 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Implicit Channel Learning for Machine Learning Applications in 6G Wireless Networks
Jun 24, 2022
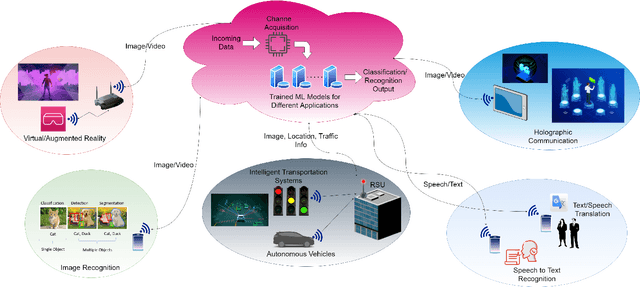
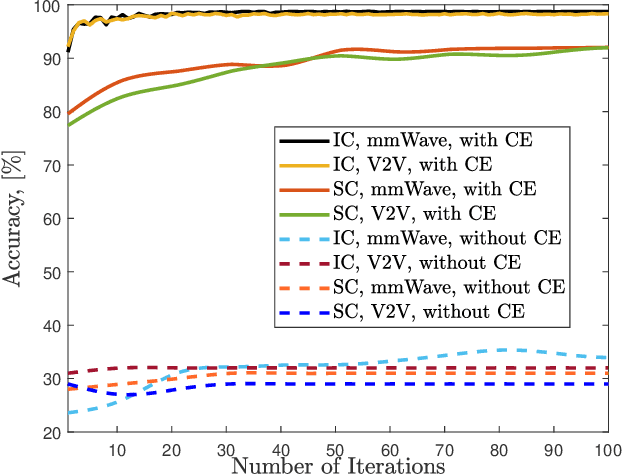
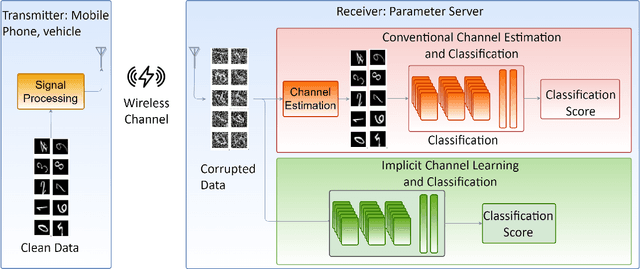
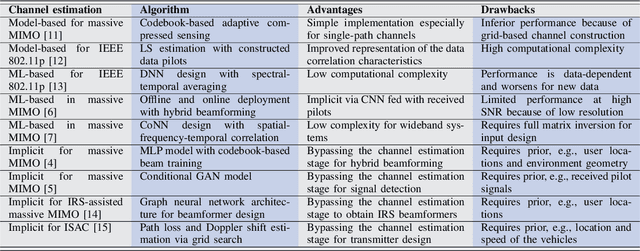
With the deployment of the fifth generation (5G) wireless systems gathering momentum across the world, possible technologies for 6G are under active research discussions. In particular, the role of machine learning (ML) in 6G is expected to enhance and aid emerging applications such as virtual and augmented reality, vehicular autonomy, and computer vision. This will result in large segments of wireless data traffic comprising image, video and speech. The ML algorithms process these for classification/recognition/estimation through the learning models located on cloud servers. This requires wireless transmission of data from edge devices to the cloud server. Channel estimation, handled separately from recognition step, is critical for accurate learning performance. Toward combining the learning for both channel and the ML data, we introduce implicit channel learning to perform the ML tasks without estimating the wireless channel. Here, the ML models are trained with channel-corrupted datasets in place of nominal data. Without channel estimation, the proposed approach exhibits approximately 60% improvement in image and speech classification tasks for diverse scenarios such as millimeter wave and IEEE 802.11p vehicular channels.
