 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Text-free non-parallel many-to-many voice conversion using normalising flows
Mar 15, 2022
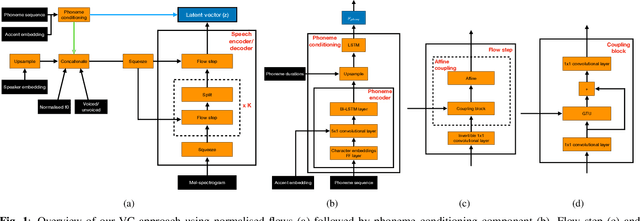
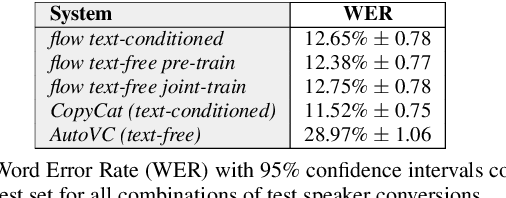
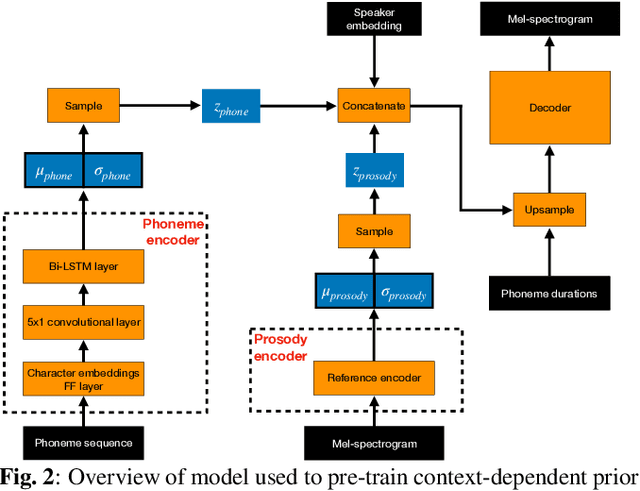
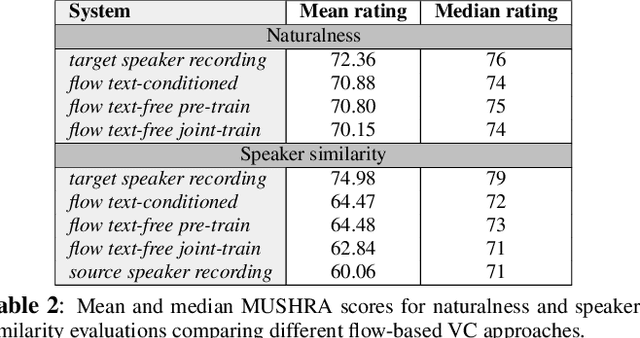
Non-parallel voice conversion (VC) is typically achieved using lossy representations of the source speech. However, ensuring only speaker identity information is dropped whilst all other information from the source speech is retained is a large challenge. This is particularly challenging in the scenario where at inference-time we have no knowledge of the text being read, i.e., text-free VC. To mitigate this, we investigate information-preserving VC approaches. Normalising flows have gained attention for text-to-speech synthesis, however have been under-explored for VC. Flows utilize invertible functions to learn the likelihood of the data, thus provide a lossless encoding of speech. We investigate normalising flows for VC in both text-conditioned and text-free scenarios. Furthermore, for text-free VC we compare pre-trained and jointly-learnt priors. Flow-based VC evaluations show no degradation between text-free and text-conditioned VC, resulting in improvements over the state-of-the-art. Also, joint-training of the prior is found to negatively impact text-free VC quality.
