 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network
Apr 27, 2021
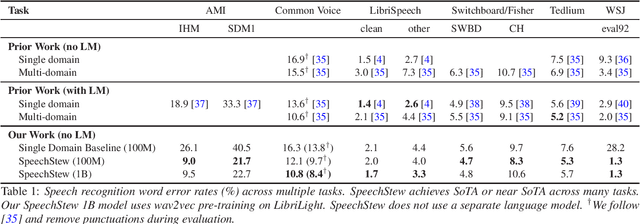
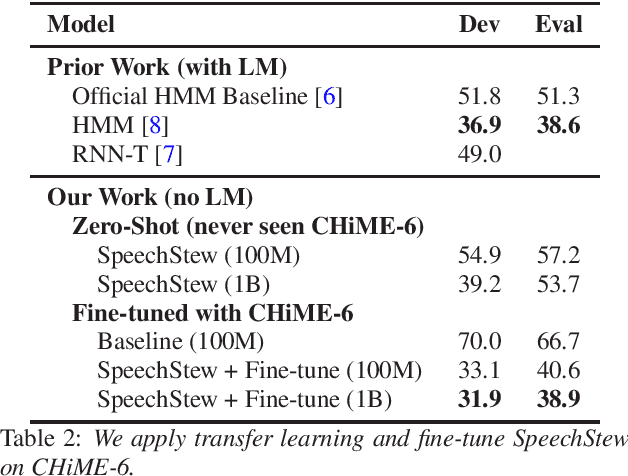
We present SpeechStew, a speech recognition model that is trained on a combination of various publicly available speech recognition datasets: AMI, Broadcast News, Common Voice, LibriSpeech, Switchboard/Fisher, Tedlium, and Wall Street Journal. SpeechStew simply mixes all of these datasets together, without any special re-weighting or re-balancing of the datasets. SpeechStew achieves SoTA or near SoTA results across a variety of tasks, without the use of an external language model. Our results include 9.0\% WER on AMI-IHM, 4.7\% WER on Switchboard, 8.3\% WER on CallHome, and 1.3\% on WSJ, which significantly outperforms prior work with strong external language models. We also demonstrate that SpeechStew learns powerful transfer learning representations. We fine-tune SpeechStew on a noisy low resource speech dataset, CHiME-6. We achieve 38.9\% WER without a language model, which compares to 38.6\% WER to a strong HMM baseline with a language model.
Multi-Window Data Augmentation Approach for Speech Emotion Recognition
Oct 28, 2020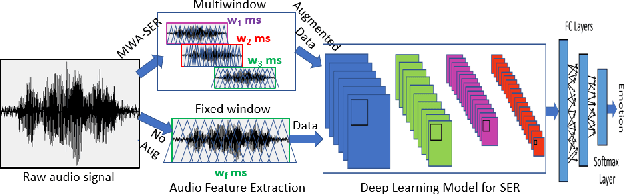
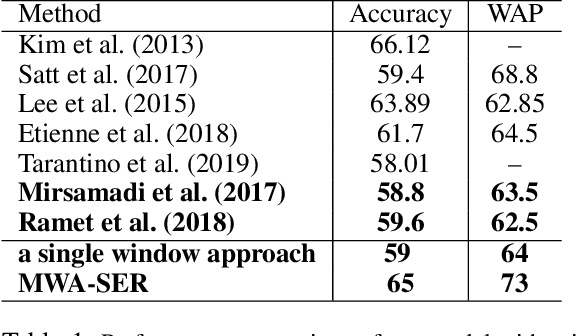
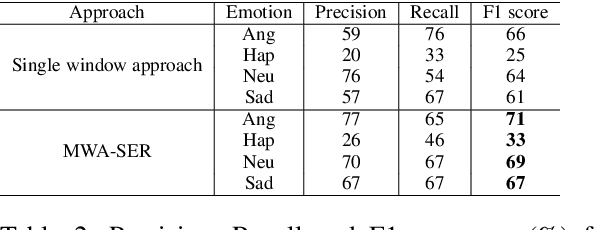
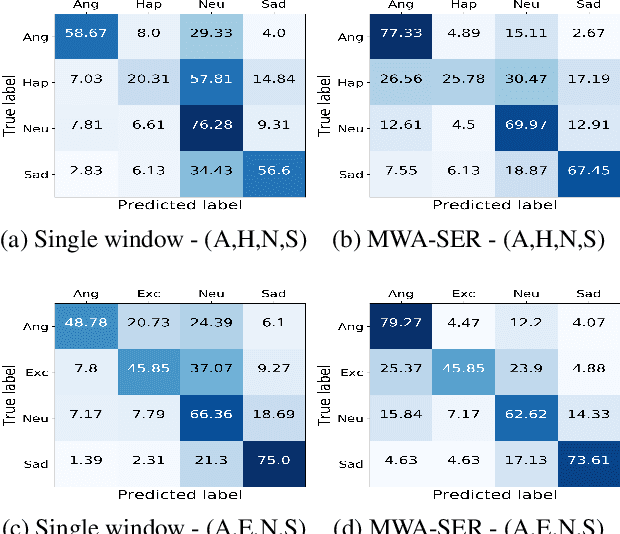
