 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
High-Quality Vocoding Design with Signal Processing for Speech Synthesis and Voice Conversion
Jan 25, 2021
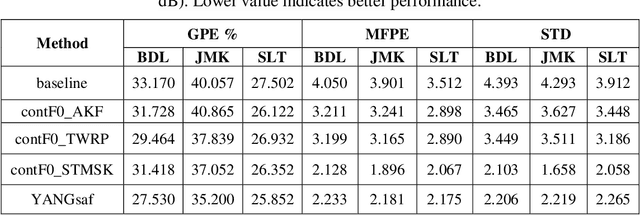
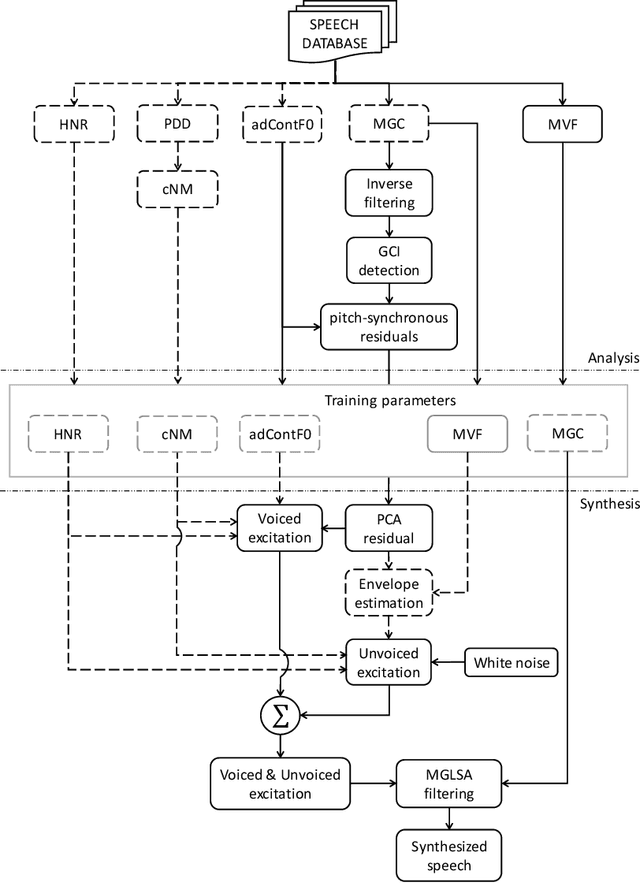
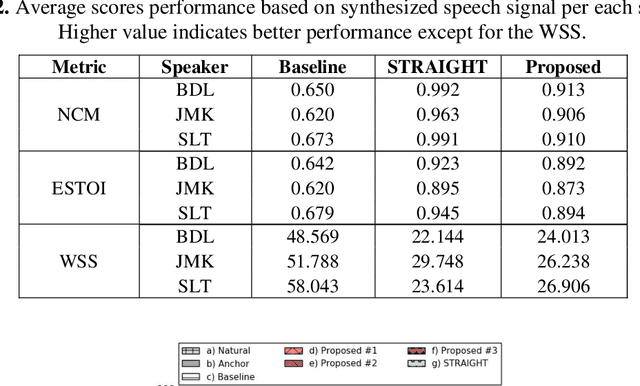
This Ph.D. thesis focuses on developing a system for high-quality speech synthesis and voice conversion. Vocoder-based speech analysis, manipulation, and synthesis plays a crucial role in various kinds of statistical parametric speech research. Although there are vocoding methods which yield close to natural synthesized speech, they are typically computationally expensive, and are thus not suitable for real-time implementation, especially in embedded environments. Therefore, there is a need for simple and computationally feasible digital signal processing algorithms for generating high-quality and natural-sounding synthesized speech. In this dissertation, I propose a solution to extract optimal acoustic features and a new waveform generator to achieve higher sound quality and conversion accuracy by applying advances in deep learning. The approach remains computationally efficient. This challenge resulted in five thesis groups, which are briefly summarized below.
