 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Knowledge-based Analogical Reasoning in Neuro-symbolic Latent Spaces
Sep 19, 2022
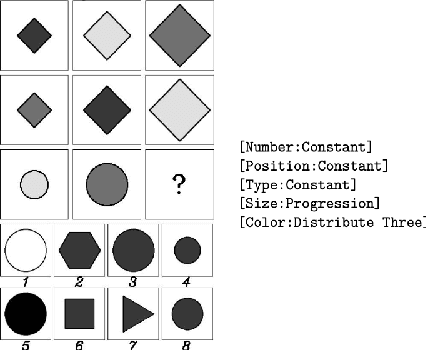
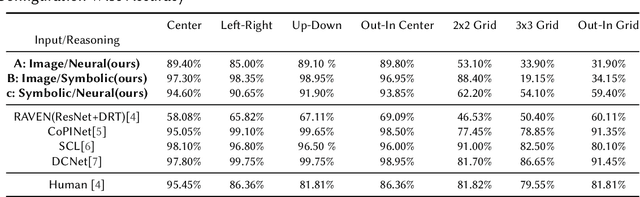
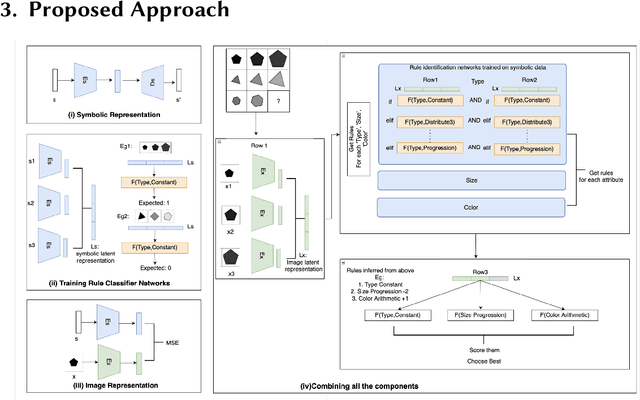
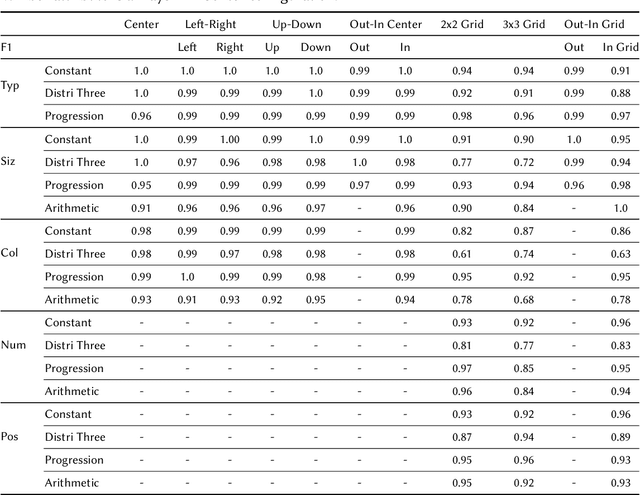
Analogical Reasoning problems challenge both connectionist and symbolic AI systems as these entail a combination of background knowledge, reasoning and pattern recognition. While symbolic systems ingest explicit domain knowledge and perform deductive reasoning, they are sensitive to noise and require inputs be mapped to preset symbolic features. Connectionist systems on the other hand can directly ingest rich input spaces such as images, text or speech and recognize pattern even with noisy inputs. However, connectionist models struggle to include explicit domain knowledge for deductive reasoning. In this paper, we propose a framework that combines the pattern recognition abilities of neural networks with symbolic reasoning and background knowledge for solving a class of Analogical Reasoning problems where the set of attributes and possible relations across them are known apriori. We take inspiration from the 'neural algorithmic reasoning' approach [DeepMind 2020] and use problem-specific background knowledge by (i) learning a distributed representation based on a symbolic model of the problem (ii) training neural-network transformations reflective of the relations involved in the problem and finally (iii) training a neural network encoder from images to the distributed representation in (i). These three elements enable us to perform search-based reasoning using neural networks as elementary functions manipulating distributed representations. We test this on visual analogy problems in RAVENs Progressive Matrices, and achieve accuracy competitive with human performance and, in certain cases, superior to initial end-to-end neural-network based approaches. While recent neural models trained at scale yield SOTA, our novel neuro-symbolic reasoning approach is a promising direction for this problem, and is arguably more general, especially for problems where domain knowledge is available.
