 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speech & Song Emotion Recognition Using Multilayer Perceptron and Standard Vector Machine
May 19, 2021
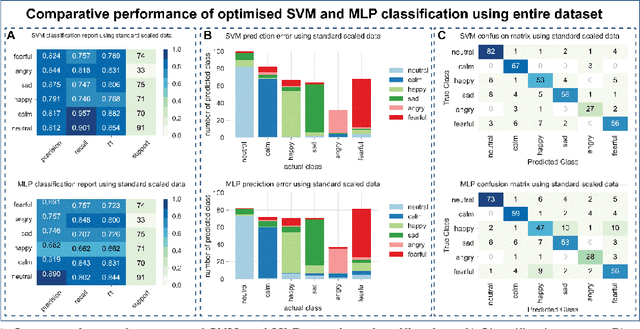
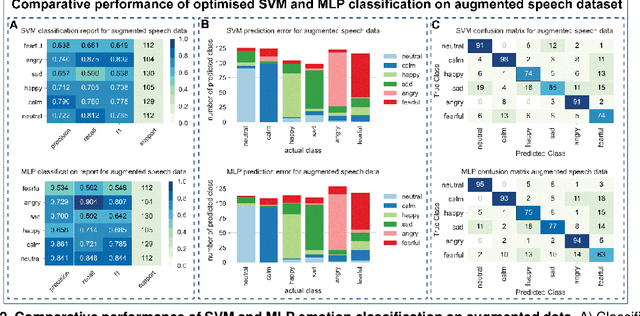
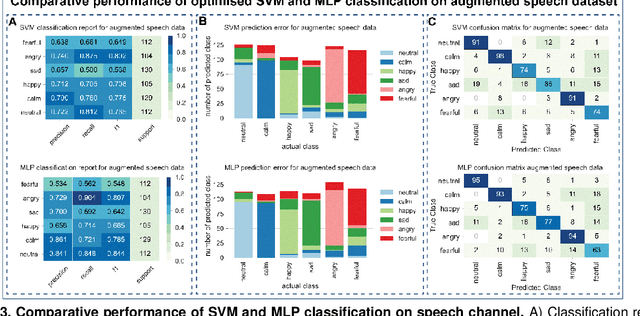
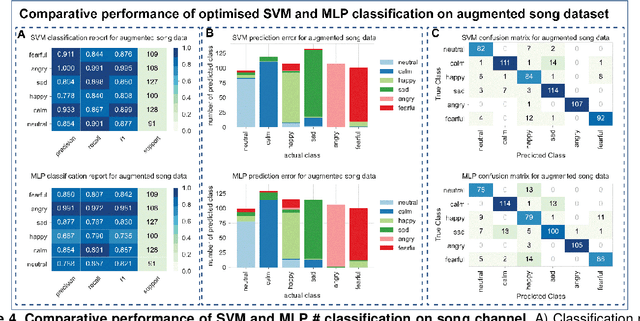
Herein, we have compared the performance of SVM and MLP in emotion recognition using speech and song channels of the RAVDESS dataset. We have undertaken a journey to extract various audio features, identify optimal scaling strategy and hyperparameter for our models. To increase sample size, we have performed audio data augmentation and addressed data imbalance using SMOTE. Our data indicate that optimised SVM outperforms MLP with an accuracy of 82 compared to 75%. Following data augmentation, the performance of both algorithms was identical at ~79%, however, overfitting was evident for the SVM. Our final exploration indicated that the performance of both SVM and MLP were similar in which both resulted in lower accuracy for the speech channel compared to the song channel. Our findings suggest that both SVM and MLP are powerful classifiers for emotion recognition in a vocal-dependent manner.
