 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
FV2ES: A Fully End2End Multimodal System for Fast Yet Effective Video Emotion Recognition Inference
Sep 21, 2022
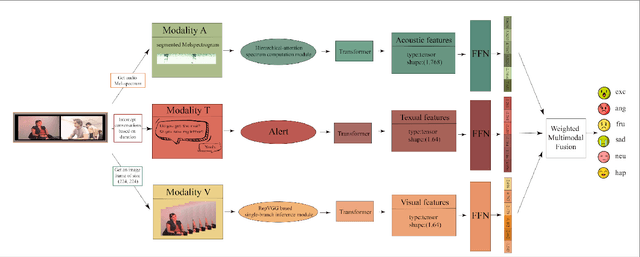
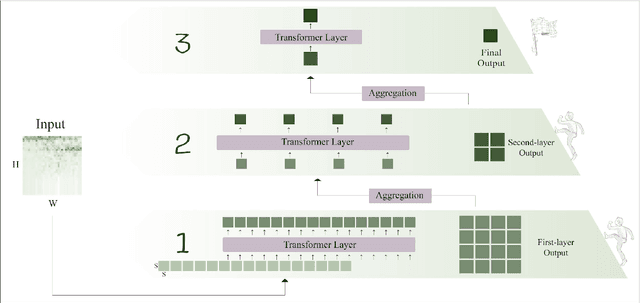
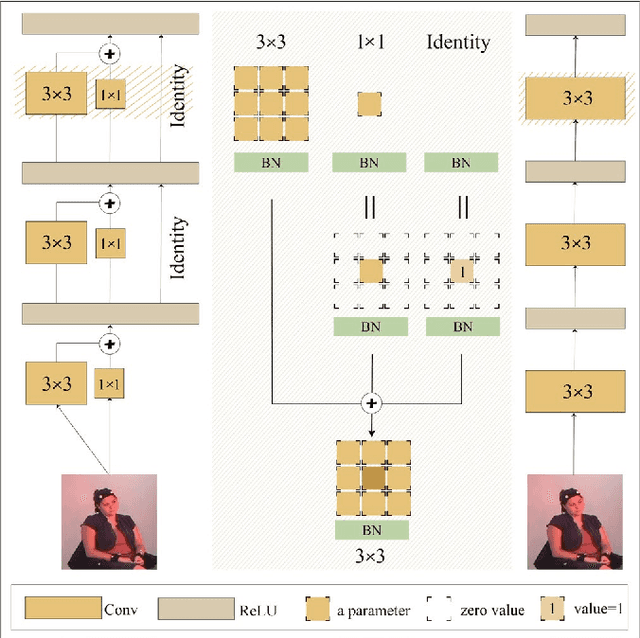
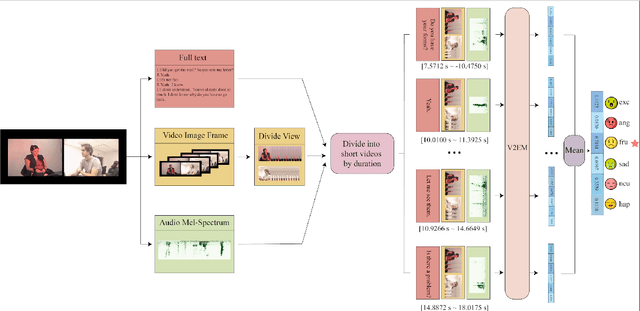
In the latest social networks, more and more people prefer to express their emotions in videos through text, speech, and rich facial expressions. Multimodal video emotion analysis techniques can help understand users' inner world automatically based on human expressions and gestures in images, tones in voices, and recognized natural language. However, in the existing research, the acoustic modality has long been in a marginal position as compared to visual and textual modalities. That is, it tends to be more difficult to improve the contribution of the acoustic modality for the whole multimodal emotion recognition task. Besides, although better performance can be obtained by introducing common deep learning methods, the complex structures of these training models always result in low inference efficiency, especially when exposed to high-resolution and long-length videos. Moreover, the lack of a fully end-to-end multimodal video emotion recognition system hinders its application. In this paper, we designed a fully multimodal video-to-emotion system (named FV2ES) for fast yet effective recognition inference, whose benefits are threefold: (1) The adoption of the hierarchical attention method upon the sound spectra breaks through the limited contribution of the acoustic modality and outperforms the existing models' performance on both IEMOCAP and CMU-MOSEI datasets; (2) the introduction of the idea of multi-scale for visual extraction while single-branch for inference brings higher efficiency and maintains the prediction accuracy at the same time; (3) the further integration of data pre-processing into the aligned multimodal learning model allows the significant reduction of computational costs and storage space.