Improving Contextual Recognition of Rare Words with an Alternate Spelling Prediction Model
Sep 02, 2022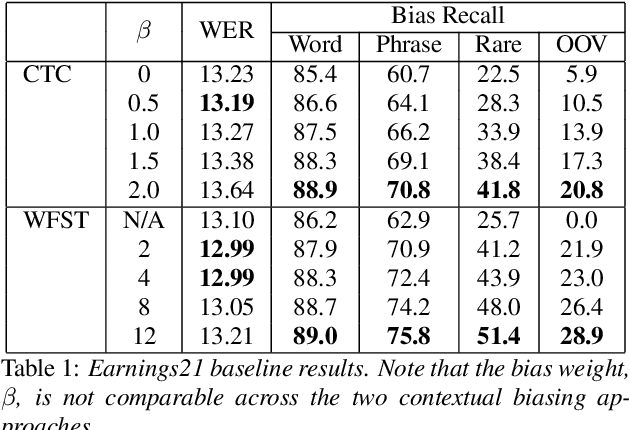
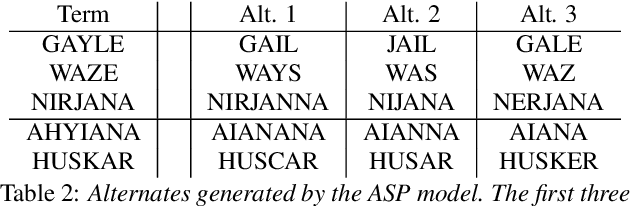
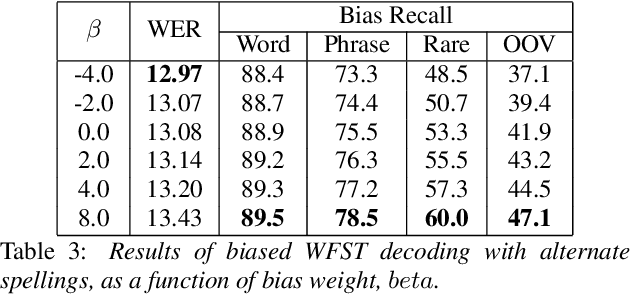
Contextual ASR, which takes a list of bias terms as input along with audio, has drawn recent interest as ASR use becomes more widespread. We are releasing contextual biasing lists to accompany the Earnings21 dataset, creating a public benchmark for this task. We present baseline results on this benchmark using a pretrained end-to-end ASR model from the WeNet toolkit. We show results for shallow fusion contextual biasing applied to two different decoding algorithms. Our baseline results confirm observations that end-to-end models struggle in particular with words that are rarely or never seen during training, and that existing shallow fusion techniques do not adequately address this problem. We propose an alternate spelling prediction model that improves recall of rare words by 34.7% relative and of out-of-vocabulary words by 97.2% relative, compared to contextual biasing without alternate spellings. This model is conceptually similar to ones used in prior work, but is simpler to implement as it does not rely on either a pronunciation dictionary or an existing text-to-speech system.
Dimensions of Interpersonal Dynamics in Text: Group Membership and Fine-grained Interpersonal Emotion
Sep 14, 2022
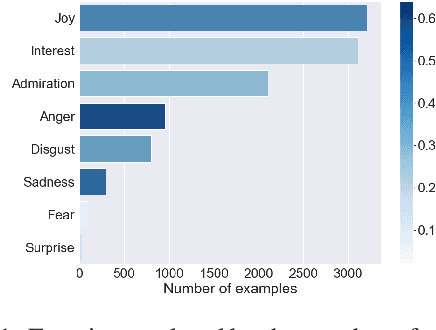
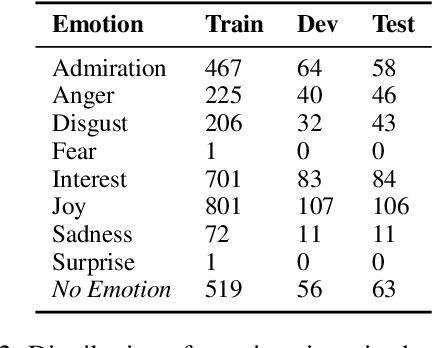
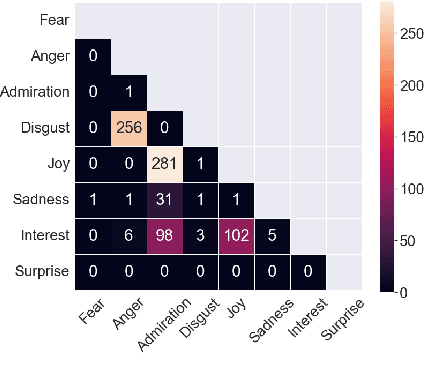
The ability of language to perpetuate inequality is most evident when individuals refer to, or talk about, other individuals in their utterances. While current studies of bias in NLP rely mainly on identifying hate speech or bias towards a specific group, we believe we can reach a more subtle and nuanced understanding of the interaction between bias and language use by modeling the speaker, the text, and the target in the text. In this