 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
English Accent Accuracy Analysis in a State-of-the-Art Automatic Speech Recognition System
May 09, 2021
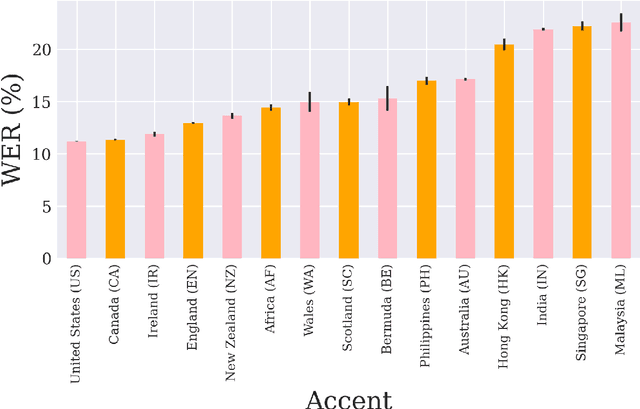

Nowadays, research in speech technologies has gotten a lot out thanks to recently created public domain corpora that contain thousands of recording hours. These large amounts of data are very helpful for training the new complex models based on deep learning technologies. However, the lack of dialectal diversity in a corpus is known to cause performance biases in speech systems, mainly for underrepresented dialects. In this work, we propose to evaluate a state-of-the-art automatic speech recognition (ASR) deep learning-based model, using unseen data from a corpus with a wide variety of labeled English accents from different countries around the world. The model has been trained with 44.5K hours of English speech from an open access corpus called Multilingual LibriSpeech, showing remarkable results in popular benchmarks. We test the accuracy of such ASR against samples extracted from another public corpus that is continuously growing, the Common Voice dataset. Then, we present graphically the accuracy in terms of Word Error Rate of each of the different English included accents, showing that there is indeed an accuracy bias in terms of accentual variety, favoring the accents most prevalent in the training corpus.
Royalflush Speaker Diarization System for ICASSP 2022 Multi-channel Multi-party Meeting Transcription Challenge
Feb 18, 2022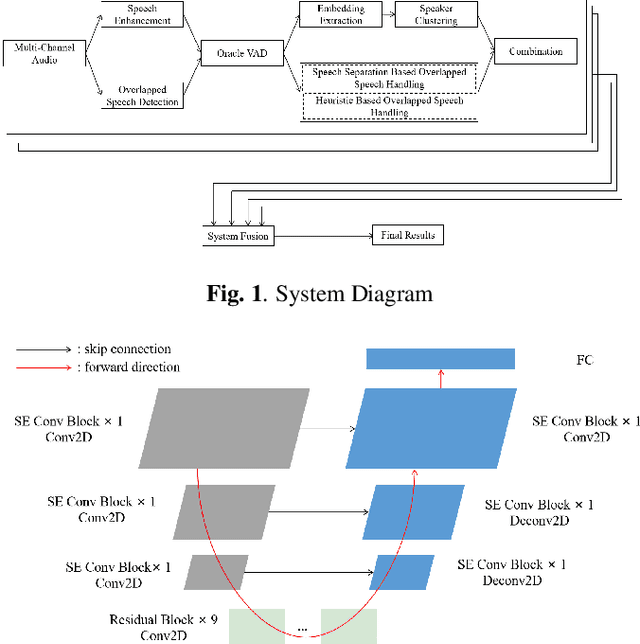
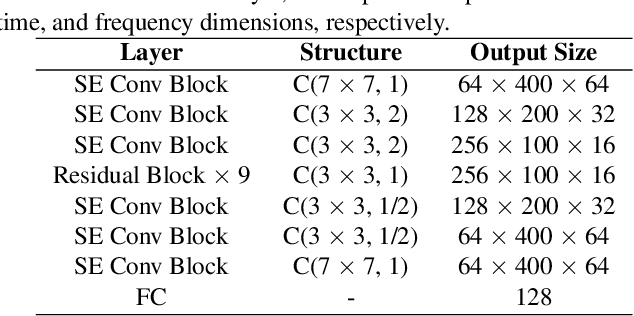
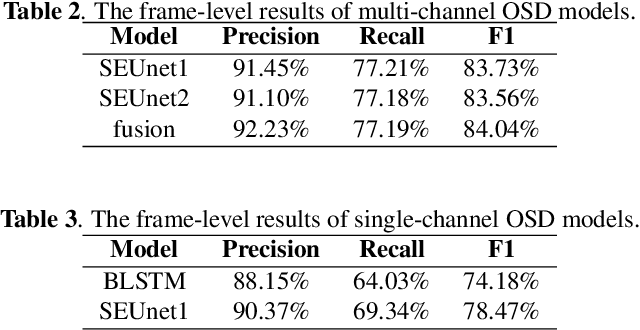
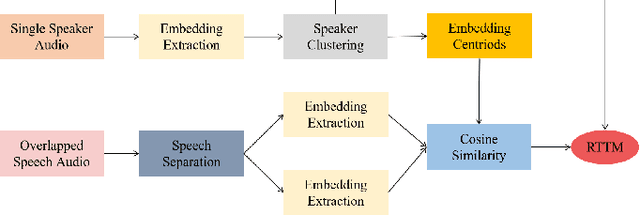
