 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
LiRA: Learning Visual Speech Representations from Audio through Self-supervision
Jun 16, 2021
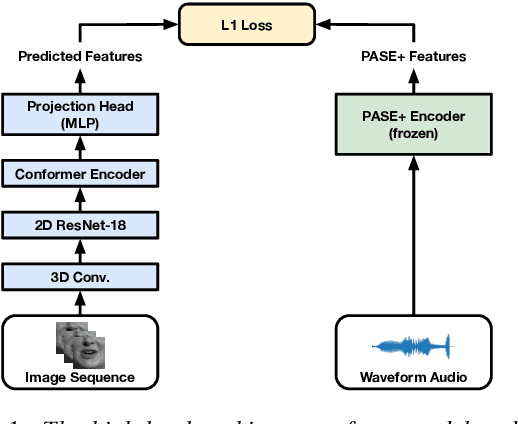
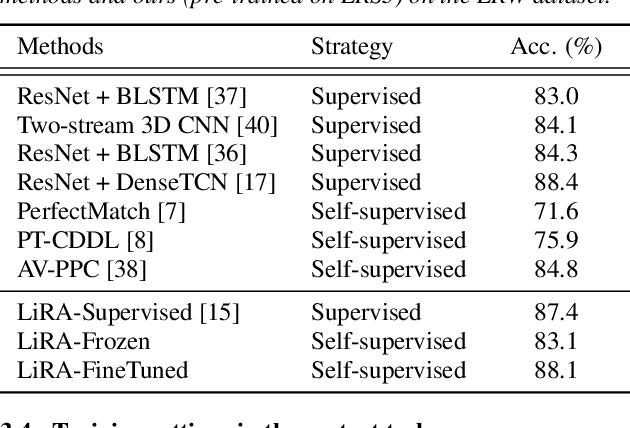
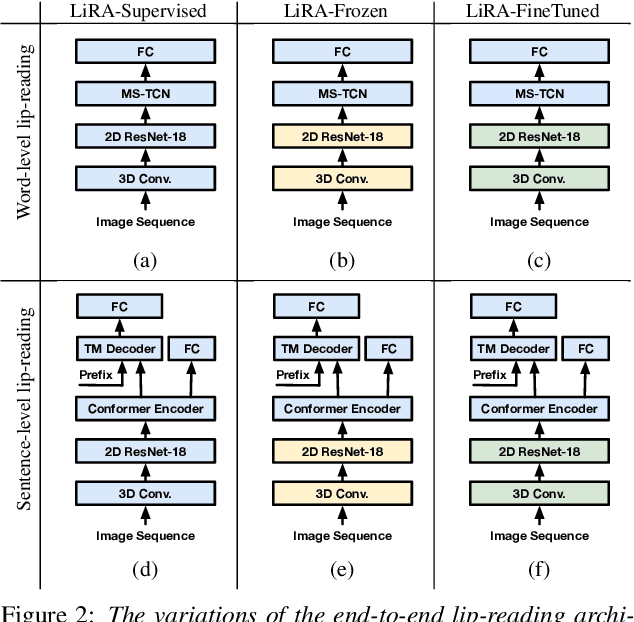
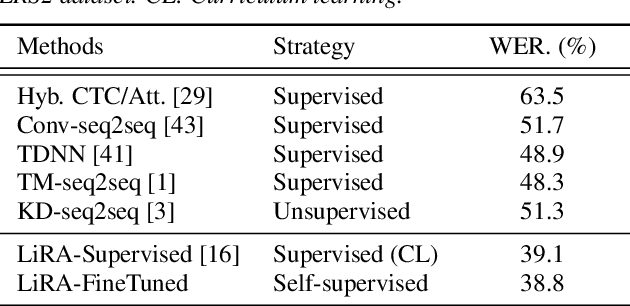
The large amount of audiovisual content being shared online today has drawn substantial attention to the prospect of audiovisual self-supervised learning. Recent works have focused on each of these modalities separately, while others have attempted to model both simultaneously in a cross-modal fashion. However, comparatively little attention has been given to leveraging one modality as a training objective to learn from the other. In this work, we propose Learning visual speech Representations from Audio via self-supervision (LiRA). Specifically, we train a ResNet+Conformer model to predict acoustic features from unlabelled visual speech. We find that this pre-trained model can be leveraged towards word-level and sentence-level lip-reading through feature extraction and fine-tuning experiments. We show that our approach significantly outperforms other self-supervised methods on the Lip Reading in the Wild (LRW) dataset and achieves state-of-the-art performance on Lip Reading Sentences 2 (LRS2) using only a fraction of the total labelled data.