Streaming Transformer Transducer Based Speech Recognition Using Non-Causal Convolution
Oct 07, 2021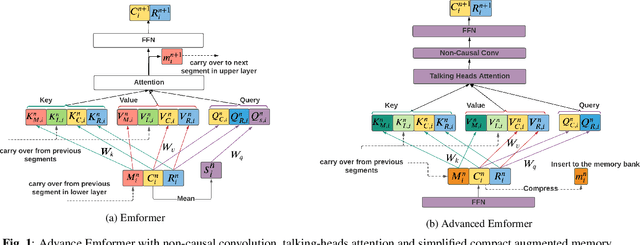
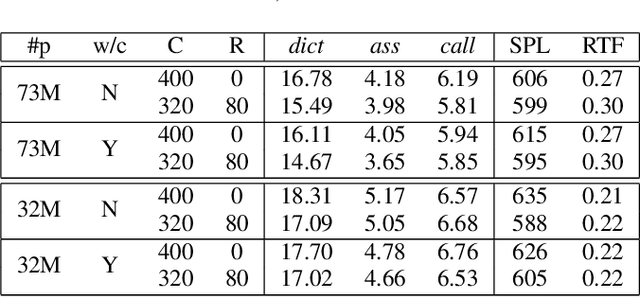
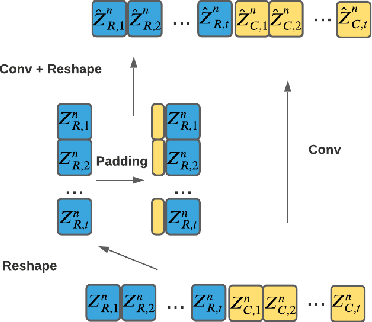
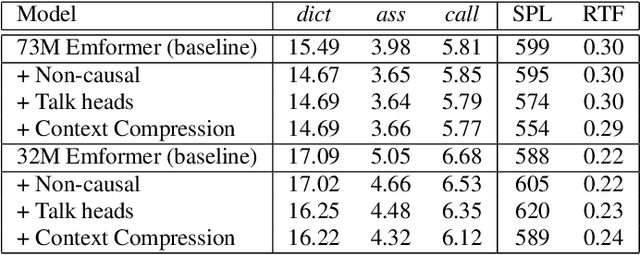
This paper improves the streaming transformer transducer for speech recognition by using non-causal convolution. Many works apply the causal convolution to improve streaming transformer ignoring the lookahead context. We propose to use non-causal convolution to process the center block and lookahead context separately. This method leverages the lookahead context in convolution and maintains similar training and decoding efficiency. Given the similar latency, using the non-causal convolution with lookahead context gives better accuracy than causal convolution, especially for open-domain dictation scenarios. Besides, this paper applies talking-head attention and a novel history context compression scheme to further improve the performance. The talking-head attention improves the multi-head self-attention by transferring information among different heads. The history context compression method introduces more extended history context compactly. On our in-house data, the proposed methods improve a small Emformer baseline with lookahead context by relative WERR 5.1\%, 14.5\%, 8.4\% on open-domain dictation, assistant general scenarios, and assistant calling scenarios, respectively.
Consonant-Vowel Transition Models Based on Deep Learning for Objective Evaluation of Articulation
Mar 18, 2022
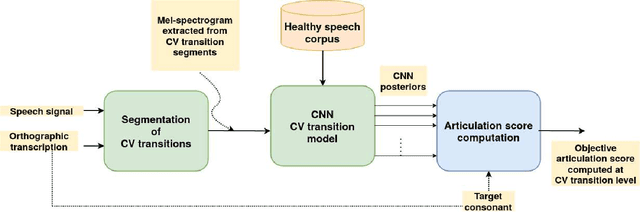
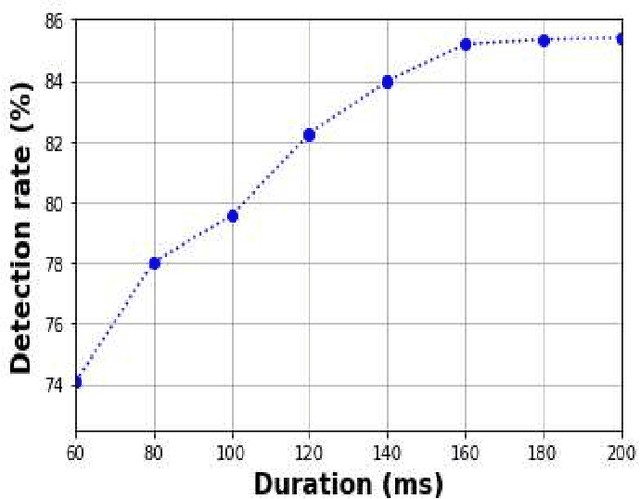
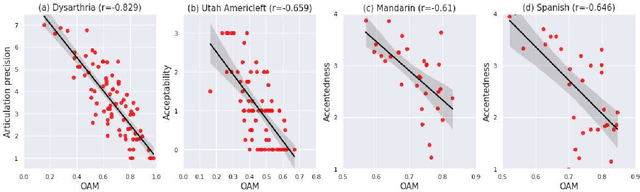
Spectro-temporal dynamics of consonant-vowel (CV) transition regions are considered to provide robust cues related to articulation. In this work, we propose an objective measure of precise articulation, dubbed the objective articulation measure (OAM), by analyzing the CV transitions segmented around vowel onsets. The OAM is derived based on the posteriors of a convolutional neural network pre-trained to classify between different consonants using CV regions as input. We demonstrate the OAM is correlated with perceptual measures in a variety of contexts including (a) adult dysarthric speech, (b) the speech of children with cleft lip/palate, and (c) a database of accented English speech from native Mandarin and Spanish speakers.
