 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Adversarial Example Devastation and Detection on Speech Recognition System by Adding Random Noise
Aug 31, 2021
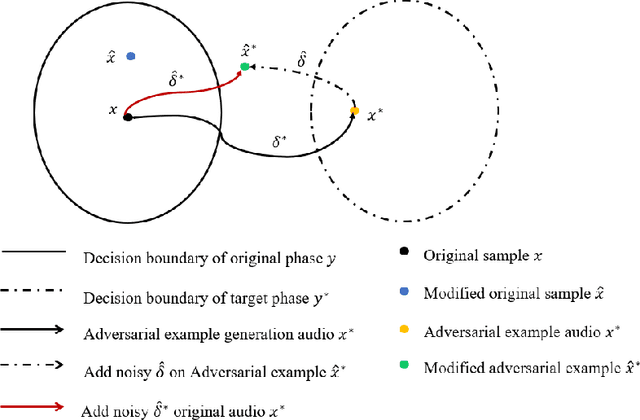

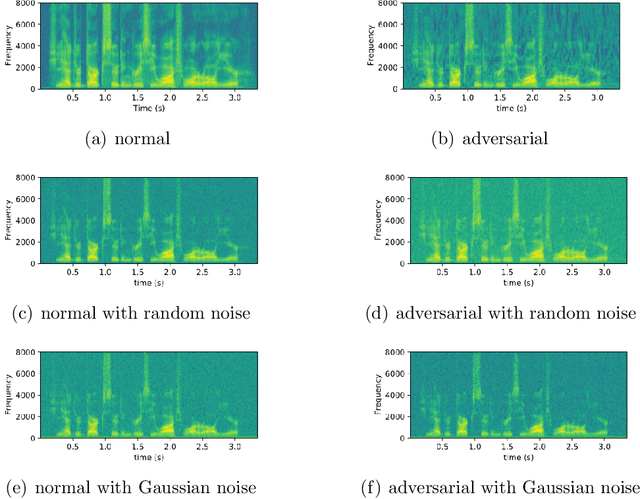
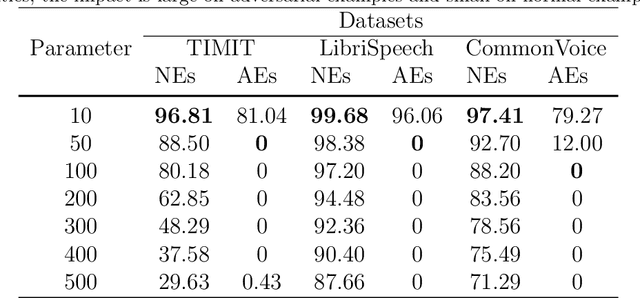
The automatic speech recognition (ASR) system based on deep neural network is easy to be attacked by an adversarial example due to the vulnerability of neural network, which is a hot topic in recent years. The adversarial example does harm to the ASR system, especially if the common-dependent ASR goes wrong, it will lead to serious consequences. To improve the robustness and security of the ASR system, the defense method against adversarial examples must be proposed. Based on this idea, we propose an algorithm of devastation and detection on adversarial examples which can attack the current advanced ASR system. We choose advanced text-dependent and command-dependent ASR system as our target system. Generating adversarial examples by the OPT on text-dependent ASR and the GA-based algorithm on command-dependent ASR. The main idea of our method is input transformation of the adversarial examples. Different random intensities and kinds of noise are added to the adversarial examples to devastate the perturbation previously added to the normal examples. From the experimental results, the method performs well. For the devastation of examples, the original speech similarity before and after adding noise can reach 99.68%, the similarity of the adversarial examples can reach 0%, and the detection rate of the adversarial examples can reach 94%.
