 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speech-language Pre-training for End-to-end Spoken Language Understanding
Feb 11, 2021
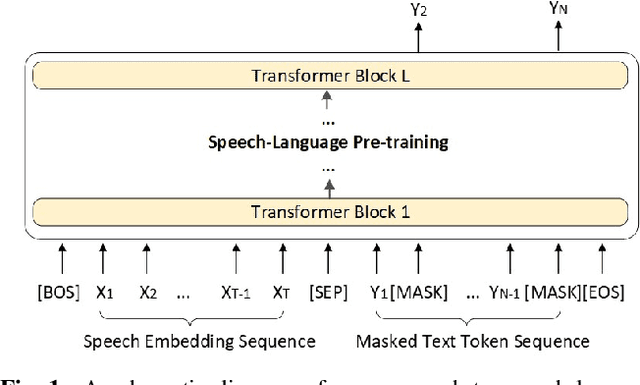
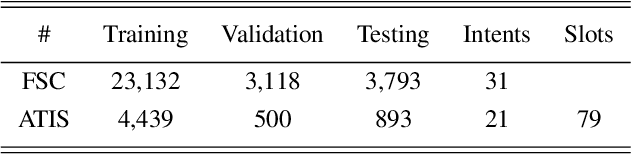
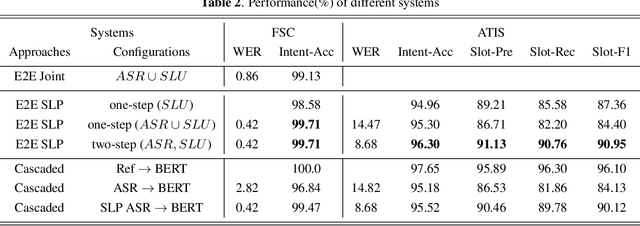
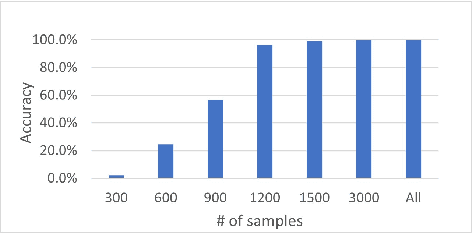
End-to-end (E2E) spoken language understanding (SLU) can infer semantics directly from speech signal without cascading an automatic speech recognizer (ASR) with a natural language understanding (NLU) module. However, paired utterance recordings and corresponding semantics may not always be available or sufficient to train an E2E SLU model in a real production environment. In this paper, we propose to unify a well-optimized E2E ASR encoder (speech) and a pre-trained language model encoder (language) into a transformer decoder. The unified speech-language pre-trained model (SLP) is continually enhanced on limited labeled data from a target domain by using a conditional masked language model (MLM) objective, and thus can effectively generate a sequence of intent, slot type, and slot value for given input speech in the inference. The experimental results on two public corpora show that our approach to E2E SLU is superior to the conventional cascaded method. It also outperforms the present state-of-the-art approaches to E2E SLU with much less paired data.
Diff-TTS: A Denoising Diffusion Model for Text-to-Speech
Apr 03, 2021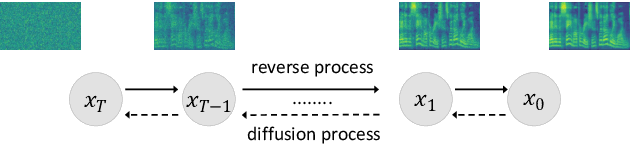

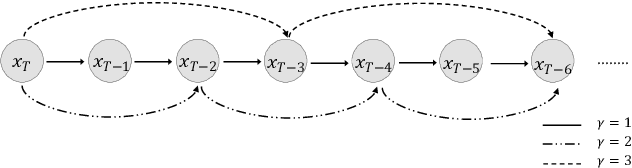
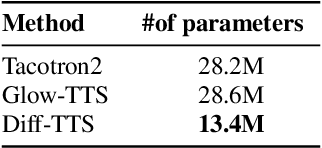
Although neural text-to-speech (TTS) models have attracted a lot of attention and succeeded in generating human-like speech, there is still room for improvements to its naturalness and architectural efficiency. In this work, we propose a novel non-autoregressive TTS model, namely Diff-TTS, which achieves highly natural and efficient speech synthesis. Given the text, Diff-TTS exploits a denoising diffusion framework to transform the noise signal into a mel-spectrogram via diffusion time steps. In order to learn the mel-spectrogram distribution conditioned on the text, we present a likelihood-based optimization method for TTS. Furthermore, to boost up the inference speed, we leverage the accelerated sampling method that allows Diff-TTS to generate raw waveforms much faster without significantly degrading perceptual quality. Through experiments, we verified that Diff-TTS generates 28 times faster than the real-time with a single NVIDIA 2080Ti GPU.
