 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Respiratory Distress Detection from Telephone Speech using Acoustic and Prosodic Features
Nov 15, 2020
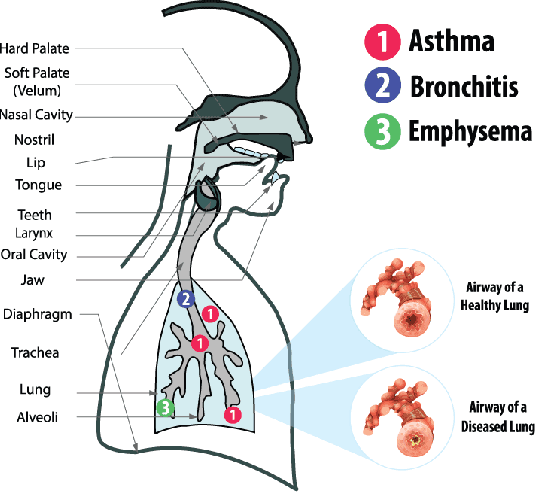

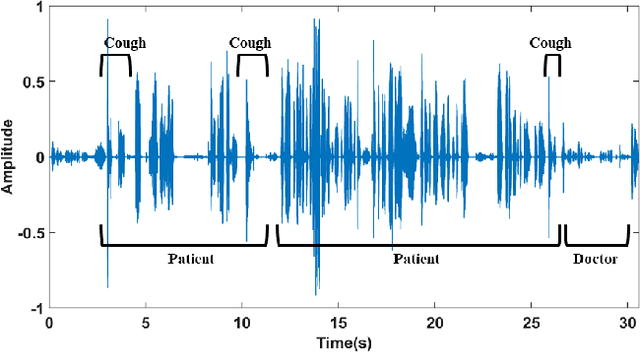
With the widespread use of telemedicine services, automatic assessment of health conditions via telephone speech can significantly impact public health. This work summarizes our preliminary findings on automatic detection of respiratory distress using well-known acoustic and prosodic features. Speech samples are collected from de-identified telemedicine phonecalls from a healthcare provider in Bangladesh. The recordings include conversational speech samples of patients talking to doctors showing mild or severe respiratory distress or asthma symptoms. We hypothesize that respiratory distress may alter speech features such as voice quality, speaking pattern, loudness, and speech-pause duration. To capture these variations, we utilize a set of well-known acoustic and prosodic features with a Support Vector Machine (SVM) classifier for detecting the presence of respiratory distress. Experimental evaluations are performed using a 3-fold cross-validation scheme, ensuring patient-independent data splits. We obtained an overall accuracy of 86.4\% in detecting respiratory distress from the speech recordings using the acoustic feature set. Correlation analysis reveals that the top-performing features include loudness, voice rate, voice duration, and pause duration.
Speech Emotion Recognition Using Deep Sparse Auto-Encoder Extreme Learning Machine with a New Weighting Scheme and Spectro-Temporal Features Along with Classical Feature Selection and A New Quantum-Inspired Dimension Reduction Method
Nov 13, 2021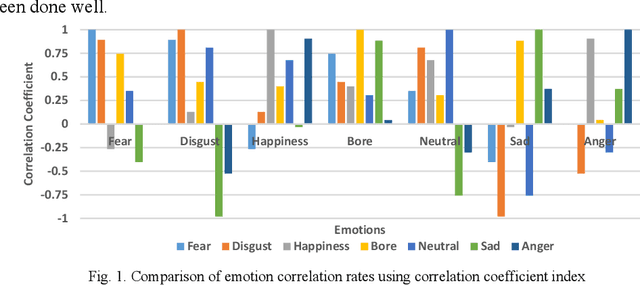
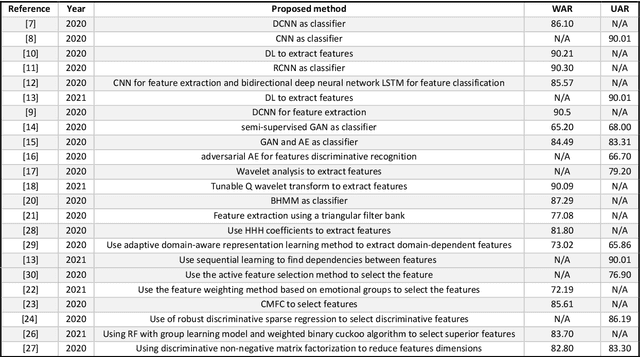
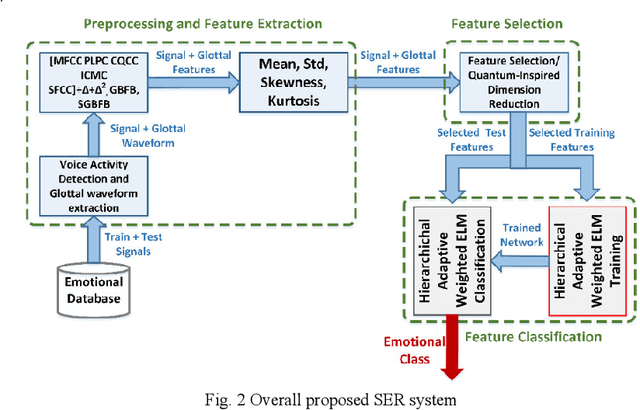

