 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network
Apr 27, 2021
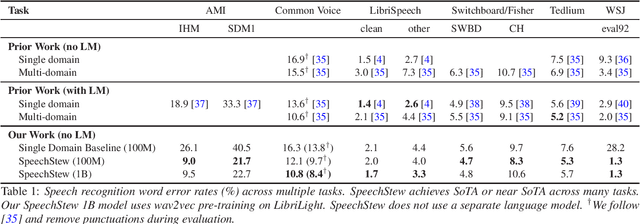
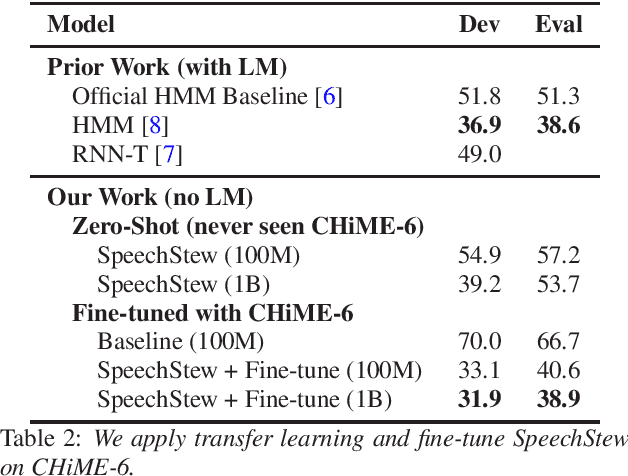
We present SpeechStew, a speech recognition model that is trained on a combination of various publicly available speech recognition datasets: AMI, Broadcast News, Common Voice, LibriSpeech, Switchboard/Fisher, Tedlium, and Wall Street Journal. SpeechStew simply mixes all of these datasets together, without any special re-weighting or re-balancing of the datasets. SpeechStew achieves SoTA or near SoTA results across a variety of tasks, without the use of an external language model. Our results include 9.0\% WER on AMI-IHM, 4.7\% WER on Switchboard, 8.3\% WER on CallHome, and 1.3\% on WSJ, which significantly outperforms prior work with strong external language models. We also demonstrate that SpeechStew learns powerful transfer learning representations. We fine-tune SpeechStew on a noisy low resource speech dataset, CHiME-6. We achieve 38.9\% WER without a language model, which compares to 38.6\% WER to a strong HMM baseline with a language model.
End-to-End Speech Recognition and Disfluency Removal
Sep 28, 2020

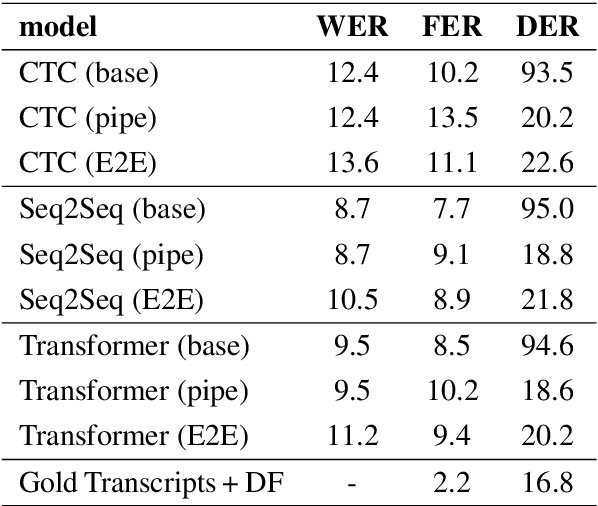
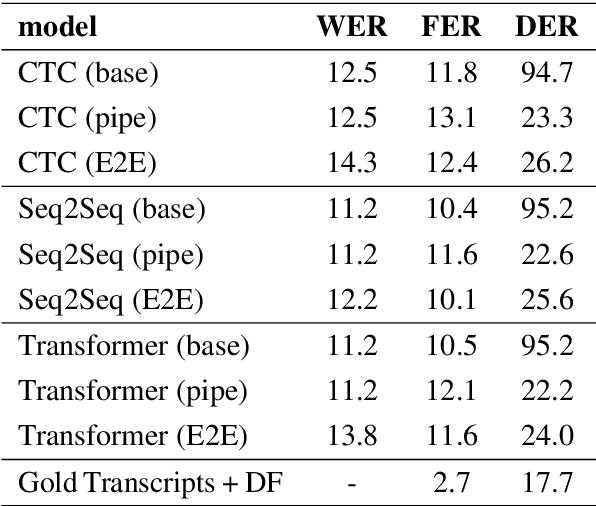
Disfluency detection is usually an intermediate step between an automatic speech recognition (ASR) system and a downstream task. By contrast, this paper aims to investigate the task of end-to-end speech recognition and disfluency removal. We specifically explore whether it is possible to train an ASR model to directly map disfluent speech into fluent transcripts, without relying on a separate disfluency detection model. We show that end-to-end models do learn to directly generate fluent transcripts; however, their performance is slightly worse than a baseline pipeline approach consisting of an ASR system and a disfluency detection model. We also propose two new metrics that can be used for evaluating integrated ASR and disfluency models. The findings of this paper can serve as a benchmark for further research on the task of end-to-end speech recognition and disfluency removal in the future.
