 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Applying Wav2vec2.0 to Speech Recognition in Various Low-resource Languages
Jan 17, 2021
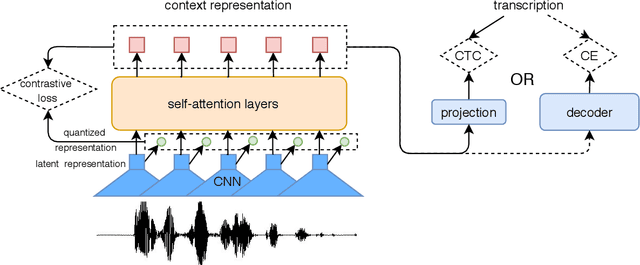
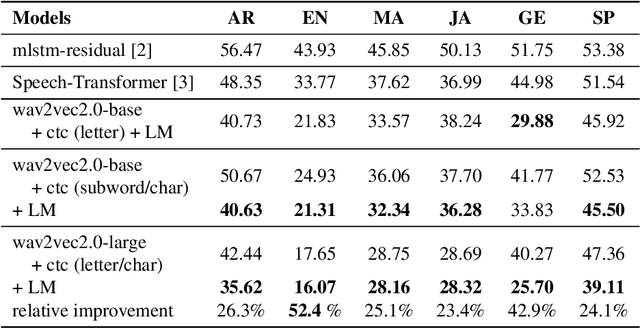
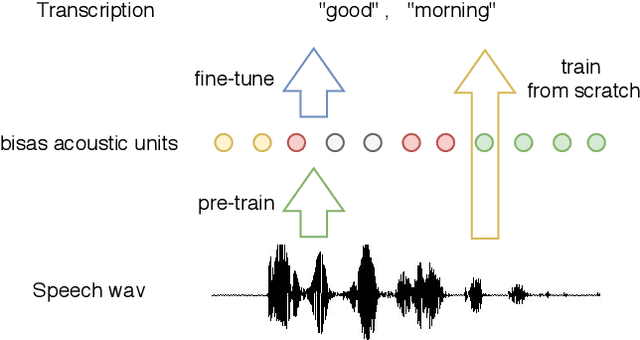
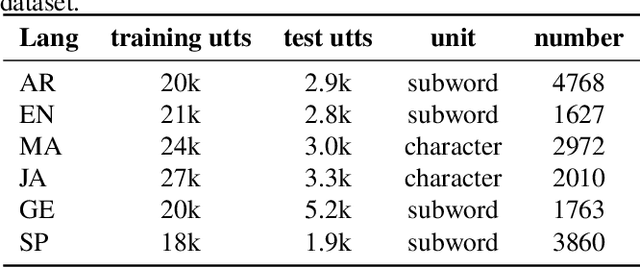
There are several domains that own corresponding widely used feature extractors, such as ResNet, BERT, and GPT-x. These models are usually pre-trained on large amounts of unlabeled data by self-supervision and can be effectively applied to downstream tasks. In the speech domain, wav2vec2.0 starts to show its powerful representation ability and feasibility of ultra-low resource speech recognition on the Librispeech corpus, which belongs to the audiobook domain. However, wav2vec2.0 has not been examined on real spoken scenarios and languages other than English. To verify its universality over languages, we apply pre-trained models to solve low-resource speech recognition tasks in various spoken languages. We achieve more than 20% relative improvements in six languages compared with previous work. Among these languages, English achieves a gain of 52.4%. Moreover, using coarse-grained modeling units, such as subword or character, achieves better results than fine-grained modeling units, such as phone or letter.