Affective computing is very important in the relationship between man and machine. In this paper, a system for speech emotion recognition (SER) based on speech signal is proposed, which uses new techniques in different stages of processing. The system consists of three stages: feature extraction, feature selection, and finally feature classification. In the first stage, a complex set of long-term statistics features is extracted from both the speech signal and the glottal-waveform signal using a combination of new and diverse features such as prosodic, spectral, and spectro-temporal features. One of the challenges of the SER systems is to distinguish correlated emotions. These features are good discriminators for speech emotions and increase the SER's ability to recognize similar and different emotions. This feature vector with a large number of dimensions naturally has redundancy. In the second stage, using classical feature selection techniques as well as a new quantum-inspired technique to reduce the feature vector dimensionality, the number of feature vector dimensions is reduced. In the third stage, the optimized feature vector is classified by a weighted deep sparse extreme learning machine (ELM) classifier. The classifier performs classification in three steps: sparse random feature learning, orthogonal random projection using the singular value decomposition (SVD) technique, and discriminative classification in the last step using the generalized Tikhonov regularization technique. Also, many existing emotional datasets suffer from the problem of data imbalanced distribution, which in turn increases the classification error and decreases system performance. In this paper, a new weighting method has also been proposed to deal with class imbalance, which is more efficient than existing weighting methods. The proposed method is evaluated on three standard emotional databases.
Avoid Overfitting User Specific Information in Federated Keyword Spotting
Jun 17, 2022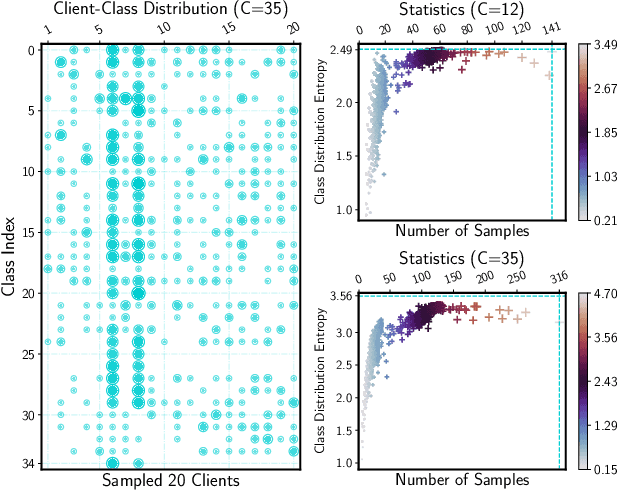
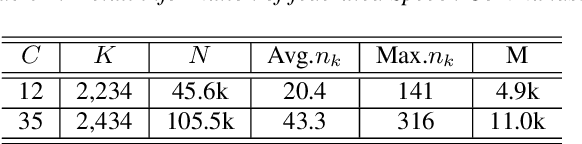
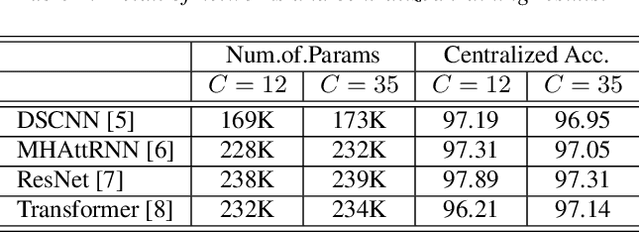
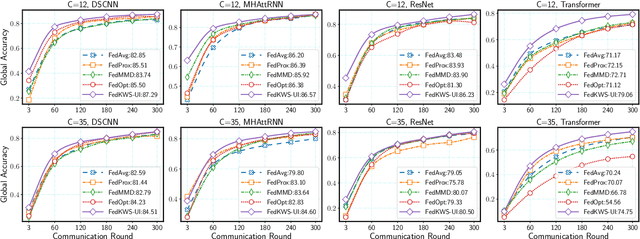
Keyword spotting (KWS) aims to discriminate a specific wake-up word from other signals precisely and efficiently for different users. Recent works utilize various deep networks to train KWS models with all users' speech data centralized without considering data privacy. Federated KWS (FedKWS) could serve as a solution without directly sharing users' data. However, the