This paper describes the Royalflush speaker diarization system submitted to the Multi-channel Multi-party Meeting Transcription Challenge(M2MeT). Our system comprises speech enhancement, overlapped speech detection, speaker embedding extraction, speaker clustering, speech separation and system fusion. In this system, we made three contributions. First, we propose an architecture of combining the multi-channel and U-Net-based models, aiming at utilizing the benefits of these two individual architectures, for far-field overlapped speech detection. Second, in order to use overlapped speech detection model to help speaker diarization, a speech separation based overlapped speech handling approach, in which the speaker verification technique is further applied, is proposed. Third, we explore three speaker embedding methods, and obtained the state-of-the-art performance on the CNCeleb-E test set. With these proposals, our best individual system significantly reduces DER from 15.25% to 6.40%, and the fusion of four systems finally achieves a DER of 6.30% on the far-field Alimeeting evaluation set.
Contextual Lexicon-Based Approach for Hate Speech and Offensive Language Detection
May 09, 2021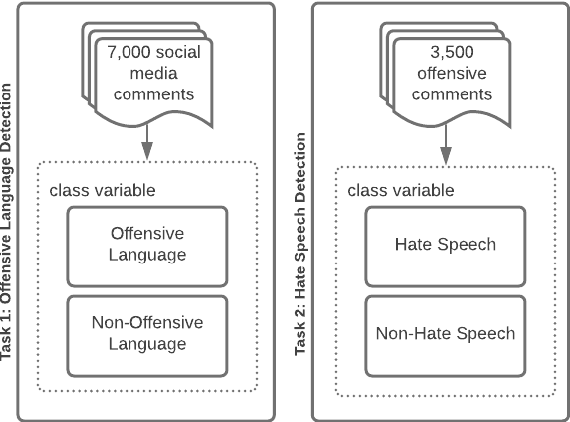
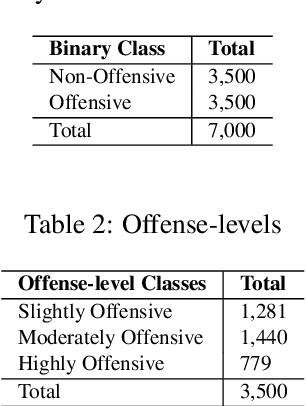
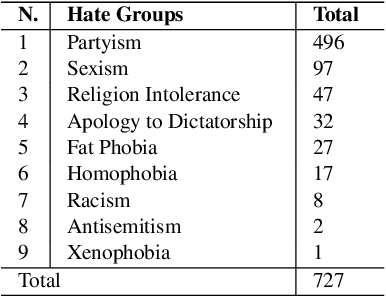
This paper provides a new approach for offensive language and hate speech detection on social media. Our approach incorporates an offensive lexicon composed of implicit and explicit offensive and swearing expressions annotated with binary classes: context-dependent and context-independent offensive. Due to the severity of the hate speech and offensive comments in Brazil, and the lack of research in Portuguese, Brazilian Portuguese is the language used to validate the proposed method. Nevertheless, our proposal may be applied to any other language or domain. Based on the obtained results, the proposed approach showed high-performance overcoming the current baselines for European and Brazilian Portuguese.