Bayesian Recurrent Units and the Forward-Backward Algorithm
Jul 21, 2022

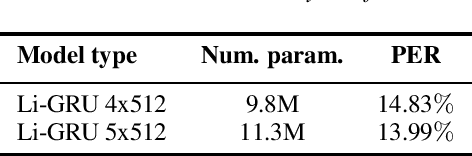
Using Bayes's theorem, we derive a unit-wise recurrence as well as a backward recursion similar to the forward-backward algorithm. The resulting Bayesian recurrent units can be integrated as recurrent neural networks within deep learning frameworks, while retaining a probabilistic interpretation from the direct correspondence with hidden Markov models. Whilst the contribution is mainly theoretical, experiments on speech recognition indicate that adding the derived units at the end of state-of-the-art recurrent architectures can improve the performance at a very low cost in terms of trainable parameters.
Direct Noisy Speech Modeling for Noisy-to-Noisy Voice Conversion
Nov 13, 2021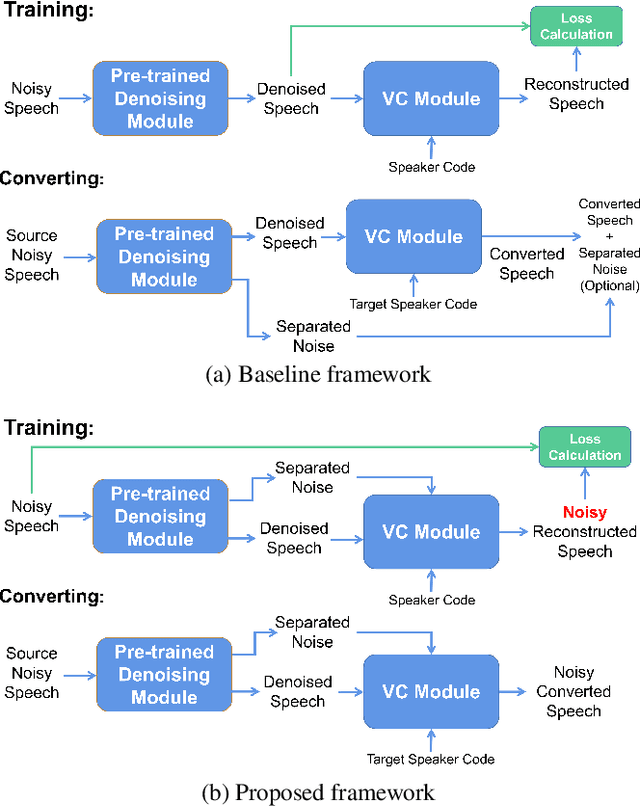
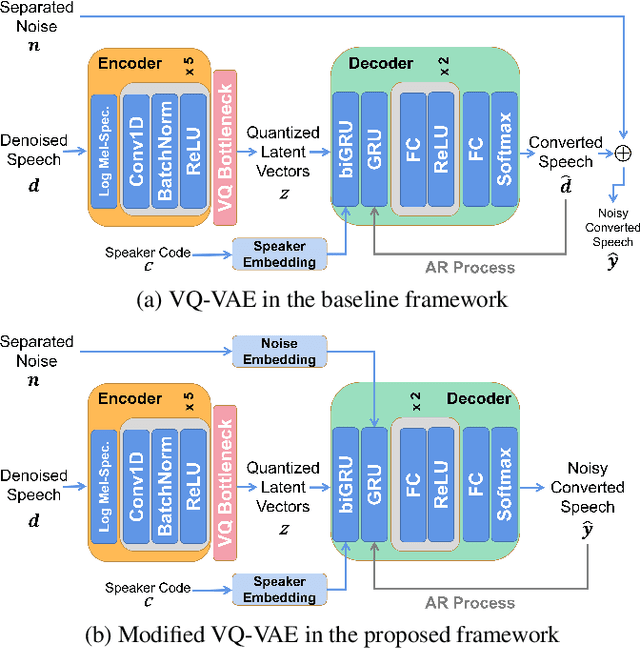
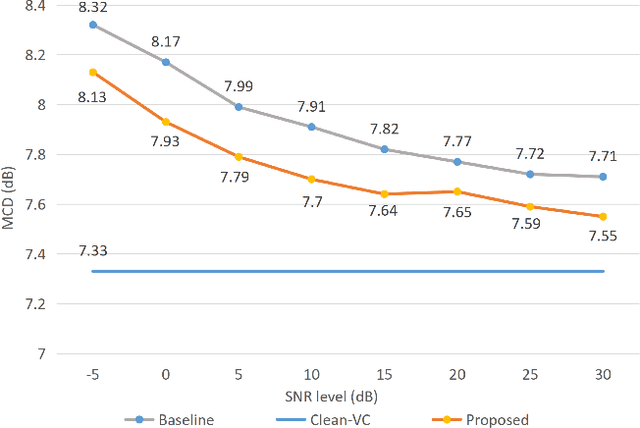
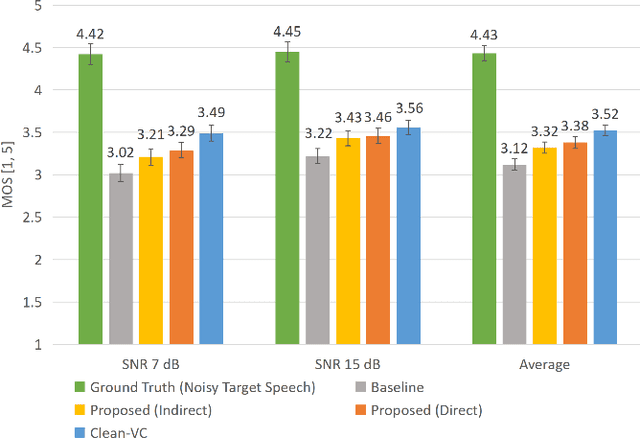
Beyond the conventional voice conversion (VC) where the speaker information is converted without altering the linguistic content, the background sounds are informative and need to be retained in some real-world scenarios, such as VC in movie/video and VC in music where the voice is entangled with background sounds. As a new VC framework, we have developed a noisy-to-noisy (N2N) VC framework to convert the speaker's identity while preserving the background sounds. Although our framework consisting of a denoising module and a VC module well handles the background sounds, the VC module is sensitive to the distortion caused by the denoising module. To address this distortion issue, in this paper we propose the improved VC module to directly model the noisy speech waveform while controlling the background sounds. The experimental results have demonstrated that our improved framework significantly outperforms the previous one and achieves an acceptable score in terms of naturalness, while reaching comparable similarity performance to the upper bound of our framework.
