 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Deliberation Model for On-Device Spoken Language Understanding
Apr 04, 2022
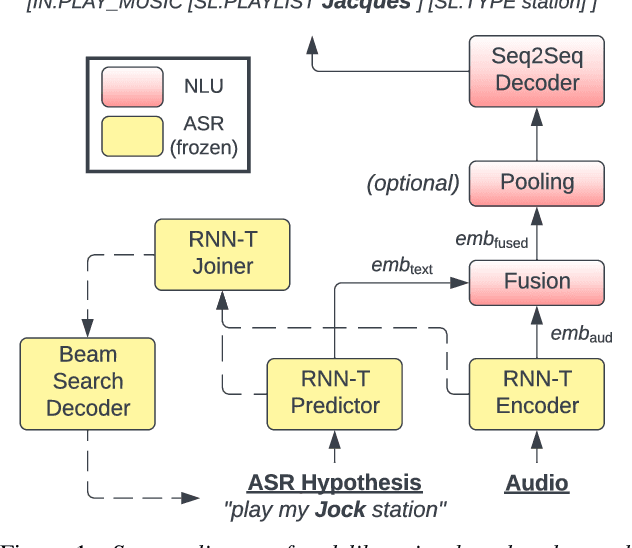

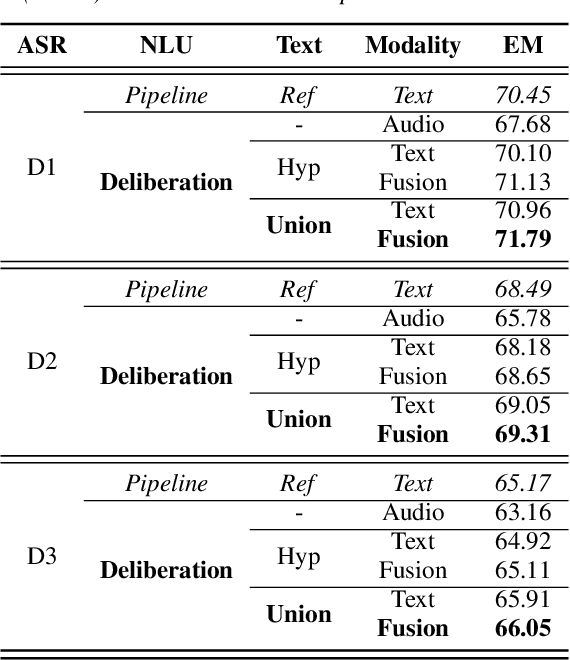
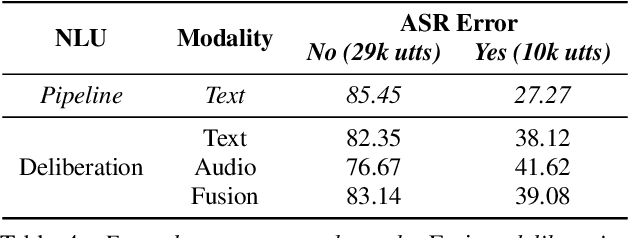
We propose a novel deliberation-based approach to end-to-end (E2E) spoken language understanding (SLU), where a streaming automatic speech recognition (ASR) model produces the first-pass hypothesis and a second-pass natural language understanding (NLU) component generates the semantic parse by conditioning on both ASR's text and audio embeddings. By formulating E2E SLU as a generalized decoder, our system is able to support complex compositional semantic structures. Furthermore, the sharing of parameters between ASR and NLU makes the system especially suitable for resource-constrained (on-device) environments; our proposed approach consistently outperforms strong pipeline NLU baselines by 0.82% to 1.34% across various operating points on the spoken version of the TOPv2 dataset. We demonstrate that the fusion of text and audio features, coupled with the system's ability to rewrite the first-pass hypothesis, makes our approach more robust to ASR errors. Finally, we show that our approach can significantly reduce the degradation when moving from natural speech to synthetic speech training, but more work is required to make text-to-speech (TTS) a viable solution for scaling up E2E SLU.