Attention based end to end Speech Recognition for Voice Search in Hindi and English
Nov 15, 2021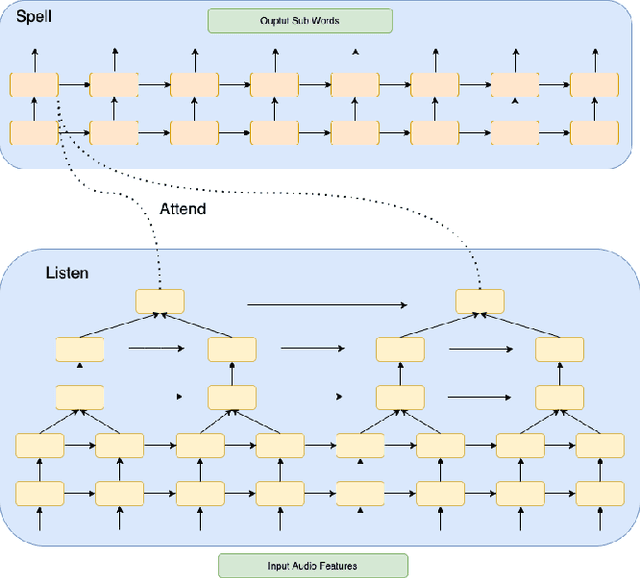
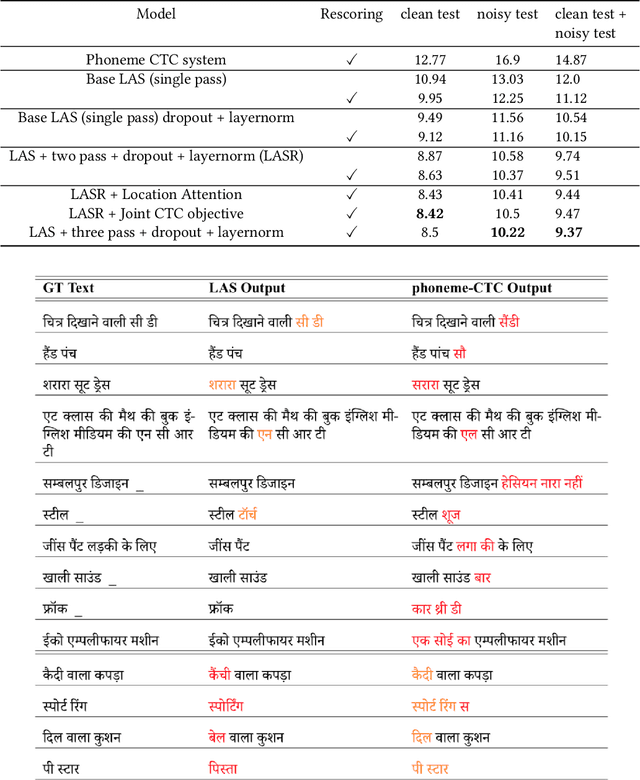
We describe here our work with automatic speech recognition (ASR) in the context of voice search functionality on the Flipkart e-Commerce platform. Starting with the deep learning architecture of Listen-Attend-Spell (LAS), we build upon and expand the model design and attention mechanisms to incorporate innovative approaches including multi-objective training, multi-pass training, and external rescoring using language models and phoneme based losses. We report a relative WER improvement of 15.7% on top of state-of-the-art LAS models using these modifications. Overall, we report an improvement of 36.9% over the phoneme-CTC system. The paper also provides an overview of different components that can be tuned in a LAS-based system.