What shall we do with an hour of data? Speech recognition for the un- and under-served languages of Common Voice
May 10, 2021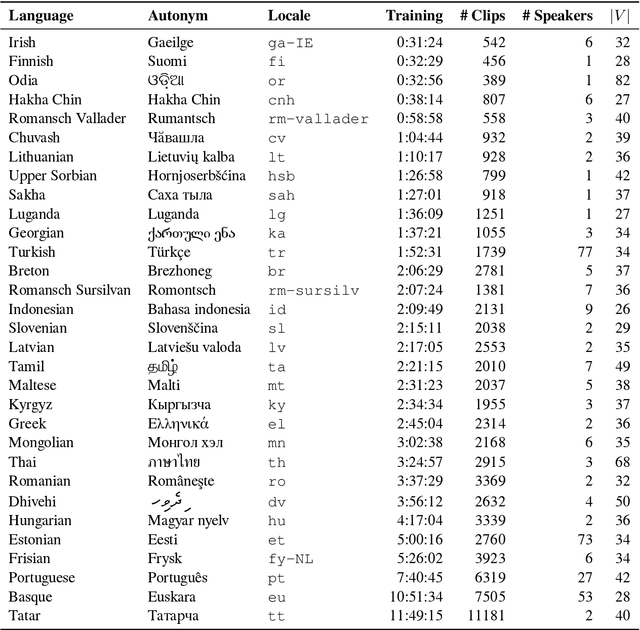
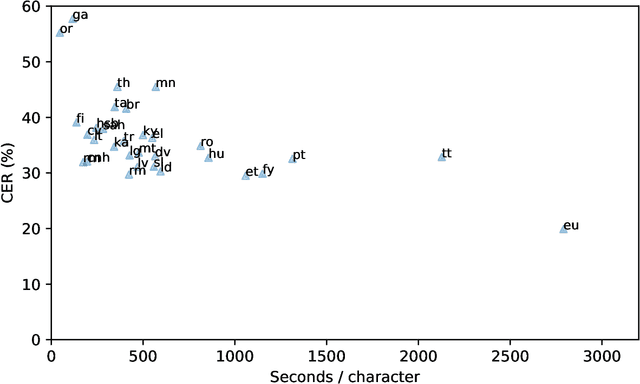
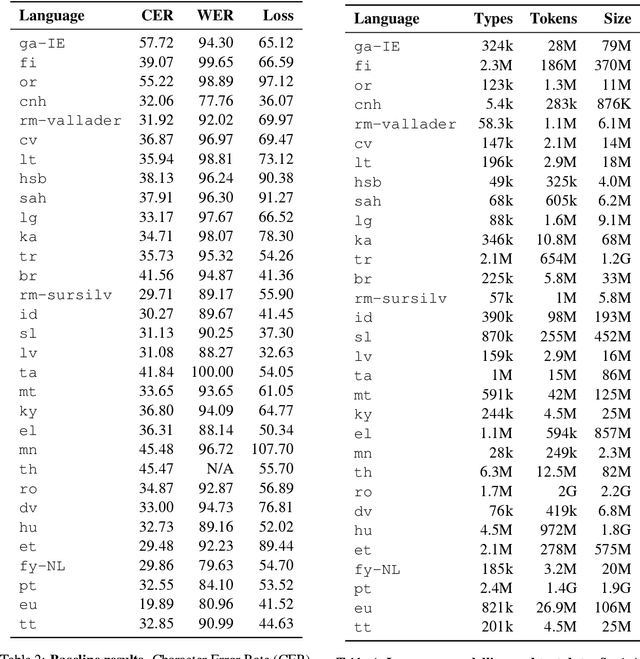
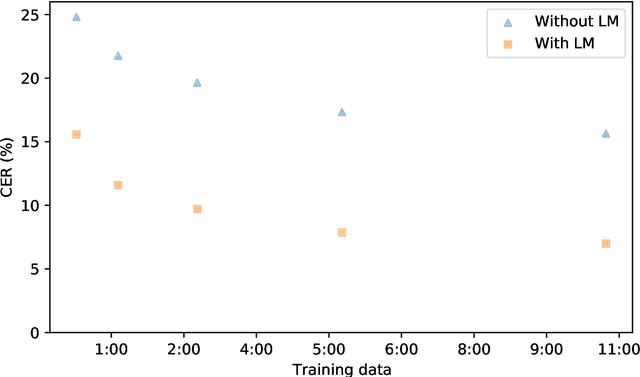
This technical report describes the methods and results of a three-week sprint to produce deployable speech recognition models for 31 under-served languages of the Common Voice project. We outline the preprocessing steps, hyperparameter selection, and resulting accuracy on official testing sets. In addition to this we evaluate the models on multiple tasks: closed-vocabulary speech recognition, pre-transcription, forced alignment, and key-word spotting. The following experiments use Coqui STT, a toolkit for training and deployment of neural Speech-to-Text models.