Improved Lite Audio-Visual Speech Enhancement
Aug 30, 2020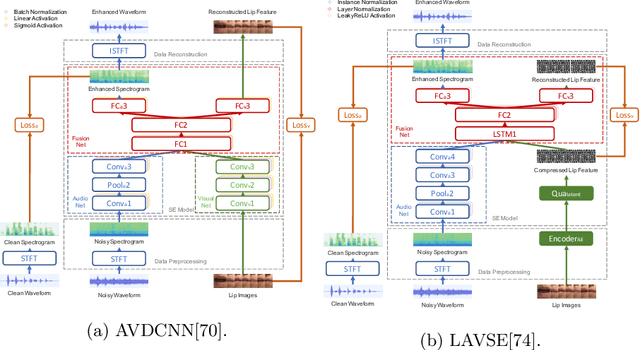
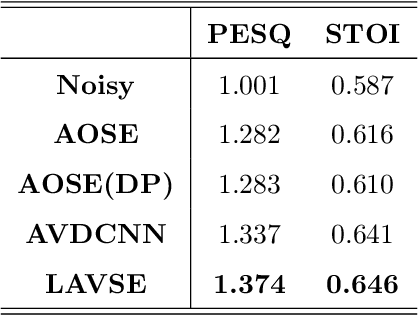

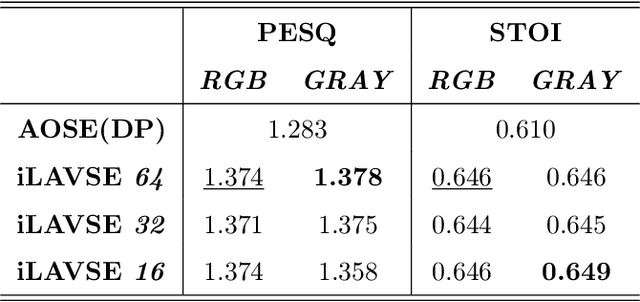
Numerous studies have investigated the effectiveness of audio-visual multimodal learning for speech enhancement (AVSE) tasks, seeking a solution that uses visual data as auxiliary and complementary input to reduce the noise of noisy speech signals. Recently, we proposed a lite audio-visual speech enhancement (LAVSE) algorithm. Compared to conventional AVSE systems, LAVSE requires less online computation and moderately solves the user privacy problem on facial data. In this study, we extend LAVSE to improve its ability to address three practical issues often encountered in implementing AVSE systems, namely, the requirement for additional visual data, audio-visual asynchronization, and low-quality visual data. The proposed system is termed improved LAVSE (iLAVSE), which uses a convolutional recurrent neural network architecture as the core AVSE model. We evaluate iLAVSE on the Taiwan Mandarin speech with video dataset. Experimental results confirm that compared to conventional AVSE systems, iLAVSE can effectively overcome the aforementioned three practical issues and can improve enhancement performance. The results also confirm that iLAVSE is suitable for real-world scenarios, where high-quality audio-visual sensors may not always be available.
Into-TTS : Intonation Template based Prosody Control System
Apr 04, 2022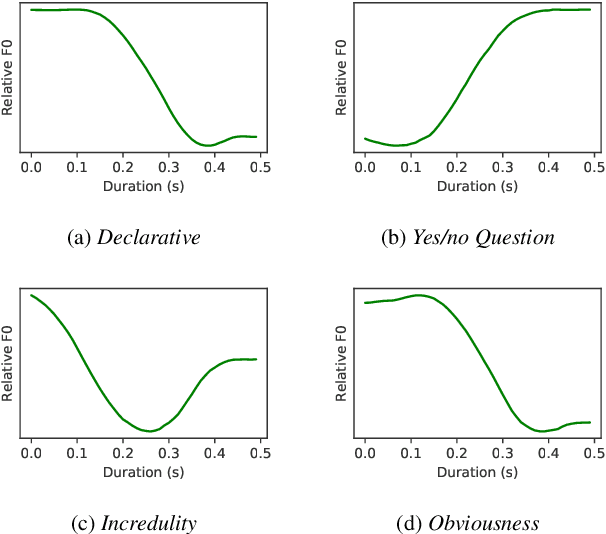

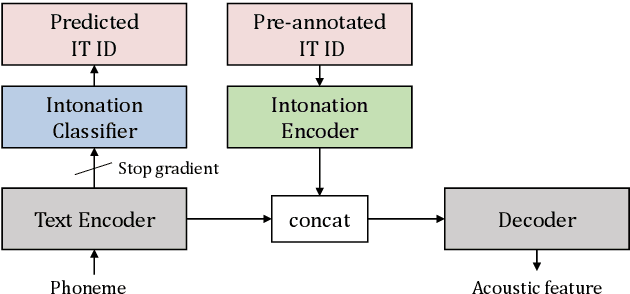
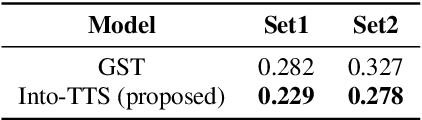
Intonations take an important role in delivering the intention of the speaker. However, current end-to-end TTS systems often fail to model proper intonations. To alleviate this problem, we propose a novel, intuitive method to synthesize speech in different intonations using predefined intonation templates. Prior to the