 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Automatic Spoken Language Identification using a Time-Delay Neural Network
May 19, 2022
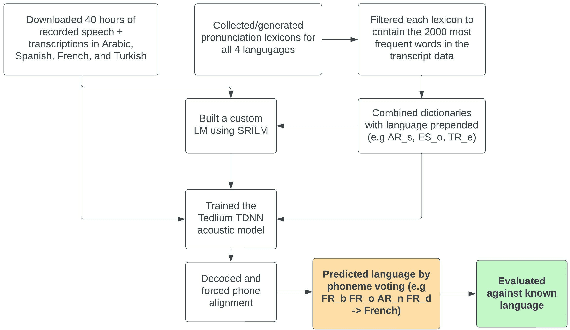



Closed-set spoken language identification is the task of recognizing the language being spoken in a recorded audio clip from a set of known languages. In this study, a language identification system was built and trained to distinguish between Arabic, Spanish, French, and Turkish based on nothing more than recorded speech. A pre-existing multilingual dataset was used to train a series of acoustic models based on the Tedlium TDNN model to perform automatic speech recognition. The system was provided with a custom multilingual language model and a specialized pronunciation lexicon with language names prepended to phones. The trained model was used to generate phone alignments to test data from all four languages, and languages were predicted based on a voting scheme choosing the most common language prepend in an utterance. Accuracy was measured by comparing predicted languages to known languages, and was determined to be very high in identifying Spanish and Arabic, and somewhat lower in identifying Turkish and French.
STYLER: Style Modeling with Rapidity and Robustness via SpeechDecomposition for Expressive and Controllable Neural Text to Speech
Mar 17, 2021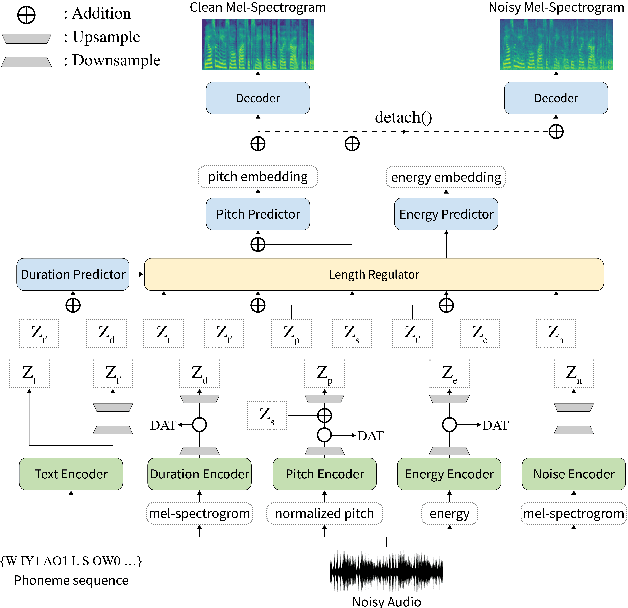
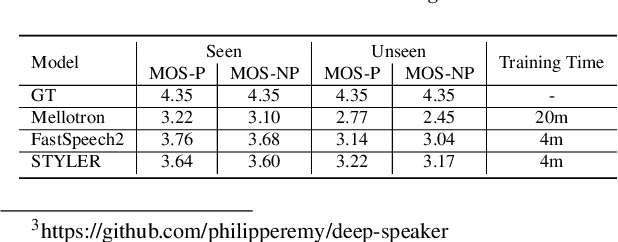
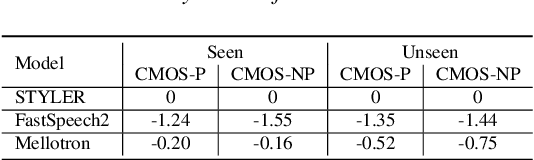
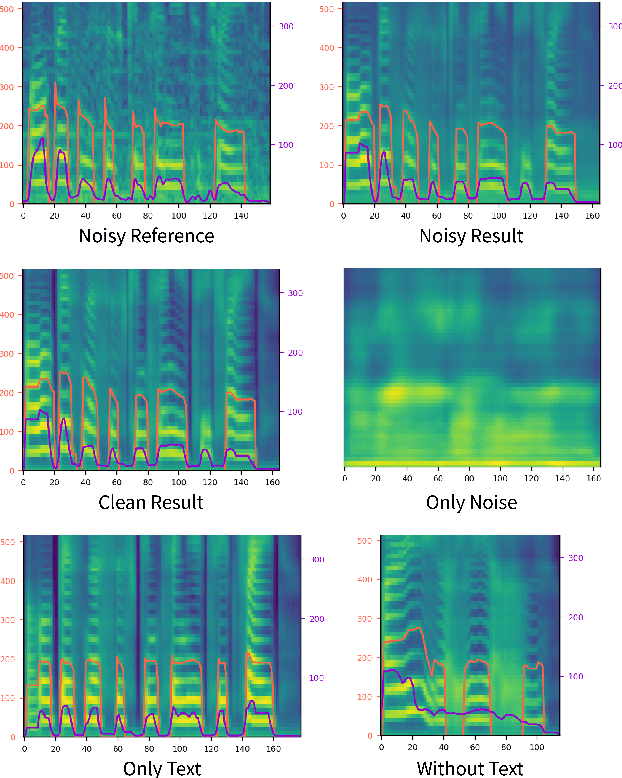
Previous works on expressive text-to-speech (TTS) have a limitation on robustness and speed when training and inferring. Such drawbacks mostly come from autoregressive decoding, which makes the succeeding step vulnerable to preceding error. To overcome this weakness, we propose STYLER, a novel expressive text-to-speech model with