Learning to Understand Child-directed and Adult-directed Speech
May 06, 2020
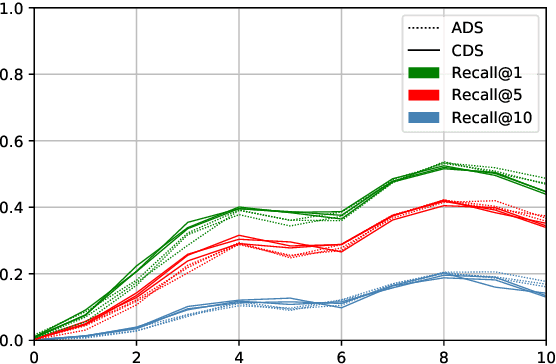
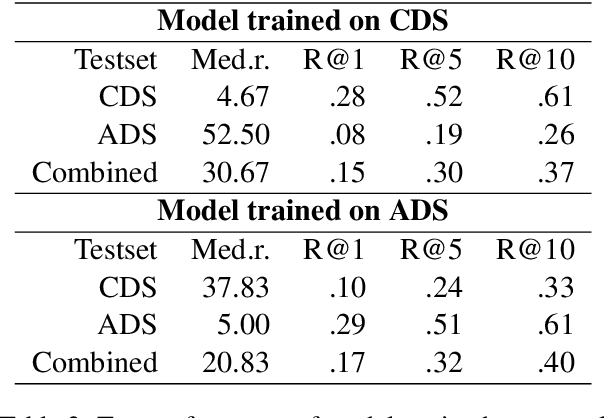
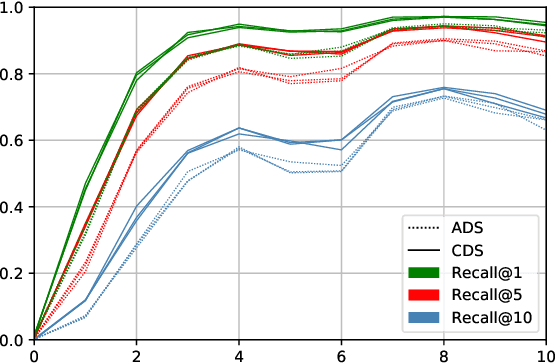
Speech directed to children differs from adult-directed speech in linguistic aspects such as repetition, word choice, and sentence length, as well as in aspects of the speech signal itself, such as prosodic and phonemic variation. Human language acquisition research indicates that child-directed speech helps language learners. This study explores the effect of child-directed speech when learning to extract semantic information from speech directly. We compare the task performance of models trained on adult-directed speech (ADS) and child-directed speech (CDS). We find indications that CDS helps in the initial stages of learning, but eventually, models trained on ADS reach comparable task performance, and generalize better. The results suggest that this is at least partially due to linguistic rather than acoustic properties of the two registers, as we see the same pattern when looking at models trained on acoustically comparable synthetic speech.
Detecting English Speech in the Air Traffic Control Voice Communication
Apr 06, 2021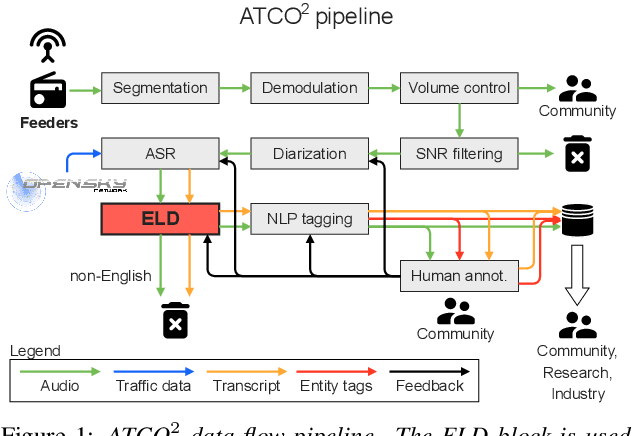
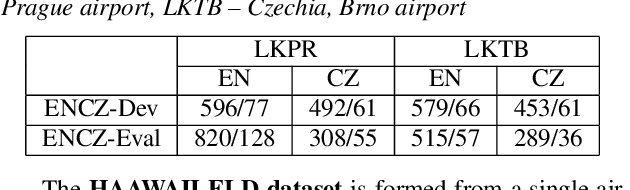
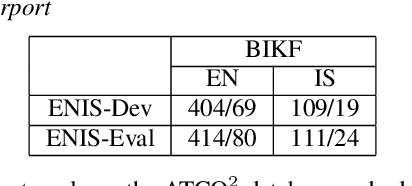

We launched a community platform for collecting the ATC speech world-wide in the ATCO2 project. Filtering out unseen non-English speech is one of the main components in the data processing pipeline. The proposed English Language Detection (ELD) system is based on the embeddings from Bayesian subspace multinomial model. It is trained on the word confusion network from an ASR system. It is robust, easy to train, and light weighted. We achieved 0.0439 equal-error-rate (EER), a 50% relative reduction as compared to the state-of-the-art acoustic ELD system based on x-vectors, in the in-domain scenario. Further, we achieved an EER of 0.1352, a 33% relative reduction as compared to the acoustic ELD, in the unseen language (out-of-domain) condition. We plan to publish the evaluation dataset from the ATCO2 project.