MLS: A Large-Scale Multilingual Dataset for Speech Research
Dec 19, 2020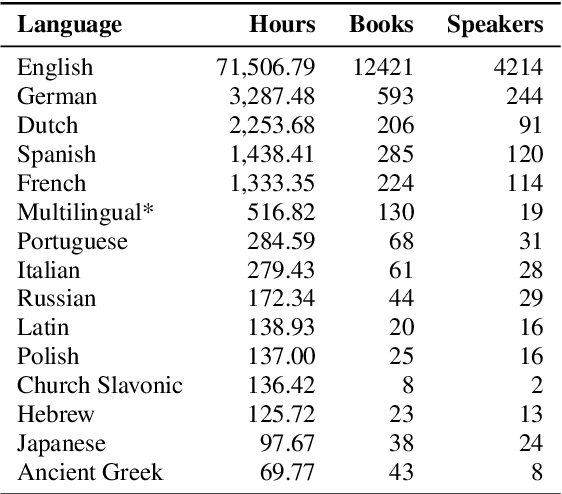
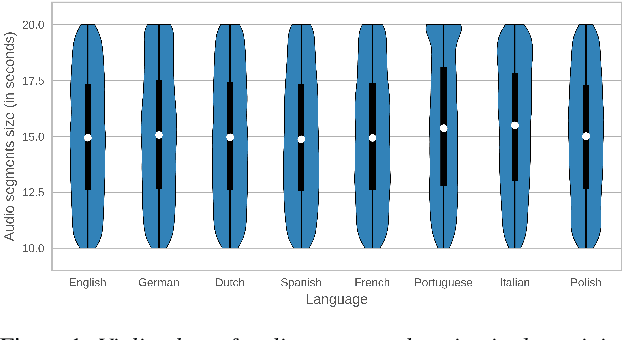
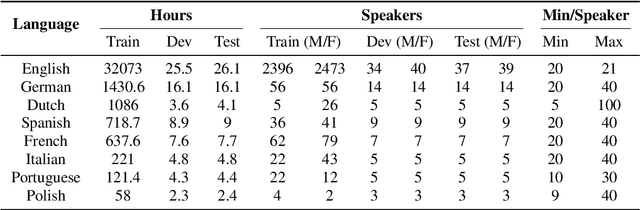
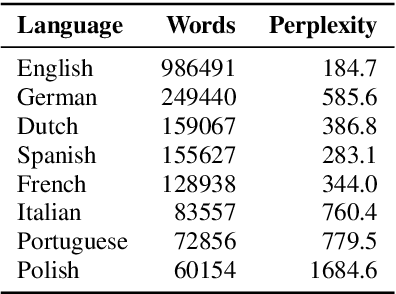
This paper introduces Multilingual LibriSpeech (MLS) dataset, a large multilingual corpus suitable for speech research. The dataset is derived from read audiobooks from LibriVox and consists of 8 languages, including about 44.5K hours of English and a total of about 6K hours for other languages. Additionally, we provide Language Models (LM) and baseline Automatic Speech Recognition (ASR) models and for all the languages in our dataset. We believe such a large transcribed dataset will open new avenues in ASR and Text-To-Speech (TTS) research. The dataset will be made freely available for anyone at http://www.openslr.org.