Cross-Modal Transformer-Based Neural Correction Models for Automatic Speech Recognition
Jul 04, 2021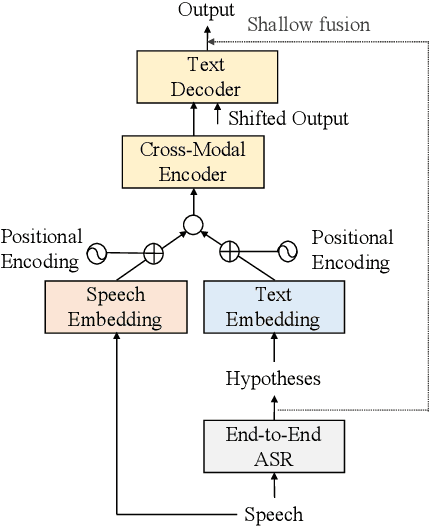
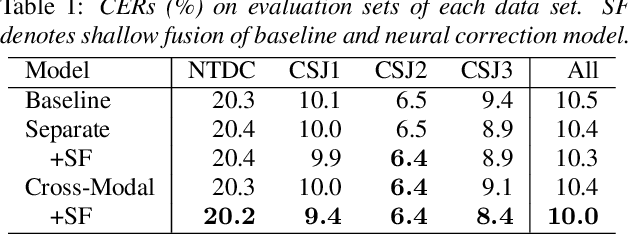
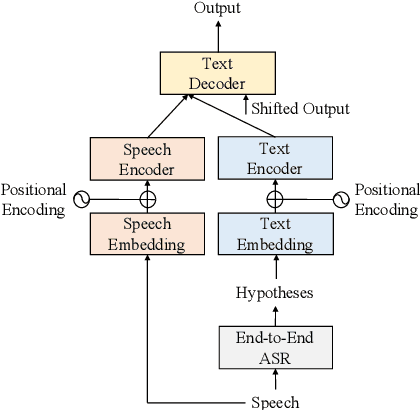
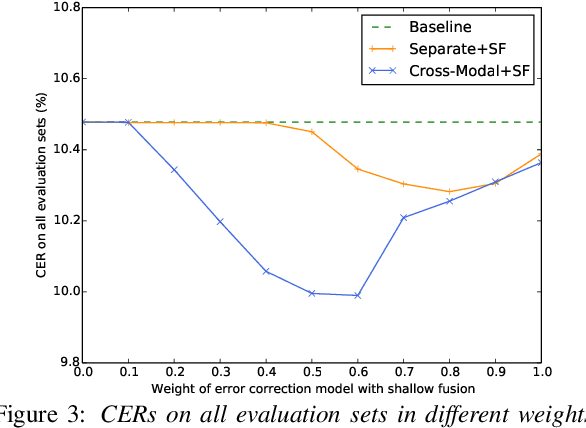
We propose a cross-modal transformer-based neural correction models that refines the output of an automatic speech recognition (ASR) system so as to exclude ASR errors. Generally, neural correction models are composed of encoder-decoder networks, which can directly model sequence-to-sequence mapping problems. The most successful method is to use both input speech and its ASR output text as the input contexts for the encoder-decoder networks. However, the conventional method cannot take into account the relationships between these two different modal inputs because the input contexts are separately encoded for each modal. To effectively leverage the correlated information between the two different modal inputs, our proposed models encode two different contexts jointly on the basis of cross-modal self-attention using a transformer. We expect that cross-modal self-attention can effectively capture the relationships between two different modals for refining ASR hypotheses. We also introduce a shallow fusion technique to efficiently integrate the first-pass ASR model and our proposed neural correction model. Experiments on Japanese natural language ASR tasks demonstrated that our proposed models achieve better ASR performance than conventional neural correction models.