Heterogeneous Target Speech Separation
Apr 07, 2022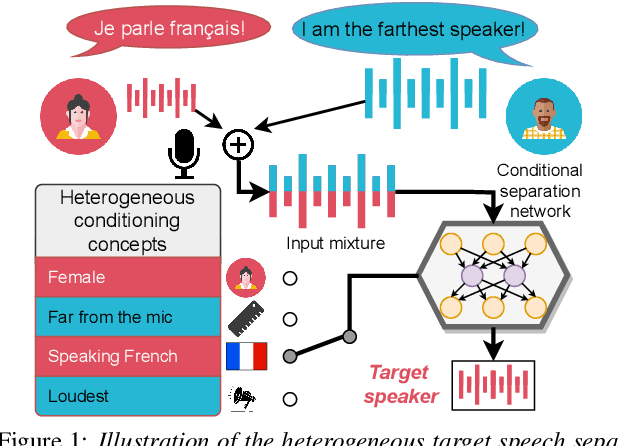
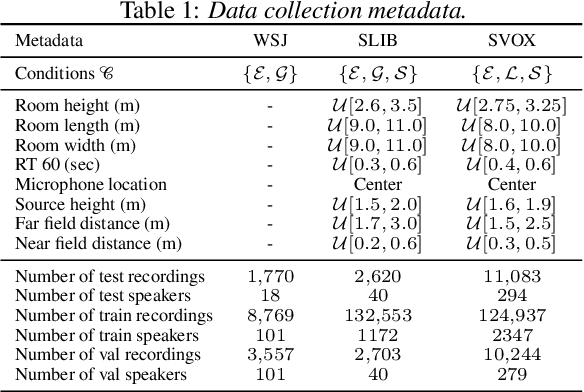
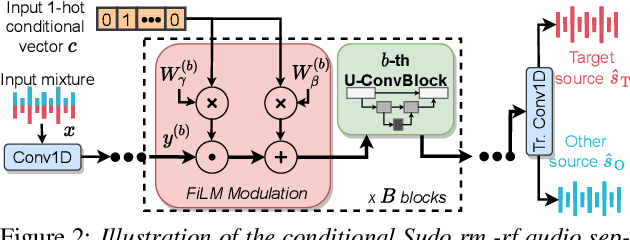
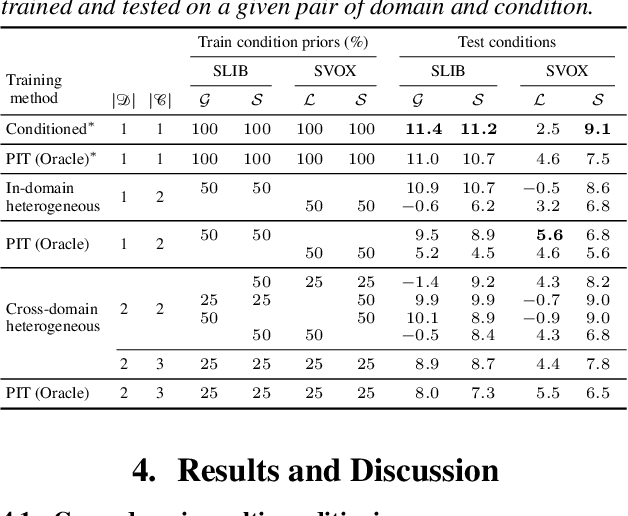
We introduce a new paradigm for single-channel target source separation where the sources of interest can be distinguished using non-mutually exclusive concepts (e.g., loudness, gender, language, spatial location, etc). Our proposed heterogeneous separation framework can seamlessly leverage datasets with large distribution shifts and learn cross-domain representations under a variety of concepts used as conditioning. Our experiments show that training separation models with heterogeneous conditions facilitates the generalization to new concepts with unseen out-of-domain data while also performing substantially higher than single-domain specialist models. Notably, such training leads to more robust learning of new harder source separation discriminative concepts and can yield improvements over permutation invariant training with oracle source selection. We analyze the intrinsic behavior of source separation training with heterogeneous metadata and propose ways to alleviate emerging problems with challenging separation conditions. We release the collection of preparation recipes for all datasets used to further promote research towards this challenging task.