The Accented English Speech Recognition Challenge 2020: Open Datasets, Tracks, Baselines, Results and Methods
Feb 20, 2021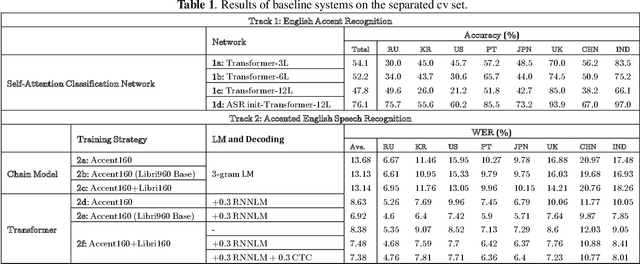
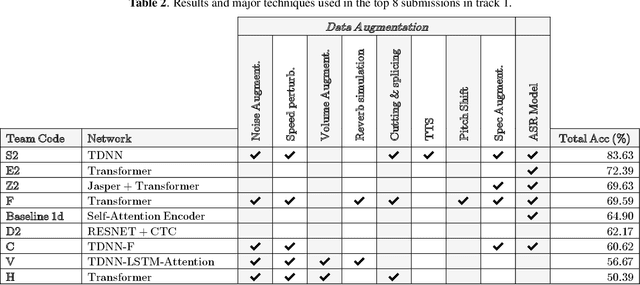
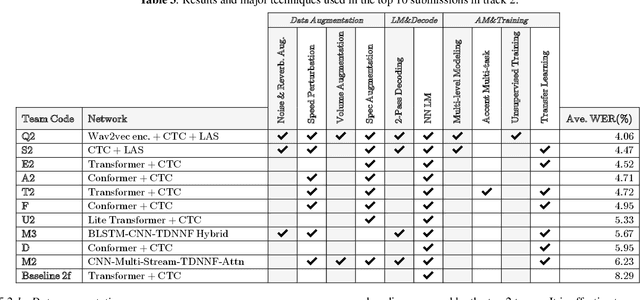
The variety of accents has posed a big challenge to speech recognition. The Accented English Speech Recognition Challenge (AESRC2020) is designed for providing a common testbed and promoting accent-related research. Two tracks are set in the challenge -- English accent recognition (track 1) and accented English speech recognition (track 2). A set of 160 hours of accented English speech collected from 8 countries is released with labels as the training set. Another 20 hours of speech without labels is later released as the test set, including two unseen accents from another two countries used to test the model generalization ability in track 2. We also provide baseline systems for the participants. This paper first reviews the released dataset, track setups, baselines and then summarizes the challenge results and major techniques used in the submissions.
