 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Multi-Window Data Augmentation Approach for Speech Emotion Recognition
Oct 28, 2020
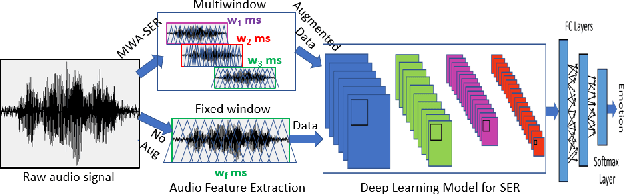
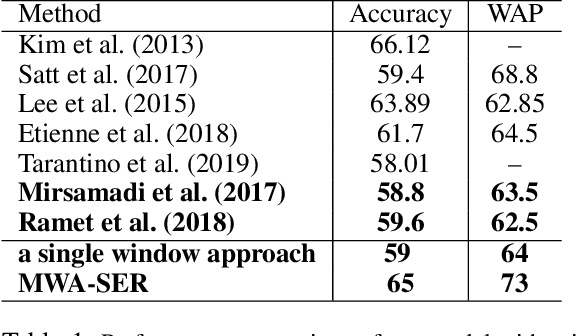
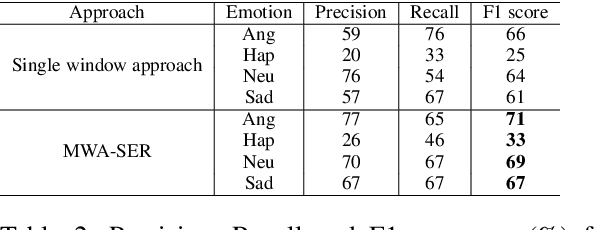
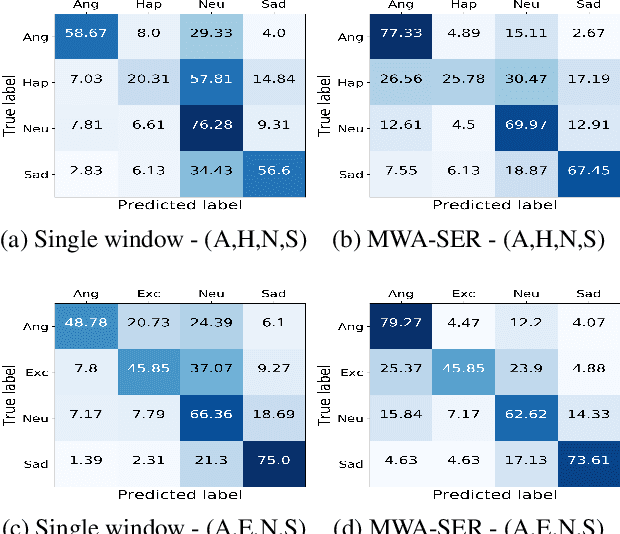
We present a novel, Multi-Window Data Augmentation (MWA-SER) approach for speech emotion recognition. MWA-SER is a unimodal approach that focuses on two key concepts; designing the speech augmentation method to generate additional data samples and building the deep learning models to recognize the underlying emotion of an audio signal. The multi-window augmentation method extracts more audio features from the speech signal by employing multiple window sizes in the audio feature extraction process. We show that our proposed augmentation method, combined with a deep learning model, improves the speech emotion recognition performance. We evaluate the performance of our MWA-SER approach on the IEMOCAP corpus and show that our proposed method achieves state-of-the-art results. Furthermore, the proposed system demonstrated 70% and 88% accuracy while recognizing the emotions for the SAVEE and RAVDESS datasets, respectively.