Voice Cloning: a Multi-Speaker Text-to-Speech Synthesis Approach based on Transfer Learning
Feb 10, 2021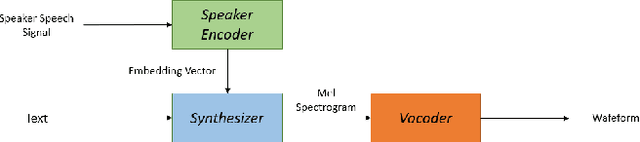
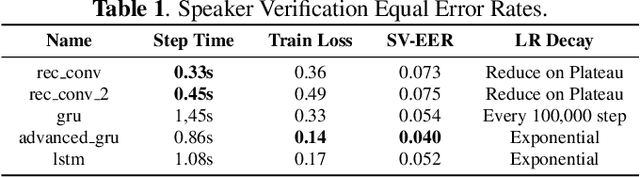
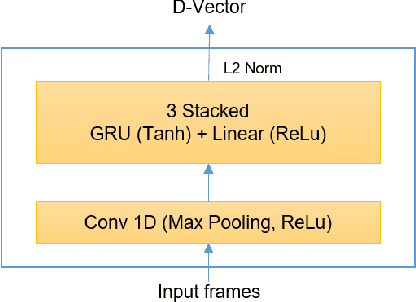
Deep learning models are becoming predominant in many fields of machine learning. Text-to-Speech (TTS), the process of synthesizing artificial speech from text, is no exception. To this end, a deep neural network is usually trained using a corpus of several hours of recorded speech from a single speaker. Trying to produce the voice of a speaker other than the one learned is expensive and requires large effort since it is necessary to record a new dataset and retrain the model. This is the main reason why the TTS models are usually single speaker. The proposed approach has the goal to overcome these limitations trying to obtain a system which is able to model a multi-speaker acoustic space. This allows the generation of speech audio similar to the voice of different target speakers, even if they were not observed during the training phase.
WAVPROMPT: Towards Few-Shot Spoken Language Understanding with Frozen Language Models
Apr 14, 2022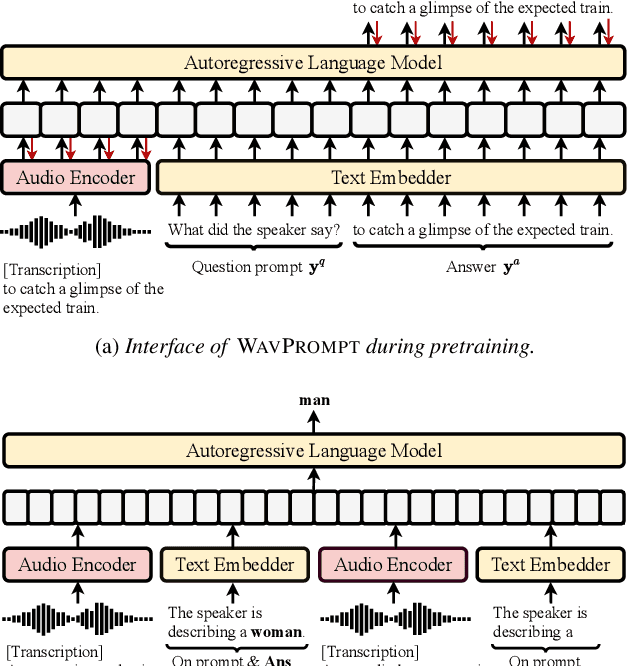

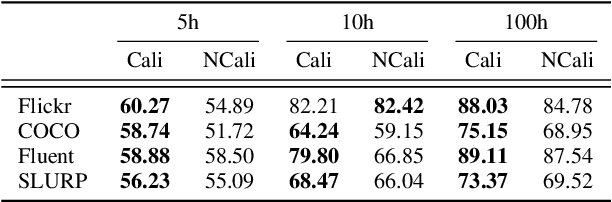
Large-scale auto-regressive language models pretrained on massive text have demonstrated their impressive ability to perform new natural language tasks with only a few text examples, without the need for fine-tuning. Recent studies further show that such a few-shot learning ability can be extended to the text-image setting by training an encoder to encode the images into embeddings functioning like the text embeddings of the language model. Interested in exploring the possibility of transferring the few-shot learning ability to the audio-text setting, we propose a novel speech understanding framework, WavPrompt, where we finetune a wav2vec model to generate a sequence of audio embeddings understood by the language model. We show that WavPrompt is a few-shot learner