Dimensions of Interpersonal Dynamics in Text: Group Membership and Fine-grained Interpersonal Emotion
Sep 14, 2022
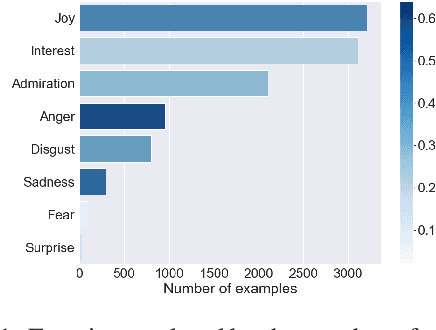
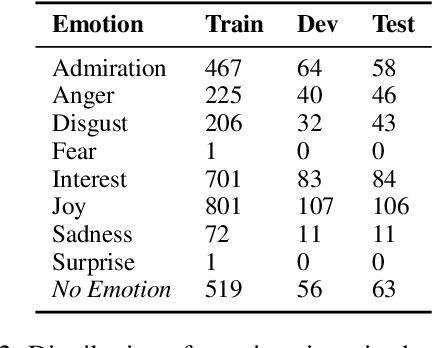
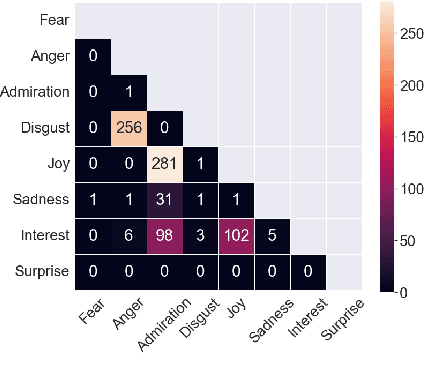
The ability of language to perpetuate inequality is most evident when individuals refer to, or talk about, other individuals in their utterances. While current studies of bias in NLP rely mainly on identifying hate speech or bias towards a specific group, we believe we can reach a more subtle and nuanced understanding of the interaction between bias and language use by modeling the speaker, the text, and the target in the text. In this paper, we introduce a dataset of 3033 English tweets by US Congress members annotated for interpersonal emotion, and `found supervision' for interpersonal group membership labels. We find that negative emotions such as anger and disgust are used predominantly in out-group situations, and directed predominantly at leaders of opposite parties. While humans can perform better than chance at identifying interpersonal group membership given an utterance, neural models perform much better; furthermore, a shared encoding between interpersonal group membership and interpersonal perceived emotion enabled some performance gains in the latter. This work aims to re-align the study of bias in NLP away from specific instances of bias to one which encapsulates the relationship between speaker, text, target and social dynamics. Data and code for this paper are available at https://github.com/venkatasg/Interpersonal-Dynamics
Blackbox Untargeted Adversarial Testing of Automatic Speech Recognition Systems
Dec 03, 2021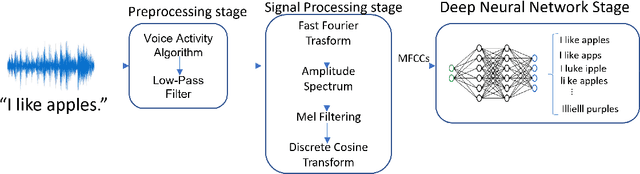
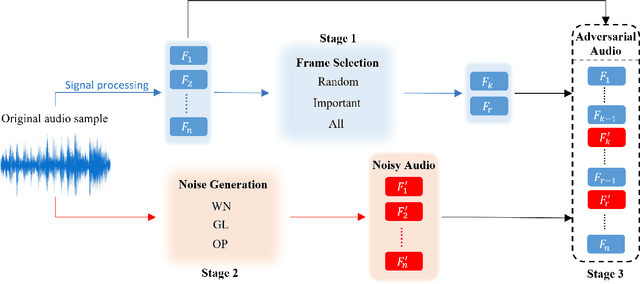
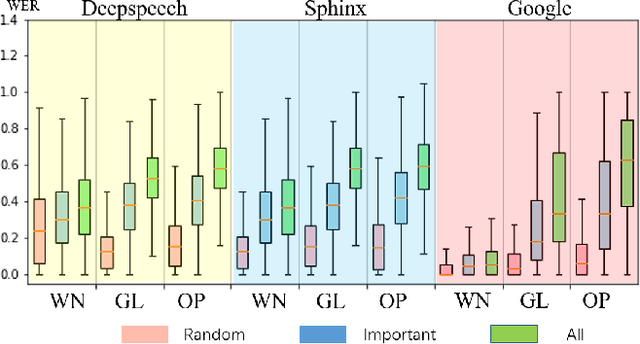
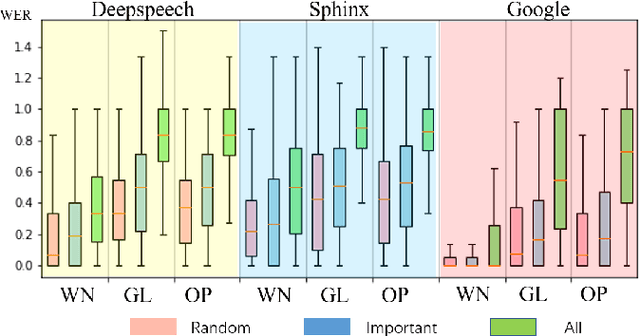
Automatic speech recognition (ASR) systems are prevalent, particularly in applications for voice navigation and voice control of domestic appliances. The computational core of ASRs are deep neural networks (DNNs) that have been shown to be susceptible to adversarial perturbations; easily misused by attackers to generate malicious outputs. To help test the correctness of ASRS, we propose techniques that automatically generate blackbox (agnostic to the DNN), untargeted adversarial attacks that are portable across ASRs. Much of the existing work on