 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Constructive and Toxic Speech Detection for Open-domain Social Media Comments in Vietnamese
Mar 24, 2021
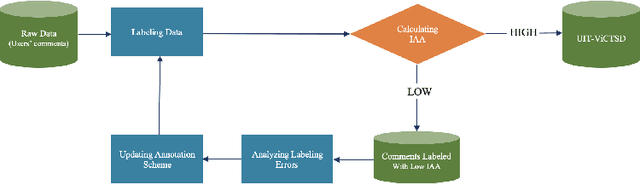

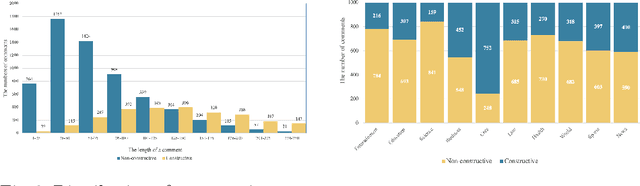

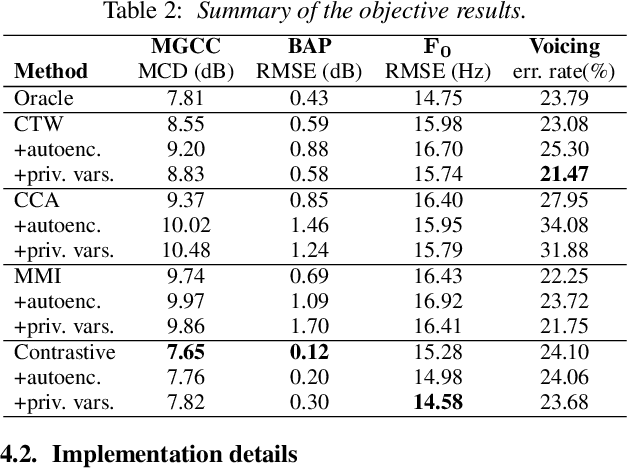
The rise of social media has led to the increasing of comments on online forums. However, there still exists some invalid comments which were not informative for users. Moreover, those comments are also quite toxic and harmful to people. In this paper, we create a dataset for classifying constructive and toxic speech detection, named UIT-ViCTSD (Vietnamese Constructive and Toxic Speech Detection dataset) with 10,000 human-annotated comments. For these tasks, we proposed a system for constructive and toxic speech detection with the state-of-the-art transfer learning model in Vietnamese NLP as PhoBERT. With this system, we achieved 78.59% and 59.40% F1-score for identifying constructive and toxic comments separately. Besides, to have an objective assessment for the dataset, we implement a variety of baseline models as traditional Machine Learning and Deep Neural Network-Based models. With the results, we can solve some problems on the online discussions and develop the framework for identifying constructiveness and toxicity Vietnamese social media comments automatically.
Multi-view Temporal Alignment for Non-parallel Articulatory-to-Acoustic Speech Synthesis
Dec 30, 2020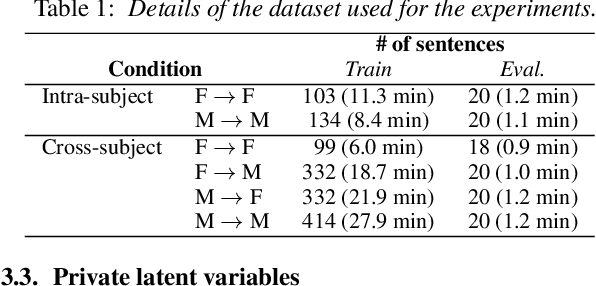
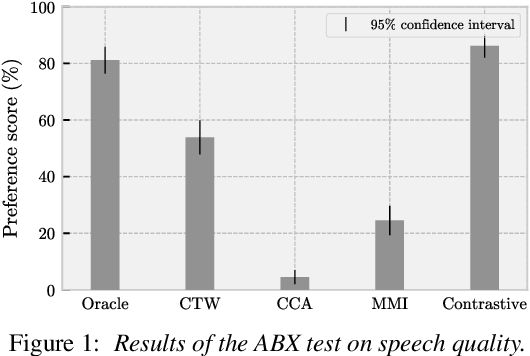
Articulatory-to-acoustic (A2A) synthesis refers to the generation of audible speech from captured movement of the speech articulators. This technique has numerous applications, such as restoring oral communication to people who cannot longer speak due to illness or injury. Most successful techniques so far adopt a supervised learning framework, in which time-synchronous articulatory-and-speech recordings are used to train a supervised machine learning algorithm that can be used later to map articulator movements to speech. This, however, prevents the application of A2A techniques in cases where parallel data is unavailable, e.g., a person has already lost her/his voice and only articulatory data can be captured. In this work, we propose a solution to this problem based on the theory of multi-view learning. The proposed algorithm attempts to find an optimal temporal alignment between pairs of non-aligned articulatory-and-acoustic sequences with the same phonetic content by projecting them into a common latent space where both views are maximally correlated and then applying dynamic time warping. Several variants of this idea are discussed and explored. We show that the quality of speech generated in the non-aligned scenario is comparable to that obtained in the parallel scenario.
