 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Bridging Modalities: Knowledge Distillation and Masked Training for Translating Multi-Modal Emotion Recognition to Uni-Modal, Speech-Only Emotion Recognition
Jan 04, 2024
This paper presents an innovative approach to address the challenges of translating multi-modal emotion recognition models to a more practical and resource-efficient uni-modal counterpart, specifically focusing on speech-only emotion recognition. Recognizing emotions from speech signals is a critical task with applications in human-computer interaction, affective computing, and mental health assessment. However, existing state-of-the-art models often rely on multi-modal inputs, incorporating information from multiple sources such as facial expressions and gestures, which may not be readily available or feasible in real-world scenarios. To tackle this issue, we propose a novel framework that leverages knowledge distillation and masked training techniques.
LiteVSR: Efficient Visual Speech Recognition by Learning from Speech Representations of Unlabeled Data
Dec 15, 2023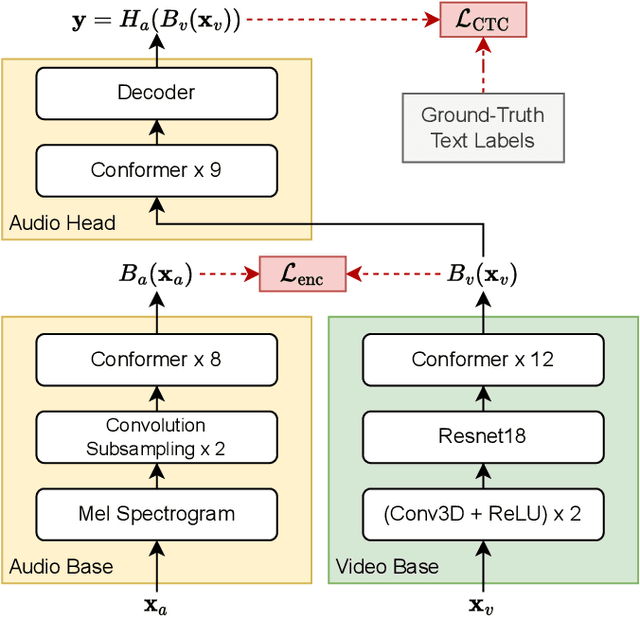
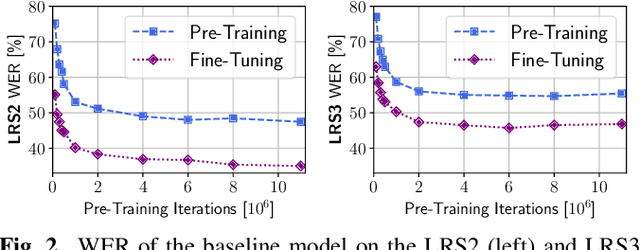
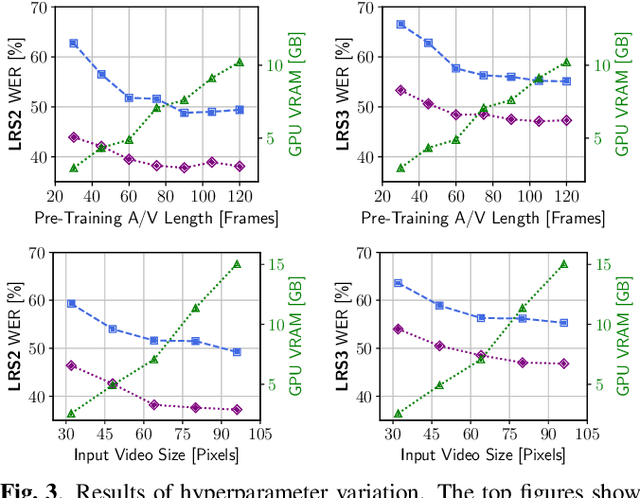
This paper proposes a novel, resource-efficient approach to Visual Speech Recognition (VSR) leveraging speech representations produced by any trained Automatic Speech Recognition (ASR) model. Moving away from the resource-intensive trends prevalent in recent literature, our method distills knowledge from a trained Conformer-based ASR model, achieving competitive performance on standard VSR benchmarks with significantly less resource utilization. Using unlabeled audio-visual data only, our baseline model achieves a word error rate (WER) of 47.4% and 54.7% on the LRS2 and LRS3 test benchmarks, respectively. After fine-tuning the model with limited labeled data, the word error rate reduces to 35% (LRS2) and 45.7% (LRS3). Our model can be trained on a single consumer-grade GPU within a few days and is capable of performing real-time end-to-end VSR on dated hardware, suggesting a path towards more accessible and resource-efficient VSR methodologies.