Speech enhancement with mixture-of-deep-experts with clean clustering pre-training
Feb 11, 2021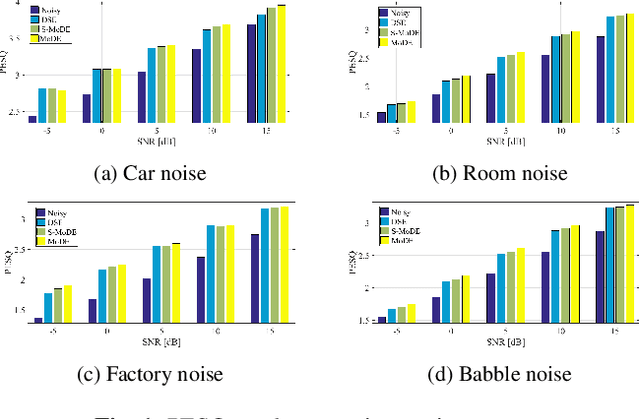

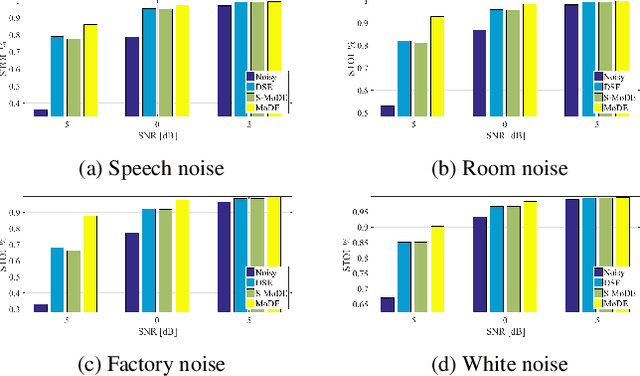
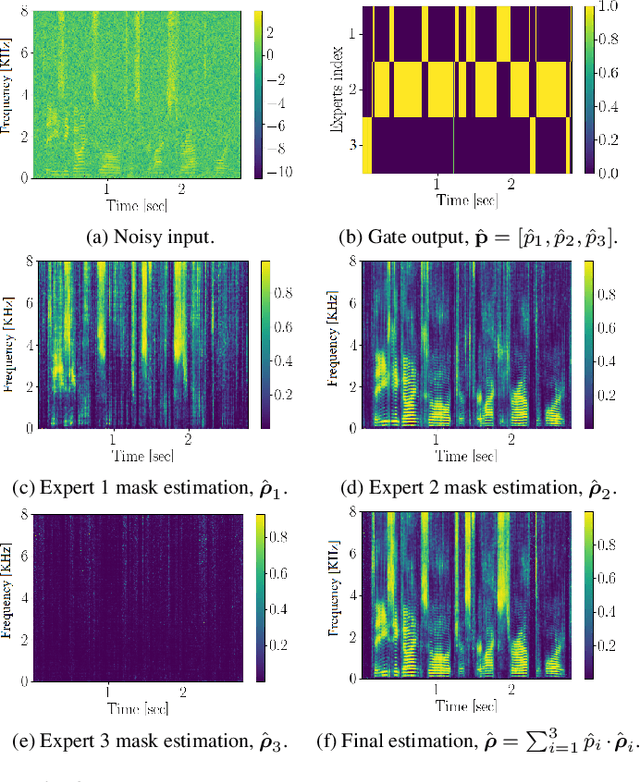
In this study we present a mixture of deep experts (MoDE) neural-network architecture for single microphone speech enhancement. Our architecture comprises a set of deep neural networks (DNNs), each of which is an 'expert' in a different speech spectral pattern such as phoneme. A gating DNN is responsible for the latent variables which are the weights assigned to each expert's output given a speech segment. The experts estimate a mask from the noisy input and the final mask is then obtained as a weighted average of the experts' estimates, with the weights determined by the gating DNN. A soft spectral attenuation, based on the estimated mask, is then applied to enhance the noisy speech signal. As a byproduct, we gain reduction at the complexity in test time. We show that the experts specialization allows better robustness to unfamiliar noise types.
Speech Emotion Recognition using Semantic Information
Mar 04, 2021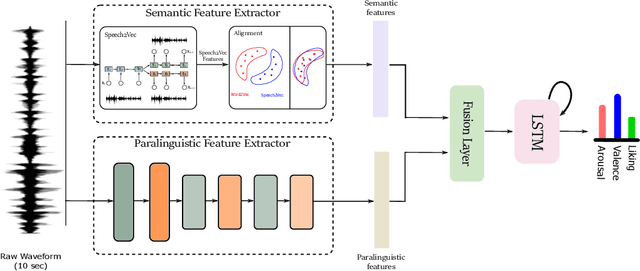

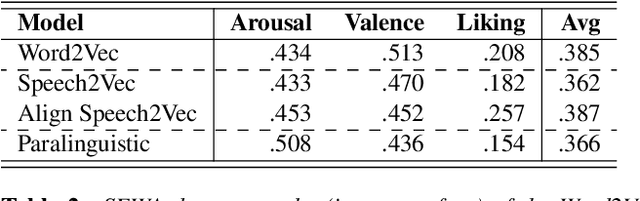

Speech emotion recognition is a crucial problem manifesting in a multitude of applications such as human computer interaction and education. Although several advancements have been made in the recent years, especially with the advent of Deep Neural Networks (DNN), most of the studies in the literature fail to consider the semantic information in the speech signal. In this paper, we propose a novel framework that can capture both the semantic and the paralinguistic information in the signal. In particular, our framework is comprised of a semantic feature extractor, that captures the semantic information, and a paralinguistic feature extractor, that captures the paralinguistic information. Both semantic and paraliguistic features are then combined to a unified representation using a novel attention mechanism. The unified feature vector is passed through a LSTM to capture the temporal dynamics in the signal, before the final prediction. To validate the effectiveness of our framework, we use the popular SEWA dataset of the AVEC challenge series and compare with the three winning papers. Our model provides state-of-the-art results in the valence and liking dimensions.
