 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speaker Identification Experiments Under Gender De-Identification
Mar 09, 2022
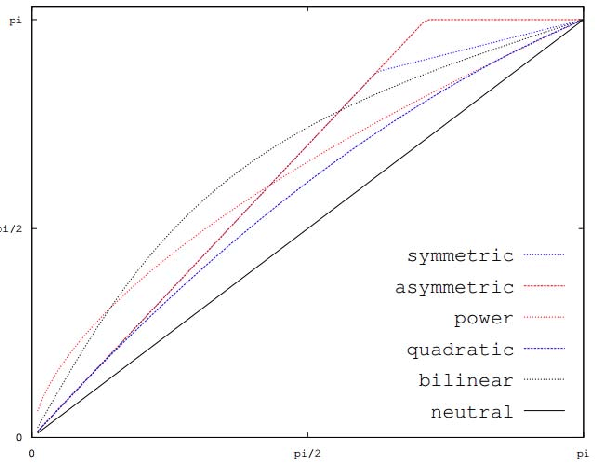
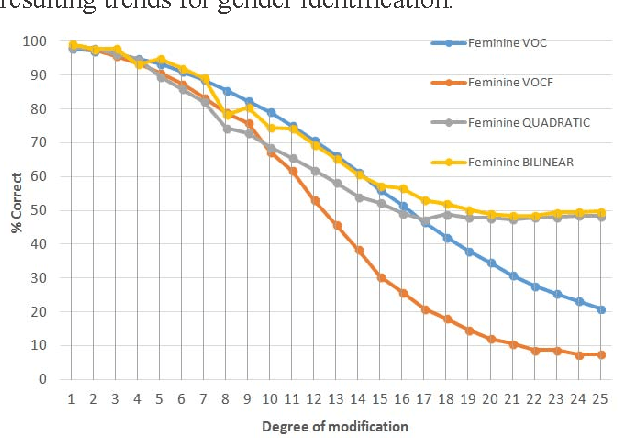
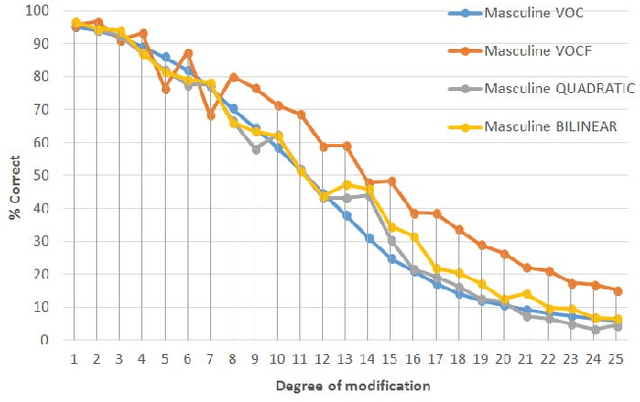
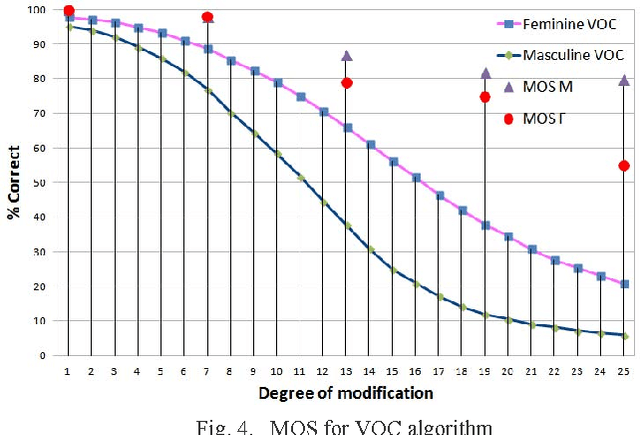
The present work is based on the COST Action IC1206 for De-identification in multimedia content. It was performed to test four algorithms of voice modifications on a speech gender recognizer to find the degree of modification of pitch when the speech recognizer have the probability of success equal to the probability of failure. The purpose of this analysis is to assess the intensity of the speech tone modification, the quality, the reversibility and not-reversibility of the changes made. Keywords DeIdentification; Speech Algorithms
* 5 pages
Convolutive Prediction for Reverberant Speech Separation
Aug 16, 2021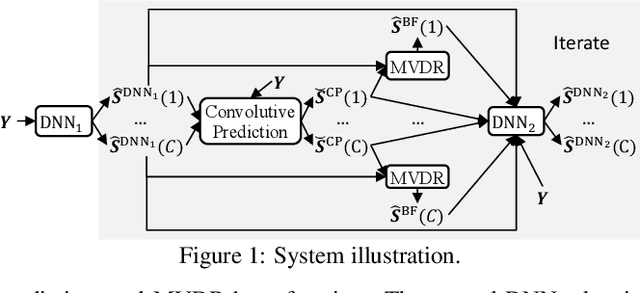
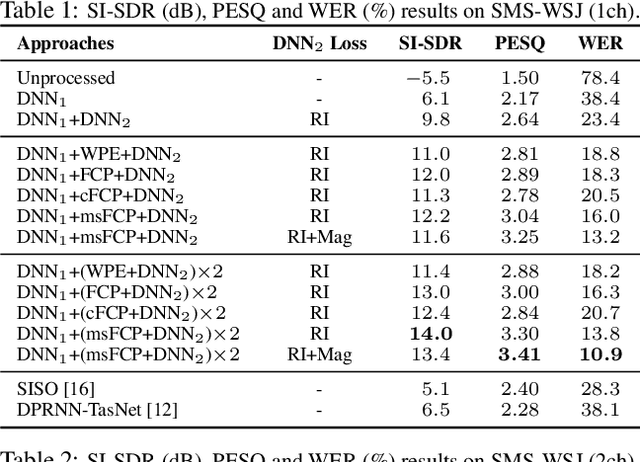
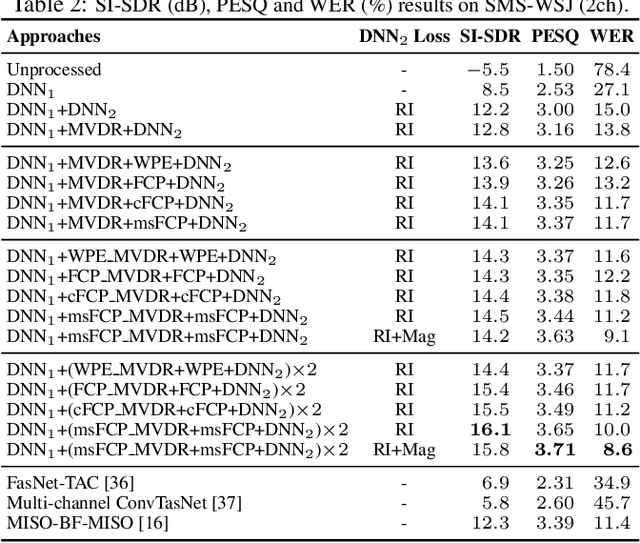
We investigate the effectiveness of convolutive prediction, a novel formulation of linear prediction for speech dereverberation, for speaker separation in reverberant conditions. The key idea is to first use a deep neural network (DNN) to estimate the direct-path signal of each speaker, and then identify delayed and decayed copies of the estimated direct-path signal. Such copies are likely due to reverberation, and can be directly removed for dereverberation or used as extra features for another DNN to perform better dereverberation and separation. To identify such copies, we solve a linear regression problem per frequency efficiently in the time-frequency (T-F) domain to estimate the underlying room impulse response (RIR). In the multi-channel extension, we perform minimum variance distortionless response (MVDR) beamforming on the outputs of convolutive prediction. The beamforming and dereverberation results are used as extra features for a second DNN to perform better separation and dereverberation. State-of-the-art results are obtained on the SMS-WSJ corpus.