acoustic model training, speech data are automatically grouped into intonation templates by k-means clustering, according to their sentence-final F0 contour. Two proposed modules are added to the end-to-end TTS framework: intonation classifier and intonation encoder. The intonation classifier recommends a suitable intonation template to the given text. The intonation encoder, attached to the text encoder output, synthesizes speech abiding the requested intonation template. Main contributions of our paper are: (a) an easy-to-use intonation control system covering a wide range of users; (b) better performance in wrapping speech in a requested intonation with improved pitch distance and MOS; and (c) feasibility to future integration between TTS and NLP, TTS being able to utilize contextual information. Audio samples are available at https://srtts.github.io/IntoTTS.
Plant Species Classification Using Transfer Learning by Pretrained Classifier VGG-19
Sep 07, 2022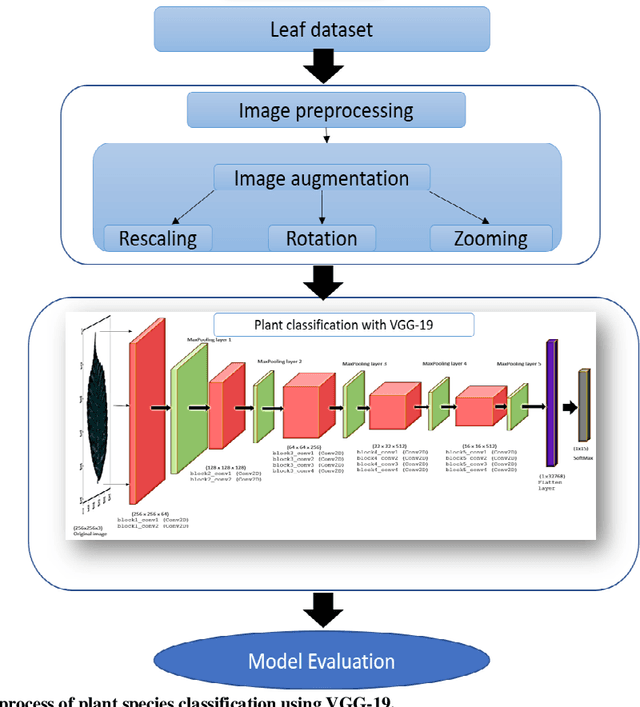


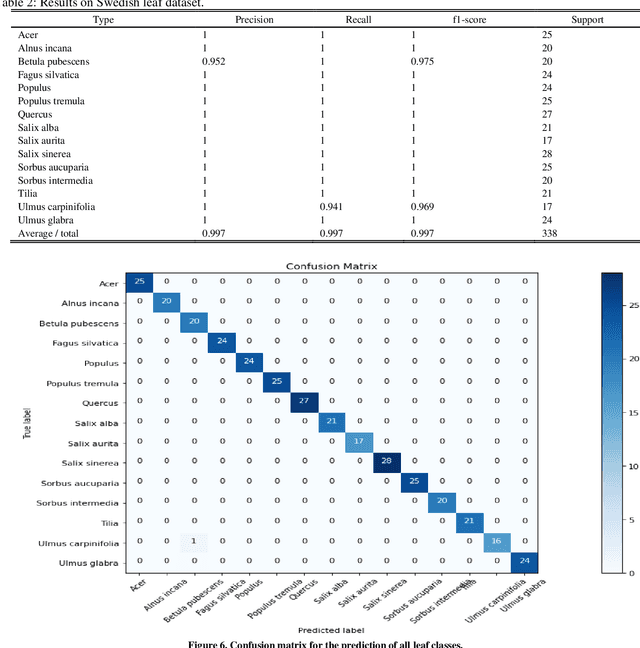
Deep learning is currently the most important branch of machine learning, with applications in speech recognition, computer vision, image classification, and medical imaging analysis. Plant recognition is one of the areas where image classification can be used to identify plant species through their leaves. Botanists devote a significant amount of time to recognizing plant species by personally inspecting. This paper describes a method for dissecting color images of Swedish leaves and identifying plant species. To achieve higher accuracy, the task is completed using transfer learning with the help of pre-trained classifier VGG-19. The four primary processes of classification are image preprocessing, image augmentation, feature extraction, and recognition, which are performed as part of the overall model evaluation. The VGG-19 classifier grasps the characteristics of leaves by employing pre-defined