Streaming Transformer Transducer Based Speech Recognition Using Non-Causal Convolution
Oct 07, 2021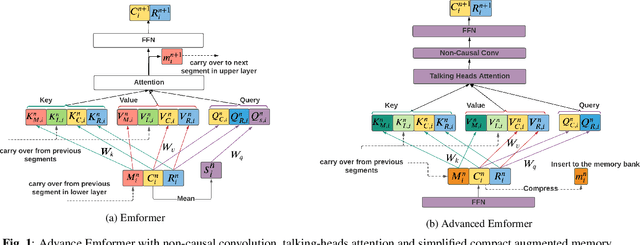
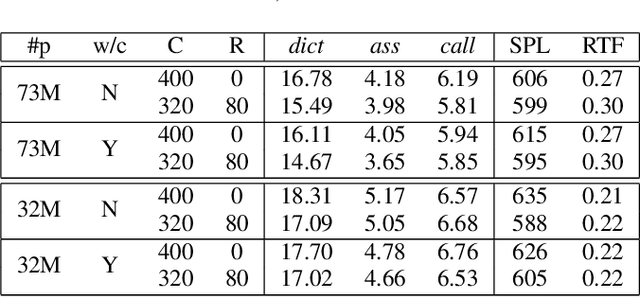
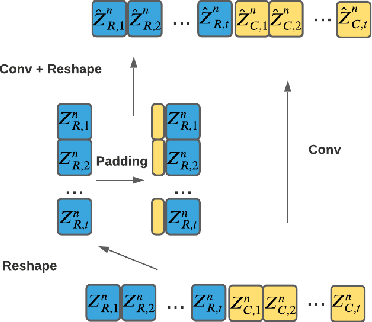
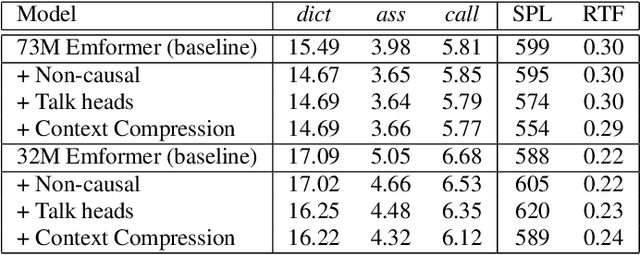
This paper improves the streaming transformer transducer for speech recognition by using non-causal convolution. Many works apply the causal convolution to improve streaming transformer ignoring the lookahead context. We propose to use non-causal convolution to process the center block and lookahead context separately. This method leverages the lookahead context in convolution and maintains similar training and decoding efficiency. Given the similar latency, using the non-causal convolution with lookahead context gives better accuracy than causal convolution, especially for open-domain dictation scenarios. Besides, this paper applies talking-head attention and a novel history context compression scheme to further improve the performance. The talking-head attention improves the multi-head self-attention by transferring information among different heads. The history context compression method introduces more extended history context compactly. On our in-house data, the proposed methods improve a small Emformer baseline with lookahead context by relative WERR 5.1\%, 14.5\%, 8.4\% on open-domain dictation, assistant general scenarios, and assistant calling scenarios, respectively.
