 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
"Short is the Road that Leads from Fear to Hate": Fear Speech in Indian WhatsApp Groups
Feb 07, 2021
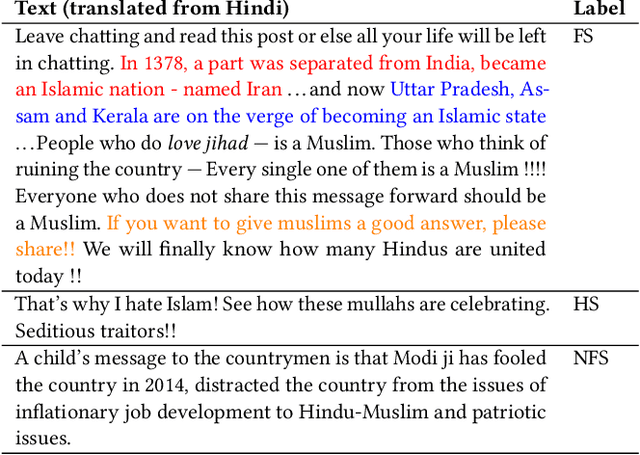
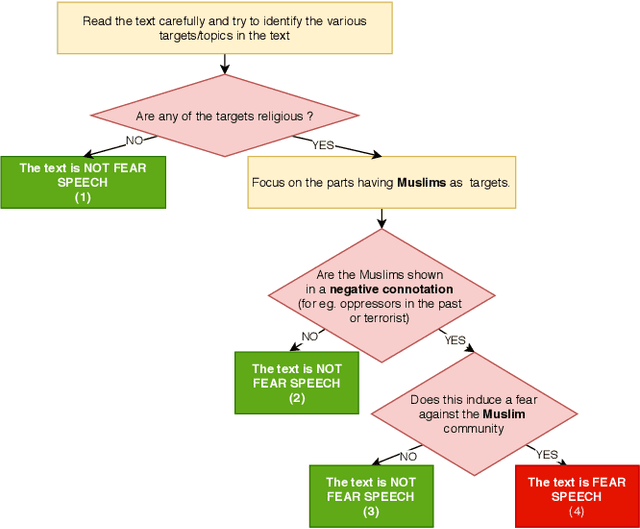

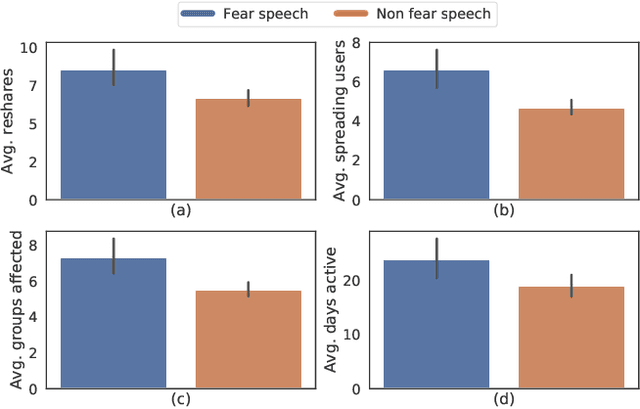
WhatsApp is the most popular messaging app in the world. Due to its popularity, WhatsApp has become a powerful and cheap tool for political campaigning being widely used during the 2019 Indian general election, where it was used to connect to the voters on a large scale. Along with the campaigning, there have been reports that WhatsApp has also become a breeding ground for harmful speech against various protected groups and religious minorities. Many such messages attempt to instil fear among the population about a specific (minority) community. According to research on inter-group conflict, such `fear speech' messages could have a lasting impact and might lead to real offline violence. In this paper, we perform the first large scale study on fear speech across thousands of public WhatsApp groups discussing politics in India. We curate a new dataset and try to characterize fear speech from this dataset. We observe that users writing fear speech messages use various events and symbols to create the illusion of fear among the reader about a target community. We build models to classify fear speech and observe that current state-of-the-art NLP models do not perform well at this task. Fear speech messages tend to spread faster and could potentially go undetected by classifiers built to detect traditional toxic speech due to their low toxic nature. Finally, using a novel methodology to target users with Facebook ads, we conduct a survey among the users of these WhatsApp groups to understand the types of users who consume and share fear speech. We believe that this work opens up new research questions that are very different from tackling hate speech which the research community has been traditionally involved in.