Speaking-Rate-Controllable HiFi-GAN Using Feature Interpolation
Apr 22, 2022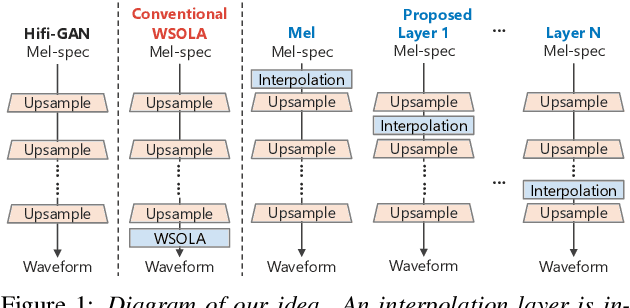

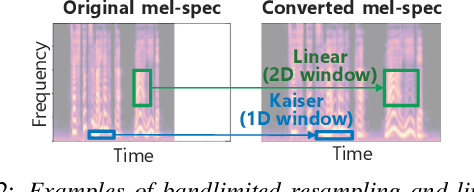
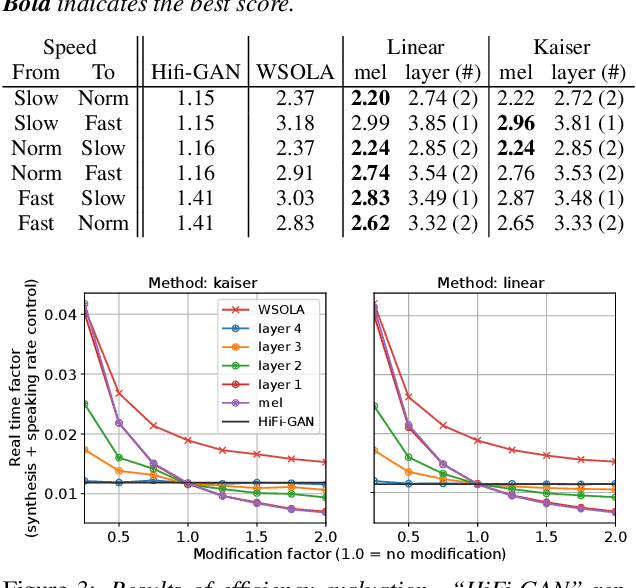
This paper presents a speaking-rate-controllable HiFi-GAN neural vocoder. Original HiFi-GAN is a high-fidelity, computationally efficient, and tiny-footprint neural vocoder. We attempt to incorporate a speaking rate control function into HiFi-GAN for improving the accessibility of synthetic speech. The proposed method inserts a differentiable interpolation layer into the HiFi-GAN architecture. A signal resampling method and an image scaling method are implemented in the proposed method to warp the mel-spectrograms or hidden features of the neural vocoder. We also design and open-source a Japanese speech corpus containing three kinds of speaking rates to evaluate the proposed speaking rate control method. Experimental results of comprehensive objective and subjective evaluations demonstrate that 1) the proposed method outperforms a baseline time-scale modification algorithm in speech naturalness, 2) warping mel-spectrograms by image scaling obtained the best performance among all proposed methods, and 3) the proposed speaking rate control method can be incorporated into HiFi-GAN without losing computational efficiency.
Consistent Training and Decoding For End-to-end Speech Recognition Using Lattice-free MMI
Dec 05, 2021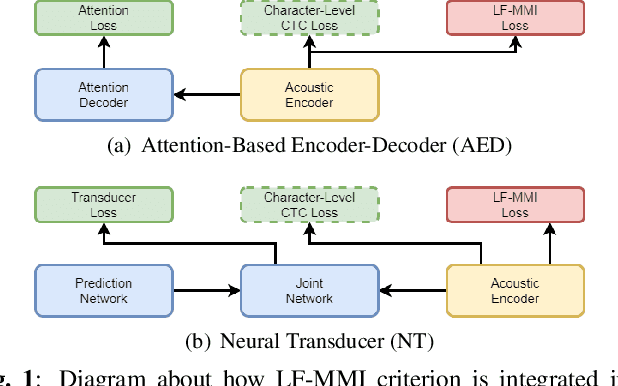
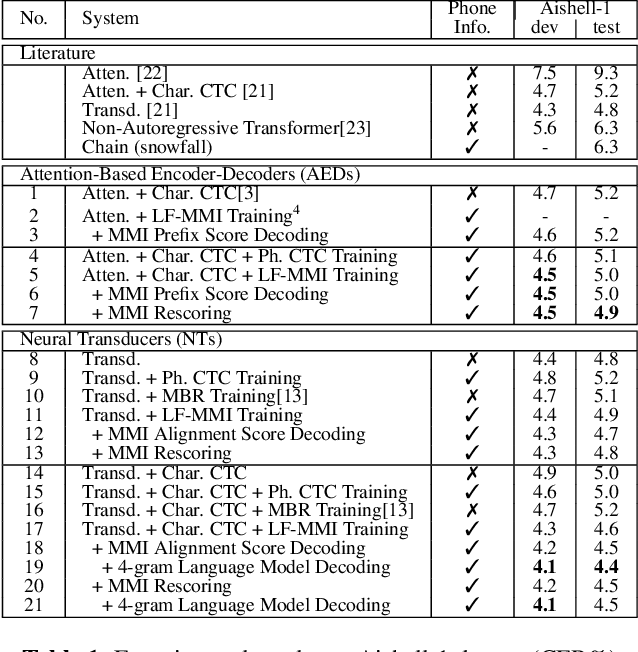
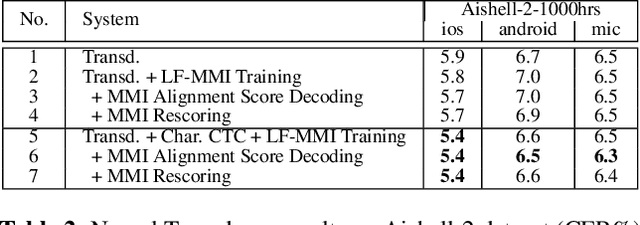
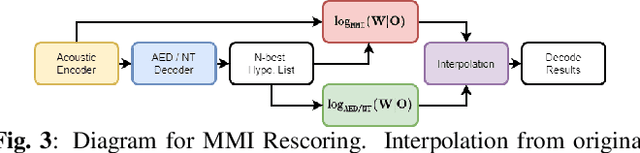
Recently, End-to-End (E2E) frameworks have achieved remarkable results on various Automatic Speech Recognition (ASR) tasks. However, Lattice-Free Maximum Mutual Information (LF-MMI), as one of the discriminative training criteria that show superior performance in hybrid ASR systems, is rarely adopted in E2E ASR frameworks. In this work, we propose a novel approach to integrate LF-MMI criterion into E2E ASR frameworks in both training and decoding stages. The proposed approach shows its effectiveness on two