Improved MVDR Beamforming Using LSTM Speech Models to Clean Spatial Clustering Masks
Dec 02, 2020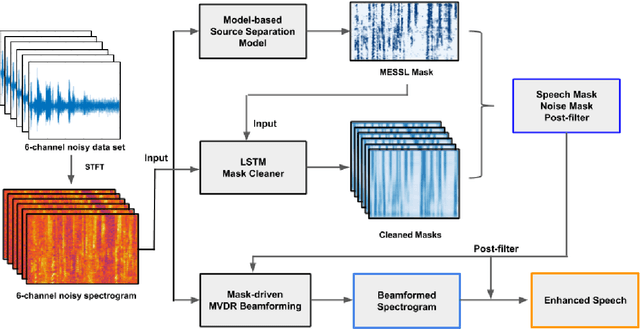
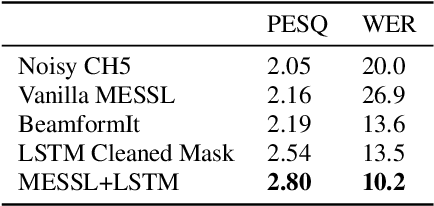
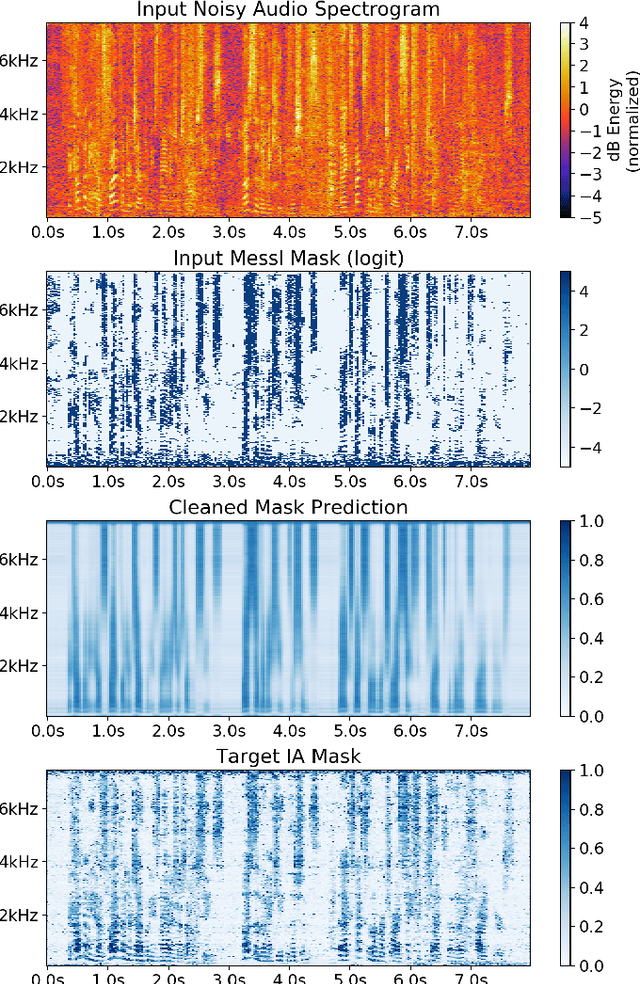
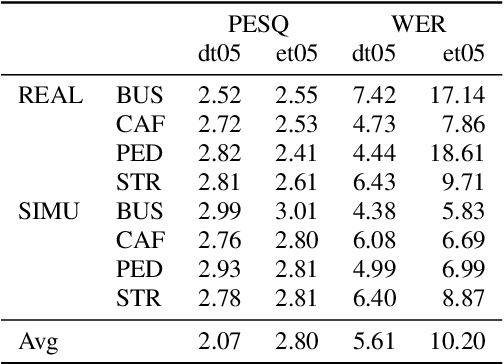
Spatial clustering techniques can achieve significant multi-channel noise reduction across relatively arbitrary microphone configurations, but have difficulty incorporating a detailed speech/noise model. In contrast, LSTM neural networks have successfully been trained to recognize speech from noise on single-channel inputs, but have difficulty taking full advantage of the information in multi-channel recordings. This paper integrates these two approaches, training LSTM speech models to clean the masks generated by the Model-based EM Source Separation and Localization (MESSL) spatial clustering method. By doing so, it attains both the spatial separation performance and generality of multi-channel spatial clustering and the signal modeling performance of multiple parallel single-channel LSTM speech enhancers. Our experiments show that when our system is applied to the CHiME-3 dataset