CoVoST 2 and Massively Multilingual Speech-to-Text Translation
Aug 20, 2020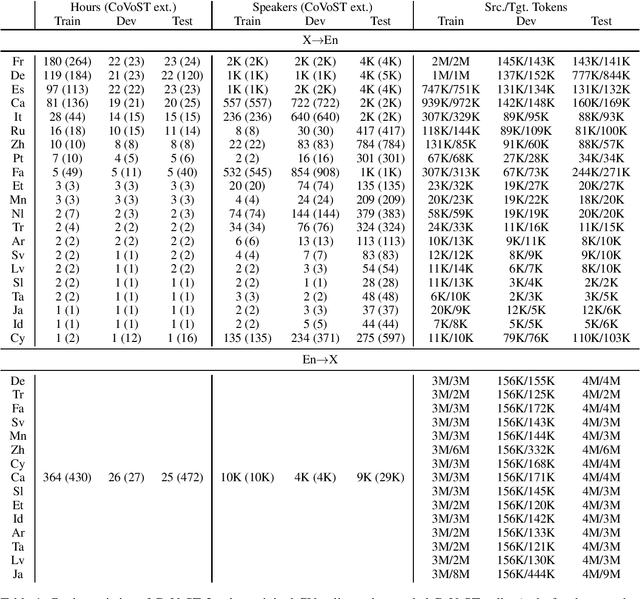
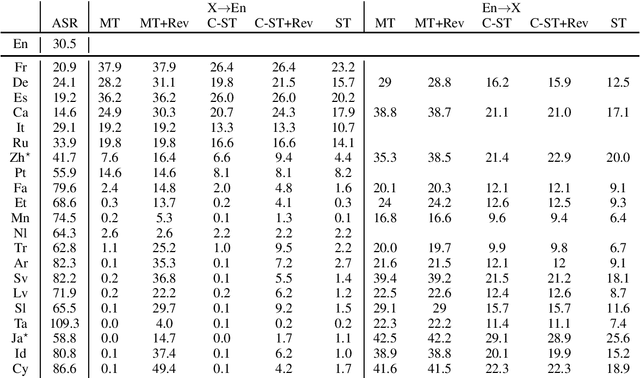
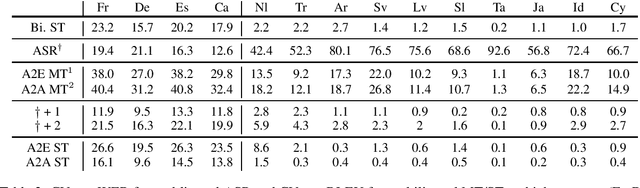
Speech translation has recently become an increasingly popular topic of research, partly due to the development of benchmark datasets. Nevertheless, current datasets cover a limited number of languages. With the aim to foster research in massive multilingual speech translation and speech translation for low resource language pairs, we release CoVoST 2, a large-scale multilingual speech translation corpus covering translations from 21 languages into English and from English into 15 languages. This represents the largest open dataset available to date from total volume and language coverage perspective. Data sanity checks provide evidence about the quality of the data, which is released under CC0 license. We also provide extensive speech recognition, bilingual and multilingual machine translation and speech translation baselines.