parallelized architecture. Expelling autoregressive decoding and introducing speech decomposition for encoding enables speech synthesis more robust even with high style transfer performance. Moreover, our novel noise modeling approach from audio using domain adversarial training and Residual Decoding enabled style transfer without transferring noise. Our experiments prove the naturalness and expressiveness of our model from comparison with other parallel TTS models. Together we investigate our model's robustness and speed by comparison with the expressive TTS model with autoregressive decoding.
3D Convolutional Neural Networks for Ultrasound-Based Silent Speech Interfaces
Apr 23, 2021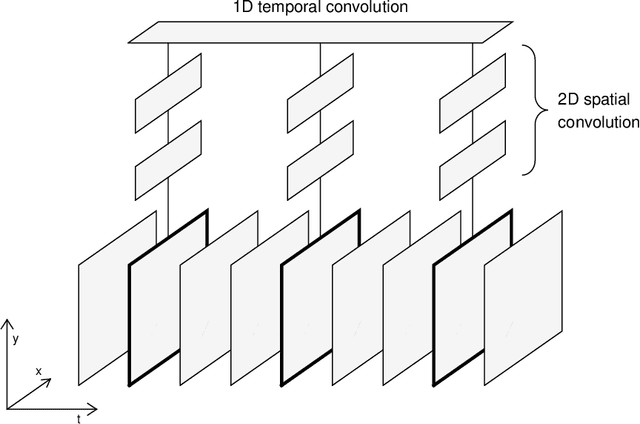
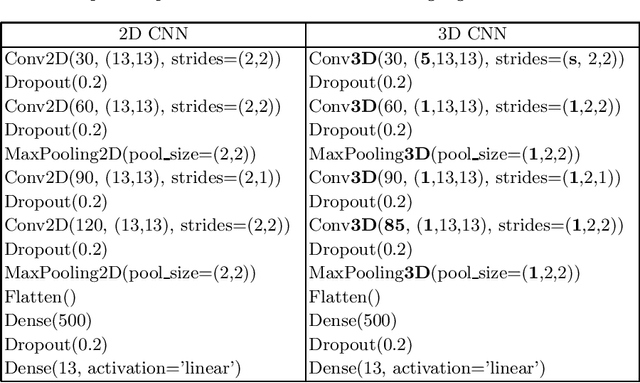

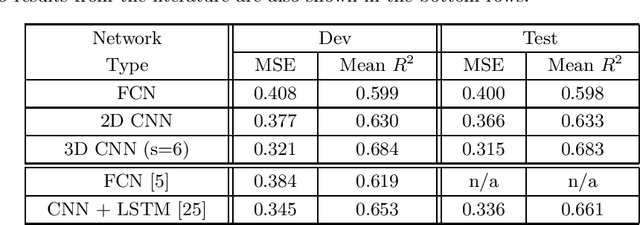
Silent speech interfaces (SSI) aim to reconstruct the speech signal from a recording of the articulatory movement, such as an ultrasound video of the tongue. Currently, deep neural networks are the most successful technology for this task. The efficient solution requires methods that do not simply process single images, but are able to extract the tongue movement information from a sequence of video frames. One option for this is to apply recurrent neural structures such as the long short-term memory network (LSTM) in combination with 2D convolutional neural networks (CNNs). Here, we experiment with another approach that extends the CNN to perform 3D convolution, where the extra dimension corresponds to time. In particular, we apply the spatial and temporal convolutions in a decomposed form, which proved very successful recently in video action recognition. We find experimentally that our 3D network outperforms the CNN+LSTM model, indicating that 3D CNNs may be a feasible alternative to CNN+LSTM networks in SSI systems.
