and UK-DALE and clearly outperforms the state of the art while keeping a significantly smaller size than the competing models.
End-to-End Learning of Speech 2D Feature-Trajectory for Prosthetic Hands
Sep 22, 2020



Speech is one of the most common forms of communication in humans. Speech commands are essential parts of multimodal controlling of prosthetic hands. In the past decades, researchers used automatic speech recognition systems for controlling prosthetic hands by using speech commands. Automatic speech recognition systems learn how to map human speech to text. Then, they used natural language processing or a look-up table to map the estimated text to a trajectory. However, the performance of conventional speech-controlled prosthetic hands is still unsatisfactory. Recent advancements in general-purpose graphics processing units (GPGPUs) enable intelligent devices to run deep neural networks in real-time. Thus, architectures of intelligent systems have rapidly transformed from the paradigm of composite subsystems optimization to the paradigm of end-to-end optimization. In this paper, we propose an end-to-end convolutional neural network (CNN) that maps speech 2D features directly to trajectories for prosthetic hands. The proposed convolutional neural network is lightweight, and thus it runs in real-time in an embedded GPGPU. The proposed method can use any type of speech 2D feature that has local correlations in each dimension such as spectrogram, MFCC, or PNCC. We omit the speech to text step in controlling the prosthetic hand in this paper. The network is written in Python with Keras library that has a TensorFlow backend. We optimized the CNN for NVIDIA Jetson TX2 developer kit. Our experiment on this CNN demonstrates a root-mean-square error of 0.119 and 20ms running time to produce trajectory outputs corresponding to the voice input data. To achieve a lower error in real-time, we can optimize a similar CNN for a more powerful embedded GPGPU such as NVIDIA AGX Xavier.
Real-time Monaural Speech Enhancement With Short-time Discrete Cosine Transform
Feb 09, 2021

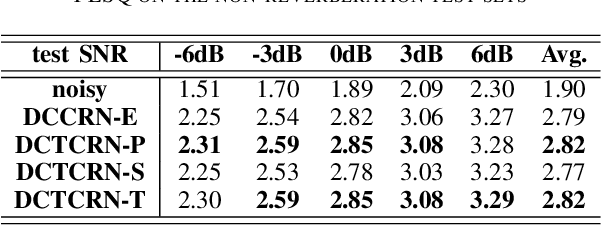
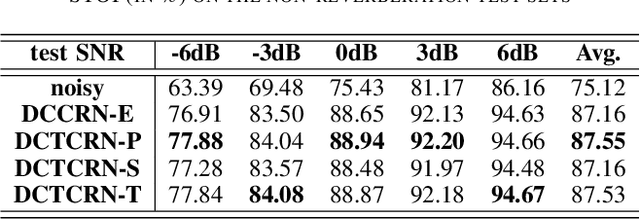
Speech enhancement algorithms based on deep learning have been improved in terms of speech intelligibility and perceptual quality greatly. Many methods focus on enhancing the amplitude spectrum while reconstructing speech using the mixture phase. Since the clean phase is very important and difficult to predict, the performance of these methods will be limited. Some researchers attempted to estimate the phase spectrum directly or indirectly, but the effect is not ideal. Recently, some studies proposed the complex-valued model and achieved state-of-the-art performance, such as deep complex convolution recurrent network (DCCRN). However, the computation of the model is huge. To reduce the complexity and further improve the performance, we propose a novel method using discrete cosine transform as the input in this paper, called deep cosine transform convolutional recurrent network (DCTCRN). Experimental results show that DCTCRN achieves state-of-the-art performance both on objective and subjective metrics. Compared with noisy mixtures, the mean opinion score (MOS) increased by 0.46 (2.86 to 3.32) absolute processed by the proposed model with only 2.86M parameters.