Cross-lingual Dysarthria Severity Classification for English, Korean, and Tamil
Sep 26, 2022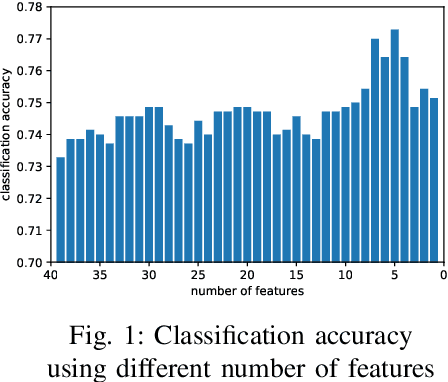
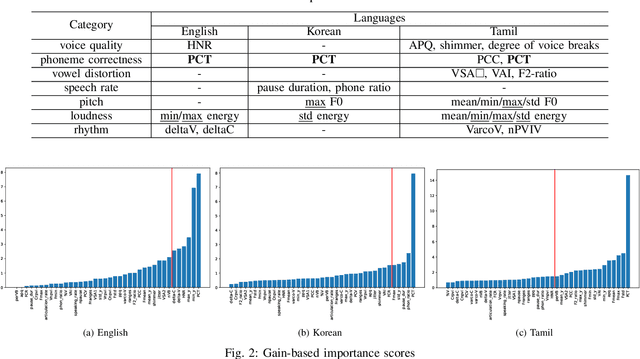
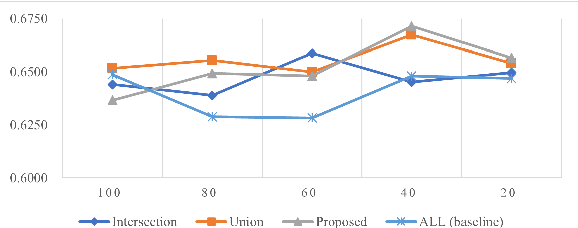
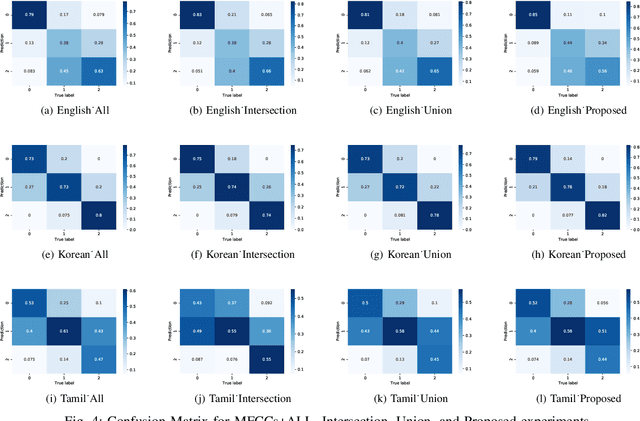
This paper proposes a cross-lingual classification method for English, Korean, and Tamil, which employs both language-independent features and language-unique features. First, we extract thirty-nine features from diverse speech dimensions such as voice quality, pronunciation, and prosody. Second, feature selections are applied to identify the optimal feature set for each language. A set of shared features and a set of distinctive features are distinguished by comparing the feature selection results of the three languages. Lastly, automatic severity classification is performed, utilizing the two feature sets. Notably, the proposed method removes different features by languages to prevent the negative effect of unique features for other languages. Accordingly, eXtreme Gradient Boosting (XGBoost) algorithm is employed for classification, due to its strength in imputing missing data. In order to validate the effectiveness of our proposed method, two baseline experiments are conducted: experiments using the intersection set of mono-lingual feature sets (Intersection) and experiments using the union set of mono-lingual feature sets (Union). According to the experimental results, our method achieves better performance with a 67.14% F1 score, compared to 64.52% for the Intersection experiment and 66.74% for the Union experiment. Further, the proposed method attains better performances than mono-lingual classifications for all three languages, achieving 17.67%, 2.28%, 7.79% relative percentage increases for English, Korean, and Tamil, respectively. The result specifies that commonly shared features and language-specific features must be considered separately for cross-language dysarthria severity classification.
