 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Deliberation Model for On-Device Spoken Language Understanding
Apr 04, 2022
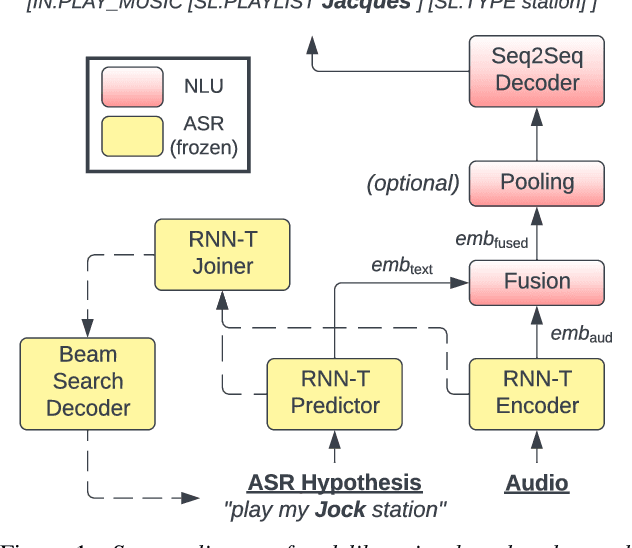

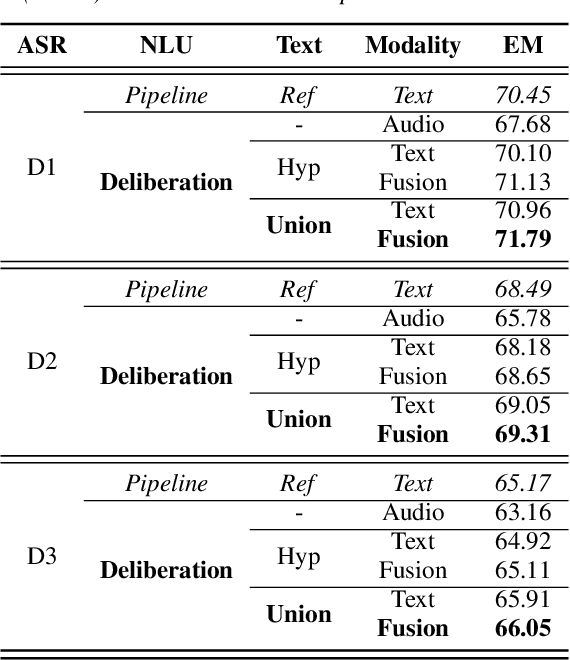
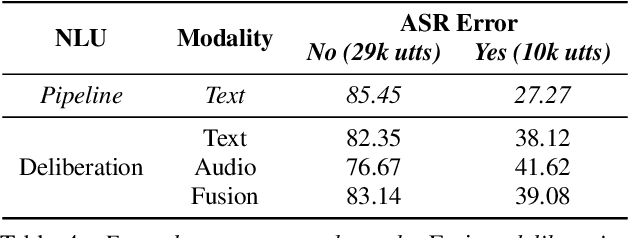
We propose a novel deliberation-based approach to end-to-end (E2E) spoken language understanding (SLU), where a streaming automatic speech recognition (ASR) model produces the first-pass hypothesis and a second-pass natural language understanding (NLU) component generates the semantic parse by conditioning on both ASR's text and audio embeddings. By formulating E2E SLU as a generalized decoder, our system is able to support complex compositional semantic structures. Furthermore, the sharing of parameters between ASR and NLU makes the system especially suitable for resource-constrained (on-device) environments; our proposed approach consistently outperforms strong pipeline NLU baselines by 0.82% to 1.34% across various operating points on the spoken version of the TOPv2 dataset. We demonstrate that the fusion of text and audio features, coupled with the system's ability to rewrite the first-pass hypothesis, makes our approach more robust to ASR errors. Finally, we show that our approach can significantly reduce the degradation when moving from natural speech to synthetic speech training, but more work is required to make text-to-speech (TTS) a viable solution for scaling up E2E SLU.