Exploring Timbre Disentanglement in Non-Autoregressive Cross-Lingual Text-to-Speech
Oct 14, 2021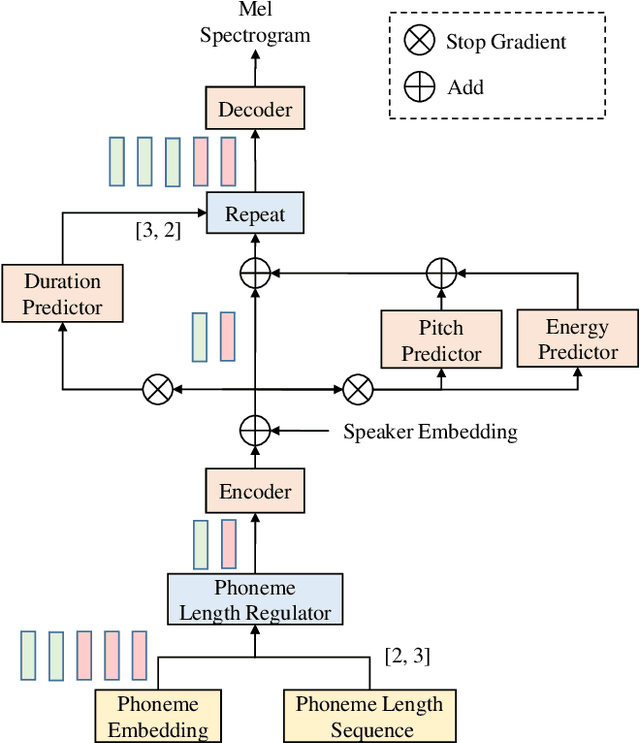
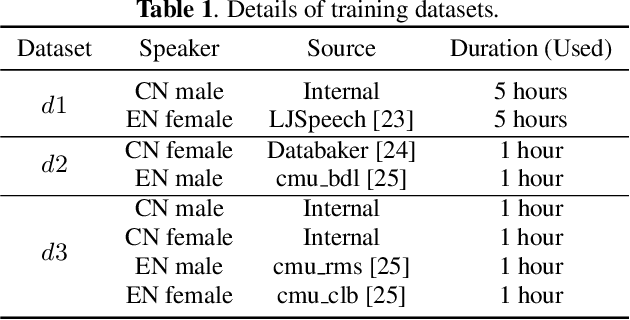

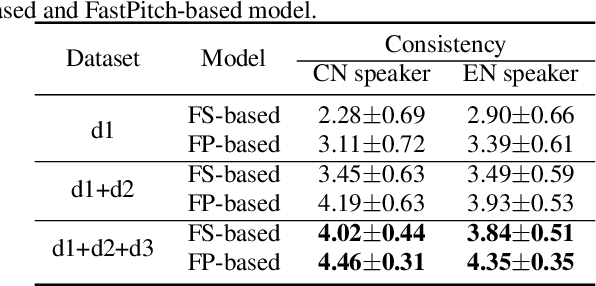
In this paper, we present a FastPitch-based non-autoregressive cross-lingual Text-to-Speech (TTS) model built with language independent input representation and monolingual force aligners. We propose a phoneme length regulator that solves the length mismatch problem between language-independent phonemes and monolingual alignment results. Our experiments show that (1) an increasing number of training speakers encourages non-autoregressive cross-lingual TTS model to disentangle speaker and language representations, and (2) variance adaptors of FastPitch model can help disentangle speaker identity from learned representations in cross-lingual TTS. The subjective evaluation shows that our proposed model is able to achieve decent speaker consistency and similarity. We further improve the naturalness of Mandarin-dominated mixed-lingual utterances by utilizing the controllability of our proposed model.