small amount of data, different user habits, and various accents could lead to fatal problems, e.g., overfitting or weight divergence. Hence, we propose several strategies to encourage the model not to overfit user-specific information in FedKWS. Specifically, we first propose an adversarial learning strategy, which updates the downloaded global model against an overfitted local model and explicitly encourages the global model to capture user-invariant information. Furthermore, we propose an adaptive local training strategy, letting clients with more training data and more uniform class distributions undertake more local update steps. Equivalently, this strategy could weaken the negative impacts of those users whose data is less qualified. Our proposed FedKWS-UI could explicitly and implicitly learn user-invariant information in FedKWS. Abundant experimental results on federated Google Speech Commands verify the effectiveness of FedKWS-UI.
Uconv-Conformer: High Reduction of Input Sequence Length for End-to-End Speech Recognition
Aug 16, 2022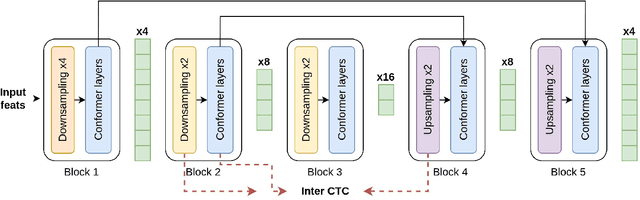
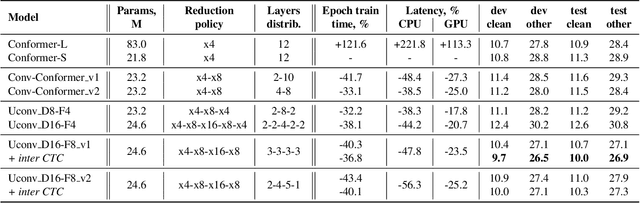
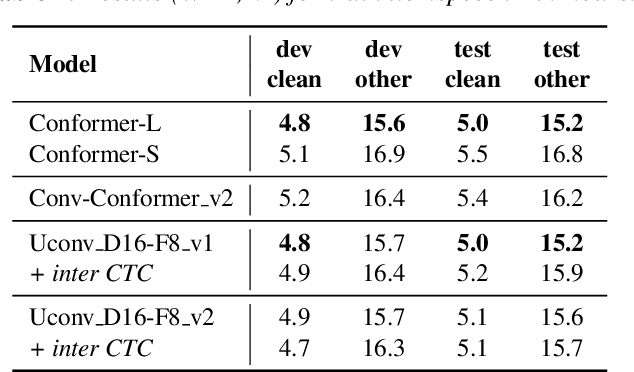
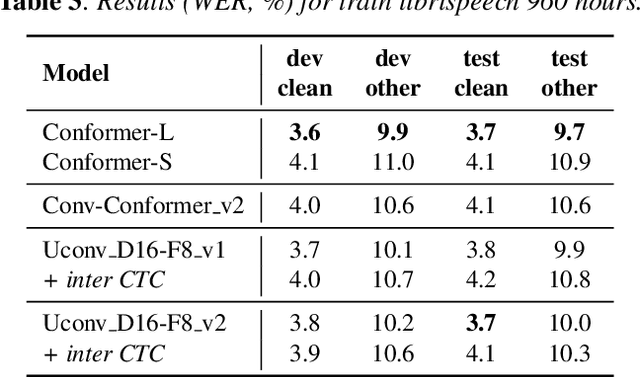
Optimization of modern ASR architectures is among the highest priority tasks since it saves many computational resources for model training and inference. The work proposes a new Uconv-Conformer architecture based on the standard Conformer model that consistently reduces the input sequence length by 16 times, which results in speeding up the work of the intermediate layers. To solve the convergence problem with such a significant reduction of the time dimension, we use upsampling blocks similar to the U-Net architecture to ensure the correct CTC loss calculation and stabilize network training. The Uconv-Conformer architecture appears to be not only faster in terms of training and inference but also shows better WER compared to the baseline Conformer. Our best Uconv-Conformer model showed 40.3% epoch training time reduction, 47.8%, and 23.5% inference acceleration on the CPU and GPU, respectively. Relative WER on Librispeech test_clean and test_other decreased by 7.3% and 9.2%.