SE-MelGAN -- Speaker Agnostic Rapid Speech Enhancement
Jun 13, 2020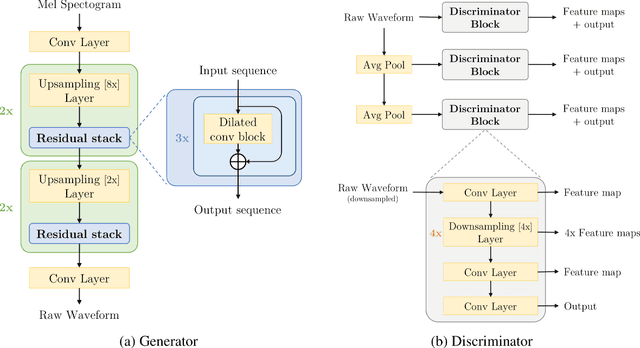
Recent advancement in Generative Adversarial Networks in speech synthesis domain[3],[2] have shown, that it's possible to train GANs [8] in a reliable manner for high quality coherent waveform generation from mel-spectograms. We propose that it is possible to transfer the MelGAN's [3] robustness in learning speech features to speech enhancement and noise reduction domain without any model modification tasks. Our proposed method generalizes over multi-speaker speech dataset and is able to robustly handle unseen background noises during the inference. Also, we show that by increasing the batch size for this particular approach not only yields better speech results, but generalizes over multi-speaker dataset easily and leads to faster convergence. Additionally, it outperforms previous state of the art GAN approach for speech enhancement SEGAN [5] in two domains: 1. quality ; 2. speed. Proposed method runs at more than 100x faster than realtime on GPU and more than 2x faster than real time on CPU without any hardware optimization tasks, right at the speed of MelGAN [3].
LRSpeech: Extremely Low-Resource Speech Synthesis and Recognition
Aug 09, 2020

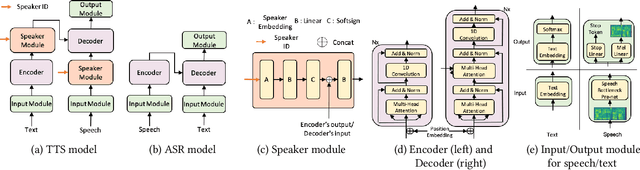
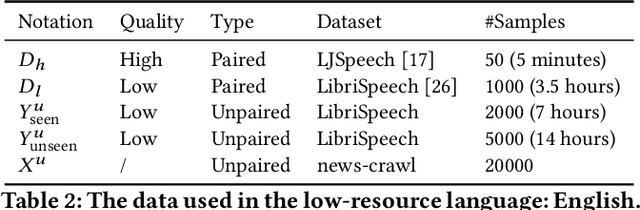
Speech synthesis (text to speech, TTS) and recognition (automatic speech recognition, ASR) are important speech tasks, and require a large amount of text and speech pairs for model training. However, there are more than 6,000 languages in the world and most languages are lack of speech training data, which poses significant challenges when building TTS and ASR systems for extremely low-resource languages. In this paper, we develop LRSpeech, a TTS and ASR system under the extremely low-resource setting, which can support rare languages with low data cost. LRSpeech consists of three key techniques: 1) pre-training on rich-resource languages and fine-tuning on low-resource languages; 2) dual transformation between TTS and ASR to iteratively boost the accuracy of each other; 3) knowledge distillation to customize the TTS model on a high-quality target-speaker voice and improve the ASR model on multiple voices. We conduct experiments on an experimental language (English) and a truly low-resource language (Lithuanian) to verify the effectiveness of LRSpeech. Experimental results show that LRSpeech 1) achieves high quality for TTS in terms of both intelligibility (more than 98% intelligibility rate) and naturalness (above 3.5 mean opinion score (MOS)) of the synthesized speech, which satisfy the requirements for industrial deployment, 2) achieves promising recognition accuracy for ASR, and 3) last but not least, uses extremely low-resource training data. We also conduct comprehensive analyses on LRSpeech with different amounts of data resources, and provide valuable insights and guidances for industrial deployment. We are currently deploying LRSpeech into a commercialized cloud speech service to support TTS on more rare languages.