An Optimized Signal Processing Pipeline for Syllable Detection and Speech Rate Estimation
Mar 07, 2021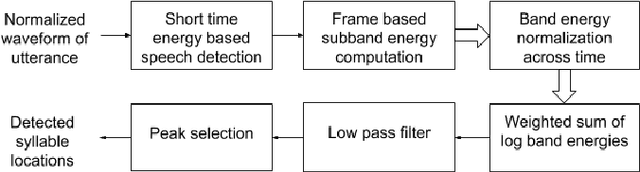
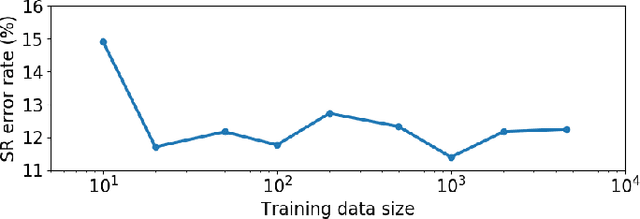
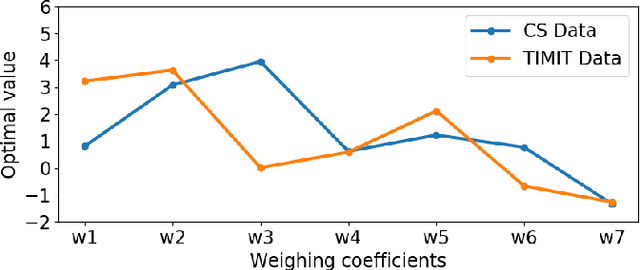
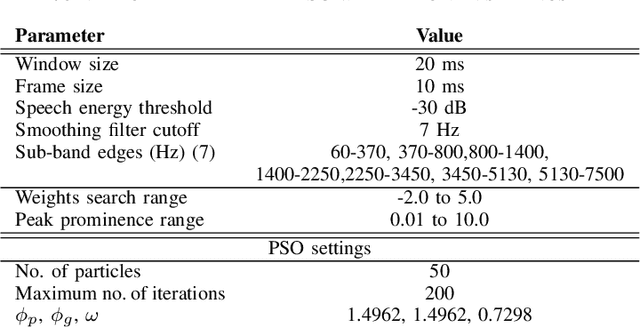
Syllable detection is an important speech analysis task with applications in speech rate estimation, word segmentation, and automatic prosody detection. Based on the well understood acoustic correlates of speech articulation, it has been realized by local peak picking on a frequency-weighted energy contour that represents vowel sonority. While several of the analysis parameters are set based on known speech signal properties, the selection of the frequency-weighting coefficients and peak-picking threshold typically involves heuristics, raising the possibility of data-based optimisation. In this work, we consider the optimization of the parameters based on the direct minimization of naturally arising task-specific objective functions. The resulting non-convex cost function is minimized using a population-based search algorithm to achieve a performance that exceeds previously published performance results on the same corpus using a relatively low amount of labeled data. Further, the optimisation of system parameters on a different corpus is shown to result in an explainable change in the optimal values.
Contextual Lexicon-Based Approach for Hate Speech and Offensive Language Detection
May 09, 2021
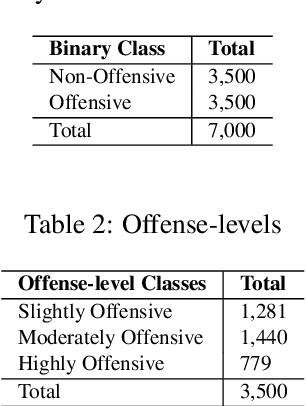
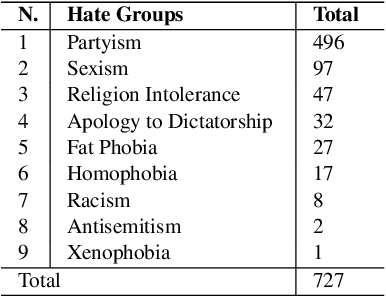
This paper provides a new approach for offensive language and hate speech detection on social media. Our approach incorporates an offensive lexicon composed of implicit and explicit offensive and swearing expressions annotated with binary classes: context-dependent and context-independent offensive. Due to the severity of the hate speech and offensive comments in Brazil, and the lack of research in Portuguese, Brazilian Portuguese is the language used to validate the proposed method. Nevertheless, our proposal may be applied to any other language or domain. Based on the obtained results, the proposed approach showed high-performance overcoming the current baselines for European and Brazilian Portuguese.