Royalflush Speaker Diarization System for ICASSP 2022 Multi-channel Multi-party Meeting Transcription Challenge
Feb 10, 2022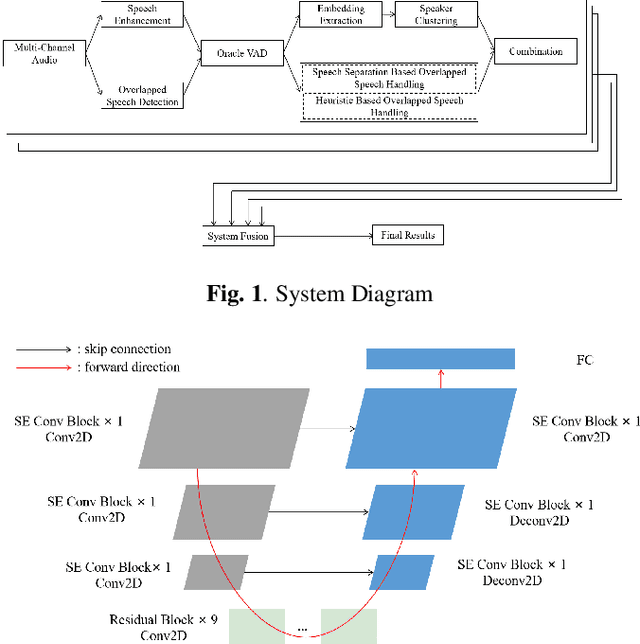
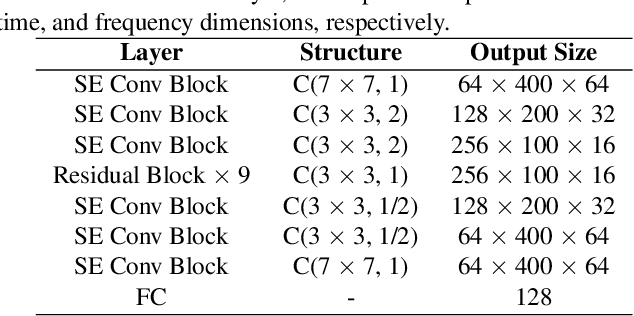
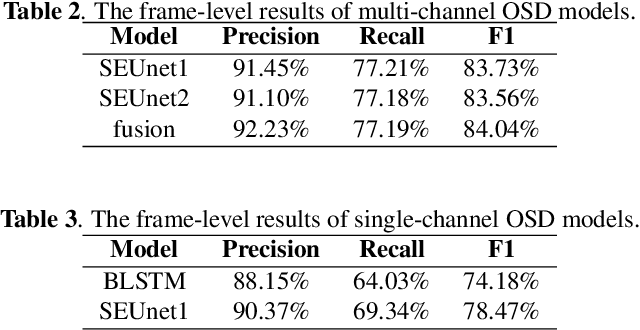
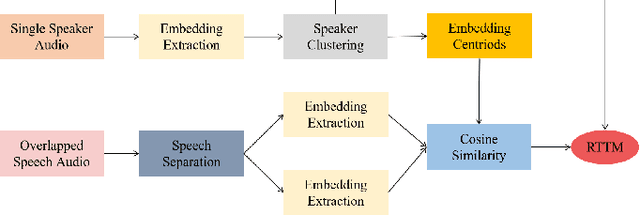
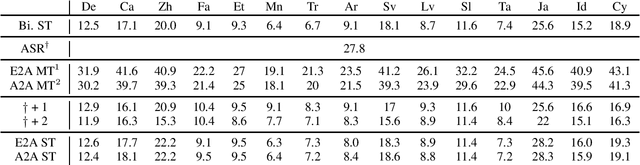
This paper describes the Royalflush speaker diarization system submitted to the Multi-channel Multi-party Meeting Transcription Challenge. Our system comprises speech enhancement, overlapped speech detection, speaker embedding extraction, speaker clustering, speech separation and system fusion. In this system, we made three contributions. First, we propose an architecture of combining the multi-channel and U-Net-based models, aiming at utilizing the benefits of these two individual architectures, for far-field overlapped speech detection. Second, in order to use overlapped speech detection model to help speaker diarization, a speech separation based overlapped speech handling approach, in which the speaker verification technique is further applied, is proposed. Third, we explore three speaker embedding methods, and obtained the state-of-the-art performance on the CNCeleb-E test set. With these proposals, our best individual system significantly reduces DER from 15.25% to 6.40%, and the fusion of four systems finally achieves a DER of 6.30% on the far-field Alimeeting evaluation set.