paper, we introduce a dataset of 3033 English tweets by US Congress members annotated for interpersonal emotion, and `found supervision' for interpersonal group membership labels. We find that negative emotions such as anger and disgust are used predominantly in out-group situations, and directed predominantly at leaders of opposite parties. While humans can perform better than chance at identifying interpersonal group membership given an utterance, neural models perform much better; furthermore, a shared encoding between interpersonal group membership and interpersonal perceived emotion enabled some performance gains in the latter. This work aims to re-align the study of bias in NLP away from specific instances of bias to one which encapsulates the relationship between speaker, text, target and social dynamics. Data and code for this paper are available at https://github.com/venkatasg/Interpersonal-Dynamics
The USTC-NELSLIP Systems for Simultaneous Speech Translation Task at IWSLT 2021
Jul 01, 2021
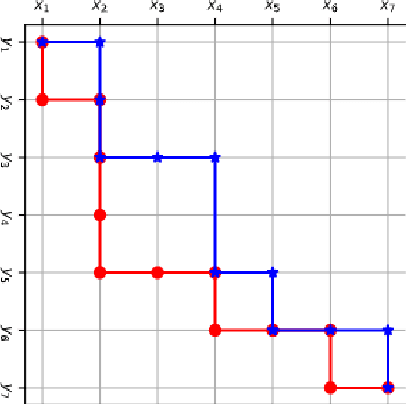
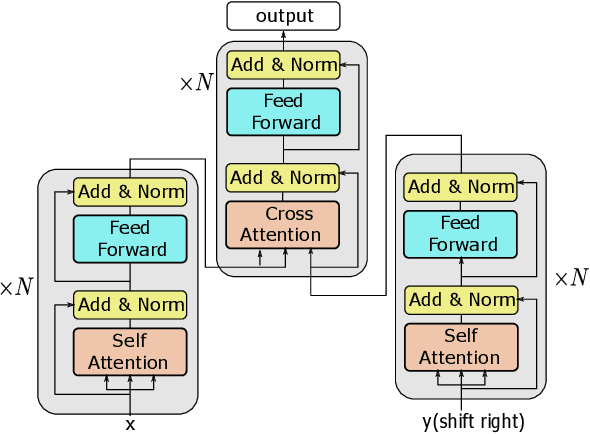
This paper describes USTC-NELSLIP's submissions to the IWSLT2021 Simultaneous Speech Translation task. We proposed a novel simultaneous translation model, Cross Attention Augmented Transducer (CAAT), which extends conventional RNN-T to sequence-to-sequence tasks without monotonic constraints, e.g., simultaneous translation. Experiments on speech-to-text (S2T) and text-to-text (T2T) simultaneous translation tasks shows CAAT achieves better quality-latency trade-offs compared to \textit{wait-k}, one of the previous state-of-the-art approaches. Based on CAAT architecture and data augmentation, we build S2T and T2T simultaneous translation systems in this evaluation campaign. Compared to last year's optimal systems, our S2T simultaneous translation system improves by an average of 11.3 BLEU for all latency regimes, and our T2T simultaneous translation system improves by an average of 4.6 BLEU.