Speech-Image Semantic Alignment Does Not Depend on Any Prior Classification Tasks
Oct 29, 2020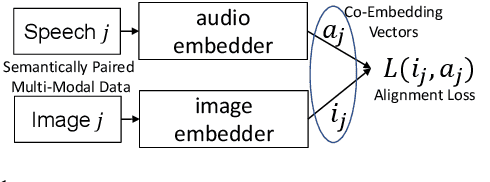
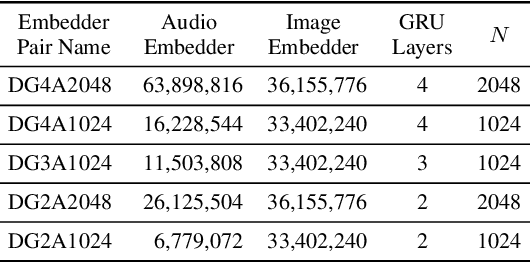
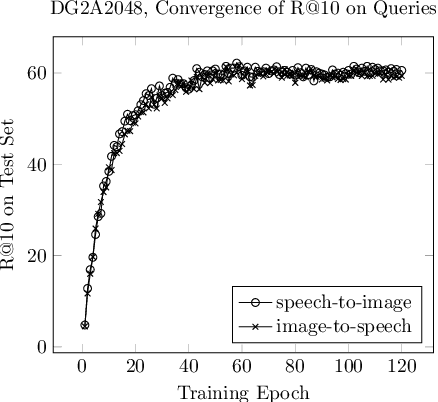
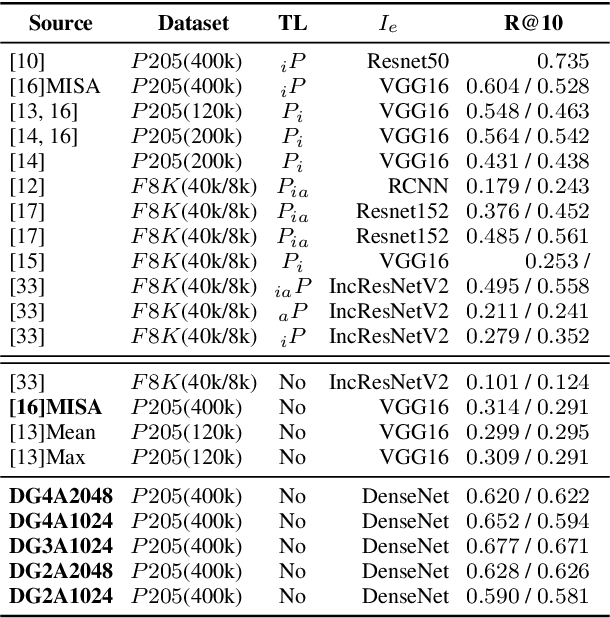
Semantically-aligned $(speech, image)$ datasets can be used to explore "visually-grounded speech". In a majority of existing investigations, features of an image signal are extracted using neural networks "pre-trained" on other tasks (e.g., classification on ImageNet). In still others, pre-trained networks are used to extract audio features prior to semantic embedding. Without "transfer learning" through pre-trained initialization or pre-trained feature extraction, previous results have tended to show low rates of recall in $speech \rightarrow image$ and $image \rightarrow speech$ queries. Choosing appropriate neural architectures for encoders in the speech and image branches and using large datasets, one can obtain competitive recall rates without any reliance on any pre-trained initialization or feature extraction: $(speech,image)$ semantic alignment and $speech \rightarrow image$ and $image \rightarrow speech$ retrieval are canonical tasks worthy of independent investigation of their own and allow one to explore other questions---e.g., the size of the audio embedder can be reduced significantly with little loss of recall rates in $speech \rightarrow image$ and $image \rightarrow speech$ queries.