KOLD: Korean Offensive Language Dataset
May 23, 2022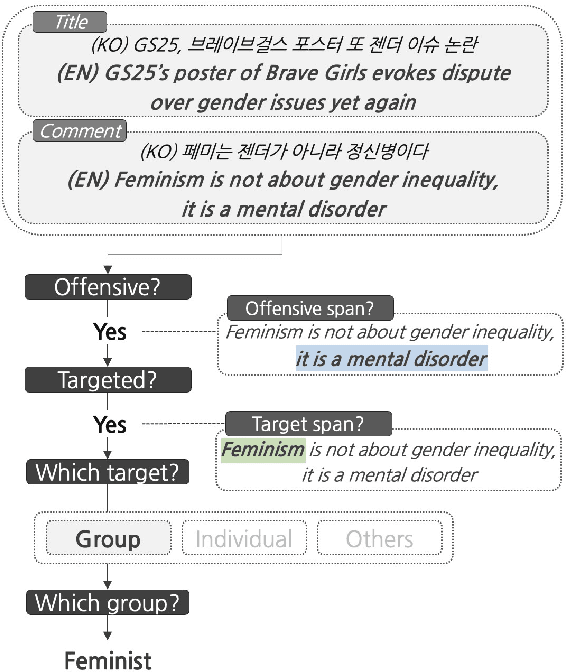
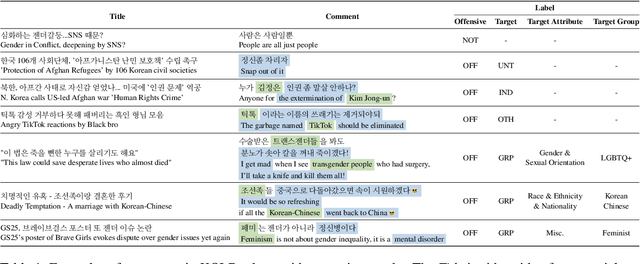
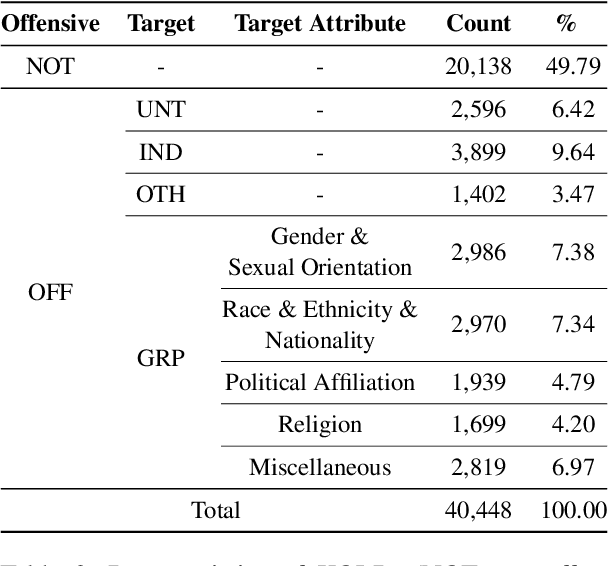
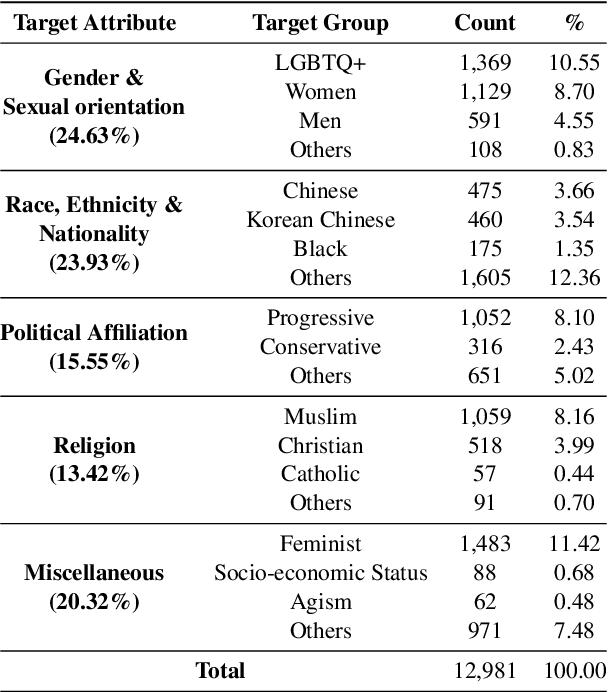
Although large attention has been paid to the detection of hate speech, most work has been done in English, failing to make it applicable to other languages. To fill this gap, we present a Korean offensive language dataset (KOLD), 40k comments labeled with offensiveness, target, and targeted group information. We also collect two types of span, offensive and target span that justifies the decision of the categorization within the text. Comparing the distribution of targeted groups with the existing English dataset, we point out the necessity of a hate speech dataset fitted to the language that best reflects the culture. Trained with our dataset, we report the baseline performance of the models built on top of large pretrained language models. We also show that title information serves as context and is helpful to discern the target of hatred, especially when they are omitted in the comment.