We present a novel, Multi-Window Data Augmentation (MWA-SER) approach for speech emotion recognition. MWA-SER is a unimodal approach that focuses on two key concepts; designing the speech augmentation method to generate additional data samples and building the deep learning models to recognize the underlying emotion of an audio signal. The multi-window augmentation method extracts more audio features from the speech signal by employing multiple window sizes in the audio feature extraction process. We show that our proposed augmentation method, combined with a deep learning model, improves the speech emotion recognition performance. We evaluate the performance of our MWA-SER approach on the IEMOCAP corpus and show that our proposed method achieves state-of-the-art results. Furthermore, the proposed system demonstrated 70% and 88% accuracy while recognizing the emotions for the SAVEE and RAVDESS datasets, respectively.
Which one is more toxic? Findings from Jigsaw Rate Severity of Toxic Comments
Jun 27, 2022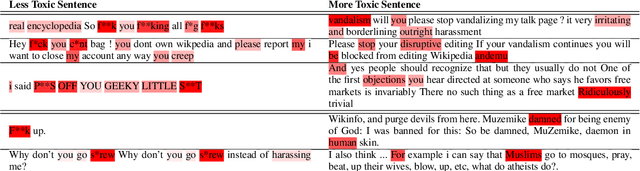
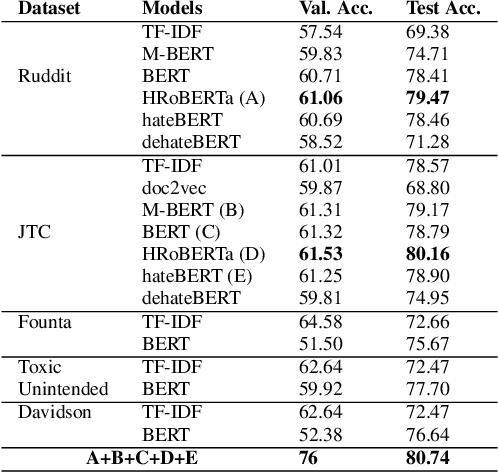
The proliferation of online hate speech has necessitated the creation of algorithms which can detect toxicity. Most of the past research focuses on this detection as a classification task, but assigning an absolute toxicity label is often tricky. Hence, few of the past works transform the same task into a regression. This paper shows the comparative evaluation of different transformers and traditional machine learning models on a recently released toxicity severity measurement dataset by Jigsaw. We further demonstrate the issues with the model predictions using explainability analysis.