Speaker Recognition in the Wild
May 05, 2022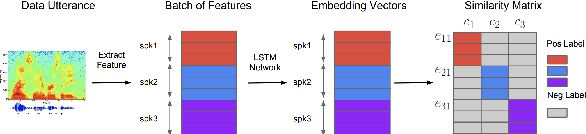

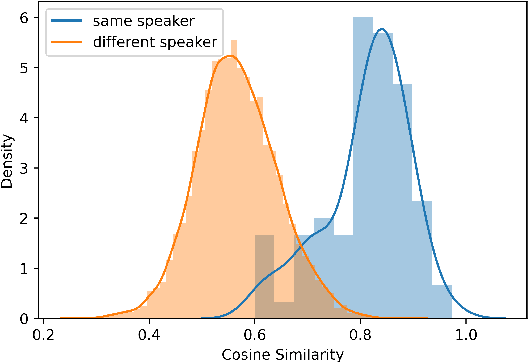
In this paper, we propose a pipeline to find the number of speakers, as well as audios belonging to each of these now identified speakers in a source of audio data where number of speakers or speaker labels are not known a priori. We used this approach as a part of our Data Preparation pipeline for Speech Recognition in Indic Languages (https://github.com/Open-Speech-EkStep/vakyansh-wav2vec2-experimentation). To understand and evaluate the accuracy of our proposed pipeline, we introduce two metrics: Cluster Purity, and Cluster Uniqueness. Cluster Purity quantifies how "pure" a cluster is. Cluster Uniqueness, on the other hand, quantifies what percentage of clusters belong only to a single dominant speaker. We discuss more on these metrics in section \ref{sec:metrics}. Since we develop this utility to aid us in identifying data based on speaker IDs before training an Automatic Speech Recognition (ASR) model, and since most of this data takes considerable effort to scrape, we also conclude that 98\% of data gets mapped to the top 80\% of clusters (computed by removing any clusters with less than a fixed number of utterances -- we do this to get rid of some very small clusters and use this threshold as 30), in the test set chosen.
MFFCN: Multi-layer Feature Fusion Convolution Network for Audio-visual Speech Enhancement
Jan 15, 2021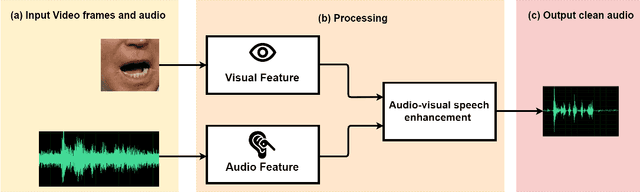
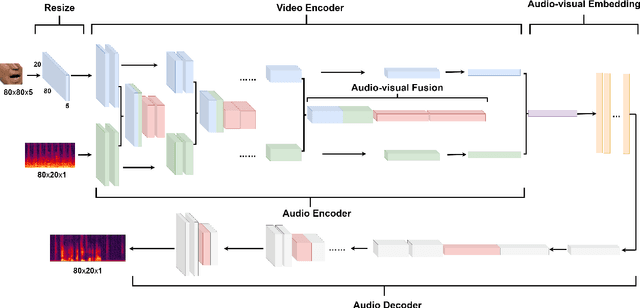
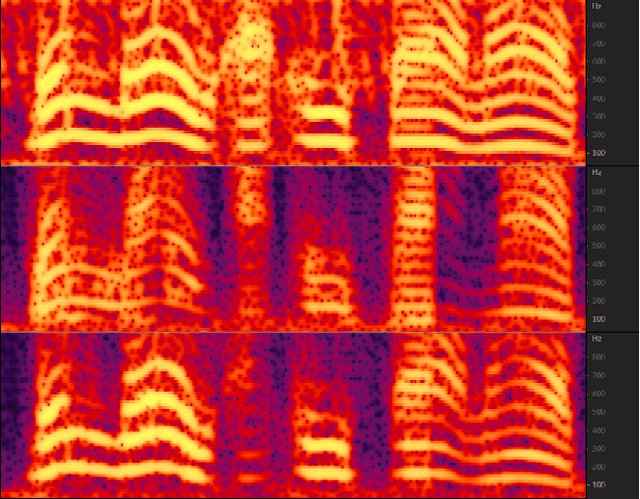
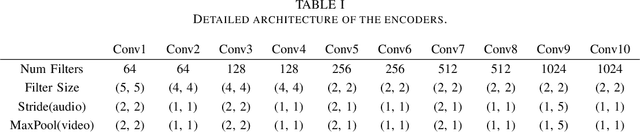
The purpose of speech enhancement is to extract target speech signal from a mixture of sounds generated from several sources. Speech enhancement can potentially benefit from the visual information from the target speaker, such as lip move-ment and facial expressions, because the visual aspect of speech isessentially unaffected by acoustic environment. In order to fuse audio and visual information, an audio-visual fusion strategy is proposed, which goes beyond simple feature