Model Blending for Text Classification
Aug 05, 2022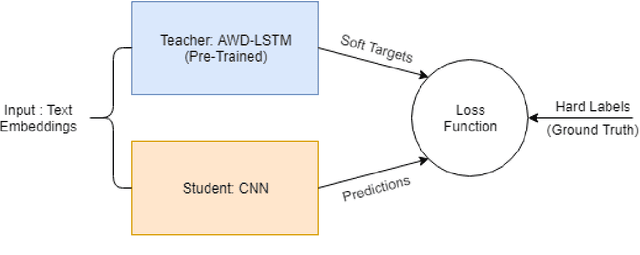
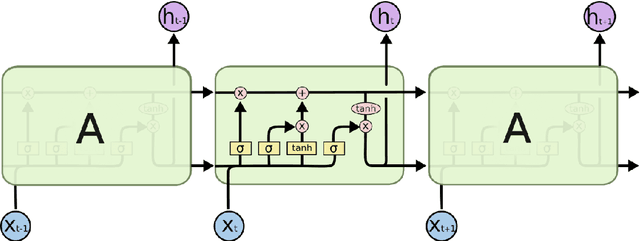
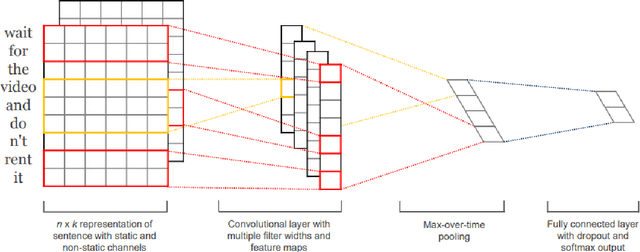
Deep neural networks (DNNs) have proven successful in a wide variety of applications such as speech recognition and synthesis, computer vision, machine translation, and game playing, to name but a few. However, existing deep neural network models are computationally expensive and memory intensive, hindering their deployment in devices with low memory resources or in applications with strict latency requirements. Therefore, a natural thought is to perform model compression and acceleration in deep networks without significantly decreasing the model performance, which is what we call reducing the complexity. In the following work, we try reducing the complexity of state of the art LSTM models for natural language tasks such as text classification, by distilling their knowledge to CNN based models, thus reducing the inference time(or latency) during testing.
Towards Semi-Supervised Semantics Understanding from Speech
Nov 11, 2020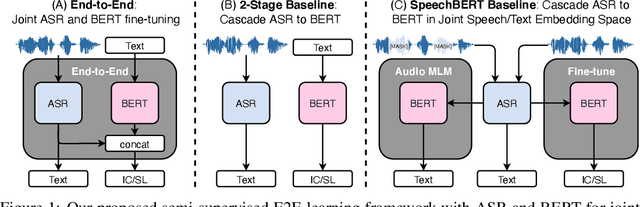
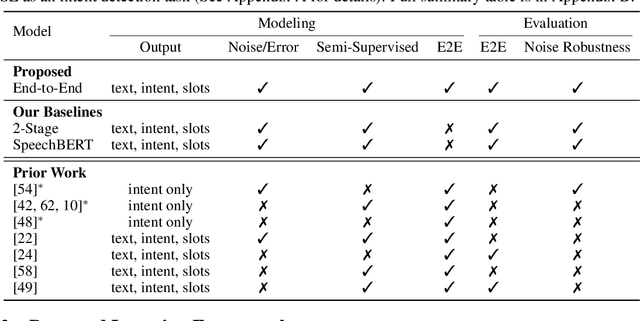
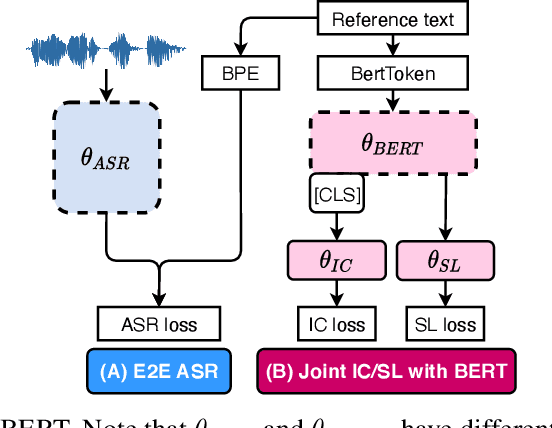
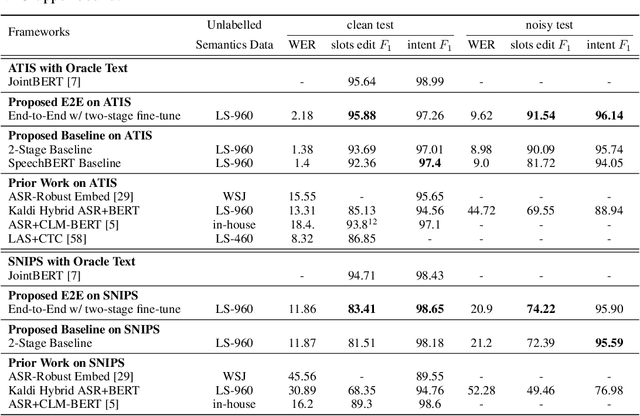
Much recent work on Spoken Language Understanding (SLU) falls short in at least one of three ways: models were trained on oracle text input and neglected the Automatics Speech Recognition (ASR) outputs, models were trained to predict only intents without the slot values, or models were trained on a large amount of in-house data. We proposed a clean and general framework to learn semantics directly from speech with semi-supervision from transcribed speech to address these. Our framework is built upon pretrained end-to-end (E2E) ASR and self-supervised language models, such as BERT, and fine-tuned on a limited amount of target SLU corpus. In parallel, we identified two inadequate settings under which SLU models have been tested: noise-robustness and