Enhanced exemplar autoencoder with cycle consistency loss in any-to-one voice conversion
Apr 12, 2022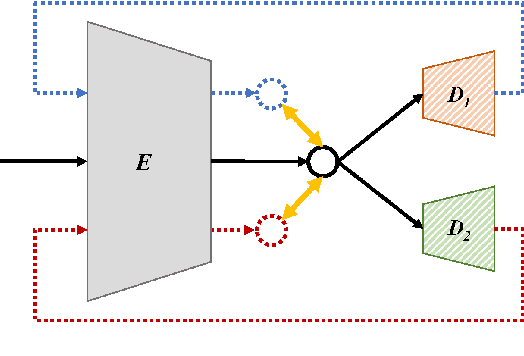

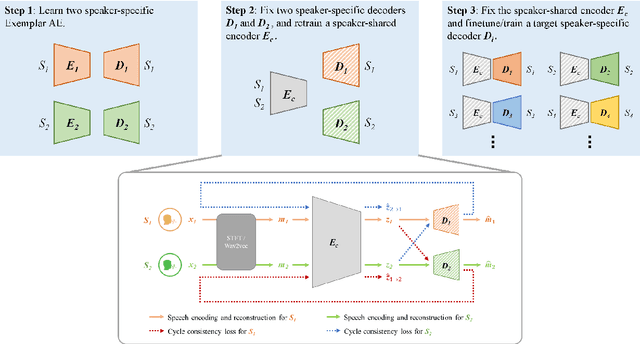
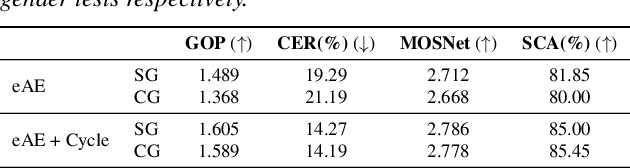
Recent research showed that an autoencoder trained with speech of a single speaker, called exemplar autoencoder (eAE), can be used for any-to-one voice conversion (VC). Compared to large-scale many-to-many models such as AutoVC, the eAE model is easy and fast in training, and may recover more details of the target speaker. To ensure VC quality, the latent code should represent and only represent content information. However, this is not easy to attain for eAE as it is unaware of any speaker variation in model training. To tackle the problem, we propose a simple yet effective approach based on a cycle consistency loss. Specifically, we train eAEs of multiple speakers with a shared encoder, and meanwhile encourage the speech reconstructed from any speaker-specific decoder to get a consistent latent code as the original speech when cycled back and encoded again. Experiments conducted on the AISHELL-3 corpus showed that this new approach improved the baseline eAE consistently. The source code and examples are available at the project page: http://project.cslt.org/.