adversarial ASR testing focuses on targeted attacks, i.e generating audio samples given an output text. Targeted techniques are not portable, customised to the structure of DNNs (whitebox) within a specific ASR. In contrast, our method attacks the signal processing stage of the ASR pipeline that is shared across most ASRs. Additionally, we ensure the generated adversarial audio samples have no human audible difference by manipulating the acoustic signal using a psychoacoustic model that maintains the signal below the thresholds of human perception. We evaluate portability and effectiveness of our techniques using three popular ASRs and three input audio datasets using the metrics - WER of output text, Similarity to original audio and attack Success Rate on different ASRs. We found our testing techniques were portable across ASRs, with the adversarial audio samples producing high Success Rates, WERs and Similarities to the original audio.
Design of a novel Korean learning application for efficient pronunciation correction
May 04, 2022
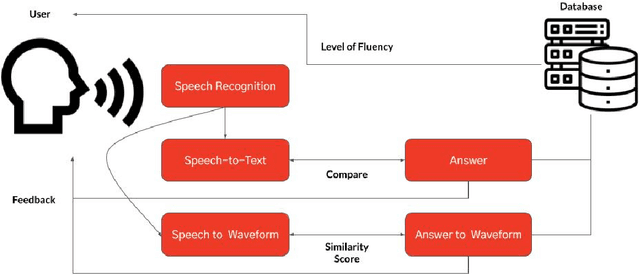
The Korean wave, which denotes the global popularity of South Korea's cultural economy, contributes to the increasing demand for the Korean language. However, as there does not exist any application for foreigners to learn Korean, this paper suggested a design of a novel Korean learning application. Speech recognition, speech-to-text, and speech-to-waveform are the three key systems in the proposed system. The Google API and the librosa library will transform the user's voice into a sentence and MFCC. The software will then display the user's phrase and answer, with mispronounced elements highlighted in red, allowing users to more easily recognize the incorrect parts of their pronunciation. Furthermore, the Siamese network might utilize those translated spectrograms to provide a similarity score, which could subsequently be used to offer feedback to the user. Despite the fact that we were unable to collect sufficient foreigner data for this research, it is notable that we presented a novel Korean pronunciation correction method for foreigners.
Non-autoregressive End-to-end Speech Translation with Parallel Autoregressive Rescoring
Sep 09, 2021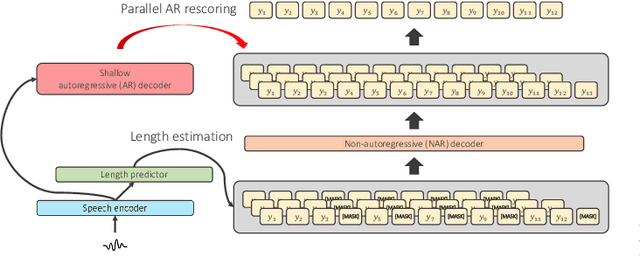
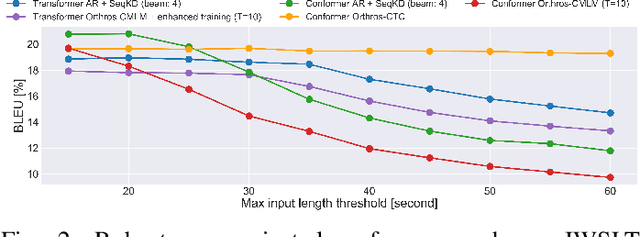
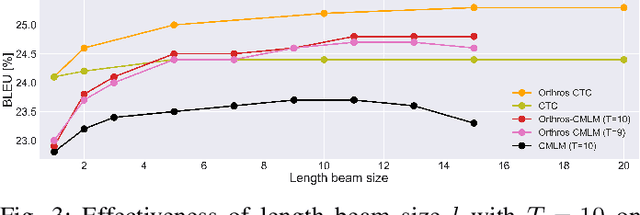
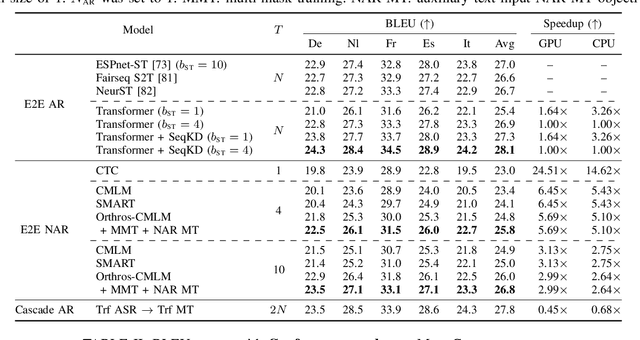