Direct multimodal few-shot learning of speech and images
Dec 10, 2020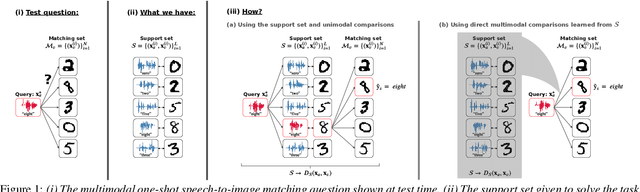

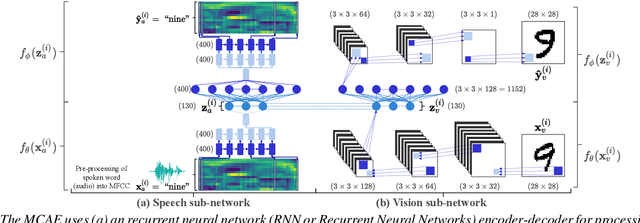
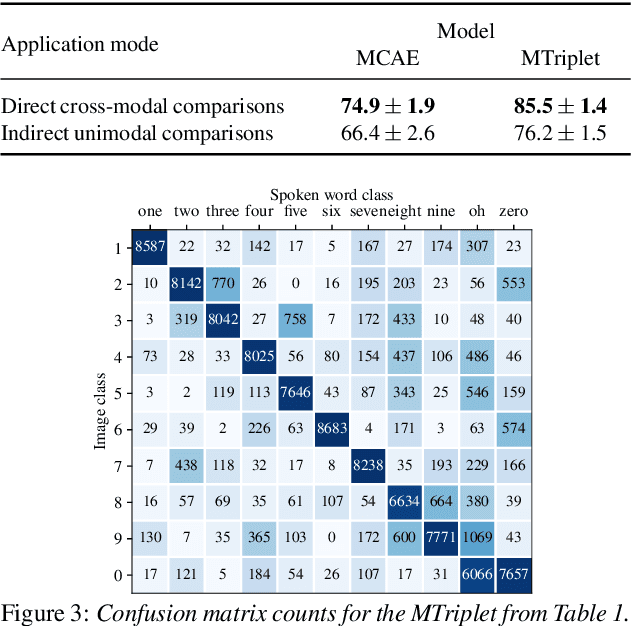
We propose direct multimodal few-shot models that learn a shared embedding space of spoken words and images from only a few paired examples. Imagine an agent is shown an image along with a spoken word describing the object in the picture, e.g. pen, book and eraser. After observing a few paired examples of each class, the model is asked to identify the "book" in a set of unseen pictures. Previous work used a two-step indirect approach relying on learned unimodal representations: speech-speech and image-image comparisons are performed across the support set of given speech-image pairs. We propose two direct models which instead learn a single multimodal space where inputs from different modalities are directly comparable: a multimodal triplet network (MTriplet) and a multimodal correspondence autoencoder (MCAE). To train these direct models, we mine speech-image pairs: the support set is used to pair up unlabelled in-domain speech and images. In a speech-to-image digit matching task, direct models outperform indirect models, with the MTriplet achieving the best multimodal five-shot accuracy. We show that the improvements are due to the combination of unsupervised and transfer learning in the direct models, and the absence of two-step compounding errors.
Language model fusion for streaming end to end speech recognition
Apr 09, 2021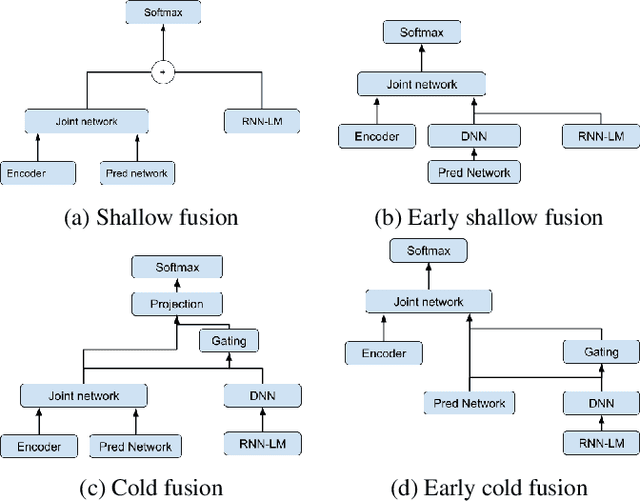
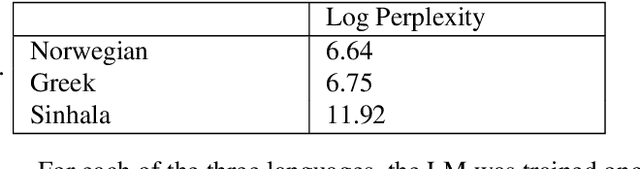
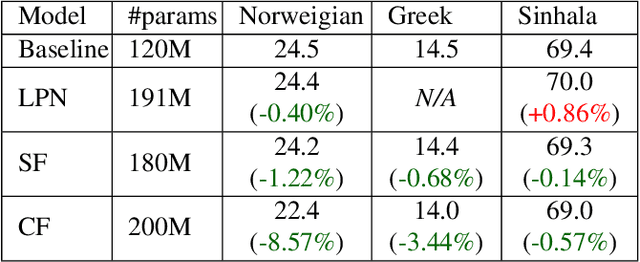
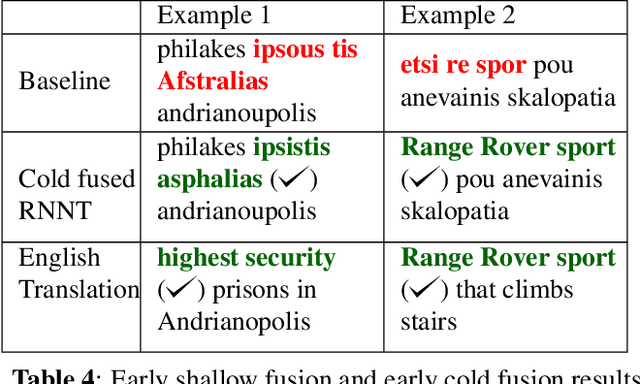
Streaming processing of speech audio is required for many contemporary practical speech recognition tasks. Even with the large corpora of manually transcribed speech data available today, it is impossible for such corpora to cover adequately the long tail of linguistic content that's important for tasks such as open-ended dictation and voice search. We seek to address both the streaming and the tail recognition challenges by using a