of noisy tablet recordings, it increases speech quality as measured by the Perceptual Evaluation of Speech Quality (PESQ) algorithm and reduces the word error rate of the baseline CHiME-3 speech recognizer, as compared to the default BeamformIt beamformer.
BART based semantic correction for Mandarin automatic speech recognition system
Mar 26, 2021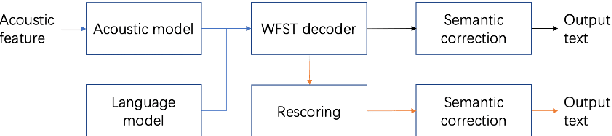
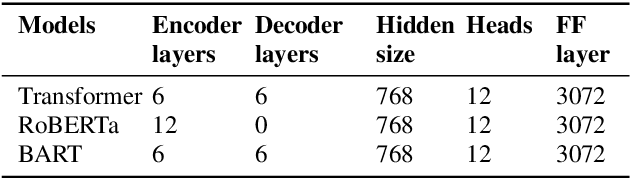
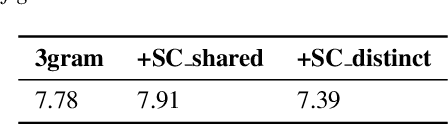

Although automatic speech recognition (ASR) systems achieved significantly improvements in recent years, spoken language recognition error occurs which can be easily spotted by human beings. Various language modeling techniques have been developed on post recognition tasks like semantic correction. In this paper, we propose a Transformer based semantic correction method with pretrained BART initialization, Experiments on 10000 hours Mandarin speech dataset show that character error rate (CER) can be effectively reduced by 21.7% relatively compared to our baseline ASR system. Expert evaluation demonstrates that actual improvement of our model surpasses what CER indicates.