Continual Speaker Adaptation for Text-to-Speech Synthesis
Mar 26, 2021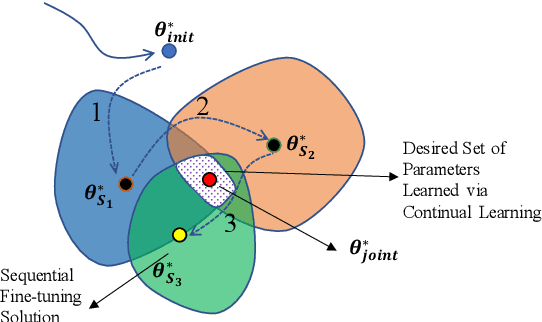
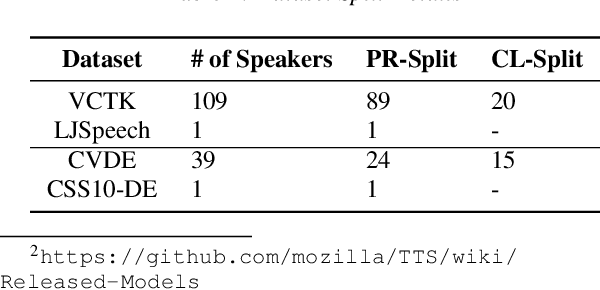
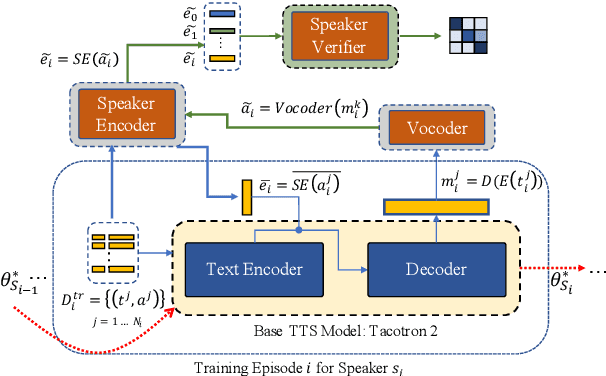
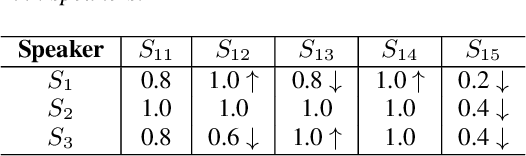
Training a multi-speaker Text-to-Speech (TTS) model from scratch is computationally expensive and adding new speakers to the dataset requires the model to be re-trained. The naive solution of sequential fine-tuning of a model for new speakers can cause the model to have poor performance on older speakers. This phenomenon is known as catastrophic forgetting. In this paper, we look at TTS modeling from a continual learning perspective where the goal is to add new speakers without forgetting previous speakers. Therefore, we first propose an experimental setup and show that serial fine-tuning for new speakers can result in the forgetting of the previous speakers. Then we exploit two well-known techniques for continual learning namely experience replay and weight regularization and we reveal how one can mitigate the effect of degradation in speech synthesis diversity in sequential training of new speakers using these methods. Finally, we present a simple extension to improve the results in extreme setups.
Indoor optical fiber eavesdropping approach and its avoidance
Jul 12, 2022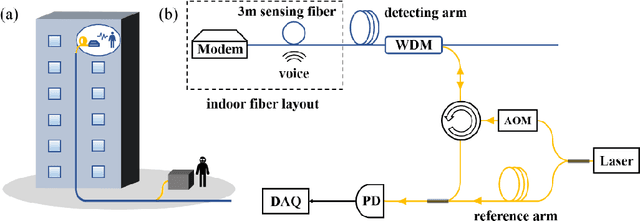
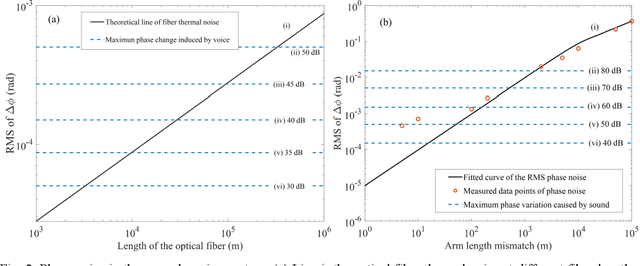
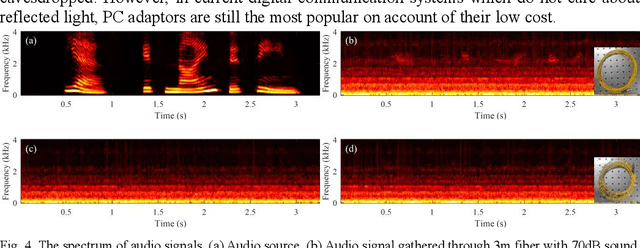
The optical fiber network has become a worldwide infrastructure. In addition to the basic functions in telecommunication, its sensing ability has attracted more and more attention. In this paper, we discuss the risk of household fiber being used for eavesdropping and demonstrate its performance in the lab. Using a 3-meter tail fiber in front of the household optical modem, voices of normal human speech can be eavesdropped by a laser interferometer and recovered 1.1 km away. The detection distance limit and system noise are analyzed quantitatively. We also give some practical ways to prevent eavesdropping through household fiber.