hidden layers such as convolutional layers, max pooling layers, and fully connected layers, and finally uses the soft-max layer to generate a feature representation for all plant classes. The model obtains knowledge connected to aspects of the Swedish leaf dataset, which contains fifteen tree classes, and aids in predicting the proper class of an unknown plant with an accuracy of 99.70% which is higher than previous research works reported.
Robust Acoustic Scene Classification in the Presence of Active Foreground Speech
Aug 02, 2021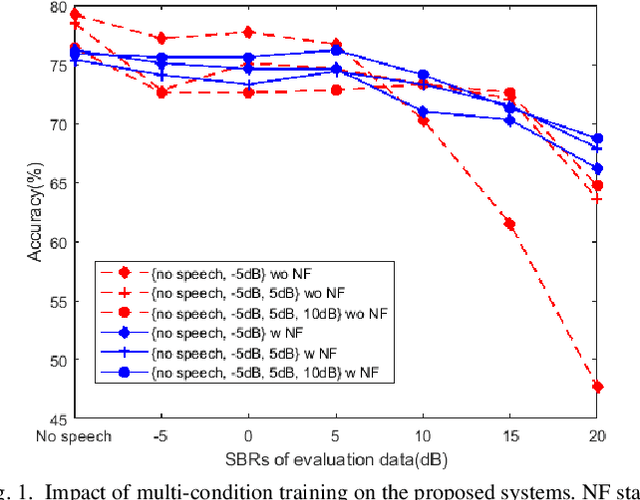


We present an iVector based Acoustic Scene Classification (ASC) system suited for real life settings where active foreground speech can be present. In the proposed system, each recording is represented by a fixed-length iVector that models the recording's important properties. A regularized Gaussian backend classifier with class-specific covariance models is used to extract the relevant acoustic scene information from these iVectors. To alleviate the large performance degradation when a foreground speaker dominates the captured signal, we investigate the use of the iVector framework on Mel-Frequency Cepstral Coefficients (MFCCs) that are derived from an estimate of the noise power spectral density. This noise-floor can be extracted in a statistical manner for single channel recordings. We show that the use of noise-floor features is complementary to multi-condition training in which foreground speech is added to training signal to reduce the mismatch between training and testing conditions. Experimental results on the DCASE 2016 Task 1 dataset show that the noise-floor based features and multi-condition training realize significant classification accuracy gains of up to more than 25 percentage points (absolute) in the most adverse conditions. These promising results can further facilitate the integration of ASC in resource-constrained devices such as hearables.