E2E semantics evaluation. We tested the proposed framework under realistic environmental noises and with a new metric, the slots edit F1 score, on two public SLU corpora. Experiments show that our SLU framework with speech as input can perform on par with those with oracle text as input in semantics understanding, while environmental noises are present, and a limited amount of labeled semantics data is available.
Learning from human perception to improve automatic speaker verification in style-mismatched conditions
Jun 28, 2022
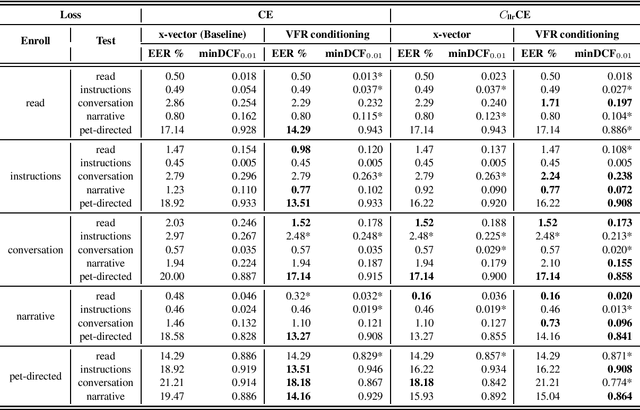
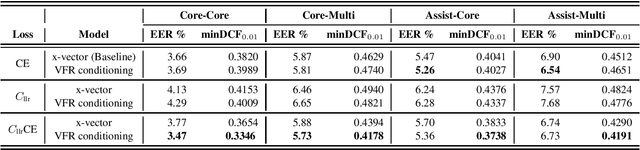
Our prior experiments show that humans and machines seem to employ different approaches to speaker discrimination, especially in the presence of speaking style variability. The experiments examined read versus conversational speech. Listeners focused on speaker-specific idiosyncrasies while "telling speakers together", and on relative distances in a shared acoustic space when "telling speakers apart". However, automatic speaker verification (ASV) systems use the same loss function irrespective of target or non-target trials. To improve ASV performance in the presence of style variability, insights learnt from human perception are used to design a new training loss function that we refer to as "CllrCE loss". CllrCE loss uses both speaker-specific idiosyncrasies and relative acoustic distances between speakers to train the ASV system. When using the UCLA speaker variability database, in the x-vector and conditioning setups, CllrCE loss results in significant relative improvements in EER by 1-66%, and minDCF by 1-31% and 1-56%, respectively, when compared to the x-vector baseline. Using the SITW evaluation tasks, which involve different conversational speech tasks, the proposed loss combined with self-attention conditioning results in significant relative improvements in EER by 2-5% and minDCF by 6-12% over baseline. In the SITW case, performance improvements were consistent only with conditioning.