language model (LM) trained on unpaired text data to enhance the end-to-end (E2E) model. We extend shallow fusion and cold fusion approaches to streaming Recurrent Neural Network Transducer (RNNT), and also propose two new competitive fusion approaches that further enhance the RNNT architecture. Our results on multiple languages with varying training set sizes show that these fusion methods improve streaming RNNT performance through introducing extra linguistic features. Cold fusion works consistently better on streaming RNNT with up to a 8.5% WER improvement.
INTERSPEECH 2021 ConferencingSpeech Challenge: Towards Far-field Multi-Channel Speech Enhancement for Video Conferencing
Apr 02, 2021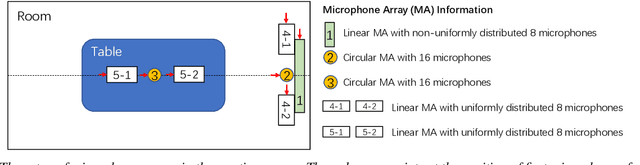
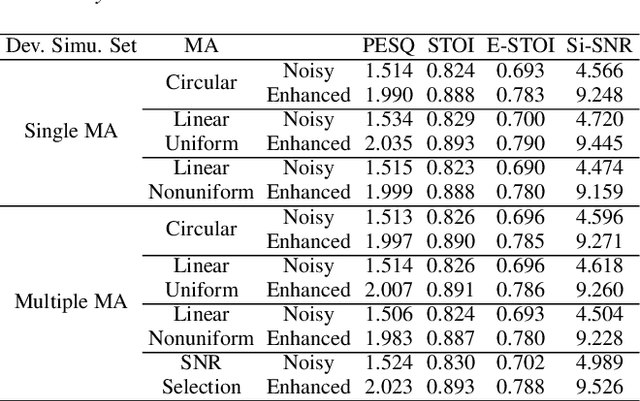

The ConferencingSpeech 2021 challenge is proposed to stimulate research on far-field multi-channel speech enhancement for video conferencing. The challenge consists of two separate tasks: 1) Task 1 is multi-channel speech enhancement with single microphone array and focusing on practical application with real-time requirement and 2) Task 2 is multi-channel speech enhancement with multiple distributed microphone arrays, which is a non-real-time track and does not have any constraints so that participants could explore any algorithms to obtain high speech quality. Targeting the real video conferencing room application, the challenge database was recorded from real speakers and all recording facilities were located by following the real setup of conferencing room. In this challenge, we open-sourced the list of open source clean speech and noise datasets, simulation scripts, and a baseline system for participants to develop their own system. The final ranking of the challenge will be decided by the subjective evaluation which is performed using Absolute Category Ratings (ACR) to estimate Mean Opinion Score (MOS), speech MOS (S-MOS), and noise MOS (N-MOS). This paper describes the challenge, tasks, datasets, and subjective evaluation. The baseline system which is a complex ratio mask based neural network and its experimental results are also presented.
