 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speaker Verification in Multi-Speaker Environments Using Temporal Feature Fusion
Jun 28, 2022
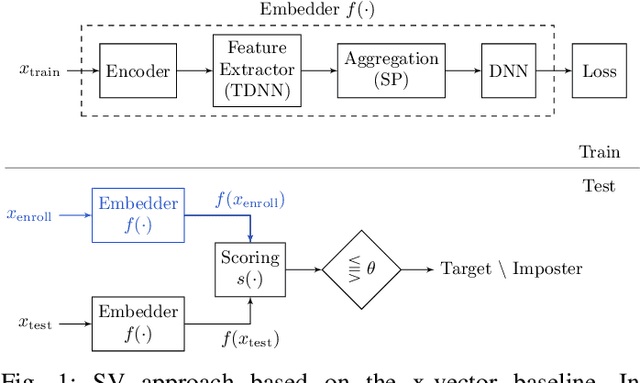
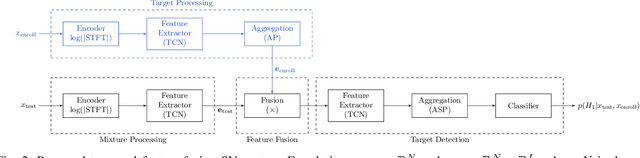
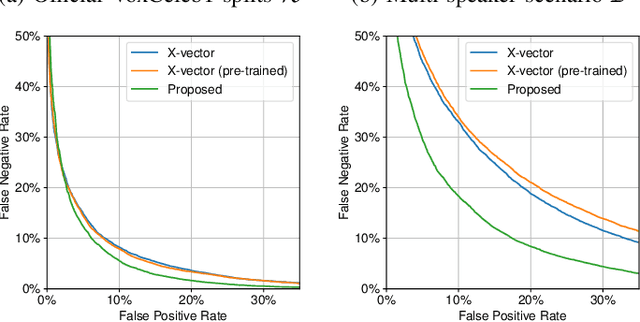
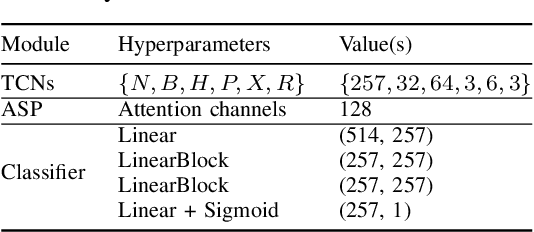
Verifying the identity of a speaker is crucial in modern human-machine interfaces, e.g., to ensure privacy protection or to enable biometric authentication. Classical speaker verification (SV) approaches estimate a fixed-dimensional embedding from a speech utterance that encodes the speaker's voice characteristics. A speaker is verified if his/her voice embedding is sufficiently similar to the embedding of the claimed speaker. However, such approaches assume that only a single speaker exists in the input. The presence of concurrent speakers is likely to have detrimental effects on the performance. To address SV in a multi-speaker environment, we propose an end-to-end deep learning-based SV system that detects whether the target speaker exists within an input or not. First, an embedding is estimated from a reference utterance to represent the target's characteristics. Second, frame-level features are estimated from the input mixture. The reference embedding is then fused frame-wise with the mixture's features to allow distinguishing the target from other speakers on a frame basis. Finally, the fused features are used to predict whether the target speaker is active in the speech segment or not. Experimental evaluation shows that the proposed method outperforms the x-vector in multi-speaker conditions.