Improving speaker de-identification with functional data analysis of f0 trajectories
Mar 31, 2022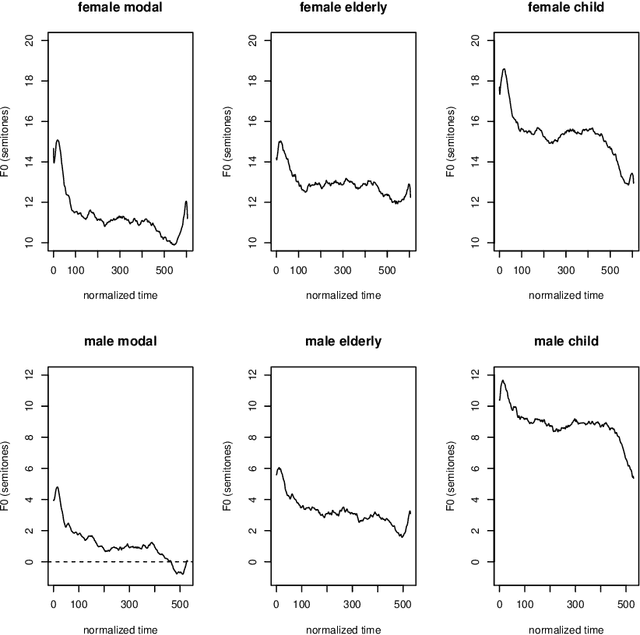
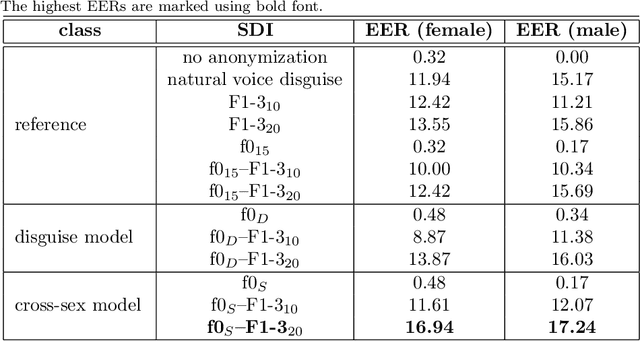
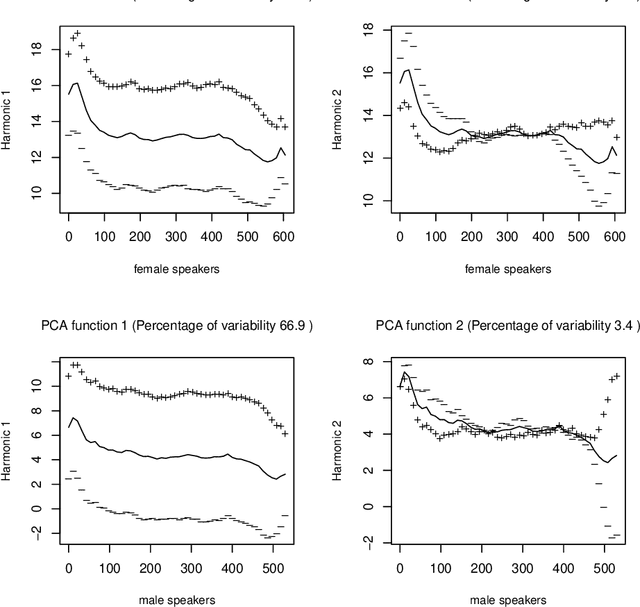
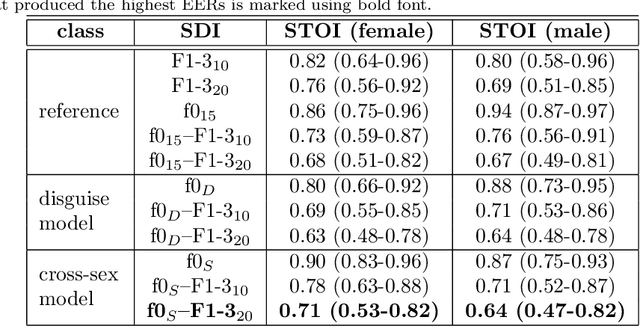
Due to a constantly increasing amount of speech data that is stored in different types of databases, voice privacy has become a major concern. To respond to such concern, speech researchers have developed various methods for speaker de-identification. The state-of-the-art solutions utilize deep learning solutions which can be effective but might be unavailable or impractical to apply for, for example, under-resourced languages. Formant modification is a simpler, yet effective method for speaker de-identification which requires no training data. Still, remaining intonational patterns in formant-anonymized speech may contain speaker-dependent cues. This study introduces a novel speaker de-identification method, which, in addition to simple formant shifts, manipulates f0 trajectories based on functional data analysis. The proposed speaker de-identification method will conceal plausibly identifying pitch characteristics in a phonetically controllable manner and improve formant-based speaker de-identification up to 25%.