MM-TTS: Multi-modal Prompt based Style Transfer for Expressive Text-to-Speech Synthesis
Dec 28, 2023The style transfer task in Text-to-Speech refers to the process of transferring style information into text content to generate corresponding speech with a specific style. However, most existing style transfer approaches are either based on fixed emotional labels or reference speech clips, which cannot achieve flexible style transfer. Recently, some methods have adopted text descriptions to guide style transfer. In this paper, we propose a more flexible multi-modal and style controllable TTS framework named MM-TTS. It can utilize any modality as the prompt in unified multi-modal prompt space, including reference speech, emotional facial images, and text descriptions, to control the style of the generated speech in a system. The challenges of modeling such a multi-modal style controllable TTS mainly lie in two aspects:1)aligning the multi-modal information into a unified style space to enable the input of arbitrary modality as the style prompt in a single system, and 2)efficiently transferring the unified style representation into the given text content, thereby empowering the ability to generate prompt style-related voice. To address these problems, we propose an aligned multi-modal prompt encoder that embeds different modalities into a unified style space, supporting style transfer for different modalities. Additionally, we present a new adaptive style transfer method named Style Adaptive Convolutions to achieve a better style representation. Furthermore, we design a Rectified Flow based Refiner to solve the problem of over-smoothing Mel-spectrogram and generate audio of higher fidelity. Since there is no public dataset for multi-modal TTS, we construct a dataset named MEAD-TTS, which is related to the field of expressive talking head. Our experiments on the MEAD-TTS dataset and out-of-domain datasets demonstrate that MM-TTS can achieve satisfactory results based on multi-modal prompts.
Efficiency-oriented approaches for self-supervised speech representation learning
Dec 18, 2023Self-supervised learning enables the training of large neural models without the need for large, labeled datasets. It has been generating breakthroughs in several fields, including computer vision, natural language processing, biology, and speech. In particular, the state-of-the-art in several speech processing applications, such as automatic speech recognition or speaker identification, are models where the latent representation is learned using self-supervised approaches. Several configurations exist in self-supervised learning for speech, including contrastive, predictive, and multilingual approaches. There is, however, a crucial limitation in most existing approaches: their high computational costs. These costs limit the deployment of models, the size of the training dataset, and the number of research groups that can afford research with large self-supervised models. Likewise, we should consider the environmental costs that high energy consumption implies. Efforts in this direction comprise optimization of existing models, neural architecture efficiency, improvements in finetuning for speech processing tasks, and data efficiency. But despite current efforts, more work could be done to address high computational costs in self-supervised representation learning.
UCorrect: An Unsupervised Framework for Automatic Speech Recognition Error Correction
Jan 11, 2024Error correction techniques have been used to refine the output sentences from automatic speech recognition (ASR) models and achieve a lower word error rate (WER). Previous works usually adopt end-to-end models and has strong dependency on Pseudo Paired Data and Original Paired Data. But when only pre-training on Pseudo Paired Data, previous models have negative effect on correction. While fine-tuning on Original Paired Data, the source side data must be transcribed by a well-trained ASR model, which takes a lot of time and not universal. In this paper, we propose UCorrect, an unsupervised Detector-Generator-Selector framework for ASR Error Correction. UCorrect has no dependency on the training data mentioned before. The whole procedure is first to detect whether the character is erroneous, then to generate some candidate characters and finally to select the most confident one to replace the error character. Experiments on the public AISHELL-1 dataset and WenetSpeech dataset show the effectiveness of UCorrect for ASR error correction: 1) it achieves significant WER reduction, achieves 6.83\% even without fine-tuning and 14.29\% after fine-tuning; 2) it outperforms the popular NAR correction models by a large margin with a competitive low latency; and 3) it is an universal method, as it reduces all WERs of the ASR model with different decoding strategies and reduces all WERs of ASR models trained on different scale datasets.