Diverse and Controllable Speech Synthesis with GMM-Based Phone-Level Prosody Modelling
May 27, 2021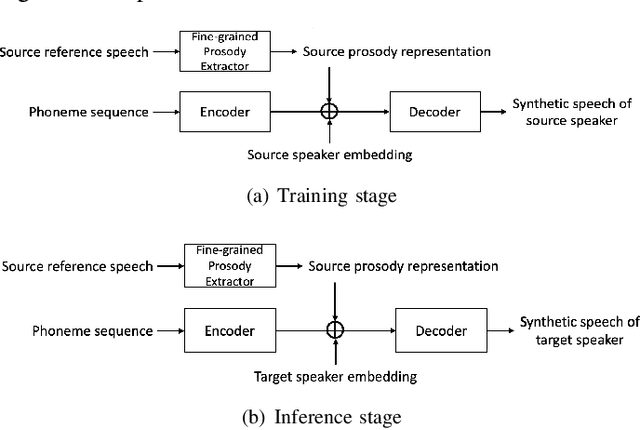
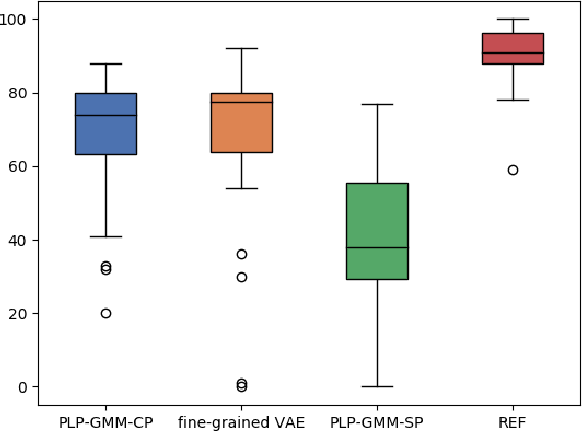
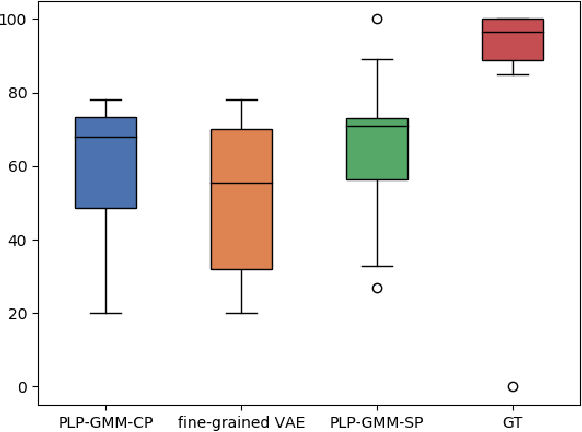
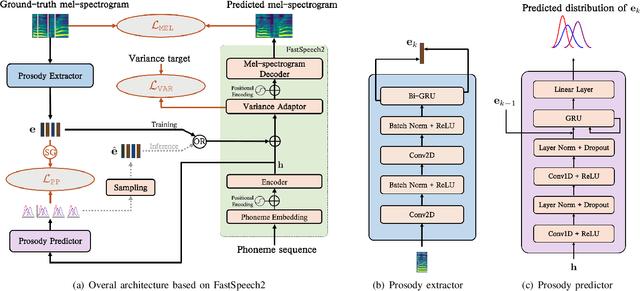
Generating natural speech with diverse and smooth prosody pattern is a challenging task. Although random sampling with phone-level prosody distribution has been investigated to generate different prosody patterns, the diversity of the generated speech is still very limited and far from what can be achieved by human. This is largely due to the use of uni-modal distribution, such as single Gaussian, in the prior works of phone-level prosody modelling. In this work, we propose a novel approach that models phone-level prosodies with a GMM-based mixture density network and then extend it for multi-speaker TTS using speaker adaptation transforms of Gaussian means and variances. Furthermore, we show that we can clone the prosodies from a reference speech by sampling prosodies from the Gaussian components that produce the reference prosodies. Our experiments on LJSpeech and LibriTTS dataset show that the proposed GMM-based method not only achieves significantly better diversity than using a single Gaussian in both single-speaker and multi-speaker TTS, but also provides better naturalness. The prosody cloning experiments demonstrate that the prosody similarity of the proposed GMM-based method is comparable to recent proposed fine-grained VAE while the target speaker similarity is better.