On the limit of English conversational speech recognition
May 03, 2021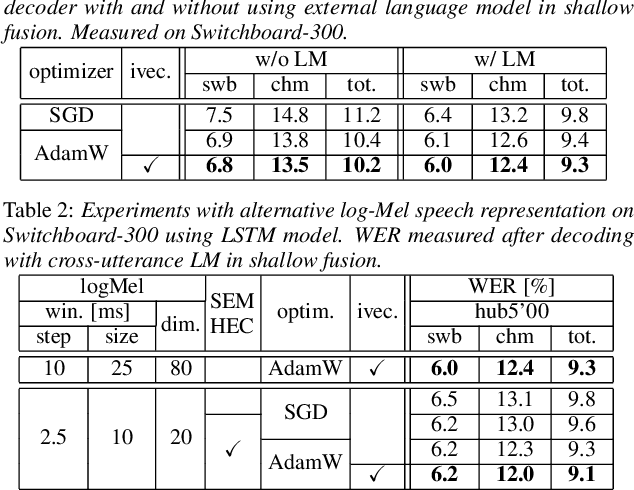
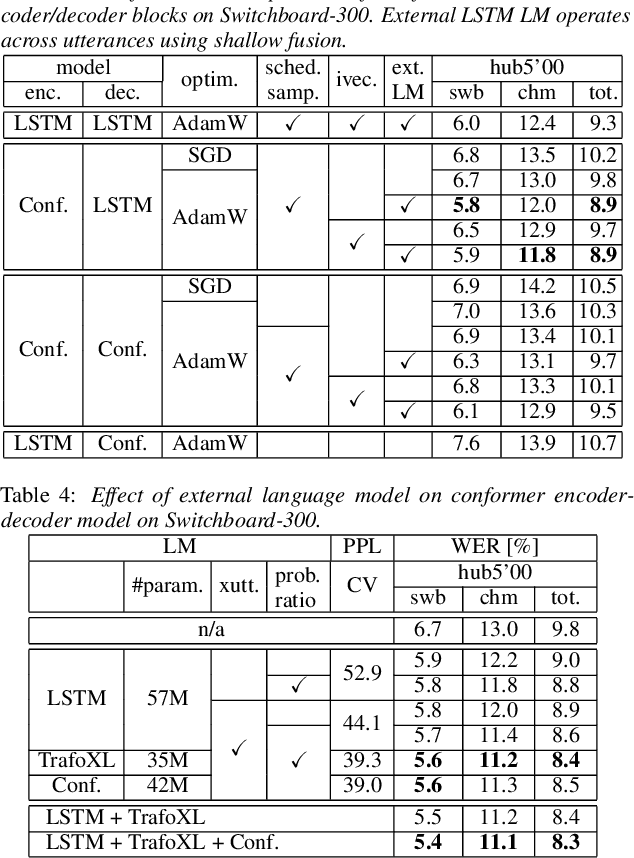
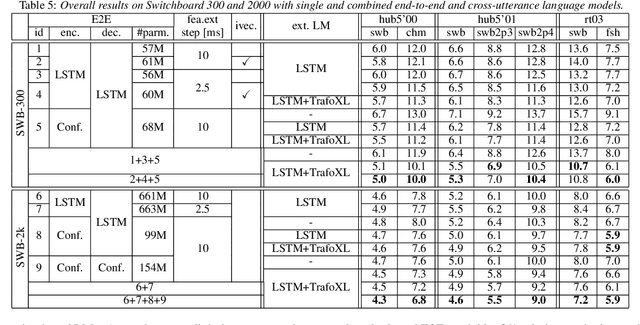
In our previous work we demonstrated that a single headed attention encoder-decoder model is able to reach state-of-the-art results in conversational speech recognition. In this paper, we further improve the results for both Switchboard 300 and 2000. Through use of an improved optimizer, speaker vector embeddings, and alternative speech representations we reduce the recognition errors of our LSTM system on Switchboard-300 by 4% relative. Compensation of the decoder model with the probability ratio approach allows more efficient integration of an external language model, and we report 5.9% and 11.5% WER on the SWB and CHM parts of Hub5'00 with very simple LSTM models. Our study also considers the recently proposed conformer, and more advanced self-attention based language models. Overall, the conformer shows similar performance to the LSTM; nevertheless, their combination and decoding with an improved LM reaches a new record on Switchboard-300, 5.0% and 10.0% WER on SWB and CHM. Our findings are also confirmed on Switchboard-2000, and a new state of the art is reported, practically reaching the limit of the benchmark.