Unsupervised Pattern Discovery from Thematic Speech Archives Based on Multilingual Bottleneck Features
Nov 03, 2020
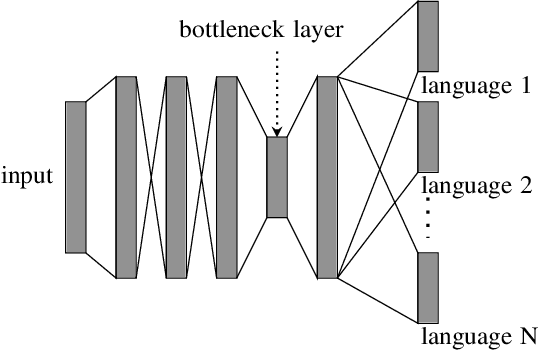
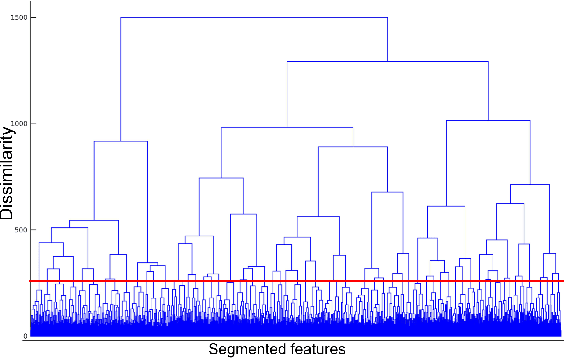
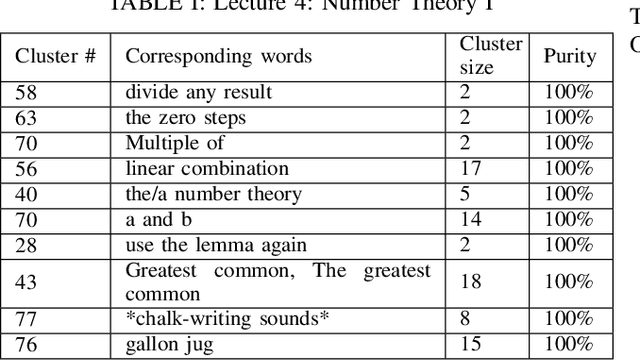
The present study tackles the problem of automatically discovering spoken keywords from untranscribed audio archives without requiring word-by-word speech transcription by automatic speech recognition (ASR) technology. The problem is of practical significance in many applications of speech analytics, including those concerning low-resource languages, and large amount of multilingual and multi-genre data. We propose a two-stage approach, which comprises unsupervised acoustic modeling and decoding, followed by pattern mining in acoustic unit sequences. The whole process starts by deriving and modeling a set of subword-level speech units with untranscribed data. With the unsupervisedly trained acoustic models, a given audio archive is represented by a pseudo transcription, from which spoken keywords can be discovered by string mining algorithms. For unsupervised acoustic modeling, a deep neural network trained by multilingual speech corpora is used to generate speech segmentation and compute bottleneck features for segment clustering. Experimental results show that the proposed system is able to effectively extract topic-related words and phrases from the lecture recordings on MIT OpenCourseWare.