General-Purpose Speech Representation Learning through a Self-Supervised Multi-Granularity Framework
Feb 03, 2021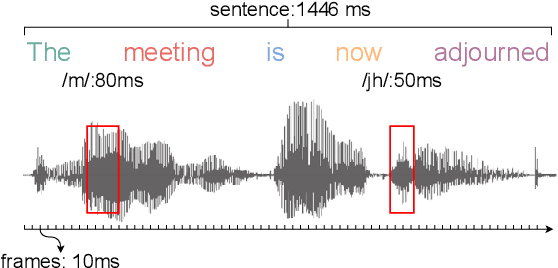
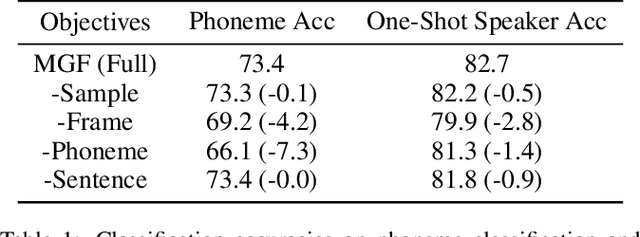
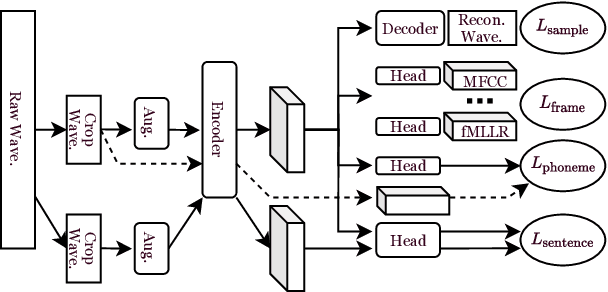
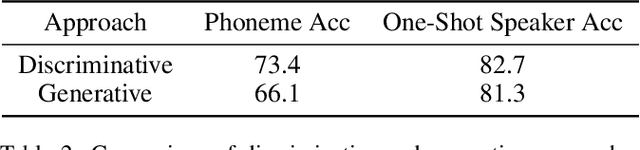
This paper presents a self-supervised learning framework, named MGF, for general-purpose speech representation learning. In the design of MGF, speech hierarchy is taken into consideration. Specifically, we propose to use generative learning approaches to capture fine-grained information at small time scales and use discriminative learning approaches to distill coarse-grained or semantic information at large time scales. For phoneme-scale learning, we borrow idea from the masked language model but tailor it for the continuous speech signal by replacing classification loss with a contrastive loss. We corroborate our design by evaluating MGF representation on various downstream tasks, including phoneme classification, speaker classification, speech recognition, and emotion classification. Experiments verify that training at different time scales needs different training targets and loss functions, which in general complement each other and lead to a better performance.
Learning from human perception to improve automatic speaker verification in style-mismatched conditions
Jun 28, 2022
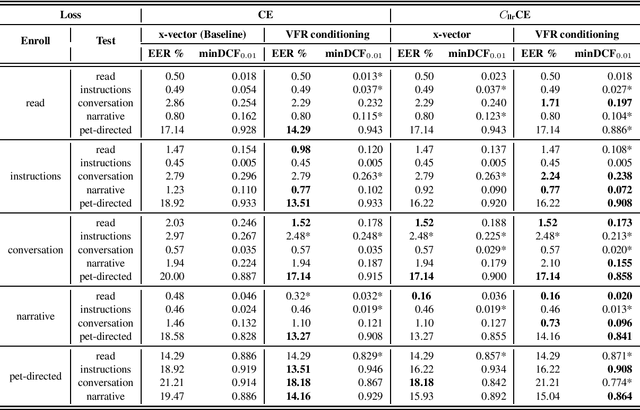
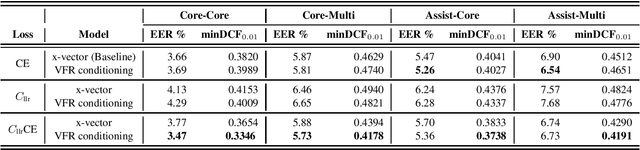
Our prior experiments show that humans and machines seem to employ different approaches to speaker discrimination, especially in the presence of speaking style variability. The experiments examined read versus conversational speech. Listeners focused on speaker-specific idiosyncrasies while "telling speakers together", and on relative distances in a shared acoustic space when "telling speakers apart". However, automatic speaker verification (ASV) systems use the same loss function irrespective of target or non-target trials. To improve ASV performance in the presence of style variability, insights learnt from human perception are used to design a new training loss function that we refer to as "CllrCE loss". CllrCE loss uses both speaker-specific idiosyncrasies and relative acoustic distances between speakers to train the ASV system. When using the UCLA speaker variability database, in the x-vector and conditioning setups, CllrCE loss results in significant relative improvements in EER by 1-66%, and minDCF by 1-31% and 1-56%, respectively, when compared to the x-vector baseline. Using the SITW evaluation tasks, which involve different conversational speech tasks, the proposed loss combined with self-attention conditioning results in significant relative improvements in EER by 2-5% and minDCF by 6-12% over baseline. In the SITW case, performance improvements were consistent only with conditioning.