that can perform speech understanding tasks better than a naive text baseline. We conduct detailed ablation studies on different components and hyperparameters to empirically identify the best model configuration. In addition, we conduct a non-speech understanding experiment to show WavPrompt can extract more information than just the transcriptions. Code is available at https://github.com/Hertin/WavPrompt
Dual-branch Attention-In-Attention Transformer for single-channel speech enhancement
Nov 05, 2021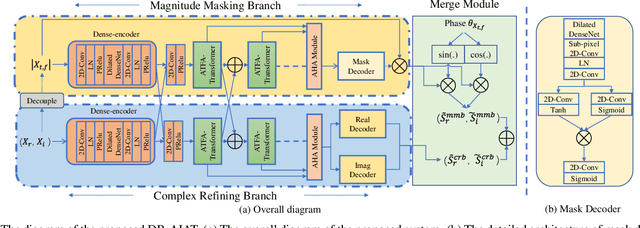
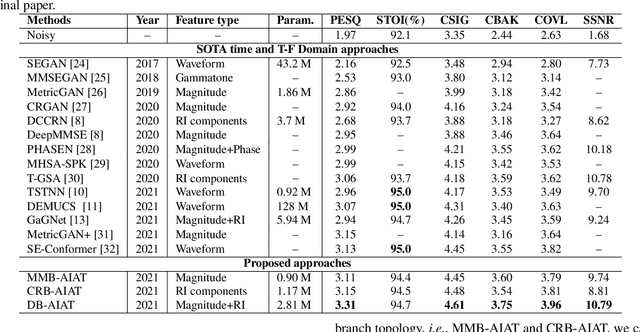
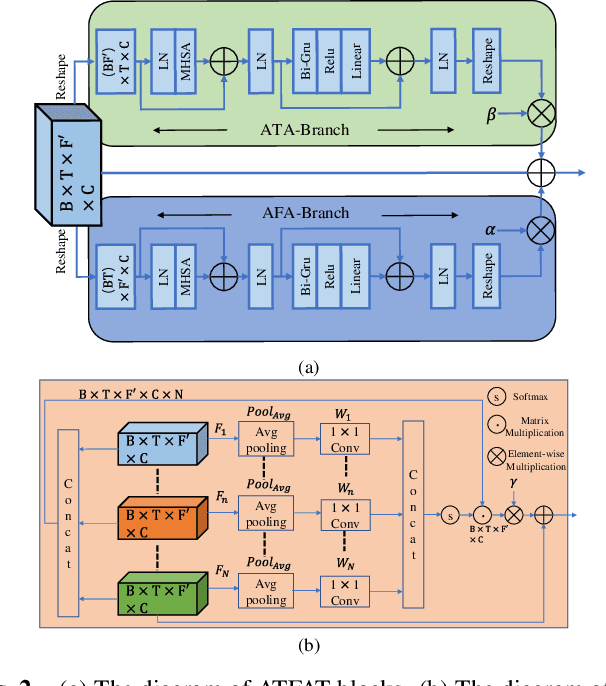
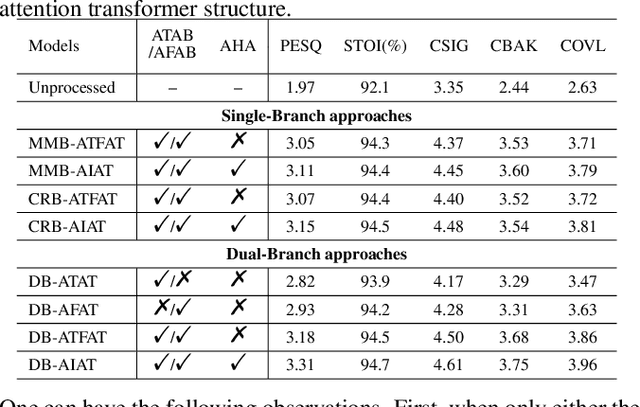
Curriculum learning begins to thrive in the speech enhancement area, which decouples the original spectrum estimation task into multiple easier sub-tasks to achieve better performance. Motivated by that, we propose a dual-branch attention-in-attention transformer dubbed DB-AIAT to handle both coarse- and fine-grained regions of the spectrum in parallel. From a complementary perspective, a magnitude masking branch is proposed to coarsely estimate the overall magnitude spectrum, and simultaneously a complex refining branch is elaborately designed to compensate for the missing spectral details and implicitly derive phase information. Within each branch, we propose a novel attention-in-attention transformer-based module to replace the conventional RNNs and temporal convolutional networks for temporal sequence modeling. Specifically, the proposed attention-in-attention transformer consists of adaptive temporal-frequency attention transformer blocks and an adaptive hierarchical attention module, aiming to capture long-term temporal-frequency dependencies and further aggregate global hierarchical contextual information. Experimental results on Voice Bank + DEMAND demonstrate that DB-AIAT yields state-of-the-art performance (e.g., 3.31 PESQ, 95.6% STOI and 10.79dB SSNR) over previous advanced systems with a relatively small model size (2.81M).