Bunched LPCNet2: Efficient Neural Vocoders Covering Devices from Cloud to Edge
Mar 27, 2022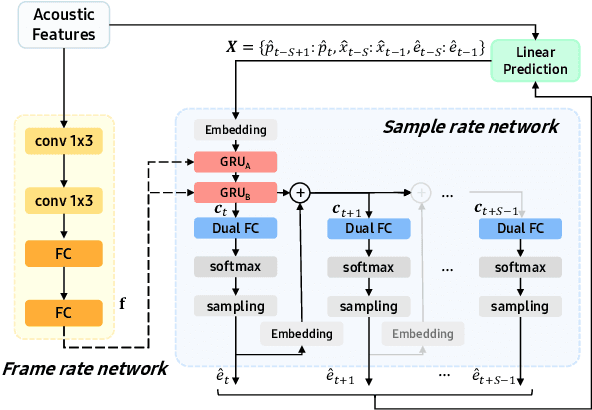

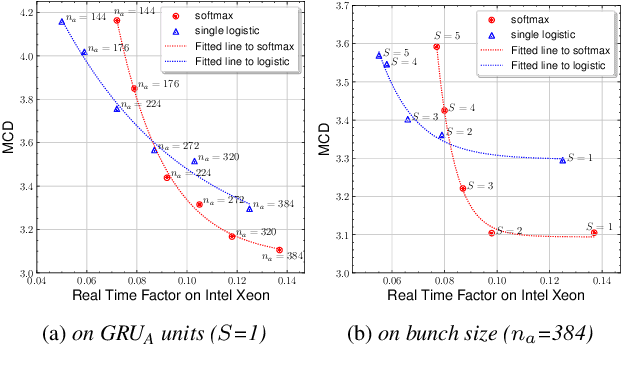
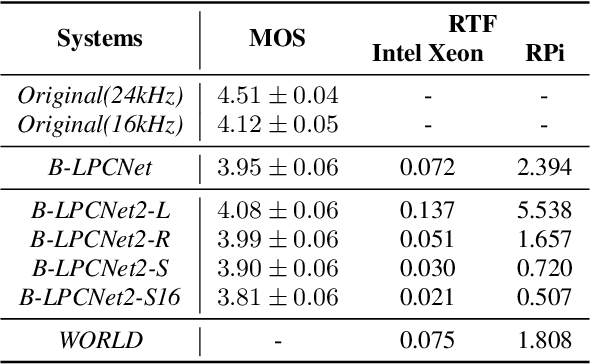
Text-to-Speech (TTS) services that run on edge devices have many advantages compared to cloud TTS, e.g., latency and privacy issues. However, neural vocoders with a low complexity and small model footprint inevitably generate annoying sounds. This study proposes a Bunched LPCNet2, an improved LPCNet architecture that provides highly efficient performance in high-quality for cloud servers and in a low-complexity for low-resource edge devices. Single logistic distribution achieves computational efficiency, and insightful tricks reduce the model footprint while maintaining speech quality. A DualRate architecture, which generates a lower sampling rate from a prosody model, is also proposed to reduce maintenance costs. The experiments demonstrate that Bunched LPCNet2 generates satisfactory speech quality with a model footprint of 1.1MB while operating faster than real-time on a RPi 3B. Our audio samples are available at https://srtts.github.io/bunchedLPCNet2.
TalkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Prediction
Apr 19, 2021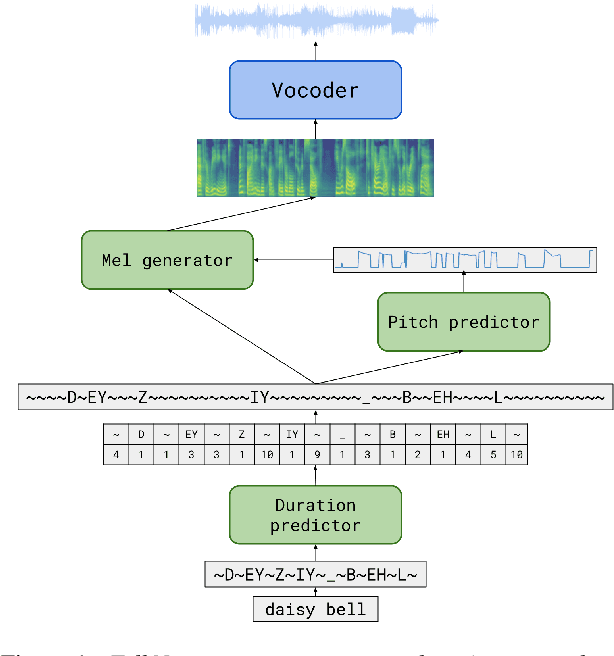
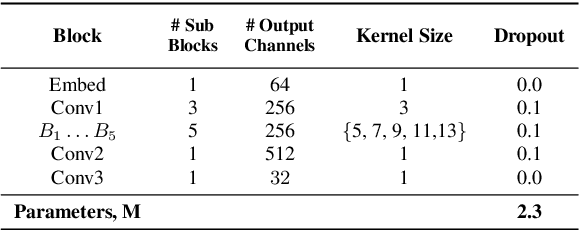
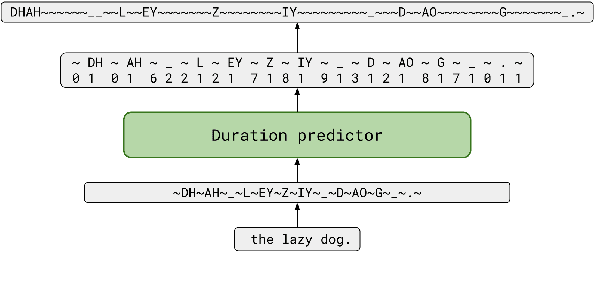
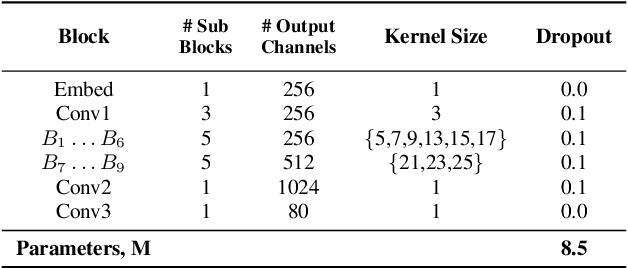
We propose TalkNet, a non-autoregressive convolutional neural model for speech synthesis with explicit pitch and duration prediction. The model consists of three feed-forward convolutional networks. The first network predicts grapheme durations. An input text is expanded by repeating each symbol according to the predicted duration. The second network predicts pitch value for every mel frame. The third network generates a mel-spectrogram from the expanded text conditioned on predicted pitch. All networks are based on 1D depth-wise separable convolutional architecture. The explicit duration prediction eliminates word skipping and repeating. The quality of the generated speech nearly matches the best auto-regressive models - TalkNet trained on the LJSpeech dataset got MOS4.08. The model has only 13.2M parameters, almost 2x less than the present state-of-the-art text-to-speech models. The non-autoregressive architecture allows for fast training and inference - 422x times faster than real-time. The small model size and fast inference make the TalkNet an attractive candidate for embedded speech synthesis.