Non-native English lexicon creation for bilingual speech synthesis
Jun 21, 2021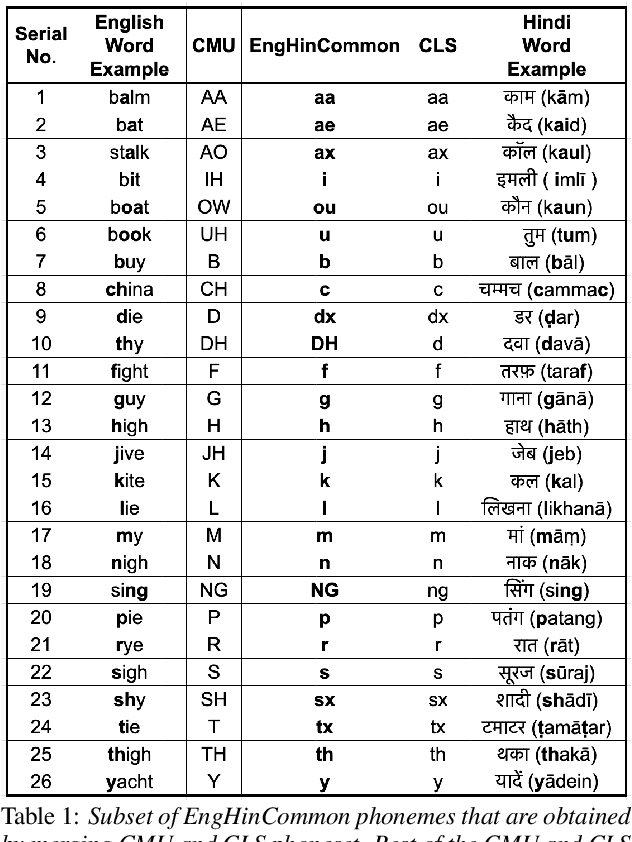
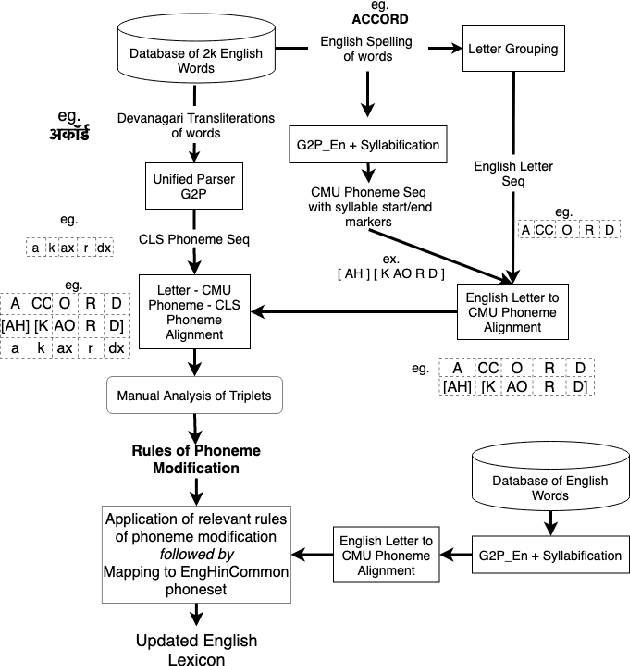
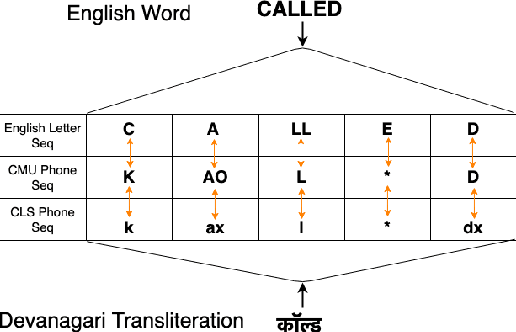
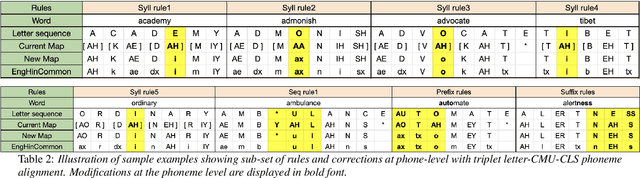
Bilingual English speakers speak English as one of their languages. Their English is of a non-native kind, and their conversations are of a code-mixed fashion. The intelligibility of a bilingual text-to-speech (TTS) system for such non-native English speakers depends on a lexicon that captures the phoneme sequence used by non-native speakers. However, due to the lack of non-native English lexicon, existing bilingual TTS systems employ native English lexicons that are widely available, in addition to their native language lexicon. Due to the inconsistency between the non-native English pronunciation in the audio and native English lexicon in the text, the intelligibility of synthesized speech in such TTS systems is significantly reduced. This paper is motivated by the knowledge that the native language of the speaker highly influences non-native English pronunciation. We propose a generic approach to obtain rules based on letter to phoneme alignment to map native English lexicon to their non-native version. The effectiveness of such mapping is studied by comparing bilingual (Indian English and Hindi) TTS systems trained with and without the proposed rules. The subjective evaluation shows that the bilingual TTS system trained with the proposed non-native English lexicon rules obtains a 6% absolute improvement in preference.