Speaker-Independent Microphone Identification in Noisy Conditions
Jun 23, 2022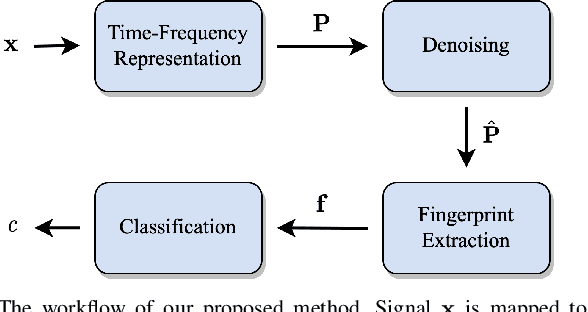
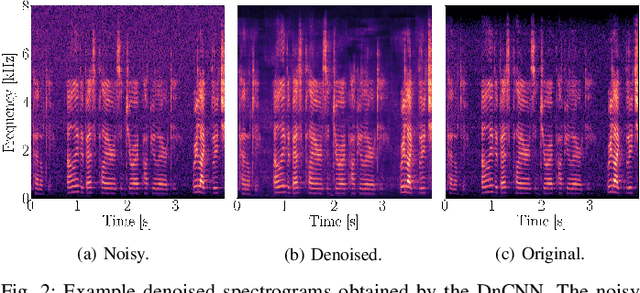
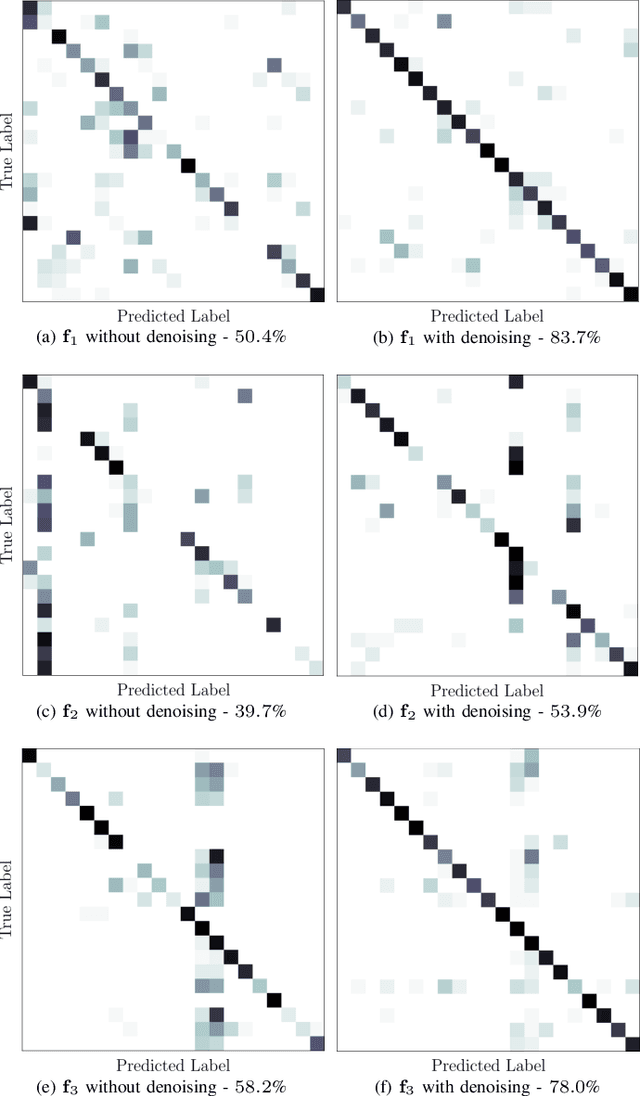
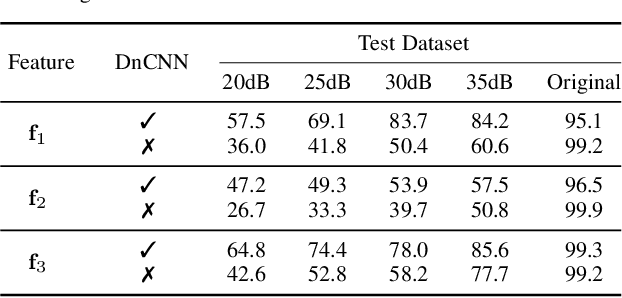
This work proposes a method for source device identification from speech recordings that applies neural-network-based denoising, to mitigate the impact of counter-forensics attacks using noise injection. The method is evaluated by comparing the impact of denoising on three state-of-the-art features for microphone classification, determining their discriminating power with and without denoising being applied. The proposed framework achieves a significant performance increase for noisy material, and more generally, validates the usefulness of applying denoising prior to device identification for noisy recordings.
Foster Strengths and Circumvent Weaknesses: a Speech Enhancement Framework with Two-branch Collaborative Learning