A review of on-device fully neural end-to-end automatic speech recognition algorithms
Dec 14, 2020
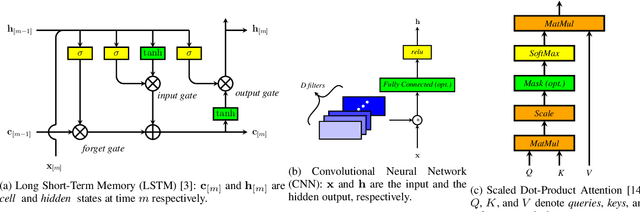
In this paper, we review various end-to-end automatic speech recognition algorithms and their optimization techniques for on-device applications. Conventional speech recognition systems comprise a large number of discrete components such as an acoustic model, a language model, a pronunciation model, a text-normalizer, an inverse-text normalizer, a decoder based on a Weighted Finite State Transducer (WFST), and so on. To obtain sufficiently high speech recognition accuracy with such conventional speech recognition systems, a very large language model (up to 100 GB) is usually needed. Hence, the corresponding WFST size becomes enormous, which prohibits their on-device implementation. Recently, fully neural network end-to-end speech recognition algorithms have been proposed. Examples include speech recognition systems based on Connectionist Temporal Classification (CTC), Recurrent Neural Network Transducer (RNN-T), Attention-based Encoder-Decoder models (AED), Monotonic Chunk-wise Attention (MoChA), transformer-based speech recognition systems, and so on. These fully neural network-based systems require much smaller memory footprints compared to conventional algorithms, therefore their on-device implementation has become feasible. In this paper, we review such end-to-end speech recognition models. We extensively discuss their structures, performance, and advantages compared to conventional algorithms.
Which one is more toxic? Findings from Jigsaw Rate Severity of Toxic Comments
Jun 27, 2022
The proliferation of online hate speech has necessitated the creation of algorithms which can detect toxicity. Most of the past research focuses on this detection as a classification task, but assigning an absolute toxicity label is often tricky. Hence, few of the past works transform the same task into a regression. This paper shows the comparative evaluation of different transformers and traditional machine learning models on a recently released toxicity severity measurement dataset by Jigsaw. We further demonstrate the issues with the model predictions using explainability analysis.
Continual Speaker Adaptation for Text-to-Speech Synthesis
Mar 26, 2021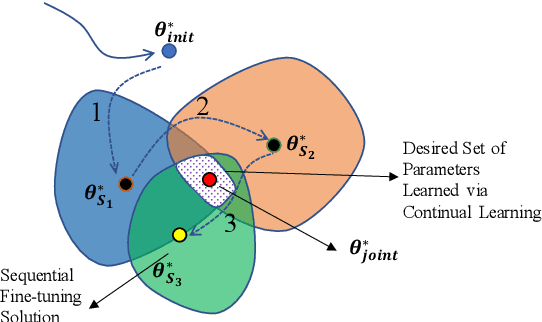
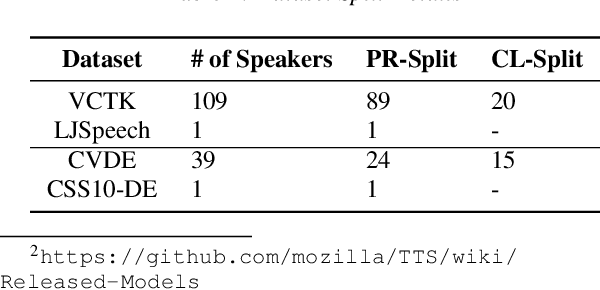
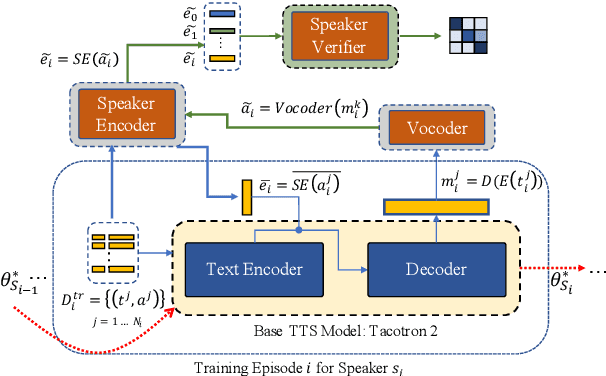
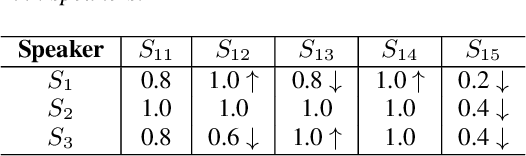