Conformal prediction for text infilling and part-of-speech prediction
Nov 04, 2021
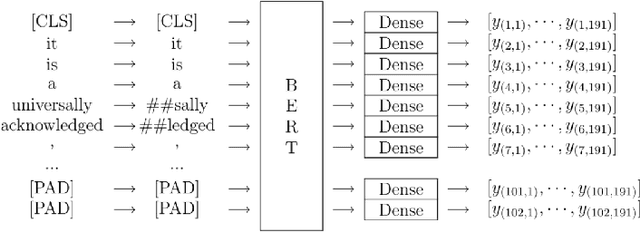
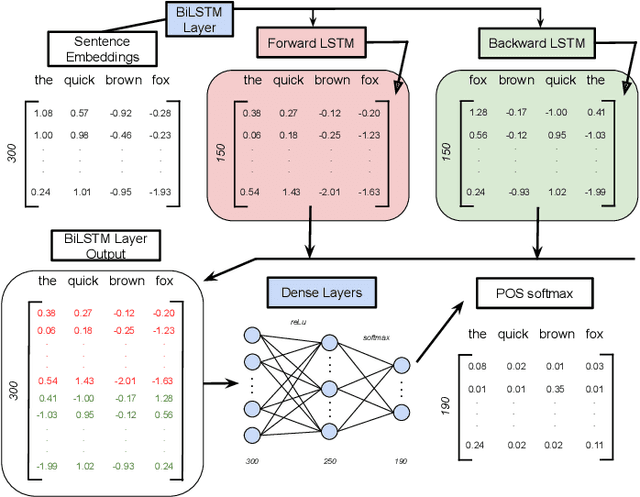
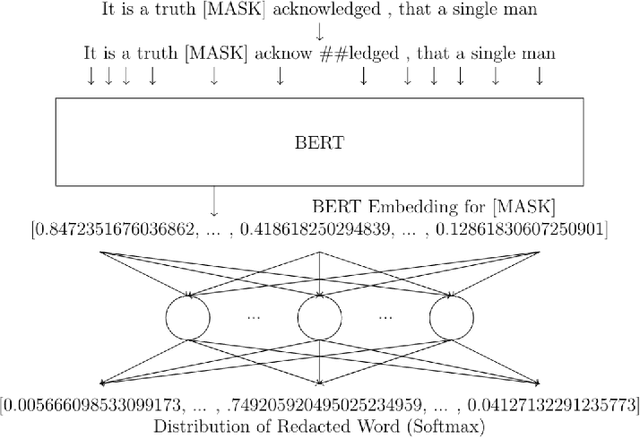
Modern machine learning algorithms are capable of providing remarkably accurate point-predictions; however, questions remain about their statistical reliability. Unlike conventional machine learning methods, conformal prediction algorithms return confidence sets (i.e., set-valued predictions) that correspond to a given significance level. Moreover, these confidence sets are valid in the sense that they guarantee finite sample control over type 1 error probabilities, allowing the practitioner to choose an acceptable error rate. In our paper, we propose inductive conformal prediction (ICP) algorithms for the tasks of text infilling and part-of-speech (POS) prediction for natural language data. We construct new conformal prediction-enhanced bidirectional encoder representations from transformers (BERT) and bidirectional long short-term memory (BiLSTM) algorithms for POS tagging and a new conformal prediction-enhanced BERT algorithm for text infilling. We analyze the performance of the algorithms in simulations using the Brown Corpus, which contains over 57,000 sentences. Our results demonstrate that the ICP algorithms are able to produce valid set-valued predictions that are small enough to be applicable in real-world applications. We also provide a real data example for how our proposed set-valued predictions can improve machine generated audio transcriptions.
Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition
Sep 14, 2021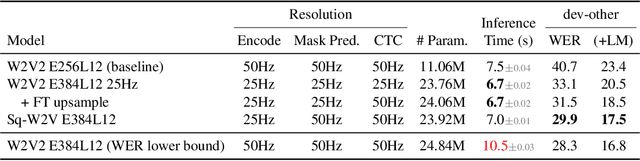
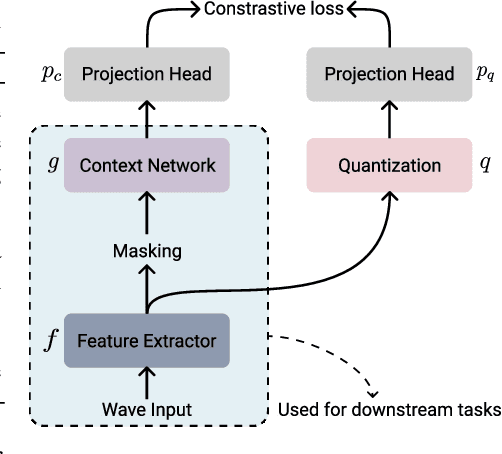
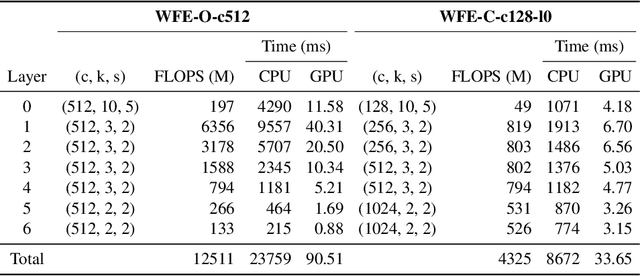
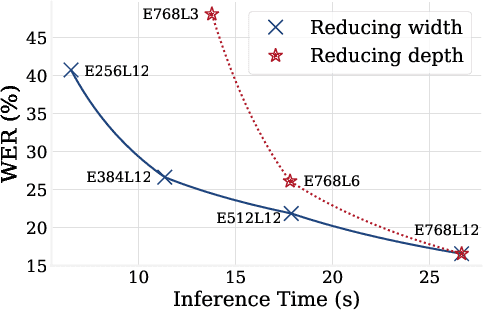
This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition (ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference time, SEW reduces word error rate by 25-50% across different model sizes.
Podcast Summary Assessment: A Resource for Evaluating Summary Assessment Methods
Aug 28, 2022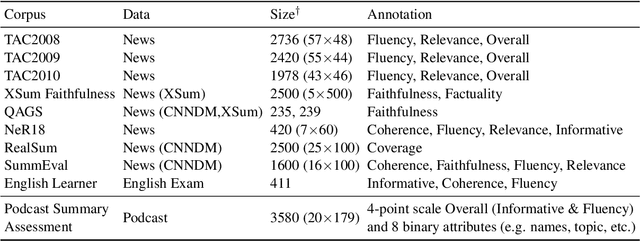
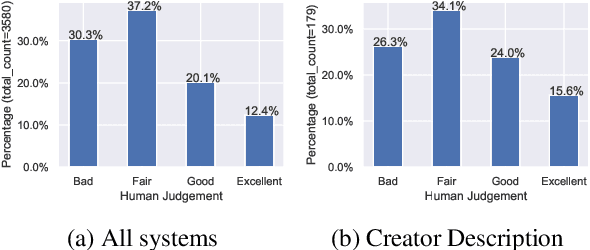
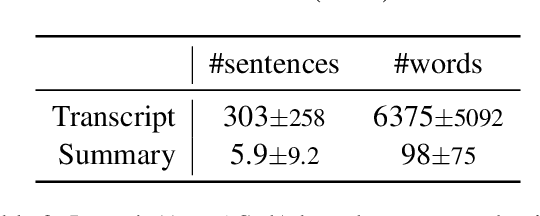
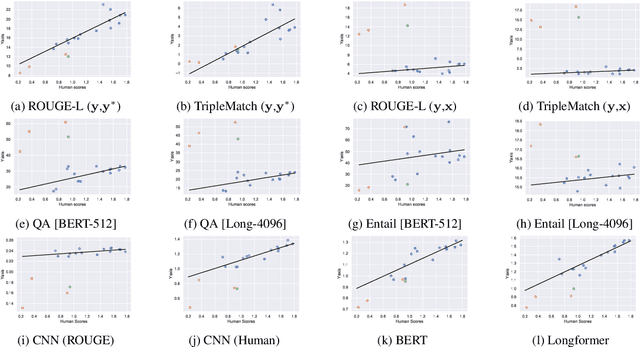
Automatic summary assessment is useful for both machine-generated and human-produced summaries. Automatically evaluating the summary text given the document enables, for example, summary generation system development and detection of inappropriate summaries. Summary assessment can be run in a number of modes: ranking summary generation systems; ranking summaries of a particular document; and estimating the quality of a document-summary pair on an absolute scale. Existing datasets with annotation for summary assessment are usually based on news summarization datasets such as CNN/DailyMail or XSum. In this work, we describe a new dataset, the podcast summary assessment corpus, a collection of podcast summaries that were evaluated by human experts at TREC2020. Compared to existing summary assessment data, this dataset has two unique aspects: (i) long-input, speech podcast based, documents; and (ii) an opportunity to detect inappropriate reference summaries in