of the most widely used E2E frameworks including Attention-Based Encoder-Decoders (AEDs) and Neural Transducers (NTs). Experiments suggest that the introduction of the LF-MMI criterion consistently leads to significant performance improvements on various datasets and different E2E ASR frameworks. The best of our models achieves competitive CER of 4.1\% / 4.4\% on Aishell-1 dev/test set; we also achieve significant error reduction on Aishell-2 and Librispeech datasets over strong baselines.
Handling and Presenting Harmful Text
Apr 29, 2022
Textual data can pose a risk of serious harm. These harms can be categorised along three axes: (1) the harm type (e.g. misinformation, hate speech or racial stereotypes) (2) whether it is \textit{elicited} as a feature of the research design from directly studying harmful content (e.g. training a hate speech classifier or auditing unfiltered large-scale datasets) versus \textit{spuriously} invoked from working on unrelated problems (e.g. language generation or part of speech tagging) but with datasets that nonetheless contain harmful content, and (3) who it affects, from the humans (mis)represented in the data to those handling or labelling the data to readers and reviewers of publications produced from the data. It is an unsolved problem in NLP as to how textual harms should be handled, presented, and discussed; but, stopping work on content which poses a risk of harm is untenable. Accordingly, we provide practical advice and introduce \textsc{HarmCheck}, a resource for reflecting on research into textual harms. We hope our work encourages ethical, responsible, and respectful research in the NLP community.
ZR-2021VG: Zero-Resource Speech Challenge, Visually-Grounded Language Modelling track, 2021 edition
Jul 14, 2021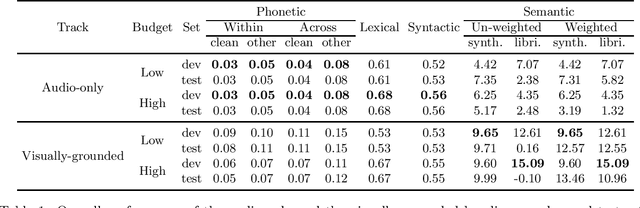
We present the visually-grounded language modelling track that was introduced in the Zero-Resource Speech challenge, 2021 edition, 2nd round. We motivate the new track and discuss participation rules in detail. We also present the two baseline systems that were developed for this track.