LSSED: a large-scale dataset and benchmark for speech emotion recognition
Jan 30, 2021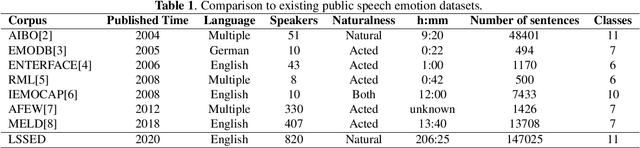
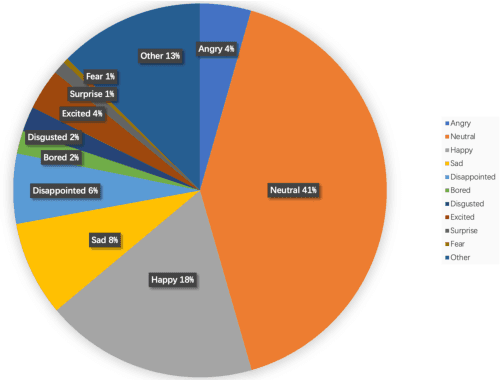


Speech emotion recognition is a vital contributor to the next generation of human-computer interaction (HCI). However, current existing small-scale databases have limited the development of related research. In this paper, we present LSSED, a challenging large-scale english speech emotion dataset, which has data collected from 820 subjects to simulate real-world distribution. In addition, we release some pre-trained models based on LSSED, which can not only promote the development of speech emotion recognition, but can also be transferred to related downstream tasks such as mental health analysis where data is extremely difficult to collect. Finally, our experiments show the necessity of large-scale datasets and the effectiveness of pre-trained models. The dateset will be released on https://github.com/tobefans/LSSED.
Improving Mispronunciation Detection with Wav2vec2-based Momentum Pseudo-Labeling for Accentedness and Intelligibility Assessment
Apr 07, 2022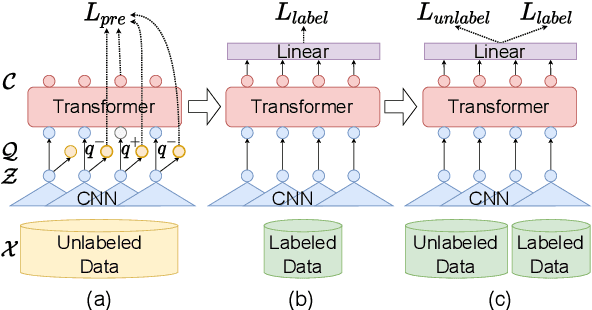
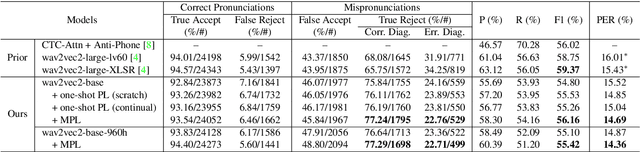
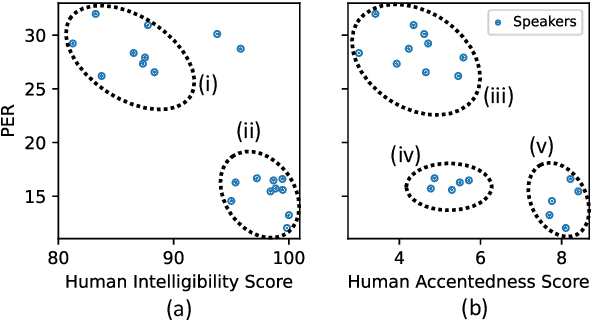
Current leading mispronunciation detection and diagnosis (MDD) systems achieve promising performance via end-to-end phoneme recognition. One challenge of such end-to-end solutions is the scarcity of human-annotated phonemes on natural L2 speech. In this work, we leverage unlabeled L2 speech via a pseudo-labeling (PL) procedure and extend the fine-tuning approach based on pre-trained self-supervised learning (SSL) models. Specifically, we use Wav2vec 2.0 as our SSL model, and fine-tune it using original labeled L2 speech samples plus the created pseudo-labeled L2 speech samples. Our pseudo labels are dynamic and are produced by an ensemble of the online model on-the-fly, which ensures that our model is robust to pseudo label noise. We show that fine-tuning with pseudo labels gains a 5.35% phoneme error rate reduction and 2.48% MDD F1 score improvement over a labeled-samples-only fine-tuning baseline. The proposed PL method is also shown to outperform conventional offline PL methods. Compared to the state-of-the-art MDD systems, our MDD solution achieves a more accurate and consistent phonetic error diagnosis. In addition, we conduct an open test on a separate UTD-4Accents dataset, where our system recognition outputs show a strong correlation with human perception, based on accentedness and intelligibility.