concatenation and learns to automatically align the two modalities, leading to more powerful representation which increase intelligibility in noisy conditions. The proposed model fuses audio-visual featureslayer by layer, and feed these audio-visual features to each corresponding decoding layer. Experiment results show relative improvement from 6% to 24% on test sets over the audio modalityalone, depending on audio noise level. Moreover, there is a significant increase of PESQ from 1.21 to 2.06 in our -15 dB SNR experiment.
Mobile Microphone Array Speech Detection and Localization in Diverse Everyday Environments
Jun 28, 2021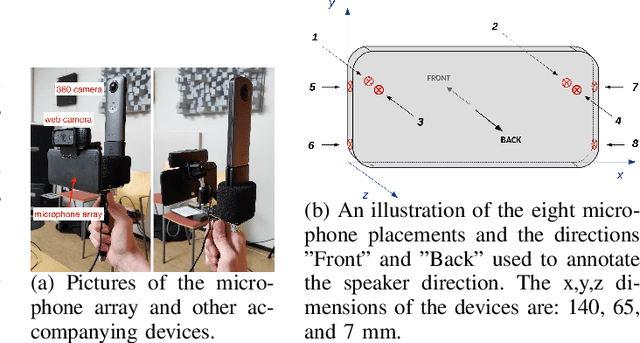
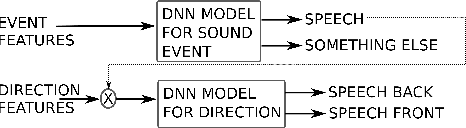
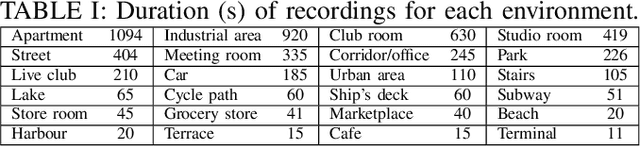
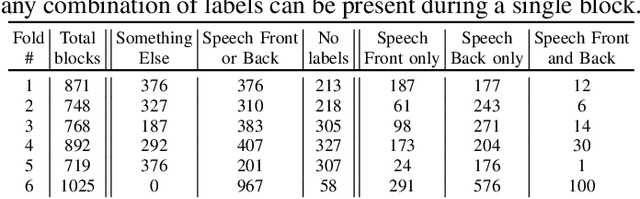
Joint sound event localization and detection (SELD) is an integral part of developing context awareness into communication interfaces of mobile robots, smartphones, and home assistants. For example, an automatic audio focus for video capture on a mobile phone requires robust detection of relevant acoustic events around the device and their direction. Existing SELD approaches have been evaluated using material produced in controlled indoor environments, or the audio is simulated by mixing isolated sounds to different spatial locations. This paper studies SELD of speech in diverse everyday environments, where the audio corresponds to typical usage scenarios of handheld mobile devices. In order to allow weighting the relative importance of localization vs. detection, we will propose a two-stage hierarchical system, where the first stage is to detect the target events, and the second stage is to localize them. The proposed method utilizes convolutional recurrent neural network (CRNN) and is evaluated on a database of manually annotated microphone array recordings from various acoustic conditions. The array is embedded in a contemporary mobile phone form factor. The obtained results show good speech detection and localization accuracy of the proposed method in contrast to a non-hierarchical flat classification model.