Stacked Acoustic-and-Textual Encoding: Integrating the Pre-trained Models into Speech Translation Encoders
May 12, 2021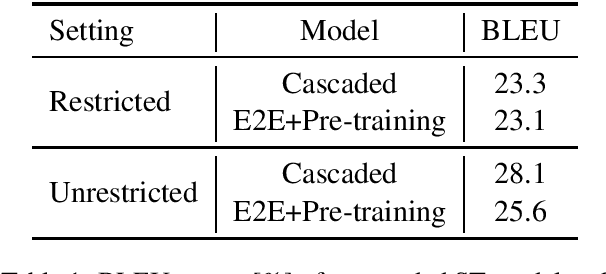
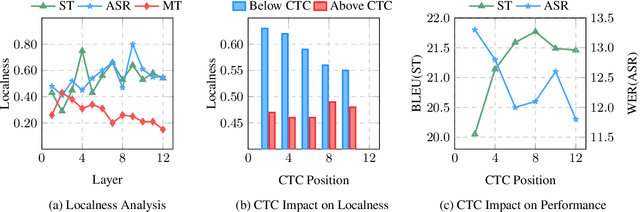
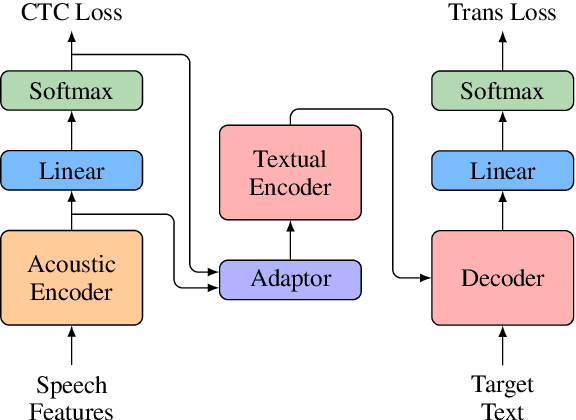
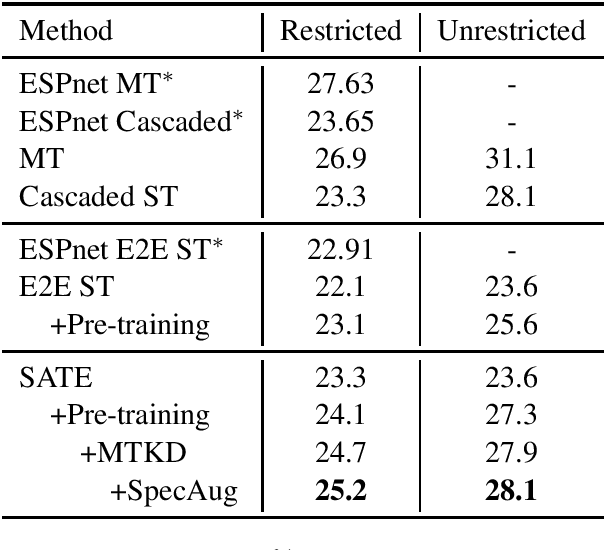
Encoder pre-training is promising in end-to-end Speech Translation (ST), given the fact that speech-to-translation data is scarce. But ST encoders are not simple instances of Automatic Speech Recognition (ASR) or Machine Translation (MT) encoders. For example, we find ASR encoders lack the global context representation, which is necessary for translation, whereas MT encoders are not designed to deal with long but locally attentive acoustic sequences. In this work, we propose a Stacked Acoustic-and-Textual Encoding (SATE) method for speech translation. Our encoder begins with processing the acoustic sequence as usual, but later behaves more like an MT encoder for a global representation of the input sequence. In this way, it is straightforward to incorporate the pre-trained models into the system. Also, we develop an adaptor module to alleviate the representation inconsistency between the pre-trained ASR encoder and MT encoder, and a multi-teacher knowledge distillation method to preserve the pre-training knowledge. Experimental results on the LibriSpeech En-Fr and MuST-C En-De show that our method achieves the state-of-the-art performance of 18.3 and 25.2 BLEU points. To our knowledge, we are the first to develop an end-to-end ST system that achieves comparable or even better BLEU performance than the cascaded ST counterpart when large-scale ASR and MT data is available.