Audio-visual Speech Separation with Adversarially Disentangled Visual Representation
Nov 29, 2020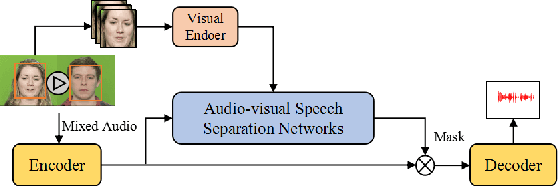
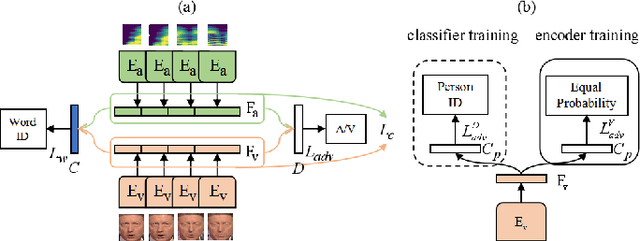
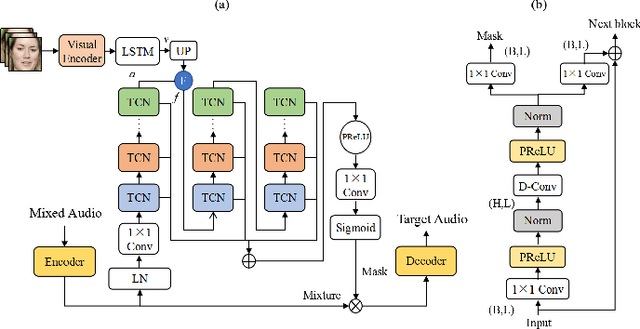
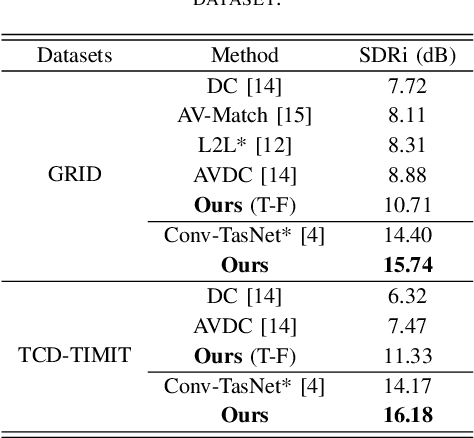
Speech separation aims to separate individual voice from an audio mixture of multiple simultaneous talkers. Although audio-only approaches achieve satisfactory performance, they build on a strategy to handle the predefined conditions, limiting their application in the complex auditory scene. Towards the cocktail party problem, we propose a novel audio-visual speech separation model. In our model, we use the face detector to detect the number of speakers in the scene and use visual information to avoid the permutation problem. To improve our model's generalization ability to unknown speakers, we extract speech-related visual features from visual inputs explicitly by the adversarially disentangled method, and use this feature to assist speech separation. Besides, the time-domain approach is adopted, which could avoid the phase reconstruction problem existing in the time-frequency domain models. To compare our model's performance with other models, we create two benchmark datasets of 2-speaker mixture from GRID and TCDTIMIT audio-visual datasets. Through a series of experiments, our proposed model is shown to outperform the state-of-the-art audio-only model and three audio-visual models.