Contextual Lexicon-Based Approach for Hate Speech and Offensive Language Detection
Apr 25, 2021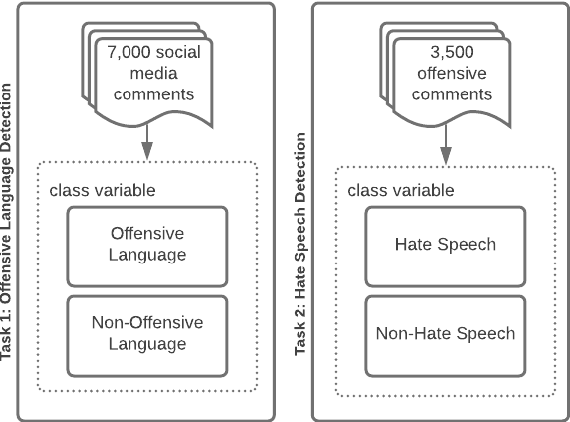
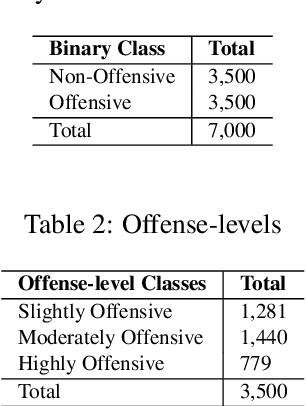
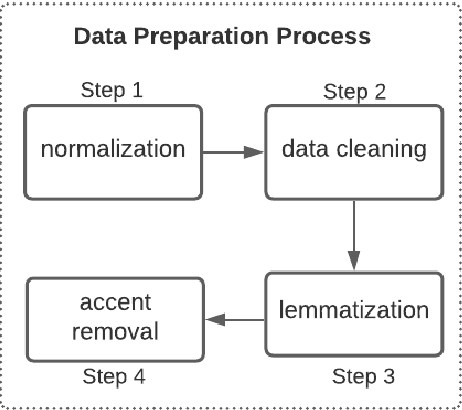
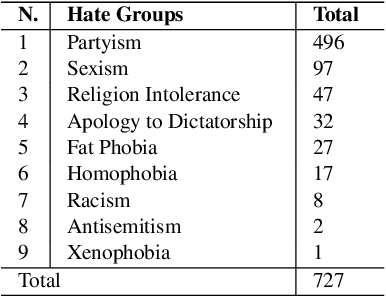
This paper presents a new approach for offensive language and hate speech detection on social media. Our approach incorporates an offensive lexicon composed by implicit and explicit offensive and swearing expressions annotated with binary classes: context-dependent offensive and context-independent offensive. Due to the severity of the hate speech and offensive comments in Brazil and the lack of research in Portuguese, Brazilian Portuguese is the language used to validate our method. However, the proposal may be applied to any other language or domain. Based on the obtained results, the proposed approach showed high performance results overcoming the current baselines for European and Brazilian Portuguese.
Royalflush Speaker Diarization System for ICASSP 2022 Multi-channel Multi-party Meeting Transcription Challenge
Feb 10, 2022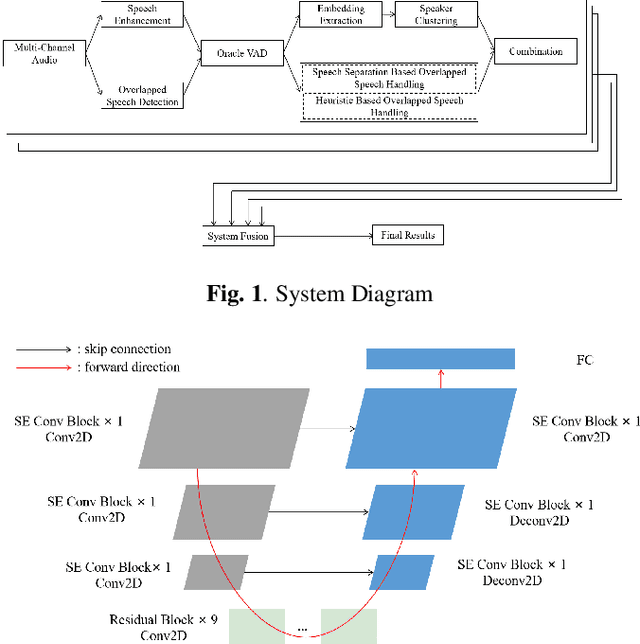
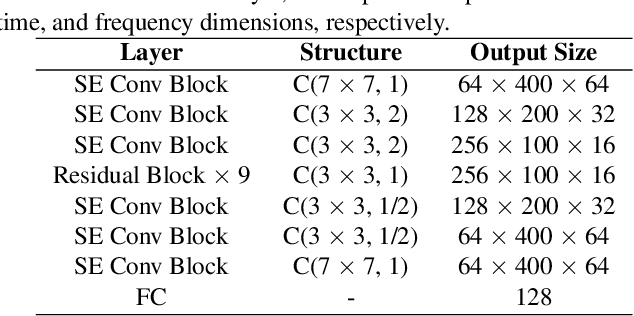
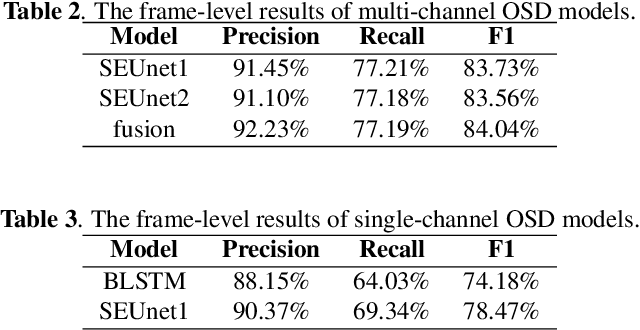
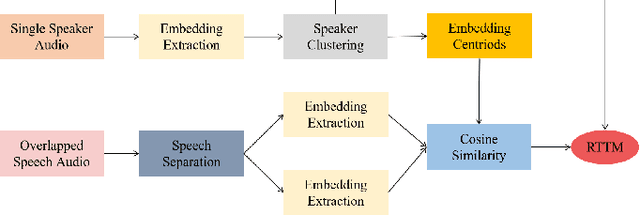
This paper describes the Royalflush speaker diarization system submitted to the Multi-channel Multi-party Meeting Transcription Challenge. Our system comprises speech enhancement, overlapped speech detection, speaker embedding extraction, speaker clustering, speech separation and system fusion. In this system, we made three contributions. First, we propose an architecture of combining the multi-channel and U-Net-based models, aiming at utilizing the benefits of