Training end-to-end speech-to-text models on mobile phones
Dec 07, 2021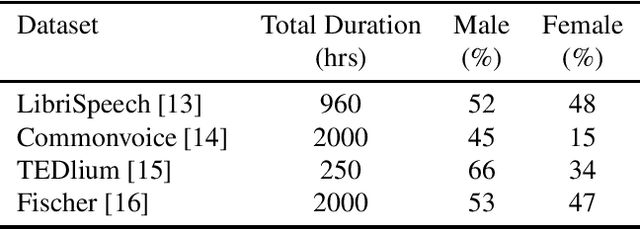
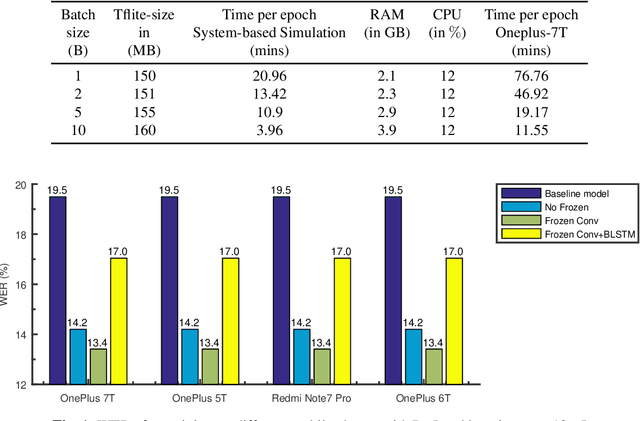
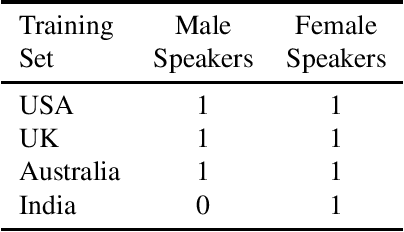
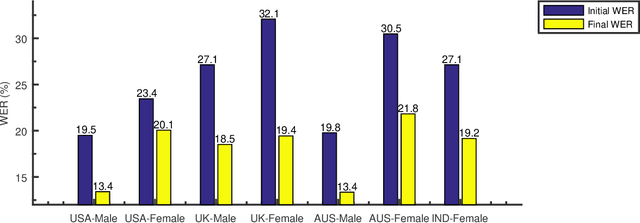
Training the state-of-the-art speech-to-text (STT) models in mobile devices is challenging due to its limited resources relative to a server environment. In addition, these models are trained on generic datasets that are not exhaustive in capturing user-specific characteristics. Recently, on-device personalization techniques have been making strides in mitigating the problem. Although many current works have already explored the effectiveness of on-device personalization, the majority of their findings are limited to simulation settings or a specific smartphone. In this paper, we develop and provide a detailed explanation of our framework to train end-to-end models in mobile phones. To make it simple, we considered a model based on connectionist temporal classification (CTC) loss. We evaluated the framework on various mobile phones from different brands and reported the results. We provide enough evidence that fine-tuning the models and choosing the right hyperparameter values is a trade-off between the lowest WER achievable, training time on-device, and memory consumption. Hence, this is vital for a successful deployment of on-device training onto a resource-limited environment like mobile phones. We use training sets from speakers with different accents and record a 7.6% decrease in average word error rate (WER). We also report the associated computational cost measurements with respect to time, memory usage, and cpu utilization in mobile phones in real-time.