MLS: A Large-Scale Multilingual Dataset for Speech Research
Dec 07, 2020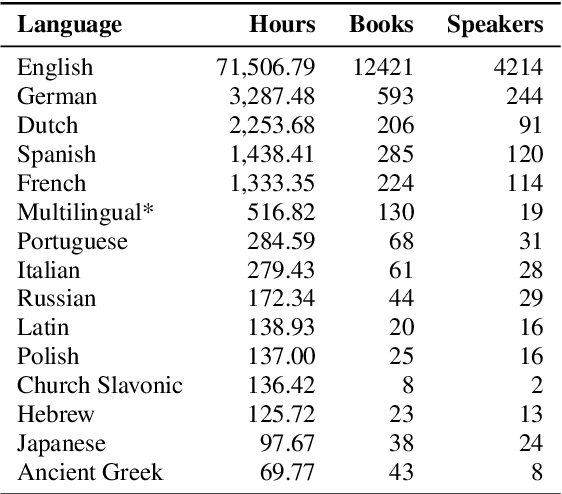
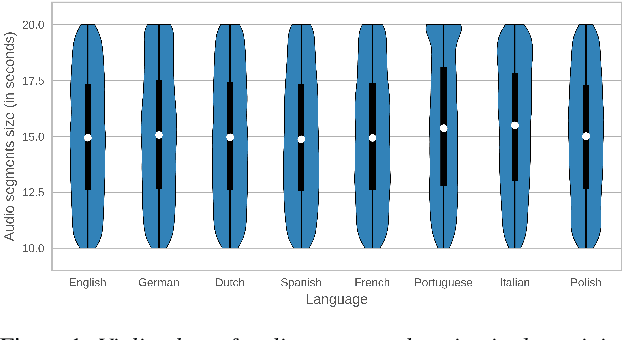
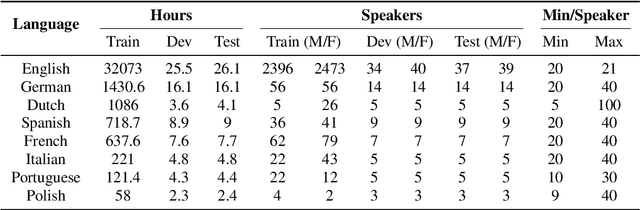
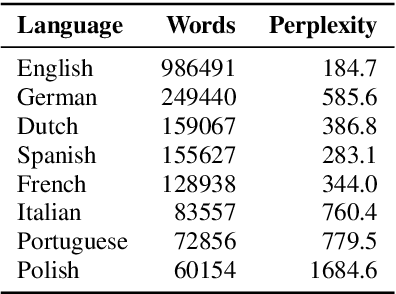
This paper introduces Multilingual LibriSpeech (MLS) dataset, a large multilingual corpus suitable for speech research. The dataset is derived from read audiobooks from LibriVox and consists of 8 languages, including about 44.5K hours of English and a total of about 6K hours for other languages. Additionally, we provide Language Models (LM) and baseline Automatic Speech Recognition (ASR) models and for all the languages in our dataset. We believe such a large transcribed dataset will open new avenues in ASR and Text-To-Speech (TTS) research. The dataset will be made freely available for anyone at http://www.openslr.org.
Target Speaker Verification with Selective Auditory Attention for Single and Multi-talker Speech
Mar 30, 2021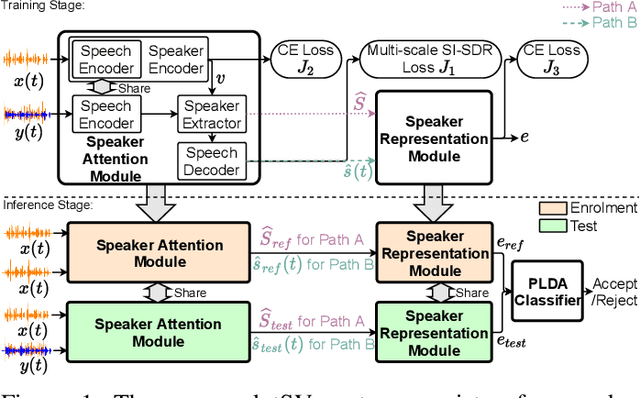
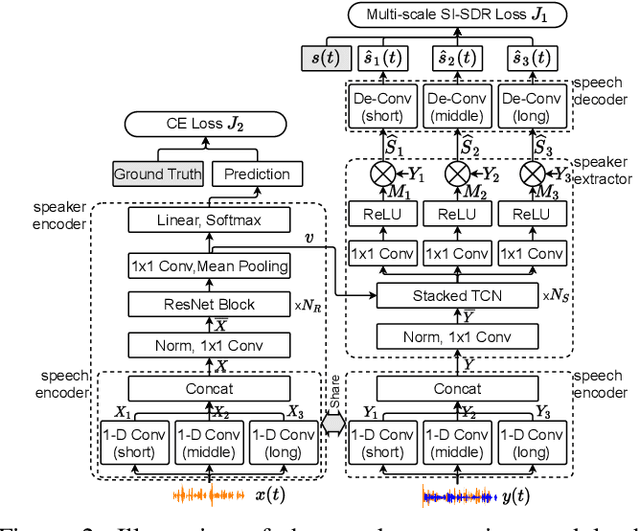
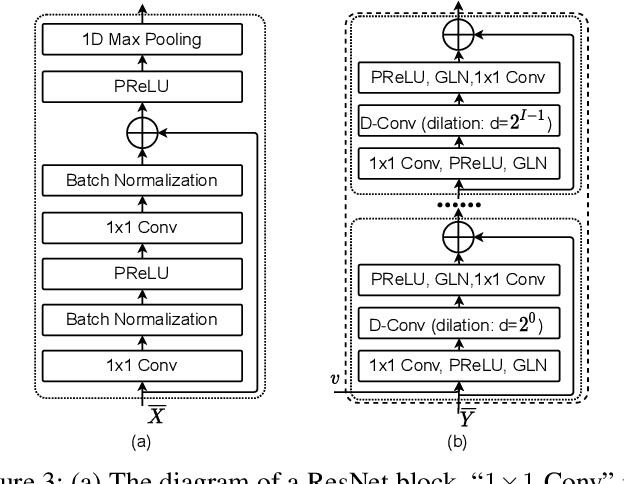
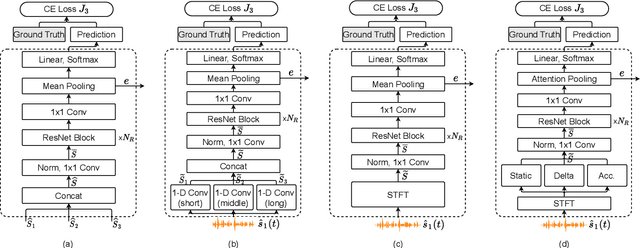
Speaker verification has been studied mostly under the single-talker condition. It is adversely affected in the presence of interference speakers. Inspired by the study on target speaker extraction, e.g., SpEx, we propose a unified speaker verification framework for both single- and multi-talker speech, that is able to pay selective auditory attention to the target speaker. This target speaker verification (tSV) framework