podcast corpus. First, we examine existing assessment methods, including model-free and model-based methods, and provide benchmark results for this long-input summary assessment dataset. Second, with the aim of filtering reference summary-document pairings for training, we apply summary assessment for data selection. The experimental results on these two aspects provide interesting insights on the summary assessment and generation tasks. The podcast summary assessment data is available.
Speech & Song Emotion Recognition Using Multilayer Perceptron and Standard Vector Machine
May 19, 2021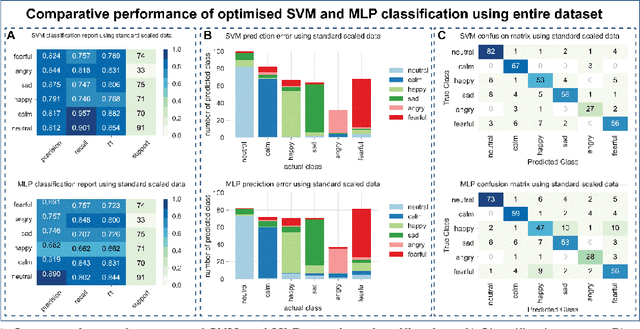
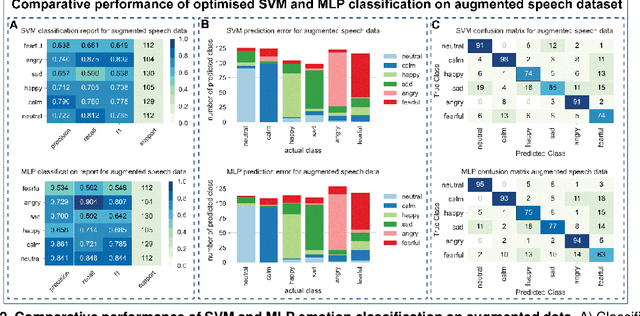
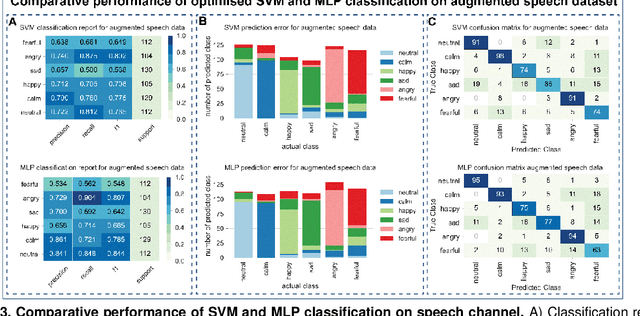
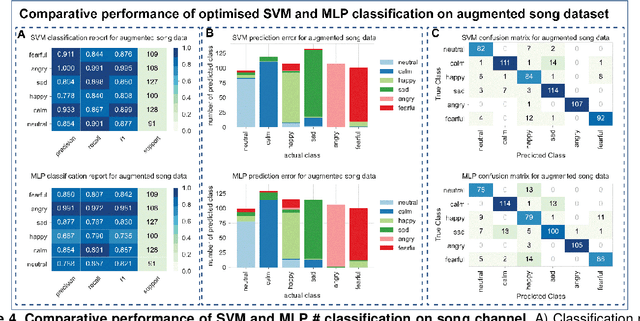
Herein, we have compared the performance of SVM and MLP in emotion recognition using speech and song channels of the RAVDESS dataset. We have undertaken a journey to extract various audio features, identify optimal scaling strategy and hyperparameter for our models. To increase sample size, we have performed audio data augmentation and addressed data imbalance using SMOTE. Our data indicate that optimised SVM outperforms MLP with an accuracy of 82 compared to 75%. Following data augmentation, the performance of both algorithms was identical at ~79%, however, overfitting was evident for the SVM. Our final exploration indicated that the performance of both SVM and MLP were similar in which both resulted in lower accuracy for the speech channel compared to the song channel. Our findings suggest that both SVM and MLP are powerful classifiers for emotion recognition in a vocal-dependent manner.