Audio-visual Speech Separation with Adversarially Disentangled Visual Representation
Nov 29, 2020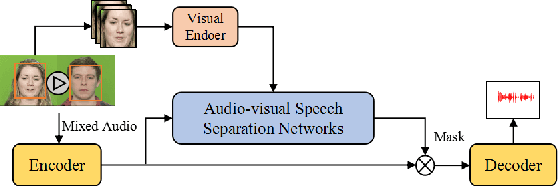
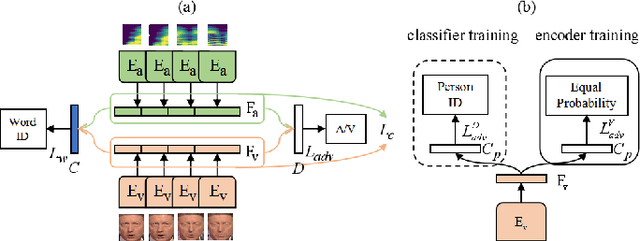
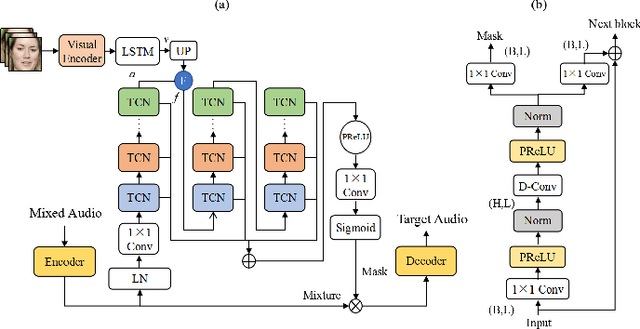
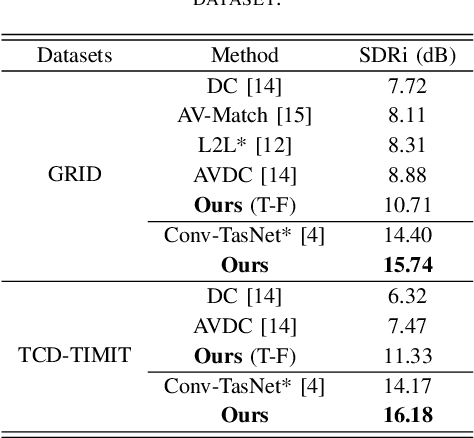
Speech separation aims to separate individual voice from an audio mixture of multiple simultaneous talkers. Although audio-only approaches achieve satisfactory performance, they build on a strategy to handle the predefined conditions, limiting their application in the complex auditory scene. Towards the cocktail party problem, we propose a novel audio-visual speech separation model. In our model, we use the face detector to detect the number of speakers in the scene and use visual information to avoid the permutation problem. To improve our model's generalization ability to unknown speakers, we extract speech-related visual features from visual inputs explicitly by the adversarially disentangled method, and use this feature to assist speech separation. Besides, the time-domain approach is adopted, which could avoid the phase reconstruction problem existing in the time-frequency domain models. To compare our model's performance with other models, we create two benchmark datasets of 2-speaker mixture from GRID and TCDTIMIT audio-visual datasets. Through a series of experiments, our proposed model is shown to outperform the state-of-the-art audio-only model and three audio-visual models.
Detecting and analysing spontaneous oral cancer speech in the wild
Jul 28, 2020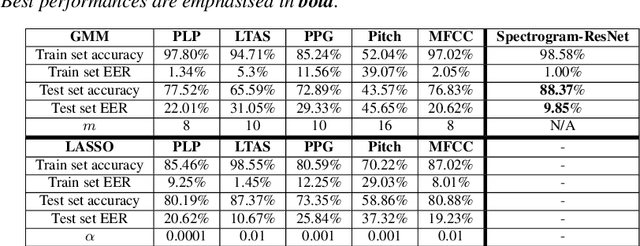
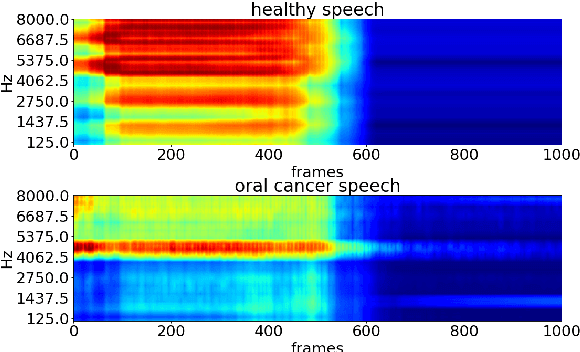
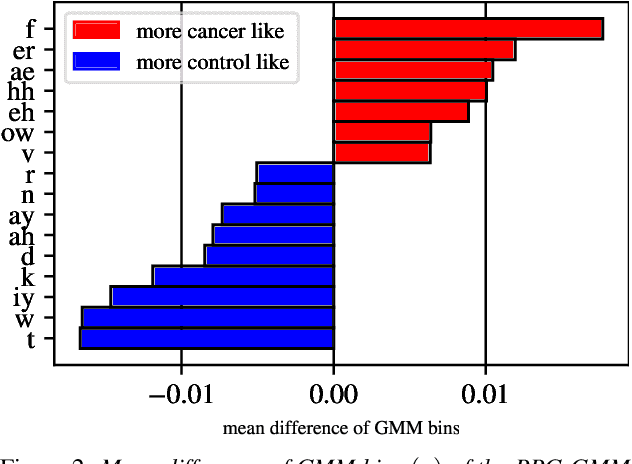
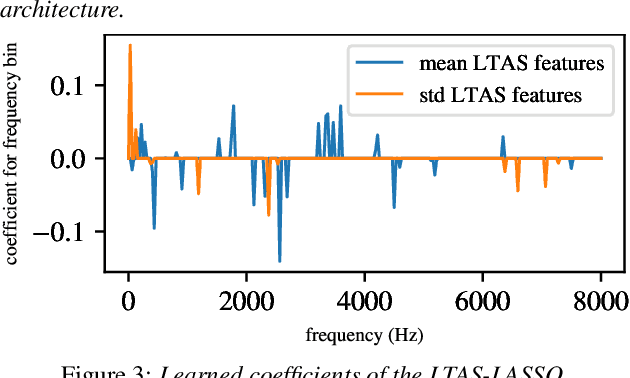