Model Blending for Text Classification
Aug 05, 2022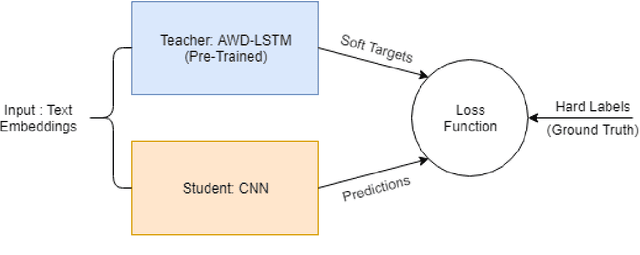
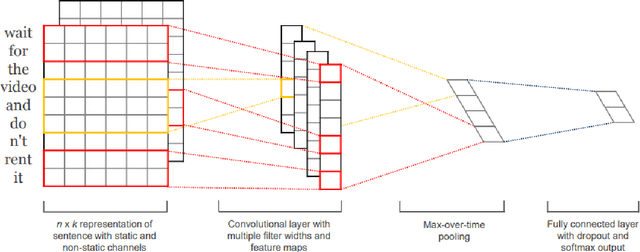
Deep neural networks (DNNs) have proven successful in a wide variety of applications such as speech recognition and synthesis, computer vision, machine translation, and game playing, to name but a few. However, existing deep neural network models are computationally expensive and memory intensive, hindering their deployment in devices with low memory resources or in applications with strict latency requirements. Therefore, a natural thought is to perform model compression and acceleration in deep networks without significantly decreasing the model performance, which is what we call reducing the complexity. In the following work, we try reducing the complexity of state of the art LSTM models for natural language tasks such as text classification, by distilling their knowledge to CNN based models, thus reducing the inference time(or latency) during testing.
Silent Speech and Emotion Recognition from Vocal Tract Shape Dynamics in Real-Time MRI
Jun 16, 2021
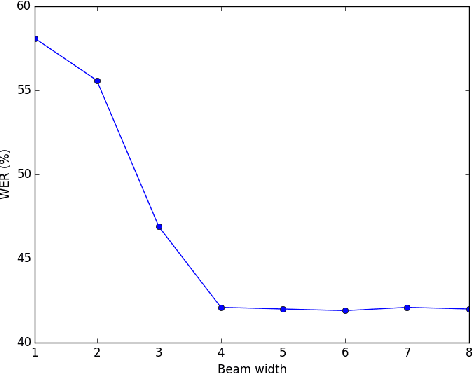
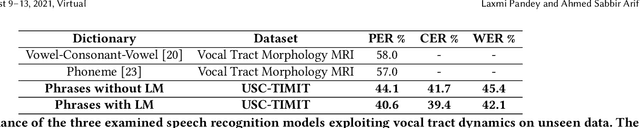
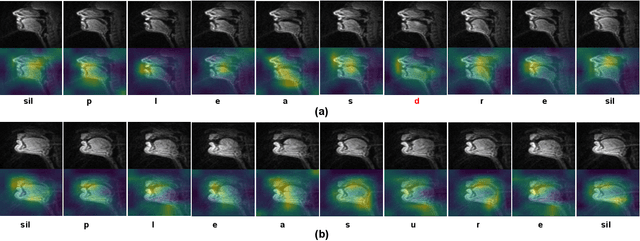
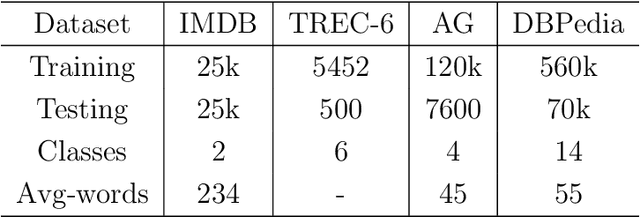
Speech sounds of spoken language are obtained by varying configuration of the articulators surrounding the vocal tract. They contain abundant information that can be utilized to better understand the underlying mechanism of human speech production. We propose a novel deep neural network-based learning framework that understands acoustic information in the variable-length sequence of vocal tract shaping during speech production, captured by real-time magnetic resonance imaging (rtMRI), and translate it into text. The proposed framework comprises of spatiotemporal convolutions, a recurrent network, and the connectionist temporal classification loss, trained entirely end-to-end. On the USC-TIMIT corpus, the model achieved a 40.6% PER at sentence-level, much better compared to the existing models. To the best of our knowledge, this is the first study that demonstrates the recognition of entire spoken sentence based on an individual's articulatory motions captured by rtMRI video. We also performed an analysis of variations in the geometry of articulation in each sub-regions of the vocal tract (i.e., pharyngeal, velar and dorsal, hard palate, labial constriction region) with respect to different emotions and genders. Results suggest that each sub-regions distortion is affected by both emotion and gender.