Lost in Context? On the Sense-wise Variance of Contextualized Word Embeddings
Aug 20, 2022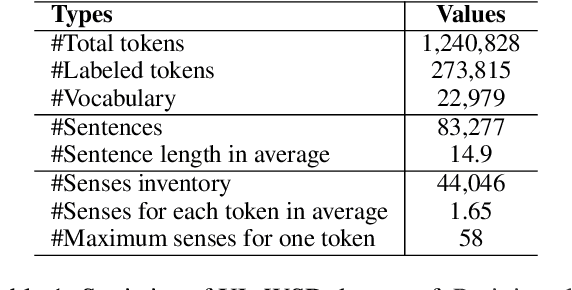
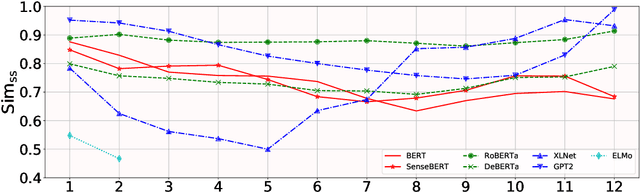
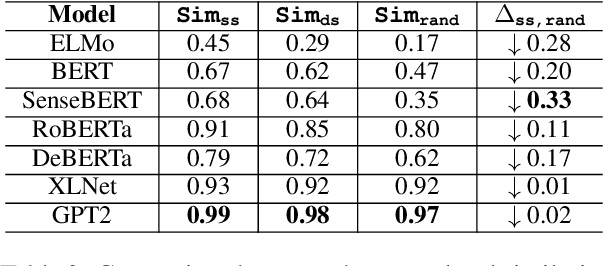
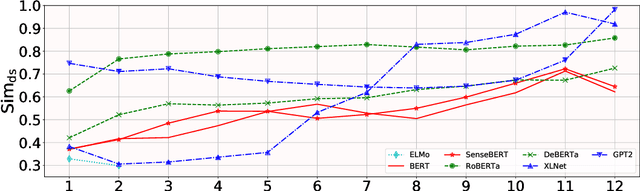
Contextualized word embeddings in language models have given much advance to NLP. Intuitively, sentential information is integrated into the representation of words, which can help model polysemy. However, context sensitivity also leads to the variance of representations, which may break the semantic consistency for synonyms. We quantify how much the contextualized embeddings of each word sense vary across contexts in typical pre-trained models. Results show that contextualized embeddings can be highly consistent across contexts. In addition, part-of-speech, number of word senses, and sentence length have an influence on the variance of sense representations. Interestingly, we find that word representations are position-biased, where the first words in different contexts tend to be more similar. We analyze such a phenomenon and also propose a simple way to alleviate such bias in distance-based word sense disambiguation settings.
Speech Synthesis using EEG
Feb 22, 2020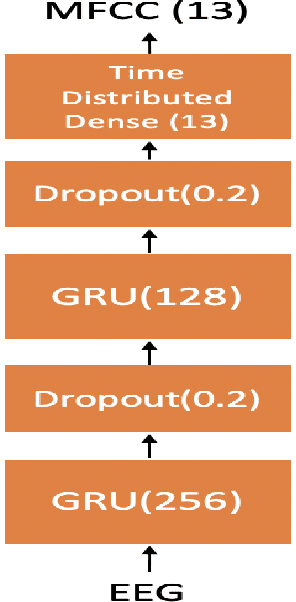
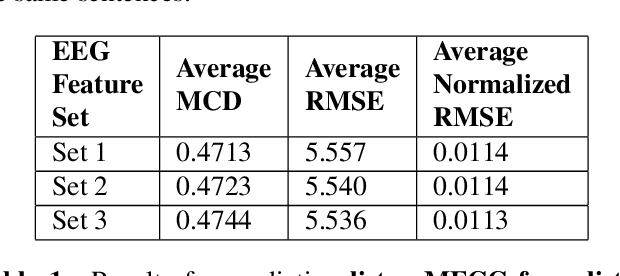
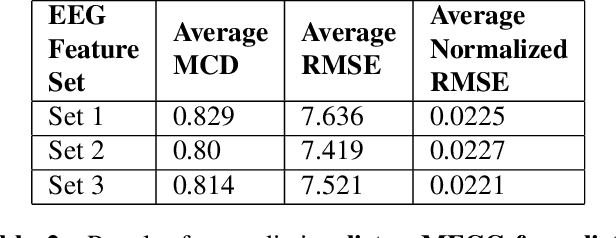
In this paper we demonstrate speech synthesis using different electroencephalography (EEG) feature sets recently introduced in [1]. We make use of a recurrent neural network (RNN) regression model to predict acoustic features directly from EEG features. We demonstrate our results using EEG features recorded in parallel with spoken speech as well as using EEG recorded in parallel with listening utterances. We provide EEG based speech synthesis results for four subjects in this paper and our results demonstrate the feasibility of synthesizing speech directly from EEG features.