Joint Speaker Counting, Speech Recognition, and Speaker Identification for Overlapped Speech of Any Number of Speakers
Jun 19, 2020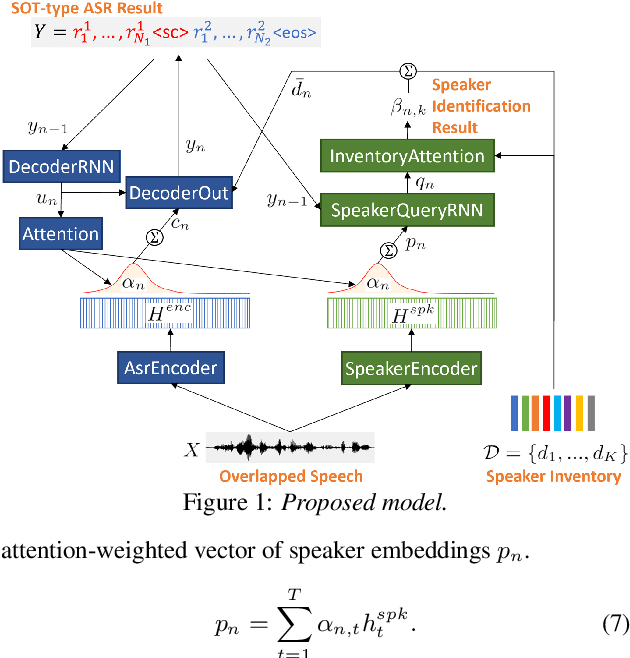
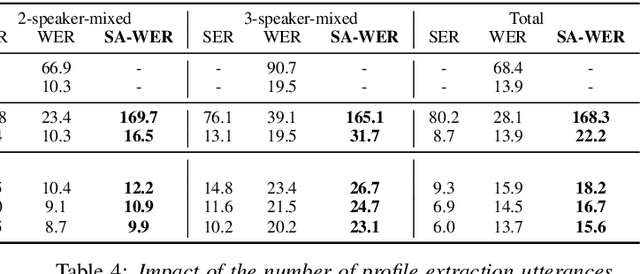
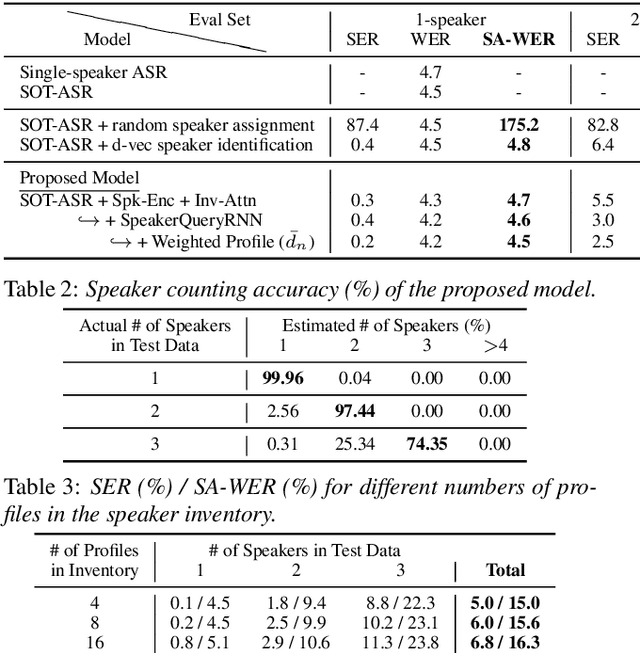
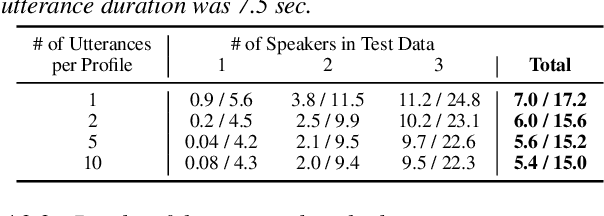
In this paper, we propose a joint model for simultaneous speaker counting, speech recognition, and speaker identification on monaural overlapped speech. Our model is built on serialized output training (SOT) with attention-based encoder-decoder, a recently proposed method for recognizing overlapped speech comprising an arbitrary number of speakers. We extend the SOT model by introducing a speaker inventory as an auxiliary input to produce speaker labels as well as multi-speaker transcriptions. All model parameters are optimized by speaker-attributed maximum mutual information criterion, which represents a joint probability for overlapped speech recognition and speaker identification. Experiments on LibriSpeech corpus show that our proposed method achieves significantly better speaker-attributed word error rate than the baseline that separately performs overlapped speech recognition and speaker identification.