Machine Learning based COVID-19 Detection from Smartphone Recordings: Cough, Breath and Speech
Apr 02, 2021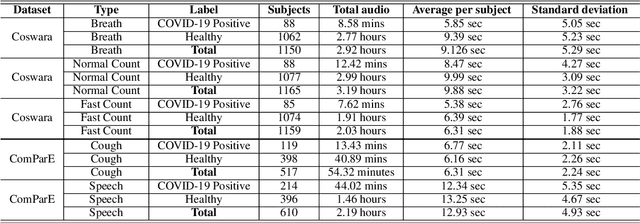
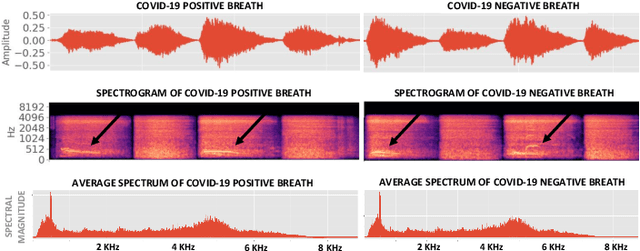
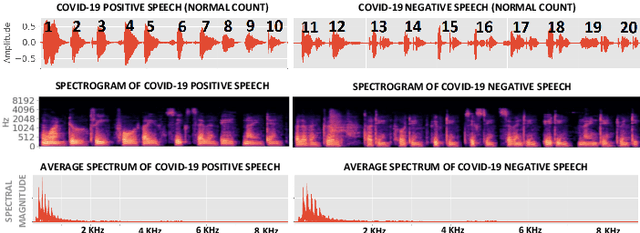
We present an experimental investigation into the automatic detection of COVID-19 from smartphone recordings of coughs, breaths and speech. This type of screening is attractive because it is non-contact, does not require specialist medical expertise or laboratory facilities and can easily be deployed on inexpensive consumer hardware. We base our experiments on two datasets, Coswara and ComParE, containing recordings of coughing, breathing and speech from subjects around the globe. We have considered seven machine learning classifiers and all of them are trained and evaluated using leave-p-out cross-validation. For the Coswara data, the highest AUC of 0.92 was achieved using a Resnet50 architecture on breaths. For the ComParE data, the highest AUC of 0.93 was achieved using a k-nearest neighbours (KNN) classifier on cough recordings after selecting the best 12 features using sequential forward selection (SFS) and the highest AUC of 0.91 was also achieved on speech by a multilayer perceptron (MLP) when using SFS to select the best 23 features. We conclude that among all vocal audio, coughs carry the strongest COVID-19 signature followed by breath and speech. Although these signatures are not perceivable by human ear, machine learning based COVID-19 detection is possible from vocal audio recorded via smartphone.
Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition
Sep 14, 2021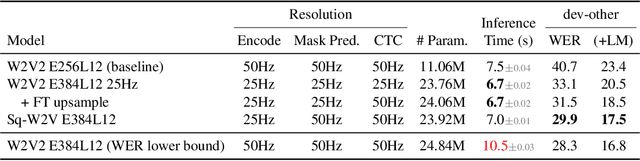
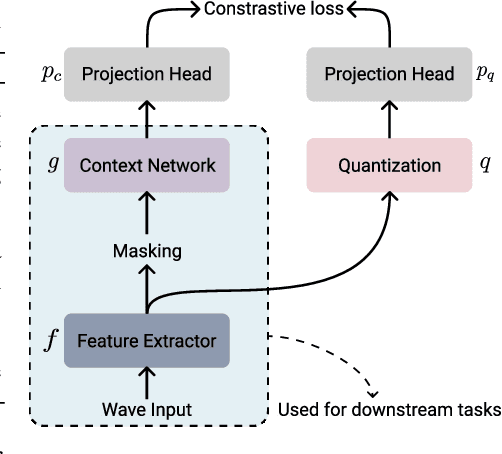
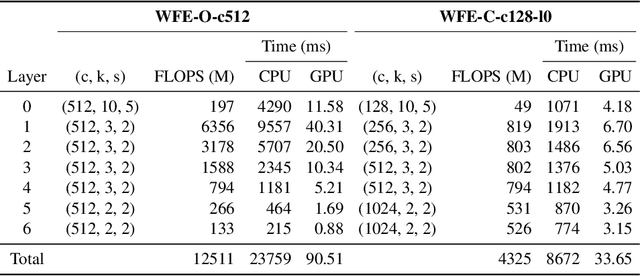
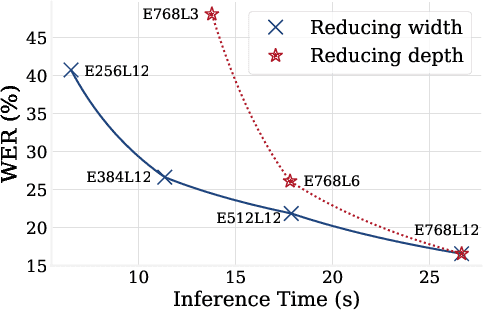
This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition (ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference time, SEW reduces word error rate by 25-50% across different model sizes.