Training a multi-speaker Text-to-Speech (TTS) model from scratch is computationally expensive and adding new speakers to the dataset requires the model to be re-trained. The naive solution of sequential fine-tuning of a model for new speakers can cause the model to have poor performance on older speakers. This phenomenon is known as catastrophic forgetting. In this paper, we look at TTS modeling from a continual learning perspective where the goal is to add new speakers without forgetting previous speakers. Therefore, we first propose an experimental setup and show that serial fine-tuning for new speakers can result in the forgetting of the previous speakers. Then we exploit two well-known techniques for continual learning namely experience replay and weight regularization and we reveal how one can mitigate the effect of degradation in speech synthesis diversity in sequential training of new speakers using these methods. Finally, we present a simple extension to improve the results in extreme setups.
Machine Learning based COVID-19 Detection from Smartphone Recordings: Cough, Breath and Speech
Apr 02, 2021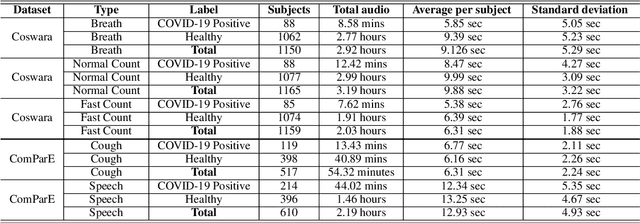
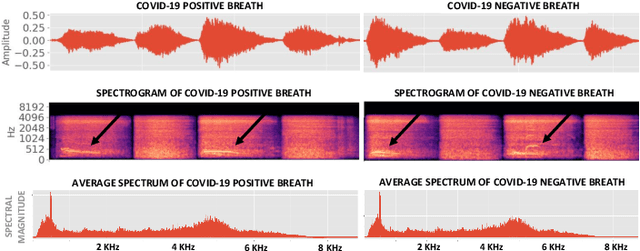
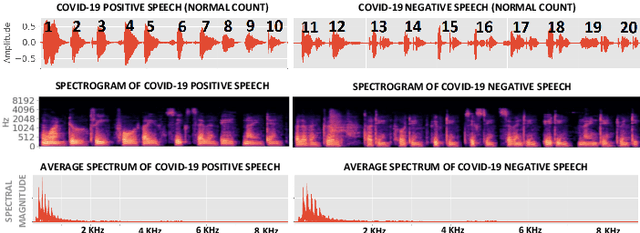
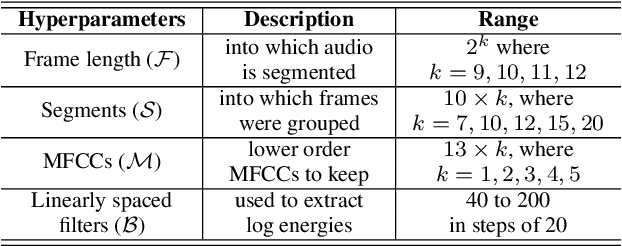
We present an experimental investigation into the automatic detection of COVID-19 from smartphone recordings of coughs, breaths and speech. This type of screening is attractive because it is non-contact, does not require specialist medical expertise or laboratory facilities and can easily be deployed on inexpensive consumer hardware. We base our experiments on two datasets, Coswara and ComParE, containing recordings of coughing, breathing and speech from subjects around the globe. We have considered seven machine learning classifiers and all of them are trained and evaluated using leave-p-out cross-validation. For the Coswara data, the highest AUC of 0.92 was achieved using a Resnet50 architecture on breaths. For the ComParE data, the highest AUC of 0.93 was achieved using a k-nearest neighbours (KNN) classifier on cough recordings after selecting the best 12 features using sequential forward selection (SFS) and the highest AUC of 0.91 was also achieved on speech by a multilayer perceptron (MLP) when using SFS to select the best 23 features. We conclude that among all vocal audio, coughs carry the strongest COVID-19 signature followed by breath and speech. Although these signatures are not perceivable by human ear, machine learning based COVID-19 detection is possible from vocal audio recorded via smartphone.