Oral cancer speech is a disease which impacts more than half a million people worldwide every year. Analysis of oral cancer speech has so far focused on read speech. In this paper, we 1) present and 2) analyse a three-hour long spontaneous oral cancer speech dataset collected from YouTube. 3) We set baselines for an oral cancer speech detection task on this dataset. The analysis of these explainable machine learning baselines shows that sibilants and stop consonants are the most important indicators for spontaneous oral cancer speech detection.
Unsupervised Speech Segmentation and Variable Rate Representation Learning using Segmental Contrastive Predictive Coding
Oct 08, 2021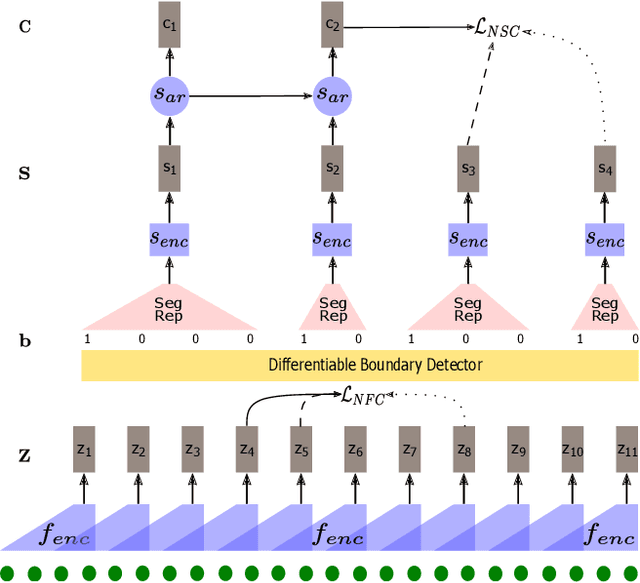
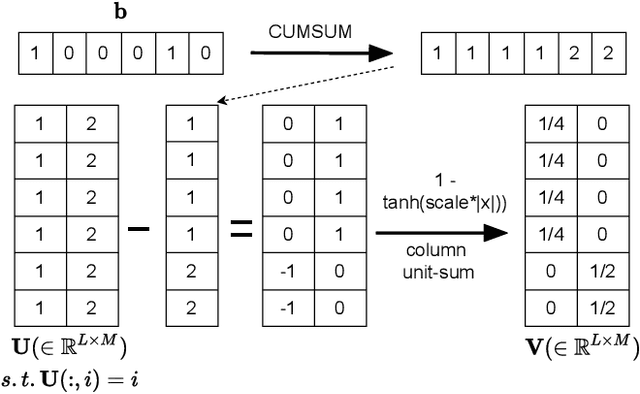
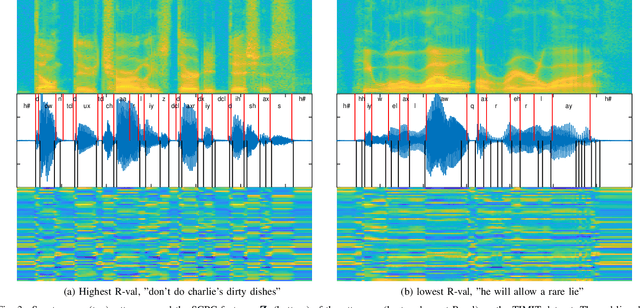
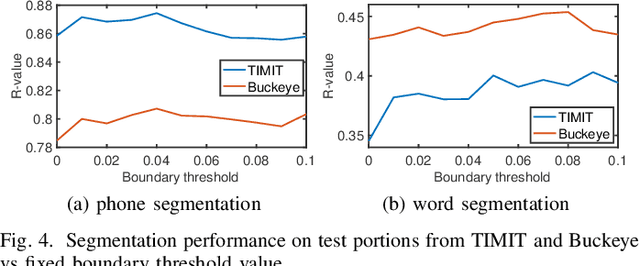
Typically, unsupervised segmentation of speech into the phone and word-like units are treated as separate tasks and are often done via different methods which do not fully leverage the inter-dependence of the two tasks. Here, we unify them and propose a technique that can jointly perform both, showing that these two tasks indeed benefit from each other. Recent attempts employ self-supervised learning, such as contrastive predictive coding (CPC), where the next frame is predicted given past context. However, CPC only looks at the audio signal's frame-level structure. We overcome this limitation with a segmental contrastive predictive coding (SCPC) framework to model the signal structure at a higher level, e.g., phone level. A convolutional neural network learns frame-level representation from the raw waveform via noise-contrastive estimation (NCE). A differentiable boundary detector finds variable-length segments, which are then used to optimize a segment encoder via NCE to learn segment