TSTNN: Two-stage Transformer based Neural Network for Speech Enhancement in the Time Domain
Mar 18, 2021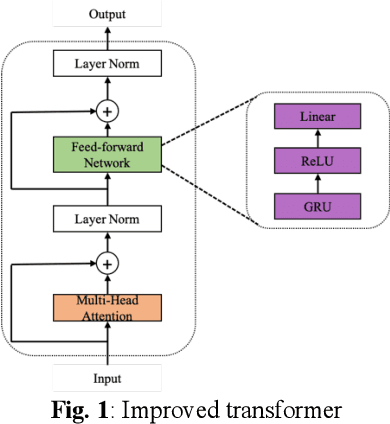
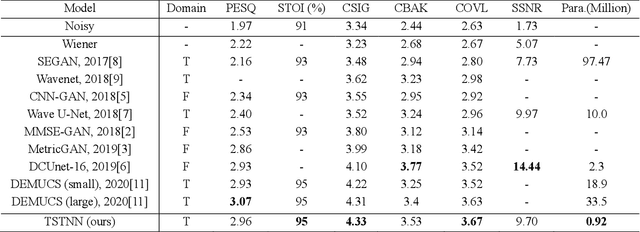
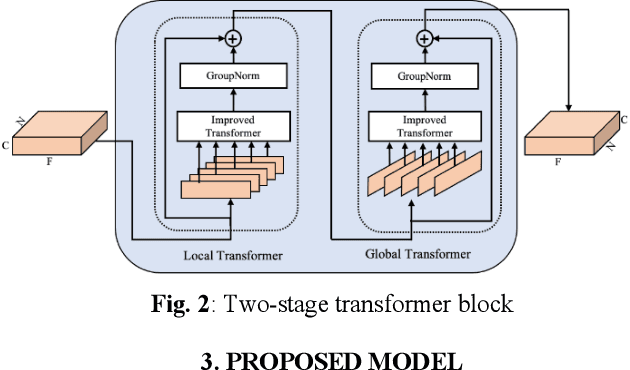
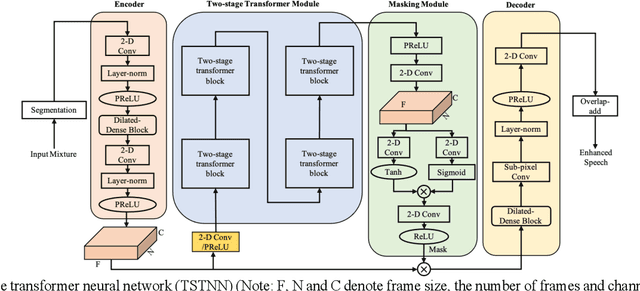
In this paper, we propose a transformer-based architecture, called two-stage transformer neural network (TSTNN) for end-to-end speech denoising in the time domain. The proposed model is composed of an encoder, a two-stage transformer module (TSTM), a masking module and a decoder. The encoder maps input noisy speech into feature representation. The TSTM exploits four stacked two-stage transformer blocks to efficiently extract local and global information from the encoder output stage by stage. The masking module creates a mask which will be multiplied with the encoder output. Finally, the decoder uses the masked encoder feature to reconstruct the enhanced speech. Experimental results on the benchmark dataset show that the TSTNN outperforms most state-of-the-art models in time or frequency domain while having significantly lower model complexity.
The Multilingual TEDx Corpus for Speech Recognition and Translation
Feb 02, 2021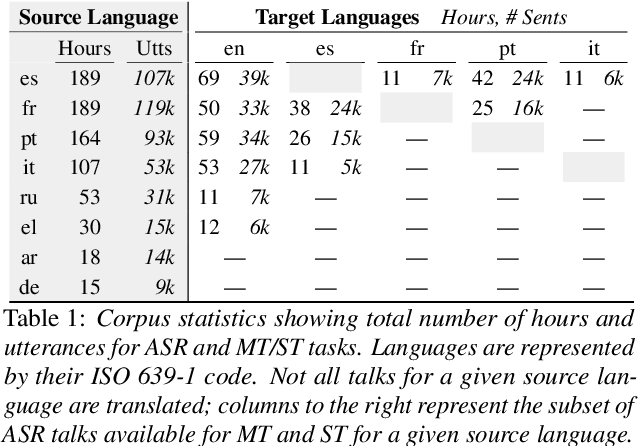
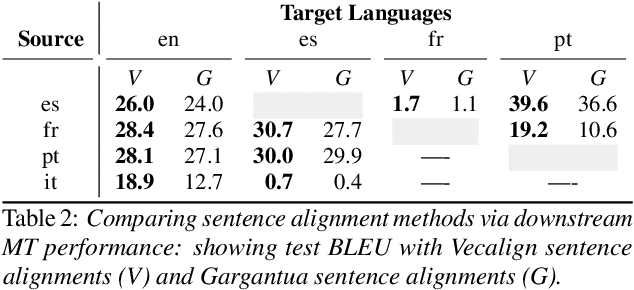
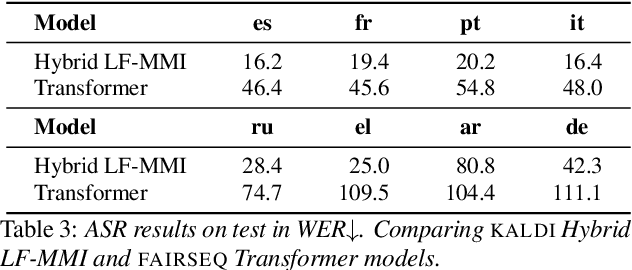
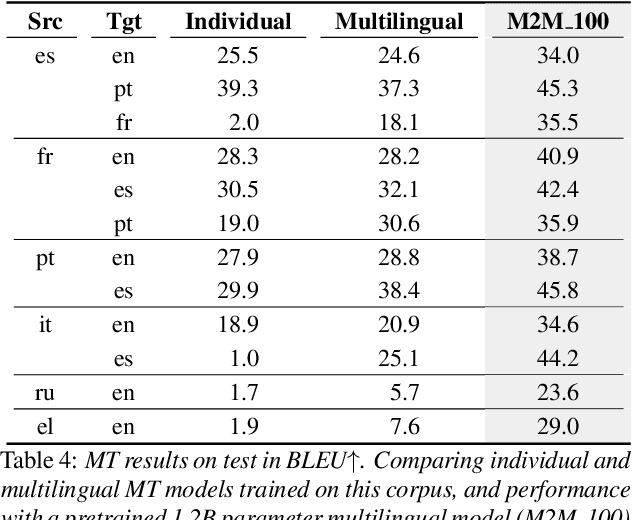
We present the Multilingual TEDx corpus, built to support speech recognition (ASR) and speech translation (ST) research across many non-English source languages. The corpus is a collection of audio recordings from TEDx talks in 8 source languages. We segment transcripts into sentences and align them to the source-language audio and target-language translations. The corpus is released along with open-sourced code enabling extension to new talks and languages as they become available. Our corpus creation methodology can be applied to more languages than previous work, and creates multi-way parallel evaluation sets. We provide baselines in multiple ASR and ST settings, including multilingual models to improve translation performance for low-resource language pairs.