Improving Multilingual Neural Machine Translation System for Indic Languages
Sep 27, 2022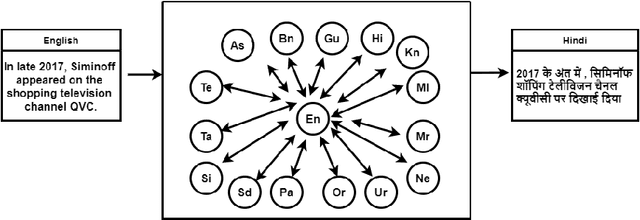
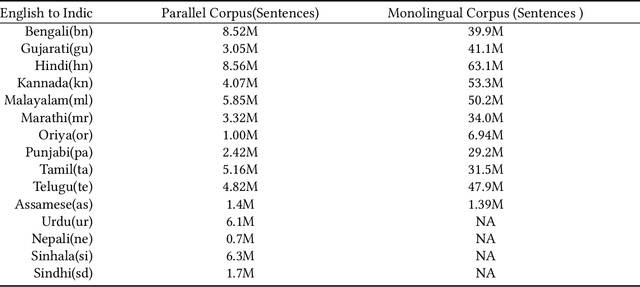
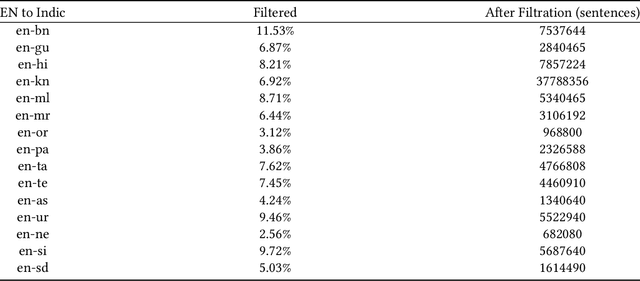
Machine Translation System (MTS) serves as an effective tool for communication by translating text or speech from one language to another language. The need of an efficient translation system becomes obvious in a large multilingual environment like India, where English and a set of Indian Languages (ILs) are officially used. In contrast with English, ILs are still entreated as low-resource languages due to unavailability of corpora. In order to address such asymmetric nature, multilingual neural machine translation (MNMT) system evolves as an ideal approach in this direction. In this paper, we propose a MNMT system to address the issues related to low-resource language translation. Our model comprises of two MNMT systems i.e. for English-Indic (one-to-many) and the other for Indic-English (many-to-one) with a shared encoder-decoder containing 15 language pairs (30 translation directions). Since most of IL pairs have scanty amount of parallel corpora, not sufficient for training any machine translation model. We explore various augmentation strategies to improve overall translation quality through the proposed model. A state-of-the-art transformer architecture is used to realize the proposed model. Trials over a good amount of data reveal its superiority over the conventional models. In addition, the paper addresses the use of language relationships (in terms of dialect, script, etc.), particularly about the role of high-resource languages of the same family in boosting the performance of low-resource languages. Moreover, the experimental results also show the advantage of backtranslation and domain adaptation for ILs to enhance the translation quality of both source and target languages. Using all these key approaches, our proposed model emerges to be more efficient than the baseline model in terms of evaluation metrics i.e BLEU (BiLingual Evaluation Understudy) score for a set of ILs.