Deep Residual Echo Suppression and Noise Reduction: A Multi-Input FCRN Approach in a Hybrid Speech Enhancement System
Aug 06, 2021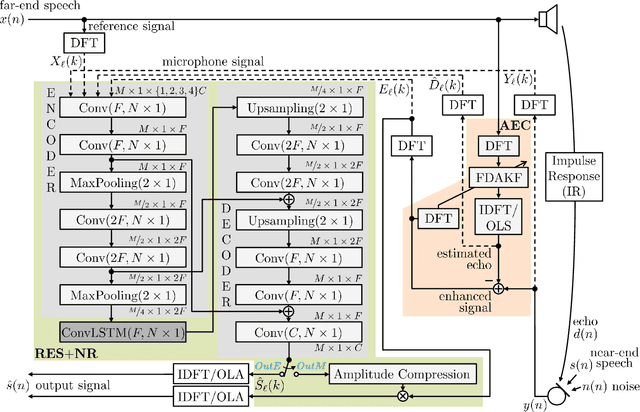
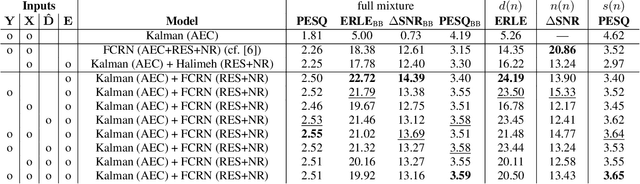
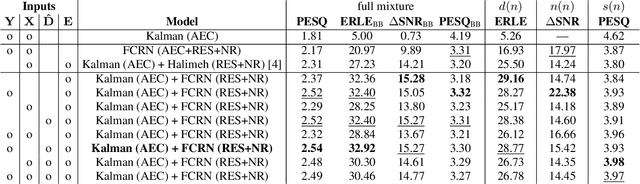
Deep neural network (DNN)-based approaches to acoustic echo cancellation (AEC) and hybrid speech enhancement systems have gained increasing attention recently, introducing significant performance improvements to this research field. Using the fully convolutional recurrent network (FCRN) architecture that is among state of the art topologies for noise reduction, we present a novel deep residual echo suppression and noise reduction with up to four input signals as part of a hybrid speech enhancement system with a linear frequency domain adaptive Kalman filter AEC. In an extensive ablation study, we reveal trade-offs with regard to echo suppression, noise reduction, and near-end speech quality, and provide surprising insights to the choice of the FCRN inputs: In contrast to often seen input combinations for this task, we propose not to use the loudspeaker reference signal, but the enhanced signal after AEC, the microphone signal, and the echo estimate, yielding improvements over previous approaches by more than 0.2 PESQ points.
End-to-End Rich Transcription-Style Automatic Speech Recognition with Semi-Supervised Learning
Jul 07, 2021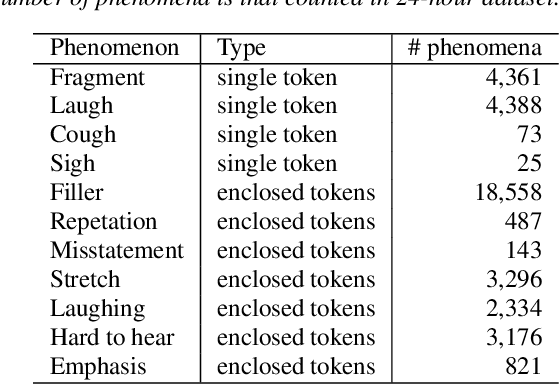
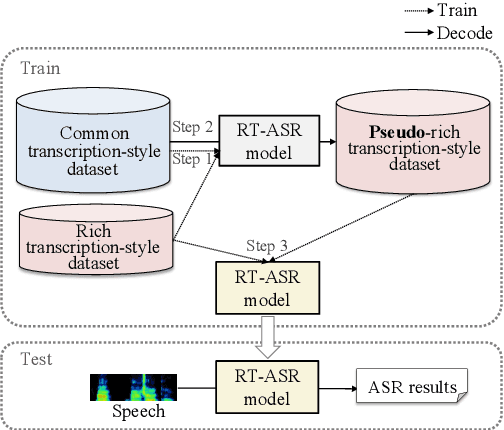
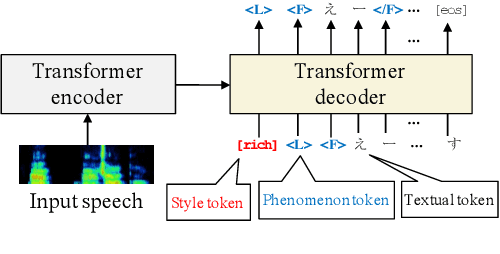
We propose a semi-supervised learning method for building end-to-end rich transcription-style automatic speech recognition (RT-ASR) systems from small-scale rich transcription-style and large-scale common transcription-style datasets. In spontaneous speech tasks, various speech phenomena such as fillers, word fragments, laughter