Continuously Controllable Facial Expression Editing in Talking Face Videos
Sep 17, 2022
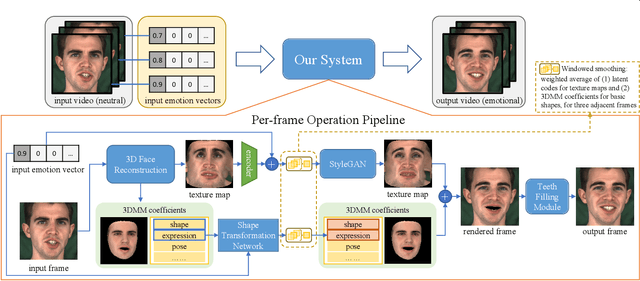
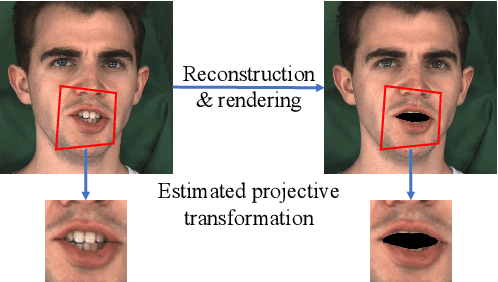

Recently audio-driven talking face video generation has attracted considerable attention. However, very few researches address the issue of emotional editing of these talking face videos with continuously controllable expressions, which is a strong demand in the industry. The challenge is that speech-related expressions and emotion-related expressions are often highly coupled. Meanwhile, traditional image-to-image translation methods cannot work well in our application due to the coupling of expressions with other attributes such as poses, i.e., translating the expression of the character in each frame may simultaneously change the head pose due to the bias of the training data distribution. In this paper, we propose a high-quality facial expression editing method for talking face videos, allowing the user to control the target emotion in the edited video continuously. We present a new perspective for this task as a special case of motion information editing, where we use a 3DMM to capture major facial movements and an associated texture map modeled by a StyleGAN to capture appearance details. Both representations (3DMM and texture map) contain emotional information and can be continuously modified by neural networks and easily smoothed by averaging in coefficient/latent spaces, making our method simple yet effective. We also introduce a mouth shape preservation loss to control the trade-off between lip synchronization and the degree of exaggeration of the edited expression. Extensive experiments and a user study show that our method achieves state-of-the-art performance across various evaluation criteria.