Cross-Modal Transformer-Based Neural Correction Models for Automatic Speech Recognition
Jul 04, 2021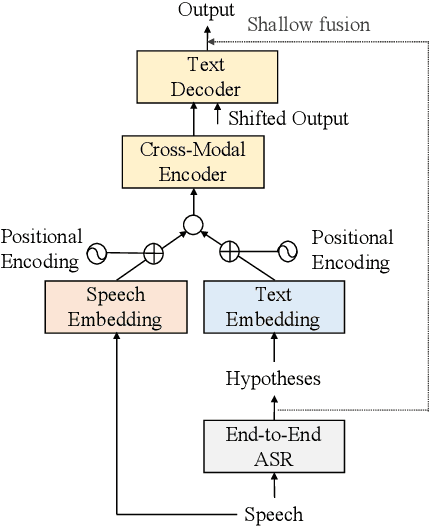
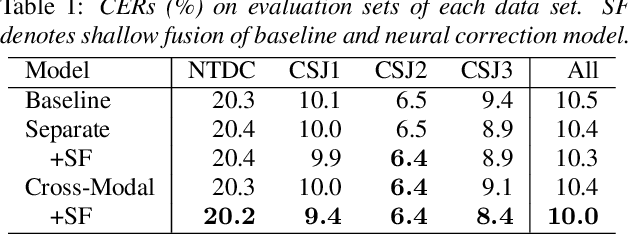
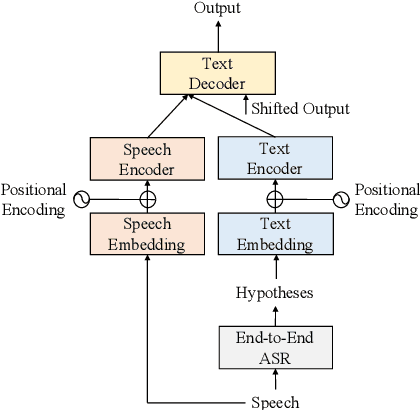
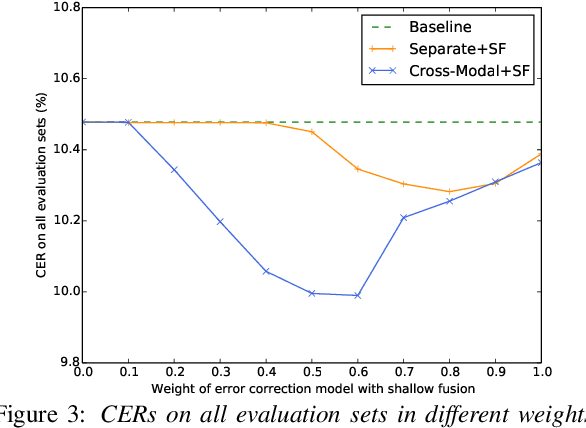
We propose a cross-modal transformer-based neural correction models that refines the output of an automatic speech recognition (ASR) system so as to exclude ASR errors. Generally, neural correction models are composed of encoder-decoder networks, which can directly model sequence-to-sequence mapping problems. The most successful method is to use both input speech and its ASR output text as the input contexts for the encoder-decoder networks. However, the conventional method cannot take into account the relationships between these two different modal inputs because the input contexts are separately encoded for each modal. To effectively leverage the correlated information between the two different modal inputs, our proposed models encode two different contexts jointly on the basis of cross-modal self-attention using a transformer. We expect that cross-modal self-attention can effectively capture the relationships between two different modals for refining ASR hypotheses. We also introduce a shallow fusion technique to efficiently integrate the first-pass ASR model and our proposed neural correction model. Experiments on Japanese natural language ASR tasks demonstrated that our proposed models achieve better ASR performance than conventional neural correction models.