Bi-LSTM Scoring Based Similarity Measurement with Agglomerative Hierarchical Clustering (AHC) for Speaker Diarization
May 19, 2022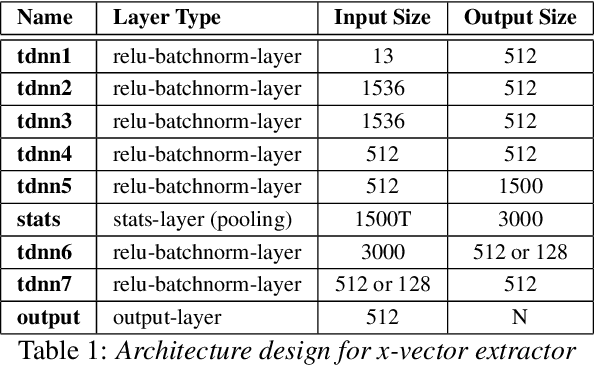
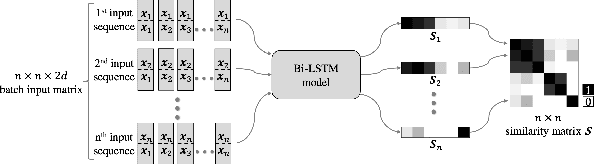
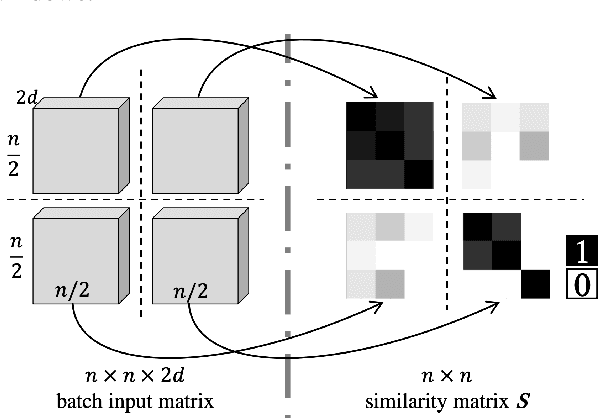
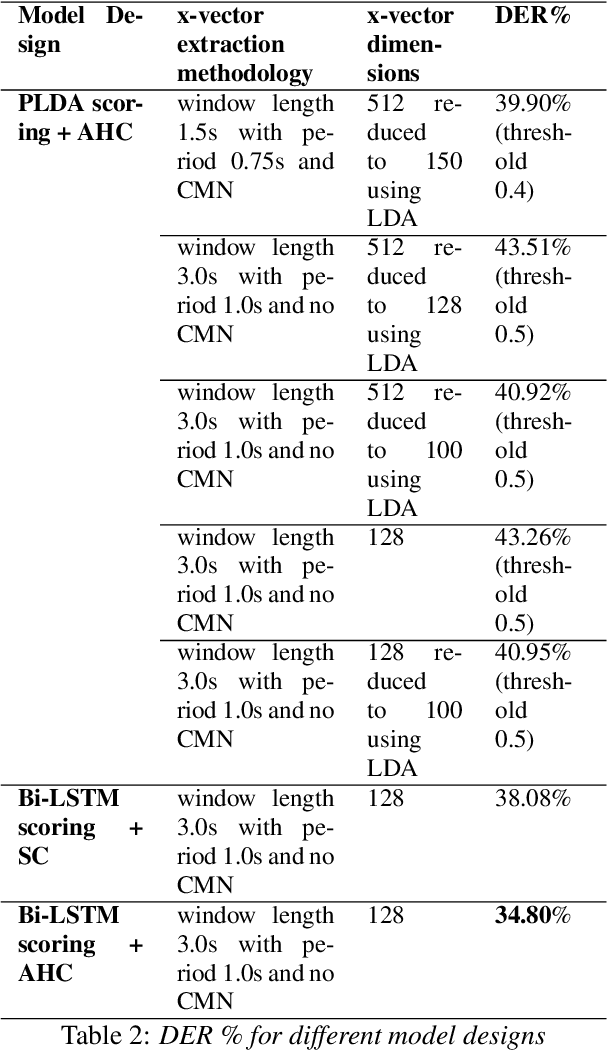
Majority of speech signals across different scenarios are never available with well-defined audio segments containing only a single speaker. A typical conversation between two speakers consists of segments where their voices overlap, interrupt each other or halt their speech in between multiple sentences. Recent advancements in diarization technology leverage neural network-based approaches to improvise multiple subsystems of speaker diarization system comprising of extracting segment-wise embedding features and detecting changes in the speaker during conversation. However, to identify speaker through clustering, models depend on methodologies like PLDA to generate similarity measure between two extracted segments from a given conversational audio. Since these algorithms ignore the temporal structure of conversations, they tend to achieve a higher Diarization Error Rate (DER), thus leading to misdetections both in terms of speaker and change identification. Therefore, to compare similarity of two speech segments both independently and sequentially, we propose a Bi-directional Long Short-term Memory network for estimating the elements present in the similarity matrix. Once the similarity matrix is generated, Agglomerative Hierarchical Clustering (AHC) is applied to further identify speaker segments based on thresholding. To evaluate the performance, Diarization Error Rate (DER%) metric is used. The proposed model achieves a low DER of 34.80% on a test set of audio samples derived from ICSI Meeting Corpus as compared to traditional PLDA based similarity measurement mechanism which achieved a DER of 39.90%.