Thai Wav2Vec2.0 with CommonVoice V8
Aug 09, 2022

Recently, Automatic Speech Recognition (ASR), a system that converts audio into text, has caught a lot of attention in the machine learning community. Thus, a lot of publicly available models were released in HuggingFace. However, most of these ASR models are available in English; only a minority of the models are available in Thai. Additionally, most of the Thai ASR models are closed-sourced, and the performance of existing open-sourced models lacks robustness. To address this problem, we train a new ASR model on a pre-trained XLSR-Wav2Vec model with the Thai CommonVoice corpus V8 and train a trigram language model to boost the performance of our ASR model. We hope that our models will be beneficial to individuals and the ASR community in Thailand.
Implicit Channel Learning for Machine Learning Applications in 6G Wireless Networks
Jun 24, 2022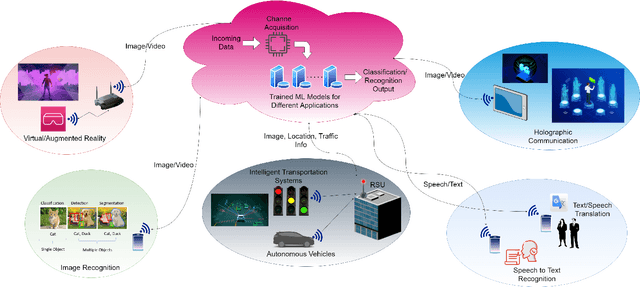
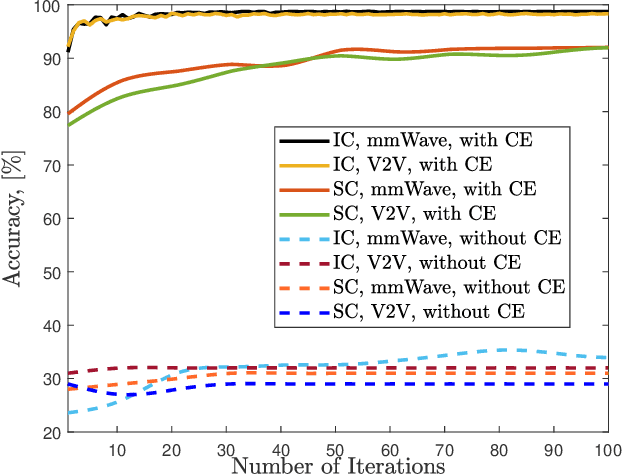
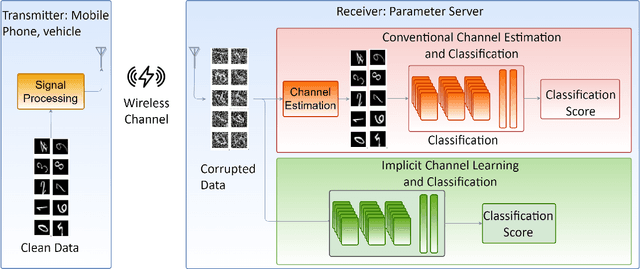
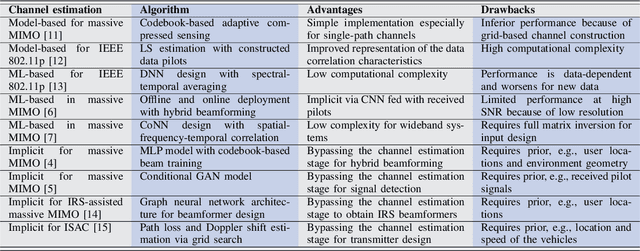
With the deployment of the fifth generation (5G) wireless systems gathering momentum across the world, possible technologies for 6G are under active research discussions. In particular, the role of machine learning (ML) in 6G is expected to enhance and aid emerging applications such as virtual and augmented reality, vehicular autonomy, and computer vision. This will result in large segments of wireless data traffic comprising image, video and speech. The ML algorithms process these for classification/recognition/estimation through the learning models located on cloud servers. This requires wireless transmission of data from edge devices to the cloud server. Channel estimation, handled separately from recognition step, is critical for accurate learning performance. Toward combining the learning for both channel and the ML data, we introduce implicit channel learning to perform the ML tasks without estimating the wireless channel. Here, the ML models are trained with channel-corrupted datasets in place of nominal data. Without channel estimation, the proposed approach exhibits approximately 60% improvement in image and speech classification tasks for diverse scenarios such as millimeter wave and IEEE 802.11p vehicular channels.