Almost Unsupervised Text to Speech and Automatic Speech Recognition
May 22, 2019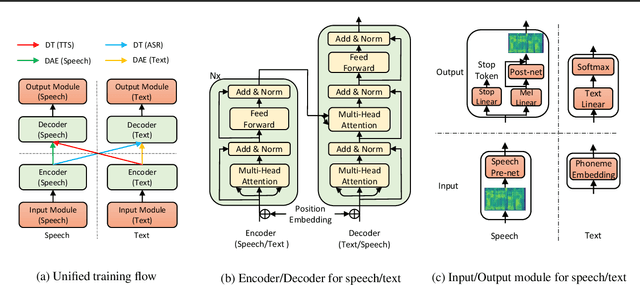
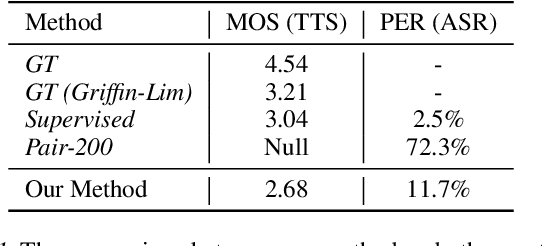
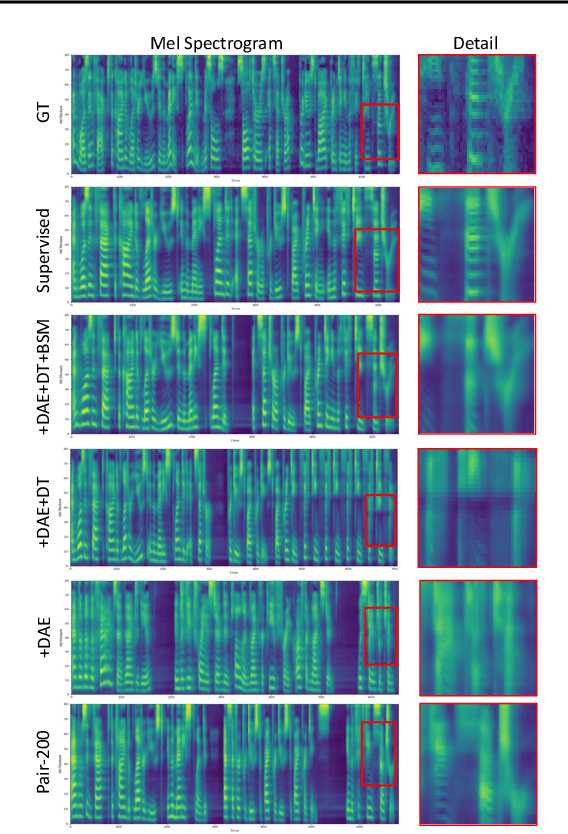

Text to speech (TTS) and automatic speech recognition (ASR) are two dual tasks in speech processing and both achieve impressive performance thanks to the recent advance in deep learning and large amount of aligned speech and text data. However, the lack of aligned data poses a major practical problem for TTS and ASR on low-resource languages. In this paper, by leveraging the dual nature of the two tasks, we propose an almost unsupervised learning method that only leverages few hundreds of paired data and extra unpaired data for TTS and ASR. Our method consists of the following components: (1) a denoising auto-encoder, which reconstructs speech and text sequences respectively to develop the capability of language modeling both in speech and text domain; (2) dual transformation, where the TTS model transforms the text $y$ into speech $\hat{x}$, and the ASR model leverages the transformed pair $(\hat{x},y)$ for training, and vice versa, to boost the accuracy of the two tasks; (3) bidirectional sequence modeling, which addresses error propagation especially in the long speech and text sequence when training with few paired data; (4) a unified model structure, which combines all the above components for TTS and ASR based on Transformer model. Our method achieves 99.84% in terms of word level intelligible rate and 2.68 MOS for TTS, and 11.7% PER for ASR on LJSpeech dataset, by leveraging only 200 paired speech and text data (about 20 minutes audio), together with extra unpaired speech and text data.