Attentive activation function for improving end-to-end spoofing countermeasure systems
May 03, 2022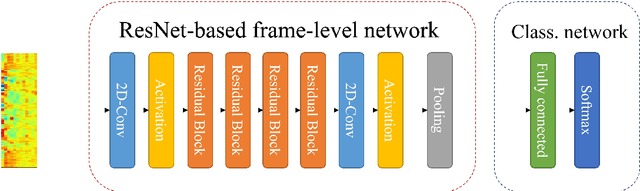
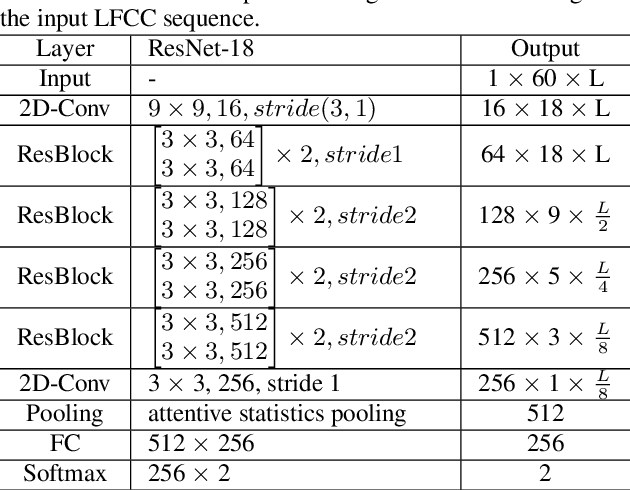
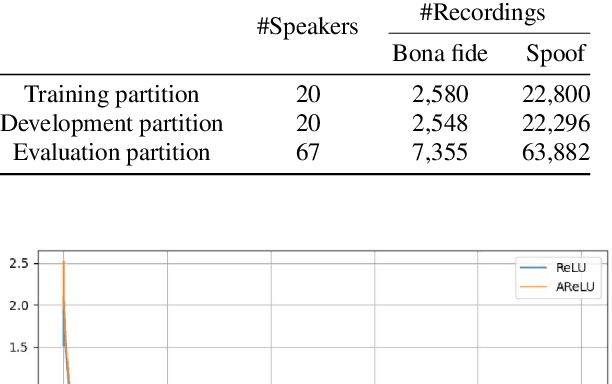
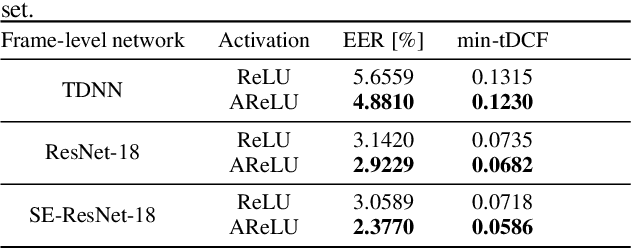
The main objective of the spoofing countermeasure system is to detect the artifacts within the input speech caused by the speech synthesis or voice conversion process. In order to achieve this, we propose to adopt an attentive activation function, more specifically attention rectified linear unit (AReLU) to the end-to-end spoofing countermeasure system. Since the AReLU employs the attention mechanism to boost the contribution of relevant input features while suppressing the irrelevant ones, introducing AReLU can help the countermeasure system to focus on the features related to the artifacts. The proposed framework was experimented on the logical access (LA) task of ASVSpoof2019 dataset, and outperformed the systems using the standard non-learnable activation functions.