Evaluating the Susceptibility of Pre-Trained Language Models via Handcrafted Adversarial Examples
Sep 05, 2022
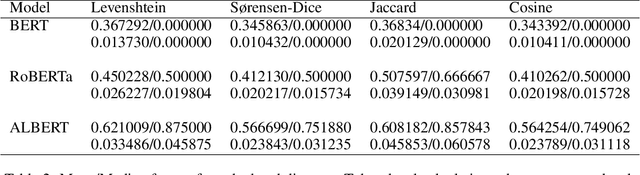

Recent advances in the development of large language models have resulted in public access to state-of-the-art pre-trained language models (PLMs), including Generative Pre-trained Transformer 3 (GPT-3) and Bidirectional Encoder Representations from Transformers (BERT). However, evaluations of PLMs, in practice, have shown their susceptibility to adversarial attacks during the training and fine-tuning stages of development. Such attacks can result in erroneous outputs, model-generated hate speech, and the exposure of users' sensitive information. While existing research has focused on adversarial attacks during either the training or the fine-tuning of PLMs, there is a deficit of information on attacks made between these two development phases. In this work, we highlight a major security vulnerability in the public release of GPT-3 and further investigate this vulnerability in other state-of-the-art PLMs. We restrict our work to pre-trained models that have not undergone fine-tuning. Further, we underscore token distance-minimized perturbations as an effective adversarial approach, bypassing both supervised and unsupervised quality measures. Following this approach, we observe a significant decrease in text classification quality when evaluating for semantic similarity.
Analysis and Synthesis of Hypo and Hyperarticulated Speech
Jun 07, 2020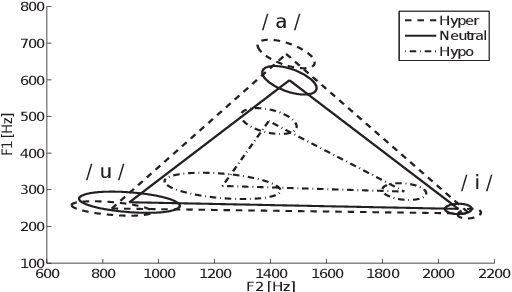

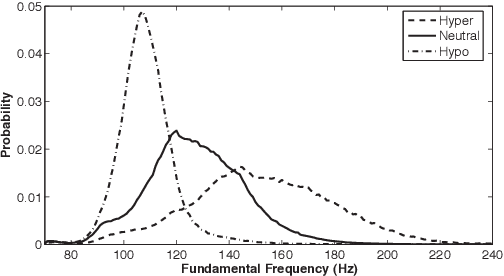
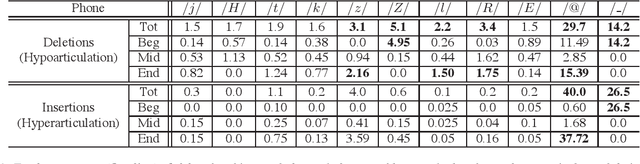
This paper focuses on the analysis and synthesis of hypo and hyperarticulated speech in the framework of HMM-based speech synthesis. First of all, a new French database matching our needs was created, which contains three identical sets, pronounced with three different degrees of articulation: neutral, hypo and hyperarticulated speech. On that basis, acoustic and phonetic analyses were performed. It is shown that the degrees of articulation significantly influence, on one hand, both vocal tract and glottal characteristics, and on the other hand, speech rate, phone durations, phone variations and the presence of glottal stops. Finally, neutral, hypo and hyperarticulated speech are synthesized using HMM-based speech synthesis and both objective and subjective tests aiming at assessing the generated speech quality are performed. These tests show that synthesized hypoarticulated speech seems to be less naturally rendered than neutral and hyperarticulated speech.