Deep Variational Generative Models for Audio-visual Speech Separation
Aug 17, 2020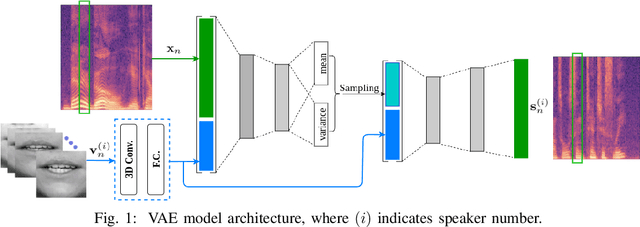
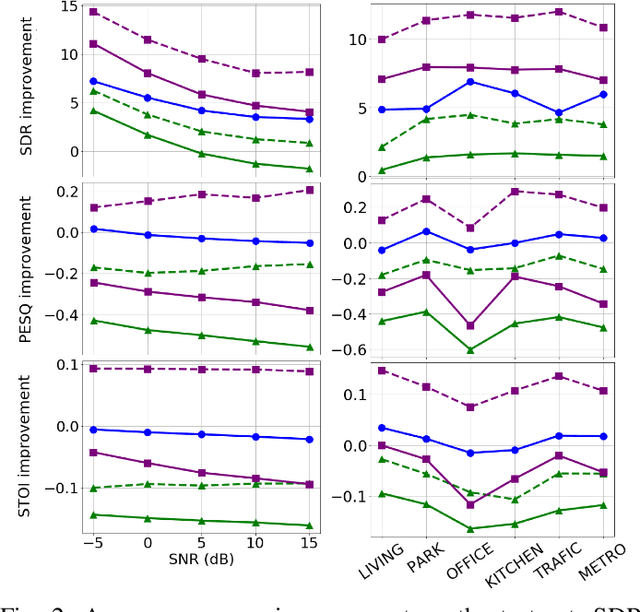
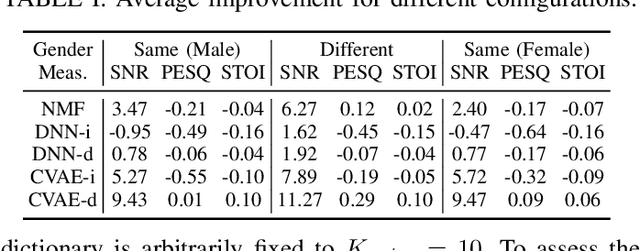
In this paper, we are interested in audio-visual speech separation given a single-channel audio recording as well as visual information (lips movements) associated with each speaker. We propose an unsupervised technique based on audio-visual generative modeling of clean speech. More specifically, during training, a latent variable generative model is learned from clean speech spectrograms using a variational auto-encoder (VAE). To better utilize the visual information, the posteriors of the latent variables are inferred from mixed speech (instead of clean speech) as well as the visual data. The visual modality also serves as a prior for latent variables, through a visual network. At test time, the learned generative model (both for speaker-independent and speaker-dependent scenarios) is combined with an unsupervised non-negative matrix factorization (NMF) variance model for background noise. All the latent variables and noise parameters are then estimated by a Monte Carlo expectation-maximization algorithm. Our experiments show that the proposed unsupervised VAE-based method yields better separation performance than NMF-based approaches as well as a supervised deep learning-based technique.
Adversarial Attacks on ASR Systems: An Overview
Aug 03, 2022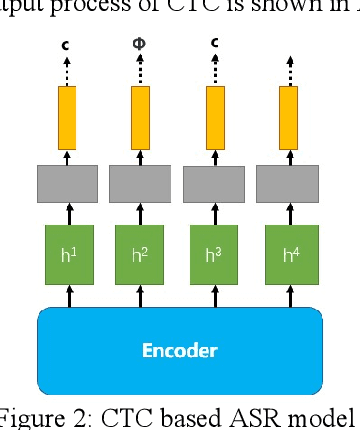
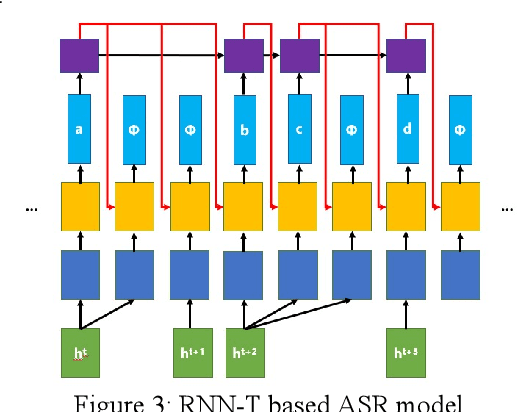
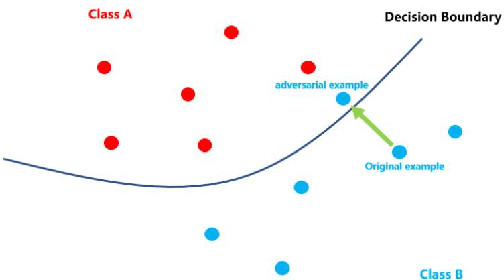
With the development of hardware and algorithms, ASR(Automatic Speech Recognition) systems evolve a lot. As The models get simpler, the difficulty of development and deployment become easier, ASR systems are getting closer to our life. On the one hand, we often use APPs or APIs of ASR to generate subtitles and record meetings. On the other hand, smart speaker and self-driving car rely on ASR systems to control AIoT devices. In past few years, there are a lot of works on adversarial examples attacks against ASR systems. By adding a small perturbation to the waveforms, the recognition results make a big difference. In this paper, we describe the development of ASR system, different assumptions of attacks, and how to evaluate these attacks. Next, we introduce the current works on adversarial examples attacks from two attack assumptions: white-box attack and black-box attack. Different from other surveys, we pay more attention to which layer they perturb waveforms in ASR system, the relationship between these attacks, and their implementation methods. We focus on the effect of their works.