BART based semantic correction for Mandarin automatic speech recognition system
Mar 26, 2021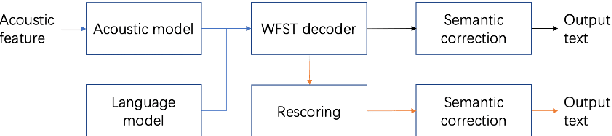
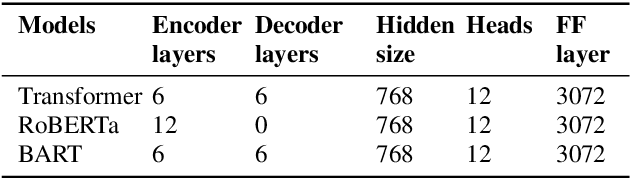
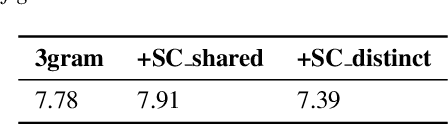

Although automatic speech recognition (ASR) systems achieved significantly improvements in recent years, spoken language recognition error occurs which can be easily spotted by human beings. Various language modeling techniques have been developed on post recognition tasks like semantic correction. In this paper, we propose a Transformer based semantic correction method with pretrained BART initialization, Experiments on 10000 hours Mandarin speech dataset show that character error rate (CER) can be effectively reduced by 21.7% relatively compared to our baseline ASR system. Expert evaluation demonstrates that actual improvement of our model surpasses what CER indicates.
Supervised and Self-supervised Pretraining Based COVID-19 Detection Using Acoustic Breathing/Cough/Speech Signals
Jan 22, 2022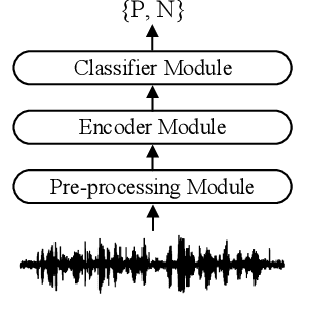
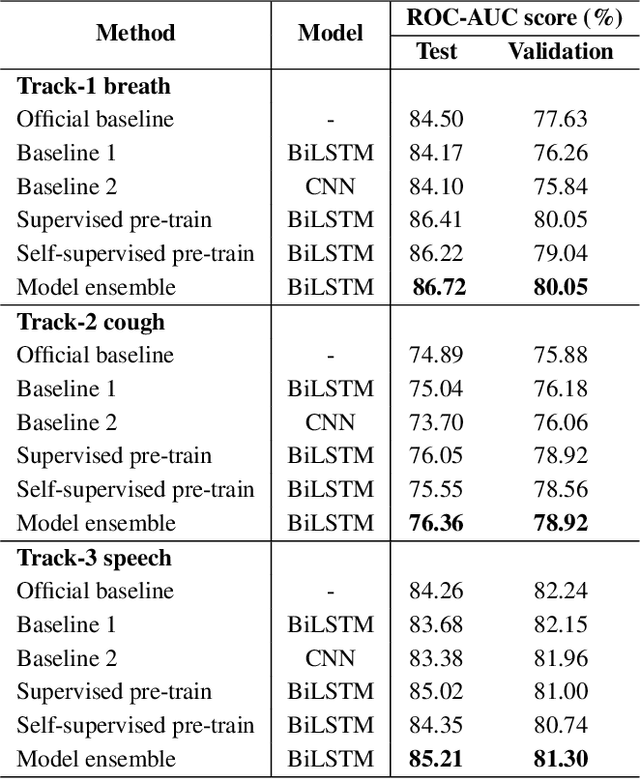
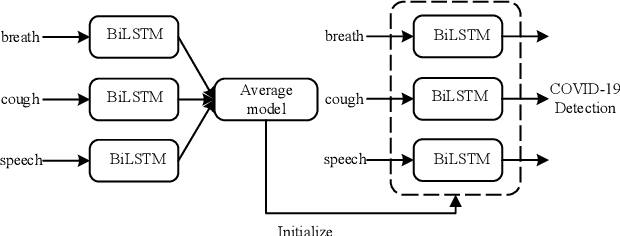
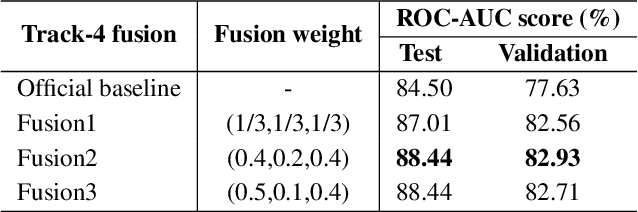
In this work, we propose a bi-directional long short-term memory (BiLSTM) network based COVID-19 detection method using breath/speech/cough signals. By using the acoustic signals to train the network, respectively, we can build individual models for three tasks, whose parameters are averaged to obtain an average model, which is then used as the initialization for the BiLSTM model training of each task. This initialization method can significantly improve the performance on the three tasks, which surpasses the official baseline results. Besides, we also utilize a public pre-trained model wav2vec2.0 and pre-train it using the official DiCOVA datasets. This wav2vec2.0 model is utilized to extract high-level features of the sound as the model input to replace conventional mel-frequency cepstral coefficients (MFCC) features. Experimental results reveal that using high-level features together with MFCC features can improve the performance. To further improve