Combining Spatial Clustering with LSTM Speech Models for Multichannel Speech Enhancement
Dec 02, 2020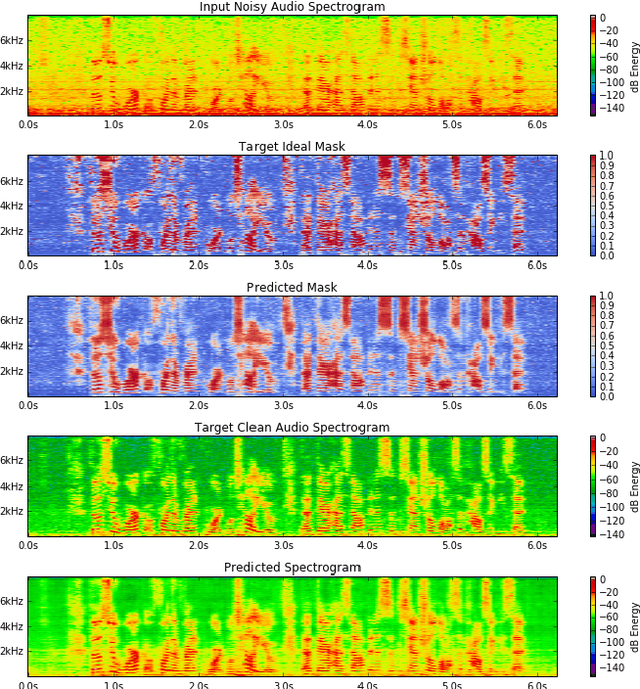
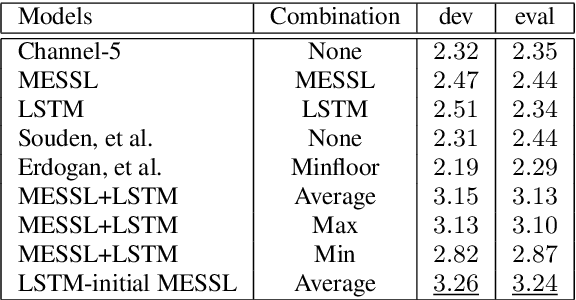
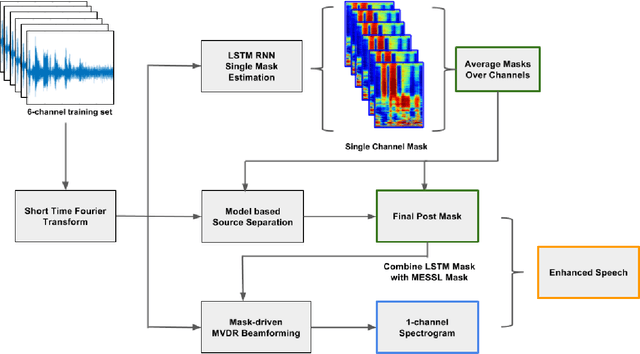
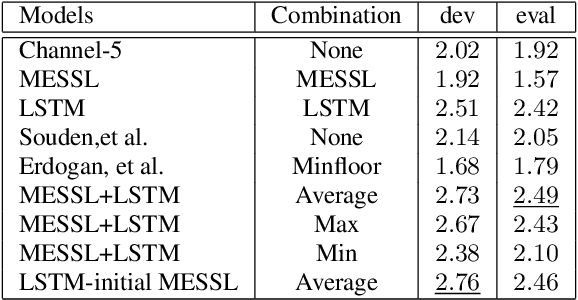
Recurrent neural networks using the LSTM architecture can achieve significant single-channel noise reduction. It is not obvious, however, how to apply them to multi-channel inputs in a way that can generalize to new microphone configurations. In contrast, spatial clustering techniques can achieve such generalization, but lack a strong signal model. This paper combines the two approaches to attain both the spatial separation performance and generality of multichannel spatial clustering and the signal modeling performance of multiple parallel single-channel LSTM speech enhancers. The system is compared to several baselines on the CHiME3 dataset in terms of speech quality predicted by the PESQ algorithm and word error rate of a recognizer trained on mis-matched conditions, in order to focus on generalization. Our experiments show that by combining the LSTM models with the spatial clustering, we reduce word error rate by 4.6\% absolute (17.2\% relative) on the development set and 11.2\% absolute (25.5\% relative) on test set compared with spatial clustering system, and reduce by 10.75\% (32.72\% relative) on development set and 6.12\% absolute (15.76\% relative) on test data compared with LSTM model.