IMS-Speech: A Speech to Text Tool
Aug 13, 2019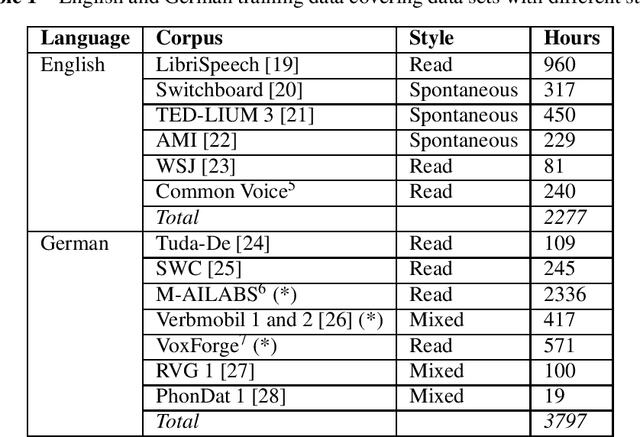


We present the IMS-Speech, a web based tool for German and English speech transcription aiming to facilitate research in various disciplines which require accesses to lexical information in spoken language materials. This tool is based on modern open source software stack, advanced speech recognition methods and public data resources and is freely available for academic researchers. The utilized models are built to be generic in order to provide transcriptions of competitive accuracy on a diverse set of tasks and conditions.
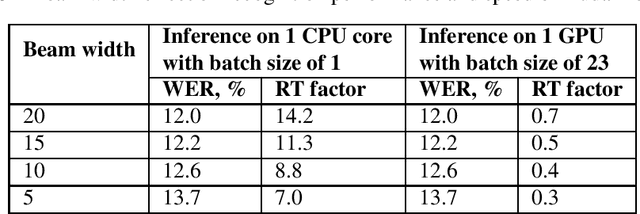
Training end-to-end speech-to-text models on mobile phones
Dec 07, 2021
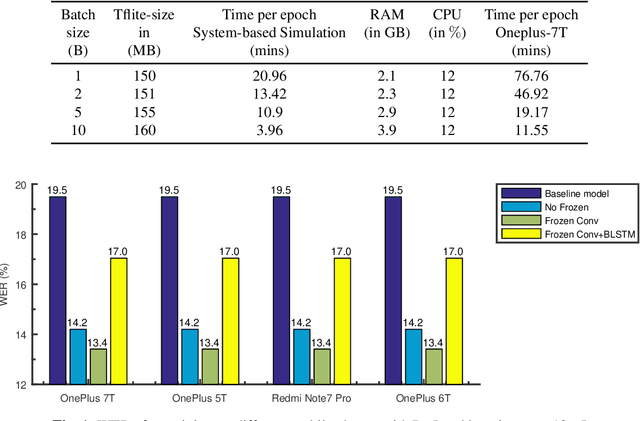
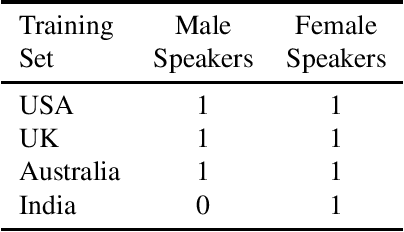
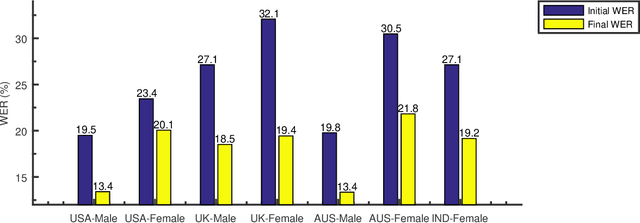
Training the state-of-the-art speech-to-text (STT) models in mobile devices is challenging due to its limited resources relative to a server environment. In addition, these models are trained on generic datasets that are not exhaustive in capturing user-specific characteristics. Recently, on-device personalization techniques have been making strides in mitigating the problem. Although many current works have already explored the effectiveness of on-device personalization, the majority of their findings are limited to simulation settings or a specific smartphone. In this paper, we develop and provide a detailed explanation of our framework to train end-to-end models in mobile phones. To make it simple, we considered a model based on connectionist temporal classification (CTC) loss. We evaluated the framework on various mobile phones from different brands and reported the results. We provide enough evidence that fine-tuning the models and choosing the right hyperparameter values is a trade-off between the lowest WER achievable, training time on-device, and memory consumption. Hence, this is vital for a successful deployment of on-device training onto a resource-limited environment like mobile phones. We use training sets from speakers with different accents and record a 7.6% decrease in average word error rate (WER). We also report the associated computational cost measurements with respect to time, memory usage, and cpu utilization in mobile phones in real-time.