these two individual architectures, for far-field overlapped speech detection. Second, in order to use overlapped speech detection model to help speaker diarization, a speech separation based overlapped speech handling approach, in which the speaker verification technique is further applied, is proposed. Third, we explore three speaker embedding methods, and obtained the state-of-the-art performance on the CNCeleb-E test set. With these proposals, our best individual system significantly reduces DER from 15.25% to 6.40%, and the fusion of four systems finally achieves a DER of 6.30% on the far-field Alimeeting evaluation set.
A Benchmark of Dynamical Variational Autoencoders applied to Speech Spectrogram Modeling
Jun 11, 2021
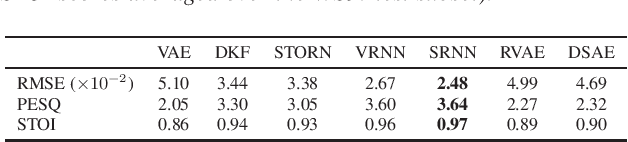
The Variational Autoencoder (VAE) is a powerful deep generative model that is now extensively used to represent high-dimensional complex data via a low-dimensional latent space learned in an unsupervised manner. In the original VAE model, input data vectors are processed independently. In recent years, a series of papers have presented different extensions of the VAE to process sequential data, that not only model the latent space, but also model the temporal dependencies within a sequence of data vectors and corresponding latent vectors, relying on recurrent neural networks. We recently performed a comprehensive review of those models and unified them into a general class called Dynamical Variational Autoencoders (DVAEs). In the present paper, we present the results of an experimental benchmark comparing six of those DVAE models on the speech analysis-resynthesis task, as an illustration of the high potential of DVAEs for speech modeling.