Information Sieve: Content Leakage Reduction in End-to-End Prosody For Expressive Speech Synthesis
Aug 04, 2021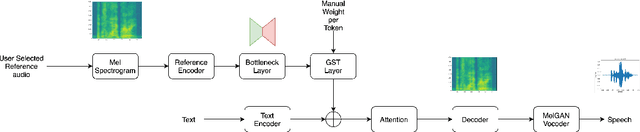
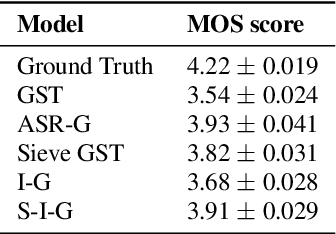
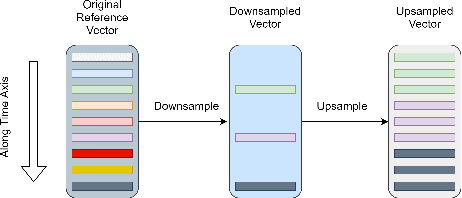
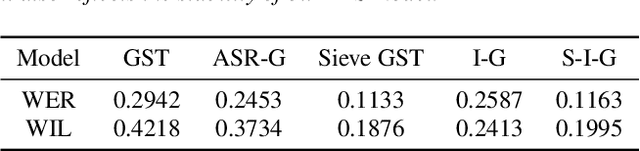
Expressive neural text-to-speech (TTS) systems incorporate a style encoder to learn a latent embedding as the style information. However, this embedding process may encode redundant textual information. This phenomenon is called content leakage. Researchers have attempted to resolve this problem by adding an ASR or other auxiliary supervision loss functions. In this study, we propose an unsupervised method called the "information sieve" to reduce the effect of content leakage in prosody transfer. The rationale of this approach is that the style encoder can be forced to focus on style information rather than on textual information contained in the reference speech by a well-designed downsample-upsample filter, i.e., the extracted style embeddings can be downsampled at a certain interval and then upsampled by duplication. Furthermore, we used instance normalization in convolution layers to help the system learn a better latent style space. Objective metrics such as the significantly lower word error rate (WER) demonstrate the effectiveness of this model in mitigating content leakage. Listening tests indicate that the model retains its prosody transferability compared with the baseline models such as the original GST-Tacotron and ASR-guided Tacotron.
Amortized Neural Networks for Low-Latency Speech Recognition
Aug 03, 2021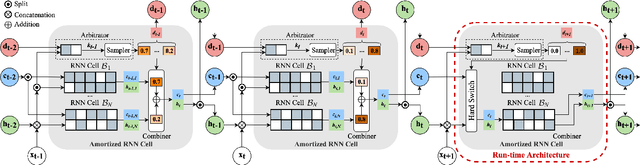
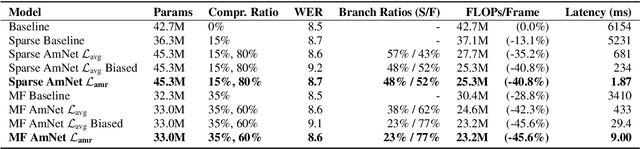
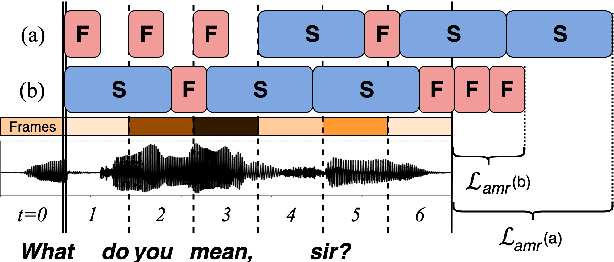
We introduce Amortized Neural Networks (AmNets), a compute cost- and latency-aware network architecture particularly well-suited for sequence modeling tasks. We apply AmNets to the Recurrent Neural Network Transducer (RNN-T) to reduce compute cost and latency for an automatic speech recognition (ASR) task. The AmNets RNN-T architecture enables the network to dynamically switch between encoder branches on a frame-by-frame basis. Branches are constructed with variable levels of compute cost and model capacity. Here, we achieve variable compute for two well-known candidate techniques: one using sparse pruning and the other using matrix factorization. Frame-by-frame switching is determined by an arbitrator network that requires negligible compute overhead. We present results using both architectures on LibriSpeech data and show that our proposed architecture can reduce inference cost by up to 45\% and latency to nearly real-time without incurring a loss in accuracy.