the performance, we also deploy some preprocessing techniques like silent segment removal, amplitude normalization and time-frequency mask. The proposed detection model is evaluated on the DiCOVA dataset and results show that our method achieves an area under curve (AUC) score of 88.44% on blind test in the fusion track.
End-to-end Spoken Conversational Question Answering: Task, Dataset and Model
Apr 29, 2022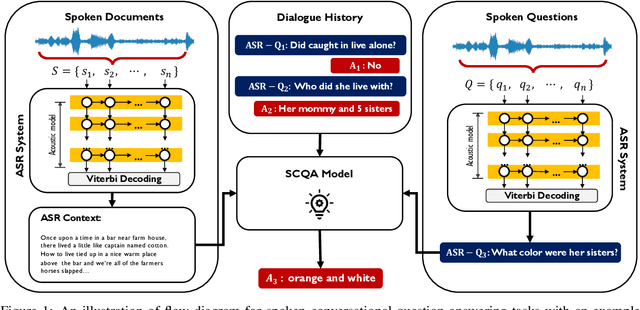

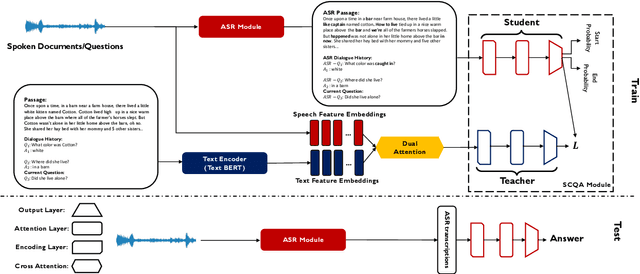

In spoken question answering, the systems are designed to answer questions from contiguous text spans within the related speech transcripts. However, the most natural way that human seek or test their knowledge is via human conversations. Therefore, we propose a new Spoken Conversational Question Answering task (SCQA), aiming at enabling the systems to model complex dialogue flows given the speech documents. In this task, our main objective is to build the system to deal with conversational questions based on the audio recordings, and to explore the plausibility of providing more cues from different modalities with systems in information gathering. To this end, instead of directly adopting automatically generated speech transcripts with highly noisy data, we propose a novel unified data distillation approach, DDNet, which effectively ingests cross-modal information to achieve fine-grained representations of the speech and language modalities. Moreover, we propose a simple and novel mechanism, termed Dual Attention, by encouraging better alignments between audio and text to ease the process of knowledge transfer. To evaluate the capacity of SCQA systems in a dialogue-style interaction, we assemble a Spoken Conversational Question Answering (Spoken-CoQA) dataset with more than 40k question-answer pairs from 4k conversations. The performance of the existing state-of-the-art methods significantly degrade on our dataset, hence demonstrating the necessity of cross-modal information integration. Our experimental results demonstrate that our proposed method achieves superior performance in spoken conversational question answering tasks.