Machine Learning based COVID-19 Detection from Smartphone Recordings: Cough, Breath and Speech
Apr 12, 2021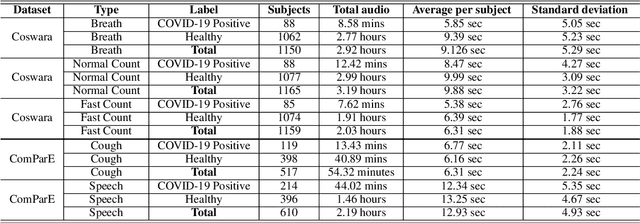
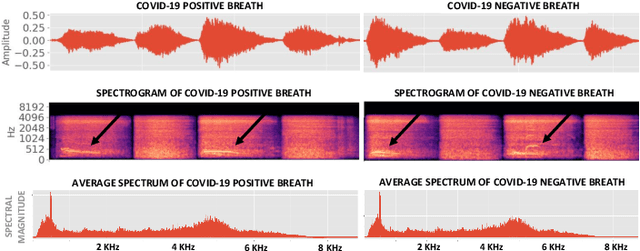
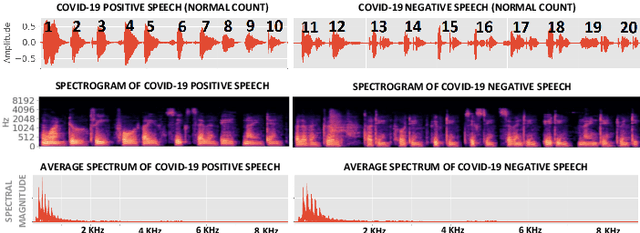
We present an experimental investigation into the automatic detection of COVID-19 from smartphone recordings of coughs, breaths and speech. This type of screening is attractive because it is non-contact, does not require specialist medical expertise or laboratory facilities and can easily be deployed on inexpensive consumer hardware. We base our experiments on two datasets, Coswara and ComParE, containing recordings of coughing, breathing and speech from subjects around the globe. We have considered seven machine learning classifiers and all of them are trained and evaluated using leave-p-out cross-validation. For the Coswara data, the highest AUC of 0.92 was achieved using a Resnet50 architecture on breaths. For the ComParE data, the highest AUC of 0.93 was achieved using a k-nearest neighbours (KNN) classifier on cough recordings after selecting the best 12 features using sequential forward selection (SFS) and the highest AUC of 0.91 was also achieved on speech by a multilayer perceptron (MLP) when using SFS to select the best 23 features. We conclude that among all vocal audio, coughs carry the strongest COVID-19 signature followed by breath and speech. Although these signatures are not perceivable by human ear, machine learning based COVID-19 detection is possible from vocal audio recorded via smartphone.