representations. The differentiable boundary detector allows us to train frame-level and segment-level encoders jointly. Experiments show that our single model outperforms existing phone and word segmentation methods on TIMIT and Buckeye datasets. We discover that phone class impacts the boundary detection performance, and the boundaries between successive vowels or semivowels are the most difficult to identify. Finally, we use SCPC to extract speech features at the segment level rather than at uniformly spaced frame level (e.g., 10 ms) and produce variable rate representations that change according to the contents of the utterance. We can lower the feature extraction rate from the typical 100 Hz to as low as 14.5 Hz on average while still outperforming the MFCC features on the linear phone classification task.
LSSED: a large-scale dataset and benchmark for speech emotion recognition
Jan 30, 2021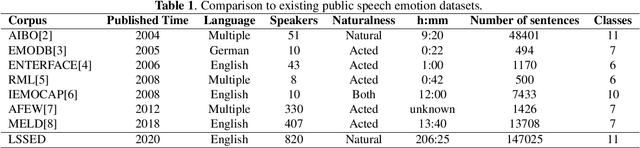


Speech emotion recognition is a vital contributor to the next generation of human-computer interaction (HCI). However, current existing small-scale databases have limited the development of related research. In this paper, we present LSSED, a challenging large-scale english speech emotion dataset, which has data collected from 820 subjects to simulate real-world distribution. In addition, we release some pre-trained models based on LSSED, which can not only promote the development of speech emotion recognition, but can also be transferred to related downstream tasks such as mental health analysis where data is extremely difficult to collect. Finally, our experiments show the necessity of large-scale datasets and the effectiveness of pre-trained models. The dateset will be released on https://github.com/tobefans/LSSED.