A Post Auto-regressive GAN Vocoder Focused on Spectrum Fracture
Apr 12, 2022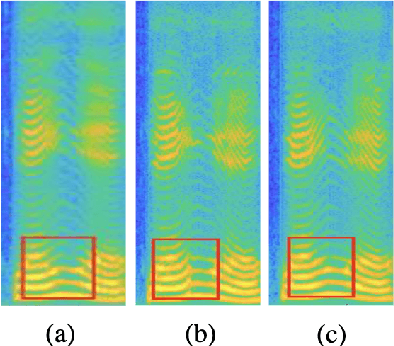
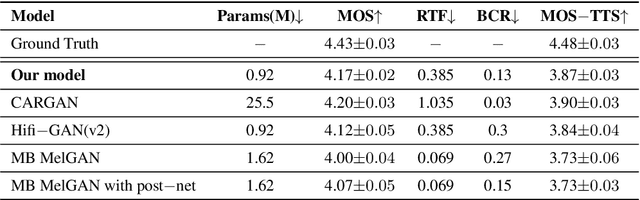
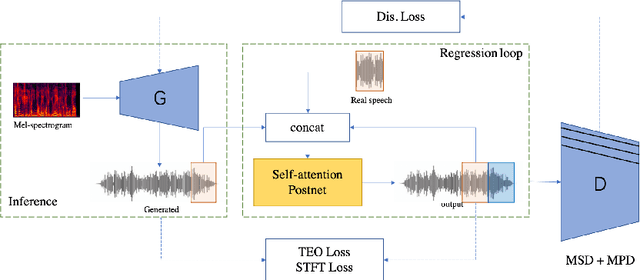
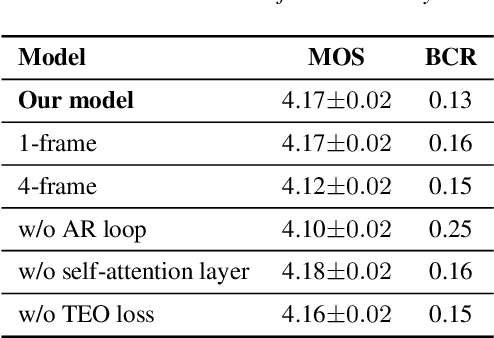
Generative adversarial networks (GANs) have been indicated their superiority in usage of the real-time speech synthesis. Nevertheless, most of them make use of deep convolutional layers as their backbone, which may cause the absence of previous signal information. However, the generation of speech signals invariably require preceding waveform samples in its reconstruction, as the lack of this can lead to artifacts in generated speech. To address this conflict, in this paper, we propose an improved model: a post auto-regressive (AR) GAN vocoder with a self-attention layer, which merging self-attention in an AR loop. It will not participate in inference, but can assist the generator to learn temporal dependencies within frames in training. Furthermore, an ablation study was done to confirm the contribution of each part. Systematic experiments show that our model leads to a consistent improvement on both objective and subjective evaluation performance.
Conformal prediction for text infilling and part-of-speech prediction
Nov 04, 2021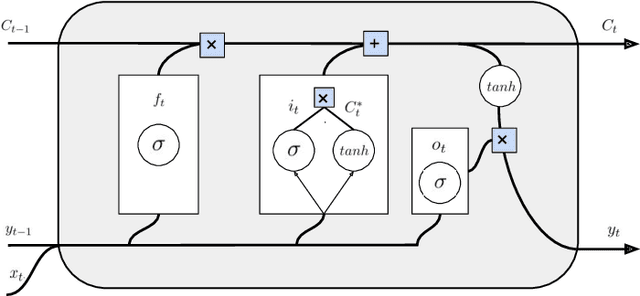
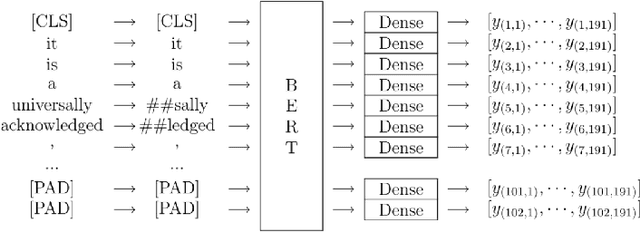
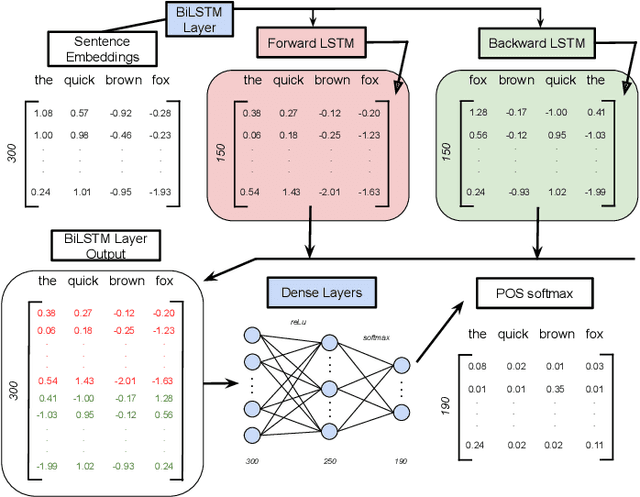
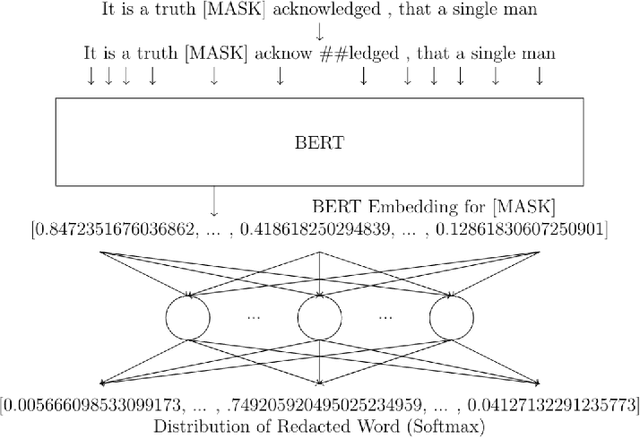
Modern machine learning algorithms are capable of providing remarkably accurate point-predictions; however, questions remain about their statistical reliability. Unlike conventional machine learning methods, conformal prediction algorithms return confidence sets (i.e., set-valued predictions) that correspond to a given significance level. Moreover, these confidence sets are valid in the sense that they