and coughs, etc. are often included. While common transcriptions do not give special awareness to these phenomena, rich transcriptions explicitly convert them into special phenomenon tokens as well as textual tokens. In previous studies, the textual and phenomenon tokens were simultaneously estimated in an end-to-end manner. However, it is difficult to build accurate RT-ASR systems because large-scale rich transcription-style datasets are often unavailable. To solve this problem, our training method uses a limited rich transcription-style dataset and common transcription-style dataset simultaneously. The Key process in our semi-supervised learning is to convert the common transcription-style dataset into a pseudo-rich transcription-style dataset. To this end, we introduce style tokens which control phenomenon tokens are generated or not into transformer-based autoregressive modeling. We use this modeling for generating the pseudo-rich transcription-style datasets and for building RT-ASR system from the pseudo and original datasets. Our experiments on spontaneous ASR tasks showed the effectiveness of the proposed method.
Minimal Feature Analysis for Isolated Digit Recognition for varying encoding rates in noisy environments
Aug 27, 2022
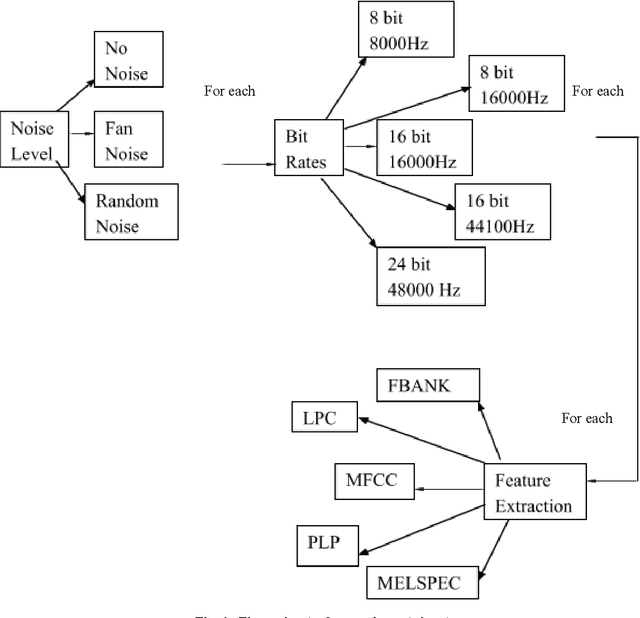
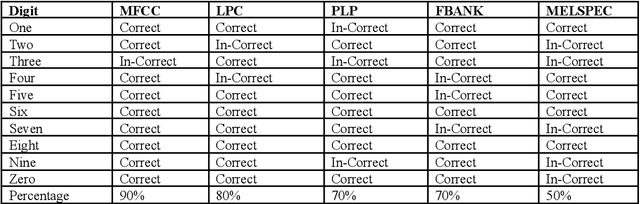
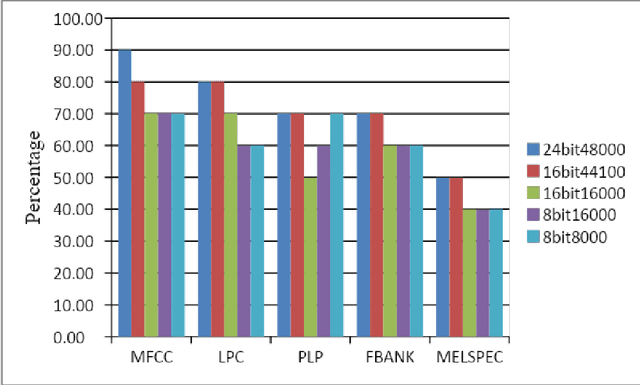
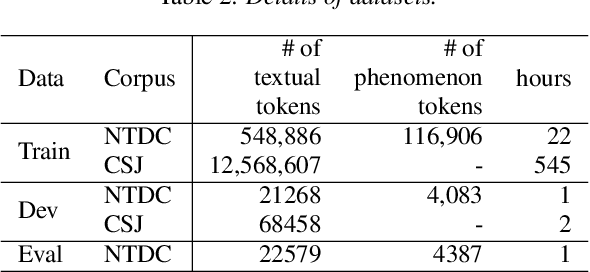
This research work is about recent development made in speech recognition. In this research work, analysis of isolated digit recognition in the presence of different bit rates and at different noise levels has been performed. This research work has been carried using audacity and HTK toolkit. Hidden Markov Model (HMM) is the recognition model which was used to perform this experiment. The feature extraction techniques used are Mel