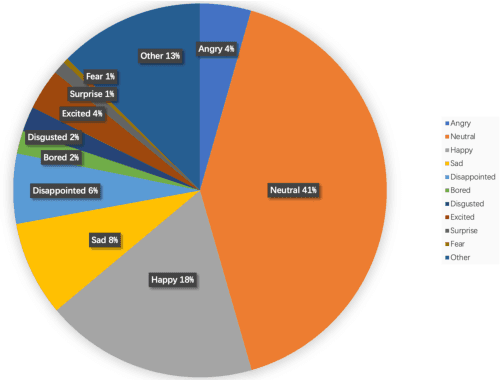
Dynamic Acoustic Unit Augmentation With BPE-Dropout for Low-Resource End-to-End Speech Recognition
Mar 12, 2021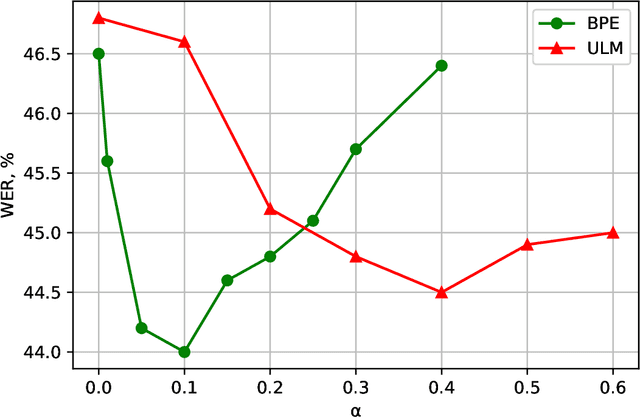
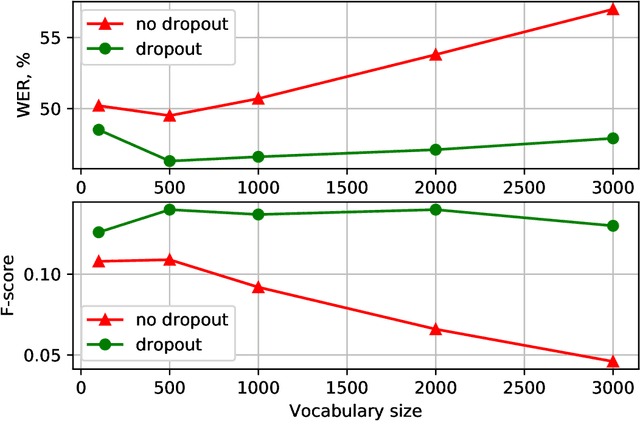
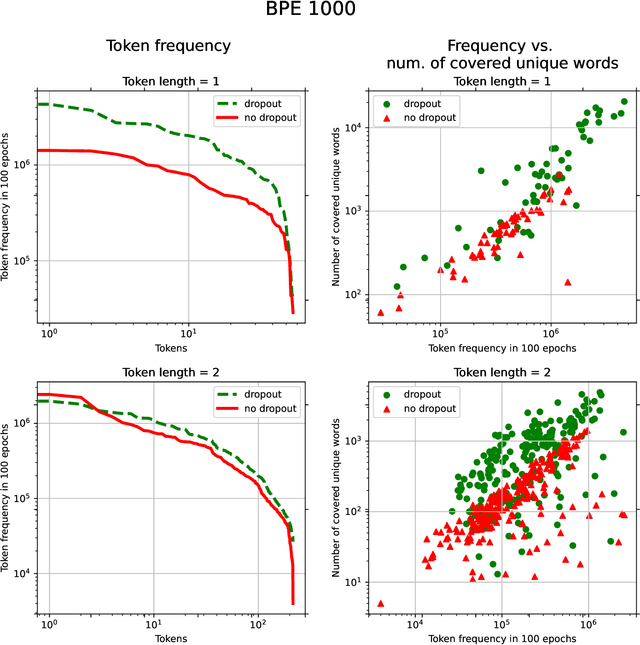
With the rapid development of speech assistants, adapting server-intended automatic speech recognition (ASR) solutions to a direct device has become crucial. Researchers and industry prefer to use end-to-end ASR systems for on-device speech recognition tasks. This is because end-to-end systems can be made resource-efficient while maintaining a higher quality compared to hybrid systems. However, building end-to-end models requires a significant amount of speech data. Another challenging task associated with speech assistants is personalization, which mainly lies in handling out-of-vocabulary (OOV) words. In this work, we consider building an effective end-to-end ASR system in low-resource setups with a high OOV rate, embodied in Babel Turkish and Babel Georgian tasks. To address the aforementioned problems, we propose a method of dynamic acoustic unit augmentation based on the BPE-dropout technique. It non-deterministically tokenizes utterances to extend the token's contexts and to regularize their distribution for the model's recognition of unseen words. It also reduces