Streaming Transformer Transducer Based Speech Recognition Using Non-Causal Convolution
Oct 07, 2021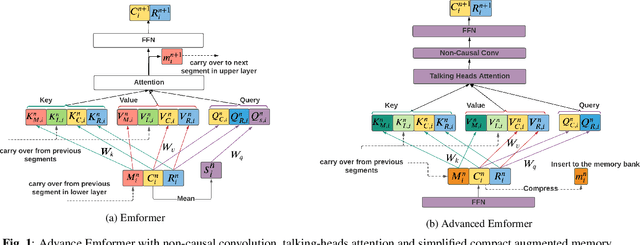
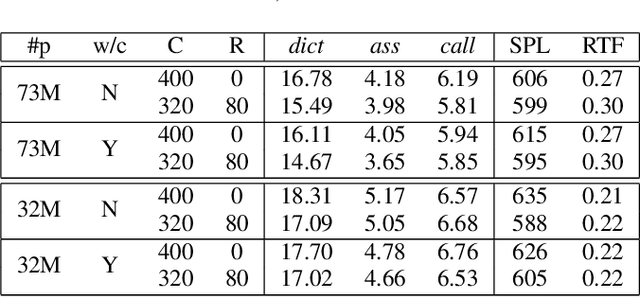
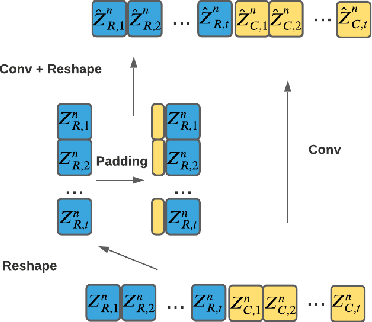
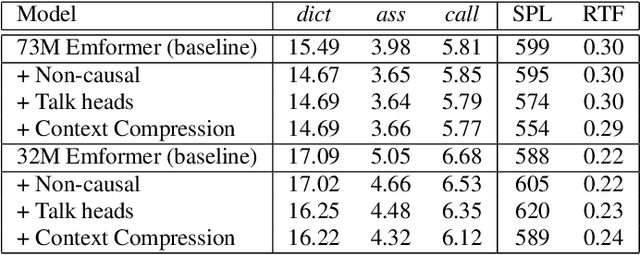
This paper improves the streaming transformer transducer for speech recognition by using non-causal convolution. Many works apply the causal convolution to improve streaming transformer ignoring the lookahead context. We propose to use non-causal convolution to process the center block and lookahead context separately. This method leverages the lookahead context in convolution and maintains similar training and decoding efficiency. Given the similar latency, using the non-causal convolution with lookahead context gives better accuracy than causal convolution, especially for open-domain dictation scenarios. Besides, this paper applies talking-head attention and a novel history context compression scheme to further improve the performance. The talking-head attention improves the multi-head self-attention by transferring information among different heads. The history context compression method introduces more extended history context compactly. On our in-house data, the proposed methods improve a small Emformer baseline with lookahead context by relative WERR 5.1\%, 14.5\%, 8.4\% on open-domain dictation, assistant general scenarios, and assistant calling scenarios, respectively.