Almost Unsupervised Text to Speech and Automatic Speech Recognition
May 13, 2019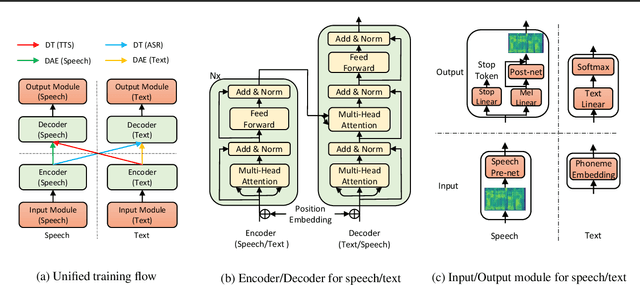
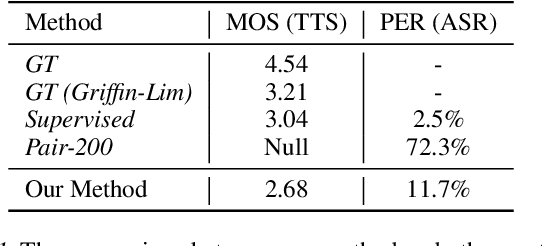
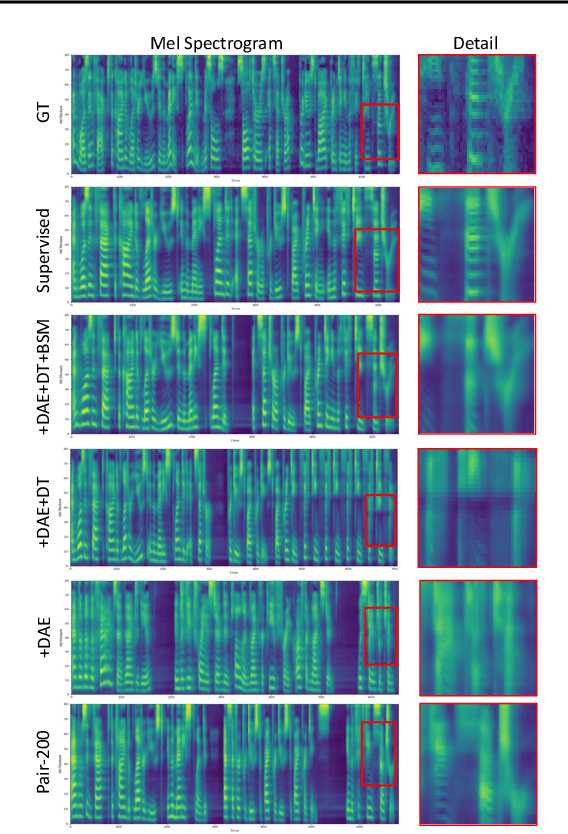

Text to speech (TTS) and automatic speech recognition (ASR) are two dual tasks in speech processing and both achieve impressive performance thanks to the recent advance in deep learning and large amount of aligned speech and text data. However, the lack of aligned data poses a major practical problem for TTS and ASR on low-resource languages. In this paper, by leveraging the dual nature of the two tasks, we propose an almost unsupervised learning method that only leverages few hundreds of paired data and extra unpaired data for TTS and ASR. Our method consists of the following components: (1) a denoising auto-encoder, which reconstructs speech and text sequences respectively to develop the capability of language modeling both in speech and text domain; (2) dual transformation, where the TTS model transforms the text $y$ into speech $\hat{x}$, and the ASR model leverages the transformed pair $(\hat{x},y)$ for training, and vice versa, to boost the accuracy of the two tasks; (3) bidirectional sequence modeling, which addresses error propagation especially in the long speech and text sequence when training with few paired data; (4) a unified model structure, which combines all the above components for TTS and ASR based on Transformer model. Our method achieves 99.84% in terms of word level intelligible rate and 2.68 MOS for TTS, and 11.7% PER for ASR on LJSpeech dataset, by leveraging only 200 paired speech and text data (about 20 minutes audio), together with extra unpaired speech and text data.