FV2ES: A Fully End2End Multimodal System for Fast Yet Effective Video Emotion Recognition Inference
Sep 21, 2022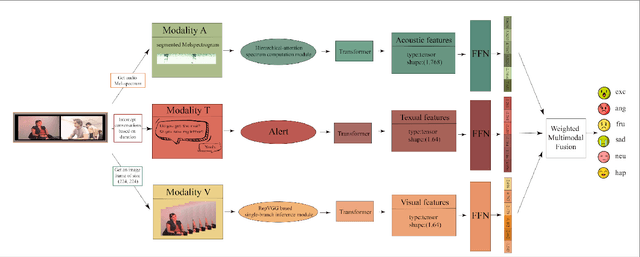
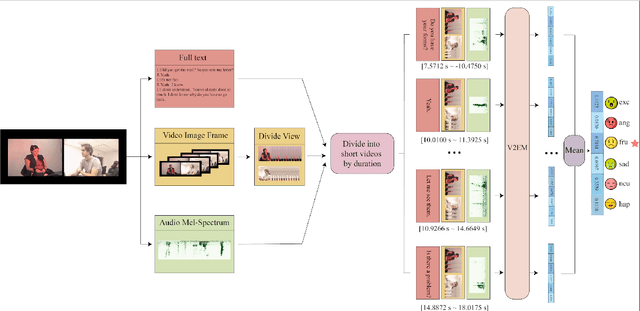
In the latest social networks, more and more people prefer to express their emotions in videos through text, speech, and rich facial expressions. Multimodal video emotion analysis techniques can help understand users' inner world automatically based on human expressions and gestures in images, tones in voices, and recognized natural language. However, in the existing research, the acoustic modality has long been in a marginal position as compared to visual and textual modalities. That is, it tends to be more difficult to improve the contribution of the acoustic modality for the whole multimodal emotion recognition task. Besides, although better performance can be obtained by introducing common deep learning methods, the complex structures of these training models always result in low inference efficiency, especially when exposed to high-resolution and long-length videos. Moreover, the lack of a fully end-to-end multimodal video emotion recognition system hinders its application. In this paper, we designed a fully multimodal video-to-emotion system (named FV2ES) for fast yet effective recognition inference, whose benefits are threefold: (1) The adoption of the hierarchical attention method upon the sound spectra breaks through the limited contribution of the acoustic modality and outperforms the existing models' performance on both IEMOCAP and CMU-MOSEI datasets; (2) the introduction of the idea of multi-scale for visual extraction while single-branch for inference brings higher efficiency and maintains the prediction accuracy at the same time; (3) the further integration of data pre-processing into the aligned multimodal learning model allows the significant reduction of computational costs and storage space.