Oct 12, 2021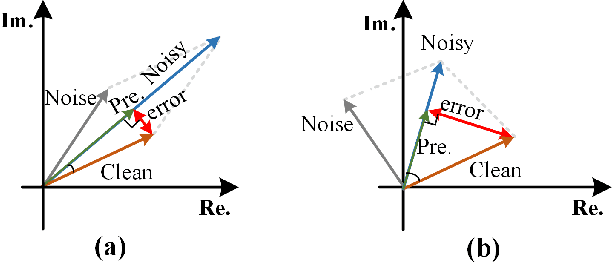
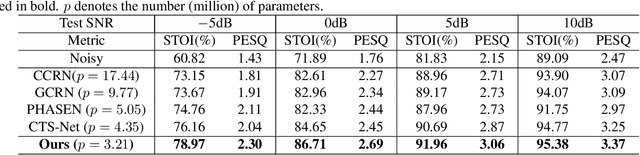
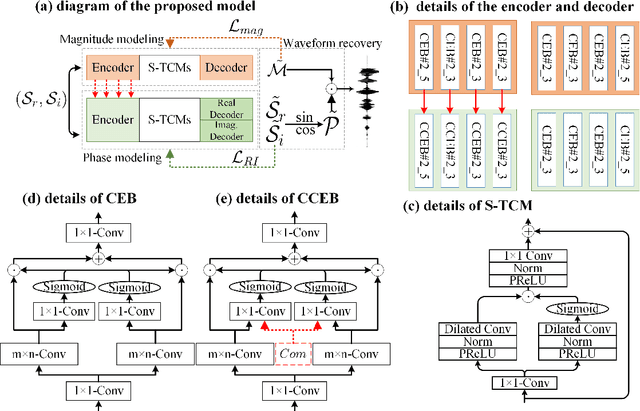
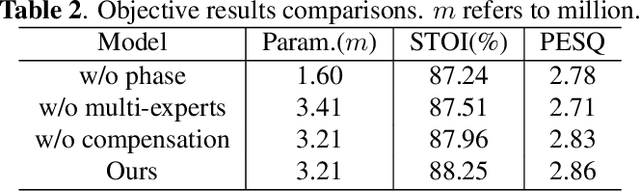
Recent single-channel speech enhancement methods usually convert waveform to the time-frequency domain and use magnitude/complex spectrum as the optimizing target. However, both magnitude-spectrum-based methods and complex-spectrum-based methods have their respective pros and cons. In this paper, we propose a unified two-branch framework to foster strengths and circumvent weaknesses of different paradigms. The proposed framework could take full advantage of the apparent spectral regularity in magnitude spectrogram and break the bottleneck that magnitude-based methods have suffered. Within each branch, we use collaborative expert block and its variants as substitutes for regular convolution layers. Experiments on TIMIT benchmark demonstrate that our method is superior to existing state-of-the-art ones.