A review of on-device fully neural end-to-end automatic speech recognition algorithms
Dec 14, 2020
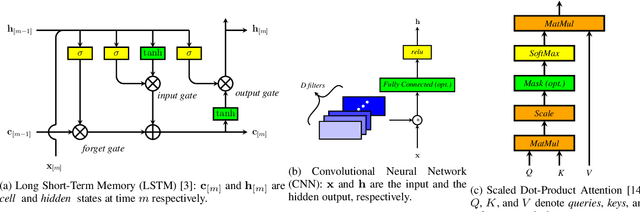
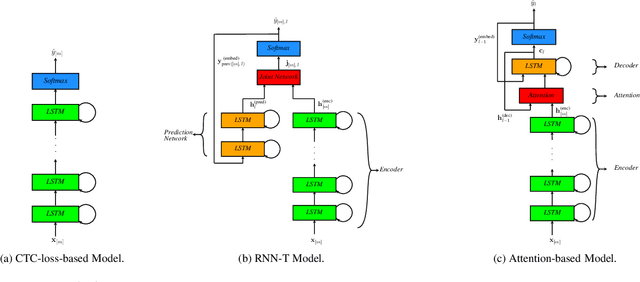
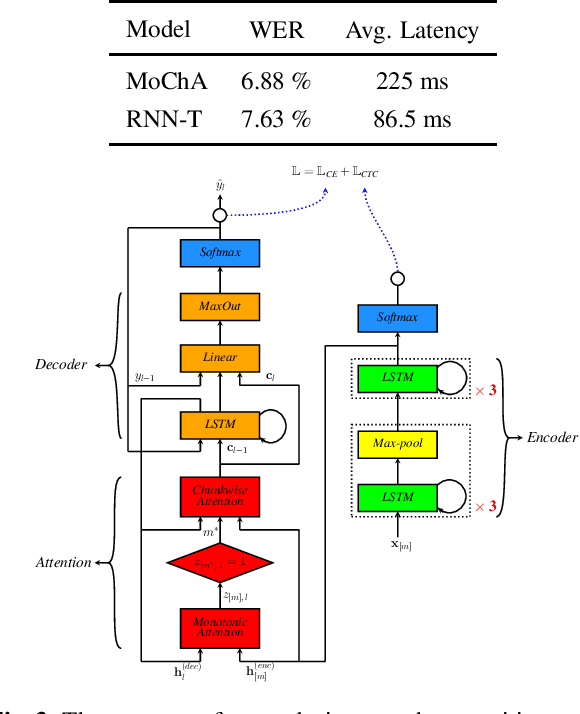
In this paper, we review various end-to-end automatic speech recognition algorithms and their optimization techniques for on-device applications. Conventional speech recognition systems comprise a large number of discrete components such as an acoustic model, a language model, a pronunciation model, a text-normalizer, an inverse-text normalizer, a decoder based on a Weighted Finite State Transducer (WFST), and so on. To obtain sufficiently high speech recognition accuracy with such conventional speech recognition systems, a very large language model (up to 100 GB) is usually needed. Hence, the corresponding WFST size becomes enormous, which prohibits their on-device implementation. Recently, fully neural network end-to-end speech recognition algorithms have been proposed. Examples include speech recognition systems based on Connectionist Temporal Classification (CTC), Recurrent Neural Network Transducer (RNN-T), Attention-based Encoder-Decoder models (AED), Monotonic Chunk-wise Attention (MoChA), transformer-based speech recognition systems, and so on. These fully neural network-based systems require much smaller memory footprints compared to conventional algorithms, therefore their on-device implementation has become feasible. In this paper, we review such end-to-end speech recognition models. We extensively discuss their structures, performance, and advantages compared to conventional algorithms.
Speaker Recognition in the Wild
May 05, 2022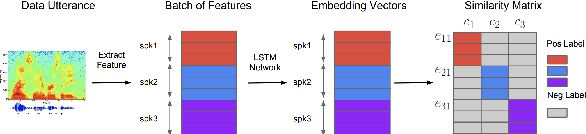

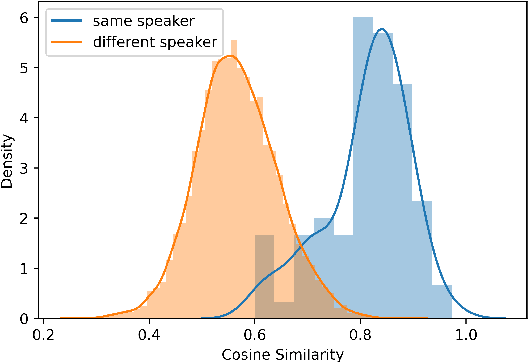
In this paper, we propose a pipeline to find the number of speakers, as well as audios belonging to each of these now identified speakers in a source of audio data where number of speakers or speaker labels are not known a priori. We used this approach as a part of our Data Preparation pipeline for Speech Recognition in Indic Languages (https://github.com/Open-Speech-EkStep/vakyansh-wav2vec2-experimentation). To understand and evaluate the accuracy of our proposed pipeline, we introduce two metrics: Cluster Purity, and Cluster Uniqueness. Cluster Purity quantifies how "pure" a cluster is. Cluster Uniqueness, on the other hand, quantifies what percentage of clusters belong only to a single dominant speaker. We discuss more on these metrics in section \ref{sec:metrics}. Since we develop this utility to aid us in identifying data based on speaker IDs before training an Automatic Speech Recognition (ASR) model, and since most of this data takes considerable effort to scrape, we also conclude that 98\% of data gets mapped to the top 80\% of clusters (computed by removing any clusters with less than a fixed number of utterances -- we do this to get rid of some very small clusters and use this threshold as 30), in the test set chosen.