Using Large Language Model for End-to-End Chinese ASR and NER
Jan 21, 2024Mapping speech tokens to the same feature space as text tokens has become the paradigm for the integration of speech modality into decoder-only large language models (LLMs). An alternative approach is to use an encoder-decoder architecture that incorporates speech features through cross-attention. This approach, however, has received less attention in the literature. In this work, we connect the Whisper encoder with ChatGLM3 and provide in-depth comparisons of these two approaches using Chinese automatic speech recognition (ASR) and name entity recognition (NER) tasks. We evaluate them not only by conventional metrics like the F1 score but also by a novel fine-grained taxonomy of ASR-NER errors. Our experiments reveal that encoder-decoder architecture outperforms decoder-only architecture with a short context, while decoder-only architecture benefits from a long context as it fully exploits all layers of the LLM. By using LLM, we significantly reduced the entity omission errors and improved the entity ASR accuracy compared to the Conformer baseline. Additionally, we obtained a state-of-the-art (SOTA) F1 score of 0.805 on the AISHELL-NER test set by using chain-of-thought (CoT) NER which first infers long-form ASR transcriptions and then predicts NER labels.
TuPy-E: detecting hate speech in Brazilian Portuguese social media with a novel dataset and comprehensive analysis of models
Dec 29, 2023Social media has become integral to human interaction, providing a platform for communication and expression. However, the rise of hate speech on these platforms poses significant risks to individuals and communities. Detecting and addressing hate speech is particularly challenging in languages like Portuguese due to its rich vocabulary, complex grammar, and regional variations. To address this, we introduce TuPy-E, the largest annotated Portuguese corpus for hate speech detection. TuPy-E leverages an open-source approach, fostering collaboration within the research community. We conduct a detailed analysis using advanced techniques like BERT models, contributing to both academic understanding and practical applications
SELM: Speech Enhancement Using Discrete Tokens and Language Models
Dec 15, 2023Language models (LMs) have shown superior performances in various speech generation tasks recently, demonstrating their powerful ability for semantic context modeling. Given the intrinsic similarity between speech generation and speech enhancement, harnessing semantic information holds potential advantages for speech enhancement tasks. In light of this, we propose SELM, a novel paradigm for speech enhancement, which integrates discrete tokens and leverages language models. SELM comprises three stages: encoding, modeling, and decoding. We transform continuous waveform signals into discrete tokens using pre-trained self-supervised learning (SSL) models and a k-means tokenizer. Language models then capture comprehensive contextual information within these tokens. Finally, a detokenizer and HiFi-GAN restore them into enhanced speech. Experimental results demonstrate that SELM achieves comparable performance in objective metrics alongside superior results in subjective perception. Our demos are available https://honee-w.github.io/SELM/.
Stateful Conformer with Cache-based Inference for Streaming Automatic Speech Recognition
Jan 11, 2024In this paper, we propose an efficient and accurate streaming speech recognition model based on the FastConformer architecture. We adapted the FastConformer architecture for streaming applications through: (1) constraining both the look-ahead and past contexts in the encoder, and (2) introducing an activation caching mechanism to enable the non-autoregressive encoder to operate autoregressively during inference. The proposed model is thoughtfully designed in a way to eliminate the accuracy disparity between the train and inference time which is common for many streaming models. Furthermore, our proposed encoder works with various decoder configurations including Connectionist Temporal Classification (CTC) and RNN-Transducer (RNNT) decoders. Additionally, we introduced a hybrid CTC/RNNT architecture which utilizes a shared encoder with both a CTC and RNNT decoder to boost the accuracy and save computation. We evaluate the proposed model on LibriSpeech dataset and a multi-domain large scale dataset and demonstrate that it can achieve better accuracy with lower latency and inference time compared to a conventional buffered streaming model baseline. We also showed that training a model with multiple latencies can achieve better accuracy than single latency models while it enables us to support multiple latencies with a single model. Our experiments also showed the hybrid architecture would not only speedup the convergence of the CTC decoder but also improves the accuracy of streaming models compared to single decoder models.
Self-Supervised Disentangled Representation Learning for Robust Target Speech Extraction
Dec 16, 2023Speech signals are inherently complex as they encompass both global acoustic characteristics and local semantic information. However, in the task of target speech extraction, certain elements of global and local semantic information in the reference speech, which are irrelevant to speaker identity, can lead to speaker confusion within the speech extraction network. To overcome this challenge, we propose a self-supervised disentangled representation learning method. Our approach tackles this issue through a two-phase process, utilizing a reference speech encoding network and a global information disentanglement network to gradually disentangle the speaker identity information from other irrelevant factors. We exclusively employ the disentangled speaker identity information to guide the speech extraction network. Moreover, we introduce the adaptive modulation Transformer to ensure that the acoustic representation of the mixed signal remains undisturbed by the speaker embeddings. This component incorporates speaker embeddings as conditional information, facilitating natural and efficient guidance for the speech extraction network. Experimental results substantiate the effectiveness of our meticulously crafted approach, showcasing a substantial reduction in the likelihood of speaker confusion.