Frequency Cepstrum coefficient (MFCC), Linear Predictive Coding (LPC), perceptual linear predictive (PLP), mel spectrum (MELSPEC), filter bank (FBANK). There were three types of different noise levels which have been considered for testing of data. These include random noise, fan noise and random noise in real time environment. This was done to analyse the best environment which can used for real time applications. Further, five different types of commonly used bit rates at different sampling rates were considered to find out the most optimum bit rate.
UPC's Speech Translation System for IWSLT 2021
May 10, 2021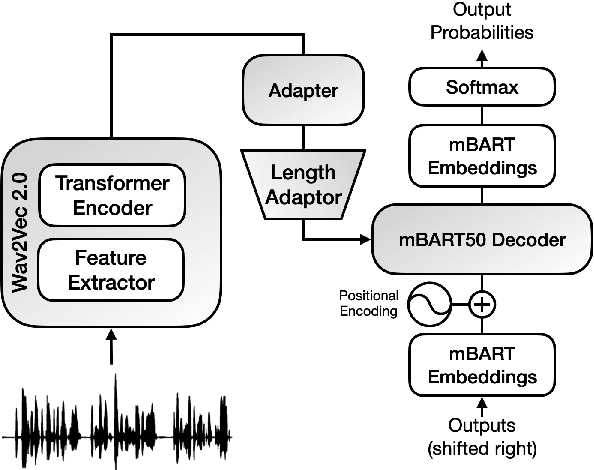

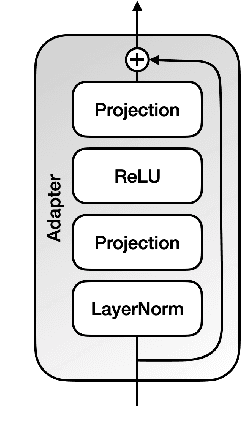
This paper describes the submission to the IWSLT 2021 offline speech translation task by the UPC Machine Translation group. The task consists of building a system capable of translating English audio recordings extracted from TED talks into German text. Submitted systems can be either cascade or end-to-end and use a custom or given segmentation. Our submission is an end-to-end speech translation system, which combines pre-trained models (Wav2Vec 2.0 and mBART) with coupling modules between the encoder and decoder, and uses an efficient fine-tuning technique, which trains only 20% of its total parameters. We show that adding an Adapter to the system and pre-training it, can increase the convergence speed and the final result, with which we achieve a BLEU score of 27.3 on the MuST-C test set. Our final model is an ensemble that obtains 28.22 BLEU score on the same set. Our submission also uses a custom segmentation algorithm that employs pre-trained Wav2Vec 2.0 for identifying periods of untranscribable text and can bring improvements of 2.5 to 3 BLEU score on the IWSLT 2019 test set, as compared to the result with the given segmentation.