Noise-robust voice conversion with domain adversarial training
Jan 26, 2022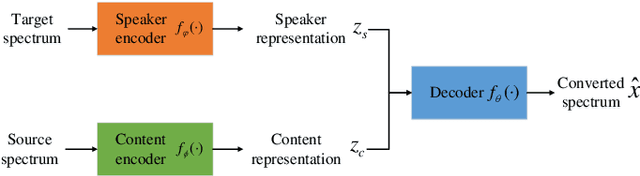
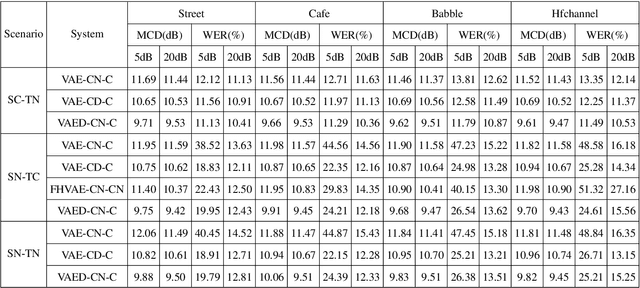
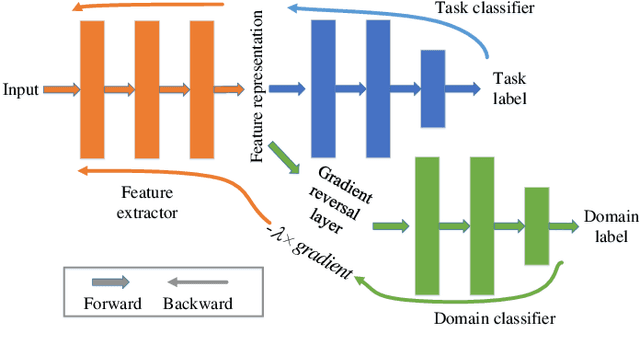
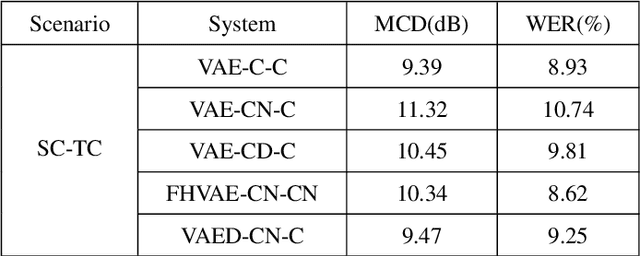
Voice conversion has made great progress in the past few years under the studio-quality test scenario in terms of speech quality and speaker similarity. However, in real applications, test speech from source speaker or target speaker can be corrupted by various environment noises, which seriously degrade the speech quality and speaker similarity. In this paper, we propose a novel encoder-decoder based noise-robust voice conversion framework, which consists of a speaker encoder, a content encoder, a decoder, and two domain adversarial neural networks. Specifically, we integrate disentangling speaker and content representation technique with domain adversarial training technique. Domain adversarial training makes speaker representations and content representations extracted by speaker encoder and content encoder from clean speech and noisy speech in the same space, respectively. In this way, the learned speaker and content representations are noise-invariant. Therefore, the two noise-invariant representations can be taken as input by the decoder to predict the clean converted spectrum. The experimental results demonstrate that our proposed method can synthesize clean converted speech under noisy test scenarios, where the source speech and target speech can be corrupted by seen or unseen noise types during the training process. Additionally, both speech quality and speaker similarity are improved.