MFFCN: Multi-layer Feature Fusion Convolution Network for Audio-visual Speech Enhancement
Feb 04, 2021
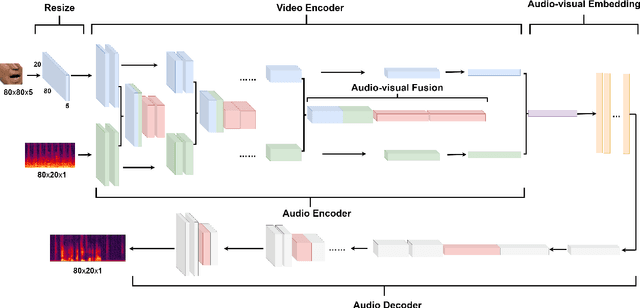
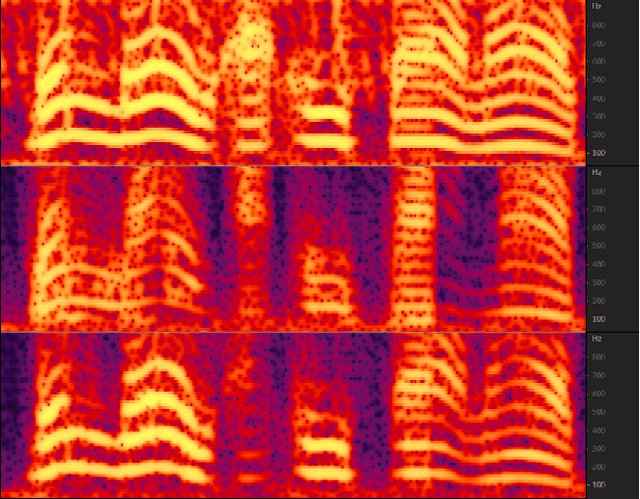
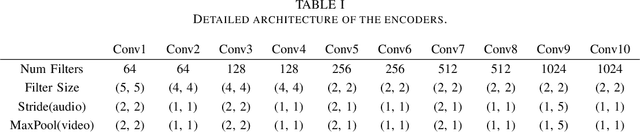
The purpose of speech enhancement is to extract target speech signal from a mixture of sounds generated from several sources. Speech enhancement can potentially benefit from the visual information from the target speaker, such as lip move-ment and facial expressions, because the visual aspect of speech isessentially unaffected by acoustic environment. In order to fuse audio and visual information, an audio-visual fusion strategy is proposed, which goes beyond simple feature concatenation and learns to automatically align the two modalities, leading to more powerful representation which increase intelligibility in noisy conditions. The proposed model fuses audio-visual featureslayer by layer, and feed these audio-visual features to each corresponding decoding layer. Experiment results show relative improvement from 6% to 24% on test sets over the audio modalityalone, depending on audio noise level. Moreover, there is a significant increase of PESQ from 1.21 to 2.06 in our -15 dB SNR experiment.
When can I Speak? Predicting initiation points for spoken dialogue agents
Aug 07, 2022



Current spoken dialogue systems initiate their turns after a long period of silence (700-1000ms), which leads to little real-time feedback, sluggish responses, and an overall stilted conversational flow. Humans typically respond within 200ms and successfully predicting initiation points in advance would allow spoken dialogue agents to do the same. In this work, we predict the lead-time to initiation using prosodic features from a pre-trained speech representation model (wav2vec 1.0) operating on user audio and word features from a pre-trained language model (GPT-2) operating on incremental transcriptions. To evaluate errors, we propose two metrics w.r.t. predicted and true lead times. We train and evaluate the models on the Switchboard Corpus and find that our method outperforms features from prior work on both metrics and vastly outperforms the common approach of waiting for 700ms of silence.