Automatic Spoken Language Identification using a Time-Delay Neural Network
May 19, 2022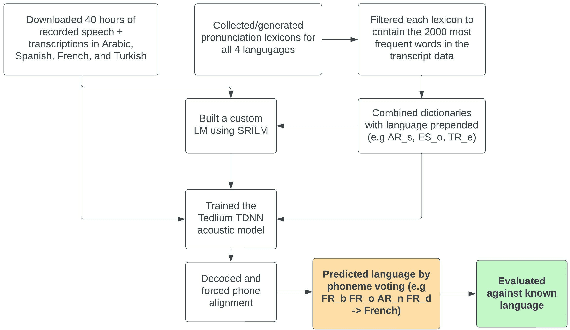



Closed-set spoken language identification is the task of recognizing the language being spoken in a recorded audio clip from a set of known languages. In this study, a language identification system was built and trained to distinguish between Arabic, Spanish, French, and Turkish based on nothing more than recorded speech. A pre-existing multilingual dataset was used to train a series of acoustic models based on the Tedlium TDNN model to perform automatic speech recognition. The system was provided with a custom multilingual language model and a specialized pronunciation lexicon with language names prepended to phones. The trained model was used to generate phone alignments to test data from all four languages, and languages were predicted based on a voting scheme choosing the most common language prepend in an utterance. Accuracy was measured by comparing predicted languages to known languages, and was determined to be very high in identifying Spanish and Arabic, and somewhat lower in identifying Turkish and French.
Vers la compréhension automatique de la parole bout-en-bout à moindre effort
Jul 01, 2022
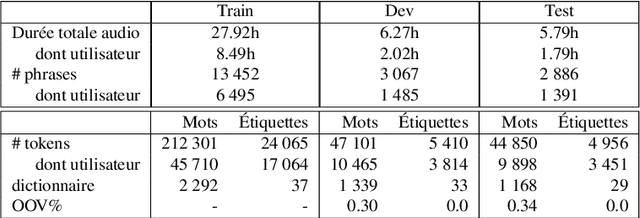
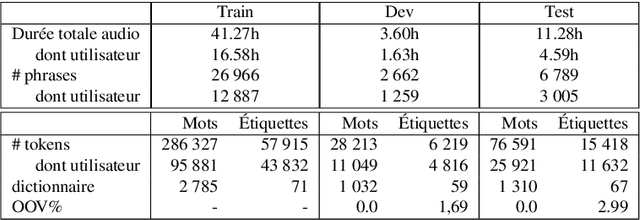
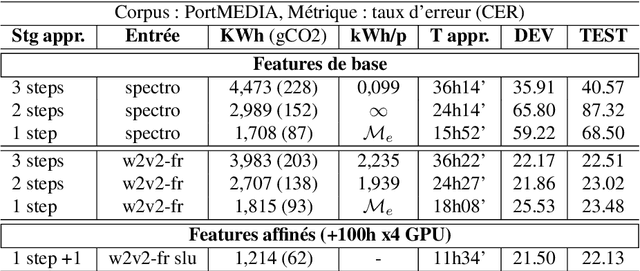
Recent advances in spoken language understanding benefited from Self-Supervised models trained on large speech corpora. For French, the LeBenchmark project has made such models available and has led to impressive progress on several tasks including spoken language understanding. These advances have a non-negligible cost in terms of computation time and energy consumption. In this paper, we compare several learning strategies aiming at reducing such cost while keeping competitive performances. The experiments are performed on the MEDIA corpus, and show that it is possible to reduce the learning cost while maintaining state-of-the-art performances.
