 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
BrainTalker: Low-Resource Brain-to-Speech Synthesis with Transfer Learning using Wav2Vec 2.0
Dec 21, 2023
Decoding spoken speech from neural activity in the brain is a fast-emerging research topic, as it could enable communication for people who have difficulties with producing audible speech. For this task, electrocorticography (ECoG) is a common method for recording brain activity with high temporal resolution and high spatial precision. However, due to the risky surgical procedure required for obtaining ECoG recordings, relatively little of this data has been collected, and the amount is insufficient to train a neural network-based Brain-to-Speech (BTS) system. To address this problem, we propose BrainTalker-a novel BTS framework that generates intelligible spoken speech from ECoG signals under extremely low-resource scenarios. We apply a transfer learning approach utilizing a pre-trained self supervised model, Wav2Vec 2.0. Specifically, we train an encoder module to map ECoG signals to latent embeddings that match Wav2Vec 2.0 representations of the corresponding spoken speech. These embeddings are then transformed into mel-spectrograms using stacked convolutional and transformer-based layers, which are fed into a neural vocoder to synthesize speech waveform. Experimental results demonstrate our proposed framework achieves outstanding performance in terms of subjective and objective metrics, including a Pearson correlation coefficient of 0.9 between generated and ground truth mel spectrograms. We share publicly available Demos and Code.
Revisiting the Entropy Semiring for Neural Speech Recognition
Dec 19, 2023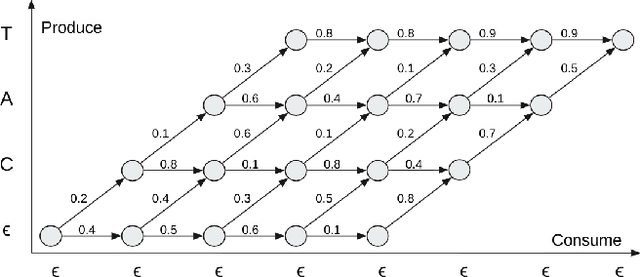
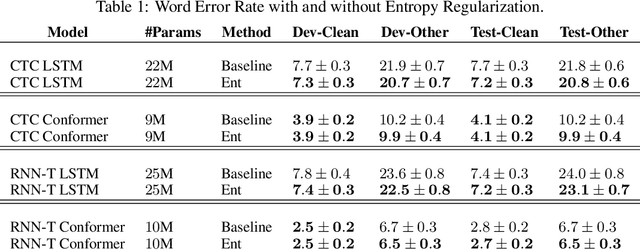

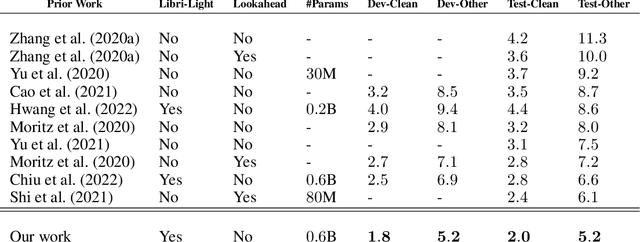
In streaming settings, speech recognition models have to map sub-sequences of speech to text before the full audio stream becomes available. However, since alignment information between speech and text is rarely available during training, models need to learn it in a completely self-supervised way. In practice, the exponential number of possible alignments makes this extremely challenging, with models often learning peaky or sub-optimal alignments. Prima facie, the exponential nature of the alignment space makes it difficult to even quantify the uncertainty of a model's alignment distribution. Fortunately, it has been known for decades that the entropy of a probabilistic finite state transducer can be computed in time linear to the size of the transducer via a dynamic programming reduction based on semirings. In this work, we revisit the entropy semiring for neural speech recognition models, and show how alignment entropy can be used to supervise models through regularization or distillation. We also contribute an open-source implementation of CTC and RNN-T in the semiring framework that includes numerically stable and highly parallel variants of the entropy semiring. Empirically, we observe that the addition of alignment distillation improves the accuracy and latency of an already well-optimized teacher-student distillation model, achieving state-of-the-art performance on the Librispeech dataset in the streaming scenario.
Maximizing Data Efficiency for Cross-Lingual TTS Adaptation by Self-Supervised Representation Mixing and Embedding Initialization
Jan 23, 2024This paper presents an effective transfer learning framework for language adaptation in text-to-speech systems, with a focus on achieving language adaptation using minimal labeled and unlabeled data. While many works focus on reducing the usage of labeled data, very few consider minimizing the usage of unlabeled data. By utilizing self-supervised features in the pretraining stage, replacing the noisy portion of pseudo labels with these features during fine-tuning, and incorporating an embedding initialization trick, our method leverages more information from unlabeled data compared to conventional approaches. Experimental results show that our framework is able to synthesize intelligible speech in unseen languages with only 4 utterances of labeled data and 15 minutes of unlabeled data. Our methodology continues to surpass conventional techniques, even when a greater volume of data is accessible. These findings highlight the potential of our data-efficient language adaptation framework.