Thai Wav2Vec2.0 with CommonVoice V8
Aug 09, 2022

Recently, Automatic Speech Recognition (ASR), a system that converts audio into text, has caught a lot of attention in the machine learning community. Thus, a lot of publicly available models were released in HuggingFace. However, most of these ASR models are available in English; only a minority of the models are available in Thai. Additionally, most of the Thai ASR models are closed-sourced, and the performance of existing open-sourced models lacks robustness. To address this problem, we train a new ASR model on a pre-trained XLSR-Wav2Vec model with the Thai CommonVoice corpus V8 and train a trigram language model to boost the performance of our ASR model. We hope that our models will be beneficial to individuals and the ASR community in Thailand.
Test-Time Adaptation Toward Personalized Speech Enhancement: Zero-Shot Learning with Knowledge Distillation
May 08, 2021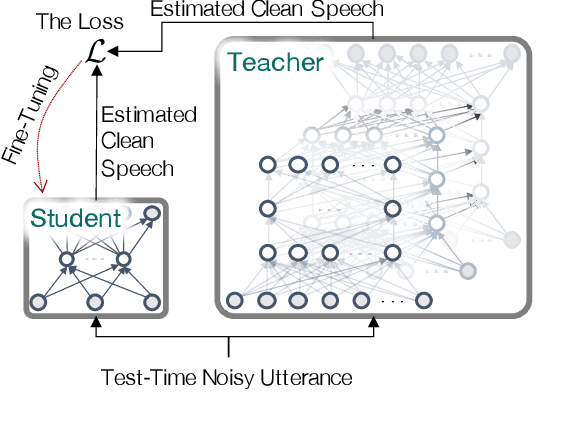
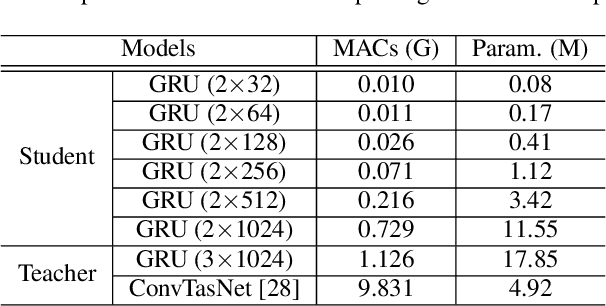
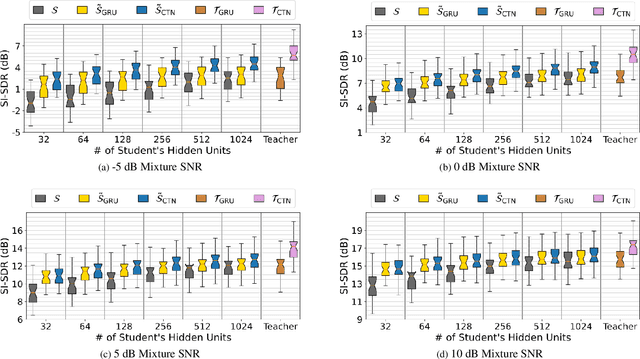
In realistic speech enhancement settings for end-user devices, we often encounter only a few speakers and noise types that tend to reoccur in the specific acoustic environment. We propose a novel personalized speech enhancement method to adapt a compact denoising model to the test-time specificity. Our goal in this test-time adaptation is to utilize no clean speech target of the test speaker, thus fulfilling the requirement for zero-shot learning. To complement the lack of clean utterance, we employ the knowledge distillation framework. Instead of the missing clean utterance target, we distill the more advanced denoising results from an overly large teacher model, and use it as the pseudo target to train the small student model. This zero-shot learning procedure circumvents the process of collecting users' clean speech, a process that users are reluctant to comply due to privacy concerns and technical difficulty of recording clean voice. Experiments on various test-time conditions show that the proposed personalization method achieves significant performance gains compared to larger baseline networks trained from a large speaker- and noise-agnostic datasets. In addition, since the compact personalized models can outperform larger general-purpose models, we claim that the proposed method performs model compression with no loss of denoising performance.