Attention-based distributed speech enhancement for unconstrained microphone arrays with varying number of nodes
Jun 15, 2021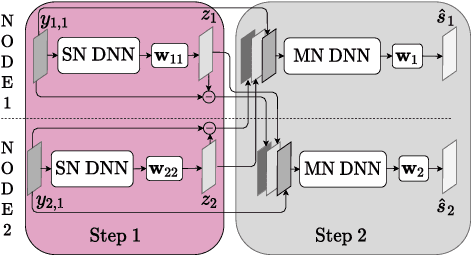
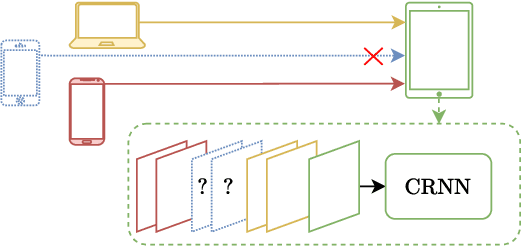
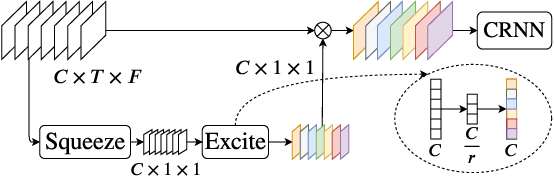
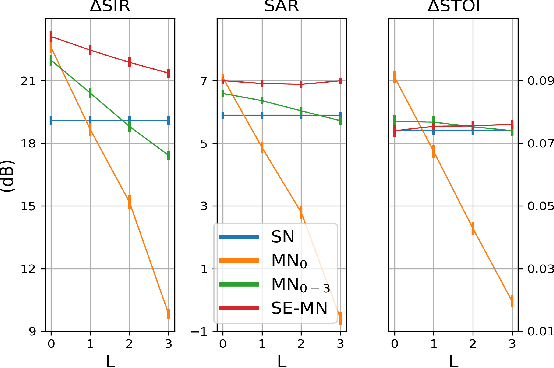
Speech enhancement promises higher efficiency in ad-hoc microphone arrays than in constrained microphone arrays thanks to the wide spatial coverage of the devices in the acoustic scene. However, speech enhancement in ad-hoc microphone arrays still raises many challenges. In particular, the algorithms should be able to handle a variable number of microphones, as some devices in the array might appear or disappear. In this paper, we propose a solution that can efficiently process the spatial information captured by the different devices of the microphone array, while being robust to a link failure. To do this, we use an attention mechanism in order to put more weight on the relevant signals sent throughout the array and to neglect the redundant or empty channels.