TweetBLM: A Hate Speech Dataset and Analysis of Black Lives Matter-related Microblogs on Twitter
Aug 27, 2021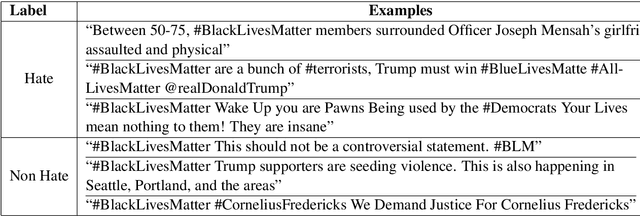
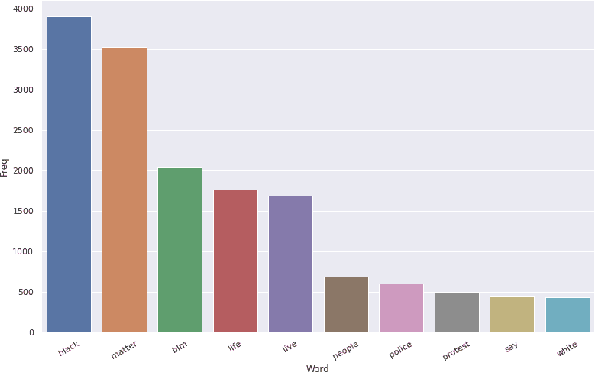

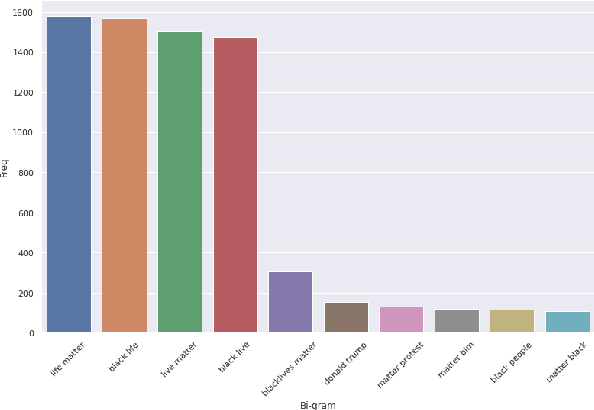
In the past few years, there has been a significant rise in toxic and hateful content on various social media platforms. Recently Black Lives Matter movement came into the picture, causing an avalanche of user generated responses on the internet. In this paper, we have proposed a Black Lives Matter related tweet hate speech dataset TweetBLM. Our dataset comprises 9165 manually annotated tweets that target the Black Lives Matter movement. We annotated the tweets into two classes, i.e., HATE and NONHATE based on their content related to racism erupted from the movement for the black community. In this work, we also generated useful statistical insights on our dataset and performed a systematic analysis of various machine learning models such as Random Forest, CNN, LSTM, BiLSTM, Fasttext, BERTbase, and BERTlarge for the classification task on our dataset. Through our work, we aim at contributing to the substantial efforts of the research community for the identification and mitigation of hate speech on the internet. The dataset is publicly available.