DBNet: A Dual-branch Network Architecture Processing on Spectrum and Waveform for Single-channel Speech Enhancement
May 06, 2021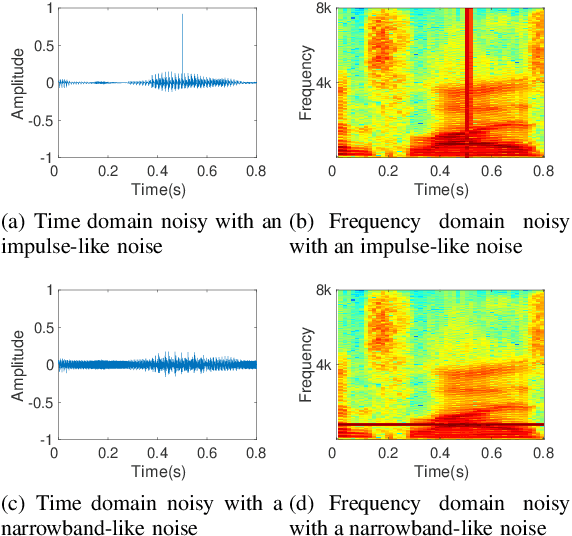
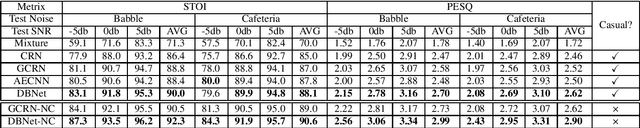
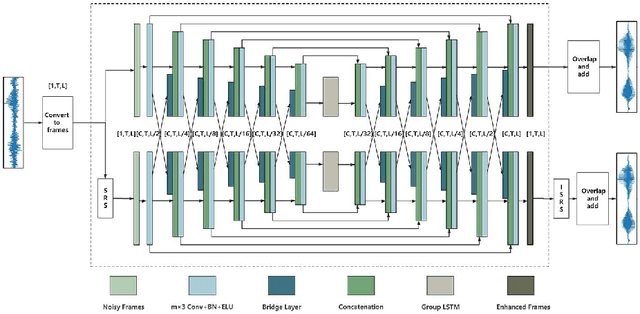

In real acoustic environment, speech enhancement is an arduous task to improve the quality and intelligibility of speech interfered by background noise and reverberation. Over the past years, deep learning has shown great potential on speech enhancement. In this paper, we propose a novel real-time framework called DBNet which is a dual-branch structure with alternate interconnection. Each branch incorporates an encoder-decoder architecture with skip connections. The two branches are responsible for spectrum and waveform modeling, respectively. A bridge layer is adopted to exchange information between the two branches. Systematic evaluation and comparison show that the proposed system substantially outperforms related algorithms under very challenging environments. And in INTERSPEECH 2021 Deep Noise Suppression (DNS) challenge, the proposed system ranks the top 8 in real-time track 1 in terms of the Mean Opinion Score (MOS) of the ITU-T P.835 framework.
Wav2Vec2.0 on the Edge: Performance Evaluation
Feb 12, 2022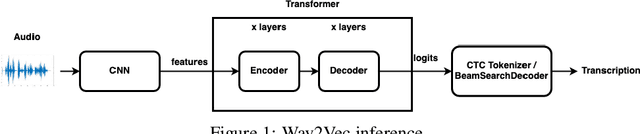


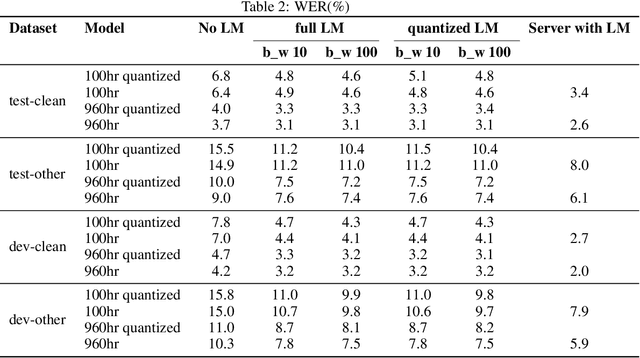
Wav2Vec2.0 is a state-of-the-art model which learns speech representations through unlabeled speech data, aka, self supervised learning. The pretrained model is then fine tuned on small amounts of labeled data to use it for speech-to-text and machine translation tasks. Wav2Vec 2.0 is a transformative solution for low resource languages as it is mainly developed using unlabeled audio data. Getting large amounts of labeled data is resource intensive and especially challenging to do for low resource languages such as Swahilli, Tatar, etc. Furthermore, Wav2Vec2.0 word-error-rate(WER) matches or surpasses the very recent supervised learning algorithms while using 100x less labeled data. Given its importance and enormous potential in enabling speech based tasks on world's 7000 languages, it is key to evaluate the accuracy, latency and efficiency of this model on low resource and low power edge devices and investigate the feasibility of using it in such devices for private, secure and reliable speech based tasks. On-device speech tasks preclude sending audio data to the server hence inherently providing privacy, reduced latency and enhanced reliability. In this paper, Wav2Vec2.0 model's accuracy and latency has been evaluated on Raspberry Pi along with the KenLM language model for speech recognition tasks. How to tune certain parameters to achieve desired level of WER rate and latency while meeting the CPU, memory and energy budgets of the product has been discussed.