A New 27 Class Sign Language Dataset Collected from 173 Individuals
Mar 08, 2022
After the interviews, it has been comprehended that speech-impaired individuals who use sign languages have difficulty communicating with other people who do not know sign language. Due to the communication problems, the sense of independence of speech-impaired individuals could be damaged and lead them to socialize less with society. To contribute to the development of technologies, that can reduce the communication problems of speech-impaired persons, a new dataset was presented with this paper. The dataset was created by processing American Sign Language-based photographs collected from 173 volunteers, published as 27 Class Sign Language Dataset on the Kaggle Datasets web page.
Speech Enhancement using Separable Polling Attention and Global Layer Normalization followed with PReLU
May 06, 2021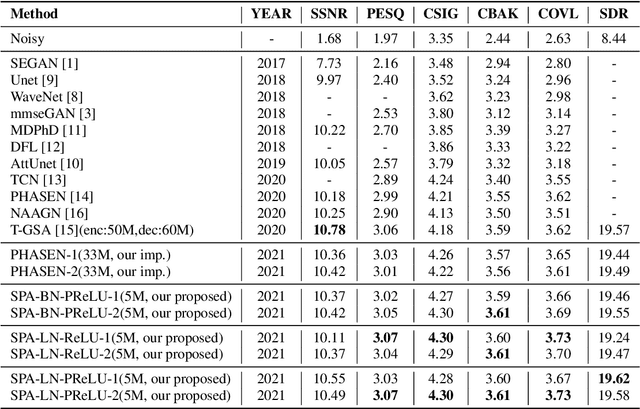
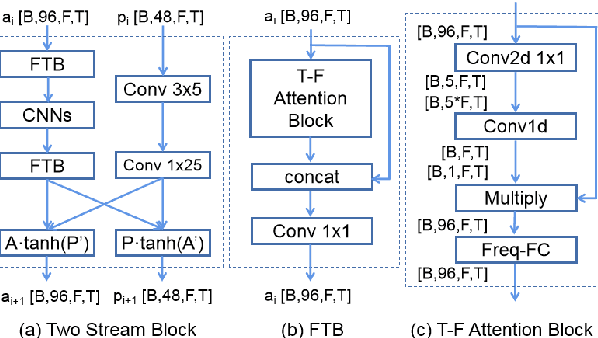
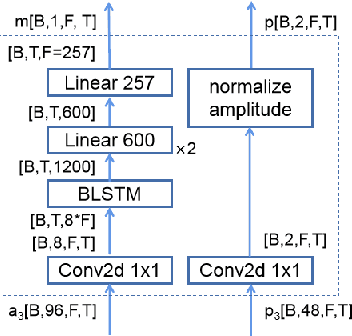

Single channel speech enhancement is a challenging task in speech community. Recently, various neural networks based methods have been applied to speech enhancement. Among these models, PHASEN and T-GSA achieve state-of-the-art performances on the publicly opened VoiceBank+DEMAND corpus. Both of the models reach the COVL score of 3.62. PHASEN achieves the highest CSIG score of 4.21 while T-GSA gets the highest PESQ score of 3.06. However, both of these two models are very large. The contradiction between the model performance and the model size is hard to reconcile. In this paper, we introduce three kinds of techniques to shrink the PHASEN model and improve the performance. Firstly, seperable polling attention is proposed to replace the frequency transformation blocks in PHASEN. Secondly, global layer normalization followed with PReLU is used to replace batch normalization followed with ReLU. Finally, BLSTM