Demoting Racial Bias in Hate Speech Detection
May 25, 2020
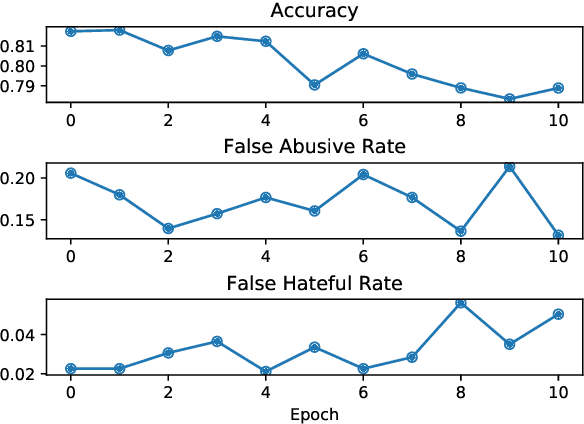

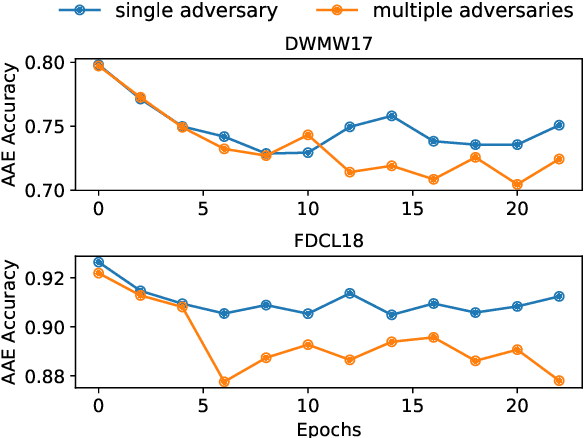
In current hate speech datasets, there exists a high correlation between annotators' perceptions of toxicity and signals of African American English (AAE). This bias in annotated training data and the tendency of machine learning models to amplify it cause AAE text to often be mislabeled as abusive/offensive/hate speech with a high false positive rate by current hate speech classifiers. In this paper, we use adversarial training to mitigate this bias, introducing a hate speech classifier that learns to detect toxic sentences while demoting confounds corresponding to AAE texts. Experimental results on a hate speech dataset and an AAE dataset suggest that our method is able to substantially reduce the false positive rate for AAE text while only minimally affecting the performance of hate speech classification.
General-Purpose Speech Representation Learning through a Self-Supervised Multi-Granularity Framework
Feb 03, 2021
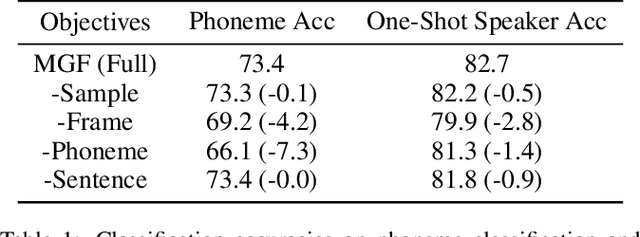
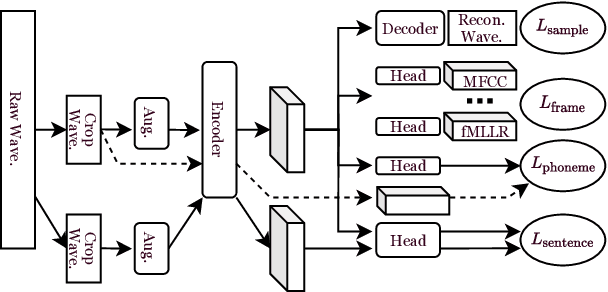
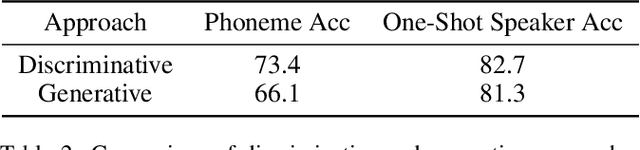
This paper presents a self-supervised learning framework, named MGF, for general-purpose speech representation learning. In the design of MGF, speech hierarchy is taken into consideration. Specifically, we propose to use generative learning approaches to capture fine-grained information at small time scales and use discriminative learning approaches to distill coarse-grained or semantic information at large time scales. For phoneme-scale learning, we borrow idea from the masked language model but tailor it for the continuous speech signal by replacing classification loss with a contrastive loss. We corroborate our design by evaluating MGF representation on various downstream tasks, including phoneme classification, speaker classification, speech recognition, and emotion classification. Experiments verify that training at different time scales needs different training targets and loss functions, which in general complement each other and lead to a better performance.