jointly optimizes a speaker attention module and a speaker representation module via multi-task learning. We study four different target speaker embedding schemes under the tSV framework. The experimental results show that all four target speaker embedding schemes significantly outperform other competitive solutions for multi-talker speech. Notably, the best tSV speaker embedding scheme achieves 76.0% and 55.3% relative improvements over the baseline system on the WSJ0-2mix-extr and Libri2Mix corpora in terms of equal-error-rate for 2-talker speech, while the performance of tSV for single-talker speech is on par with that of traditional speaker verification system, that is trained and evaluated under the same single-talker condition.
DF-Conformer: Integrated architecture of Conv-TasNet and Conformer using linear complexity self-attention for speech enhancement
Jun 30, 2021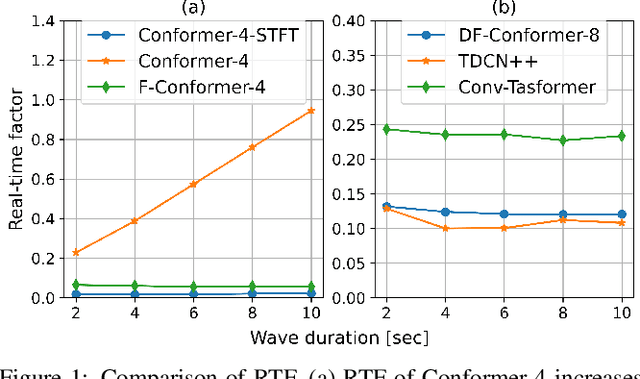
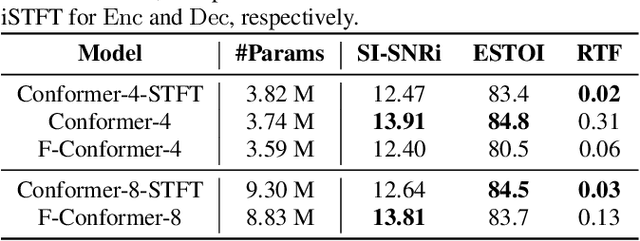
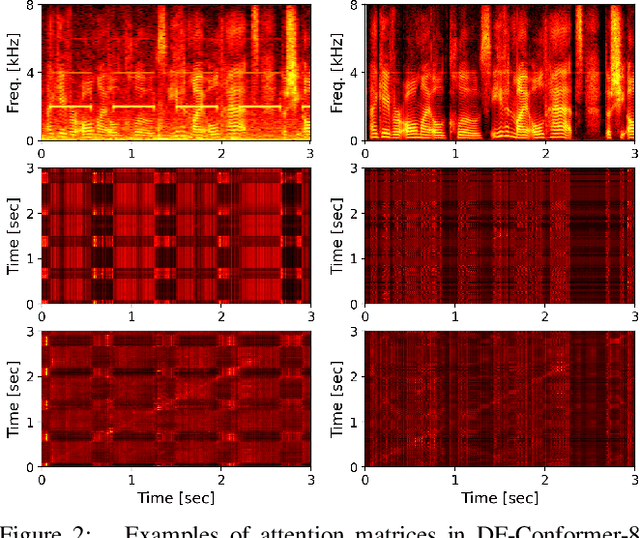
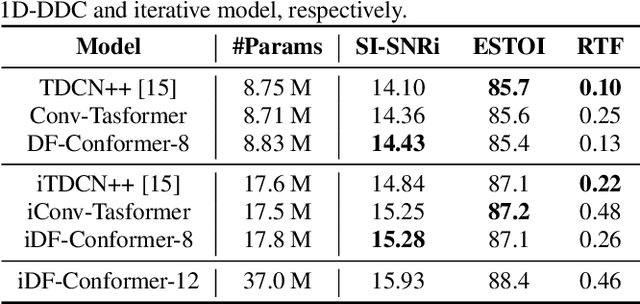
Single-channel speech enhancement (SE) is an important task in speech processing. A widely used framework combines an analysis/synthesis filterbank with a mask prediction network, such as the Conv-TasNet architecture. In such systems, the denoising performance and computational efficiency are mainly affected by the structure of the mask prediction network. In this study, we aim to improve the sequential modeling ability of Conv-TasNet architectures by integrating Conformer layers into a new mask prediction network. To