Analysis and Synthesis of Hypo and Hyperarticulated Speech
Jun 07, 2020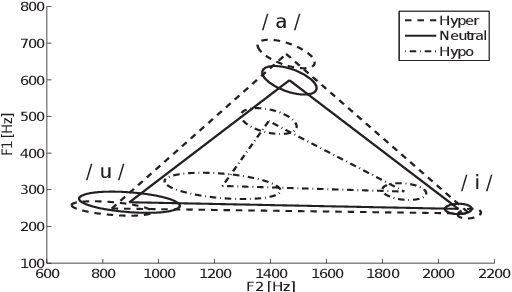

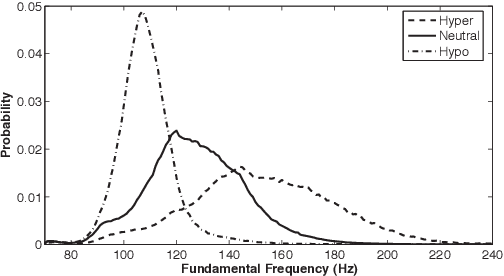
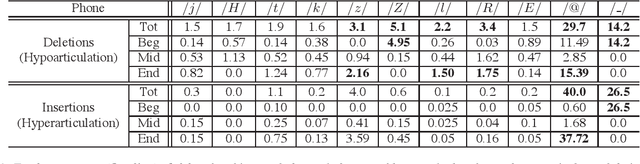
This paper focuses on the analysis and synthesis of hypo and hyperarticulated speech in the framework of HMM-based speech synthesis. First of all, a new French database matching our needs was created, which contains three identical sets, pronounced with three different degrees of articulation: neutral, hypo and hyperarticulated speech. On that basis, acoustic and phonetic analyses were performed. It is shown that the degrees of articulation significantly influence, on one hand, both vocal tract and glottal characteristics, and on the other hand, speech rate, phone durations, phone variations and the presence of glottal stops. Finally, neutral, hypo and hyperarticulated speech are synthesized using HMM-based speech synthesis and both objective and subjective tests aiming at assessing the generated speech quality are performed. These tests show that synthesized hypoarticulated speech seems to be less naturally rendered than neutral and hyperarticulated speech.
QUARC: Quaternion Multi-Modal Fusion Architecture For Hate Speech Classification
Dec 15, 2020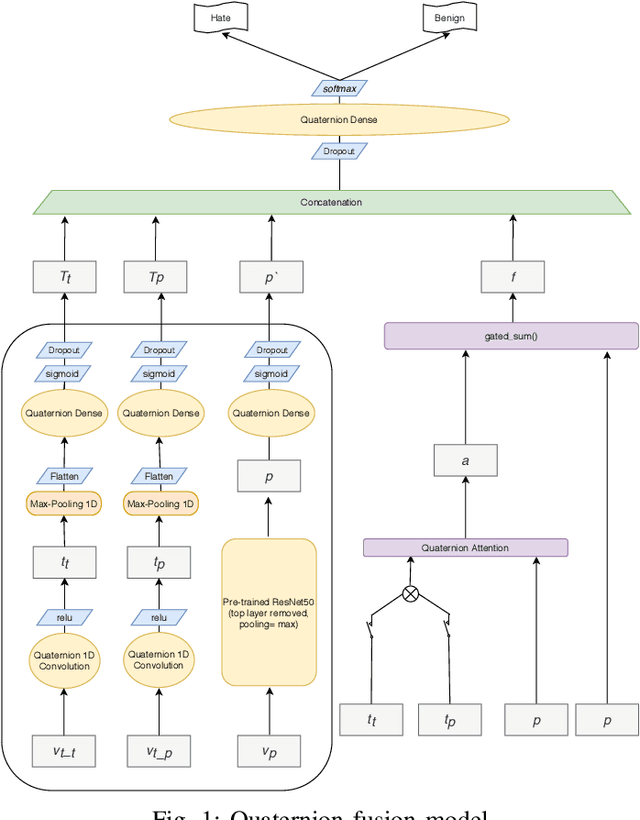

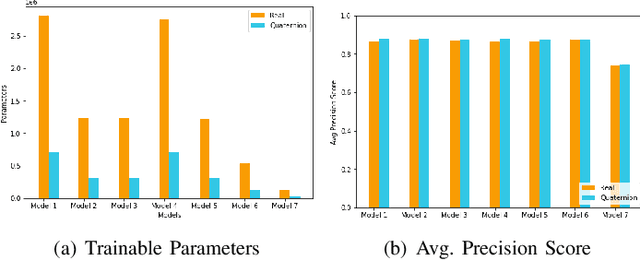
Hate speech, quite common in the age of social media, at times harmless but can also cause mental trauma to someone or even riots in communities. Image of a religious symbol with derogatory comment or video of a man abusing a particular community, all become hate speech with its every modality (such as text, image, and audio) contributing towards it. Models based on a particular