This article describes an efficient end-to-end speech translation (E2E-ST) framework based on non-autoregressive (NAR) models. End-to-end speech translation models have several advantages over traditional cascade systems such as inference latency reduction. However, conventional AR decoding methods are not fast enough because each token is generated incrementally. NAR models, however, can accelerate the decoding speed by generating multiple tokens in parallel on the basis of the token-wise conditional independence assumption. We propose a unified NAR E2E-ST framework called Orthros, which has an NAR decoder and an auxiliary shallow AR decoder on top of the shared encoder. The auxiliary shallow AR decoder selects the best hypothesis by rescoring multiple candidates generated from the NAR decoder in parallel (parallel AR rescoring). We adopt conditional masked language model (CMLM) and a connectionist temporal classification (CTC)-based model as NAR decoders for Orthros, referred to as Orthros-CMLM and Orthros-CTC, respectively. We also propose two training methods to enhance the CMLM decoder. Experimental evaluations on three benchmark datasets with six language directions demonstrated that Orthros achieved large improvements in translation quality with a very small overhead compared with the baseline NAR model. Moreover, the Conformer encoder architecture enabled large quality improvements, especially for CTC-based models. Orthros-CTC with the Conformer encoder increased decoding speed by 3.63x on CPU with translation quality comparable to that of an AR model.
Thai Wav2Vec2.0 with CommonVoice V8
Aug 09, 2022

Recently, Automatic Speech Recognition (ASR), a system that converts audio into text, has caught a lot of attention in the machine learning community. Thus, a lot of publicly available models were released in HuggingFace. However, most of these ASR models are available in English; only a minority of the models are available in Thai. Additionally, most of the Thai ASR models are closed-sourced, and the performance of existing open-sourced models lacks robustness. To address this problem, we train a new ASR model on a pre-trained XLSR-Wav2Vec model with the Thai CommonVoice corpus V8 and train a trigram language model to boost the performance of our ASR model. We hope that our models will be beneficial to individuals and the ASR community in Thailand.