Dynamic Acoustic Unit Augmentation With BPE-Dropout for Low-Resource End-to-End Speech Recognition
Mar 12, 2021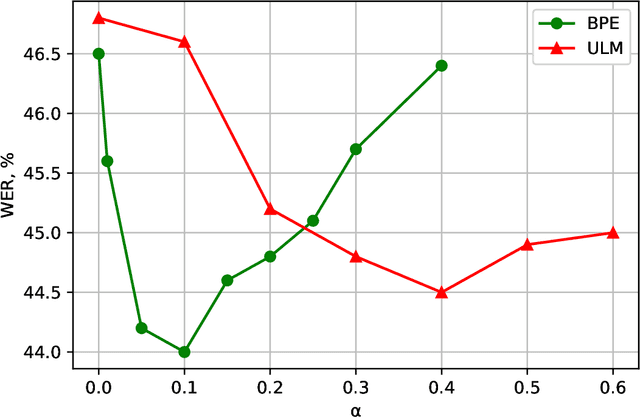
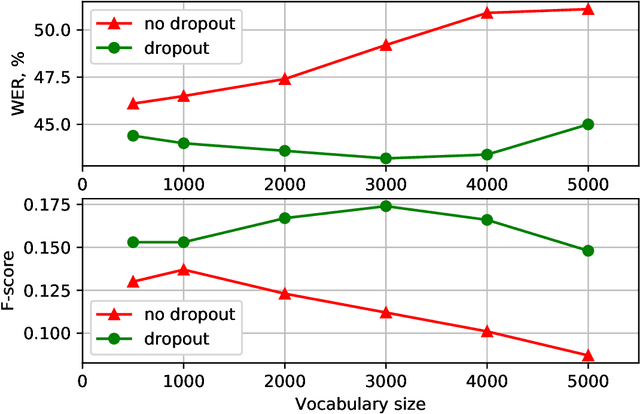
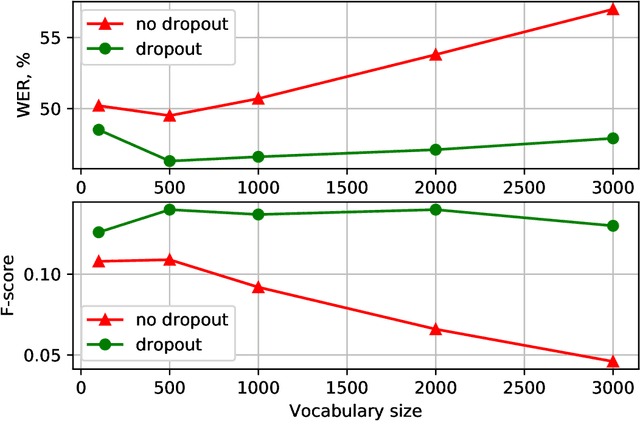
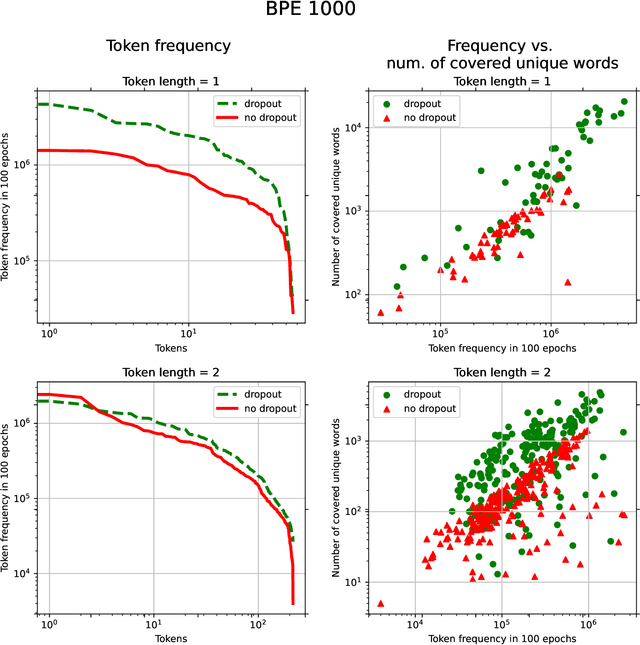
With the rapid development of speech assistants, adapting server-intended automatic speech recognition (ASR) solutions to a direct device has become crucial. Researchers and industry prefer to use end-to-end ASR systems for on-device speech recognition tasks. This is because end-to-end systems can be made resource-efficient while maintaining a higher quality compared to hybrid systems. However, building end-to-end models requires a significant amount of speech data. Another challenging task associated with speech assistants is personalization, which mainly lies in handling out-of-vocabulary (OOV) words. In this work, we consider building an effective end-to-end ASR system in low-resource setups with a high OOV rate, embodied in Babel Turkish and Babel Georgian tasks. To address the aforementioned problems, we propose a method of dynamic acoustic unit augmentation based on the BPE-dropout technique. It non-deterministically tokenizes utterances to extend the token's contexts and to regularize their distribution for the model's recognition of unseen words. It also reduces the need for optimal subword vocabulary size search. The technique provides a steady improvement in regular and personalized (OOV-oriented) speech recognition tasks (at least 6% relative WER and 25% relative F-score) at no additional computational cost. Owing to the use of BPE-dropout, our monolingual Turkish Conformer established a competitive result with 22.2% character error rate (CER) and 38.9% word error rate (WER), which is close to the best published multilingual system.