modality of hate speech post on social media are not useful, rather, we need models like multi-modal fusion models that consider both image and text while classifying hate speech. Text-image fusion models are heavily parameterized, hence we propose a quaternion neural network-based model having additional fusion components for each pair of modalities. The model is tested on the MMHS150K twitter dataset for hate speech classification. The model shows an almost 75% reduction in parameters and also benefits us in terms of storage space and training time while being at par in terms of performance as compared to its real counterpart.
Zero-Shot Personalized Speech Enhancement through Speaker-Informed Model Selection
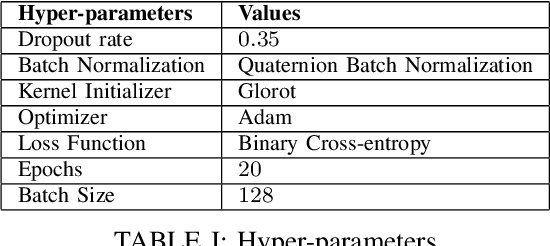
May 08, 2021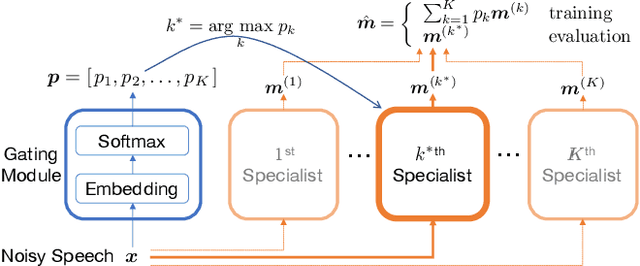
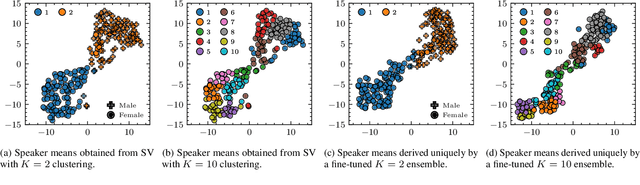
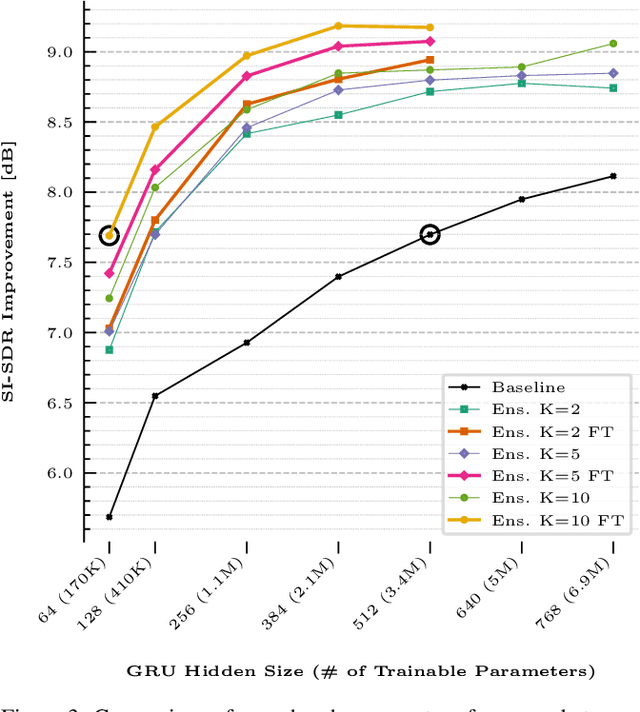
This paper presents a novel zero-shot learning approach towards personalized speech enhancement through the use of a sparsely active ensemble model. Optimizing speech denoising systems towards a particular test-time speaker can improve performance and reduce run-time complexity. However, test-time model adaptation may be challenging if collecting data from the test-time speaker is not possible. To this end, we propose using an ensemble model wherein each specialist module denoises noisy utterances from a distinct partition of training set speakers. The gating module inexpensively estimates test-time speaker characteristics in the form of an embedding vector and selects the most appropriate specialist module for denoising the test signal. Grouping the training set speakers into non-overlapping semantically similar groups