A review of on-device fully neural end-to-end automatic speech recognition algorithms
Dec 19, 2020
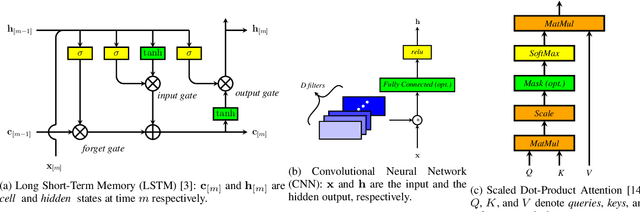
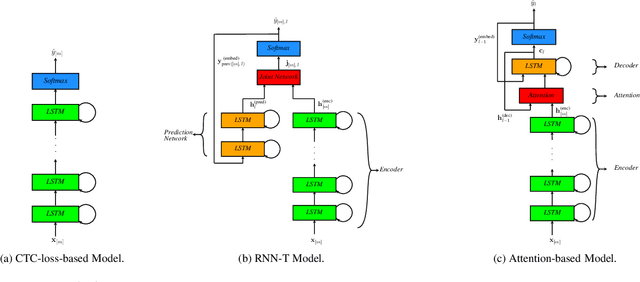
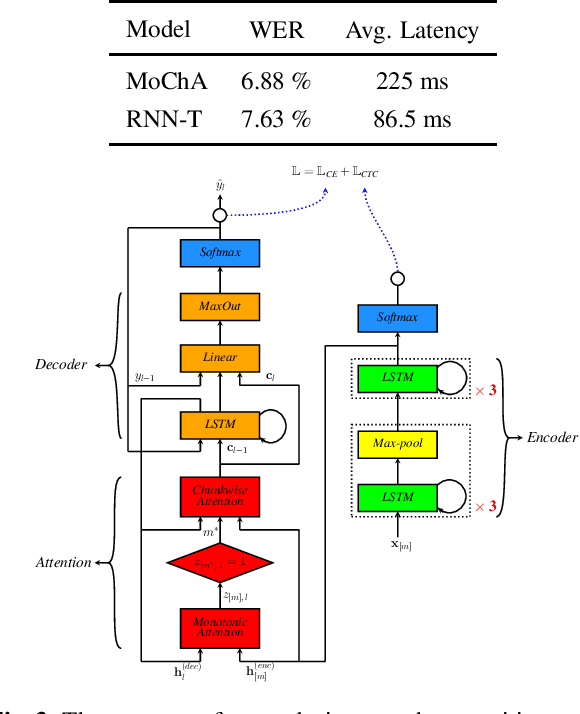
In this paper, we review various end-to-end automatic speech recognition algorithms and their optimization techniques for on-device applications. Conventional speech recognition systems comprise a large number of discrete components such as an acoustic model, a language model, a pronunciation model, a text-normalizer, an inverse-text normalizer, a decoder based on a Weighted Finite State Transducer (WFST), and so on. To obtain sufficiently high speech recognition accuracy with such conventional speech recognition systems, a very large language model (up to 100 GB) is usually needed. Hence, the corresponding WFST size becomes enormous, which prohibits their on-device implementation. Recently, fully neural network end-to-end speech recognition algorithms have been proposed. Examples include speech recognition systems based on Connectionist Temporal Classification (CTC), Recurrent Neural Network Transducer (RNN-T), Attention-based Encoder-Decoder models (AED), Monotonic Chunk-wise Attention (MoChA), transformer-based speech recognition systems, and so on. These fully neural network-based systems require much smaller memory footprints compared to conventional algorithms, therefore their on-device implementation has become feasible. In this paper, we review such end-to-end speech recognition models. We extensively discuss their structures, performance, and advantages compared to conventional algorithms.