Synth2Aug: Cross-domain speaker recognition with TTS synthesized speech
Nov 24, 2020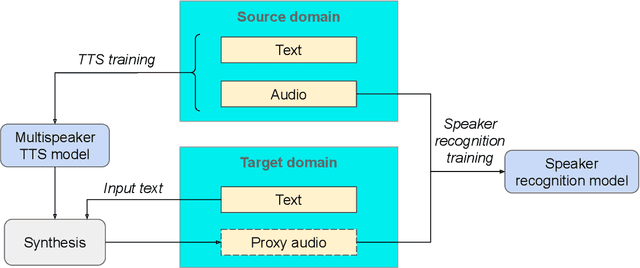
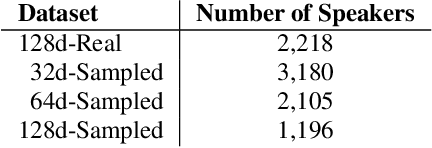
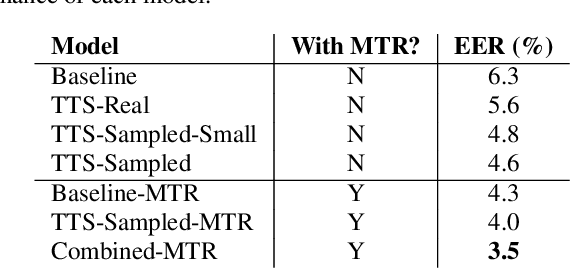
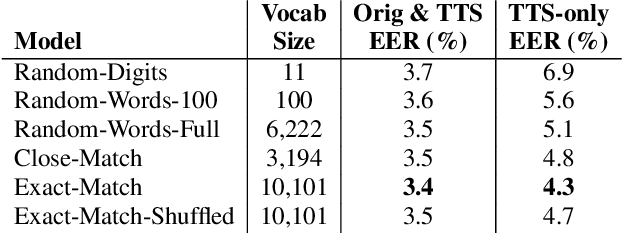
In recent years, Text-To-Speech (TTS) has been used as a data augmentation technique for speech recognition to help complement inadequacies in the training data. Correspondingly, we investigate the use of a multi-speaker TTS system to synthesize speech in support of speaker recognition. In this study we focus the analysis on tasks where a relatively small number of speakers is available for training. We observe on our datasets that TTS synthesized speech improves cross-domain speaker recognition performance and can be combined effectively with multi-style training. Additionally, we explore the effectiveness of different types of text transcripts used for TTS synthesis. Results suggest that matching the textual content of the target domain is a good practice, and if that is not feasible, a transcript with a sufficiently large vocabulary is recommended.
Exploration strategies for articulatory synthesis of complex syllable onsets
Apr 20, 2022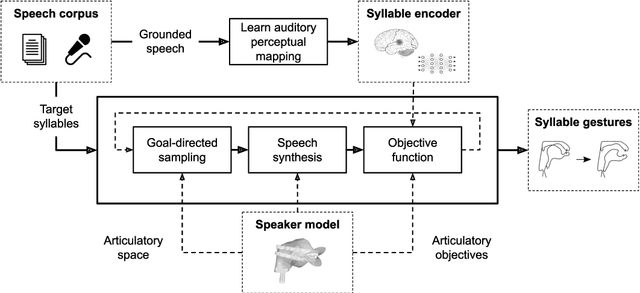

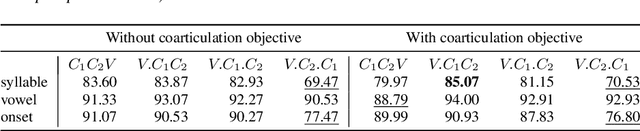
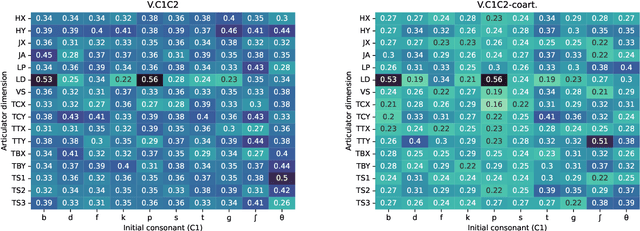
High-quality articulatory speech synthesis has many potential applications in speech science and technology. However, developing appropriate mappings from linguistic specification to articulatory gestures is difficult and time consuming. In this paper we construct an optimisation-based framework as a first step towards learning these mappings without manual intervention. We demonstrate the production of syllables with complex onsets and discuss the quality of the articulatory gestures with reference to coarticulation.