make the model computationally feasible, we extend the Conformer using linear complexity attention and stacked 1-D dilated depthwise convolution layers. We trained the model on 3,396 hours of noisy speech data, and show that (i) the use of linear complexity attention avoids high computational complexity, and (ii) our model achieves higher scale-invariant signal-to-noise ratio than the improved time-dilated convolution network (TDCN++), an extended version of Conv-TasNet.
End-to-End Speaker Diarization Conditioned on Speech Activity and Overlap Detection
Jun 08, 2021
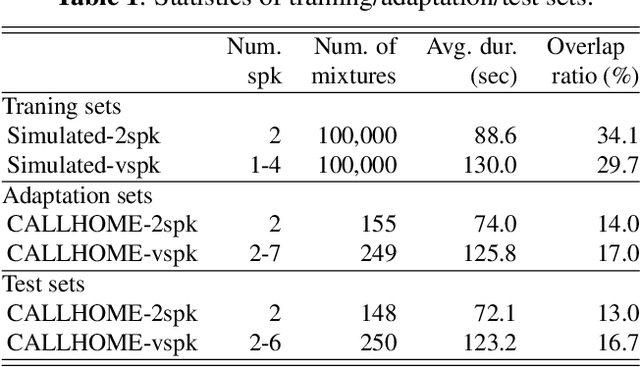
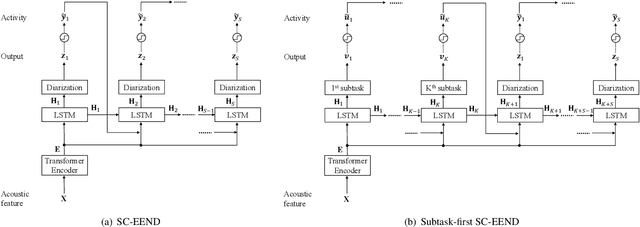
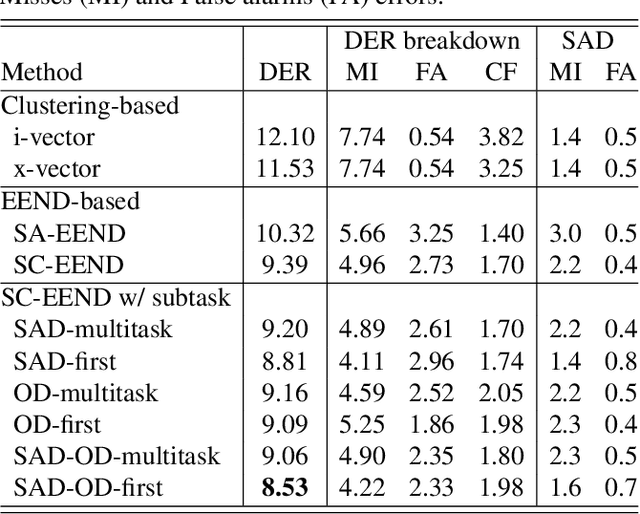
In this paper, we present a conditional multitask learning method for end-to-end neural speaker diarization (EEND). The EEND system has shown promising performance compared with traditional clustering-based methods, especially in the case of overlapping speech. In this paper, to further improve the performance of the EEND system, we propose a novel multitask learning framework that solves speaker diarization and a desired subtask while explicitly considering the task dependency. We optimize speaker diarization conditioned on speech activity and overlap detection that are subtasks of speaker diarization, based on the probabilistic chain rule. Experimental results show that our proposed method can leverage a subtask to effectively model speaker diarization, and outperforms conventional EEND systems in terms of diarization error rate.
* Accepted for SLT 2021