IMS-Speech: A Speech to Text Tool
Aug 13, 2019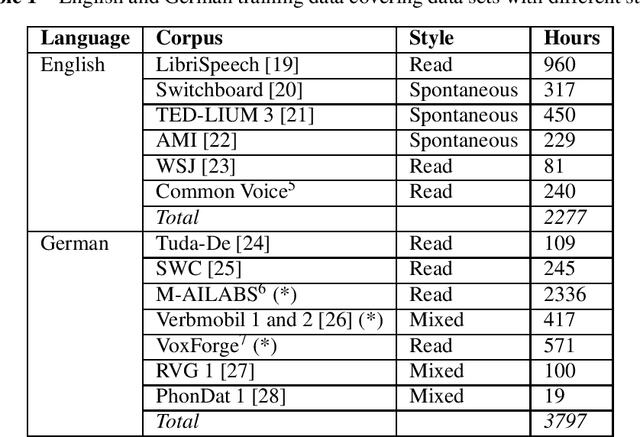

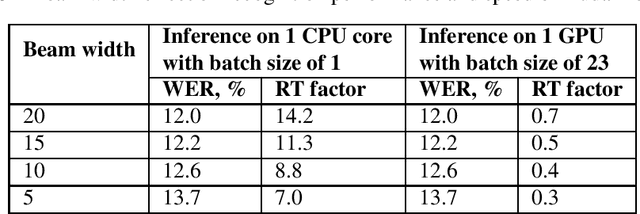

We present the IMS-Speech, a web based tool for German and English speech transcription aiming to facilitate research in various disciplines which require accesses to lexical information in spoken language materials. This tool is based on modern open source software stack, advanced speech recognition methods and public data resources and is freely available for academic researchers. The utilized models are built to be generic in order to provide transcriptions of competitive accuracy on a diverse set of tasks and conditions.
VOTE400(Voide Of The Elderly 400 Hours): A Speech Dataset to Study Voice Interface for Elderly-Care
Jan 20, 2021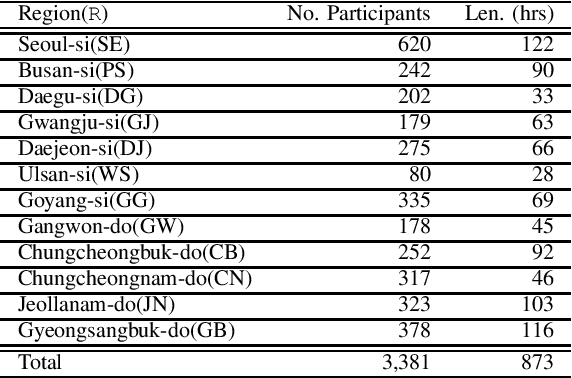
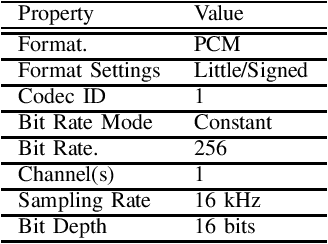
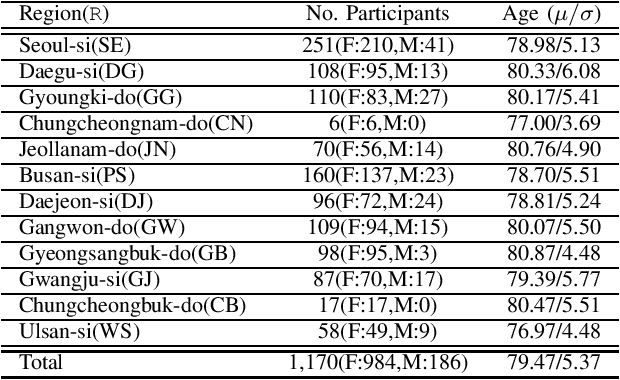
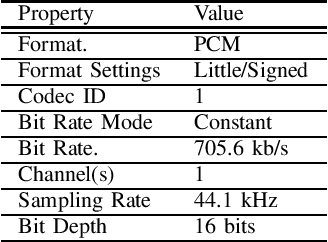
This paper introduces a large-scale Korean speech dataset, called VOTE400, that can be used for analyzing and recognizing voices of the elderly people. The dataset includes about 300 hours of continuous dialog speech and 100 hours of read speech, both recorded by the elderly people aged 65 years or over. A preliminary experiment showed that speech recognition system trained with VOTE400 can outperform conventional systems in speech recognition of elderly people's voice. This work is a multi-organizational effort led by ETRI and MINDs Lab Inc. for the purpose of advancing the speech recognition performance of the elderly-care robots.