Efficient Training Spiking Neural Networks with Parallel Spiking Unit
Feb 02, 2024Efficient parallel computing has become a pivotal element in advancing artificial intelligence. Yet, the deployment of Spiking Neural Networks (SNNs) in this domain is hampered by their inherent sequential computational dependency. This constraint arises from the need for each time step's processing to rely on the preceding step's outcomes, significantly impeding the adaptability of SNN models to massively parallel computing environments. Addressing this challenge, our paper introduces the innovative Parallel Spiking Unit (PSU) and its two derivatives, the Input-aware PSU (IPSU) and Reset-aware PSU (RPSU). These variants skillfully decouple the leaky integration and firing mechanisms in spiking neurons while probabilistically managing the reset process. By preserving the fundamental computational attributes of the spiking neuron model, our approach enables the concurrent computation of all membrane potential instances within the SNN, facilitating parallel spike output generation and substantially enhancing computational efficiency. Comprehensive testing across various datasets, including static and sequential images, Dynamic Vision Sensor (DVS) data, and speech datasets, demonstrates that the PSU and its variants not only significantly boost performance and simulation speed but also augment the energy efficiency of SNNs through enhanced sparsity in neural activity. These advancements underscore the potential of our method in revolutionizing SNN deployment for high-performance parallel computing applications.
Soft Alignment of Modality Space for End-to-end Speech Translation
Dec 18, 2023End-to-end Speech Translation (ST) aims to convert speech into target text within a unified model. The inherent differences between speech and text modalities often impede effective cross-modal and cross-lingual transfer. Existing methods typically employ hard alignment (H-Align) of individual speech and text segments, which can degrade textual representations. To address this, we introduce Soft Alignment (S-Align), using adversarial training to align the representation spaces of both modalities. S-Align creates a modality-invariant space while preserving individual modality quality. Experiments on three languages from the MuST-C dataset show S-Align outperforms H-Align across multiple tasks and offers translation capabilities on par with specialized translation models.
Acoustic Local Positioning With Encoded Emission Beacons
Feb 04, 2024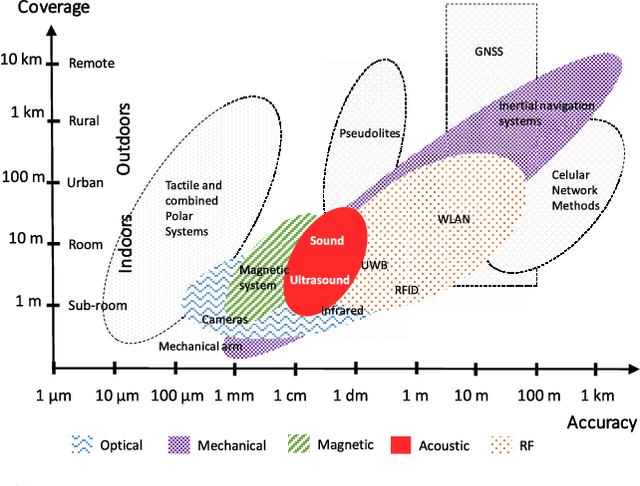
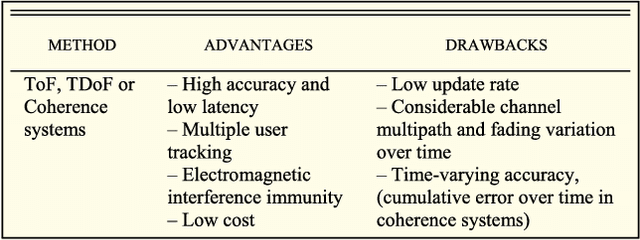
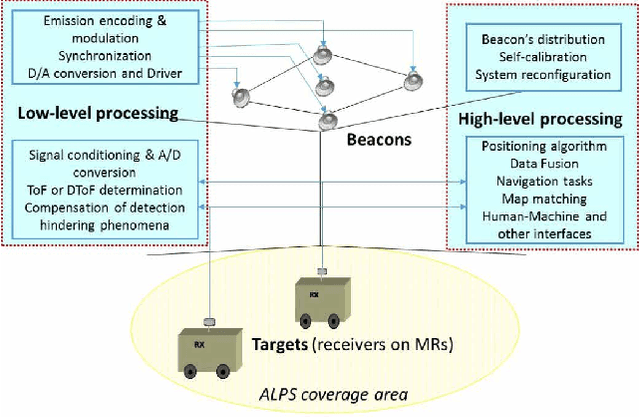
Acoustic local positioning systems (ALPSs) are an interesting alternative for indoor positioning due to certain advantages over other approaches, including their relatively high accuracy, low cost, and room-level signal propagation. Centimeter-level or fine-grained indoor positioning can be an asset for robot navigation, guiding a person to, for instance, a particular piece in a museum or to a specific product in a shop, targeted advertising, or augmented reality. In airborne system applications, acoustic positioning can be based on using opportunistic signals or sounds produced by the person or object to be located (e.g., noise from appliances or the speech from a speaker) or from encoded emission beacons (or anchors) specifically designed for this purpose. This work presents a review of the different challenges that designers of systems based on encoded emission beacons must address in order to achieve suitable performance. At low-level processing, the waveform design (coding and modulation) and the processing of the received signal are key factors to address such drawbacks as multipath propagation, multiple-access interference, nearfar effect, or Doppler shifting. With regards to high-level system design, the issues to be addressed are related to the distribution of beacons, ease of deployment, and calibration and positioning algorithms, including the possible fusion of information. Apart from theoretical discussions, this work also includes the description of an ALPS that was implemented, installed in a large area and tested for mobile robot navigation. In addition to practical interest for real applications, airborne ALPSs can also be used as an excellent platform to test complex algorithms, which can be subsequently adapted for other positioning systems, such as underwater acoustic systems or ultrawideband radiofrequency (UWB RF) systems.