Design of a novel Korean learning application for efficient pronunciation correction
May 04, 2022
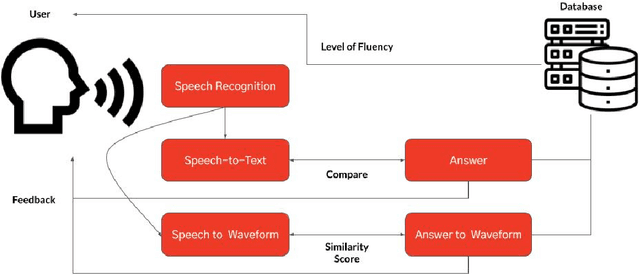
The Korean wave, which denotes the global popularity of South Korea's cultural economy, contributes to the increasing demand for the Korean language. However, as there does not exist any application for foreigners to learn Korean, this paper suggested a design of a novel Korean learning application. Speech recognition, speech-to-text, and speech-to-waveform are the three key systems in the proposed system. The Google API and the librosa library will transform the user's voice into a sentence and MFCC. The software will then display the user's phrase and answer, with mispronounced elements highlighted in red, allowing users to more easily recognize the incorrect parts of their pronunciation. Furthermore, the Siamese network might utilize those translated spectrograms to provide a similarity score, which could subsequently be used to offer feedback to the user. Despite the fact that we were unable to collect sufficient foreigner data for this research, it is notable that we presented a novel Korean pronunciation correction method for foreigners.
LiRA: Learning Visual Speech Representations from Audio through Self-supervision
Jun 16, 2021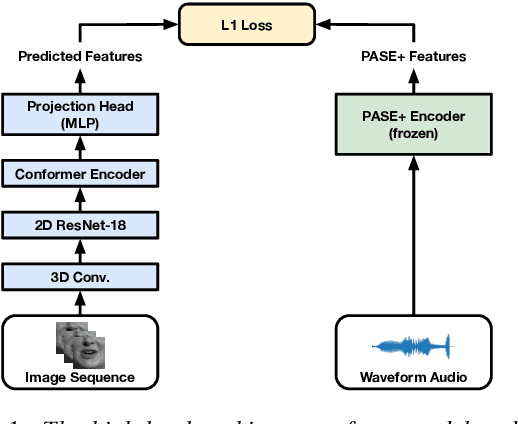
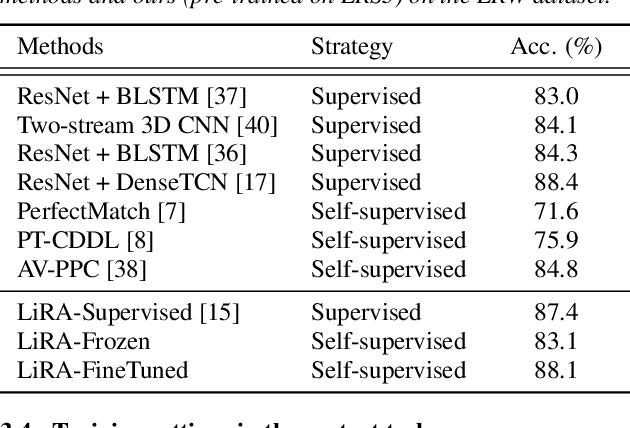
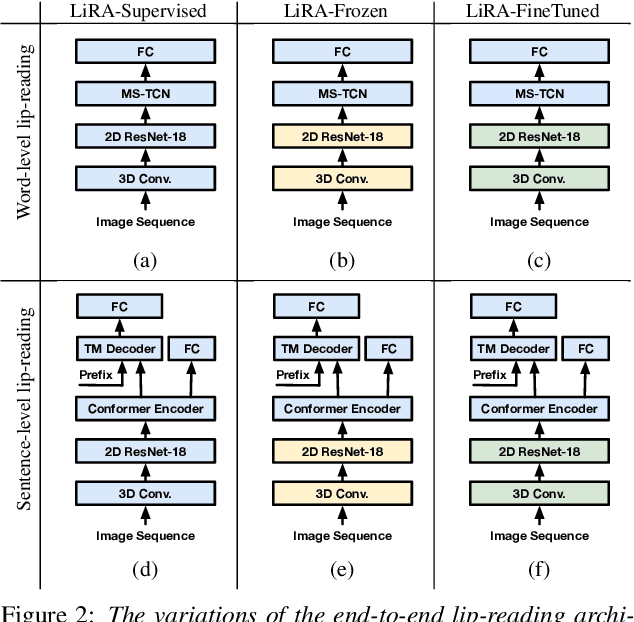
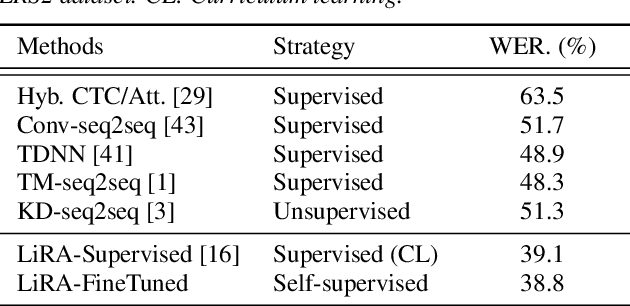
The large amount of audiovisual content being shared online today has drawn substantial attention to the prospect of audiovisual self-supervised learning. Recent works have focused on each of these modalities separately, while others have attempted to model both simultaneously