guarantee finite sample control over type 1 error probabilities, allowing the practitioner to choose an acceptable error rate. In our paper, we propose inductive conformal prediction (ICP) algorithms for the tasks of text infilling and part-of-speech (POS) prediction for natural language data. We construct new conformal prediction-enhanced bidirectional encoder representations from transformers (BERT) and bidirectional long short-term memory (BiLSTM) algorithms for POS tagging and a new conformal prediction-enhanced BERT algorithm for text infilling. We analyze the performance of the algorithms in simulations using the Brown Corpus, which contains over 57,000 sentences. Our results demonstrate that the ICP algorithms are able to produce valid set-valued predictions that are small enough to be applicable in real-world applications. We also provide a real data example for how our proposed set-valued predictions can improve machine generated audio transcriptions.
On the Role of Style in Parsing Speech with Neural Models
Oct 08, 2020
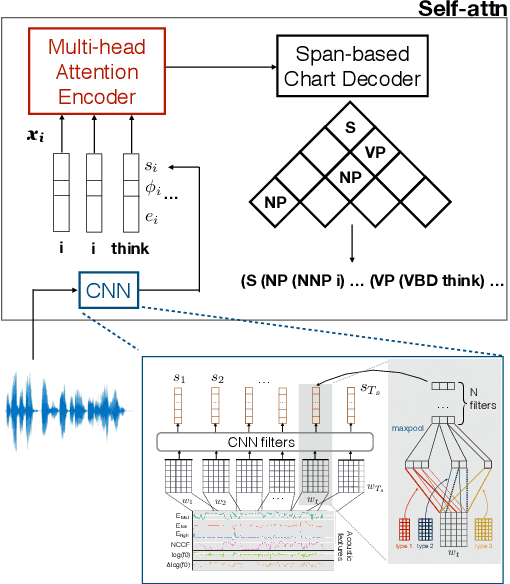

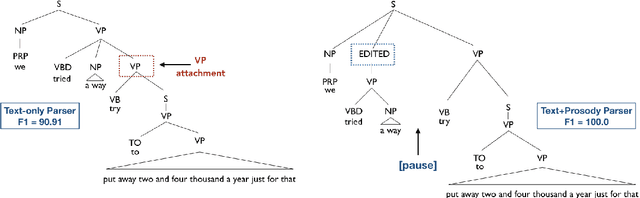
The differences in written text and conversational speech are substantial; previous parsers trained on treebanked text have given very poor results on spontaneous speech. For spoken language, the mismatch in style also extends to prosodic cues, though it is less well understood. This paper re-examines the use of written text in parsing speech in the context of recent advances in neural language processing. We show that neural approaches facilitate using written text to improve parsing of spontaneous speech, and that prosody further improves over this state-of-the-art result. Further, we find an asymmetric degradation from read vs. spontaneous mismatch, with spontaneous speech more generally useful for training parsers.