is non-trivial and ill-defined. To do this, we first train a Siamese network using noisy speech pairs to maximize or minimize the similarity of its output vectors depending on whether the utterances derive from the same speaker or not. Next, we perform k-means clustering on the latent space formed by the averaged embedding vectors per training set speaker. In this way, we designate speaker groups and train specialist modules optimized around partitions of the complete training set. Our experiments show that ensemble models made up of low-capacity specialists can outperform high-capacity generalist models with greater efficiency and improved adaptation towards unseen test-time speakers.
Diarization of Legal Proceedings. Identifying and Transcribing Judicial Speech from Recorded Court Audio
Apr 03, 2021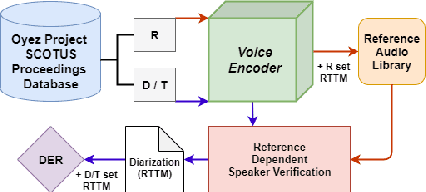

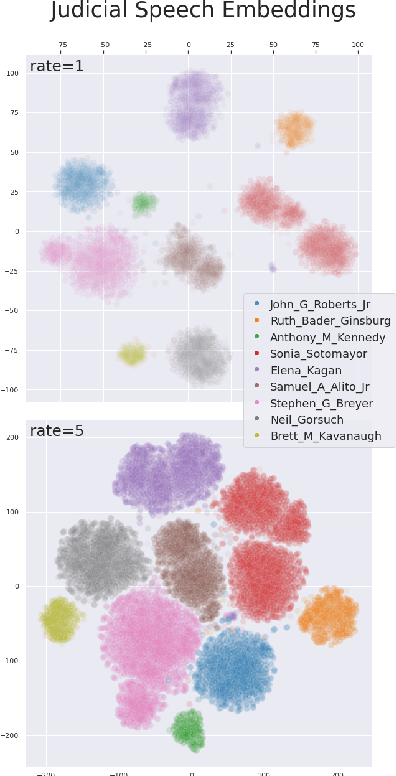
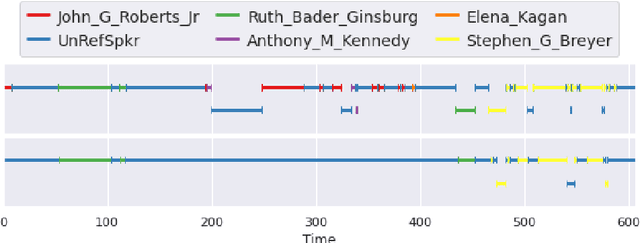
United States Courts make audio recordings of oral arguments available as public record, but these recordings rarely include speaker annotations. This paper addresses the Speech Audio Diarization problem, answering the question of "Who spoke when?" in the domain of judicial oral argument proceedings. We present a workflow for diarizing the speech of judges using audio recordings of oral arguments, a process we call Reference-Dependent Speaker Verification. We utilize a speech embedding network trained with the Generalized End-to-End Loss to encode speech into d-vectors and a pre-defined reference audio library based on annotated data. We find that by encoding reference audio for speakers and full arguments and computing similarity scores we achieve a 13.8% Diarization Error Rate