Burst2Vec: An Adversarial Multi-Task Approach for Predicting Emotion, Age, and Origin from Vocal Bursts
Jun 24, 2022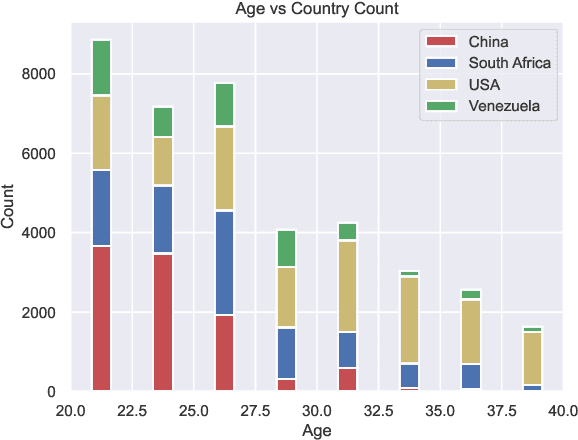
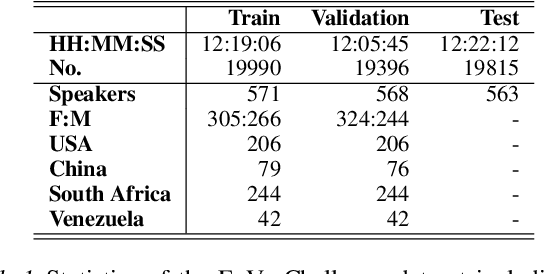
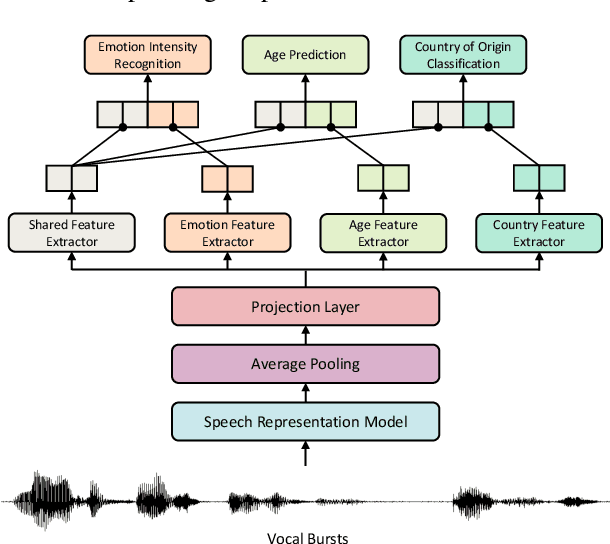
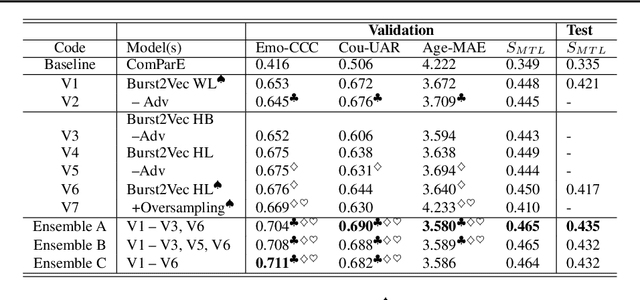
We present Burst2Vec, our multi-task learning approach to predict emotion, age, and origin (i.e., native country/language) from vocal bursts. Burst2Vec utilises pre-trained speech representations to capture acoustic information from raw waveforms and incorporates the concept of model debiasing via adversarial training. Our models achieve a relative 30 % performance gain over baselines using pre-extracted features and score the highest amongst all participants in the ICML ExVo 2022 Multi-Task Challenge.