Multi-view Temporal Alignment for Non-parallel Articulatory-to-Acoustic Speech Synthesis
Dec 30, 2020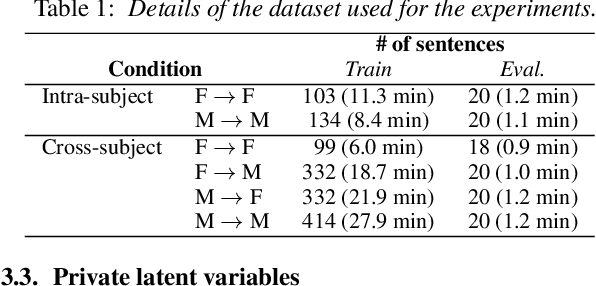
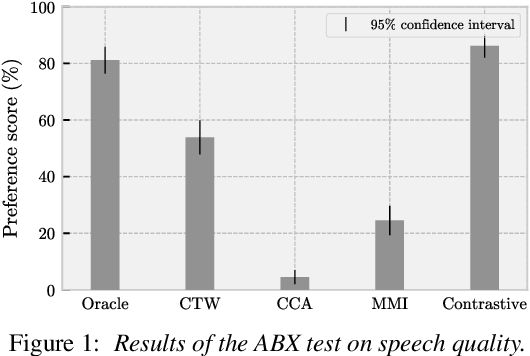
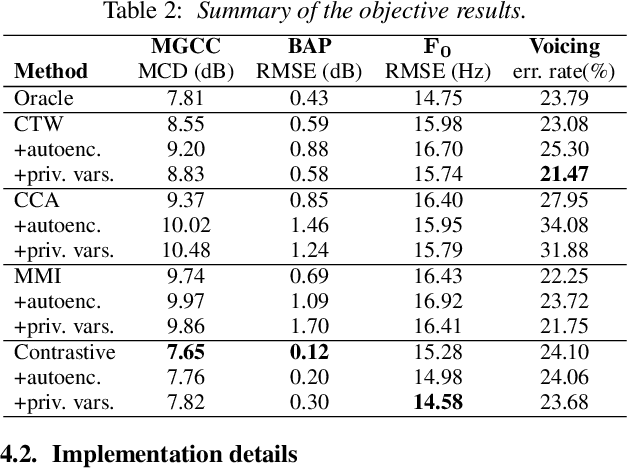
Articulatory-to-acoustic (A2A) synthesis refers to the generation of audible speech from captured movement of the speech articulators. This technique has numerous applications, such as restoring oral communication to people who cannot longer speak due to illness or injury. Most successful techniques so far adopt a supervised learning framework, in which time-synchronous articulatory-and-speech recordings are used to train a supervised machine learning algorithm that can be used later to map articulator movements to speech. This, however, prevents the application of A2A techniques in cases where parallel data is unavailable, e.g., a person has already lost her/his voice and only articulatory data can be captured. In this work, we propose a solution to this problem based on the theory of multi-view learning. The proposed algorithm attempts to find an optimal temporal alignment between pairs of non-aligned articulatory-and-acoustic sequences with the same phonetic content by projecting them into a common latent space where both views are maximally correlated and then applying dynamic time warping. Several variants of this idea are discussed and explored. We show that the quality of speech generated in the non-aligned scenario is comparable to that obtained in the parallel scenario.