Reproducibility Report: Contextualizing Hate Speech Classifiers with Post-hoc Explanation
May 24, 2021

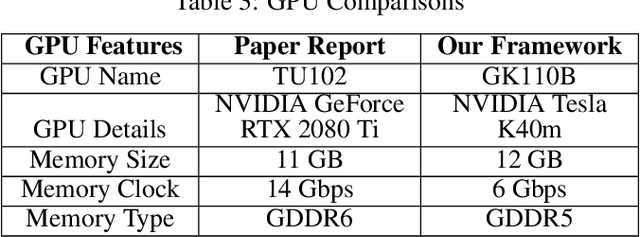
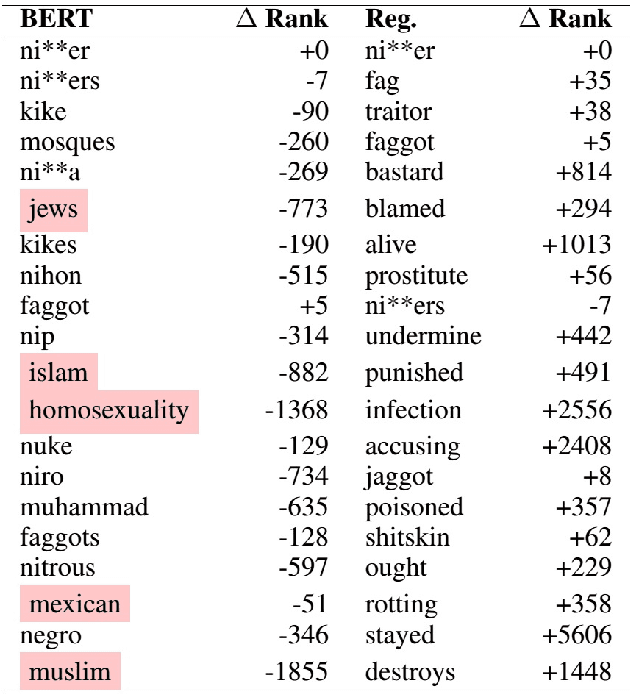
The presented report evaluates Contextualizing Hate Speech Classifiers with Post-hoc Explanation paper within the scope of ML Reproducibility Challenge 2020. Our work focuses on both aspects constituting the paper: the method itself and the validity of the stated results. In the following sections, we have described the paper, related works, algorithmic frameworks, our experiments and evaluations.
Streaming Simultaneous Speech Translation with Augmented Memory Transformer
Oct 30, 2020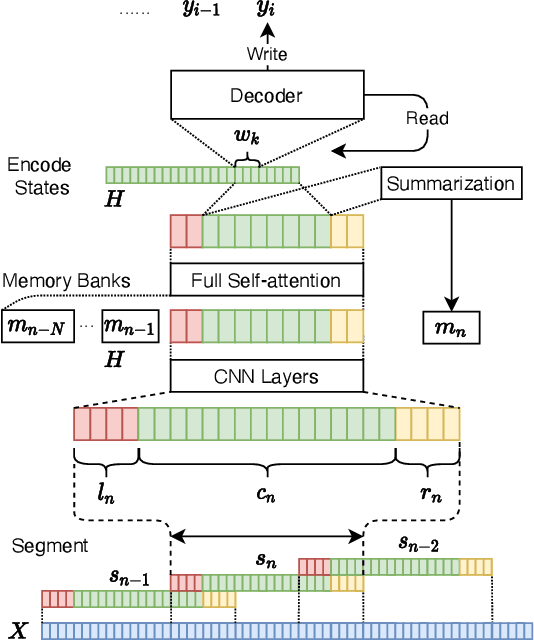
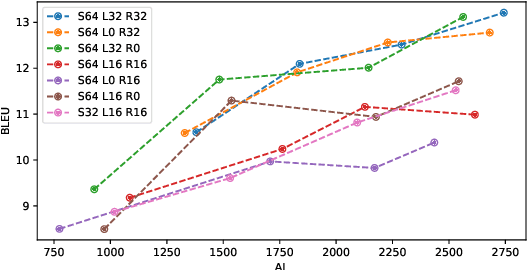
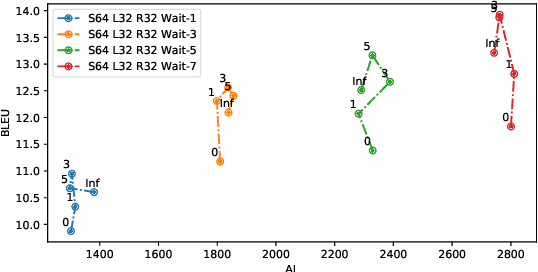
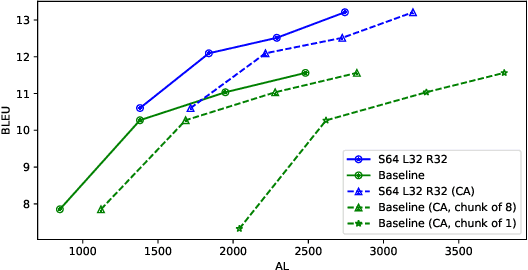
Transformer-based models have achieved state-of-the-art performance on speech translation tasks. However, the model architecture is not efficient enough for streaming scenarios since self-attention is computed over an entire input sequence and the computational cost grows quadratically with the length of the input sequence. Nevertheless, most of the previous work on simultaneous speech translation, the task of generating translations from partial audio input, ignores the time spent in generating the translation when analyzing the latency. With this assumption, a system may have good latency quality trade-offs but be inapplicable in real-time scenarios. In this paper, we focus on the task of streaming simultaneous speech translation, where the systems are not only capable