ESPnet-ST: All-in-One Speech Translation Toolkit
Apr 21, 2020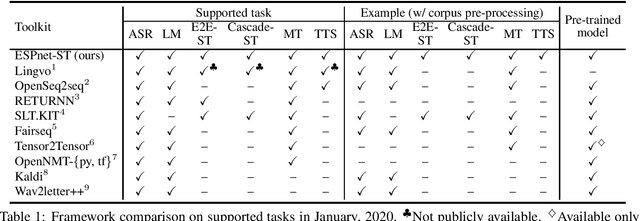
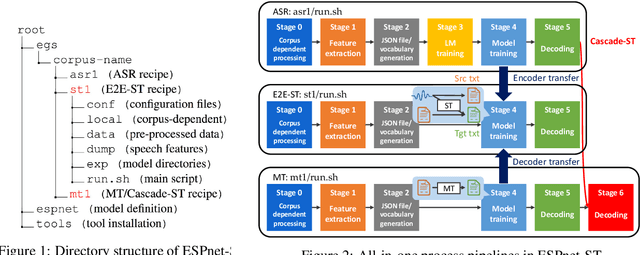


We present ESPnet-ST, which is designed for the quick development of speech-to-speech translation systems in a single framework. ESPnet-ST is a new project inside end-to-end speech processing toolkit, ESPnet, which integrates or newly implements automatic speech recognition, machine translation, and text-to-speech functions for speech translation. We provide all-in-one recipes including data pre-processing, feature extraction, training, and decoding pipelines for a wide range of benchmark datasets. Our reproducible results can match or even outperform the current state-of-the-art performances; these pre-trained models are downloadable. The toolkit is publicly available at https://github.com/espnet/espnet.
SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network
Apr 05, 2021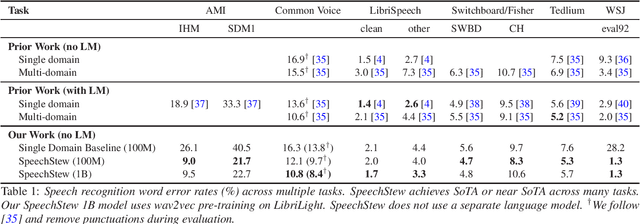
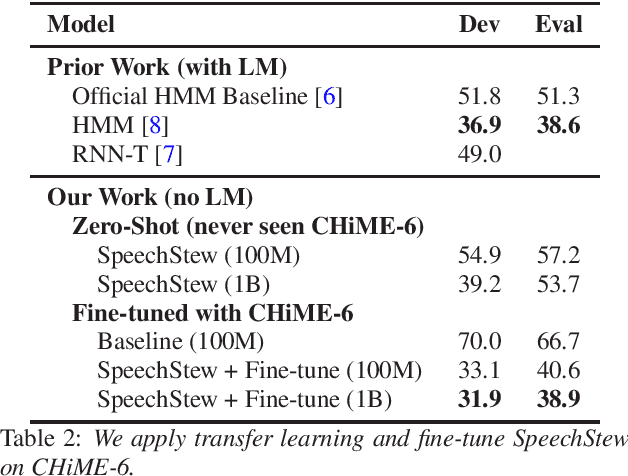
We present SpeechStew, a speech recognition model that is trained on a combination of various publicly available speech recognition datasets: AMI, Broadcast News, Common Voice, LibriSpeech, Switchboard/Fisher, Tedlium, and Wall Street Journal. SpeechStew simply mixes all of these datasets together, without any special re-weighting or re-balancing of the datasets. SpeechStew achieves SoTA or near SoTA results across a variety of tasks, without the use of an external language model. Our results include 9.0\% WER on AMI-IHM, 4.7\% WER on Switchboard, 8.3\% WER on CallHome, and 1.3\% on WSJ, which significantly outperforms prior work with strong external language models. We also demonstrate that SpeechStew learns powerful transfer learning representations. We fine-tune SpeechStew on a noisy low resource speech dataset, CHiME-6. We achieve 38.9\% WER without a language model, which compares to 38.6\% WER to a strong HMM baseline with a language model.