in a cross-modal fashion. However, comparatively little attention has been given to leveraging one modality as a training objective to learn from the other. In this work, we propose Learning visual speech Representations from Audio via self-supervision (LiRA). Specifically, we train a ResNet+Conformer model to predict acoustic features from unlabelled visual speech. We find that this pre-trained model can be leveraged towards word-level and sentence-level lip-reading through feature extraction and fine-tuning experiments. We show that our approach significantly outperforms other self-supervised methods on the Lip Reading in the Wild (LRW) dataset and achieves state-of-the-art performance on Lip Reading Sentences 2 (LRS2) using only a fraction of the total labelled data.
SC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model
Apr 02, 2021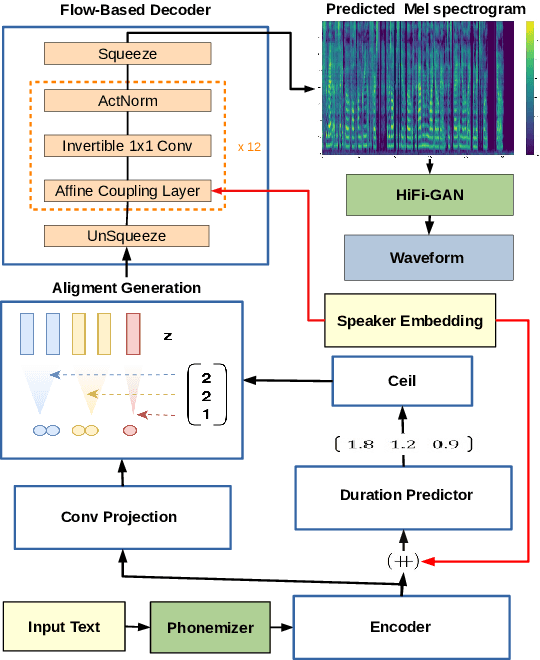
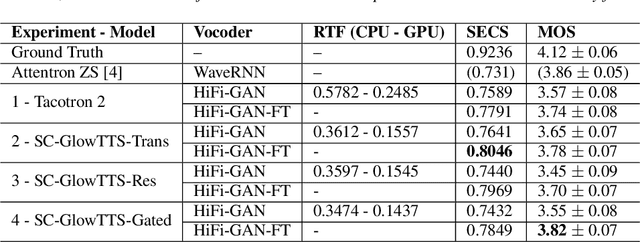
In this paper, we propose SC-GlowTTS: an efficient zero-shot multi-speaker text-to-speech model that improves similarity for speakers unseen in training. We propose a speaker-conditional architecture that explores a flow-based decoder that works in a zero-shot scenario. As text encoders, we explore a dilated residual convolutional-based encoder, gated convolutional-based encoder, and transformer-based encoder. Additionally, we have shown that adjusting a GAN-based vocoder for the spectrograms predicted by the TTS model on the training dataset can significantly improve the similarity and speech quality for new speakers. Our model is able to converge in training, using only 11 speakers, reaching state-of-the-art results for similarity with new speakers, as well as high speech quality.