Learning to Count Words in Fluent Speech enables Online Speech Recognition
Jun 11, 2020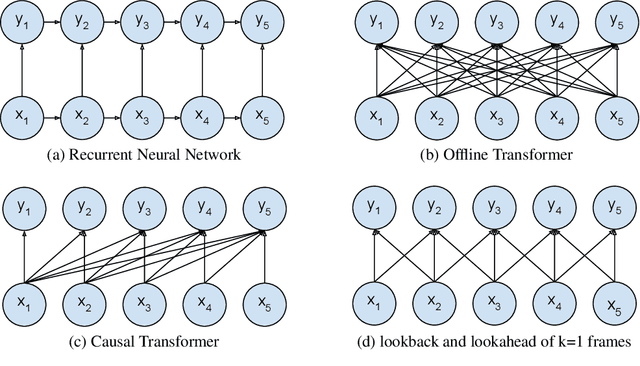

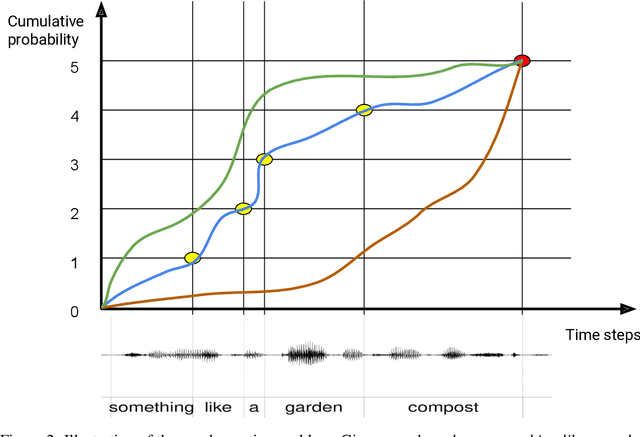
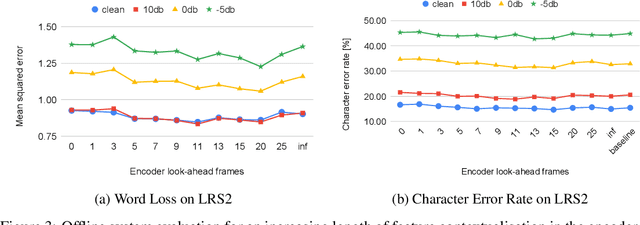
Sequence to Sequence models, in particular the Transformer, achieve state of the art results in Automatic Speech Recognition. Practical usage is however limited to cases where full utterance latency is acceptable. In this work we introduce Taris, a Transformer-based online speech recognition system aided by an auxiliary task of incremental word counting. We use the cumulative word sum to dynamically segment speech and enable its eager decoding into words. Experiments performed on the LRS2 and LibriSpeech datasets, of unconstrained and read speech respectively, show that the online system performs on a par with the offline one, while having a dynamic algorithmic delay of 5 segments. Furthermore, we show that the estimated segment length distribution resembles the word length distribution obtained with forced alignment, although our system does not require an exact segment-to-word equivalence. Taris introduces a negligible overhead compared to a standard Transformer, while the local relationship modelling between inputs and outputs grants invariance to sequence length by design.