for speakers covered by the reference audio library on a held-out test set. We evaluate our method on the Supreme Court of the United States oral arguments, accessed through the Oyez Project, and outline future work for diarizing legal proceedings. A code repository for this research is available at github.com/JeffT13/rd-diarization
Into-TTS : Intonation Template based Prosody Control System
Apr 04, 2022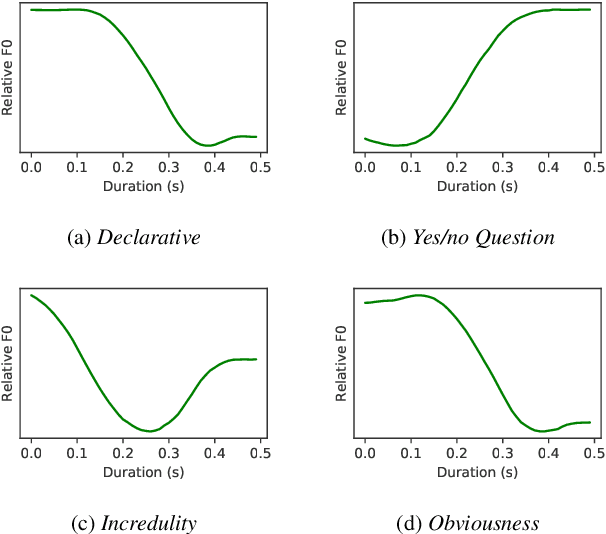

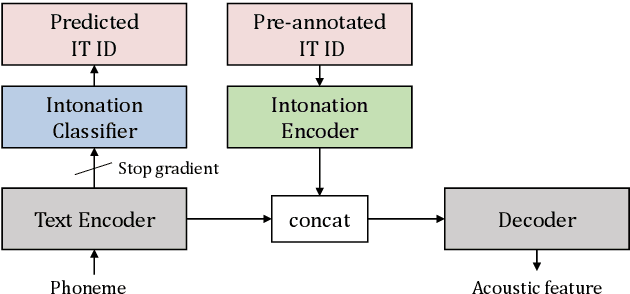
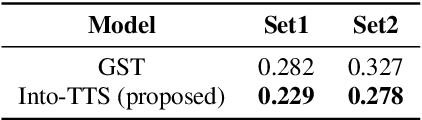
Intonations take an important role in delivering the intention of the speaker. However, current end-to-end TTS systems often fail to model proper intonations. To alleviate this problem, we propose a novel, intuitive method to synthesize speech in different intonations using predefined intonation templates. Prior to the acoustic model training, speech data are automatically grouped into intonation templates by k-means clustering, according to their sentence-final F0 contour. Two proposed modules are added to the end-to-end TTS framework: intonation classifier and intonation encoder. The intonation classifier recommends a suitable intonation template to the given text. The intonation encoder, attached to the text encoder output, synthesizes speech abiding the requested intonation template. Main contributions of our paper are: (a) an easy-to-use intonation control system covering a wide range of users; (b) better performance in wrapping speech in a requested intonation with improved pitch distance and MOS; and (c) feasibility to future integration between TTS and NLP, TTS being able to utilize contextual information. Audio samples are available at https://srtts.github.io/IntoTTS.