Blackbox Untargeted Adversarial Testing of Automatic Speech Recognition Systems
Dec 03, 2021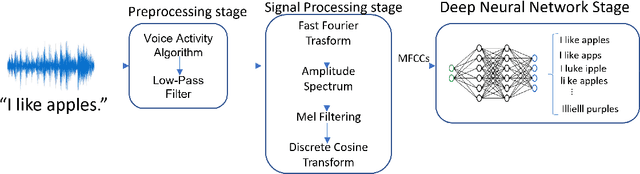
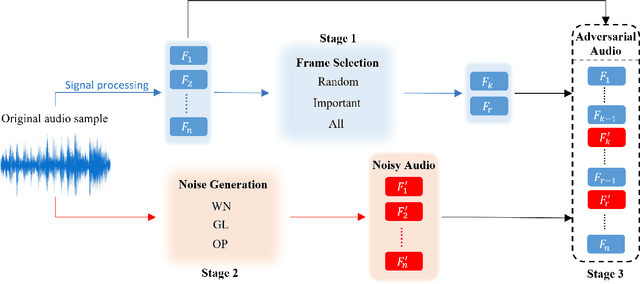
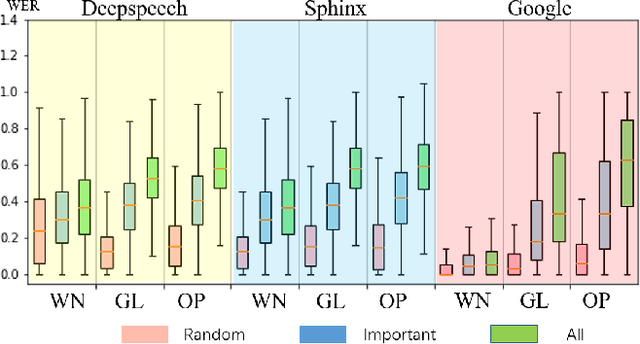
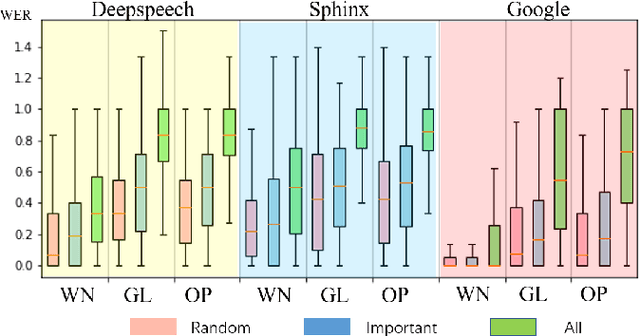
Automatic speech recognition (ASR) systems are prevalent, particularly in applications for voice navigation and voice control of domestic appliances. The computational core of ASRs are deep neural networks (DNNs) that have been shown to be susceptible to adversarial perturbations; easily misused by attackers to generate malicious outputs. To help test the correctness of ASRS, we propose techniques that automatically generate blackbox (agnostic to the DNN), untargeted adversarial attacks that are portable across ASRs. Much of the existing work on adversarial ASR testing focuses on targeted attacks, i.e generating audio samples given an output text. Targeted techniques are not portable, customised to the structure of DNNs (whitebox) within a specific ASR. In contrast, our method attacks the signal processing stage of the ASR pipeline that is shared across most ASRs. Additionally, we ensure the generated adversarial audio samples have no human audible difference by manipulating the acoustic signal using a psychoacoustic model that maintains the signal below the thresholds of human perception. We evaluate portability and effectiveness of our techniques using three popular ASRs and three input audio datasets using the metrics - WER of output text, Similarity to original audio and attack Success Rate on different ASRs. We found our testing techniques were portable across ASRs, with the adversarial audio samples producing high Success Rates, WERs and Similarities to the original audio.