Information Sieve: Content Leakage Reduction in End-to-End Prosody For Expressive Speech Synthesis
Aug 04, 2021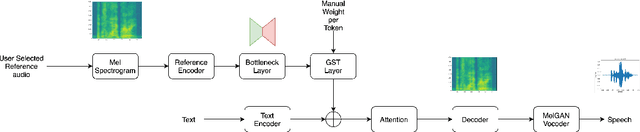
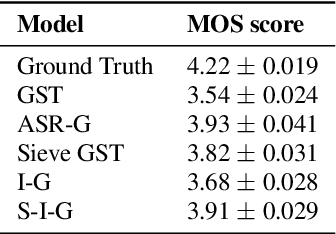
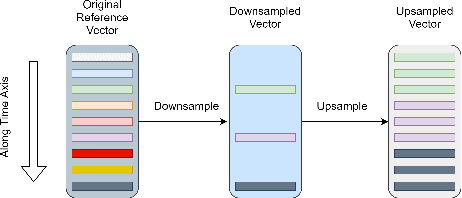
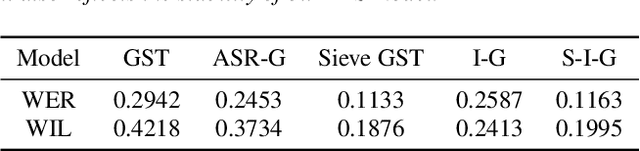
Expressive neural text-to-speech (TTS) systems incorporate a style encoder to learn a latent embedding as the style information. However, this embedding process may encode redundant textual information. This phenomenon is called content leakage. Researchers have attempted to resolve this problem by adding an ASR or other auxiliary supervision loss functions. In this study, we propose an unsupervised method called the "information sieve" to reduce the effect of content leakage in prosody transfer. The rationale of this approach is that the style encoder can be forced to focus on style information rather than on textual information contained in the reference speech by a well-designed downsample-upsample filter, i.e., the extracted style embeddings can be downsampled at a certain interval and then upsampled by duplication. Furthermore, we used instance normalization in convolution layers to help the system learn a better latent style space. Objective metrics such as the significantly lower word error rate (WER) demonstrate the effectiveness of this model in mitigating content leakage. Listening tests indicate that the model retains its prosody transferability compared with the baseline models such as the original GST-Tacotron and ASR-guided Tacotron.
Amortized Neural Networks for Low-Latency Speech Recognition
Aug 03, 2021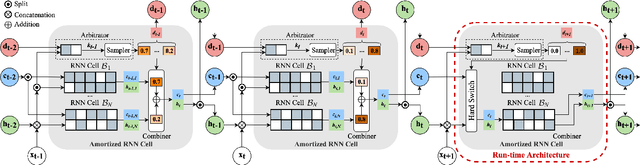
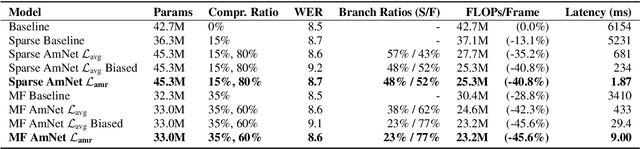
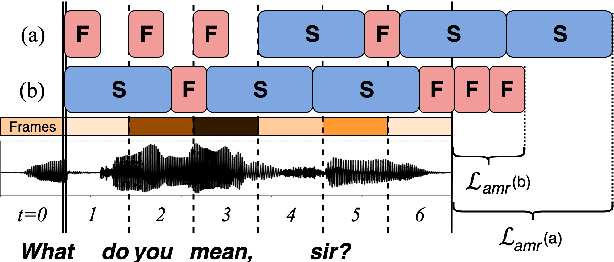
We introduce Amortized Neural Networks (AmNets), a compute cost- and latency-aware network architecture particularly well-suited for sequence modeling tasks. We apply AmNets to the Recurrent Neural Network Transducer (RNN-T) to reduce compute cost and latency for an automatic speech recognition (ASR) task. The AmNets RNN-T architecture enables the network to dynamically switch between encoder branches on a frame-by-frame basis. Branches are constructed with variable levels of compute cost and model capacity. Here, we achieve variable compute for two well-known candidate techniques: one using sparse pruning and the other using matrix factorization. Frame-by-frame switching is determined by an arbitrator network that requires negligible compute overhead. We present results using both architectures on LibriSpeech data and show that our proposed architecture can reduce inference cost by up to 45\% and latency to nearly real-time without incurring a loss in accuracy.
TalkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Prediction
Apr 19, 2021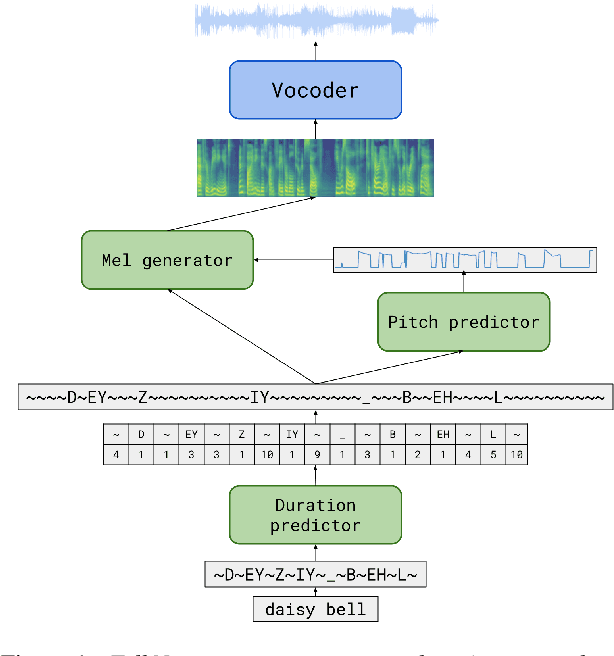
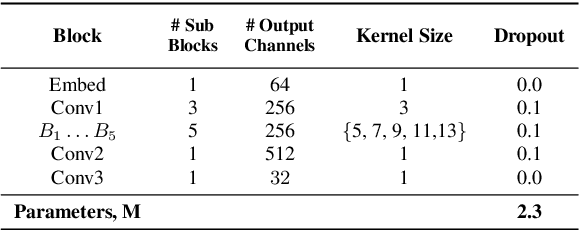
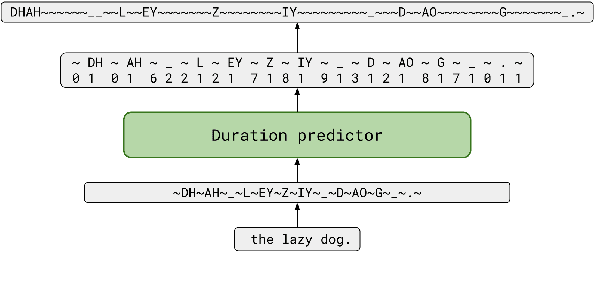
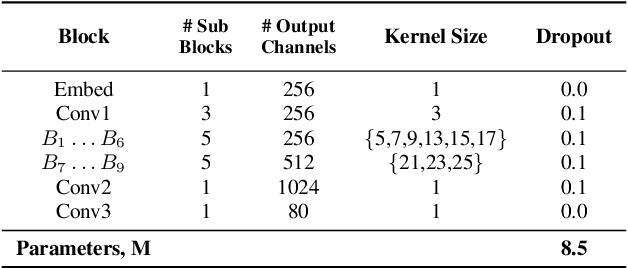
We propose TalkNet, a non-autoregressive convolutional neural model for speech synthesis with explicit pitch and duration prediction. The model consists of three feed-forward convolutional networks. The first network predicts grapheme durations. An input text is expanded by repeating each symbol according to the predicted duration. The second network predicts pitch value for every mel frame. The third network generates a mel-spectrogram from the expanded text conditioned on predicted pitch. All networks are based on 1D depth-wise separable convolutional architecture. The explicit duration prediction eliminates word skipping and repeating. The quality of the generated speech nearly matches the best auto-regressive models - TalkNet trained on the LJSpeech dataset got MOS4.08. The model has only 13.2M parameters, almost 2x less than the present state-of-the-art text-to-speech models. The non-autoregressive architecture allows for fast training and inference - 422x times faster than real-time. The small model size and fast inference make the TalkNet an attractive candidate for embedded speech synthesis.