in PHASEN is replaced with Conv2d operation and the phase stream is simplified. With all these modifications, the size of the PHASEN model is shrunk from 33M parameters to 5M parameters, while the performance on VoiceBank+DEMAND is improved to the CSIG score of 4.30, the PESQ score of 3.07 and the COVL score of 3.73.
Disentangled Speaker Representation Learning via Mutual Information Minimization
Aug 17, 2022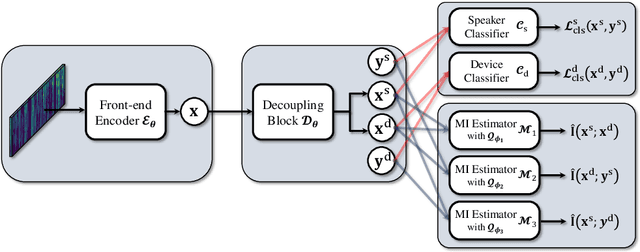
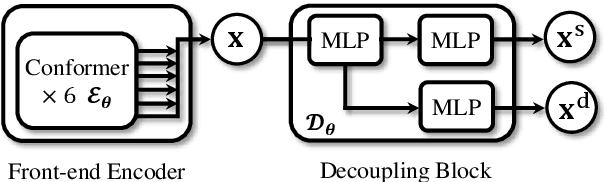
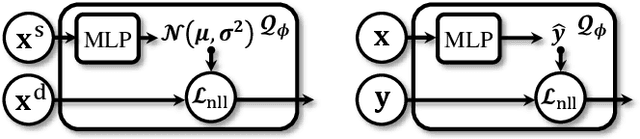
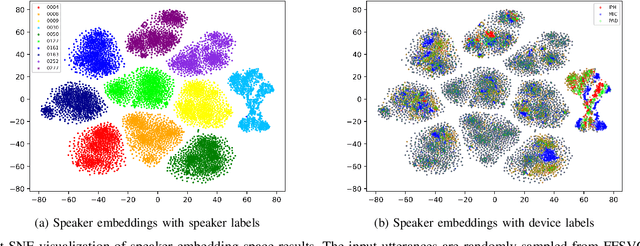
Domain mismatch problem caused by speaker-unrelated feature has been a major topic in speaker recognition. In this paper, we propose an explicit disentanglement framework to unravel speaker-relevant features from speaker-unrelated features via mutual information (MI) minimization. To achieve our goal of minimizing MI between speaker-related and speaker-unrelated features, we adopt a contrastive log-ratio upper bound (CLUB), which exploits the upper bound of MI. Our framework is constructed in a 3-stage structure. First, in the front-end encoder, input speech is encoded into shared initial embedding. Next, in the decoupling block, shared initial embedding is split into separate speaker-related and speaker-unrelated embeddings. Finally, disentanglement is conducted by MI minimization in the last stage. Experiments on Far-Field Speaker Verification Challenge 2022 (FFSVC2022) demonstrate that our proposed framework is effective for disentanglement. Also, to utilize domain-unknown datasets containing numerous speakers, we pre-trained the front-end encoder with VoxCeleb datasets. We then fine-tuned the speaker embedding model in the disentanglement framework with FFSVC 2022 dataset. The experimental results show that fine-tuning with a disentanglement framework on a existing pre-trained model is valid and can further improve performance.