of translating with partial input but are also able to handle very long or continuous input. We propose an end-to-end transformer-based sequence-to-sequence model, equipped with an augmented memory transformer encoder, which has shown great success on the streaming automatic speech recognition task with hybrid or transducer-based models. We conduct an empirical evaluation of the proposed model on segment, context and memory sizes and we compare our approach to a transformer with a unidirectional mask.
Incorporating Broad Phonetic Information for Speech Enhancement
Aug 13, 2020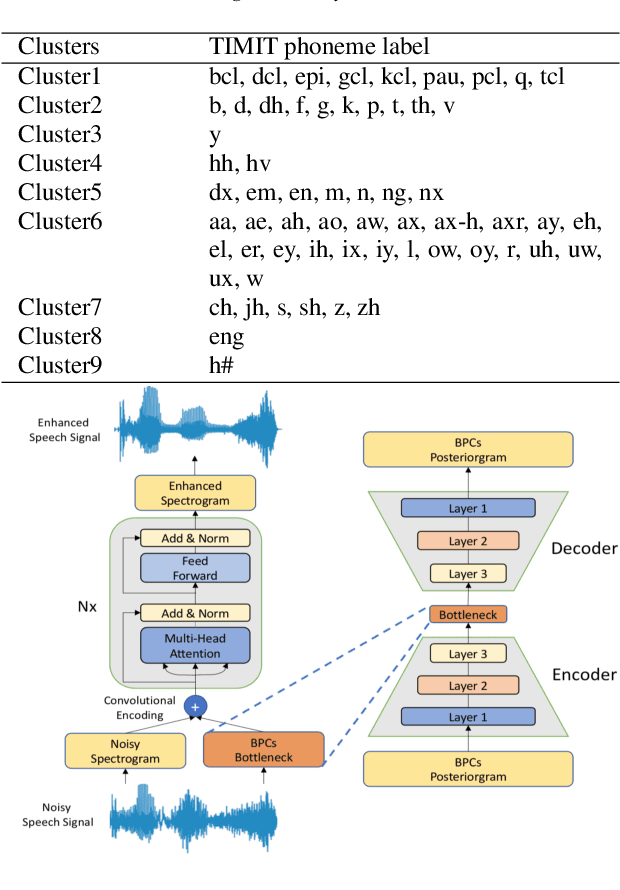
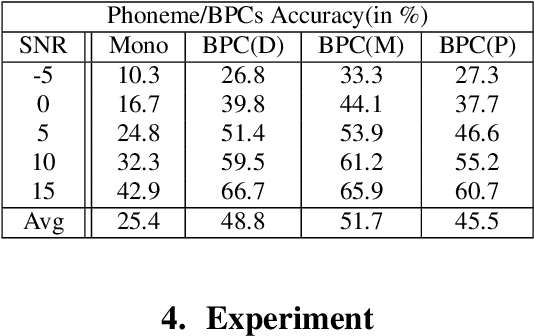
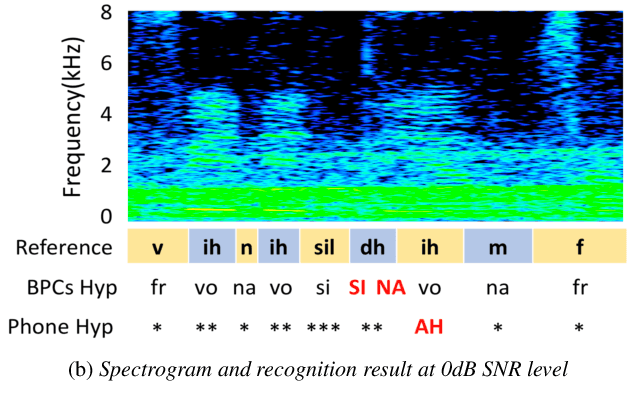

In noisy conditions, knowing speech contents facilitates listeners to more effectively suppress background noise components and to retrieve pure speech signals. Previous studies have also confirmed the benefits of incorporating phonetic information in a speech enhancement (SE) system to achieve better denoising performance. To obtain the phonetic information, we usually prepare a phoneme-based acoustic model, which is trained using speech waveforms and phoneme labels. Despite performing well in normal noisy conditions, when operating in very noisy conditions, however, the recognized phonemes may be erroneous and thus misguide the SE process. To overcome the limitation, this study proposes to incorporate the broad phonetic class (BPC) information into the SE process. We have investigated three criteria to build the BPC, including two knowledge-based criteria: place and manner of articulatory and one