MLS: A Large-Scale Multilingual Dataset for Speech Research
Dec 19, 2020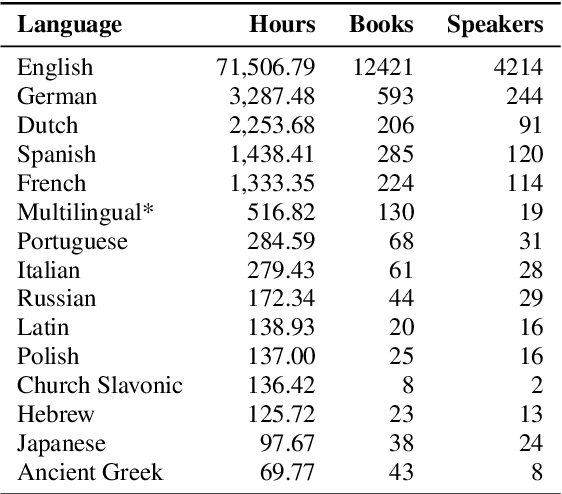
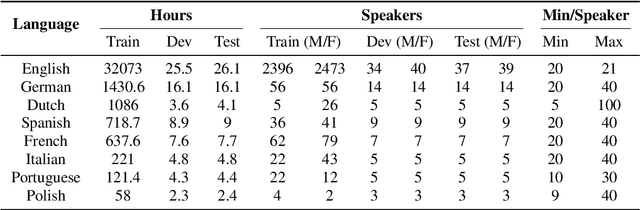
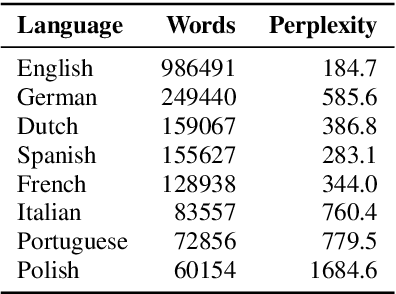
This paper introduces Multilingual LibriSpeech (MLS) dataset, a large multilingual corpus suitable for speech research. The dataset is derived from read audiobooks from LibriVox and consists of 8 languages, including about 44.5K hours of English and a total of about 6K hours for other languages. Additionally, we provide Language Models (LM) and baseline Automatic Speech Recognition (ASR) models and for all the languages in our dataset. We believe such a large transcribed dataset will open new avenues in ASR and Text-To-Speech (TTS) research. The dataset will be made freely available for anyone at http://www.openslr.org.
Speech Quality Assessment in Crowdsourcing: Comparison Category Rating Method
Apr 09, 2021
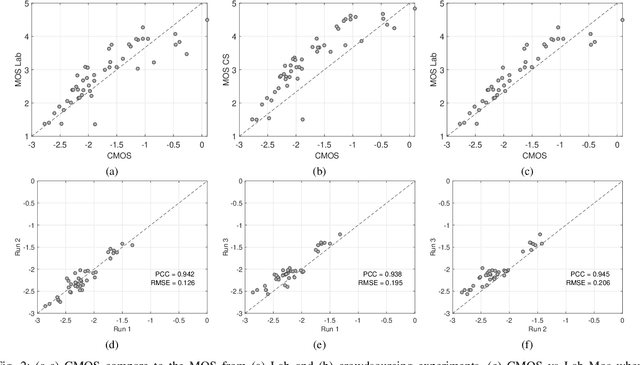
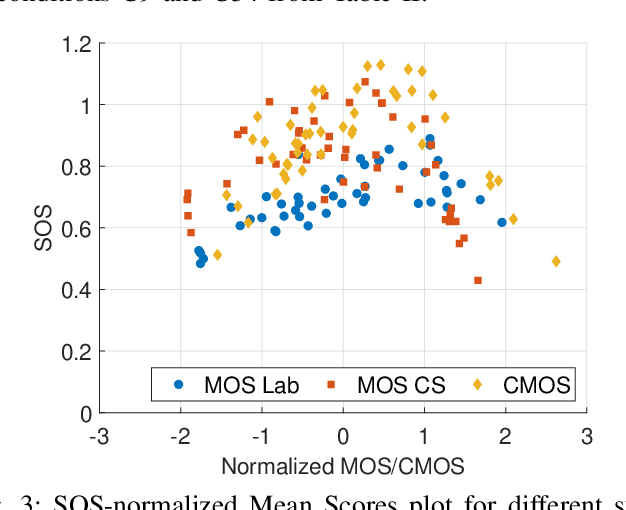

Traditionally, Quality of Experience (QoE) for a communication system is evaluated through a subjective test. The most common test method for speech QoE is the Absolute Category Rating (ACR), in which participants listen to a set of stimuli, processed by the underlying test conditions, and rate their perceived quality for each stimulus on a specific scale. The Comparison Category Rating (CCR) is another standard approach in which participants listen to both reference and processed stimuli and rate their quality compared to the other one. The CCR method is particularly suitable for systems that improve the quality of input speech. This paper evaluates an adaptation of the CCR test procedure for assessing speech quality in the crowdsourcing set-up. The CCR method was introduced in the ITU-T Rec. P.800 for laboratory-based experiments. We adapted the test for the crowdsourcing approach following the guidelines from ITU-T Rec. P.800 and P.808. We show that the results of the CCR procedure via crowdsourcing are highly reproducible. We also compared the CCR test results with widely used ACR test procedures obtained in the laboratory and crowdsourcing. Our results show that the CCR procedure in crowdsourcing is a reliable and valid test method.