the need for optimal subword vocabulary size search. The technique provides a steady improvement in regular and personalized (OOV-oriented) speech recognition tasks (at least 6% relative WER and 25% relative F-score) at no additional computational cost. Owing to the use of BPE-dropout, our monolingual Turkish Conformer established a competitive result with 22.2% character error rate (CER) and 38.9% word error rate (WER), which is close to the best published multilingual system.
On the Role of Style in Parsing Speech with Neural Models
Oct 08, 2020
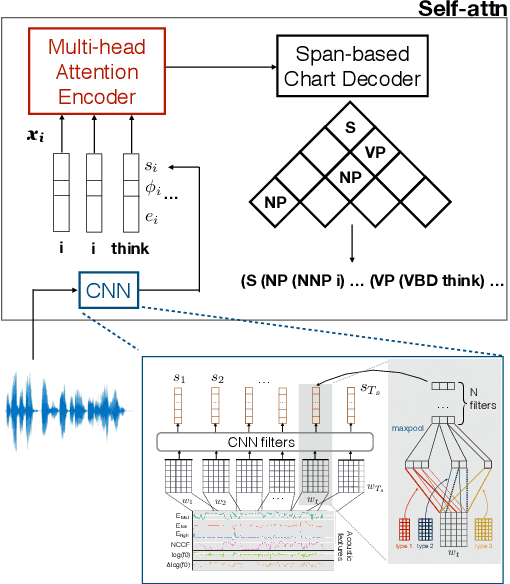

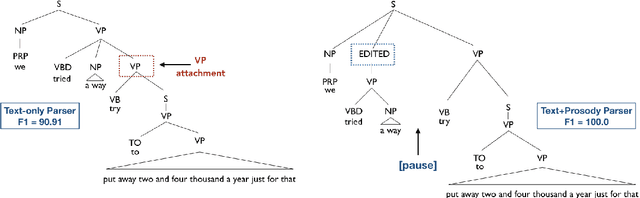
The differences in written text and conversational speech are substantial; previous parsers trained on treebanked text have given very poor results on spontaneous speech. For spoken language, the mismatch in style also extends to prosodic cues, though it is less well understood. This paper re-examines the use of written text in parsing speech in the context of recent advances in neural language processing. We show that neural approaches facilitate using written text to improve parsing of spontaneous speech, and that prosody further improves over this state-of-the-art result. Further, we find an asymmetric degradation from read vs. spontaneous mismatch, with spontaneous speech more generally useful for training parsers.