data-driven criterion. Moreover, the recognition accuracies of BPCs are much higher than that of phonemes, thus providing more accurate phonetic information to guide the SE process under very noisy conditions. Experimental results demonstrate that the proposed SE with the BPC information framework can achieve notable performance improvements over the baseline system and an SE system using monophonic information in terms of both speech quality intelligibility on the TIMIT dataset.
KazakhTTS: An Open-Source Kazakh Text-to-Speech Synthesis Dataset
Apr 26, 2021
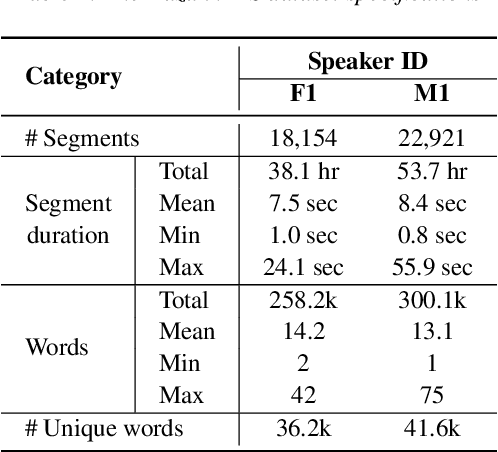
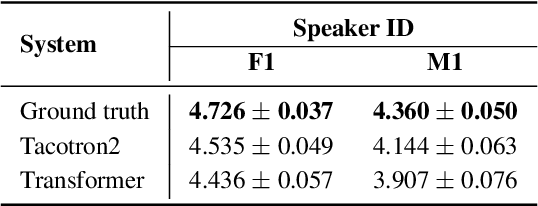
This paper introduces a high-quality open-source speech synthesis dataset for Kazakh, a low-resource language spoken by over 13 million people worldwide. The dataset consists of about 93 hours of transcribed audio recordings spoken by two professional speakers (female and male). It is the first publicly available large-scale dataset developed to promote Kazakh text-to-speech (TTS) applications in both academia and industry. In this paper, we share our experience by describing the dataset development procedures and faced challenges, and discuss important future directions. To demonstrate the reliability of our dataset, we built baseline end-to-end TTS models and evaluated them using the subjective mean opinion score (MOS) measure. Evaluation results show that the best TTS models trained on our dataset achieve MOS above 4 for both speakers, which makes them applicable for practical use. The dataset, training recipe, and pretrained TTS models are freely available.