Continuous Target Speech Extraction: Enhancing Personalized Diarization and Extraction on Complex Recordings
Jan 29, 2024Target speaker extraction (TSE) aims to extract the target speaker's voice from the input mixture. Previous studies have concentrated on high-overlapping scenarios. However, real-world applications usually meet more complex scenarios like variable speaker overlapping and target speaker absence. In this paper, we introduces a framework to perform continuous TSE (C-TSE), comprising a target speaker voice activation detection (TSVAD) and a TSE model. This framework significantly improves TSE performance on similar speakers and enhances personalization, which is lacking in traditional diarization methods. In detail, unlike conventional TSVAD deployed to refine the diarization results, the proposed Attention-target speaker voice activation detection (A-TSVAD) directly generates timestamps of the target speaker. We also explore some different integration methods of A-TSVAD and TSE by comparing the cascaded and parallel methods. The framework's effectiveness is assessed using a range of metrics, including diarization and enhancement metrics. Our experiments demonstrate that A-TSVAD outperforms conventional methods in reducing diarization errors. Furthermore, the integration of A-TSVAD and TSE in a sequential cascaded manner further enhances extraction accuracy.
Look, Listen and Recognise: Character-Aware Audio-Visual Subtitling
Jan 22, 2024The goal of this paper is automatic character-aware subtitle generation. Given a video and a minimal amount of metadata, we propose an audio-visual method that generates a full transcript of the dialogue, with precise speech timestamps, and the character speaking identified. The key idea is to first use audio-visual cues to select a set of high-precision audio exemplars for each character, and then use these exemplars to classify all speech segments by speaker identity. Notably, the method does not require face detection or tracking. We evaluate the method over a variety of TV sitcoms, including Seinfeld, Fraiser and Scrubs. We envision this system being useful for the automatic generation of subtitles to improve the accessibility of the vast amount of videos available on modern streaming services. Project page : \url{https://www.robots.ox.ac.uk/~vgg/research/look-listen-recognise/}
PEFT for Speech: Unveiling Optimal Placement, Merging Strategies, and Ensemble Techniques
Jan 04, 2024Parameter-Efficient Fine-Tuning (PEFT) is increasingly recognized as an effective method in speech processing. However, the optimal approach and the placement of PEFT methods remain inconclusive. Our study conducts extensive experiments to compare different PEFT methods and their layer-wise placement adapting Differentiable Architecture Search (DARTS). We also explore the use of ensemble learning to leverage diverse PEFT strategies. The results reveal that DARTS does not outperform the baseline approach, which involves inserting the same PEFT method into all layers of a Self-Supervised Learning (SSL) model. In contrast, an ensemble learning approach, particularly one employing majority voting, demonstrates superior performance. Our statistical evidence indicates that different PEFT methods learn in varied ways. This variation might explain why the synergistic integration of various PEFT methods through ensemble learning can harness their unique learning capabilities more effectively compared to individual layer-wise optimization.
Multi-Input Multi-Output Target-Speaker Voice Activity Detection For Unified, Flexible, and Robust Audio-Visual Speaker Diarization
Jan 16, 2024Audio-visual learning has demonstrated promising results in many classical speech tasks (e.g., speech separation, automatic speech recognition, wake-word spotting). We believe that introducing visual modality will also benefit speaker diarization. To date, target-speaker voice activity detection (TS-VAD) plays an essential role in highly accurate speaker diarization. However, previous TS-VAD models take audio features and utilize the speaker's acoustic footprint to distinguish his or her personal speech activities, which is susceptible to overlapped speaking in multi-speaker scenarios. Although visual information naturally tolerates overlapped speech, it easily suffers from spatial occlusion. The potential modality-missing problem blocks TS-VAD towards an audio-visual approach. This paper proposes a multi-input multi-output target-speaker voice activity detection (MIMO-TSVAD) framework for speaker diarization. The proposed method can take audio-visual input and leverage the speaker's acoustic footprint or lip track to flexibly conduct audio-based, video-based, and audio-visual speaker diarization in a unified sequence-to-sequence architecture. Experimental results show that the MIMO-TSVAD framework demonstrates state-of-the-art performance on the VoxConverse, DIHARD-III, and MISP 2022 datasets under corresponding evaluation metrics, obtaining the diarization error rates (DERs) of 4.18%, 10.10%, and 8.15%, respectively. In addition, it can perform robustly in heavy lip-missing scenarios.