Gender Bias in Word Embeddings: A Comprehensive Analysis of Frequency, Syntax, and Semantics
Jun 07, 2022
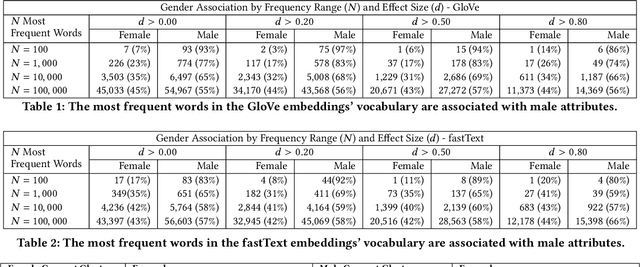
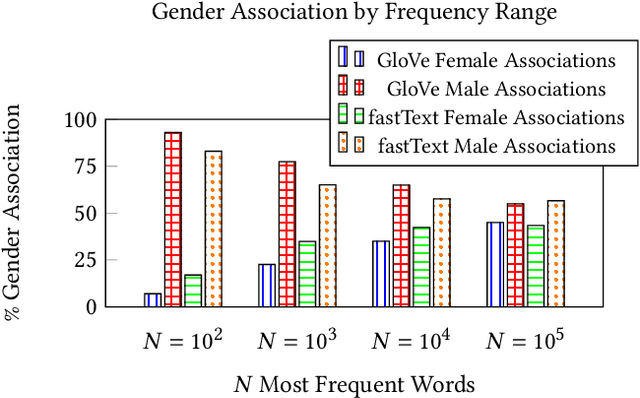
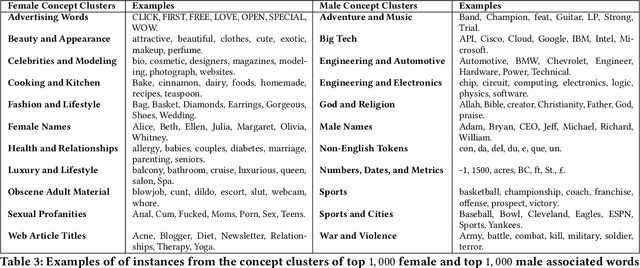
The statistical regularities in language corpora encode well-known social biases into word embeddings. Here, we focus on gender to provide a comprehensive analysis of group-based biases in widely-used static English word embeddings trained on internet corpora (GloVe 2014, fastText 2017). Using the Single-Category Word Embedding Association Test, we demonstrate the widespread prevalence of gender biases that also show differences in: (1) frequencies of words associated with men versus women; (b) part-of-speech tags in gender-associated words; (c) semantic categories in gender-associated words; and (d) valence, arousal, and dominance in gender-associated words. First, in terms of word frequency: we find that, of the 1,000 most frequent words in the vocabulary, 77% are more associated with men than women, providing direct evidence of a masculine default in the everyday language of the English-speaking world. Second, turning to parts-of-speech: the top male-associated words are typically verbs (e.g., fight, overpower) while the top female-associated words are typically adjectives and adverbs (e.g., giving, emotionally). Gender biases in embeddings also permeate parts-of-speech. Third, for semantic categories: bottom-up, cluster analyses of the top 1,000 words associated with each gender. The top male-associated concepts include roles and domains of big tech, engineering, religion, sports, and violence; in contrast, the top female-associated concepts are less focused on roles, including, instead, female-specific slurs and sexual content, as well as appearance and kitchen terms. Fourth, using human ratings of word valence, arousal, and dominance from a ~20,000 word lexicon, we find that male-associated words are higher on arousal and dominance, while female-associated words are higher on valence.