Speech-Image Semantic Alignment Does Not Depend on Any Prior Classification Tasks
Oct 29, 2020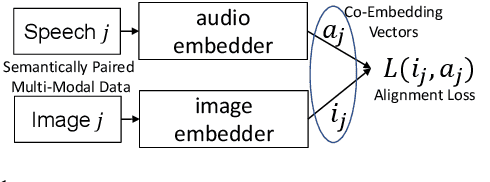
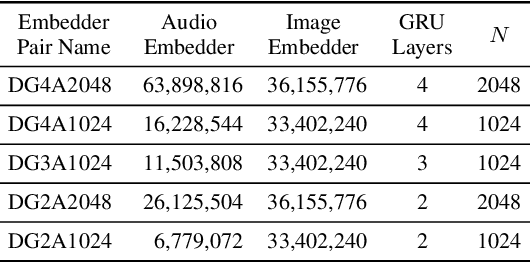
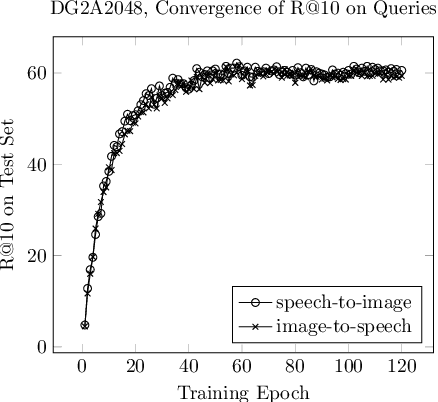
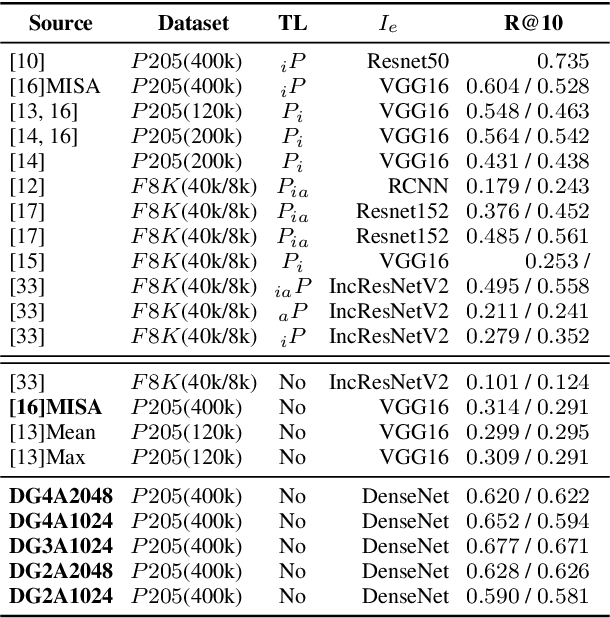
Semantically-aligned $(speech, image)$ datasets can be used to explore "visually-grounded speech". In a majority of existing investigations, features of an image signal are extracted using neural networks "pre-trained" on other tasks (e.g., classification on ImageNet). In still others, pre-trained networks are used to extract audio features prior to semantic embedding. Without "transfer learning" through pre-trained initialization or pre-trained feature extraction, previous results have tended to show low rates of recall in $speech \rightarrow image$ and $image \rightarrow speech$ queries. Choosing appropriate neural architectures for encoders in the speech and image branches and using large datasets, one can obtain competitive recall rates without any reliance on any pre-trained initialization or feature extraction: $(speech,image)$ semantic alignment and $speech \rightarrow image$ and $image \rightarrow speech$ retrieval are canonical tasks worthy of independent investigation of their own and allow one to explore other questions---e.g., the size of the audio embedder can be reduced significantly with little loss of recall rates in $speech \rightarrow image$ and $image \rightarrow speech$ queries.