Data-augmented cross-lingual synthesis in a teacher-student framework
Mar 31, 2022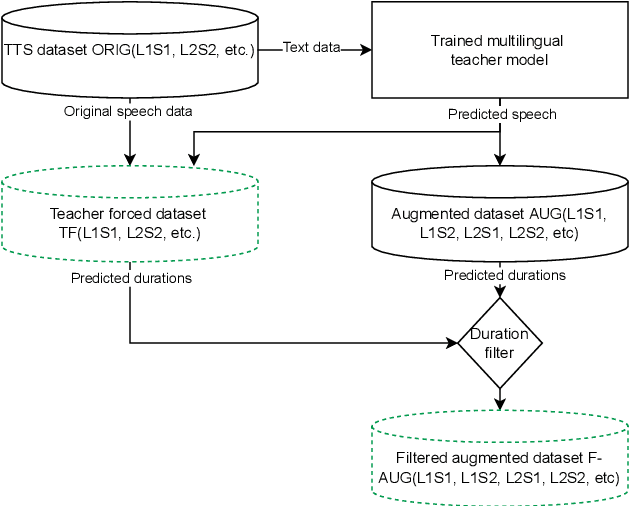
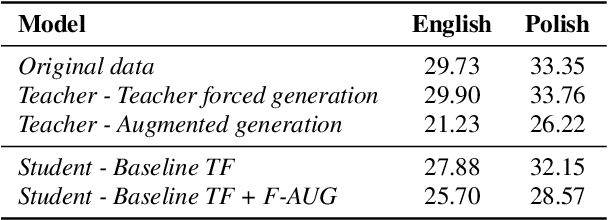
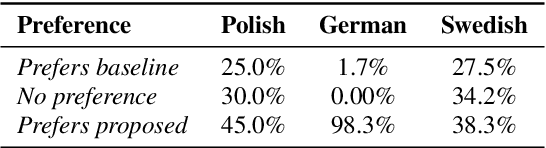
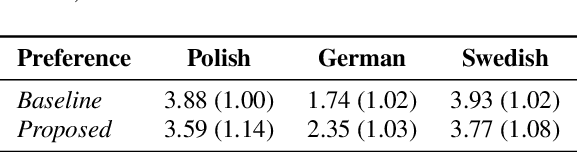
Cross-lingual synthesis can be defined as the task of letting a speaker generate fluent synthetic speech in another language. This is a challenging task, and resulting speech can suffer from reduced naturalness, accented speech, and/or loss of essential voice characteristics. Previous research shows that many models appear to have insufficient generalization capabilities to perform well on every of these cross-lingual aspects. To overcome these generalization problems, we propose to apply the teacher-student paradigm to cross-lingual synthesis. While a teacher model is commonly used to produce teacher forced data, we propose to also use it to produce augmented data of unseen speaker-language pairs, where the aim is to retain essential speaker characteristics. Both sets of data are then used for student model training, which is trained to retain the naturalness and prosodic variation present in the teacher forced data, while learning the speaker identity from the augmented data. Some modifications to the student model are proposed to make the separation of teacher forced and augmented data more straightforward. Results show that the proposed approach improves the retention of speaker characteristics in the speech, while managing to retain high levels of naturalness and prosodic variation.