Adaptation of Tacotron2-based Text-To-Speech for Articulatory-to-Acoustic Mapping using Ultrasound Tongue Imaging
Jul 26, 2021
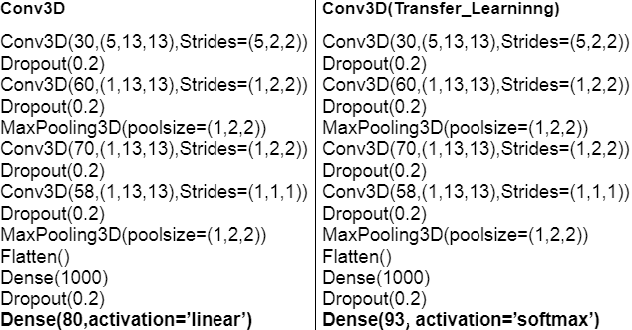
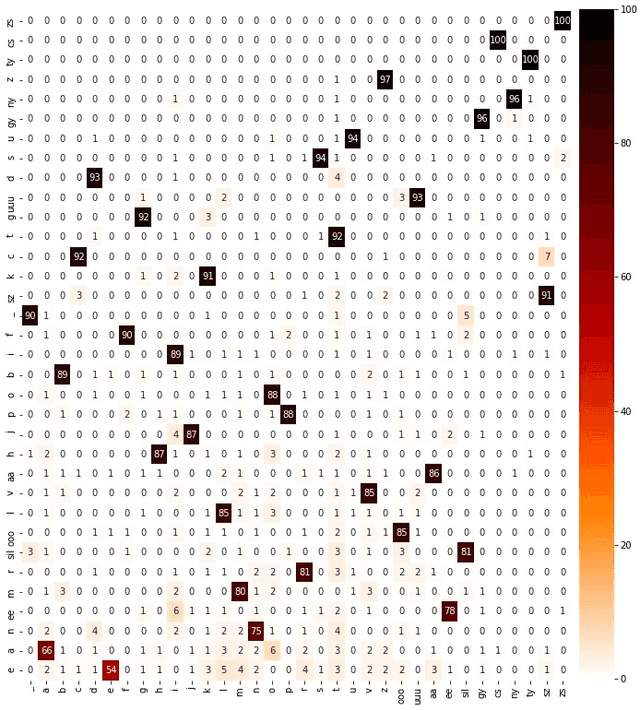
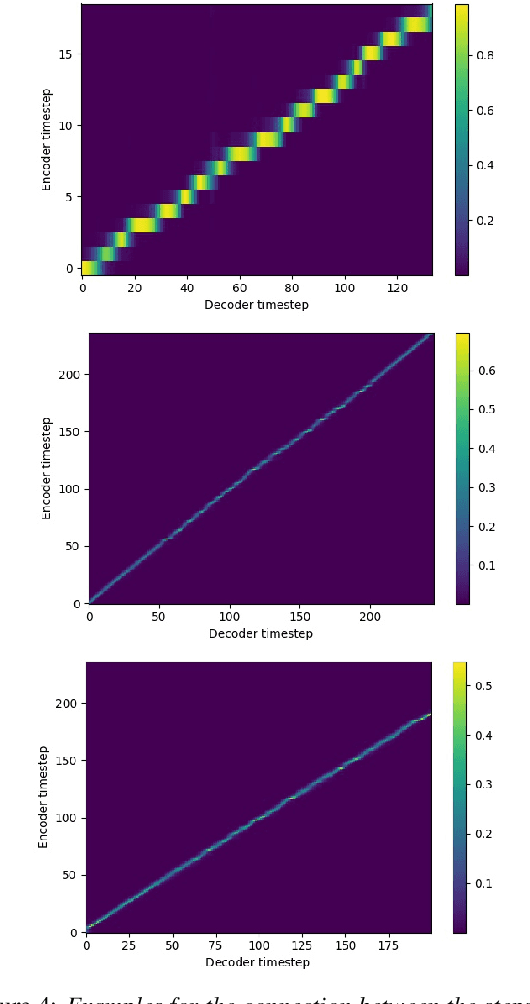
For articulatory-to-acoustic mapping, typically only limited parallel training data is available, making it impossible to apply fully end-to-end solutions like Tacotron2. In this paper, we experimented with transfer learning and adaptation of a Tacotron2 text-to-speech model to improve the final synthesis quality of ultrasound-based articulatory-to-acoustic mapping with a limited database. We use a multi-speaker pre-trained Tacotron2 TTS model and a pre-trained WaveGlow neural vocoder. The articulatory-to-acoustic conversion contains three steps: 1) from a sequence of ultrasound tongue image recordings, a 3D convolutional neural network predicts the inputs of the pre-trained Tacotron2 model, 2) the Tacotron2 model converts this intermediate representation to an 80-dimensional mel-spectrogram, and 3) the WaveGlow model is applied for final inference. This generated speech contains the timing of the original articulatory data from the ultrasound recording, but the F0 contour and the spectral information is predicted by the Tacotron2 model. The F0 values are independent of the original ultrasound images, but represent the target speaker, as they are inferred from the pre-trained Tacotron2 model. In our experiments, we demonstrated that the synthesized speech quality is more natural with the proposed solutions than with our earlier model.