An error correction scheme for improved air-tissue boundary in real-time MRI video for speech production
Mar 09, 2022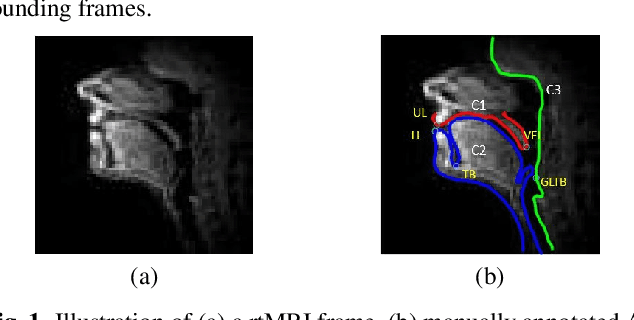

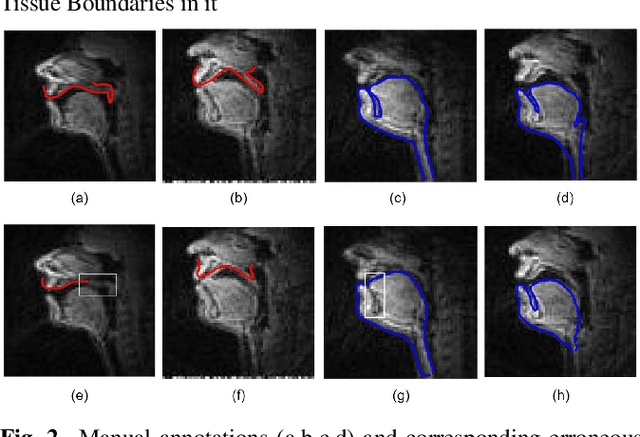
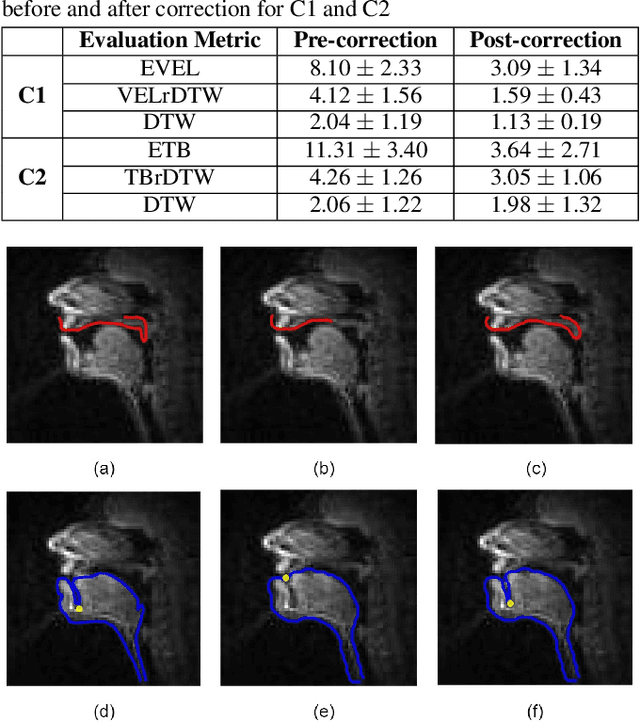
The best performance in Air-tissue boundary (ATB) segmentation of real-time Magnetic Resonance Imaging (rtMRI) videos in speech production is known to be achieved by a 3-dimensional convolutional neural network (3D-CNN) model. However, the evaluation of this model, as well as other ATB segmentation techniques reported in the literature, is done using Dynamic Time Warping (DTW) distance between the entire original and predicted contours. Such an evaluation measure may not capture local errors in the predicted contour. Careful analysis of predicted contours reveals errors in regions like the velum part of contour1 (ATB comprising of upper lip, hard palate, and velum) and tongue base section of contour2 (ATB covering jawline, lower lip, tongue base, and epiglottis), which are not captured in a global evaluation metric like DTW distance. In this work, we automatically detect such errors and propose a correction scheme for the same. We also propose two new evaluation metrics for ATB segmentation separately in contour1 and contour2 to explicitly capture two types of errors in these contours. The proposed detection and correction strategies result in an improvement of these two evaluation metrics by 61.8% and 61.4% for contour1 and by 67.8% and 28.4% for contour2. Traditional DTW distance, on the other hand, improves by 44.6% for contour1 and 4.0% for contour2.